↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs), despite their vast knowledge, often suffer from knowledge conflicts where outdated or incorrect information contradicts the provided context. This leads to inaccurate or hallucinated outputs, hindering their real-world applications. Existing methods like fine-tuning or model editing are often computationally expensive and may lead to catastrophic forgetting.
The paper introduces IRCAN, a novel framework designed to mitigate these conflicts. IRCAN leverages integrated gradients to identify neurons significantly contributing to context processing (context-aware neurons). It then enhances these neurons by increasing their weights, allowing the model to prioritize contextual information during generation. Extensive experiments demonstrate that IRCAN significantly improves LLM performance on tasks involving knowledge conflicts, offering a scalable and easily integrable solution. This contributes significantly to making LLMs more reliable and trustworthy.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical issue in large language model (LLM) generation: knowledge conflicts. By proposing a novel framework (IRCAN) that effectively identifies and reweights context-aware neurons, the research offers a practical and scalable solution to improve LLM accuracy and reliability. This work is highly relevant to current research trends focusing on LLM trustworthiness and opens new avenues for investigating neural network interpretability and contextual understanding.
Visual Insights#

This figure illustrates the IRCAN framework. It shows how IRCAN addresses knowledge conflicts in LLMs by first identifying neurons most sensitive to contextual information (context-aware neurons). This is done by calculating an attribution score for each neuron based on the impact of the context on the model’s prediction. Then, the weights of these identified neurons are increased, which steers the LLM to prioritize the contextual knowledge when generating output.
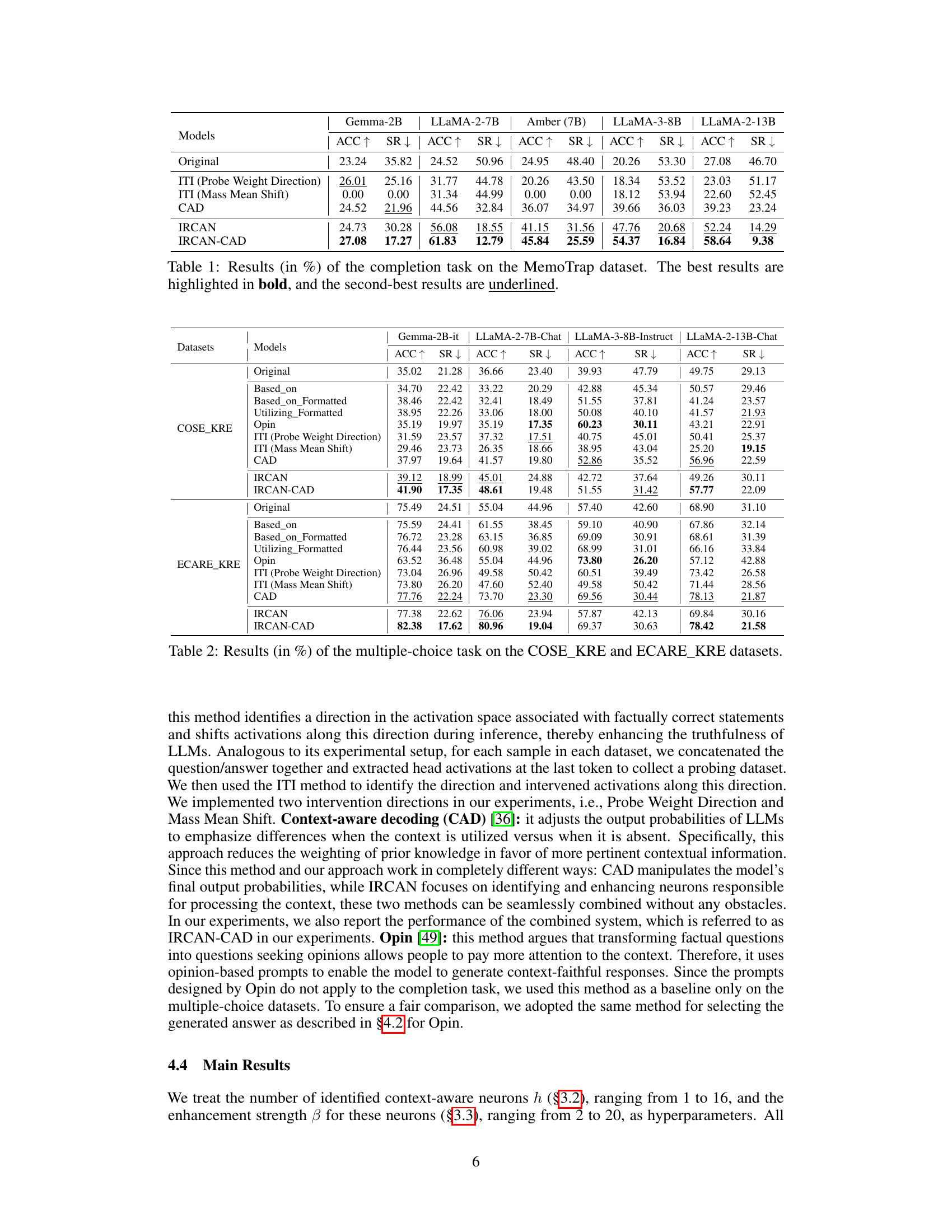
This table presents the accuracy and stubbornness rate (SR) for different LLMs on the MemoTrap completion task. The accuracy reflects how well the models generated contextually appropriate endings for proverbs, while the SR measures the tendency of models to stick to memorized, common proverb endings rather than adapting to the given context. The results show that IRCAN significantly improves both metrics across different LLMs.
