↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training large neural networks often employs learning rate warmup, which gradually increases the learning rate from a low initial value, but its benefits are not fully understood. This paper investigates why large initial updates can destabilize training, focusing on small-scale GPT training. The authors analyze different metrics for update size, including the l2-norm, directional change, and impact on network representations. They found large initial updates to be problematic.
This research explores how modifications to optimizers (like AdamW and Lion) can reduce the need for warmup. Specifically, modifications to explicitly normalize updates based on these metrics significantly reduced or eliminated the need for warmup. The findings suggest that the benefits of warmup are tied to controlling initial update size, primarily by mitigating large angular updates and high initial gradient signal-to-noise ratio. High momentum also contributes to efficient training, suggesting that careful design of optimizers might be able to remove the need for learning rate warmup altogether.
Key Takeaways#
Why does it matter?#
This paper is important because it offers new insights into the learning rate warmup technique, a common practice in neural network training. By identifying the reasons behind the effectiveness of warmup and proposing solutions to reduce or eliminate the need for it, the research contributes to more efficient and stable training of large language models. It also opens up new avenues for investigation into the dynamics of neural network training, and the relationship between gradient noise, learning rate, and representation changes.
Visual Insights#

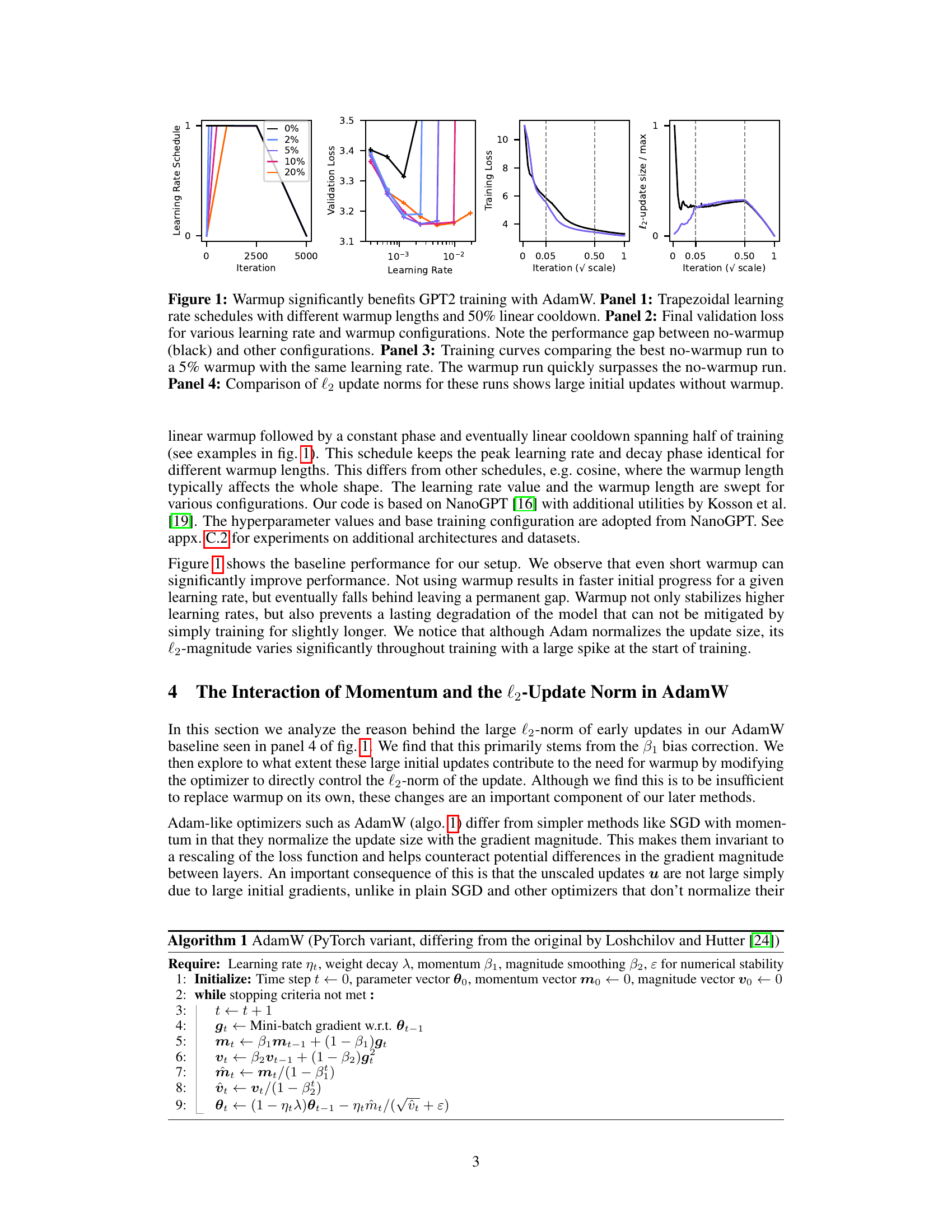
This figure shows the impact of learning rate warmup on GPT2 training using the AdamW optimizer. It demonstrates that even a short warmup period significantly improves training performance, especially when using higher learning rates. The figure displays training curves, validation loss values, and the magnitude of the updates to illustrate how warmup addresses large initial updates that negatively impact training stability and speed.

