↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual object tracking, a fundamental task in computer vision, traditionally relies on image-feature regression or coordinate autoregression models. However, these methods often struggle with unseen data and real-time performance. The paper identifies these limitations, emphasizing the need for a more robust and efficient approach.
To overcome these challenges, the paper proposes DeTrack, a novel in-model latent denoising learning paradigm. DeTrack uses a denoising Vision Transformer (ViT) to decompose the denoising process into multiple denoising blocks, enabling real-time tracking. By incorporating trajectory and visual memory, DeTrack improves tracking stability and achieves competitive results on several benchmark datasets, demonstrating the practicality and effectiveness of its novel approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel in-model latent denoising learning paradigm for visual object tracking. It addresses limitations of existing methods by enhancing model robustness to unseen data and achieving real-time performance, opening new avenues for research in this active field. The proposed method’s efficiency and competitive performance make it highly relevant to practical applications and further research.
Visual Insights#

This figure illustrates the difference between the traditional denoising learning process in image generation and object detection, and the proposed in-model latent denoising learning paradigm for visual object tracking. Panel (a) shows the diffusion model used in image generation, which involves multiple iterations of a U-Net to denoise an image progressively. Panel (b) shows how the diffusion model is applied to object detection, utilizing multiple decoder iterations for denoising. In contrast, panel (c) presents the proposed method, where the denoising process is decomposed into multiple denoising blocks within a single model (denoising ViT), enabling real-time performance. The pink box in (c) highlights the denoising module, and ‘× N’ indicates the number of denoising iterations.

This table presents the specifications of two DeTrack model variants: DeTrack256 and DeTrack384. It shows the template size, search region size, number of floating-point operations per second (FLOPs), speed in frames per second (FPS), and the device used for processing (RTX3090). The different sizes reflect variations in input resolution and processing demands.
In-depth insights#
In-model Denoising#
In-model denoising represents a significant advancement in visual object tracking by integrating the denoising process directly within the model’s architecture. This approach contrasts with traditional methods that perform denoising as a separate pre- or post-processing step. The key advantage is improved efficiency, as the denoising is done concurrently with other model operations, avoiding the computational overhead of multiple passes through separate denoising modules. This is particularly crucial for real-time applications, where speed is paramount. Furthermore, in-model denoising offers enhanced robustness. By directly handling noise within the core tracking process, the model inherently becomes more resilient to noisy inputs and variations in image quality, leading to more accurate and reliable tracking results even under challenging conditions. However, the design and implementation of effective in-model denoising strategies require careful consideration of how the denoising process interacts with other model components, such as feature extraction and bounding box prediction. Careful block design and parameter tuning are essential to avoid compromising the model’s overall performance or introducing unwanted artifacts. The success of in-model denoising highlights the increasing importance of integrating noise handling into the core algorithms, rather than treating it as a separate concern. This trend reflects a broader shift towards more integrated and efficient approaches in computer vision.
ViT Architecture#
A Vision Transformer (ViT) architecture, particularly within the context of visual object tracking, would likely involve a series of stages. First, input image patches would be embedded into a high-dimensional space, forming the initial tokens. Then, multiple transformer encoder blocks would process these tokens, capturing spatial relationships and contextual information crucial for object localization. Each block may include self-attention and feed-forward neural network layers for feature extraction. Template and search embeddings are vital; they represent the object template and the current frame region respectively, acting as contextual information during the encoding process, effectively guiding attention mechanisms towards the target. Finally, a decoder or classification layer would produce the predicted bounding box or class labels, indicating the target’s location and properties in the image. A well-designed ViT would balance the capacity for complex feature representations with efficiency for real-time performance.
Tracking Paradigm#
The core of the paper revolves around a novel tracking paradigm. Instead of relying on traditional image-feature regression or coordinate autoregression, the authors propose in-model latent denoising learning. This innovative approach introduces noise to bounding boxes during training, thereby enhancing the model’s robustness to unseen data and improving its performance on challenging datasets. The key innovation lies in decomposing the denoising process into multiple denoising blocks within the model itself, eliminating the need for iterative denoising and enabling real-time tracking. This ‘in-model’ approach contrasts with traditional diffusion models, offering a significant speed advantage crucial for practical applications. The paper further enhances tracking stability by incorporating trajectory and visual memory, leveraging temporal and contextual information to improve the accuracy and consistency of predictions. This combination of denoising learning and memory mechanisms makes the proposed paradigm highly effective in various visual object tracking scenarios.
