↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs) excel at scalability but lack flexibility for resource-constrained environments. Existing methods train separate smaller ViTs, increasing costs and memory. This work demonstrates that smaller ViTs are intrinsically sub-networks of larger ones.
The paper introduces Scala, a framework that trains a single network to represent multiple smaller ViTs. Key techniques include ‘Isolated Activation’ to disentangle the smallest sub-network and ‘Scale Coordination’ to optimize training. Results show Scala matches performance of separately trained models, offering significant improvements in efficiency and resource usage. This flexible inference capability is achieved through one-shot training, making it a significant step towards practical ViT deployment in resource-limited settings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient deep learning models, especially those focusing on Vision Transformers (ViTs). It addresses the critical need for flexible inference by proposing a novel framework that allows a single ViT to efficiently represent multiple smaller models. This addresses the limitations of separate training by significantly reducing training costs and memory usage, while maintaining competitive accuracy. The findings will be particularly important for resource-constrained environments like mobile devices and edge computing, potentially influencing the development of future ViT-based applications.
Visual Insights#
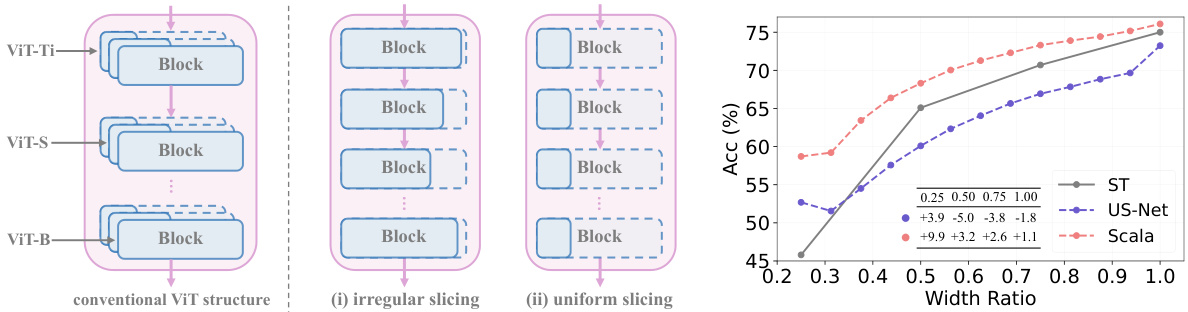
This figure illustrates three different ways to slice a Vision Transformer (ViT) architecture. The first method, irregular slicing, leads to non-standard architectures. In contrast, uniform slicing is aligned with the intrinsic design of ViTs. The figure highlights that smaller ViTs (ViT-Ti, ViT-S) are essentially sub-networks of a larger ViT (ViT-B).

This table compares the performance of Scala against three different baseline methods (AutoFormer, US-Net, and Separate Training) for different width ratios (r = 0.25, 0.50, 0.75, 1.00) on the ImageNet-1K dataset. The metrics shown include accuracy (Acc1) and GFLOPs. The table highlights Scala’s superior performance compared to the baselines, particularly at smaller width ratios, demonstrating its efficiency and effectiveness in achieving high accuracy with fewer parameters. Separate Training serves as a strong baseline, representing a fully optimized model trained separately for each size. Autoformer and US-Net are other state-of-the-art width-adjustable models.
In-depth insights#
ViT Slimmability#
The concept of “ViT Slimmability” explores the ability to efficiently reduce the size of Vision Transformers (ViTs) without significant performance degradation. Smaller ViTs are crucial for deployment on resource-constrained devices, such as mobile phones or edge computing platforms. However, simply shrinking a pre-trained ViT often leads to substantial performance drops. This is because ViTs, unlike CNNs, exhibit minimal interpolation ability, meaning that the performance of intermediate-sized ViTs cannot be reliably predicted from the performance of the largest and smallest versions. The challenges lie in the shared weight matrices across different widths. Directly reducing the width can disrupt the intricate relationships between network layers and thus affect accuracy. Effective approaches must address the training optimization challenges associated with managing multiple sub-networks simultaneously, as each smaller ViT is a sub-network within a larger model. Techniques like isolated activation and scale coordination could be employed to promote efficient training and avoid negative interference between sub-networks of differing sizes.
