↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training machine learning models and labeling data are expensive, but many pre-trained models and unlabeled data exist. This paper addresses the challenge of efficiently selecting the best pre-trained model for a given task while minimizing the need for expensive label acquisition. Existing methods for model selection often lack the context-awareness and label-efficiency needed for optimal performance in dynamic environments.
The researchers propose CAMS, a novel contextual active model selection algorithm that uses both context information and active learning to choose the most suitable model for each instance. CAMS demonstrates significant improvements in label efficiency (less than 10% labeling effort compared to existing methods) on various benchmark datasets, while maintaining high accuracy. The theoretical analysis of CAMS provides guarantees on its regret and query complexity, making it a robust and effective method for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and related fields because it presents a novel and efficient approach for active model selection, a critical aspect of various real-world applications. Its rigorous theoretical analysis and strong empirical results provide valuable insights and guidance for developing more effective and cost-efficient AI systems. The research also opens new avenues for further research in online learning, contextual bandits, and active learning, potentially leading to significant advancements in these fields.
Visual Insights#

This figure presents the CAMS algorithm, which consists of two main procedures: SETRATE and RECOMMEND. SETRATE determines the learning rate for updating the probability distribution over policies, considering both stochastic and adversarial settings. RECOMMEND selects the model for prediction, using a weighted majority strategy for stochastic cases and random sampling for adversarial ones. The algorithm dynamically queries labels based on model disagreement, balancing exploration and exploitation.

The table compares CAMS with other related works based on several key aspects of their problem setup, including whether they perform online model selection, utilize full-information online learning, employ active query strategies, consider contextual information, and address the contextual active model selection problem. This allows for a clear understanding of CAMS’s position within the existing literature and its unique contributions.
In-depth insights#
CAMS Algorithm#
The CAMS algorithm is presented as a novel approach to contextual active model selection, aiming for efficient model choice while minimizing labeling costs. It leverages context information to make informed decisions, selecting the best-performing model for a given input. A key component is the adaptive query strategy, determining when to request labels to balance prediction accuracy and cost. The algorithm’s strength lies in its adaptability to both stochastic and adversarial settings, demonstrated through theoretical analysis and empirical results showing substantial labeling cost reduction. The theoretical bounds on regret and query complexity further support its efficiency. The algorithm showcases robustness across diverse datasets, and achieves comparable or better accuracy with significantly less labeling effort than existing methods, highlighting its practical significance in label-scarce scenarios.
Active Querying#
Active Querying is a crucial strategy in label-efficient machine learning, aiming to minimize the annotation cost by strategically selecting which data points to label. Instead of labeling all data, it prioritizes informative instances likely to improve model performance most effectively. The selection process often leverages uncertainty sampling, query-by-committee, or other methods to identify data points where model predictions are most uncertain or disagree most. Contextual information can significantly enhance active querying by considering data characteristics that predict model performance. Effective active querying demands balancing exploration (sampling diverse instances) and exploitation (focusing on areas of high uncertainty). Theoretical analysis frequently involves regret bounds, quantifying the difference between the active learner’s performance and that of an oracle. Algorithms are often evaluated empirically across various datasets, comparing their cumulative loss and query complexity against baselines such as random sampling.
Theoretical Bounds#
A theoretical bounds section in a machine learning research paper would rigorously analyze the performance guarantees of a proposed algorithm. It would typically involve deriving upper bounds on quantities like regret (the difference between the algorithm’s performance and that of an optimal strategy) and query complexity (the number of data points the algorithm needs to query to achieve a certain level of performance). These bounds would often be expressed in terms of relevant problem parameters (e.g., number of models, number of classes, time horizon). The analysis might consider various settings, such as stochastic (data is drawn independently and identically distributed) and adversarial (data is chosen by an adversary to make learning as difficult as possible). A strong theoretical bounds section would demonstrate the efficiency and robustness of the algorithm, even under challenging conditions, providing a significant contribution beyond empirical evaluations.
Ablation Studies#
Ablation studies systematically remove or modify components of a model to assess their individual contributions and isolate critical features. In the context of a machine learning research paper, this usually involves removing parts of the model architecture, modifying hyperparameters, or altering data preprocessing steps. The goal is to understand the impact of each component on the model’s overall performance, highlighting which aspects are essential for success and which are less crucial or even detrimental. Well-designed ablation studies are crucial for demonstrating a model’s robustness and identifying potential areas for improvement. By systematically varying components, researchers can gain insight into the model’s behavior and make more informed design choices for future iterations. A thorough ablation study provides strong evidence that supports the model’s claims regarding performance. Furthermore, by clearly indicating which components have the most significant impact, the study helps readers understand the model’s strengths and weaknesses. Without ablation studies, it remains difficult to determine the model’s essential characteristics and to distinguish between strong and weak elements of its design or methodology.
Future Work#
The ‘Future Work’ section of a research paper on contextual active model selection would ideally explore several promising avenues. Extending the theoretical analysis to more complex scenarios, such as non-i.i.d. data streams or settings with concept drift, would enhance the algorithm’s applicability in real-world settings. Investigating alternative query strategies beyond the proposed adaptive query probability, potentially incorporating uncertainty sampling or other active learning techniques, could further improve label efficiency. Empirical evaluation on a wider range of benchmark datasets and real-world applications across diverse domains (e.g., medical imaging, natural language processing) is crucial to assess the algorithm’s generalizability and practical impact. Finally, exploring the scalability and efficiency of the algorithm for massive datasets and high-dimensional data is essential for broader adoption. A detailed investigation into the algorithm’s sensitivity to hyperparameter choices, and the development of robust methods for their selection, would also be valuable contributions.
More visual insights#
More on figures