Memory Modules#
Memory modules in visual object tracking are crucial for enhancing performance, particularly in challenging scenarios. They function by storing relevant information from previous frames, enabling the tracker to leverage contextual cues and maintain tracking stability. Visual memory typically stores template representations of the target, allowing the tracker to adapt to changes in appearance. Trajectory memory records the historical trajectory, aiding in prediction and handling occlusions. The effective integration of these modules allows the model to improve robustness to variations in target appearance, viewpoint, and lighting. The design of memory modules requires careful consideration of storage capacity, update strategies, and access mechanisms. An effective memory module should not only store relevant information but also provide efficient access to enhance real-time tracking capabilities. Furthermore, the capacity for the memory modules should be balanced to avoid excessive computational cost and memory usage. Finally, addressing how to effectively utilize the information in the memory modules to refine the final bounding box prediction is another critical element to improve the overall performance.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, these studies are crucial for demonstrating the effectiveness of each proposed technique. Well-designed ablation studies isolate the impact of specific features, allowing researchers to make more precise claims about their findings and understand the interplay between different elements. For example, removing a particular loss function and observing the impact on performance would clearly indicate its importance. The results of these studies provide evidence that supports the claims in the main sections of the paper. Ideally, ablation studies should be thorough and cover a range of design choices and experimental parameters. The results might suggest areas for future improvement or highlight unexpected interactions between different components of the model. A well-executed ablation analysis strengthens the overall validity and reliability of the paper’s conclusions. Without this crucial analysis, the paper’s contributions would be less convincing and less likely to generate further research. Therefore, a solid understanding of which components contribute to the performance gains is essential for convincing readers of the overall significance of the research. Furthermore, identifying what aspects of the design are unnecessary or detrimental is equally significant.
More visual insights#
More on figures
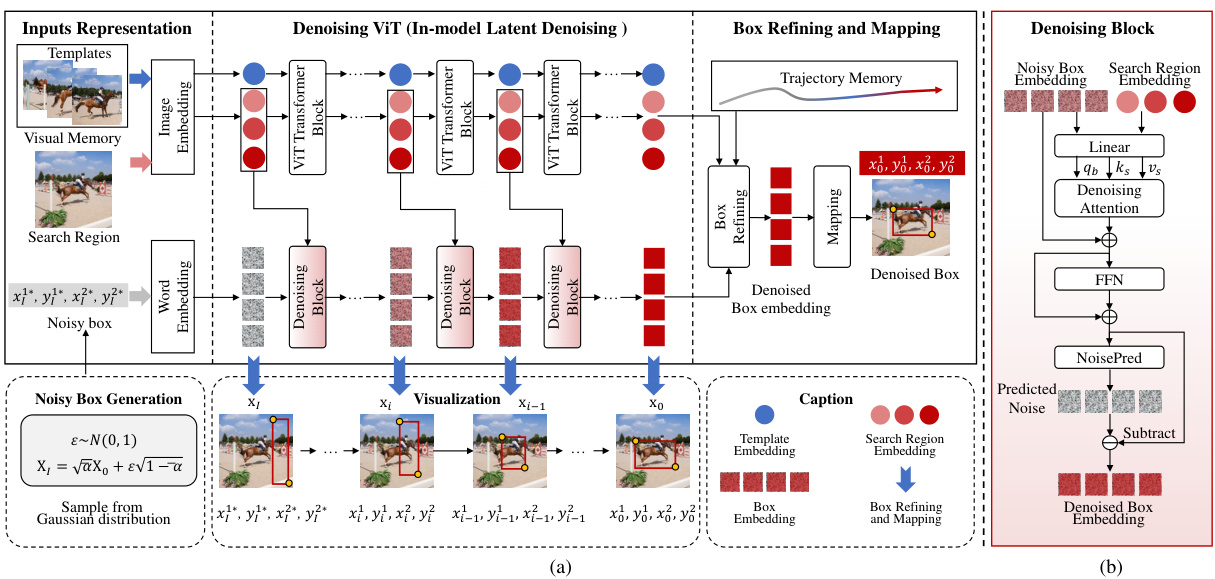
This figure provides a detailed illustration of the DeTrack model architecture. Panel (a) shows the overall workflow, starting with input representations (noisy box, templates, and search region), followed by the Denoising ViT (composed of multiple denoising blocks and ViT Transformer blocks), box refining and mapping modules, and finally the compound memory. Panel (b) zooms in on a single denoising block, showing the specific components and operations involved in the denoising process within the ViT.
