↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current tool-augmented large language models (LLMs) primarily utilize successful reasoning paths for training, neglecting valuable information from failures. This limitation hinders optimal model performance and generalization. The existing methods also exhibit limitations in efficiency and exploration of the tool-usage space.
This paper introduces TP-LLaMA, a novel framework that addresses these shortcomings. It leverages a step-wise preference learning approach, utilizing both successful and failed paths from decision trees to train the LLM. This approach not only enhances data utilization but also broadens the learning space, resulting in a model that significantly outperforms baselines across various scenarios. TP-LLaMA showcases improved generalization to unseen APIs and demonstrates superior reasoning efficiency, making it more suitable for complex tool-usage tasks. The key contribution is the introduction of a new preference dataset, ToolPreference, and the application of direct preference optimization (DPO) to improve LLM’s tool usage ability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on tool-augmented LLMs. It introduces a novel preference learning framework that significantly improves model performance and efficiency by leveraging insights from previously ignored failed attempts in reasoning trajectories. This opens new avenues for utilizing expert data more effectively and developing more robust and generalized tool-augmented LLMs.
Visual Insights#

This figure illustrates the workflow of the proposed inference trajectory optimization framework. It starts with user queries interacting with a real-world environment via RapidAPI Hub APIs. A depth-first search-based decision tree explores multiple reasoning paths, some leading to success (green checkmark) and others to failure (red X). Successful trajectories are collected and used for supervised fine-tuning (SFT) of a pre-trained LLM. The framework then introduces a novel method for generating preference data from both successful and failed steps of the decision tree, resulting in a ToolPreference dataset. This dataset is used with direct preference optimization (DPO) to further refine the LLM, leading to the final ToolPrefer-LLaMA (TP-LLaMA) model.
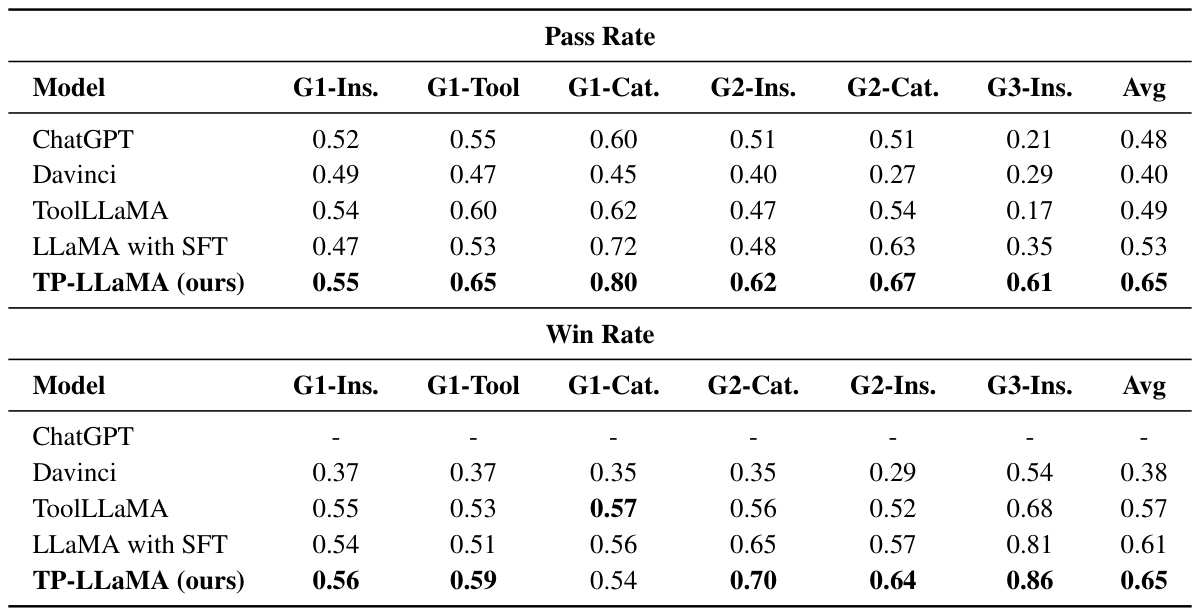
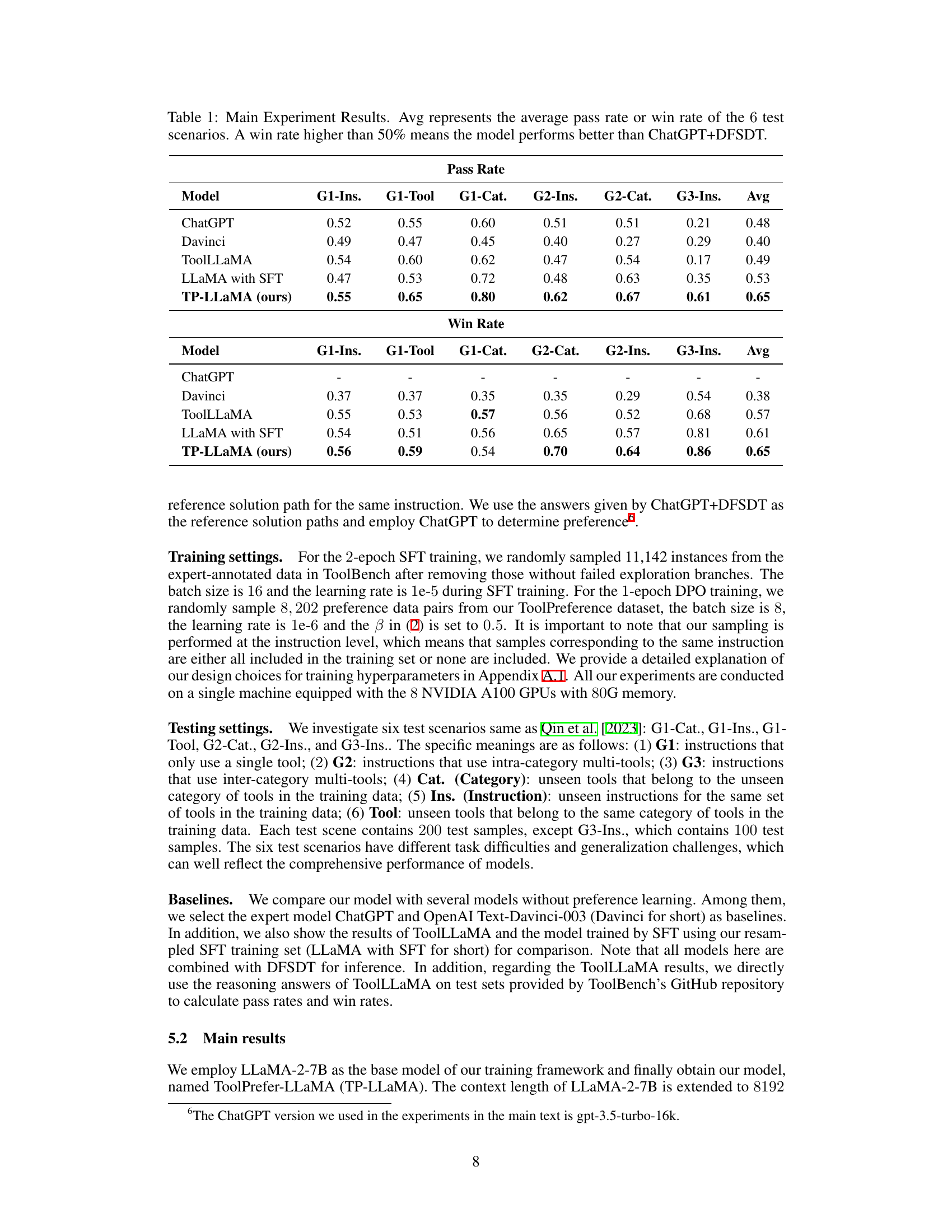
This table presents the main experimental results comparing the performance of TP-LLaMA against several baseline models (ChatGPT, Davinci, ToolLLaMA, and LLaMA with SFT) across six different test scenarios. The scenarios vary in the complexity of the tasks, involving single tools, intra-category multi-tools, and inter-category multi-tools. Performance is measured using two metrics: pass rate (the probability of the model successfully providing an answer within a limited number of steps) and win rate (the likelihood that an evaluator would prefer the model’s response over a reference solution). The ‘Avg’ column shows the average performance across all six scenarios, providing a summary of the overall performance of each model.