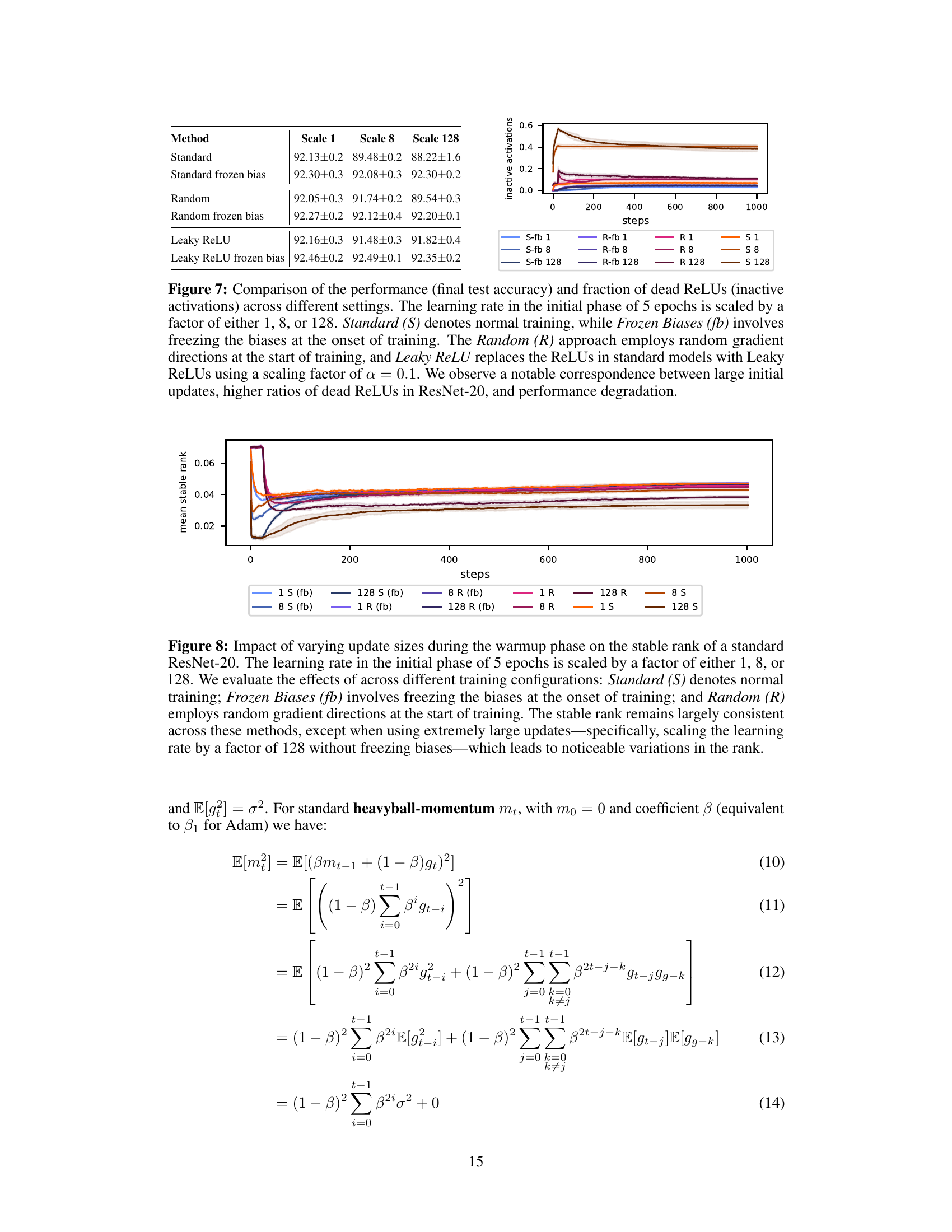
This table presents the results of an experiment comparing different training methods on a ResNet-20 model with varying initial update sizes. The methods include standard training, training with frozen biases, training with random gradients, and training with leaky ReLU activations. Each method is tested with three scaling factors for the initial learning rate (1, 8, and 128). The table shows the final test accuracy and the fraction of dead ReLUs for each method and scaling factor. The results highlight the negative impact of large initial updates on performance and the mitigating effect of leaky ReLUs.
In-depth insights#
Warmup’s Mysteries#
The concept of “warmup” in neural network training, particularly for large language models, presents several intriguing mysteries. While empirically beneficial, its effectiveness remains poorly understood. The paper delves into why initial updates are often too large, leading to instability, and explores different metrics to quantify this, such as the l2-norm and angular update size. A key finding is that large angular updates and high gradient correlation early in training contribute significantly to the need for warmup. The authors propose optimizer modifications, such as normalizing updates based on these metrics, which substantially reduces the need for explicit warmup in smaller-scale GPT training. However, it is shown that simply controlling the l2-norm or angular update size isn’t sufficient; a new metric focused on changes to the internal network representation is introduced, indicating that the effective update size is more complex than previously thought. The interplay of momentum and bias correction within optimizers like AdamW further complicates the dynamics of warmup, highlighting the nuanced and often non-intuitive behavior of this critical training technique. Ultimately, the paper argues that effective warmup strategies should aim to control the rate of change in network representations.
AdamW Momentum Bias#