The figure compares the performance of CAMS with seven other baseline methods across four different benchmark datasets. Each subplot displays the cumulative loss (y-axis) against the query cost (x-axis). The results demonstrate that CAMS consistently outperforms the baselines across all four datasets, showcasing its superior cost-effectiveness in active model selection.

This figure presents ablation studies on the proposed CAMS algorithm. Panel (a) compares different query strategies (CAMS, variance-based, random) while keeping the model selection strategy fixed. Panel (b) shows the query cost increase rate for CAMS versus other baselines. Panels (c) and (d) evaluate CAMS performance in context-free and pure adversarial settings respectively. Panel (e) displays results for a larger dataset (COVTYPE). Panels (f) and (g) show results when adjusting query probabilities for VERTEBRAL and HIV datasets respectively. Finally, panel (h) shows a comparison between CAMS and the best policy for the HIV dataset.
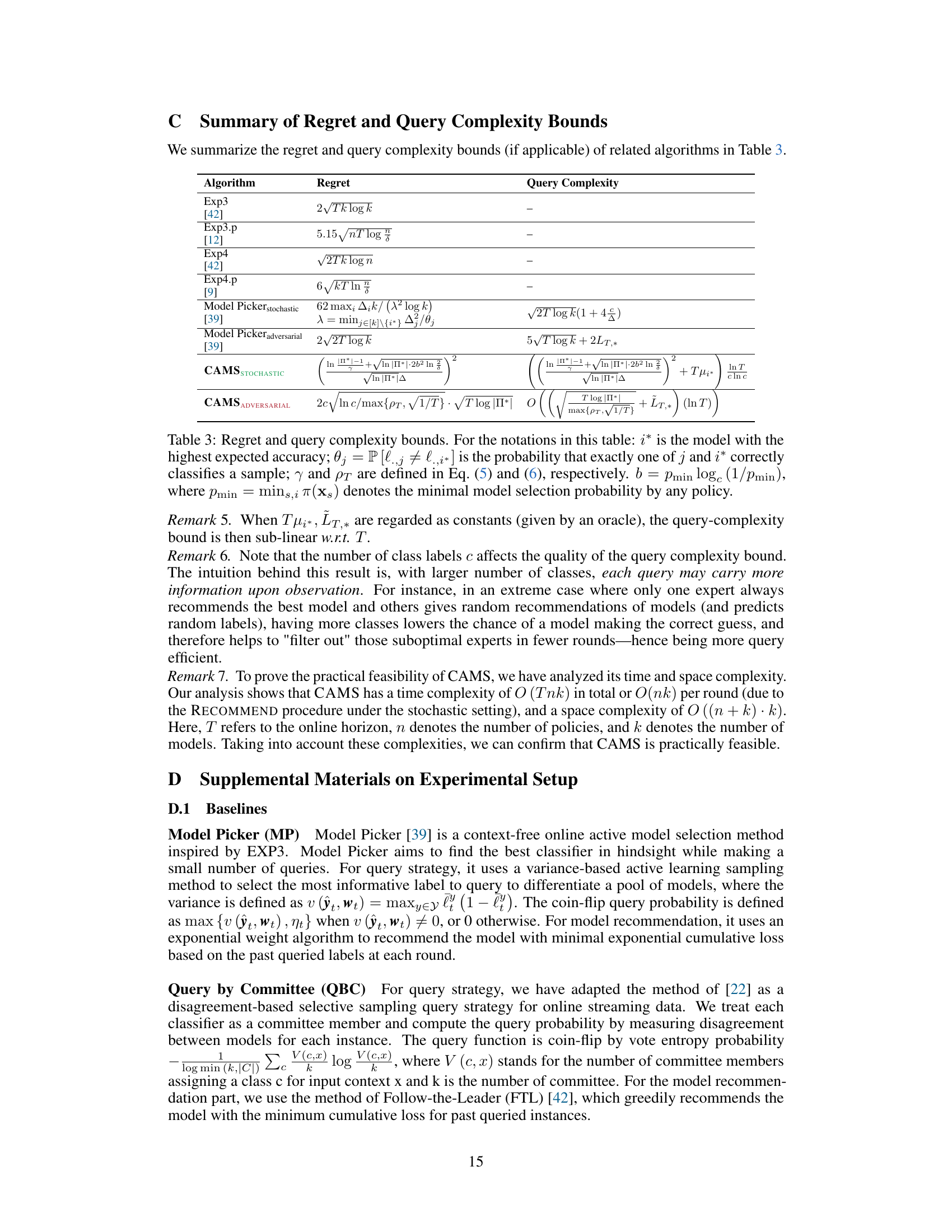
