↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Video scene graph generation (VidSGG) is a crucial task for understanding complex video content, but existing methods struggle with temporal dependencies and long-range interactions. Current datasets also lack the visual richness and detailed annotations needed to accurately capture intricate relationships and object interactions, particularly in aerial video. This limits the development and evaluation of VidSGG models that can effectively understand real-world scenarios.
This paper introduces CYCLO, a new cyclic graph transformer approach that addresses these issues. CYCLO effectively captures long-range temporal dependencies and object relationships through a cyclic attention mechanism, improving accuracy and efficiency. The authors also introduce the AeroEye dataset, which offers visually comprehensive annotations of various drone scenes. Experiments show that CYCLO outperforms existing methods on standard VidSGG benchmarks and the new dataset, establishing a new state-of-the-art in VidSGG.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to video scene graph generation (VidSGG), a crucial task in video understanding. The CYCLO model addresses limitations of existing methods by incorporating temporal information using a cyclic graph transformer architecture. This allows for more accurate and efficient modeling of complex relationships, especially in challenging scenarios like those found in aerial videos, thus advancing the state-of-the-art in VidSGG. The introduction of the AeroEye dataset, further enhances this impact by providing a valuable resource for future research in this area.
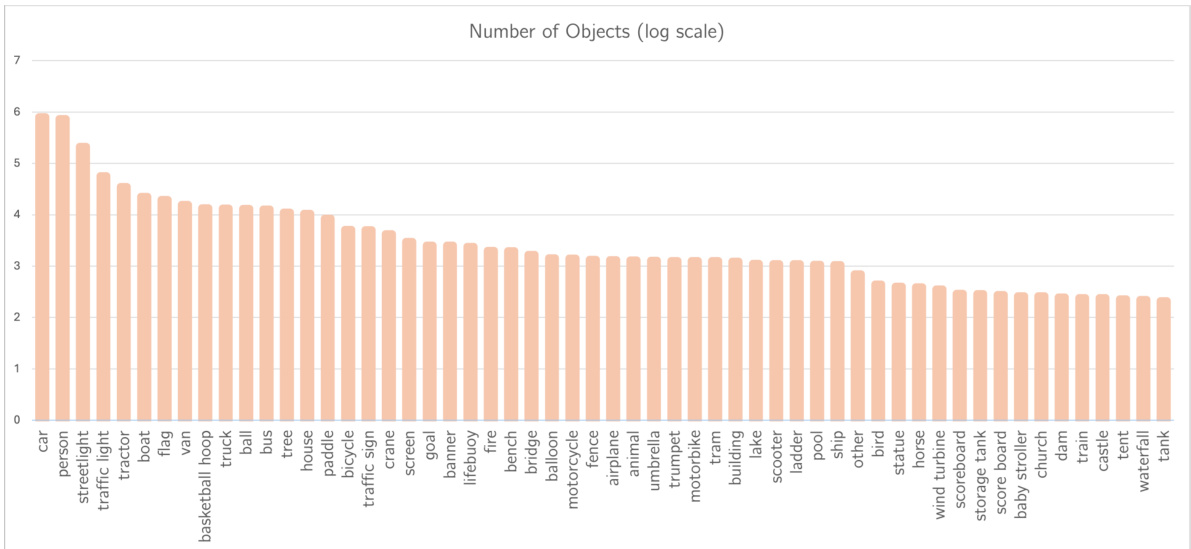
Visual Insights#
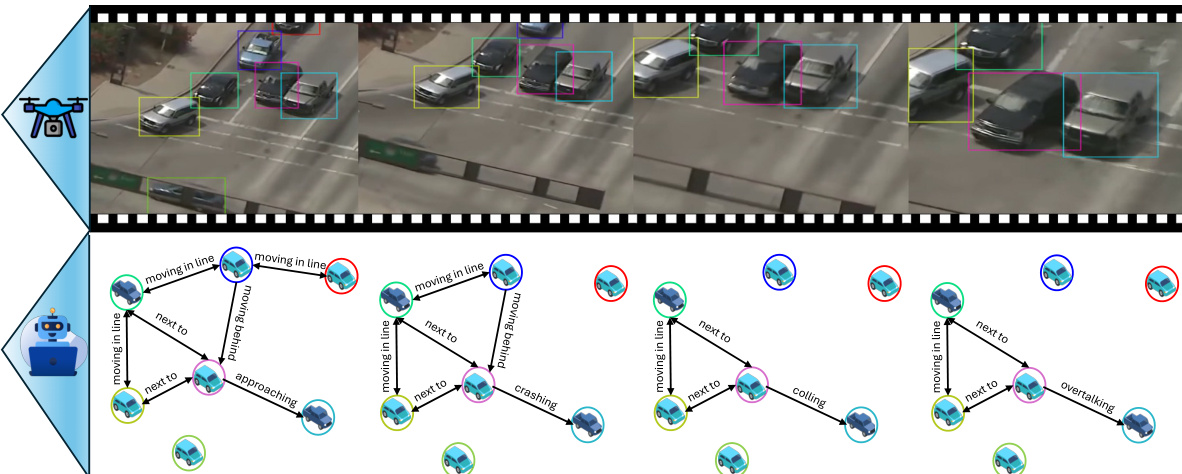
The figure illustrates the process of multi-object relationship modeling in aerial videos using the CYCLO model. The top part shows a sequence of drone-captured frames depicting several vehicles in motion. The bottom part shows how the CYCLO model identifies and refines relationships between objects across those frames, incorporating temporal information about their positions and interactions to create a more comprehensive understanding of the scene’s dynamics.