AdamW, an adaptive learning rate optimizer, incorporates momentum to accelerate convergence. However, AdamW’s momentum mechanism introduces a bias, particularly noticeable in early training stages. This bias manifests as artificially large initial updates, potentially disrupting the optimization trajectory and necessitating learning rate warmup. The bias correction term in AdamW, while intended to mitigate this issue, proves insufficient in certain scenarios, especially when early gradients are highly correlated. Analyzing the interaction between momentum and gradient magnitude is crucial for understanding this effect. Modifying the optimizer to directly control update norms, either via normalization techniques or by scaling matrices, offers a potential pathway toward reducing or eliminating the need for warmup while addressing AdamW’s momentum bias. This addresses the core problem of large updates early in training by decoupling learning rate scheduling from the intrinsic dynamics of momentum.
Angular Update Control#
The concept of ‘Angular Update Control’ in the context of neural network optimization is a novel approach focusing on the directional aspect of weight updates, rather than just their magnitude. Instead of solely considering the L2-norm of updates, this method emphasizes the change in the angle of weight vectors. This is particularly relevant for adaptive optimizers that inherently normalize the update size, potentially masking underlying issues. By regulating angular updates, the approach aims to mitigate issues arising from highly correlated gradients early in training, promoting smoother transitions in feature learning and enhancing training stability. This control can be achieved through specific optimizer modifications, for example, by incorporating mechanisms that directly limit the angular change of weight vectors. This refined control offers a promising alternative to traditional learning rate warmup strategies, providing a new perspective and potentially leading to more efficient and stable training. The effectiveness of angular update control highlights the importance of considering directional changes in weight space, offering a more nuanced approach to optimizing neural network training.
