↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The Segment Anything Model (SAM) is a powerful tool in computer vision, but its large size and computational demands limit its use on devices with limited resources. Existing compression methods require extensive data, resulting in a trade-off between model size and performance. This creates a significant hurdle for deploying SAM on resource-constrained devices, such as mobile phones or embedded systems.
This paper introduces SlimSAM, a novel approach to compressing SAM. SlimSAM uses a data-efficient technique called alternate slimming which involves iteratively pruning and distilling different parts of the model. It also introduces disturbed Taylor pruning to address inconsistencies between the model’s pruning and distillation targets. The results show that SlimSAM achieves performance close to the original SAM while using only 0.1% of the training data, reducing model size and computational costs significantly. This opens the door for using SAM in a wider range of applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel data-efficient method for compressing the Segment Anything Model (SAM), a significant advancement in computer vision. It addresses the challenge of applying SAM to resource-constrained devices by drastically reducing the model size and computational needs while maintaining high performance, opening new avenues for research and practical applications of SAM across various platforms.
Visual Insights#

This figure illustrates the alternate slimming framework used in SlimSAM. It shows the original heavyweight image encoder of SAM being progressively compressed in two stages. First, embedding pruning removes redundant parameters from the embedding dimensions, followed by bottleneck aligning which minimizes divergence from the original model using a loss function that considers the bottleneck dimensions. Next, bottleneck pruning reduces parameters in the bottleneck dimensions, and embedding aligning refines the model using a loss function focused on the embedding dimensions. The final result is a lightweight image encoder.
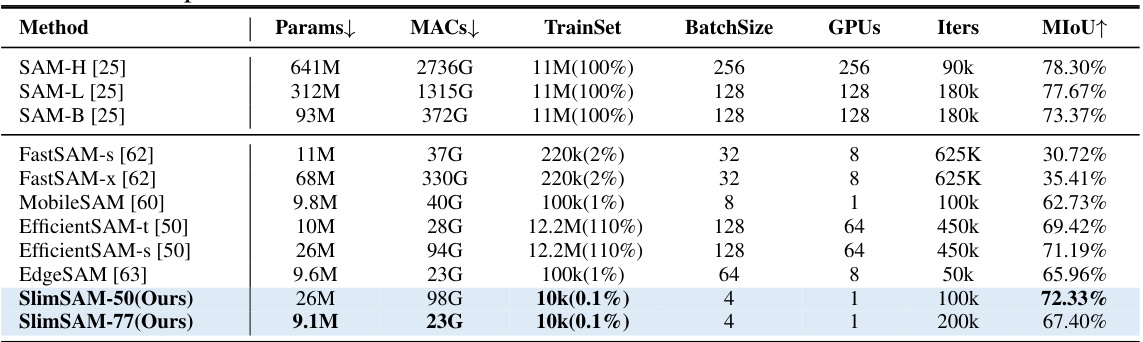
This table compares SlimSAM with other state-of-the-art (SOTA) SAM compression methods. It presents a comparison across multiple metrics: the number of parameters (Params), the number of Multiply-Accumulate operations (MACs), the size of the training dataset used (TrainSet), batch size, number of GPUs used for training, the number of training iterations, and the mean Intersection over Union (MIoU) which is a metric for evaluating segmentation accuracy. The table highlights SlimSAM’s efficiency by showing its superior performance with significantly fewer parameters, MACs, and training data.
In-depth insights#
SlimSAM: Data-Efficient SAM#
SlimSAM presents a novel data-efficient approach for compressing the Segment Anything Model (SAM). The core innovation lies in its alternate slimming framework, which progressively compresses SAM by alternately pruning and distilling distinct sub-structures. This approach, unlike traditional methods, effectively enhances knowledge inheritance under limited data. Disturbed Taylor pruning is introduced to address the misalignment between pruning and training objectives, further boosting performance. SlimSAM achieves significant performance gains while demanding only 0.1% of the original SAM training data, resulting in a drastically smaller model with minimal performance loss. This data efficiency makes SlimSAM particularly valuable for resource-constrained applications where deploying the full SAM is impractical. The method’s effectiveness highlights the potential of combining advanced pruning techniques with knowledge distillation for efficient model compression.
Alternate Slimming#
The proposed alternate slimming framework offers a novel approach to data-efficient model compression. Instead of a conventional single-step pruning and fine-tuning, it iteratively alternates between pruning and knowledge distillation on distinct, decoupled sub-structures of the model (embedding and bottleneck dimensions). This strategy is particularly beneficial when dealing with limited data and aggressive pruning ratios, mitigating the performance degradation often associated with such scenarios. By decoupling the pruning process and focusing on distinct structural components, the alternate approach minimizes divergence from the original model, ensuring the model effectively inherits prior knowledge. The framework promotes smoother compression, allowing for a more gradual reduction in model parameters without significant performance drops. This approach provides a more robust and effective means of compressing models with limited data, unlike traditional methods which typically suffer from severe performance degradation under the same circumstances.