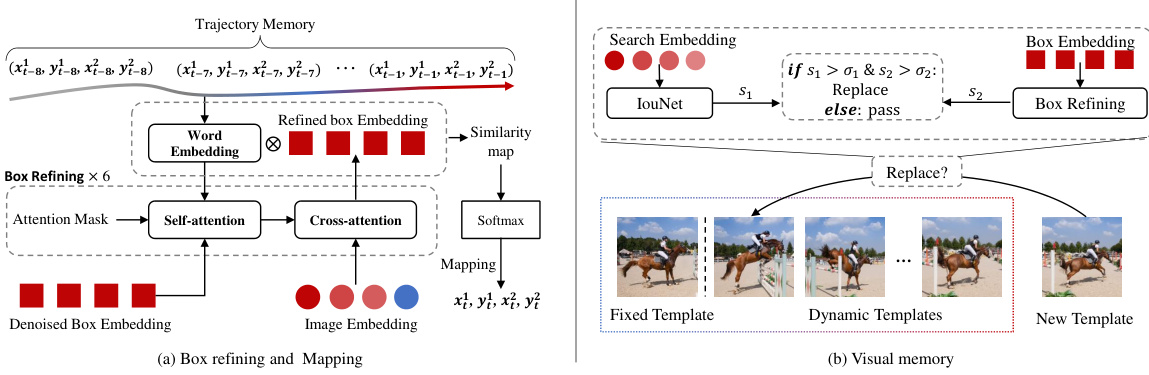
This figure shows the details of the box refining and mapping module and the visual memory updating mechanism. The left panel (a) illustrates how the trajectory memory is used in conjunction with denoised box embeddings to refine the bounding box prediction through self-attention and cross-attention. The refined bounding box is then mapped to its final position using a word embedding and a similarity map. The right panel (b) describes the visual memory update process. New templates are added to the dynamic template pool based on collaborative decision-making using IoU and Softmax scores.