SNR & RRC Analysis#
The analysis of Signal-to-Noise Ratio (SNR) and Relative Representation Change (RRC) offers a novel perspective on learning rate warmup. High initial SNR correlates with large early changes in network representations, potentially destabilizing training. The RRC, measuring the relative change in network outputs due to weight updates, provides a more direct measure of this instability than the commonly used L2 update norm. Modifying optimizers to control either SNR or RRC can reduce the need for warmup, demonstrating that the problem stems from the magnitude of representation changes, not just the magnitude of weight updates. This research highlights a critical need for better methods to quantify and control the impact of updates on the network’s internal representations during the initial stages of training.
Future of Warmup#
The “Future of Warmup” in neural network training hinges on a deeper understanding of its mechanisms. While empirical success is evident, the lack of theoretical clarity surrounding its benefits necessitates further investigation. Future research should focus on refining metrics beyond simple l2-norm and angular updates to capture the impact on internal representations. Developing adaptive methods that dynamically adjust warmup based on gradient characteristics and network dynamics is crucial. Exploring relationships between warmup, optimizer choice, and network architectures will unlock more efficient training strategies. The interplay between momentum and warmup merits further attention, given its impact on the effective update size and the angular displacement of weight vectors. Ultimately, a predictive framework for warmup’s effectiveness, potentially based on gradient signal-to-noise ratios or curvature measures, is needed. This will lead to optimal warmup schemes tailored to specific training contexts, eventually minimizing or eliminating the need for this heuristic entirely. The goal is not simply to understand warmup better, but to transition from a heuristic to a principled, theoretically grounded training technique.
More visual insights#
More on figures
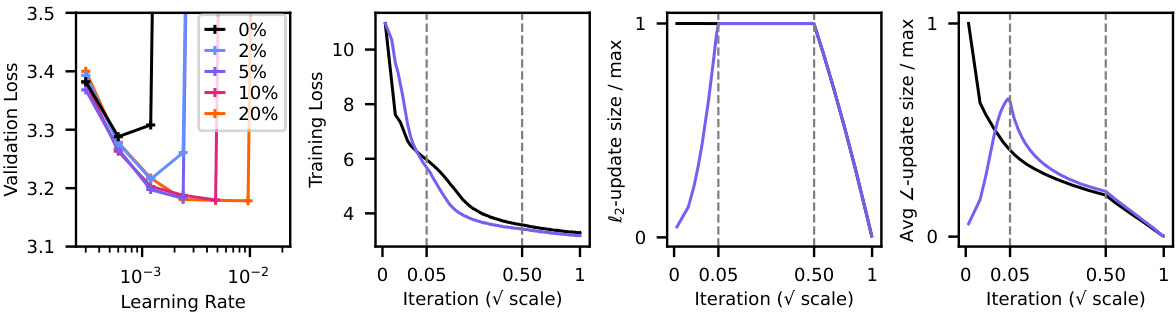
This figure demonstrates the significant impact of learning rate warmup on GPT-2 training using the AdamW optimizer. Panel 1 shows different trapezoidal learning rate schedules with varying warmup periods. Panel 2 compares the final validation loss achieved with different warmup lengths and learning rates, highlighting the substantial performance improvement with warmup. Panel 3 provides a direct comparison of training curves with and without warmup, showing the superior performance of the warmup approach. Finally, Panel 4 illustrates the difference in the l2-norm of the updates, revealing much larger initial updates in the absence of warmup.

This figure shows the effects of learning rate warmup on GPT-2 training using the AdamW optimizer. It demonstrates that even short warmup periods significantly improve performance, particularly at higher learning rates, compared to training without warmup. The figure highlights that the lack of warmup leads to substantially larger initial updates (as measured by the l2-norm of the updates).