Disturbed Taylor Pruning#
The proposed “Disturbed Taylor Pruning” method tackles limitations of standard Taylor pruning in the context of limited data and complex model architectures like SAM. Standard Taylor pruning relies on accurate hard labels for precise importance estimation, which are unavailable during the crucial post-distillation phase. Furthermore, it suffers from misalignment between the pruning objective (minimizing hard label discrepancy) and the distillation target (minimizing soft label loss). Disturbed Taylor pruning cleverly circumvents these issues by using soft labels and introducing a label-free importance estimation. It leverages the loss function between the original and a disturbed (noise-added) image embedding, generating non-zero gradients, even with soft labels, for estimating the importance of parameters to be pruned. This ingenious approach seamlessly aligns the pruning objective with the subsequent distillation target, drastically improving the efficacy of the compression process, especially when dealing with exceptionally high pruning ratios and scarce training data. The technique’s effectiveness is highlighted by its ability to improve MIoU scores significantly, even exceeding the performance of standard Taylor pruning under severe data constraints.
Ablation Study#
An ablation study systematically removes components or features of a model to assess their individual contributions. In this context, it would likely involve systematically removing or altering elements of the proposed SlimSAM model to isolate the impact of different aspects (e.g. alternate slimming, disturbed Taylor pruning). Key insights would emerge from comparisons between the full model and its ablated versions, highlighting the relative importance of each component and identifying potential areas for improvement or simplification. Results would likely show that the alternate slimming framework and the disturbed Taylor pruning method make substantial individual contributions, validating the design choices in the architecture. The ablation study should not only show the effects of removing features but also provide valuable insights into the model’s overall design. Analyzing the interplay of different components is crucial for determining the robustness of the design and possible synergistic effects. Furthermore, the ablation study will validate the efficacy of the proposed methodology in comparison to existing methods, showcasing SlimSAM’s unique advantages in data-efficient settings.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending SlimSAM to other vision models beyond SAM would demonstrate its broader applicability and robustness. Investigating alternative pruning strategies and exploring the interplay between different pruning techniques and knowledge distillation methods could further improve efficiency. Developing more sophisticated techniques for aligning the pruning objective with the distillation target is crucial for effective knowledge preservation and performance enhancement. A thorough investigation into the impact of various data augmentation techniques on SlimSAM’s performance warrants exploration, especially for scenarios with severely limited training data. Finally, adapting SlimSAM for deployment on resource-constrained edge devices would be a significant practical advancement, requiring careful optimization for minimal latency and memory footprint.
More visual insights#
More on figures
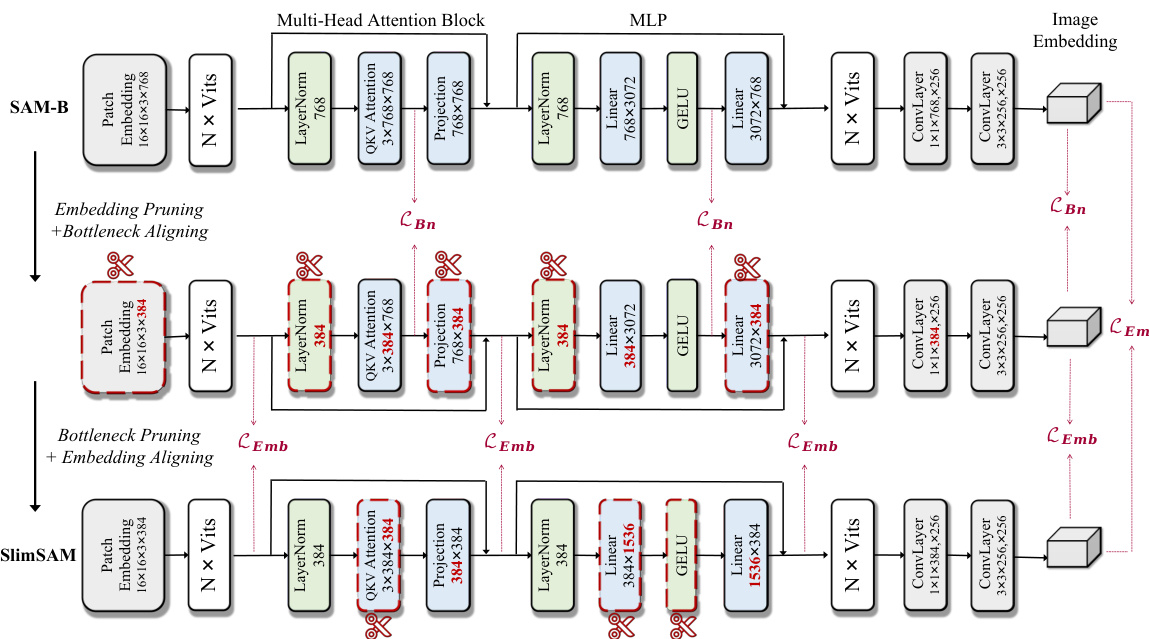
This figure illustrates the proposed alternate slimming framework for compressing the SAM-B model. It shows a step-by-step process of alternately pruning and distilling distinct, decoupled sub-structures (embedding and bottleneck dimensions) within the image encoder. The pruning is done at the channel-wise group level, and knowledge distillation from intermediate layers helps restore performance after pruning. Red numbers indicate the pruned dimensions at each step.