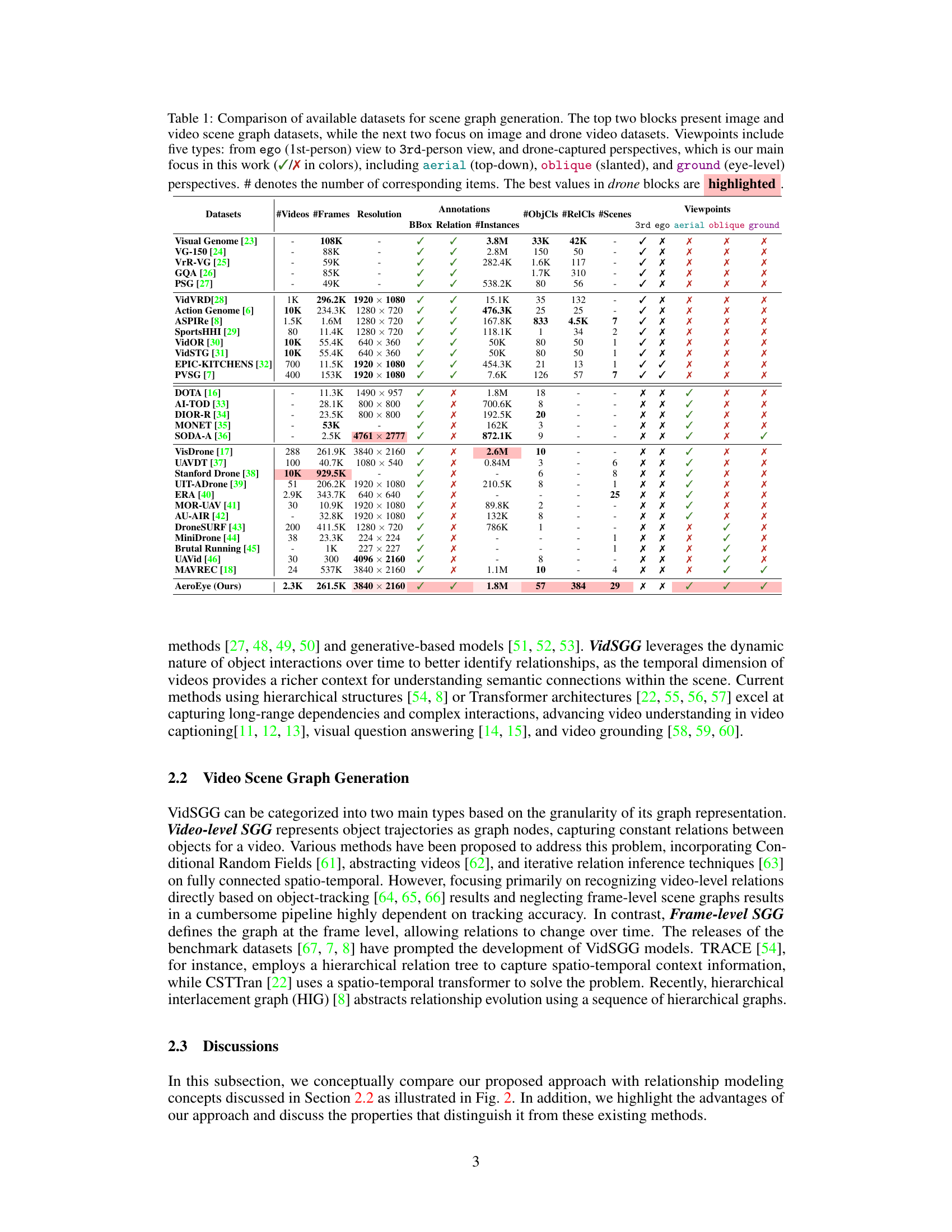
This table compares various datasets used for scene graph generation, focusing on their characteristics relevant to the paper’s work on aerial videos. It contrasts image and video datasets, highlighting the number of videos, frames, resolution, object and relation classes, number of scenes, and annotation types (bounding boxes and relations). Crucially, it indicates the viewpoints offered by each dataset (ego, 3rd-person, aerial, oblique, ground), showing the unique value of the AeroEye dataset in providing diverse aerial perspectives.