This figure compares the performance of CAMS against seven baseline algorithms on the CovType dataset in terms of relative cumulative loss, the number of queries needed, and cost-effectiveness. The left panel shows the relative cumulative loss (loss compared to the best classifier) under a fixed query budget. The middle panel displays the cumulative number of queries, and the right panel illustrates the cumulative loss as the query cost increases. CAMS consistently outperforms all baselines across all three metrics.
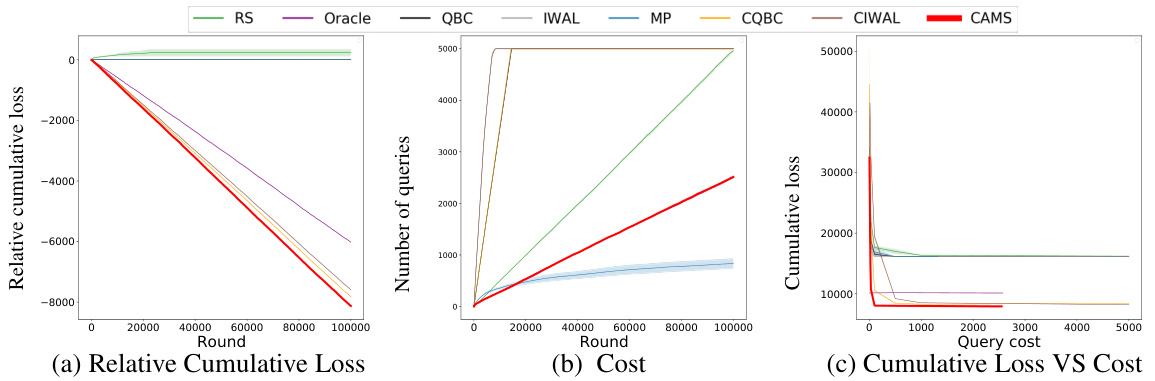
This figure compares three different query strategies (entropy, variance, and random) used in the CAMS algorithm. The experiment is conducted on four diverse benchmark datasets (CIFAR10, DRIFT, VERTEBRAL, and HIV). The results show that the entropy-based query strategy used in CAMS significantly outperforms the variance and random strategies in terms of both query cost and cumulative loss, particularly for datasets with non-binary classification tasks. The use of 90% confidence intervals helps to quantify the reliability of the results and provides a visual representation of the uncertainty associated with each data point.