In-depth insights#
Tool-LLM Augmentation#
Tool-LLM augmentation represents a significant advancement in large language model (LLM) capabilities, aiming to bridge the gap between LLMs and the real world. By integrating external tools, often in the form of APIs, LLMs can perform complex tasks that require real-time information or interactions beyond their inherent knowledge. This augmentation transforms LLMs from passive text processors into active agents capable of interacting with their environment. The depth-first search-based decision tree mechanism, as seen in ToolLLaMA, is a key enabler, facilitating multi-step reasoning through a systematic exploration of tool usage paths. However, a crucial limitation of prior approaches lies in their reliance solely on successful paths, neglecting the valuable learning opportunities embedded in failed attempts. The proposed inference trajectory optimization framework addresses this by incorporating insights from these errors, enhancing data utilization and model generalization. Utilizing preference learning, the framework leverages a novel method to generate a step-wise preference dataset, which is then employed to optimize the LLM’s policy via direct preference optimization. This leads to superior performance compared to baselines, demonstrating improved efficiency and enhanced reasoning capabilities, particularly for complex, unseen tasks.
Inference Tree Analysis#
Inference tree analysis offers a powerful lens for understanding the decision-making processes within complex systems, especially in the context of tool-augmented large language models (LLMs). By examining the paths taken during inference, both successful and failed, valuable insights into model strengths and weaknesses can be gleaned. Analyzing successful paths reveals effective reasoning strategies and highlights areas where the model excels. Conversely, studying failed paths can pinpoint critical areas for improvement, such as inadequate tool selection or flawed reasoning steps. The ability to use this analysis to create a feedback mechanism for model refinement is key. Direct Preference Optimization (DPO), for example, shows potential to effectively leverage information from both successful and unsuccessful trajectories. Furthermore, the process reveals opportunities to optimize both the model’s policy and its efficiency by identifying unnecessary steps or redundant explorations. This approach moves beyond simple accuracy metrics, offering a deeper, more nuanced understanding of model behavior and paving the way for more robust and efficient LLMs.
Preference Learning#
Preference learning, a subfield of machine learning, offers a powerful paradigm for training models by leveraging human preferences rather than explicit numerical rewards. This is particularly valuable when reward signals are difficult or expensive to engineer, as often happens with complex tasks involving human judgment or subjective assessments. The core idea is to learn a model that aligns with human preferences, even if the underlying reward function remains unknown. Instead of directly optimizing for a reward, preference learning focuses on learning a ranking or ordering that reflects human choices between different options. Several approaches exist, such as pairwise comparisons, listwise ranking, or learning to rank. The choice of method depends on the nature of the preference data and computational constraints. A key advantage is the ability to incorporate human feedback in a more natural and intuitive way, which can lead to better generalization and robustness in real-world applications. While simpler than traditional reinforcement learning, preference learning can still capture complex behaviors by modeling the relative preferences between actions. Its application to tool-augmented LLMs enhances their reasoning by learning directly from human judgments of the efficacy of different tool usage sequences.