In-depth insights#
LLM Knowledge Conflicts#
Large Language Models (LLMs), while powerful, suffer from knowledge conflicts. These arise when an LLM’s internal knowledge, acquired during training on massive datasets, contradicts information presented in a specific context. This often results in hallucinations or the generation of inaccurate or outdated responses. The root cause is the inherent limitations of LLMs in handling dynamically changing information and resolving conflicting knowledge sources. Mitigating knowledge conflicts is a crucial challenge for improving the reliability and trustworthiness of LLMs. Effective solutions often require integrating external knowledge sources, refining model training processes, or employing techniques that enhance context awareness. Identifying and re-weighting context-aware neurons within the LLM’s architecture is a promising approach, as it enables the model to prioritize relevant contextual knowledge and reduce reliance on potentially conflicting internal knowledge. This is a rapidly evolving research area, with ongoing efforts focused on developing novel methods for detecting and resolving knowledge conflicts to create more robust and dependable LLMs.
IRCAN Framework#
The IRCAN framework presents a novel approach to mitigate knowledge conflicts in large language models (LLMs). It cleverly leverages context-aware neurons, identifying those most crucial in processing contextual information via an attribution score derived from integrated gradients. By reweighting these neurons, IRCAN effectively steers the LLM towards prioritizing the new knowledge provided in the context, thus reducing reliance on potentially outdated or conflicting internal knowledge. This plug-and-play framework shows significant promise for improving LLM accuracy and reliability in various tasks, particularly those susceptible to knowledge conflicts, making it a valuable contribution to the field.
Contextual Neuron#
The concept of “Contextual Neurons” in large language models (LLMs) is a crucial one, representing the neural pathways within the network most directly involved in processing and integrating contextual information. These neurons act as bridges between the inherent, pre-trained knowledge of the LLM and newly provided context. Identifying and manipulating these neurons is key to improving the LLM’s ability to handle knowledge conflicts, where older or inaccurate information clashes with new input. The strength of the contextual neurons’ influence on the LLM’s output can be significantly amplified through reweighting, steering the model towards contextually-relevant and accurate responses. Research efforts in this area focus on attribution methods to pinpoint these neurons, enabling precise manipulation and enhanced context-awareness. This approach provides a more nuanced and interpretable method for managing knowledge conflicts compared to broader approaches like fine-tuning. The practical implication is an LLM with increased responsiveness to context, resolving inconsistencies and reducing hallucinations. Further research should explore the robustness of identifying contextual neurons across diverse LLM architectures and datasets, and investigate the long-term effects of reweighting on the model’s overall performance and knowledge retention.