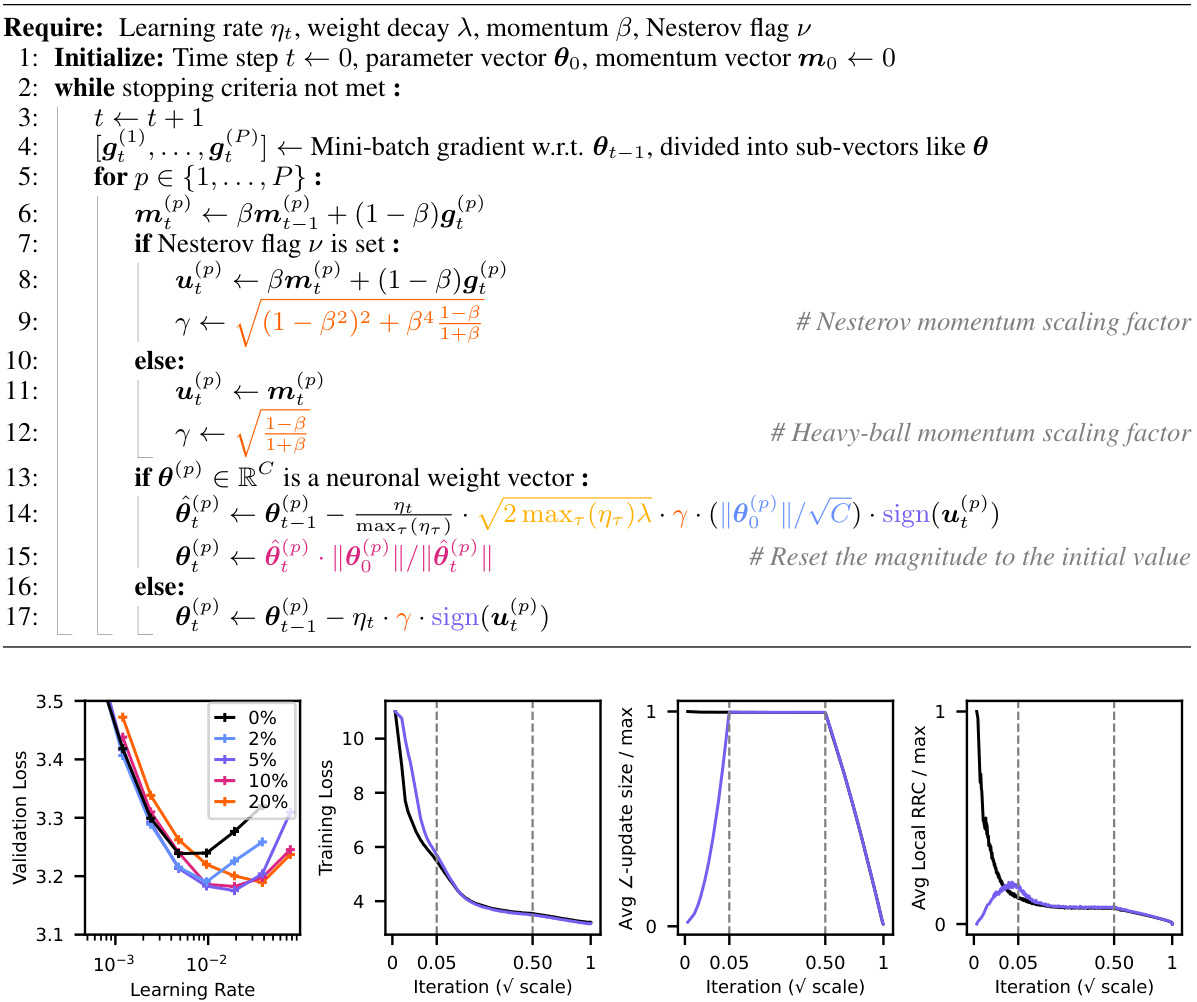
This figure demonstrates the significant benefits of learning rate warmup in GPT2 training using the AdamW optimizer. Panel 1 displays various trapezoidal learning rate schedules with different warmup lengths. Panel 2 shows the final validation loss for different learning rate and warmup configurations, highlighting a significant performance gap between runs with and without warmup. Panel 3 compares the training curves of the best no-warmup run and a run with a 5% warmup, showing the substantial improvement achieved by the warmup. Finally, Panel 4 illustrates the difference in the l2 norm of the updates between the runs with and without warmup, demonstrating that large initial updates occur without warmup.