Scala Framework#
The Scala framework, proposed for flexible inference in Vision Transformers, addresses the challenge of training multiple smaller ViTs efficiently. Instead of separate training, which is computationally expensive, Scala trains a single, larger network that encompasses smaller sub-networks. This is achieved through uniform width slicing, leveraging the inherent scalability of ViTs. Key mechanisms within Scala include Isolated Activation to prevent interference between sub-networks, and Scale Coordination to ensure each sub-network receives well-defined and stable learning objectives. These components aim to improve the slimmable representation learning and allow inference with different model sizes without retraining. The evaluation demonstrates that Scala matches the performance of separate training with far less computational overhead, offering a significant advancement for efficient deployment of ViTs in resource-constrained settings.
Isolated Activation#
The concept of “Isolated Activation” presents a novel approach to training slimmable vision transformers. The core idea revolves around decoupling the smallest sub-network’s representation from its larger counterparts during training. This is crucial because constantly activating the smallest network in standard methods hinders the optimization of other, larger sub-networks that share weights. By isolating the smallest network, it ensures the lower bound performance is maintained, while simultaneously allowing the other sub-networks the freedom to train more effectively. This disentanglement is achieved through a clever weight-slicing technique where weights are sliced differently for the smallest network compared to others. This innovative method of training directly addresses the minimal interpolation ability commonly observed in vision transformers, preventing the optimization of intermediate subnets from falling short compared to separate training. The result is a framework where a single network can effectively represent multiple smaller variants, leading to flexible inference capabilities and significantly improved efficiency.
Scale Coordination#
The proposed “Scale Coordination” training strategy in the paper aims to address the challenge of training multiple sub-networks within a single ViT model efficiently and effectively. The core idea is to ensure each sub-network (representing different ViT sizes) receives simplified, steady, and accurate learning objectives, thereby improving the overall performance and reducing the need for separate training. This is achieved through three key techniques: Progressive Knowledge Transfer, which leverages the predictions from larger sub-networks to guide the learning of smaller ones; Stable Sampling, which carefully controls the width ratios during training to maintain a stable learning process; and Noise Calibration, which mitigates the impact of noisy signals from the teacher networks by combining KL divergence and Cross-Entropy loss. In essence, Scale Coordination is a clever training optimization that enables the efficient and effective creation of a slimmable ViT model, allowing for flexible inference while maintaining comparable or even surpassing the performance of separately trained models.