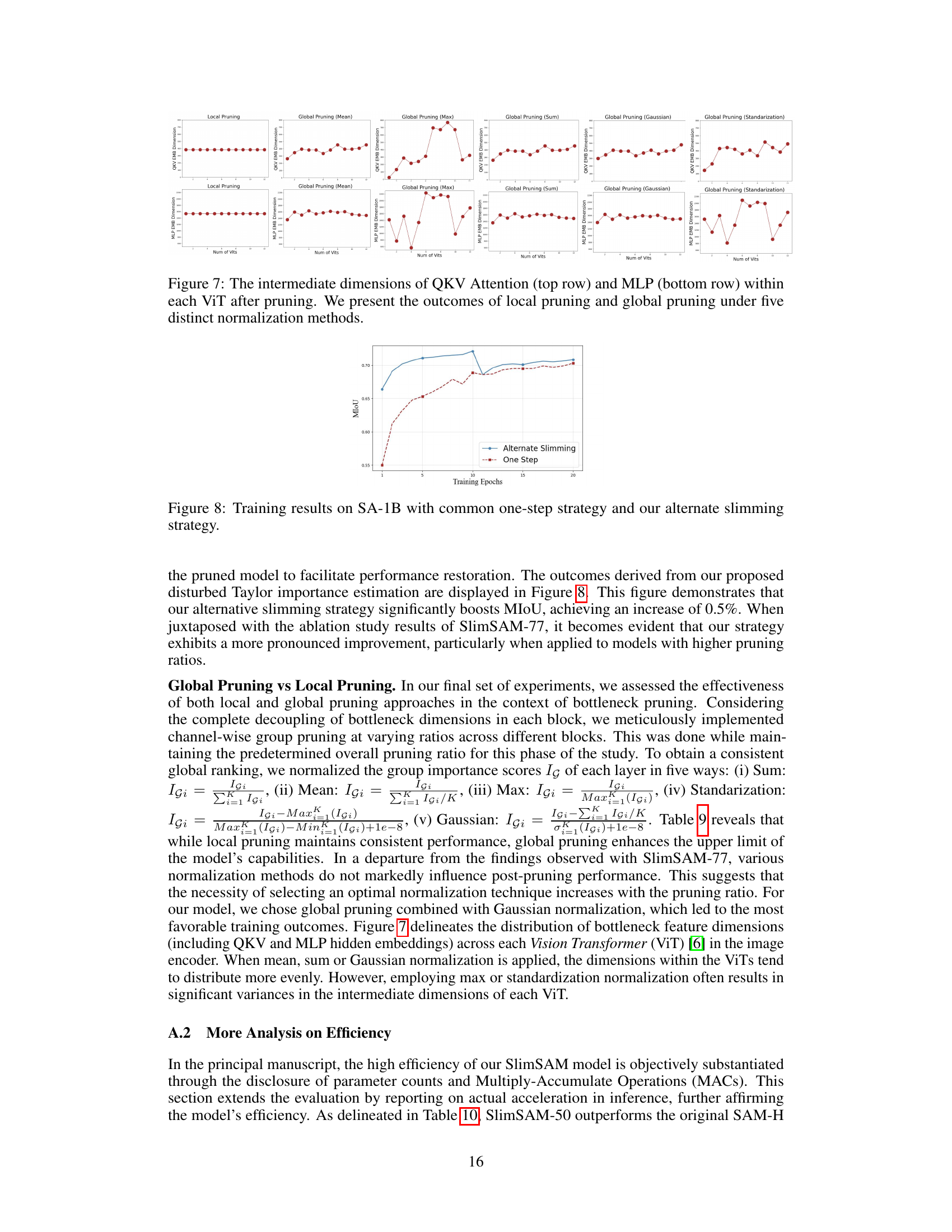
This figure compares the training performance (measured by mean IoU) of the proposed alternate slimming framework against the conventional one-step method. Two sub-figures are shown, one for each importance estimation method used: disturbed Taylor importance and random importance. The x-axis represents the number of training epochs, and the y-axis represents the mean IoU. The alternate slimming framework consistently shows better performance than the one-step approach, demonstrating the effectiveness of the proposed method in enhancing knowledge retention and achieving superior performance under limited data.