This figure shows the relationship between learning rate, signal-to-noise ratio (SNR), gradient alignment with momentum, and the need for learning rate warmup. Panel 1 demonstrates that to keep the relative representation change constant, the learning rate should be reduced as the SNR increases, especially for large batch sizes. The other panels visualize the SNR, gradient-momentum alignment, and momentum’s effect on gradient magnitude over the training process for two runs from Figure 3 (with and without warmup). The results support the idea that a high initial SNR necessitates a lower initial learning rate to control changes in network representations, explaining the benefits of warmup.
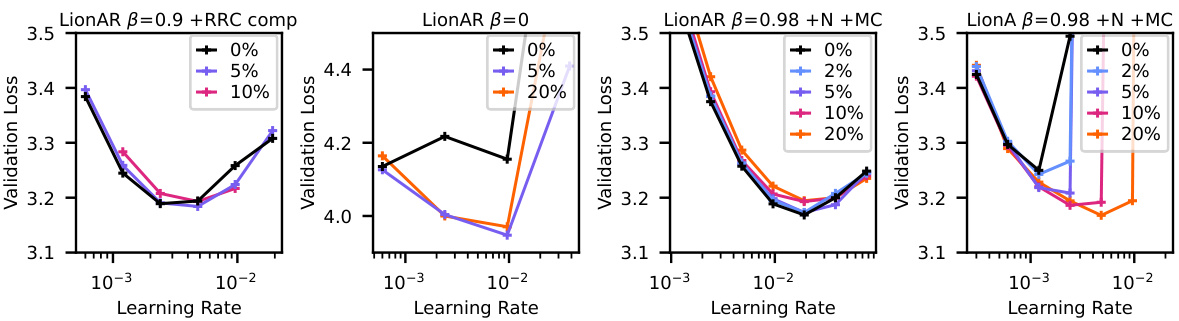
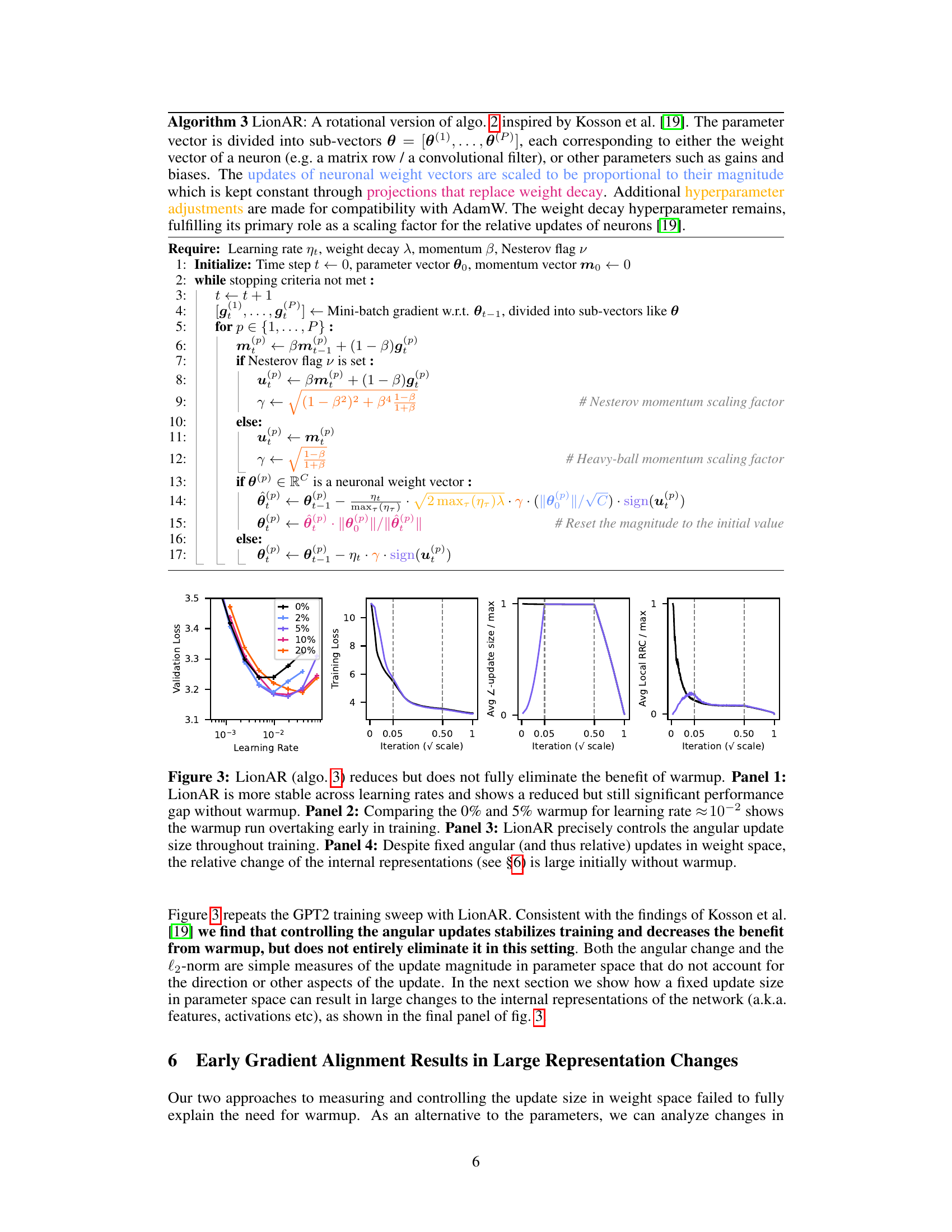
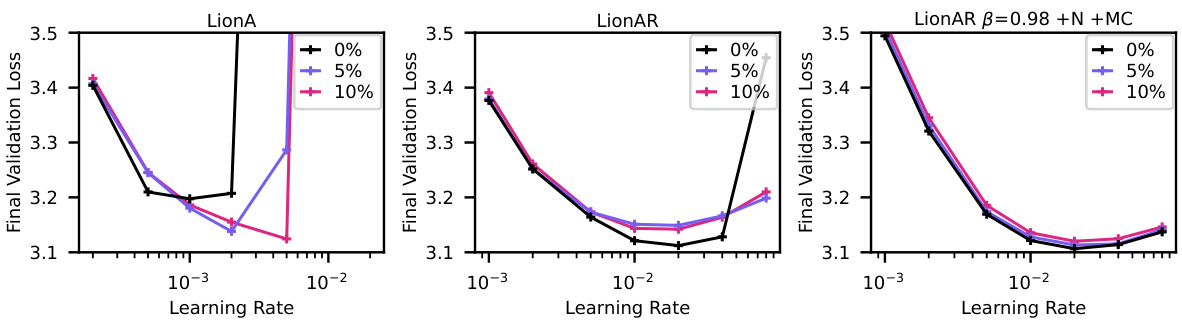