In-depth insights#
Cyclic Attention#
The concept of “Cyclic Attention” presents a novel approach to sequence processing, particularly beneficial for video analysis where cyclical patterns and temporal dependencies are crucial. Instead of the typical linear approach of standard self-attention, cyclic attention processes the sequence in a circular manner, connecting the end to the beginning. This approach is advantageous for modeling periodic or repeating actions, where the past significantly influences future events. This is achieved by applying a cyclical indexing mechanism (e.g., using the modulo operator), allowing the model to capture long-range temporal dependencies effectively. Unlike standard self-attention, cyclic attention isn’t permutation-equivariant, meaning the order of the sequence matters, reflecting the inherent temporal order in video data. This property is crucial for situations where the sequence of events is significant, ensuring correct temporal reasoning. However, a limitation of this method might be its computational cost, particularly for extremely long sequences, as the model considers all elements in each attention step, regardless of their temporal distance. Furthermore, the effectiveness of cyclic attention could be sensitive to the choice of the shift parameter in the cyclical indexing; further investigation is necessary to understand the optimal settings for various types of temporal sequences and video data.
Temporal Modeling#
Effective temporal modeling in video analysis is crucial for understanding dynamic relationships between objects. Approaches vary widely, from simple recurrent networks capturing short-term dependencies to sophisticated graph neural networks that model complex interactions over extended timeframes. The choice of model heavily depends on the nature of the temporal dependencies: are they short-lived, periodic, or long-range? Data representation also plays a critical role. Some methods employ trajectories as nodes in a graph, while others focus on frame-level relationships that evolve over time. Advanced techniques like cyclic graph transformers offer unique advantages by incorporating cyclical patterns and long-range dependencies, potentially superior for tasks involving repetitive actions or periodic events. However, challenges remain in handling noise and occlusion, particularly in high-density scenarios. Future work should explore hybrid methods combining the strengths of different approaches to achieve more robust and efficient temporal modeling. This includes addressing computational costs associated with complex architectures and developing more interpretable models.