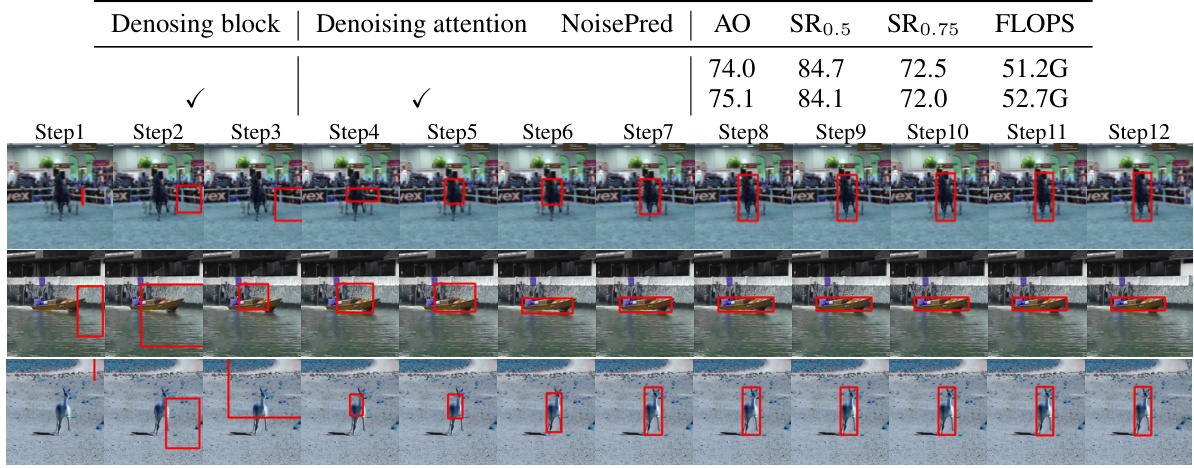
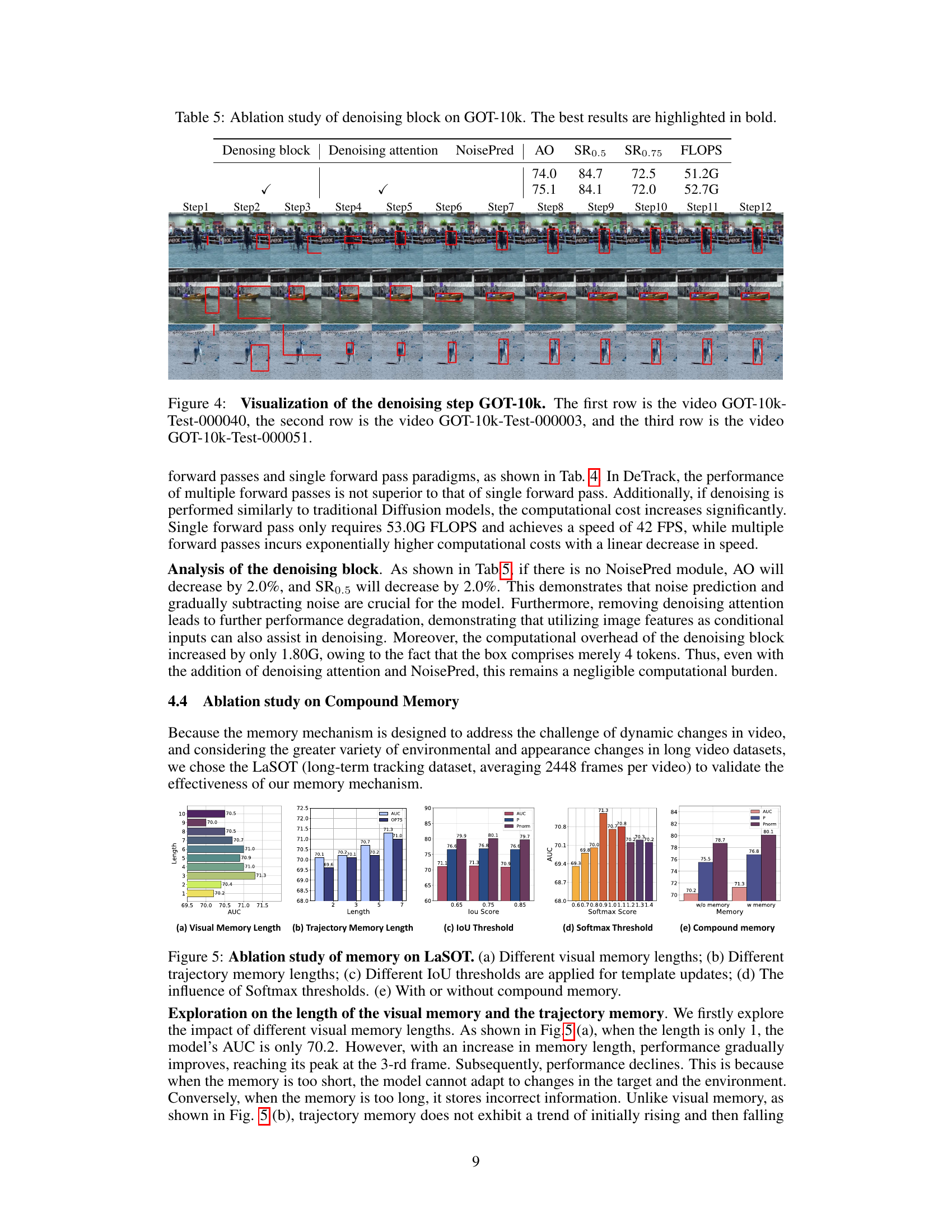
This figure visualizes the denoising process in DeTrack across three different videos from the GOT-10k dataset. Each row represents a different video sequence, showing how the bounding box prediction is progressively refined through multiple denoising steps. The initial noisy bounding boxes gradually become more accurate as the denoising process progresses, highlighting the effectiveness of DeTrack’s in-model latent denoising learning approach.