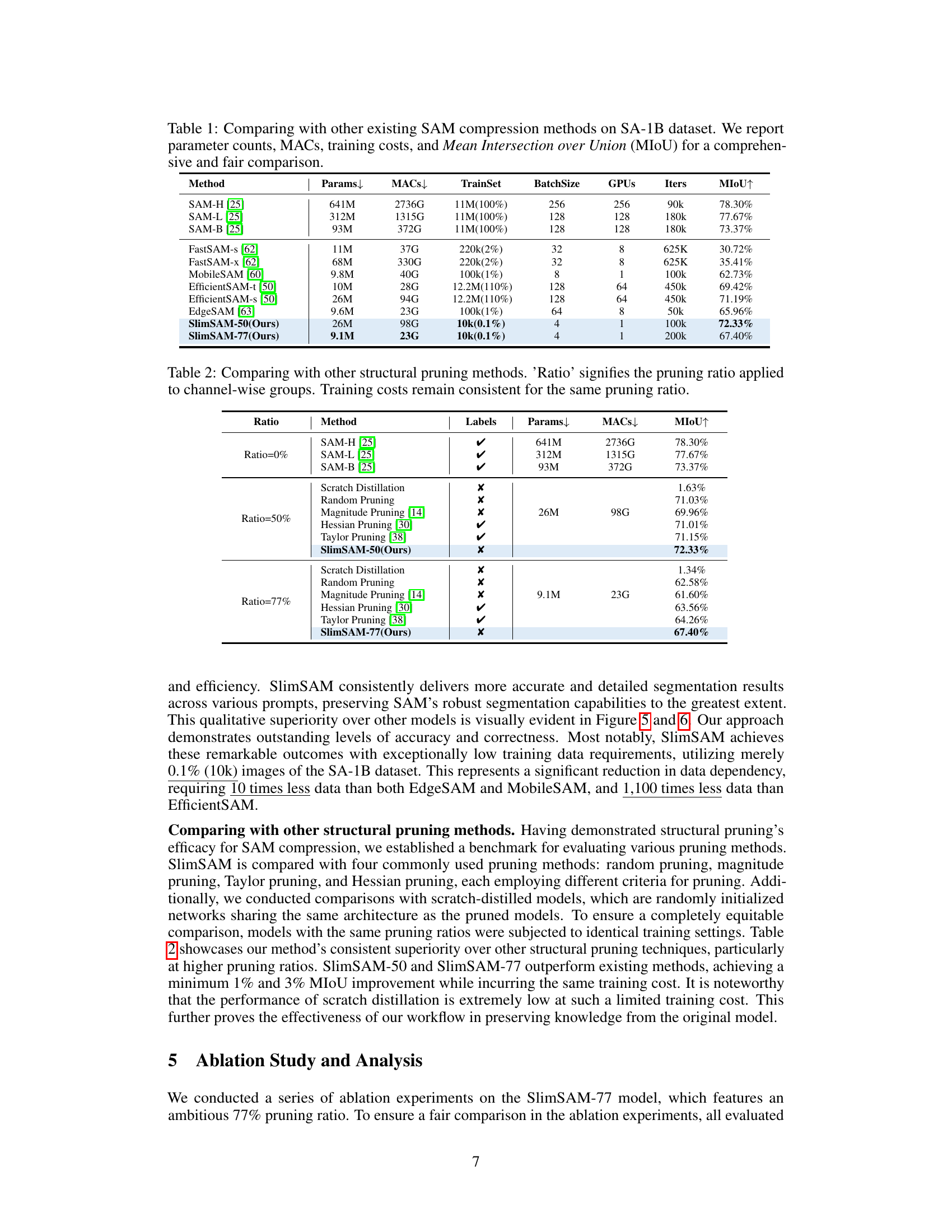
This figure shows the intermediate dimensions of QKV Attention and MLP within each ViT of the image encoder after applying different pruning methods (local and global). Five different normalization methods (mean, max, sum, Gaussian, and standardization) were used for global pruning, and their effects on the resulting dimensions are displayed for comparison.