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In this context, the authors likely performed several variations, each removing a specific element (e.g., the context-aware neuron identification, the reweighting process, or the integration with a pre-existing method). This allowed them to isolate the effects of each component and quantify its importance in the overall model performance. The results likely showed that removing key components resulted in a significant decrease in performance, highlighting the critical role of each of these elements in resolving knowledge conflicts. This kind of analysis provides a rigorous evaluation of the framework’s design, allowing the researchers to justify their choices and demonstrate the model’s robustness. The ablation results would thus serve as strong empirical evidence supporting the claims made about the individual components’ importance. By methodically dissecting the model in this way, the study gains substantial credibility and offers a deeper understanding of the mechanism behind its improvements in LLM generation.
Future Work#
The authors acknowledge the limitations of their current work, focusing on relatively small synthetic datasets. Future work should concentrate on evaluating the IRCAN framework using more extensive and diverse real-world datasets. This includes exploring its effectiveness in handling knowledge conflicts within long-context tasks and in the context of retrieval-augmented generation (RAG). Integrating IRCAN with more sophisticated prompt engineering techniques could further enhance its ability to guide LLMs toward contextually accurate responses. Furthermore, investigating the impact of hyperparameter tuning on model performance across a wider range of models and tasks is crucial. In addition, research into the impact on other model families and exploring the framework’s adaptability to different LLMs should be undertaken. Finally, a thorough investigation into the interpretability offered by IRCAN, potentially via visualization techniques, would be valuable to further understand its inner workings and potentially unlock further performance gains.
More visual insights#
More on figures

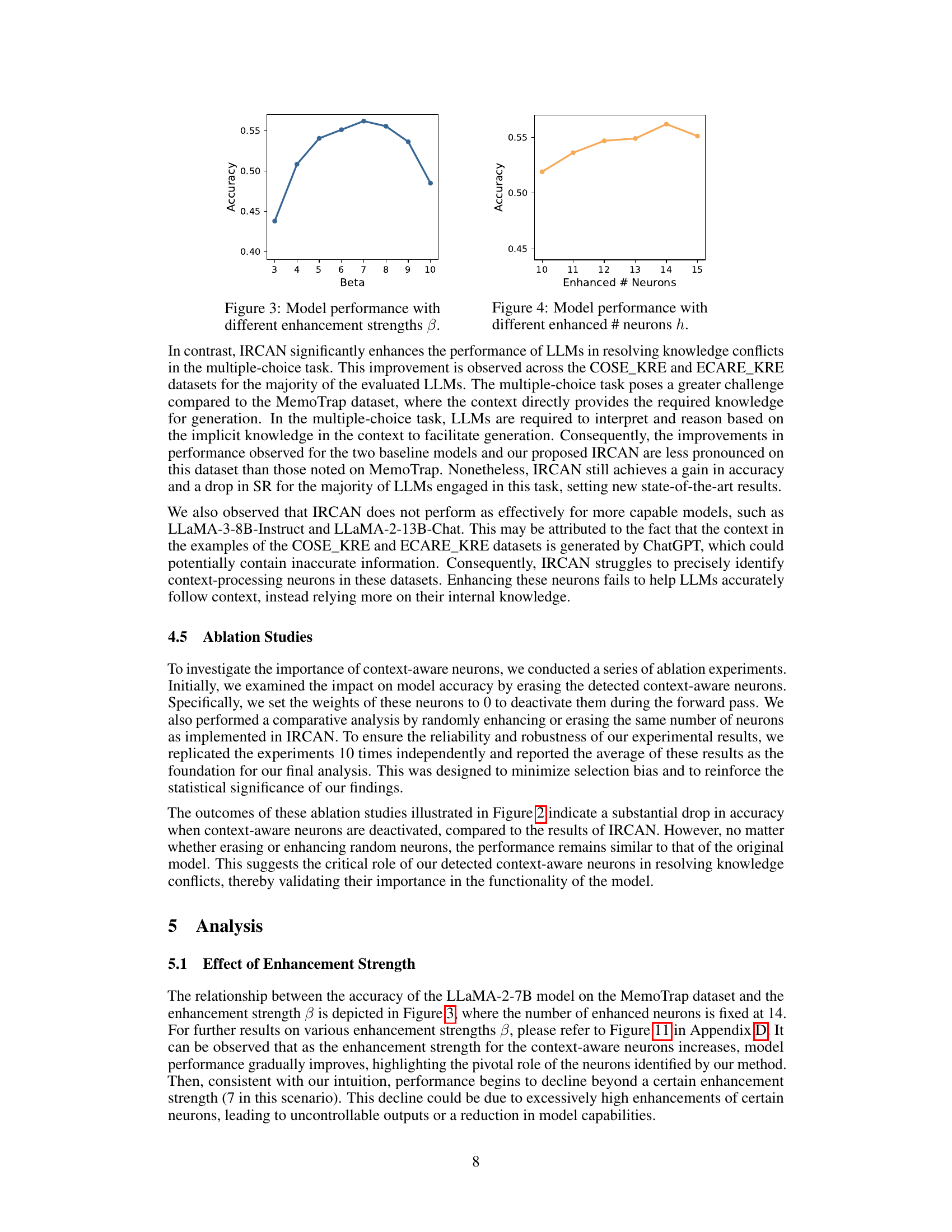
This figure presents the results of ablation studies conducted to evaluate the impact of context-aware neurons on model accuracy. Three variants are compared against the original IRCAN method: ErCAN (erasing context-aware neurons), ERN (enhancing random neurons), and ErRN (erasing random neurons). The bar charts show the accuracy achieved by each method on three different datasets (MemoTrap, COSE, and E-CARE) across several language models (Gemma-2B, Amber-7B, LLaMA-2-7B, LLaMA-3-8B, LLaMA-2-13B, and their chat/instruct versions). The results demonstrate the importance of context-aware neurons for improving model performance in handling knowledge conflicts.
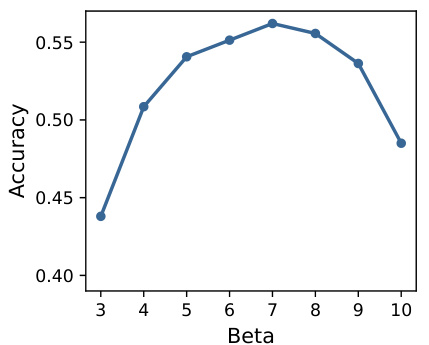