This figure provides a comprehensive overview of the DeTrack model architecture. Part (a) shows the overall structure, highlighting the input representation (noisy bounding boxes, visual memory, search region), the core denoising ViT module, the box refining and mapping module, and the integration of visual and trajectory memories. Part (b) zooms into a single denoising block within the ViT, illustrating the internal mechanism of noise removal using attention and feed-forward networks.
More on tables

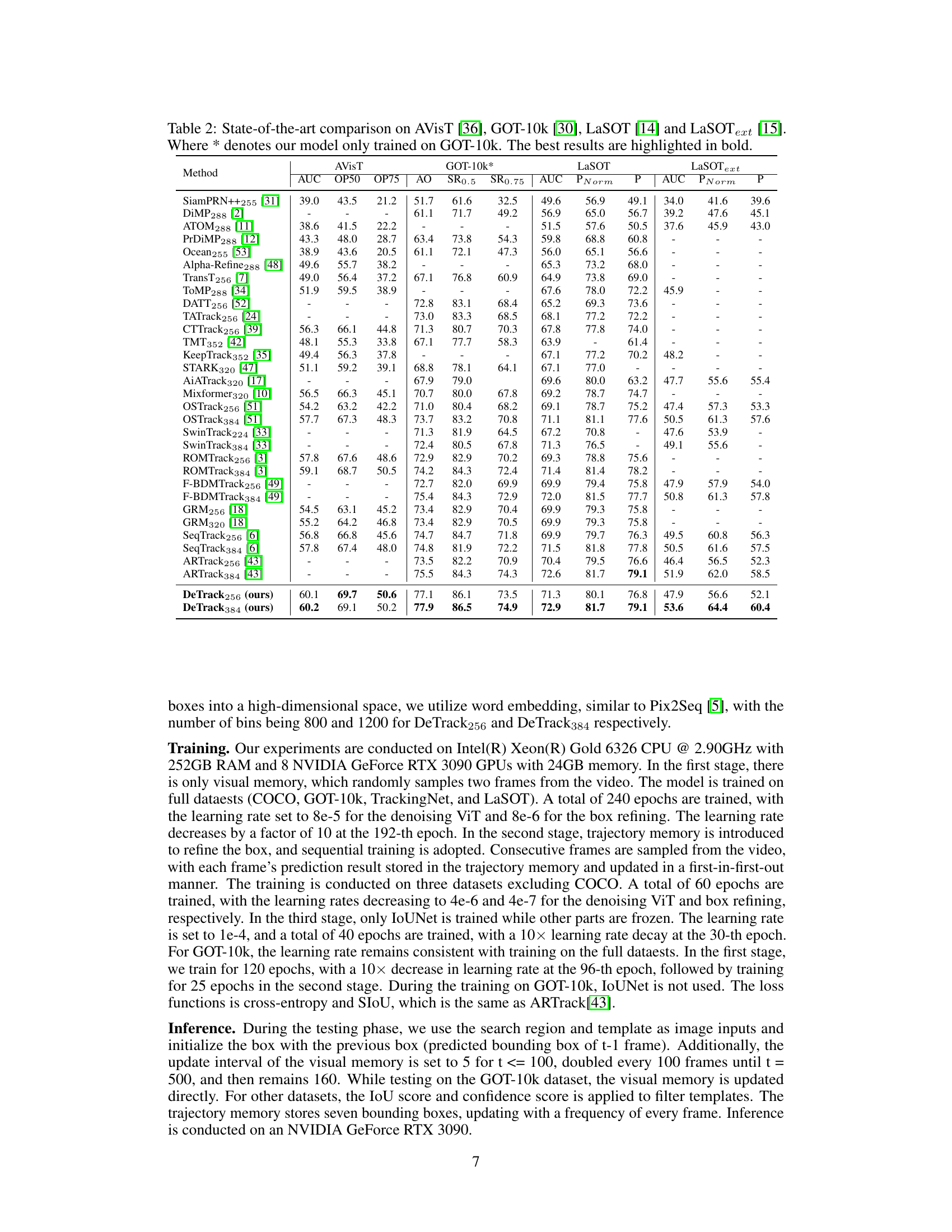
This table presents a comparison of the proposed DeTrack model’s performance against other state-of-the-art visual object tracking methods on four benchmark datasets: AVisT, GOT-10k, LaSOT, and LaSOText. The results are shown in terms of AUC (Area Under the Curve), and other metrics like OP50, OP75, SR0.5, SR0.75, P, and PNorm, which are specific evaluation metrics for each dataset. The table highlights DeTrack’s competitive performance, particularly when compared to similar methods using similar resolutions (e.g., DeTrack256 vs. SeqTrack256). The * indicates that DeTrack was also evaluated after training only on the GOT-10k dataset.