Future Work#
Future research directions stemming from this work on slicing Vision Transformers for flexible inference could focus on several key areas. Improving the interpolation ability of ViTs remains crucial, as this work highlights the challenges in directly applying existing CNN-based techniques. Investigating novel training methodologies or architectural modifications to enhance the interpolation capabilities would be highly valuable. Another important direction involves exploring different slicing strategies, potentially moving beyond uniform slicing to incorporate more nuanced approaches that better accommodate the inherent structure of ViTs. Extending the framework to other transformer-based architectures beyond vision transformers would also broaden the impact of this work. Furthermore, a comprehensive exploration of the trade-offs between inference speed and accuracy, as achieved via different slicing granularity and bounding, is needed. Finally, addressing the computational cost of training by improving the efficiency of the Scala framework, perhaps through more sophisticated sampling strategies or more effective knowledge distillation methods, warrants further research.
More visual insights#
More on figures

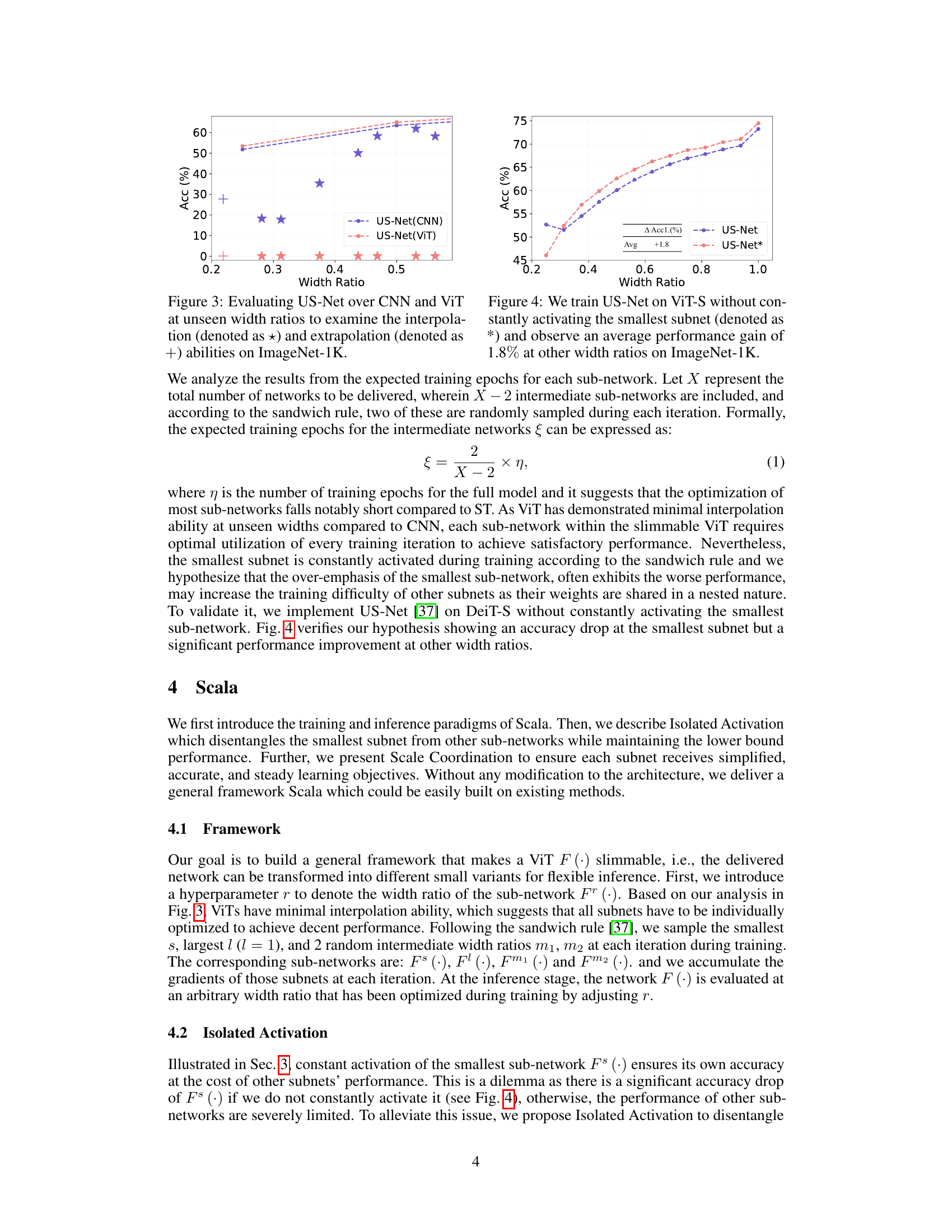
This figure compares the performance of US-Net, a method for creating slimmable neural networks, on both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). It evaluates the ability of these networks to generalize to unseen width ratios (i.e., network sizes not seen during training). The results show that CNNs exhibit good interpolation and extrapolation capabilities, meaning that their performance remains relatively consistent even when tested at network widths that differ from those used during training. In contrast, ViTs show minimal interpolation ability. This indicates that ViTs are not easily generalized to unseen width ratios, implying challenges in creating efficient and flexible ViT models.

This figure shows a comparison of the performance of the US-Net method and Separate Training (ST) on Vision Transformers (ViTs) across different width ratios. The graph clearly indicates that Separate Training consistently outperforms US-Net, highlighting a significant performance gap. This gap demonstrates that directly applying the uniform slicing technique used in US-Net, which was originally developed for Convolutional Neural Networks (CNNs), does not translate effectively to the ViT architecture. The results suggest a fundamental difference in how these two network types respond to width variations, which is a key finding discussed in the paper.