AeroEye Dataset#
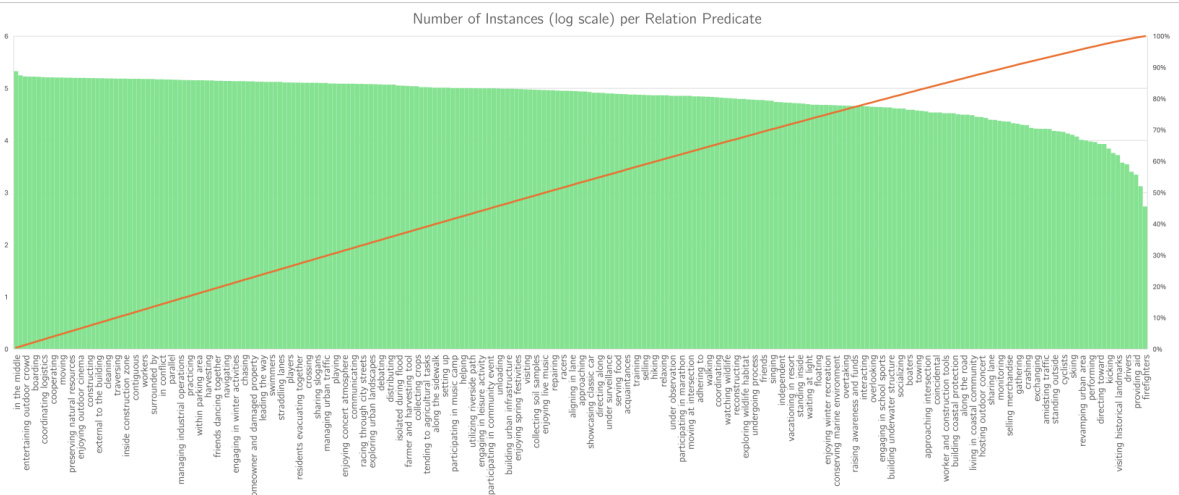
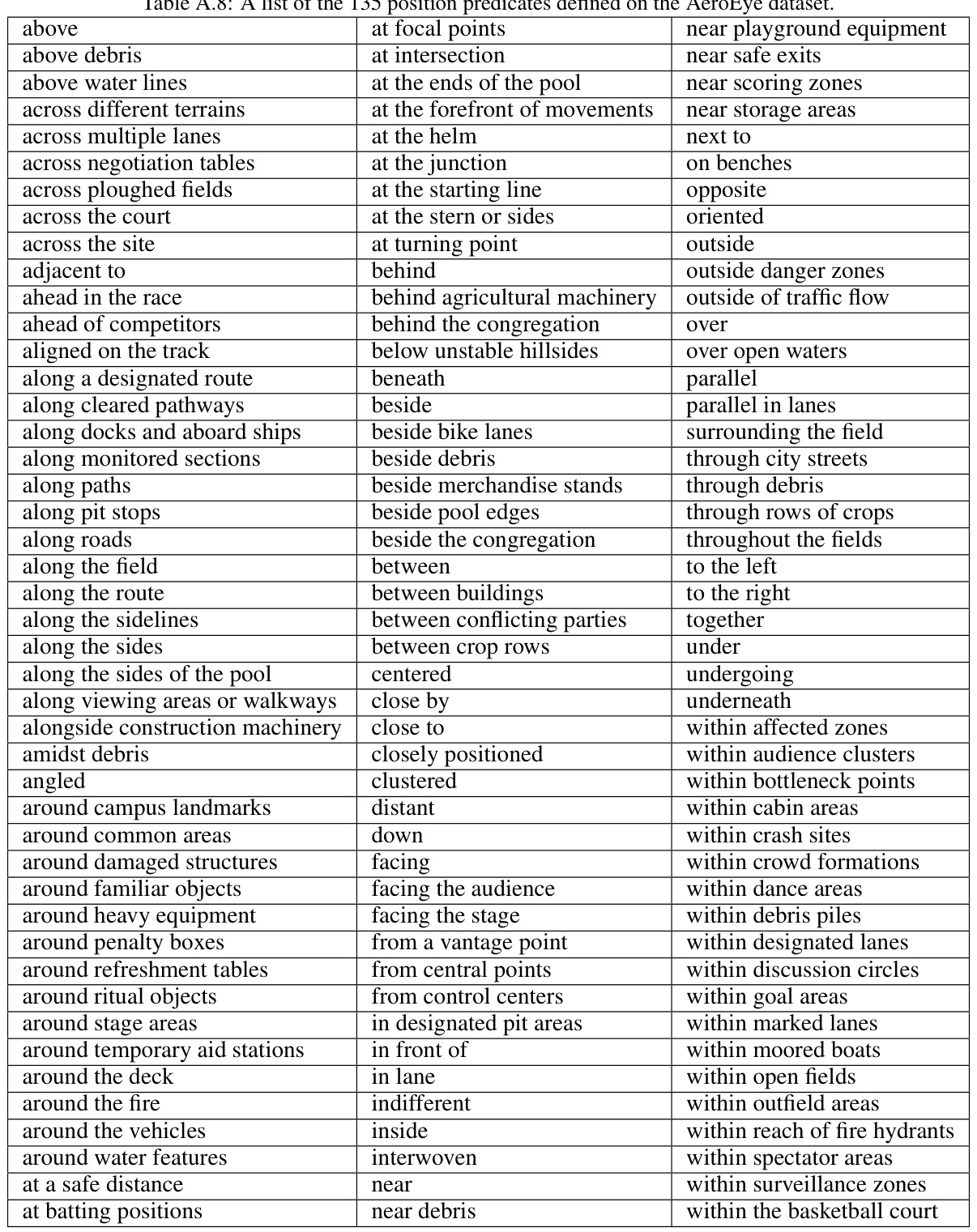
The AeroEye dataset, as described in the research paper, presents a novel contribution to the field of video scene graph generation (VidSGG). Its significance lies in its focus on aerial videos, capturing the complexities of multi-object interactions from a unique perspective. Unlike existing datasets that primarily cover ground-level perspectives, AeroEye offers a rich collection of drone-captured videos showcasing diverse scenes and intricate object relationships, especially pertinent to understanding outdoor dynamics. The dataset features various drone scenes with precisely annotated predicates, capturing both spatial arrangements and movements of objects. This detailed annotation allows for the development and evaluation of models capable of robust multi-object relationship modeling in the challenging aerial context, which is crucial for advancing applications such as surveillance, disaster response, and traffic management. The inclusion of a comprehensive set of predicates, beyond simple positional relations, makes AeroEye particularly valuable for research aiming to go beyond basic object detection and delve into understanding nuanced relationships between interacting objects.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper provides crucial insights into the performance of a proposed method or model. It should present a systematic comparison against existing state-of-the-art (SOTA) techniques, utilizing relevant metrics to quantify performance on established benchmark datasets. Quantitative results such as precision, recall, F1-score, accuracy, and AUC are essential, clearly presented in tables and/or figures. Statistical significance should be addressed to ensure results are not due to chance. The choice of benchmarks themselves is critical; they must be widely recognized and relevant to the problem addressed. A thorough analysis of the results goes beyond mere numbers, discussing trends, limitations, and potential explanations for observed performance variations, identifying scenarios where the proposed method excels or underperforms. Ultimately, the goal is to convincingly demonstrate the contribution’s superiority or specific advantages, strengthening the overall impact and credibility of the research.