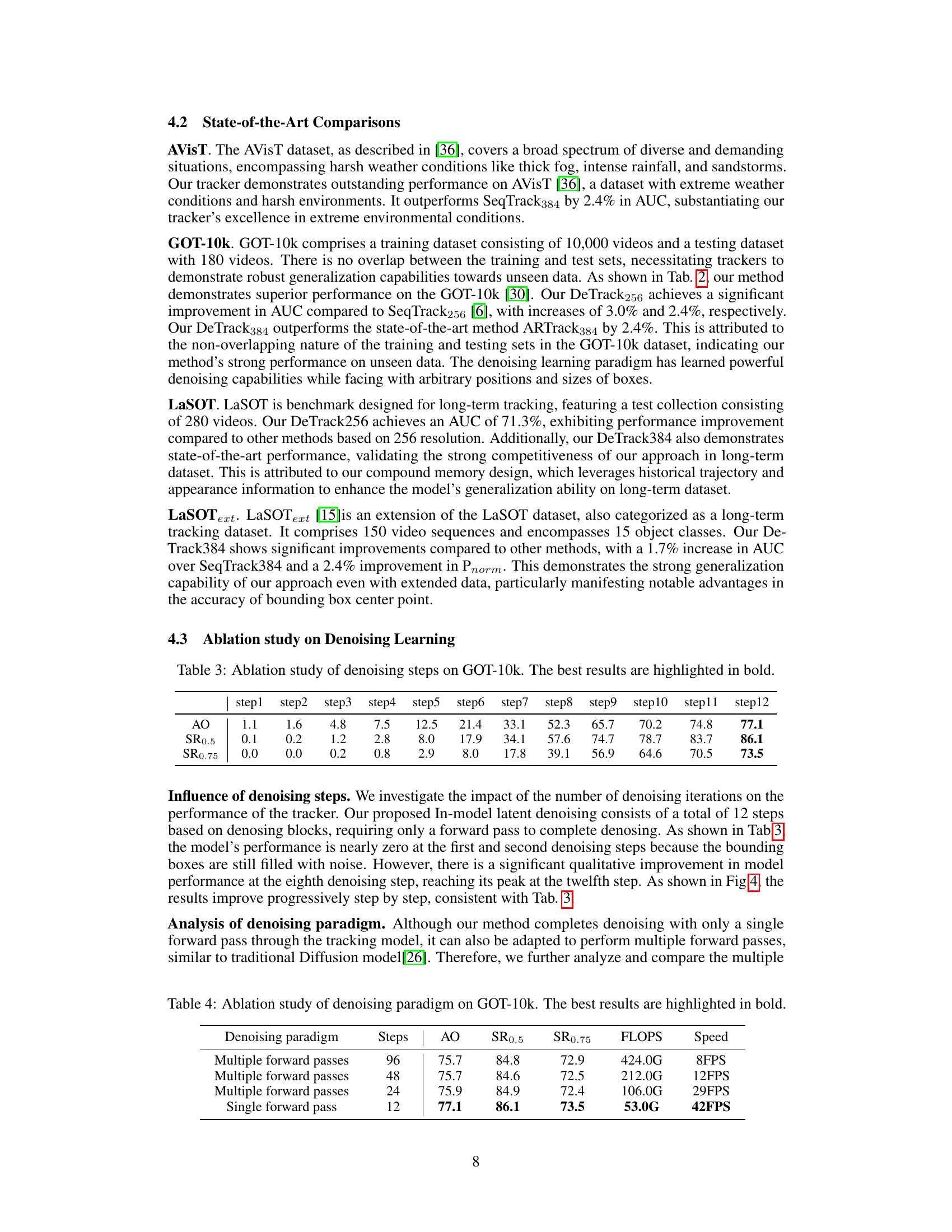
This table presents the ablation study on the number of denoising steps in the DeTrack model, evaluated on the GOT-10k dataset. It shows the impact of varying the number of denoising steps (from 1 to 12) on the model’s performance, measured by Average Overlap (AO), Success Rate at 0.5 overlap threshold (SR0.5), and Success Rate at 0.75 overlap threshold (SR0.75). The best performance for each metric is highlighted in bold, indicating the optimal number of denoising steps for the model.