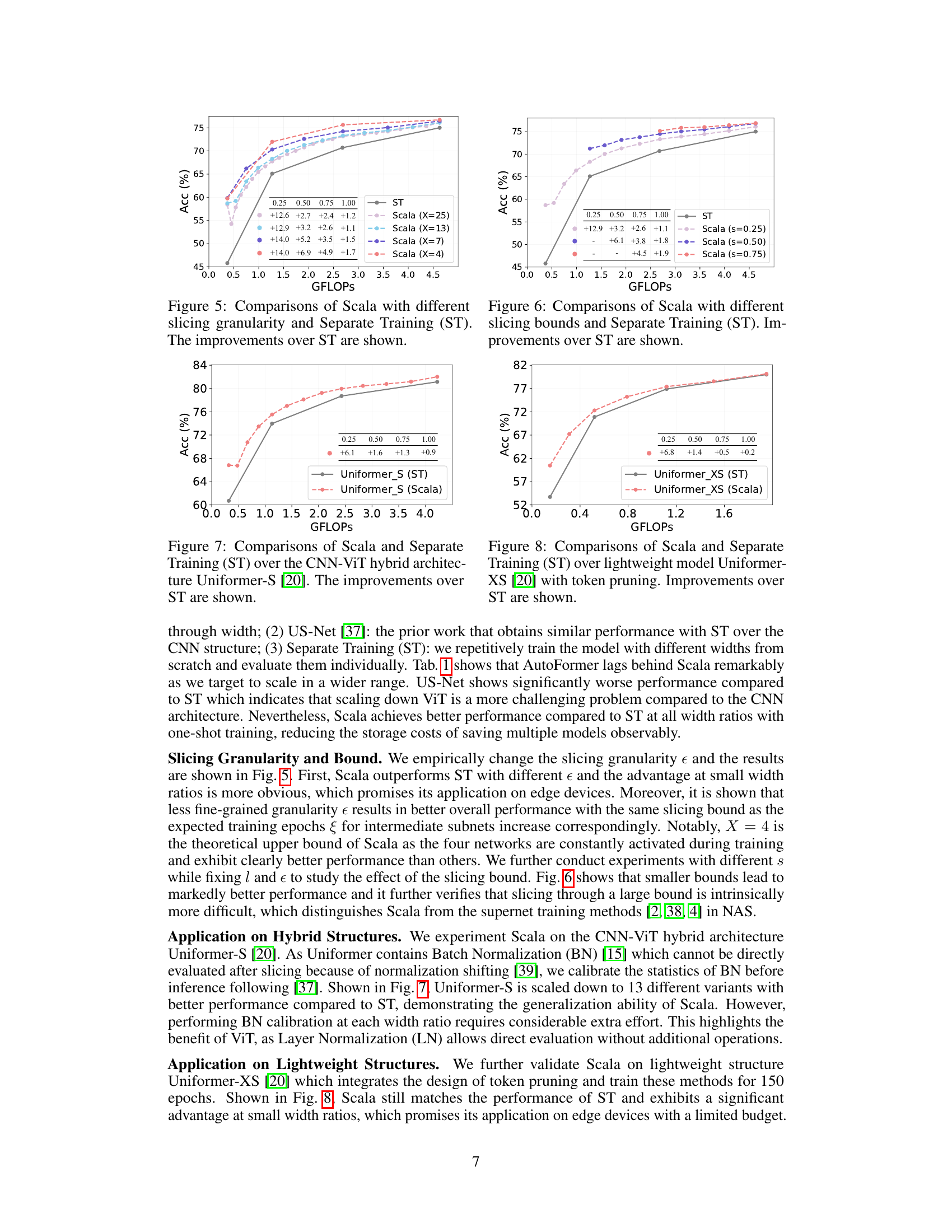
This figure compares the performance of Scala with different slicing granularities against Separate Training (ST) on the ImageNet-1K dataset. The x-axis represents the computational cost (GFLOPS), and the y-axis represents the accuracy (%). Different lines represent Scala models trained with varying numbers of sub-networks (X=4, X=7, X=13, X=25), each corresponding to a different slicing granularity. The gray line represents the performance of the baseline Separate Training method. The numbers above the lines indicate the percentage improvement in accuracy achieved by each Scala model over Separate Training at each GFLOPS point. The figure demonstrates that Scala achieves comparable or better performance than Separate Training with fewer parameters (lower GFLOPS), particularly at lower computational budgets.
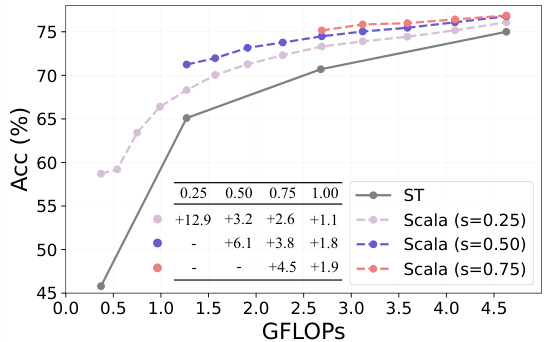
This figure compares the performance of Scala, a proposed method for training slimmable Vision Transformers, against Separate Training (ST), a traditional method. It shows that Scala outperforms ST across various model sizes (represented by GFLOPS), demonstrating its ability to efficiently produce multiple, smaller ViTs from a single trained model. Different lines represent Scala trained with different slicing granularities (the smallest sub-network width s), showcasing the effect of this hyperparameter on the overall performance. The numbers overlaid on the graph indicate the performance gain achieved by Scala over ST for each model size.