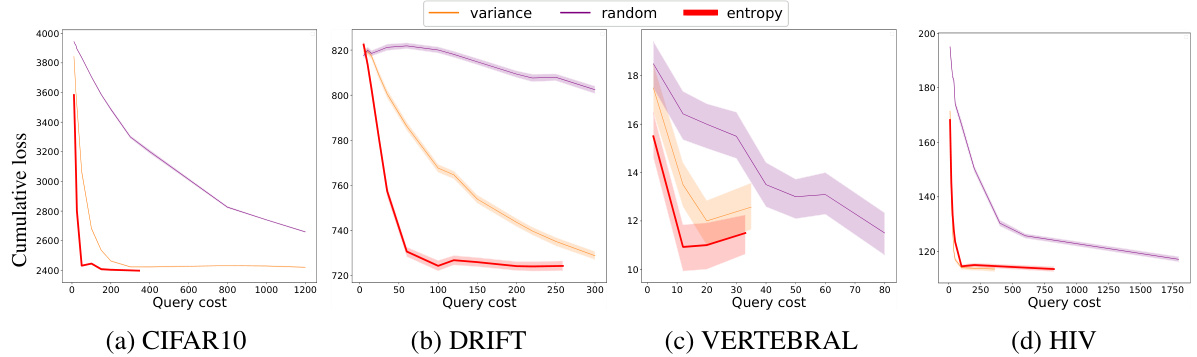
This figure compares the performance of CAMS against all individual policies (showing only the top performers for clarity) across four datasets: CIFAR10, DRIFT, VERTEBRAL, and HIV. The results demonstrate that CAMS consistently achieves a cumulative loss comparable to or even better than the best performing individual policy, while often requiring significantly fewer queries. It’s particularly notable that CAMS outperforms the best policy in the VERTEBRAL and HIV datasets.
The figure compares the performance of CAMS against 7 other algorithms (4 contextual and 3 non-contextual) on four different benchmark datasets. The x-axis represents the query cost (number of labels requested), and the y-axis represents the cumulative loss. The plots show that CAMS consistently outperforms the other algorithms in terms of cost-effectiveness, achieving a lower cumulative loss for the same query cost.

This figure compares the performance of CAMS and a conventional approach in an adversarial environment with only malicious and random policies. The results show that CAMS is robust, adapting to the situation and approaching the performance of the best classifier. In contrast, the conventional approach is trapped and its performance suffers. The experiment is conducted on four datasets.
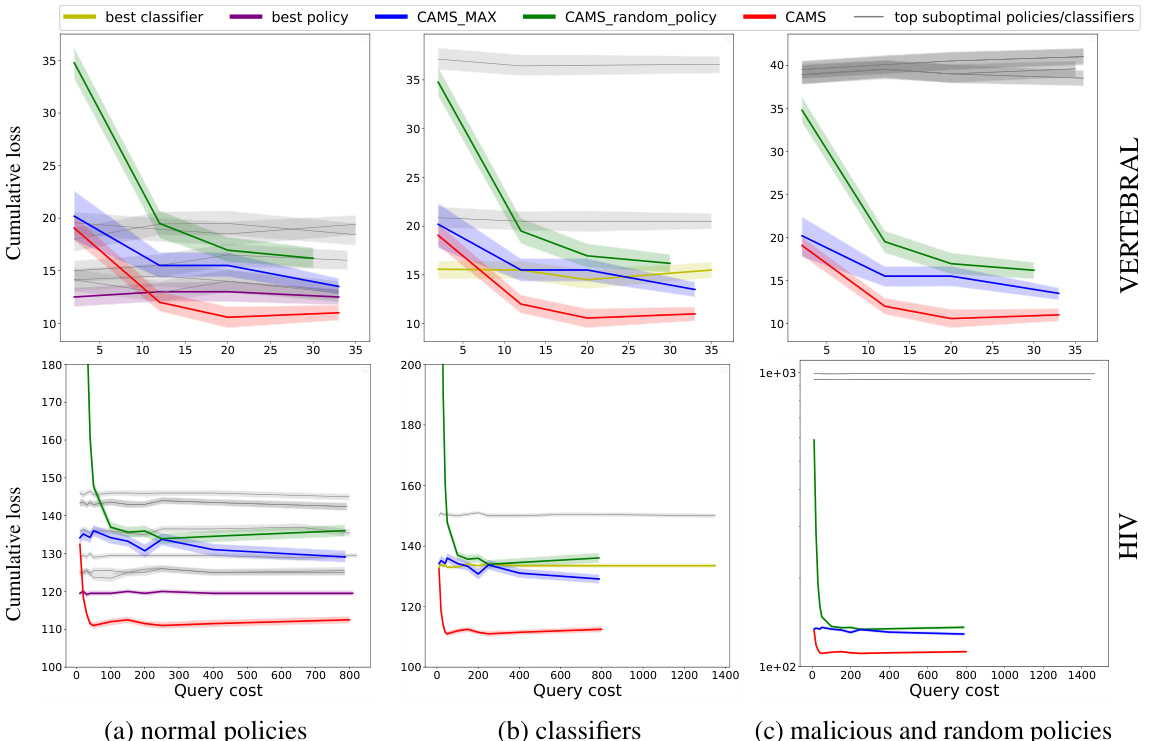
This figure compares the performance of three variants of CAMS (CAMS, CAMS-MAX, and CAMS-random-policy) against top-performing policies and classifiers on two benchmark datasets (VERTEBRAL and HIV). The results show that all three CAMS variants outperform policies that provide malicious or random advice. Interestingly, both CAMS and CAMS-MAX surpass the performance of the single best classifier. Most notably, CAMS achieves even better performance than the best policy (Oracle), consistently moving toward the hypothetical optimal solution of zero cumulative loss.