This figure shows the relationship between the enhancement strength (β) and the accuracy of the LLaMA-2-7B model on the MemoTrap dataset. The number of enhanced neurons (h) is held constant at 14. The graph illustrates that as β increases, accuracy initially improves, reaches a peak, and then declines. This indicates an optimal enhancement strength exists, beyond which increasing β negatively impacts performance.
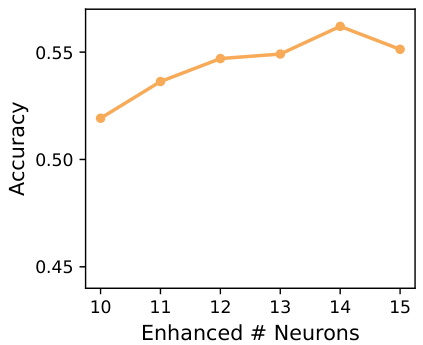
This figure shows the relationship between the number of enhanced neurons and the model’s accuracy. The x-axis represents the number of enhanced neurons (h), and the y-axis represents the accuracy. The plot shows that accuracy initially increases as the number of enhanced neurons increases, reaching a peak at around h=14. Beyond that point, accuracy starts to decrease slightly.
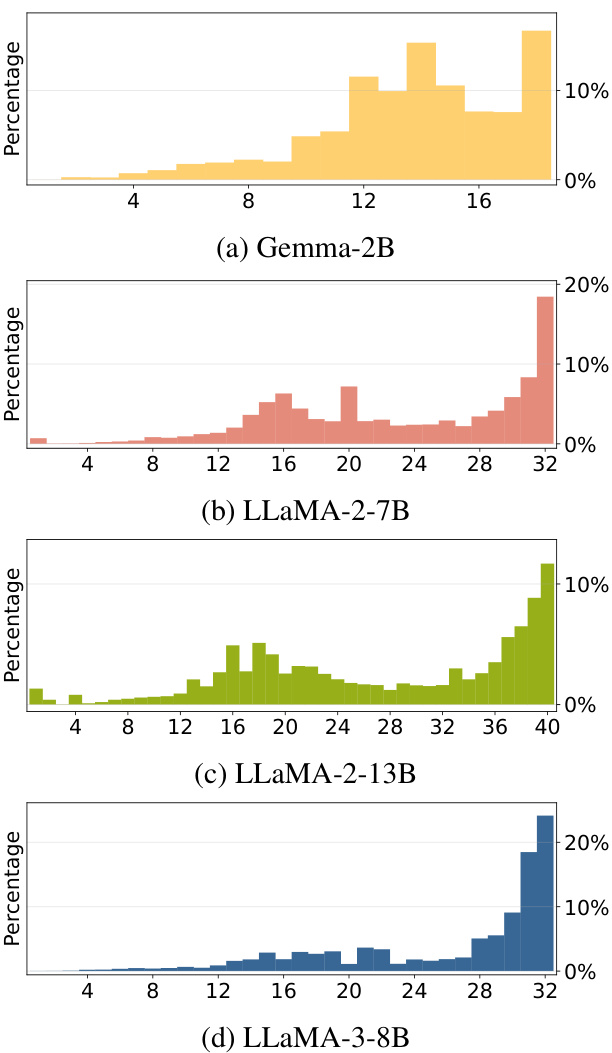
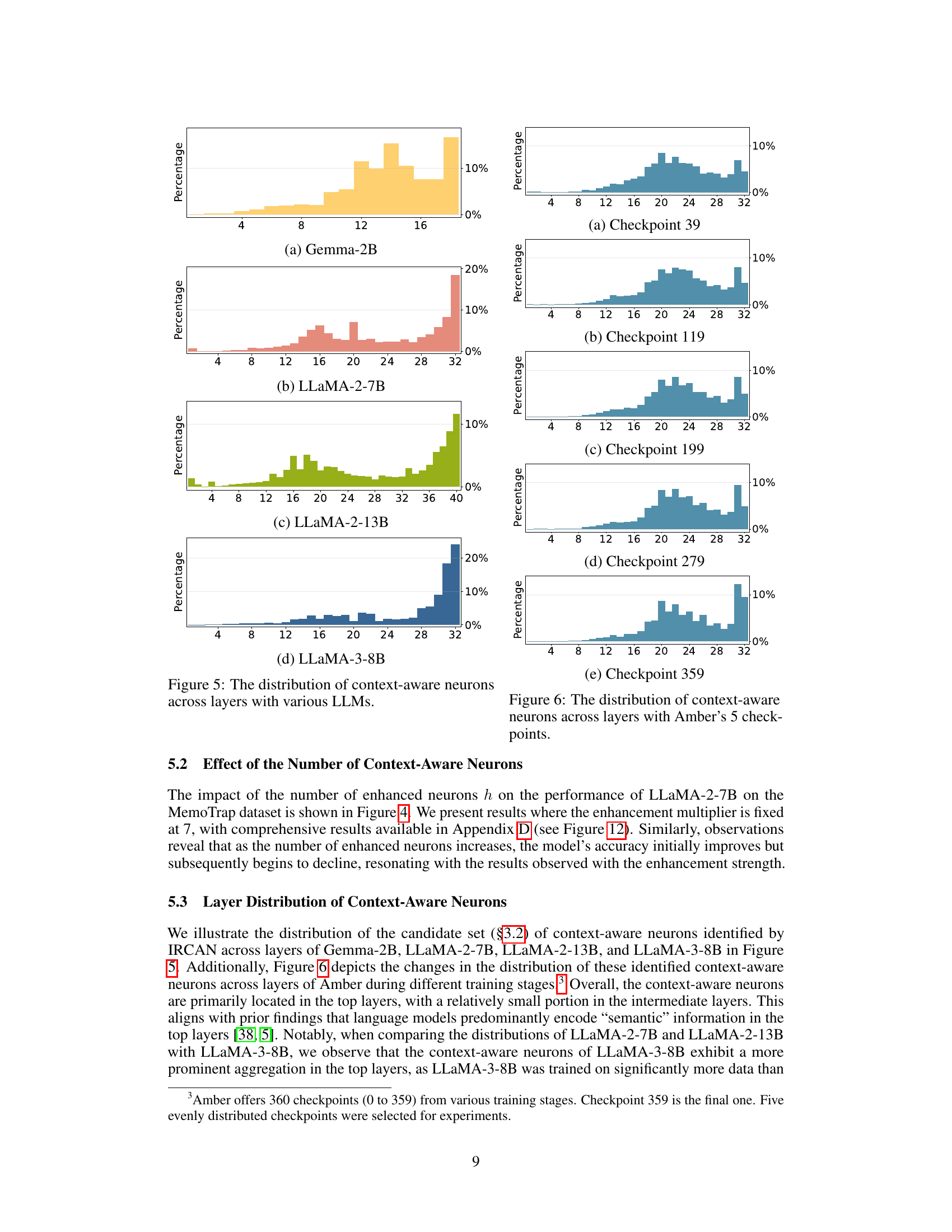
This figure shows the distribution of context-aware neurons across different layers for four different LLMs: Gemma-2B, LLaMA-2-7B, LLaMA-2-13B, and LLaMA-3-8B. Each sub-figure represents a specific LLM and displays a histogram showing the percentage of context-aware neurons found in each layer of the model. The x-axis shows the layer number, and the y-axis shows the percentage of context-aware neurons. This visualization helps to understand where in the model these context-aware neurons are most concentrated.

This figure shows the distribution of context-aware neurons across different layers of various LLMs (Gemma-2B, LLaMA-2-7B, LLaMA-2-13B, and LLaMA-3-8B). The x-axis represents the layer number, and the y-axis shows the percentage of context-aware neurons in each layer. The distribution varies across different models, indicating the diverse ways each model processes contextual information.

This figure illustrates the IRCAN framework’s three phases: context-aware attribution, neuron identification, and neuron reweighting. It shows how IRCAN addresses knowledge conflicts by identifying and strengthening neurons crucial for processing contextual information, thus aligning LLM outputs with the provided context.

This figure illustrates the IRCAN framework. It shows how IRCAN addresses knowledge conflicts in LLMs by first calculating an attribution score for each neuron to determine its contribution to context processing. Neurons with high scores are identified as ‘context-aware neurons.’ Finally, these context-aware neurons are reweighted to prioritize the contextual knowledge over the LLM’s inherent knowledge, resulting in more contextually faithful generation.

This figure illustrates the IRCAN framework. It shows how IRCAN addresses knowledge conflicts in LLMs by first calculating attribution scores for each neuron to determine its contribution to processing contextual information. Neurons with high scores (context-aware neurons) are then identified and reweighted, enabling the model to prioritize contextual knowledge during generation and improve its accuracy and faithfulness to the input context.

This figure illustrates the IRCAN framework’s three main steps: calculating the attribution score for each neuron to quantify its contribution to context processing; identifying context-aware neurons by selecting those with the highest scores; and reweighting the identified neurons to increase the model’s reliance on contextual knowledge during generation.