This figure compares the performance of Scala and Separate Training (ST) on the Uniformer-S architecture, a hybrid CNN-ViT model. It demonstrates that Scala consistently outperforms ST across various width ratios, showcasing its effectiveness in achieving comparable or better results with less computational cost. The improvements over ST are visually represented by the positive numbers shown above the bars.
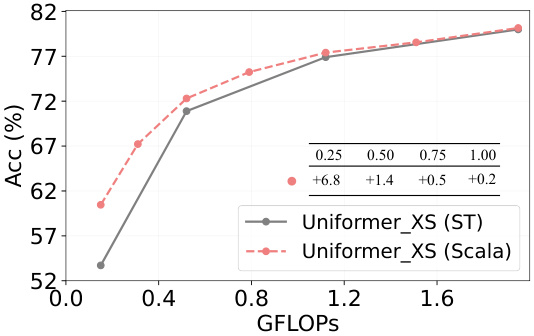
This figure compares the performance of Scala and Separate Training (ST) on the Uniformer-XS model, a lightweight model using token pruning. The x-axis represents GFLOPS (giga-floating point operations), a measure of computational cost. The y-axis shows the accuracy (Acc) in percentage. The graph plots the accuracy achieved by ST and Scala at various GFLOPS levels, achieved by changing the width ratio (r). Numerical values show the improvement in accuracy achieved by Scala over ST at specific GFLOPS levels. This illustrates that Scala achieves better performance with lower computational costs.
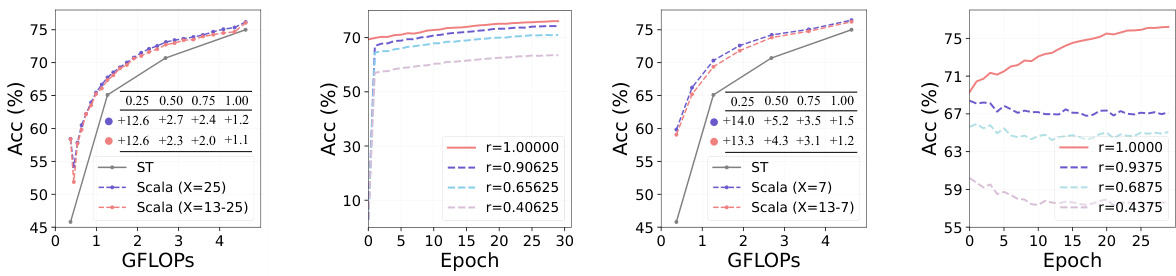
This figure compares the performance of Scala with different slicing granularities against Separate Training (ST) on ImageNet-1K. It shows accuracy results (Acc (%)) plotted against GFLOPs (floating-point operations per second), representing computational cost. Multiple lines represent different slicing granularities (X=13, X=25), and the difference in performance compared to ST is highlighted, demonstrating Scala’s efficiency and scalability with varying granularity levels.
This figure shows the transferability of Scala to video recognition tasks. The left subplot demonstrates Scala’s superior performance compared to Separate Training (ST) on the ImageNet-1K pre-training dataset across various width ratios. The right subplot further illustrates that Scala maintains its performance advantage on the UCF101 video dataset after linear probing, showcasing its adaptability to different tasks and consistent performance across multiple width ratios.
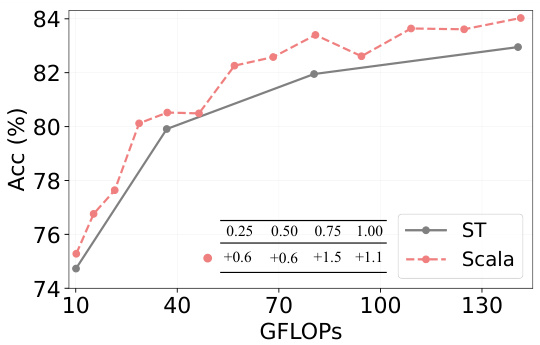
This figure compares the performance of Scala, a novel framework for training slimmable Vision Transformers, against Separate Training (ST), a traditional method. The x-axis represents the GFLOPs (floating point operations per second), a measure of computational cost, while the y-axis shows the accuracy achieved on the ImageNet-1K dataset. Different lines represent Scala models trained with varying slicing granularities (the number of sub-networks created within the main network), showcasing how Scala’s performance changes with different computational budgets. The positive numbers above each data point show the percentage improvement of Scala compared to the Separate Training method, demonstrating Scala’s effectiveness even with varying computational resources.