The figure shows the pseudocode of the CAMS algorithm, which consists of two main procedures: SETRATE and RECOMMEND. SETRATE determines the learning rate based on whether the setting is stochastic or adversarial. RECOMMEND selects the model to use for prediction, again using different methods depending on the setting. The algorithm incorporates an adaptive query strategy to strategically request labels to minimize cost.

The figure shows the pseudocode for the CAMS algorithm, which consists of two main procedures: SETRATE and RECOMMEND. SETRATE determines the learning rate and query probability based on whether the setting is stochastic or adversarial. RECOMMEND selects a model based on the current context and the probability distribution over policies. The algorithm iteratively receives data points, makes predictions, and decides whether to query the true label based on a calculated uncertainty metric. The process updates model loss and policy probabilities to refine future decisions.
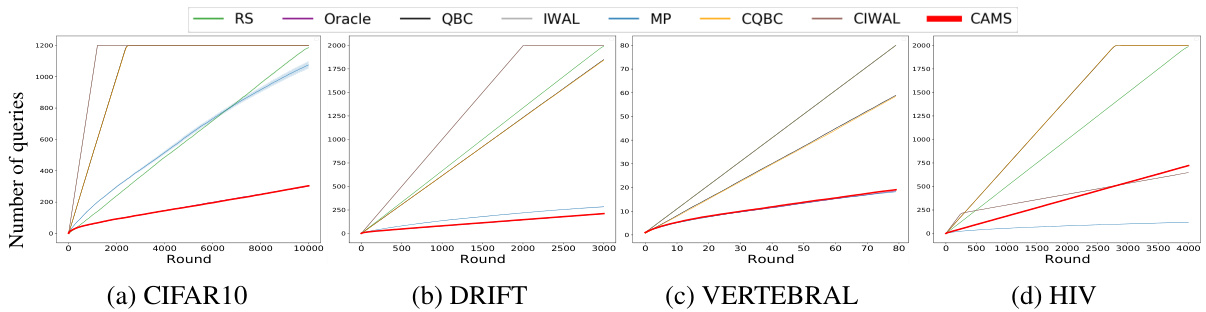
The figure compares the performance of CAMS against seven other baseline methods on four different benchmark datasets. The x-axis represents the query cost (number of labels requested), and the y-axis shows the cumulative loss. The results show that CAMS consistently outperforms all other methods across all four datasets.

The figure compares the performance of CAMS against seven baseline methods across four different benchmark datasets. The x-axis represents the query cost (number of labels requested), and the y-axis represents the cumulative loss. Each subplot corresponds to a different dataset. The results show that CAMS consistently outperforms all the baselines in terms of cost-effectiveness, achieving a lower cumulative loss for the same query cost.

This figure compares the performance of CAMS and a non-active variant (CAMS-nonactive) across four benchmark datasets. CAMS-nonactive queries labels for every incoming data point. The figure shows that CAMS performs equally well or better than CAMS-nonactive, even though it queries significantly less data. The upper plots show the number of queries over rounds, while the lower plots show the cumulative loss with respect to the query cost.