TP-LLaMA Efficiency#
TP-LLaMA’s efficiency improvements stem from its novel inference trajectory optimization framework. Unlike prior methods solely relying on successful trajectories, TP-LLaMA leverages both successful and failed paths from decision trees, generating a step-wise preference dataset. This broadened learning space, combined with direct preference optimization (DPO), allows TP-LLaMA to avoid unnecessary exploration of suboptimal branches in the decision tree. Experiments demonstrate a significant reduction in the average number of steps required for reasoning, showcasing superior efficiency compared to baselines, including ToolLLaMA and models trained using only successful trajectories. This enhanced efficiency, achieved through the effective utilization of data from inference tree errors, makes TP-LLaMA better suited for complex tool-usage reasoning tasks, enabling faster and more resource-efficient problem-solving.
Future Work#
The paper’s conclusion regarding future work highlights several promising avenues for advancement. Extending the research to encompass multimodal scenarios is a key focus, aiming to leverage the combined power of different modalities for enhanced tool-augmented reasoning. This would involve exploring more complex scenarios and tasks where multiple sensory inputs are involved, leading to a more robust and human-like interaction with tools. The researchers also plan to incorporate more sophisticated preference learning techniques, moving beyond current methods to refine the model’s ability to choose the best actions in response to feedback. This might involve investigating alternative algorithms or approaches to preference learning, or exploring ways to more effectively incorporate human feedback into the training process. Finally, they recognize the need for more complex reasoning mechanisms, particularly in addressing more intricate or nuanced challenges in the field. This could involve incorporating advanced planning algorithms, improving the representation and interpretation of knowledge, or exploring novel ways to integrate external tools with the LLM.
More visual insights#
More on figures
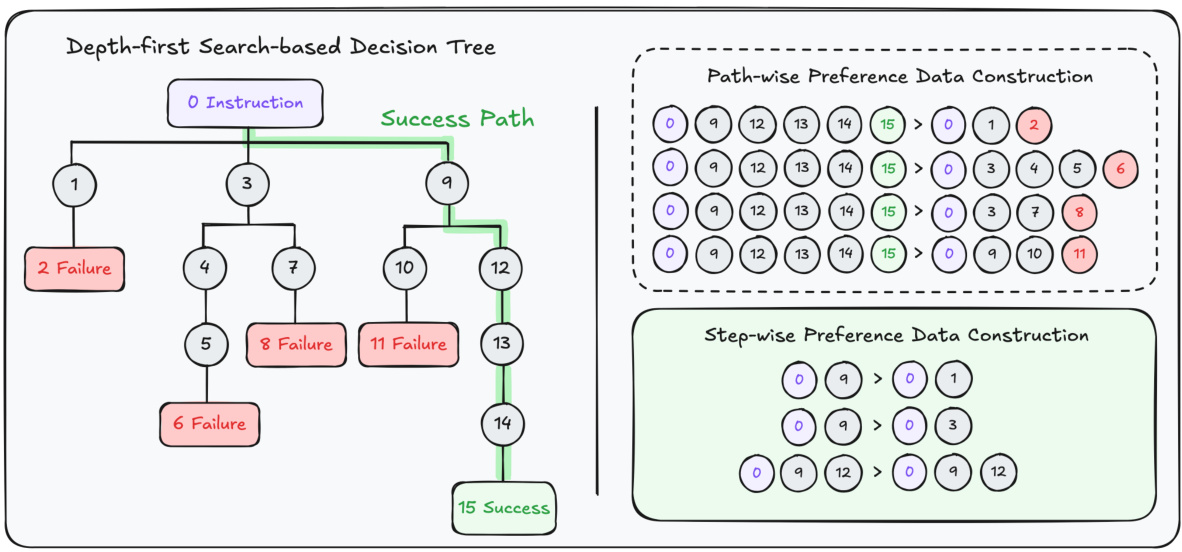
This figure illustrates the structure of depth-first search-based decision trees used in the ToolBench dataset and demonstrates two methods for constructing preference data from these trees: path-wise and step-wise. The left side shows a sample decision tree, where nodes represent LLM decisions about API calls, and edges represent the transitions between decisions. Successful and failed paths are highlighted in green and red, respectively. The right side illustrates the two preference data construction methods. The path-wise method uses an entire success path and an entire failure path to form a preference pair. The step-wise method uses branch nodes along the success path and its corresponding child nodes to create preference pairs. This figure visually explains how the authors leverage both successful and failed paths within the decision trees to create a more comprehensive preference dataset.