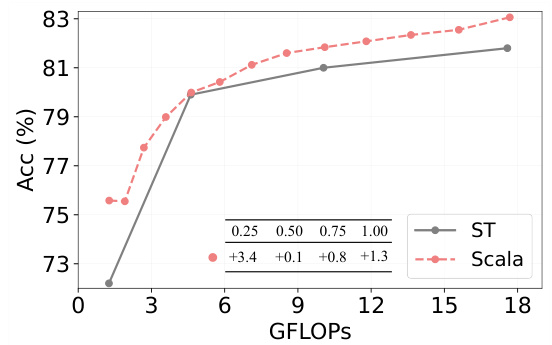
This figure shows the performance comparison between Scala and Separate Training (ST) on ImageNet-1K with DeiT-S [29] as the backbone. The x-axis represents GFLOPs, and the y-axis represents accuracy. The scaling bound of Scala is expanded from [0.25, 1.00] to [0.125, 1.000]. This figure demonstrates that Scala still outperforms ST at all width ratios, especially showing a significant advantage at the smallest ratio r = 0.125, even with the expanded scaling bound.

This figure illustrates different approaches to slicing a Vision Transformer (ViT) architecture. Irregular slicing, as shown in the leftmost example (i), involves uneven cuts across the layers of the ViT. This approach lacks the inherent structure of the ViT. In contrast, uniform slicing, as depicted in the other examples (ii), maintains the ViT’s architectural integrity and only varies the width (embedding dimension) of the network. This aligns better with how ViTs inherently scale—by varying their width.
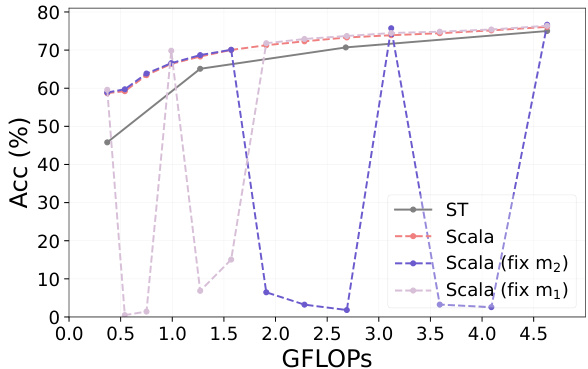
This figure shows the results of an experiment designed to test the slimmable ability of Vision Transformers (ViTs). The researchers fixed certain width ratios (m1 and m2) during training, to only optimize one sub-network at each range of width ratios. The results show that performance at unseen width ratios remains similar to the default setting even though the weights are shared, indicating that correlation between sub-networks in ViTs is weak and highlighting the challenge of making ViTs slimmable.
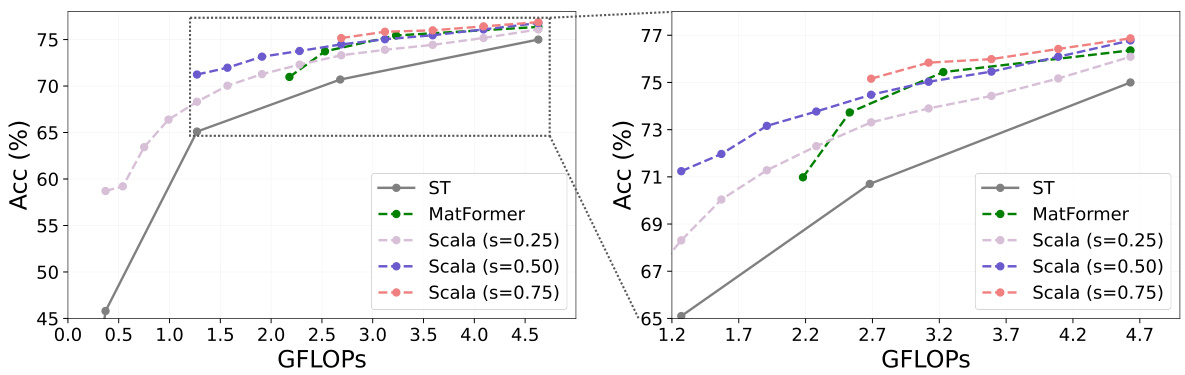