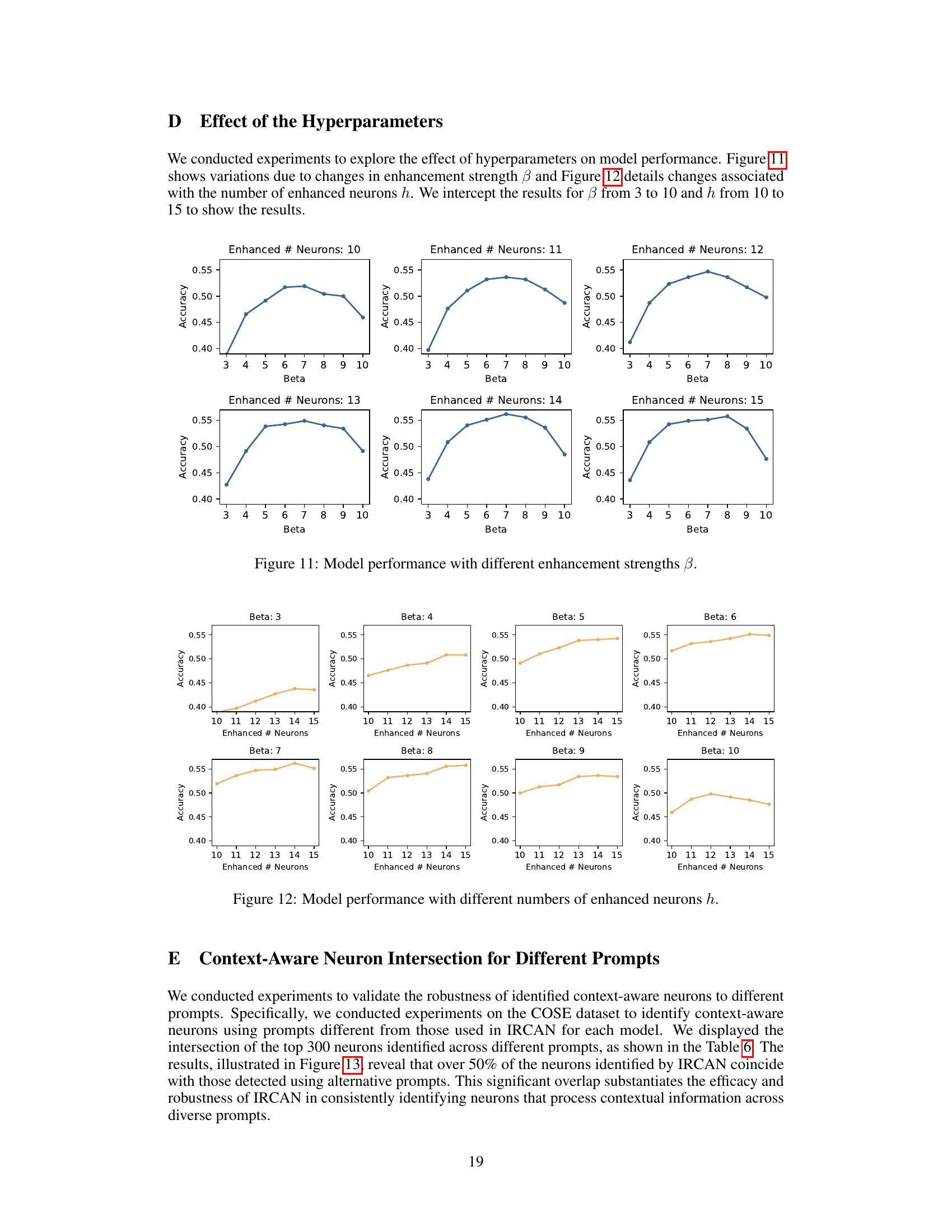
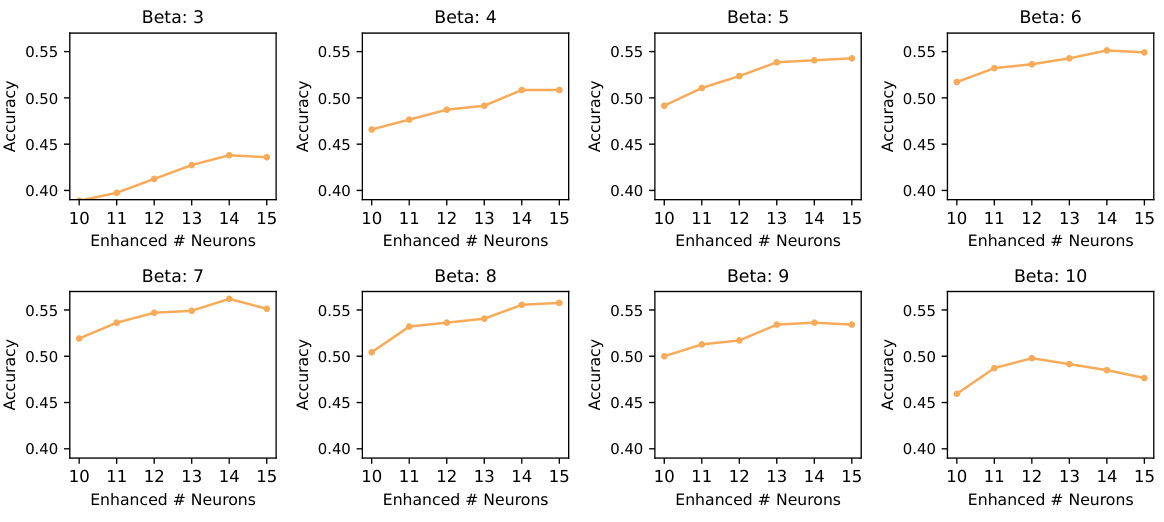
This figure shows the relationship between the model’s accuracy and the enhancement strength (β) when varying the number of enhanced neurons (h). Each subplot represents a different number of enhanced neurons (h), ranging from 10 to 15. The x-axis represents the enhancement strength (β), and the y-axis represents the accuracy. The figure demonstrates that accuracy generally improves with increasing β until reaching a peak after which accuracy starts to decline, indicating that there is an optimal enhancement strength for each number of enhanced neurons.