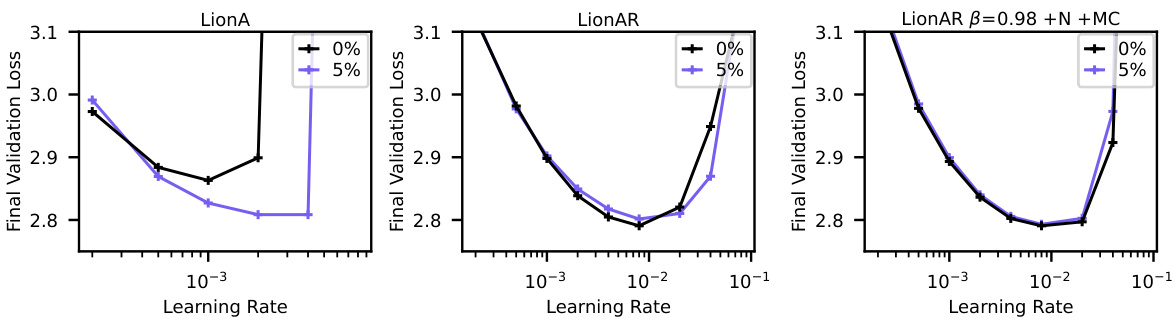
This figure shows the results of experiments to evaluate the effect of different modifications to the Lion optimizer, in an attempt to reduce or eliminate the need for warmup in GPT2 training. Panel 1 shows that even with a correction factor for the relative representation change (RRC), LionAR still benefits from warmup. Panel 2 demonstrates the crucial role of momentum; without it, performance significantly degrades. Panel 3 reveals that with high momentum (β=0.98), Nesterov momentum, and an inverse bias correction, LionAR achieves the best performance without warmup. Finally, Panel 4 highlights that these modifications are not sufficient for LionA, emphasizing that control over angular updates is necessary to fully eliminate the need for warmup.