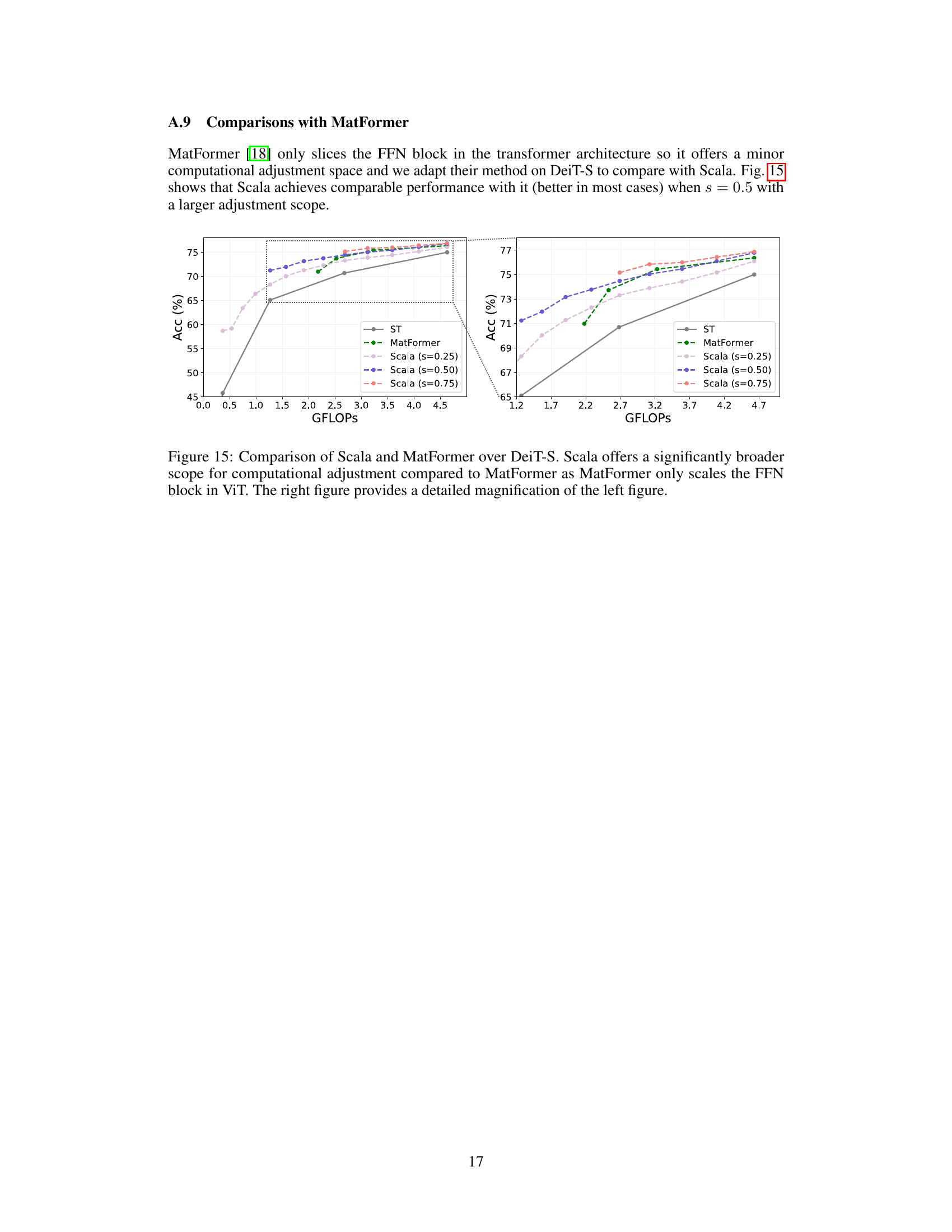
The figure compares the performance of Scala and MatFormer on DeiT-S, showing how Scala provides a significantly wider range of computational adjustments compared to MatFormer, which only scales the FFN block in ViT. The right panel shows a zoomed-in view of the left panel, highlighting the differences in performance more clearly.
More on tables

This table presents the results of evaluating the slimmable ability of different network architectures on the ImageNet-1K dataset. The architectures tested were ViT (using DeiT-S), CNN-ViT (using Uniformer-S), and CNN (using MobileNetV2). For each architecture, the top-1 accuracy is reported for various width ratios, demonstrating how well each model performs when scaled down. The blue colored numbers indicate interpolated results, highlighting the ability of the models to perform well at previously unseen width settings during inference.

This table compares the performance of Scala with the state-of-the-art method SN-Net [25] on the ImageNet-1K dataset using DeiT-B [29] as the backbone. It shows the Top-1 accuracy achieved by both methods across various width ratios (0.25 to 1.00). Two variations of Scala are presented, one using DeiT-B [29] as a teacher model (◇) and another using RegNetY-16GF [27] as a teacher model (♣) to facilitate training. The results demonstrate that Scala outperforms SN-Net in most of the width ratios and achieves a comparable performance in other ratios. The table highlights the effectiveness of Scala in achieving comparable or better results than the state-of-the-art method with fewer parameters.