This figure illustrates the overall framework of the proposed inference trajectory optimization method. It starts with a pre-trained LLM and utilizes a depth-first search-based decision tree to explore tool usage. Successful and failed trajectories are collected to create a preference dataset (ToolPreference). This dataset is then used in a direct preference optimization (DPO) step to fine-tune the LLM, resulting in the ToolPrefer-LLaMA model (TP-LLaMA).

This figure illustrates the proposed inference trajectory optimization framework. It shows the process starting from user queries, then depth-first search-based decision trees exploring different API calls. Successful and failed steps are collected to create a ToolPreference dataset used in direct preference optimization (DPO) with a pre-trained LLM. This results in the final TP-LLaMA model. The framework highlights the incorporation of insights from failed paths to improve LLM performance.
More on tables

This table presents the average number of steps taken by two models, TP-LLaMA and LLaMA with SFT, during the DFSDT inference process across six test scenarios. Each scenario is categorized by instruction type (instruction, tool, category) and tool usage (single-tool, intra-category multi-tool, inter-category multi-tool) The ‘Imp’ column shows the percentage improvement in the average number of steps achieved by TP-LLaMA compared to LLaMA with SFT.
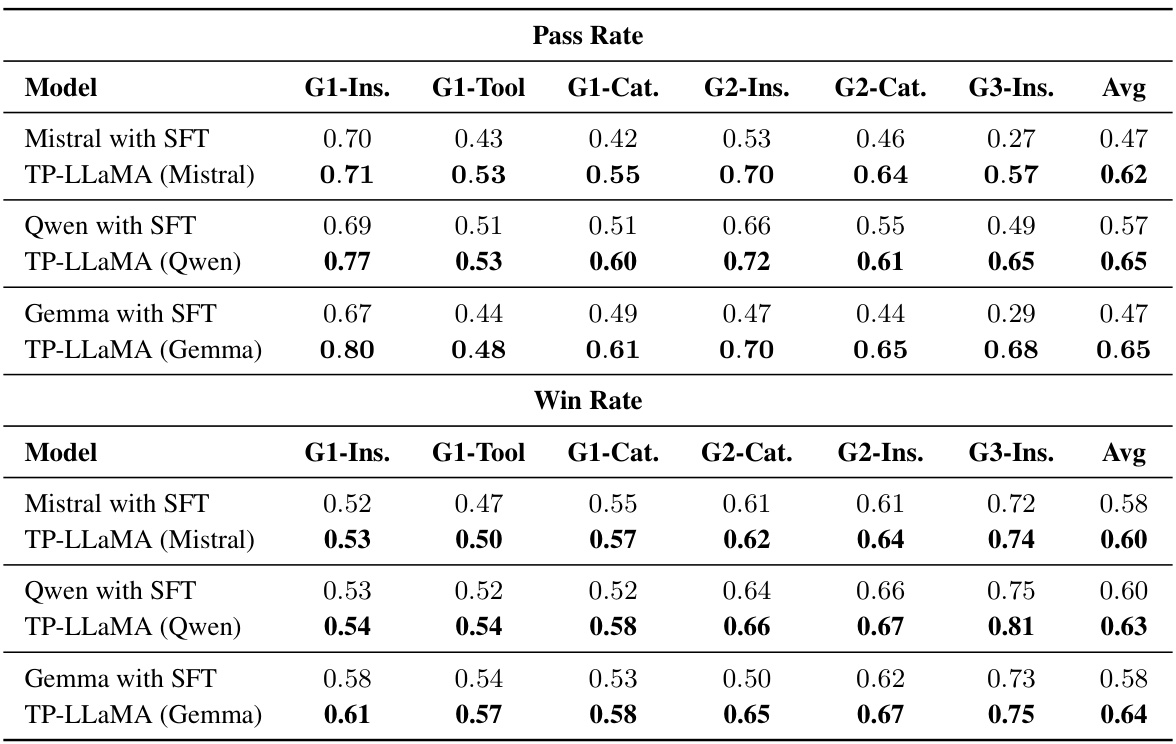
This table presents the results of ablation experiments, where the base language model in the TP-LLAMA framework was replaced with three different models: Mistral-7B, Qwen-1.5-7B, and Gemma-7B. The table shows the pass rate and win rate for each model on six test scenarios, comparing the performance of the models trained only with successful trajectories (SFT) against the models further trained with preference data obtained from failed explorations (TP-LLAMA). The results demonstrate the consistent effectiveness of the proposed framework across different base models.