Future Directions#
Future research could explore enhancing CYCLO’s capabilities by incorporating more sophisticated temporal modeling techniques to better capture long-range dependencies and complex interactions. Investigating alternative graph structures beyond the cyclic graph, such as hierarchical or recurrent networks, could improve performance on diverse video datasets. Furthermore, research into more robust object detection and tracking methods is crucial to handle challenging aerial scenarios with occlusions and varying object appearances. Improving the scalability of the CYCLO model for processing extremely long video sequences or high-resolution images is essential for real-world applications. Finally, exploring applications of CYCLO to other video domains beyond aerial surveillance, such as autonomous driving or sports analysis, could reveal new and valuable insights. A key future direction would be to evaluate the model’s performance and robustness on broader datasets featuring diverse environments and object interactions, especially those with a higher level of ambiguity or uncertainty.
More visual insights#
More on figures
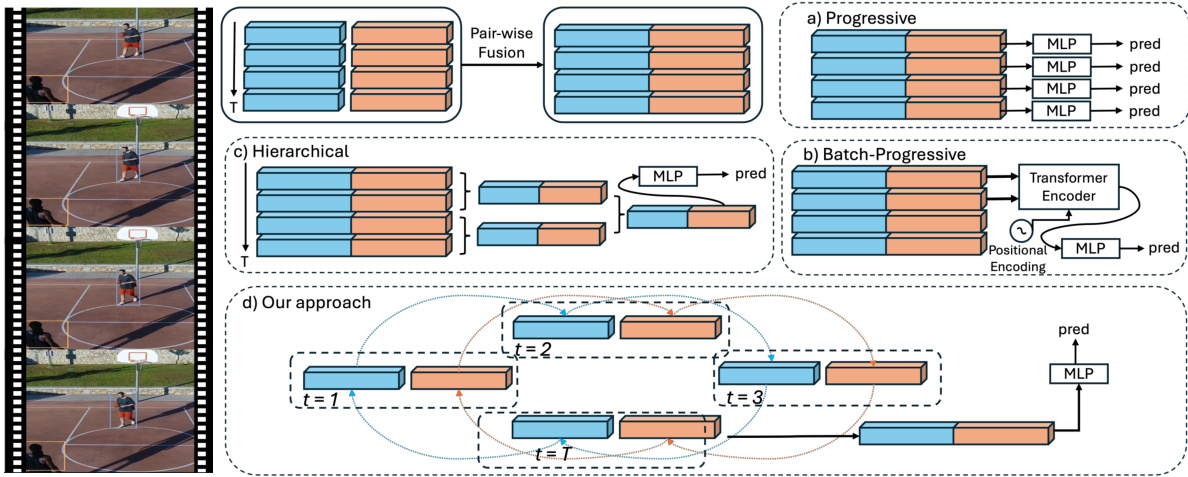
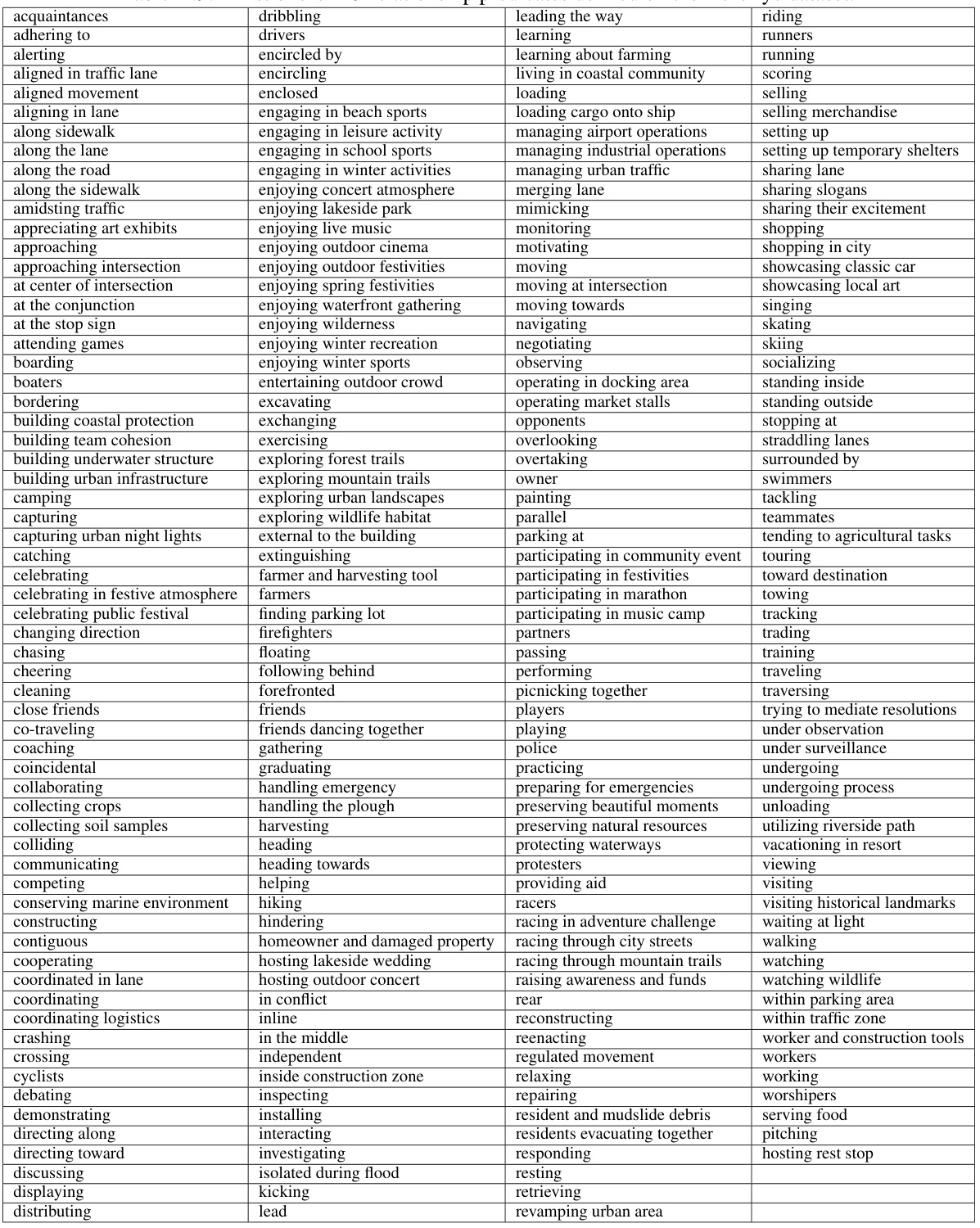
This figure compares four different approaches to relationship modeling in videos: Progressive, Batch-Progressive, Hierarchical, and CYCLO. The Progressive approach processes each frame independently, fusing pairwise features before classification. The Batch-Progressive approach uses a transformer to incorporate temporal information. The Hierarchical approach represents the video as a sequence of graphs with different levels of detail. CYCLO, the proposed method, establishes circular connectivity between frames to model temporal dependencies. The diagrams illustrate how each method processes video frames and combines spatial and temporal features to predict relationships.

This figure shows an example of the annotation process in the AeroEye dataset. Figure 3a displays a basketball scene from the ERA dataset. Figure 3b shows a graph representing the relationships between the objects in the scene. Straight arrows in the graph indicate relationships (e.g., ‘in front of,’ ‘behind,’ ’next to’), while curved arrows show the positions of the objects. Objects are represented by nodes of the same color, and the labels on the edges describe the relationship predicates.

The figure shows how the CYCLO model processes a drone video to detect and refine relationships between multiple objects over time. First, it identifies relationships within individual frames. Then, it incorporates temporal information about object positions and interactions to improve its understanding of relationships throughout the video sequence.
This figure compares four different approaches for modeling relationships in videos: Progressive, Batch-Progressive, Hierarchical, and CYCLO. The Progressive approach processes each frame independently, fusing pairwise features and classifying predicate types. The Batch-Progressive approach uses a transformer to incorporate temporal information. The Hierarchical approach represents the video as a sequence of graphs with different levels of granularity. CYCLO, the proposed method, uses circular connectivity among frames to capture both short-term and long-term dependencies, allowing for handling of cyclical patterns and periodic relationships. The illustration highlights the key differences in design and information flow.