This table presents the results of an ablation study comparing different denoising paradigms (multiple forward passes vs. single forward pass) and varying numbers of steps within the denoising process. The study was performed using the GOT-10k dataset and a ViT-Small backbone. The table shows the Average Overlap (AO), Success Rates at 0.5 overlap threshold (SR0.5), Success Rates at 0.75 overlap threshold (SR0.75), Floating Point Operations (FLOPS), and speed (in FPS) for each configuration. The best performing configuration for each metric is highlighted in bold, providing insights into the optimal balance between denoising effectiveness and computational efficiency.

This table highlights the key differences between three denoising methods: Denoising Diffusion Probabilistic Models (DDPM), Denoising Autoencoders (DAE), and the proposed DeTrack method. It compares the noise type used, the input type, encoding and decoding processes, optimization objectives, and inference procedures. The table shows that DeTrack differs significantly in how it handles noisy input (bounding boxes instead of images), incorporates denoising in a multi-layer fashion within a single model pass, and focuses on precise bounding box localization.

This table compares the performance of two different noise prediction methods in the DeTrack model on the GOT-10k dataset. The methods are ‘Predicting the total noise’ and ‘Predicting noise layer by layer’. The table shows the Average Overlap (AO), Success Rate at 0.5 overlap (SR0.5), and Success Rate at 0.75 overlap (SR0.75) for each method. The results indicate that predicting noise layer-by-layer yields better performance compared to predicting total noise at once.
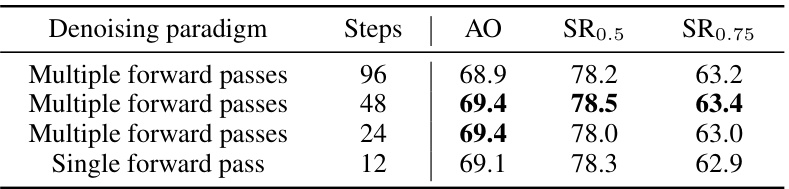
This table presents the ablation study of different denoising paradigms and step settings evaluated on the GOT-10k dataset using a ViT-Small backbone. The results show the Average Overlap (AO) and Success Rates at two different overlap thresholds (SR0.5 and SR0.75) for various numbers of steps. It compares the performance of multiple forward passes versus a single forward pass of the denoising process. The highlighted bold numbers indicate the best performing configuration across the metrics.

This table compares the encoder and decoder configurations used in two different visual object tracking models: DiffusionTrack and DeTrack. Both models utilize a DeTrack encoder, but they differ in their decoder. DiffusionTrack uses the DiffusionDet decoder, while DeTrack employs its own custom decoder. This highlights a key architectural difference between the two models.

This table compares the performance of DiffusionTrack and DeTrack on the GOT-10k dataset. It shows the Average Overlap (AO), Success Rate at 0.5 overlap (SR0.5), Success Rate at 0.75 overlap (SR0.75), and the number of floating point operations (FLOPs) for different numbers of denoising steps for both methods. DeTrack consistently outperforms DiffusionTrack in terms of AO, SR0.5, and SR0.75, while maintaining comparable or lower FLOPs.
Full paper#