This table presents the results of ablation experiments conducted to evaluate the impact of using different base LLMs on the efficiency of the proposed TP-LLaMA model. It compares the average number of steps in one successful path for six different test scenarios (G1-Ins, G1-Tool, G1-Cat, G2-Ins, G2-Cat, G3-Ins) across three different base LLMs (Mistral, Qwen, and Gemma) both with and without preference learning (TP-LLaMA). The ‘Imp’ column shows the percentage improvement in efficiency achieved by TP-LLaMA over the baseline SFT model for each base LLM. This demonstrates the robustness of TP-LLaMA’s efficiency gains across various LLMs.

This table presents the main experimental results, comparing the performance of TP-LLaMA against several baseline models (ChatGPT, Davinci, ToolLLaMA, and LLaMA with SFT) across six test scenarios. The scenarios vary in difficulty, testing the models’ abilities with single tools, intra-category multi-tools, and inter-category multi-tools, as well as their generalization to unseen APIs and instructions. Performance is measured using two metrics: pass rate (probability of successful completion within a limit of steps) and win rate (preference for the model’s answer compared to the ChatGPT+DFSDT approach). A higher pass rate indicates better performance and a win rate above 50% shows superiority to the ChatGPT+DFSDT method.
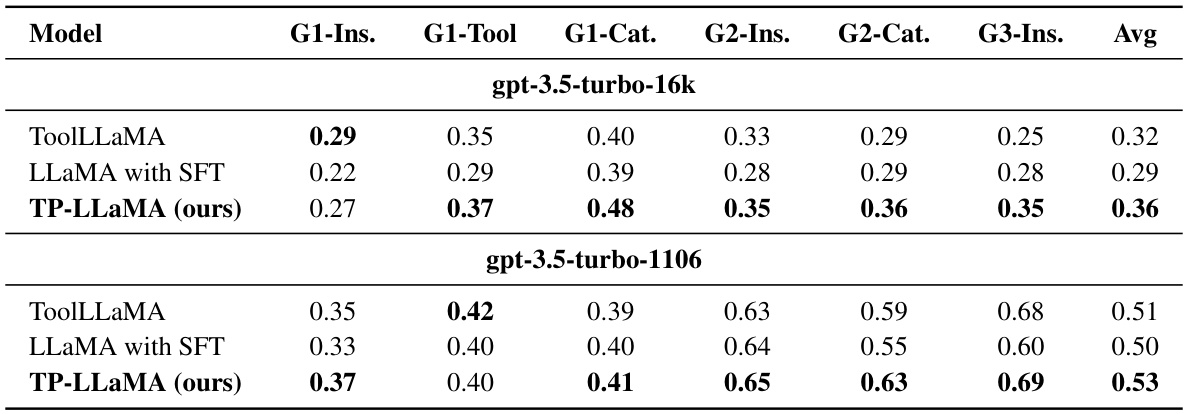
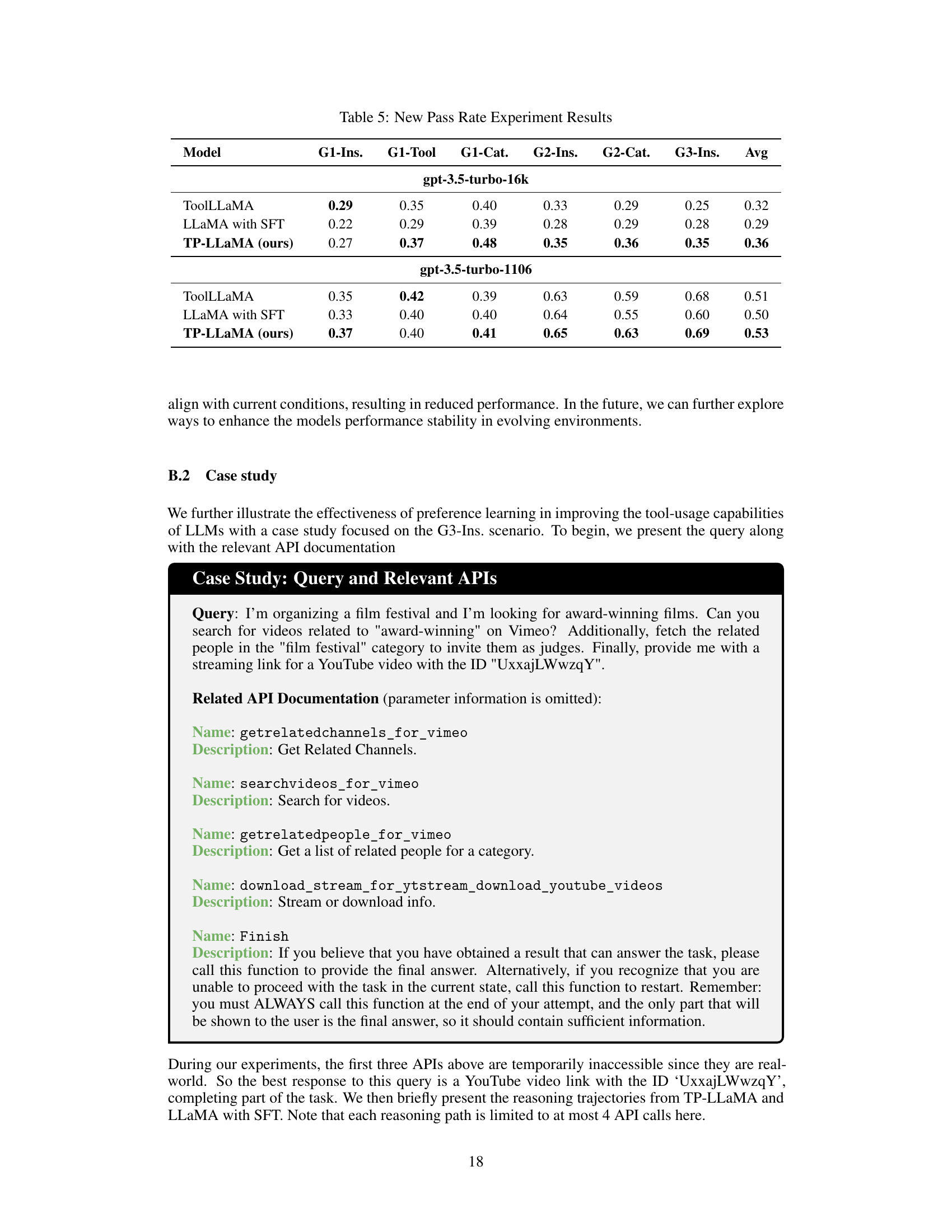
This table presents the results of experiments using a new pass rate definition based on GPT evaluation, comparing ToolLLaMA, LLaMA with SFT, and TP-LLaMA across six test scenarios. The pass rate is calculated based on whether the model successfully provides an answer, and whether GPT evaluates that answer as correct and solvable with the available APIs. Two different GPT versions (gpt-3.5-turbo-16k and gpt-3.5-turbo-1106) were used in the evaluation, highlighting the impact of GPT version on the results.
Full paper#