This figure illustrates the IRCAN framework. It shows how IRCAN addresses knowledge conflicts in LLMs by first calculating an attribution score for each neuron to determine its contribution to processing contextual information. Neurons with high scores (context-aware neurons) are then identified and reweighted to prioritize contextual knowledge during generation, thereby improving the model’s accuracy and alignment with the provided context.
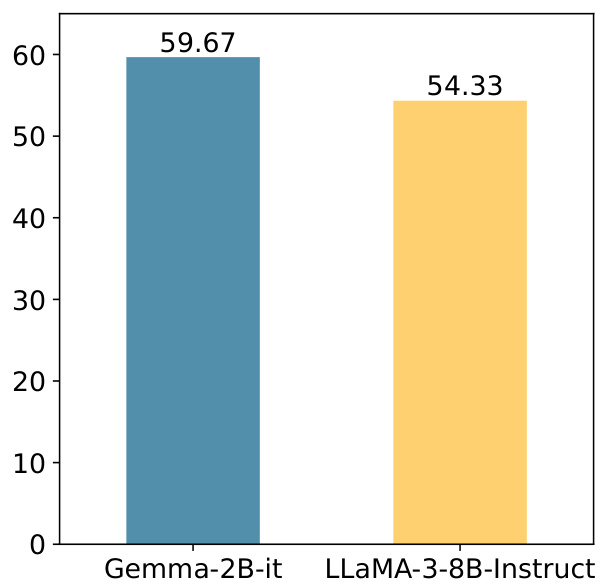
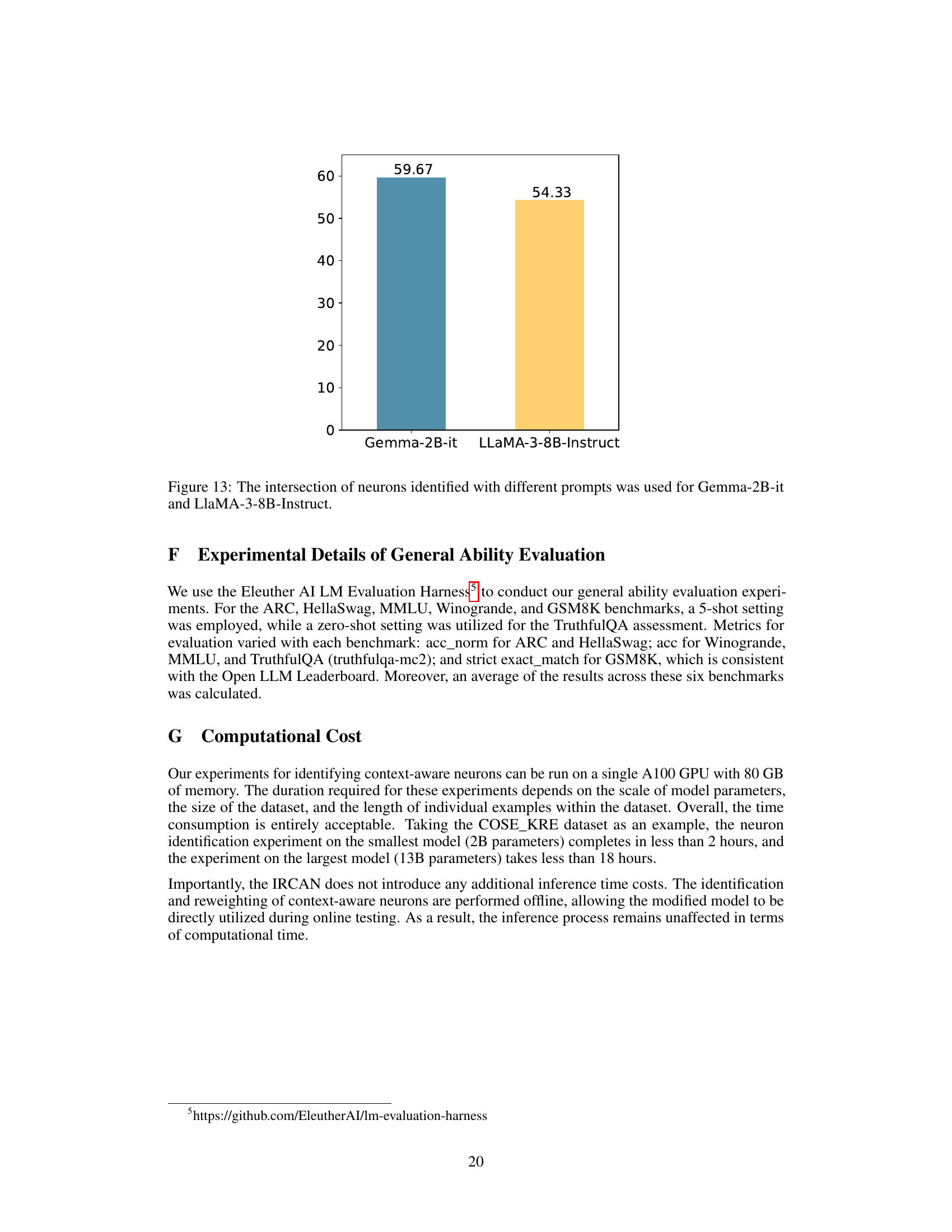
This bar chart displays the percentage overlap of context-aware neurons identified by IRCAN using different prompts for two LLMs: Gemma-2B-it and LLaMA-3-8B-Instruct. It demonstrates the robustness of IRCAN in identifying consistent context-aware neurons across various prompts, highlighting its reliability in identifying critical neurons regardless of the specific input.