This figure compares the segmentation results of different methods on various images using ‘segment everything’ prompts. It shows the original SAM-H results alongside results from SlimSAM-50, SlimSAM-77, EdgeSAM, EfficientSAM, MobileSAM, and FastSAM. The comparison highlights the differences in segmentation accuracy and detail between the different methods. SlimSAM models show promising results compared to the other methods and the original SAM-H model.

This figure compares the segmentation results obtained from several different models (SAM-H, SlimSAM-50, SlimSAM-77, EdgeSAM, EfficientSAM, MobileSAM, and FastSAM) when using point prompts. The goal is to show a qualitative comparison of the models’ performance on a variety of images and scenarios.
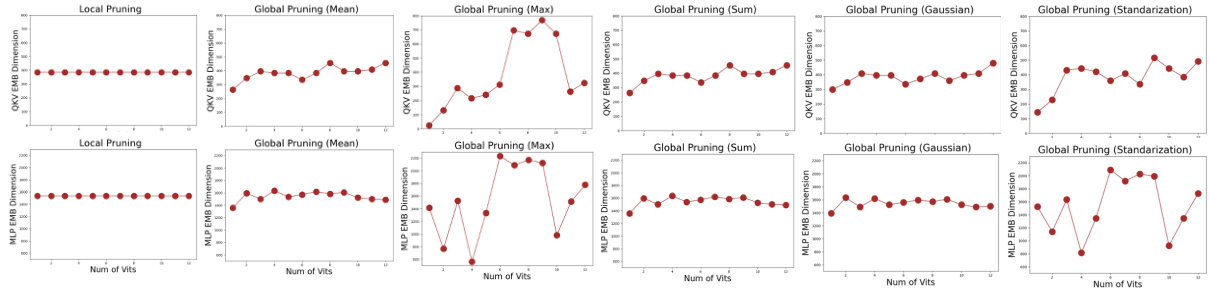
This figure visualizes the intermediate dimensions (QKV Attention and MLP) of each Vision Transformer (ViT) block within the image encoder after applying different pruning strategies. It compares local pruning with global pruning performed using five different normalization techniques (mean, max, sum, Gaussian, and standardization) to illustrate how the choice of pruning method and normalization impacts the resulting dimension distribution across the ViT blocks.
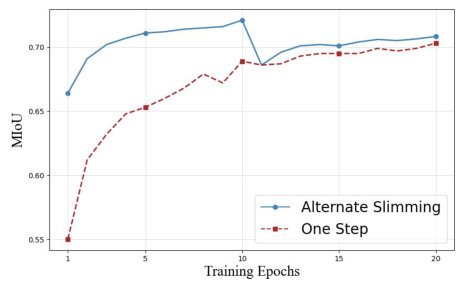
This figure compares the training performance (measured by MIoU) of the proposed alternate slimming method against a standard one-step pruning and distillation approach. The alternate slimming method shows significantly better performance in terms of MIoU across training epochs, highlighting its effectiveness in improving knowledge retention and model performance during the compression process.

This figure compares the segmentation results of different models on various images using the ‘segment everything’ prompt. The models compared include SAM-H (the original, heavy model), SlimSAM-50 (SlimSAM with 50% pruning ratio), SlimSAM-77 (SlimSAM with 77% pruning ratio), EdgeSAM, EfficientSAM, MobileSAM, and FastSAM. The images show that SlimSAM achieves comparable performance to the original SAM-H while requiring significantly less data and computation.

This figure compares the segmentation results of different methods, including SlimSAM, using box prompts. The results show the segmentation masks generated by each method for a set of images, allowing for a visual comparison of their performance. Red boxes indicate the box prompts used for the segmentation.

This figure compares the segmentation results of different models (SAM-H, SlimSAM-50, SlimSAM-77, EdgeSAM, EfficientSAM, MobileSAM, and FastSAM) on various images using point prompts. It visually demonstrates the performance of SlimSAM compared to other state-of-the-art models on different image types and scenarios.
More on tables

This table compares SlimSAM’s performance against other state-of-the-art (SOTA) SAM compression methods. It shows the parameter counts, multiply-accumulate operations (MACs), training data used, and the mean Intersection over Union (mIoU) scores achieved. The comparison highlights SlimSAM’s superior performance and efficiency, particularly given its significantly reduced training data requirement.