This figure compares the performance of CAMS against 7 other baseline methods (4 contextual and 3 non-contextual) across 4 different benchmark datasets (CIFAR10, DRIFT, VERTEBRAL, HIV). The performance is measured by relative cumulative loss, which represents the difference between the cumulative loss of each method and the cumulative loss of the best classifier. The figure shows that CAMS consistently outperforms all other methods across all datasets, achieving negative relative cumulative loss in many cases. This indicates that CAMS not only learns effectively but also surpasses the performance of simply selecting the best classifier.
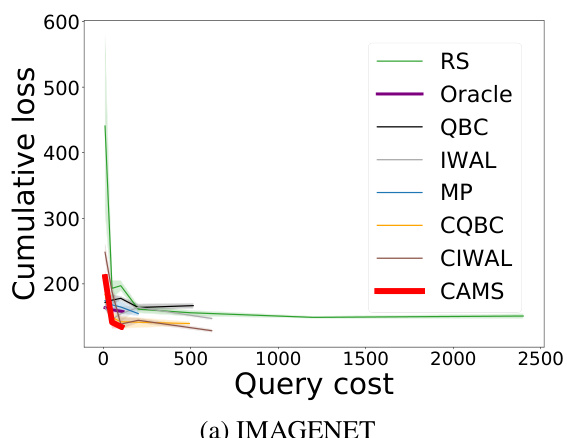
This figure compares the performance of CAMS against seven baseline methods on the ImageNet dataset. The x-axis represents the query cost (number of labels requested), and the y-axis shows the cumulative loss. The plot demonstrates that CAMS achieves the lowest cumulative loss compared to all other methods, both contextual and non-contextual, for a fixed number of rounds and a maximum query cost.
More on tables

This table compares CAMS with other related methods in terms of problem setup, highlighting the key differences and similarities in their approaches. It shows whether each algorithm uses online bagging, online learning, contextual bandits, active learning, full information, active queries, and context-awareness. This helps to situate CAMS within the existing literature and clarifies its novel contributions.

This table compares CAMS with other related methods based on several key aspects of the problem setup, including whether they are online, contextual, utilize active queries, and the type of learning setting (full information vs. bandit). It highlights the novelty of CAMS by showing how it uniquely combines features from other approaches.

This table compares CAMS with other related methods in terms of their problem setup. It highlights the key differences between CAMS and other approaches, such as online bagging, Hedge, EXP3, EXP4, Query by Committee, and ModelPicker, across various aspects like whether they use active queries, are context-aware, and employ online learning or contextual bandits.

This table compares CAMS with other related methods in terms of the problem setup. It highlights whether each method uses online bagging, contextual bandits, active learning, model selection, full-information setup, active queries, or context-aware model selection. This allows for a clear comparison of the features and methodology of CAMS and other existing approaches.
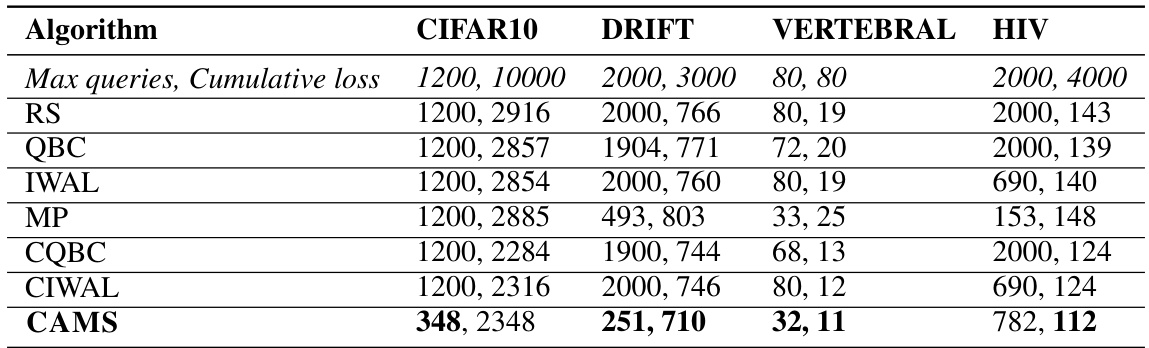
This table presents the maximum number of queries and the corresponding cumulative loss for each algorithm across four benchmark datasets (CIFAR10, DRIFT, VERTEBRAL, HIV). The results are based on a fixed number of rounds and a maximum query budget for each dataset. The values represent the worst-case scenario observed during multiple experimental runs. This provides a complementary view of the cost-effectiveness of various algorithms, compared to the average performance shown in the main results.

This table compares CAMS with other related methods in terms of problem setup, highlighting the key differences in terms of whether they use online bagging, online learning, contextual bandits, active learning, active queries, or context-aware model selection. It shows that CAMS is unique in combining contextual bandits and active learning with a focus on online model selection in a context-aware manner.
Full paper#