More on tables
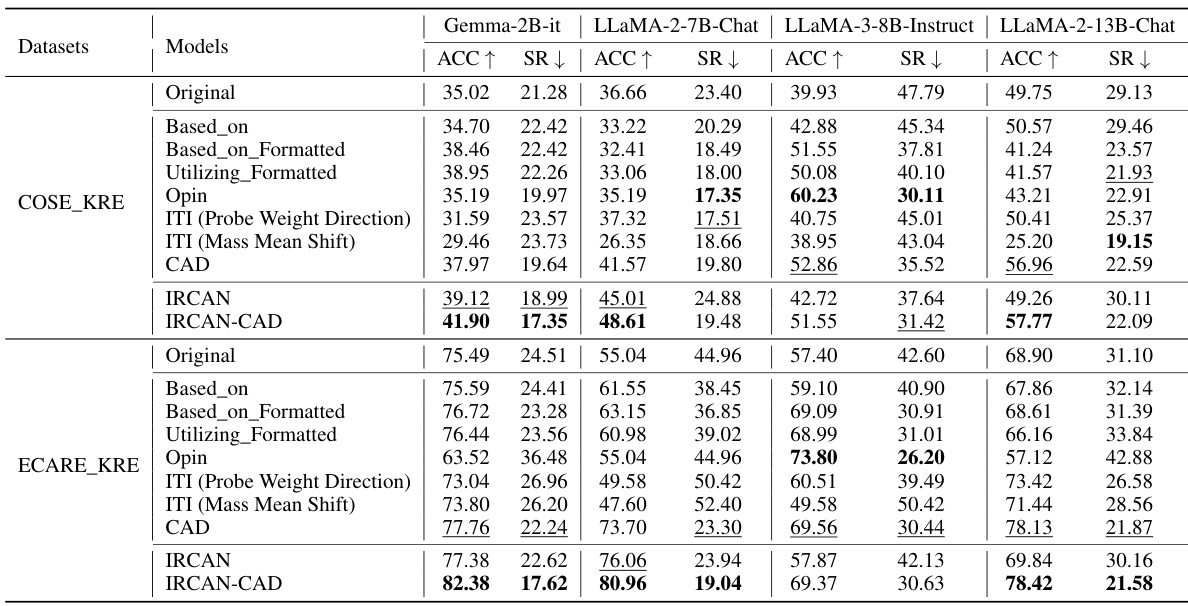
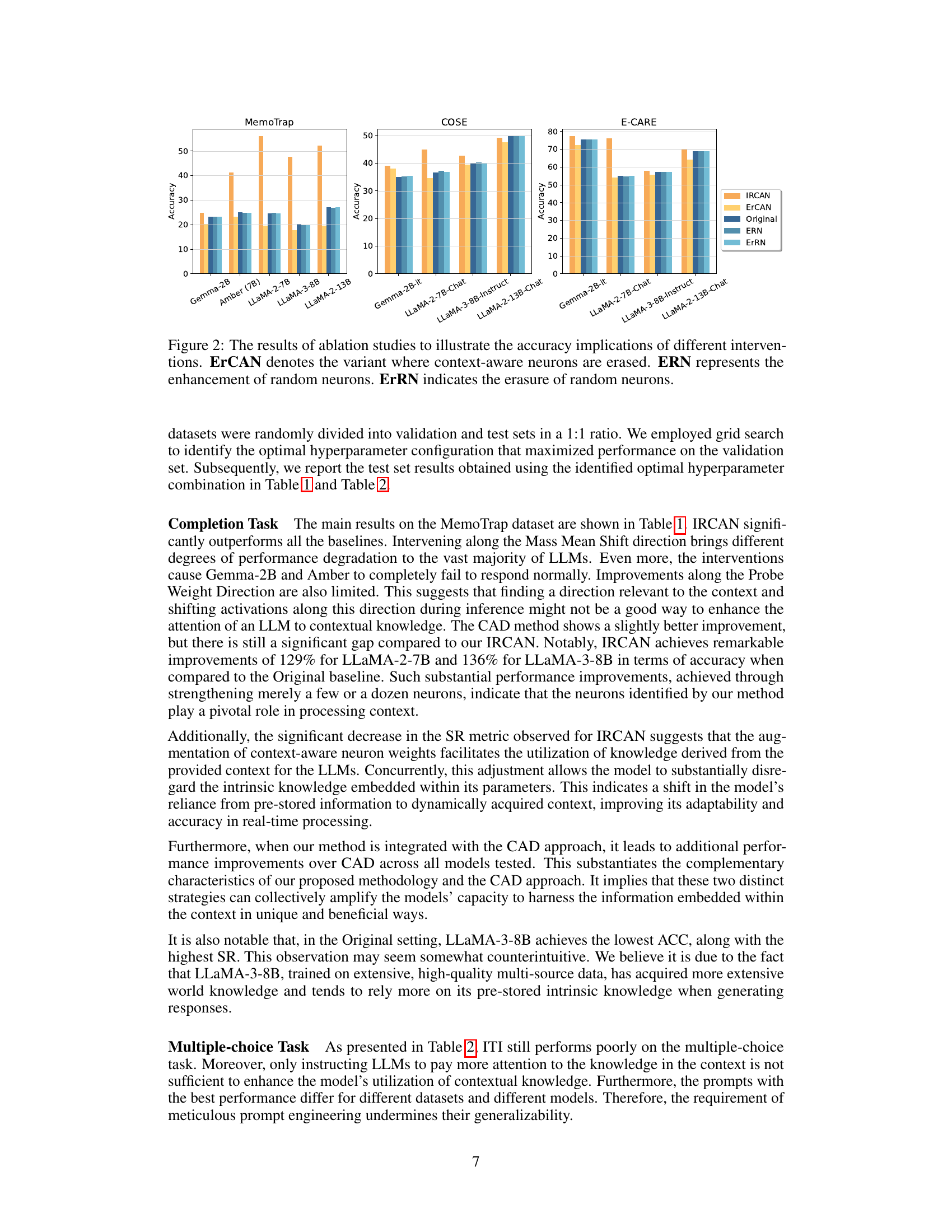
This table presents the results of the multiple-choice task using the COSE_KRE and ECARE_KRE datasets. It compares the accuracy (ACC) and stubbornness rate (SR) of several different LLMs (large language models), including baselines (Original, prompt engineering methods, ITI), CAD, IRCAN, and IRCAN combined with CAD. The results show the performance improvement of the proposed method (IRCAN) in handling knowledge conflicts in the context of multiple-choice questions.