This table compares the performance (MIoU) of different pruning methods. It shows that the proposed ‘Disturbed Taylor Pruning’ outperforms the original ‘Taylor Pruning’ method, especially when combined with the SlimSAM-77 framework. The results highlight the effectiveness of aligning the pruning objective with the distillation target.

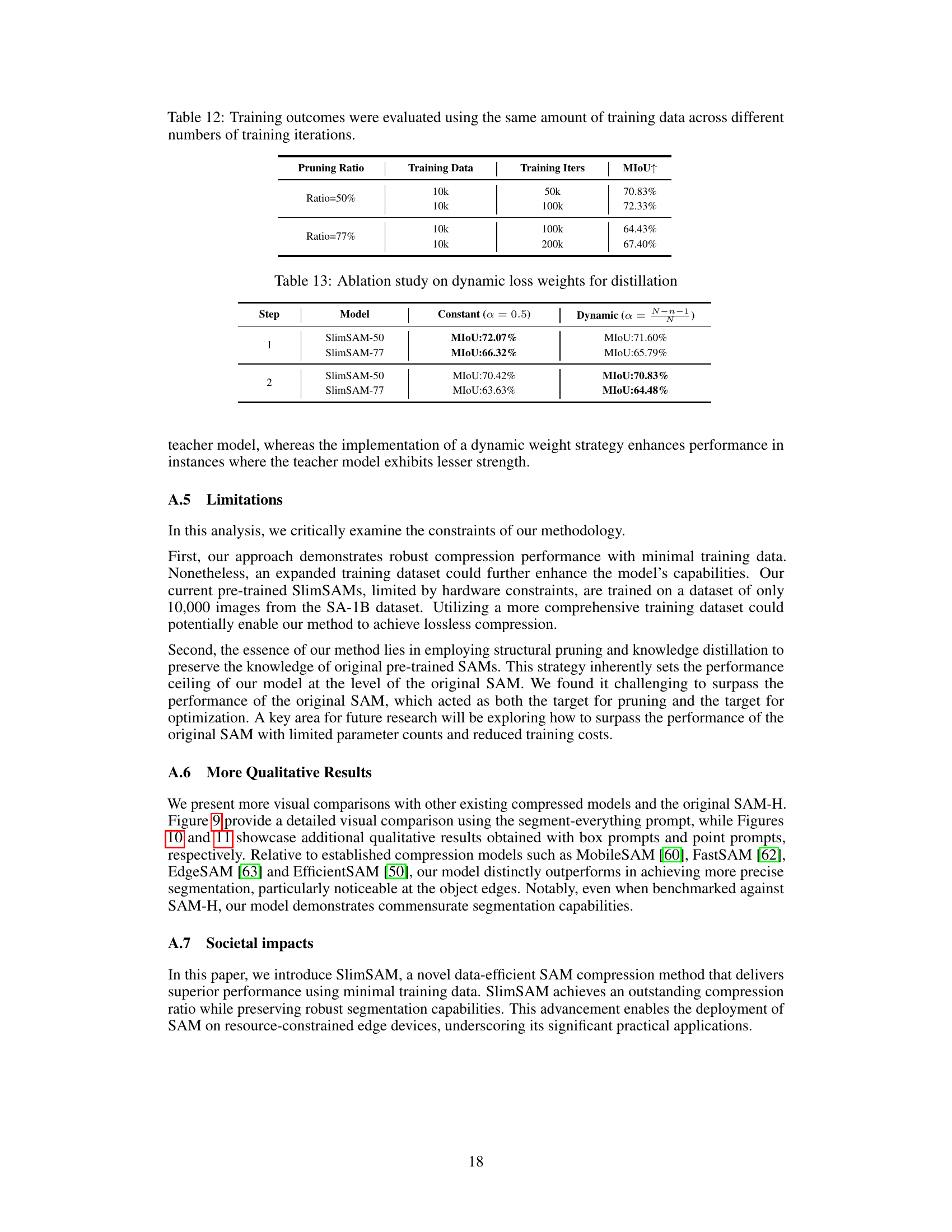
This table shows the mean Intersection over Union (mIoU) achieved by using different distillation objectives in different steps of the SlimSAM model’s alternate slimming process. It demonstrates the effectiveness of including bottleneck and embedding features along with final image embeddings in the distillation process for improving the mIoU. The comparison shows an improvement using this approach vs using only final image embeddings in both Step 1 and Step 2.
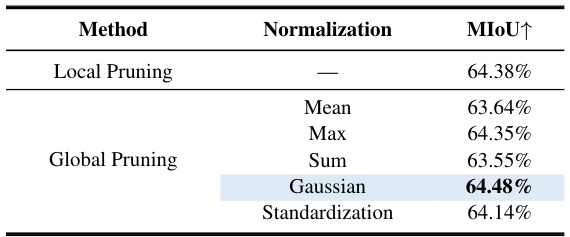
This table presents the results of an ablation study comparing different normalization methods used for global pruning. The MIoU (mean Intersection over Union) metric is used to evaluate the performance of different normalization techniques (Mean, Max, Sum, Gaussian, Standardization) applied to global pruning. The table helps understand which normalization method yields the best performance in the context of global pruning for the SlimSAM model.
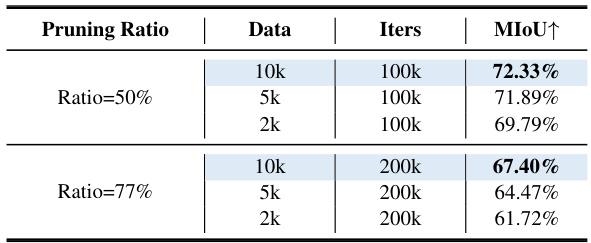
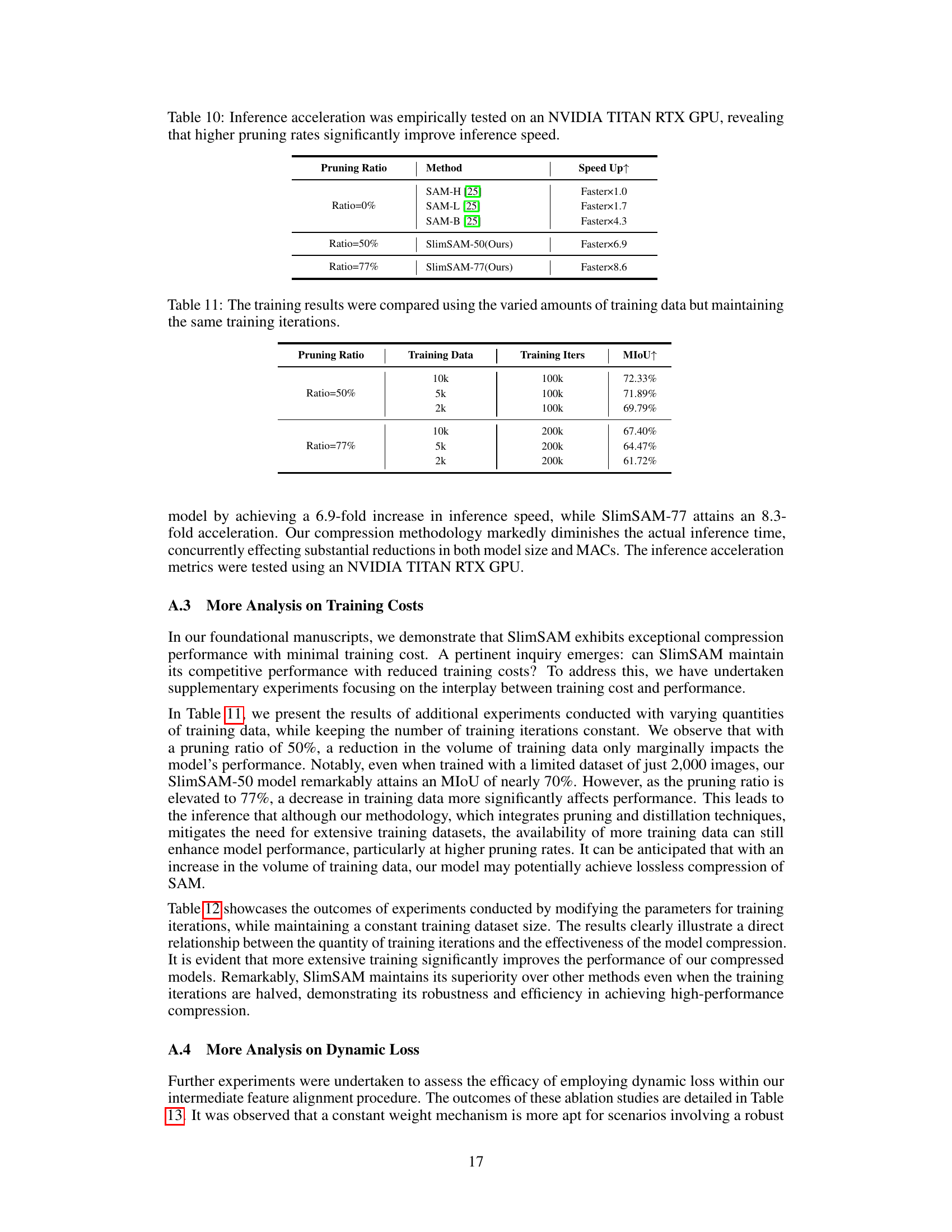
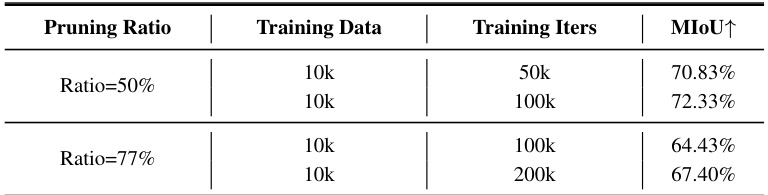
This table shows the results of experiments conducted with varying amounts of training data while keeping the number of training iterations constant. It demonstrates how model performance (measured by MIoU) changes as the amount of training data decreases for different pruning ratios (50% and 77%). This analysis helps determine the impact of data scarcity on the SlimSAM model’s performance.
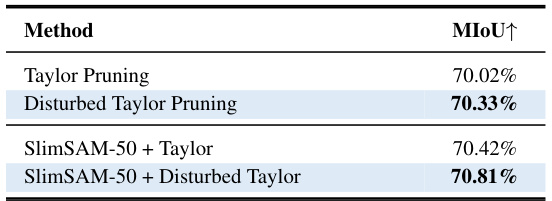
This table presents the mean Intersection over Union (MIoU) scores achieved by using Taylor pruning and disturbed Taylor pruning. It also shows the MIoU scores when these pruning methods are combined with the SlimSAM-50 method. The results demonstrate that the disturbed Taylor pruning consistently outperforms the original Taylor pruning, achieving higher MIoU scores at equivalent training expenditures.