This figure shows the impact of large initial updates on the performance of a ResNet-20 model trained on CIFAR-10. Two training methods are compared: standard ReLU activation and Leaky ReLU activation. Initial update sizes are scaled by factors of 1, 8, and 128 for both methods. The results indicate that even with extended training (800 epochs), the performance gap caused by large initial updates persists. However, using Leaky ReLU activation reduces the performance degradation, suggesting that network non-linearities play a significant role in the impact of large initial updates.
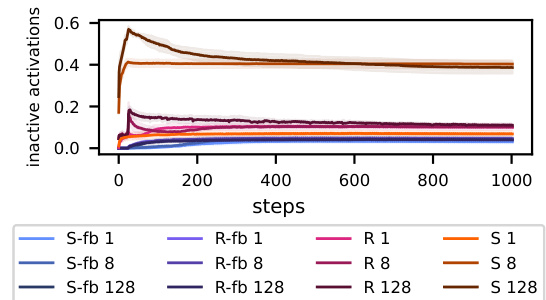
This figure compares the performance and the fraction of dead ReLUs in a ResNet-20 model under different training settings. The learning rate at the beginning of training (5 epochs) was scaled by factors of 1, 8, and 128. Three training methods were compared: standard training (S), training with frozen biases (fb), and training with random gradients (R). A leaky ReLU activation function was also compared. The results show that larger initial updates correlate with higher ratios of dead ReLUs and worse performance.

This figure shows the impact of different update sizes during the initial warmup phase on the stable rank of a ResNet-20 model. The stable rank, a measure of the effective dimensionality of the weight matrices, is plotted against training steps. Several training conditions are compared: standard training with ReLU activation (S), standard training with frozen biases (fb), and training with random initial gradient directions (R). Update sizes are scaled by factors of 1, 8, and 128. The results indicate that extremely large updates (scaling by 128 without frozen biases) lead to significant changes in the stable rank, while other conditions show relatively stable rank values.

This figure demonstrates the significant benefits of learning rate warmup in GPT2 training using the AdamW optimizer. It presents four panels: Panel 1 shows different trapezoidal learning rate schedules with varying warmup lengths, all incorporating a 50% linear cooldown phase. Panel 2 displays the final validation loss for various learning rate and warmup configurations, highlighting the performance advantage of using warmup. Panel 3 compares training curves with and without warmup, illustrating the rapid improvement achieved with warmup. Panel 4 shows a direct comparison of the l2 norms of the weight updates (Δω), emphasizing that significantly larger updates occur without warmup.

This figure demonstrates the significant impact of learning rate warmup on GPT-2 training using the AdamW optimizer. It shows that even short warmup periods drastically improve performance compared to training without warmup, reducing final validation loss. The figure compares various warmup lengths using trapezoidal learning rate schedules with a 50% linear cooldown. It visually highlights the substantial performance difference between training with and without warmup by examining validation loss, training curves, and the l2 norm of updates, illustrating that the large initial updates in the no-warmup case are responsible for the performance gap.
This figure shows the impact of learning rate warmup on GPT-2 training using the AdamW optimizer. It presents four panels: (1) illustrates different trapezoidal learning rate schedules with varying warmup lengths; (2) compares the final validation loss across various learning rate and warmup configurations, highlighting the significant performance improvement with warmup; (3) plots training curves, demonstrating that the model with warmup outperforms the one without warmup; (4) shows a comparison of the L2 norms of the updates across the runs, indicating that large initial updates occur without warmup.
This figure demonstrates the significant impact of learning rate warmup on GPT2 training using the AdamW optimizer. It compares the performance across different warmup lengths, showcasing the improved performance and stability with warmup compared to no-warmup. The plots show validation loss and the L2 norm of updates which clearly indicates large initial updates without warmup.
Full paper#