This figure illustrates the cyclic attention mechanism in the CYCLO model’s Cyclic Temporal Graph Transformer. It shows how information from different frames is integrated in a cyclical manner to capture temporal dependencies. Each frame is represented by a block, and the arrows show how queries (Qt) from each frame interact with keys (Kt) from other frames, creating a cyclical flow of information across the entire video sequence. This cyclical process helps the model better capture the temporal dynamics and long-range dependencies in video data.

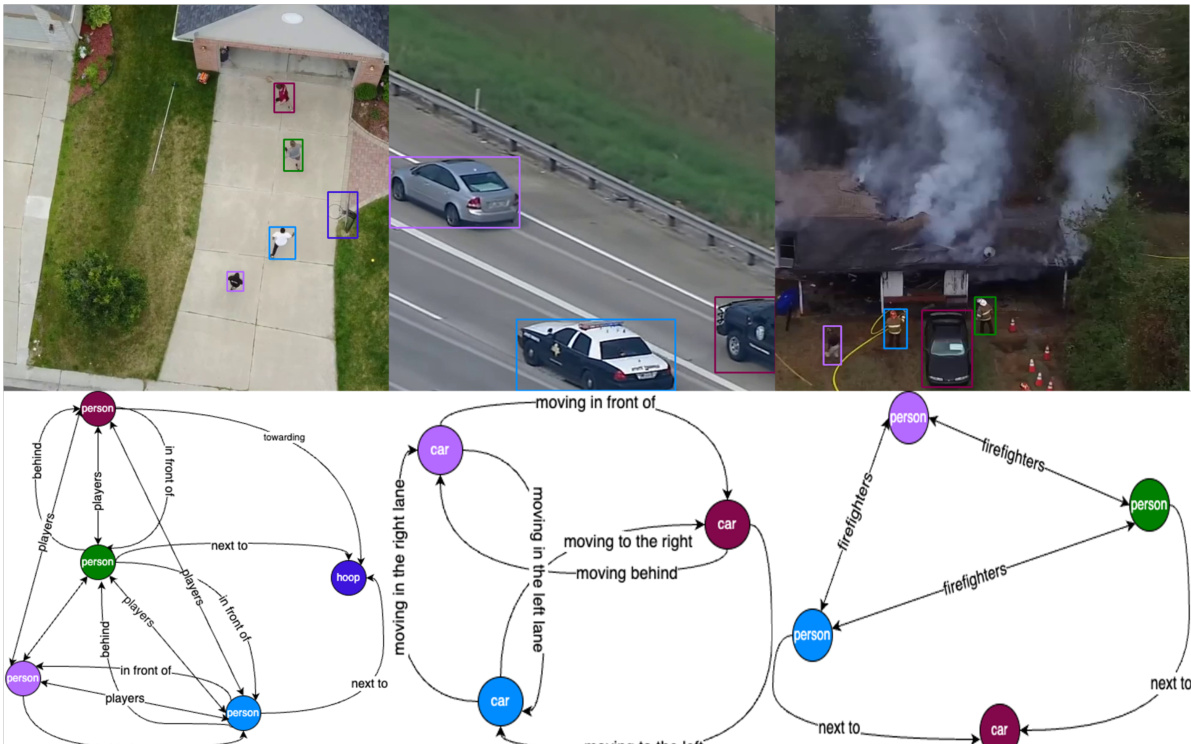
This figure shows the results of the CYCLO model on the AeroEye dataset. The top part displays a sequence of frames from a drone-captured video, showing a police interaction with a driver. Bounding boxes highlight detected objects. The bottom part shows the scene graphs generated by the CYCLO model. Each graph represents the relationships between objects (police officers, driver, car, and possibly bystanders) at a specific point in time. The edges and labels indicate the type of relationship (e.g., ‘investigating’, ‘approaching’). The graphs demonstrate how CYCLO tracks and refines these relationships over the course of the video sequence.
This figure compares four different approaches for relationship modeling in videos: Progressive, Batch-Progressive, Hierarchical, and the authors’ proposed CYCLO method. The Progressive approach processes frames individually. The Batch-Progressive approach uses a transformer to incorporate temporal information. The Hierarchical approach models the video as a sequence of graphs at different levels of granularity. The CYCLO approach uses cyclic connectivity to capture temporal dependencies, improving the handling of periodic and overlapping relationships.

This figure illustrates the overall approach of the CYCLO model for multi-object relationship modeling in aerial videos. It shows how the model processes a drone video sequence, first identifying relationships between objects within individual frames. Then, it incorporates temporal information (object movement and interactions) to improve the understanding and refinement of those relationships over the entire video.
This figure shows an example of the annotation process used in the AeroEye dataset. Figure 3a shows a basketball scene from the ERA dataset, while Figure 3b provides a visual representation of the scene graph with annotations. Straight arrows indicate the relationships between objects, curved arrows show the positions of the objects, and node colors represent the same object across the graph.