This table presents the results of an ablation study evaluating the impact of using intermediate layers in the distillation process. The experiment compares using only final image embeddings for distillation against including bottleneck features (Step 1) and embedding features (Step 2). The MIoU (mean Intersection over Union) metric demonstrates the effectiveness of including these additional features in the distillation process, showing an improvement in performance.
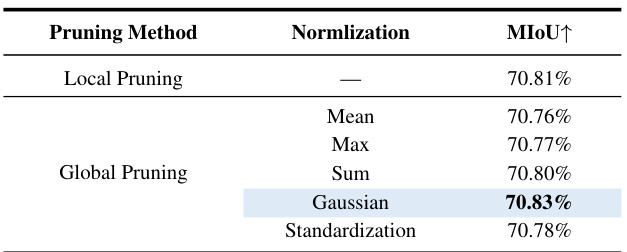
This table presents the results of an ablation study comparing different normalization methods used in global pruning. It shows the mean Intersection over Union (mIoU) achieved for each normalization technique (Mean, Max, Sum, Gaussian, Standardization) when applying global pruning to the SlimSAM model. The mIoU metric measures the model’s accuracy in semantic segmentation.

This table compares SlimSAM with other state-of-the-art (SOTA) SAM compression methods. It shows the number of parameters, Multiply-Accumulate operations (MACs), the size of the training dataset used, and the mean Intersection over Union (mIoU) achieved. The mIoU metric reflects the accuracy of semantic segmentation. The table highlights SlimSAM’s superior performance and efficiency by achieving comparable or better mIoU with significantly fewer parameters, MACs, and training data.

This table compares the model’s performance (measured by MIoU) under different amounts of training data while keeping the number of training iterations constant. It shows how the model’s performance changes with varying amounts of training data (10k, 5k, and 2k images) at two different pruning ratios (50% and 77%). This helps in understanding the impact of data availability on the model’s performance under different compression levels.
This table compares SlimSAM’s performance against other state-of-the-art (SOTA) SAM compression methods. It shows the number of parameters, Multiply-Accumulate operations (MACs), training data used, and the mean Intersection over Union (mIoU) score achieved by each method. This allows for a direct comparison of SlimSAM’s efficiency and performance relative to existing techniques.

This table presents the results of an ablation study that compares the performance of using a constant weight (α = 0.5) versus a dynamic weight (α = (N − n − 1)/N) for the distillation process in SlimSAM. The study evaluates the mIoU achieved for both SlimSAM-50 and SlimSAM-77 models at steps 1 and 2 of the distillation process, highlighting the impact of using a dynamic weighting strategy on performance.
Full paper#