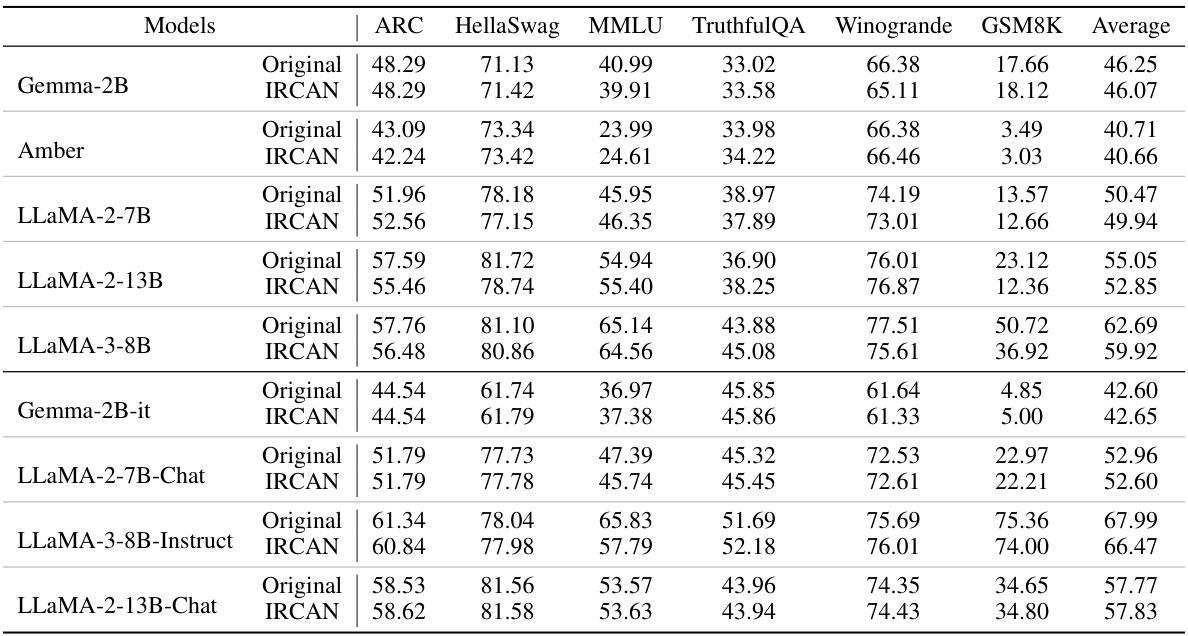
This table presents the results of evaluating various LLMs on six widely-used benchmarks: ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. The table compares the performance of the original LLMs against those enhanced by IRCAN. It shows the accuracy scores for each model on each benchmark, giving an overall sense of the models’ general abilities and how IRCAN impacts them.

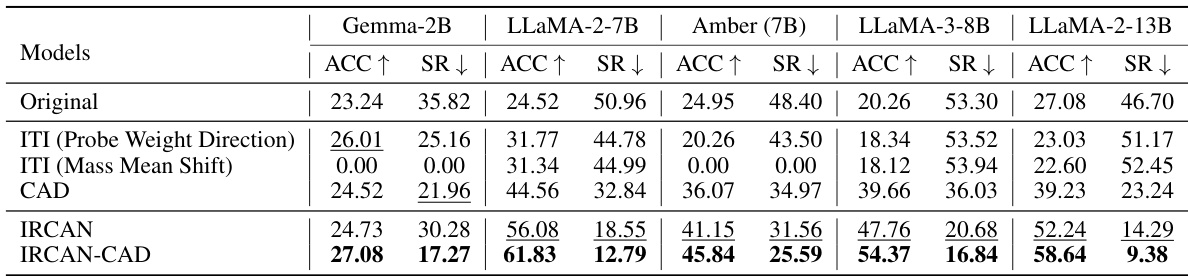
This table presents the results of the completion task using the MemoTrap dataset. It shows the accuracy and stubbornness rate for several LLMs (Gemma-2B, LLaMA-2-7B, Amber (7B), LLaMA-3-8B, LLaMA-2-13B) under different conditions: Original, ITI (Probe Weight Direction), ITI (Mass Mean Shift), CAD, IRCAN, and IRCAN-CAD. The best performing method for each LLM is highlighted in bold, and the second best is underlined. Accuracy measures the percentage of correctly generated words, while the stubbornness rate shows how often the model uses memorized knowledge instead of contextual knowledge.

This table presents the results of the completion task experiments conducted on the MemoTrap dataset. The task involved generating a continuation to a well-known proverb in a way that deviated from the standard ending. The table shows the accuracy and stubbornness rate (SR) for several large language models (LLMs) using various methods. Accuracy represents the percentage of correctly generated words, while SR indicates the tendency of the LLM to stick to its pre-trained knowledge instead of incorporating contextual information provided in the prompt. The best performing model for each LLM is highlighted in bold, with the second-best underlined.

This table presents the results of the completion task experiments performed on the MemoTrap dataset. The accuracy and stubbornness rate are measured for various LLMs (Gemma-2B, LLaMA-2-7B, Amber (7B), LLaMA-3-8B, LLaMA-2-13B) using different methods: Original, ITI (Probe Weight Direction and Mass Mean Shift), CAD, IRCAN and IRCAN-CAD. The best performing method for each LLM is highlighted in bold, while the second best is underlined.
Full paper#