This figure shows how the CYCLO model processes a drone video to understand multi-object relationships. First, relationships between objects are identified in individual frames. Then, the model uses temporal information (object movement and interactions over time) to improve its understanding of these relationships across the entire video.
More on tables

This table presents the performance of the CYCLO model on the AeroEye dataset at different shift values (η). The performance is measured using Recall (R) and mean Recall (mR) at three different recall thresholds (R@20, R@50, R@100). The shift value (η) is a parameter in the cyclic attention mechanism of the CYCLO model, affecting how the model incorporates temporal information. The table shows how the model’s performance varies depending on the choice of η, for three different tasks: Predicate Classification (PredCls), Scene Graph Classification (SGCls), and Scene Graph Detection (SGDet).

This table shows the performance of the CYCLO model on the AeroEye dataset when varying the number of frames per video. It presents the Recall (R) and mean Recall (mR) at different recall thresholds (R@20, R@50, R@100) for three different tasks: Predicate Classification (PredCls), Scene Graph Classification (SGCls), and Scene Graph Detection (SGDet). Each row represents a different number of frames discarded from the videos. The results demonstrate the model’s robustness and how well it performs with varying amounts of temporal information.

This table presents a comparison of the performance of the proposed CYCLO method against three baseline methods (Vanilla, Transformer, and HIG) on the AeroEye dataset. The performance is measured using Recall (R) at three different thresholds (R@20, R@50, and R@100) across three different tasks (PredCls, SGCls, and SGDet). The mean and standard deviation are reported for each method and task, providing a statistical measure of performance and its variability.

This table presents the performance of the CYCLO model on the AeroEye dataset when varying the number of frames per video. The performance is measured using Recall (R) and mean Recall (mR) at different recall thresholds (R@20, R@50, R@100). Three different tasks are evaluated: PredCls (predicate classification), SGCls (scene graph classification), and SGDet (scene graph detection). The table shows how the model’s performance changes as more frames are removed or discarded from the videos.

This table presents a comparison of the performance of the proposed CYCLO model against several baseline methods on the ASPIRE dataset. The metrics used for comparison are Recall (R) and mean Recall (mR) at different thresholds (R@20, R@50, R@100). The baseline methods include Vanilla, Handcrafted, 1D Convolution, Transformer, and HIG. The results show that CYCLO consistently outperforms the baseline methods across all metrics.
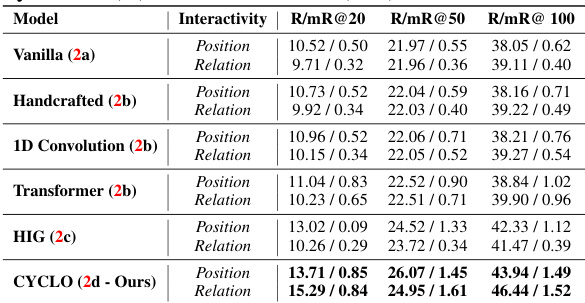
This table compares the performance of the proposed CYCLO model against several baseline methods on the ASPIRE dataset. The performance is measured using Recall (R) and mean Recall (mR) at different thresholds (R@20, R@50, R@100). The results are broken down by the type of interactivity (Position and Relation). It shows the relative improvement of CYCLO over existing approaches in recognizing and modelling object relationships in videos.
This table compares various datasets used for scene graph generation, highlighting key features like the number of videos, frames, objects, relationships, and scenes. It also indicates the type of viewpoints (ego, 3rd-person, aerial, oblique, ground) present in each dataset, indicating the suitability of each for aerial video scene graph generation. The best values for drone-captured datasets are highlighted.
This table compares various datasets used for scene graph generation, highlighting key differences in their characteristics. It categorizes datasets into image-based and video-based, further distinguishing drone-captured datasets by viewpoint (aerial, oblique, ground). The table provides a comprehensive overview of dataset properties, including the number of videos/frames, resolution, object and relation classes, number of scenes, and annotations available, facilitating a better understanding of the strengths and weaknesses of each dataset for video scene graph generation tasks. The best values among drone video datasets are highlighted for easy identification.
This table compares various datasets used for scene graph generation, highlighting key features such as the number of videos, frames, objects, relationships, and scenes. It also notes the resolution of the images/videos and importantly indicates the viewpoints (ego, aerial, oblique, ground) available in each dataset. The table is particularly useful to understand the advantages and unique characteristics of the AeroEye dataset in comparison to existing datasets, showing that AeroEye offers a richer and more diverse collection of data for aerial scene graph generation.
Full paper#