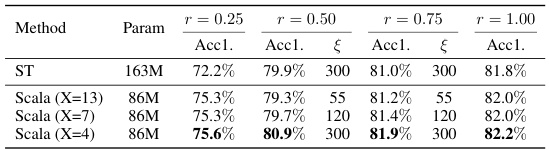
This table compares the performance of Scala and Separate Training (ST) on DeiT-B for ImageNet-1K classification. It shows accuracy (Acc1.) and the number of training epochs (§) required for different width ratios (r), representing different model sizes. The comparison highlights Scala’s efficiency in achieving comparable or better accuracy with significantly fewer training epochs than ST, especially at smaller model sizes.
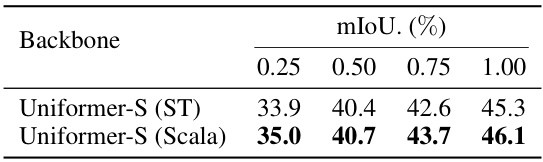
This table presents the comparison of the performance of slimmable representation on semantic segmentation task using ADE20K dataset. The backbone used is Uniformer-S, which is equipped with Semantic FPN. The results show mIoU scores for different width ratios (0.25, 0.50, 0.75, 1.00) when using both Separate Training (ST) and Scala. It demonstrates the performance of Scala compared to Separate Training across different scales.

This table presents the ablation study of the proposed method, Scala, on the ImageNet-1K dataset using the DeiT-S model. It shows the impact of removing each component of Scala (Isolated Activation, Progressive Knowledge Transfer, Stable Sampling, and Noise Calibration) on the top-1 accuracy at various width ratios (0.25, 0.375, 0.50, 0.625, 0.75, 0.875, 1.00). The results highlight the contribution of each component to the overall performance of Scala.

This table compares the performance of training a DeiT-S model from scratch versus fine-tuning a pre-trained model using the Scala method. The results are shown for different width ratios (0.25, 0.50, 0.75, 1.00), representing different model sizes. The ‘Scratch’ row represents training a model from random initialization while the ‘Fine-tune’ row shows the results of fine-tuning a pre-trained model. The table demonstrates that training from scratch significantly outperforms fine-tuning, especially for smaller models.
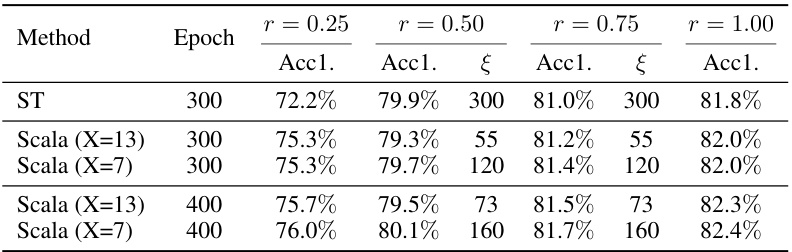
This table compares the performance of Scala and Separate Training (ST) on the DeiT-B model for ImageNet-1K classification. It shows the accuracy (Acc1.) achieved by each method at different width ratios (r = 0.25, 0.50, 0.75, 1.00) and training epochs. § represents the expected training epochs for each model, showing Scala’s efficiency in requiring fewer epochs to achieve comparable or better results than ST.

This table presents the ablation study results of the Scala model on the ImageNet-1K dataset using DeiT-S. The study examines the impact of four key components of the Scala framework: Isolated Activation (IA), Progressive Knowledge Transfer (PKT), Stable Sampling (SS), and Noise Calibration (NC). Each row represents a variant of the Scala model with one component removed. The Top-1 accuracy is reported for various width ratios (0.25 to 1.00), showing the contribution of each component to the overall performance. Boldfaced values indicate the best performance for each width ratio.

This table compares the performance of Scala against three baseline methods: AutoFormer, US-Net, and Separate Training. The comparison is made across four different width ratios (r = 0.25, 0.50, 0.75, 1.00) representing different model sizes. For each method and width ratio, the table shows the top-1 accuracy (Acc1), the number of parameters (Param), the number of training epochs (ξ), and the number of GFLOPS. The best result for each width ratio is shown in bold.

This table compares the training time (in hours) required for three different methods to train 13 models: Separate Training, US-Net, and Scala. Separate Training trains each model separately, resulting in the longest training time. US-Net and Scala are more efficient, with Scala showing a slightly longer training time than US-Net.
Full paper#