↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-language tracking (VLT) has emerged as a promising approach to object tracking by incorporating textual descriptions along with visual information. However, existing VLT models mostly rely on fixed multimodal prompts at the start, leading to poor performance when the target’s appearance changes over time. This reliance on initial static prompts significantly limits the tracker’s ability to adapt to dynamic scenarios. This is especially challenging when the target’s appearance changes dramatically or is obscured.
To overcome this challenge, this paper introduces MemVLT, a novel vision-language tracker that incorporates a memory-based system. MemVLT effectively models human memory by using a combination of short-term and long-term memory modules to dynamically adjust the prompts used for tracking. Extensive experiments demonstrate that MemVLT achieves state-of-the-art performance on several benchmark datasets, significantly outperforming existing methods and highlighting the effectiveness of incorporating memory mechanisms in VLT.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MemVLT, a novel vision-language tracking model that significantly outperforms existing methods. Its use of adaptive memory-based prompts addresses the limitations of traditional trackers that rely on static prompts, opening up new avenues for research in dynamic target tracking. This work is highly relevant to the current trend of incorporating multimodal information into computer vision tasks and will likely inspire further research on memory-augmented tracking methods.
Visual Insights#

This figure illustrates the limitations of existing vision-language tracking (VLT) methods and introduces the proposed MemVLT approach. Subfigure (a) shows a video sequence and plots showing the decreasing consistency between initial prompts and the actual target over time. This highlights the problem that VLT methods rely on fixed initial multimodal prompts, which are ineffective for dynamically changing targets. Subfigure (b) illustrates the framework of previous VLT methods, which primarily use similarity matching between the search image and the initial prompts. Subfigure (c) shows the MemVLT framework, which incorporates memory modeling based on the Complementary Learning Systems (CLS) theory to generate adaptive prompts for tracking, addressing the shortcomings of previous methods. The adaptive prompts effectively guide the tracking process by leveraging the storage and interaction of short-term and long-term memories.

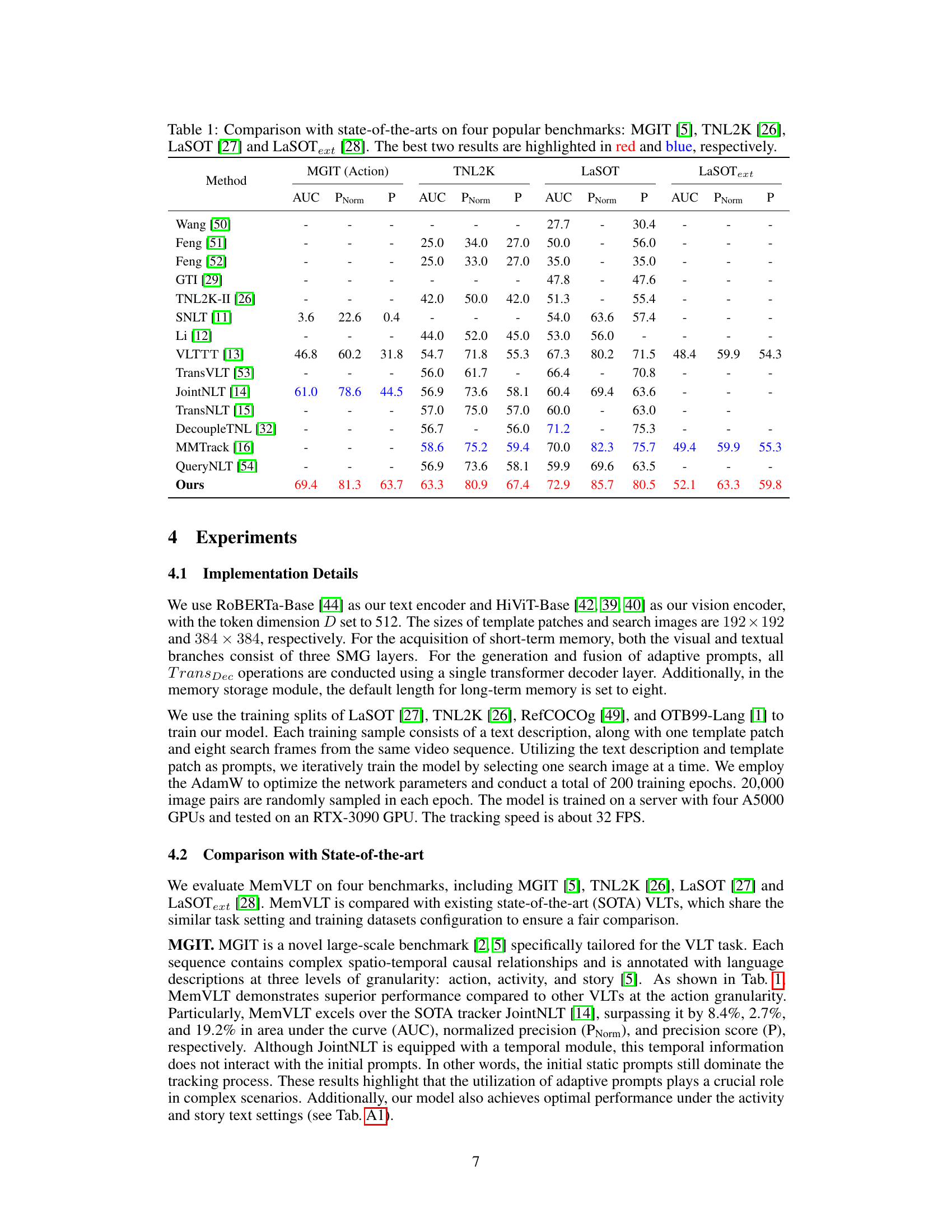
This table compares the performance of the proposed MemVLT model against other state-of-the-art methods on four benchmark datasets for vision-language tracking. The metrics used for comparison are AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The datasets are MGIT (which focuses on complex spatio-temporal relationships), TNL2K (which includes challenging scenarios like adversarial samples and modality switches), LaSOT (a large-scale dataset for long-term tracking), and LaSOText (an extension of LaSOT with language annotations). The table highlights the superior performance of MemVLT, particularly on MGIT and TNL2K, indicating its ability to handle complex and dynamic tracking challenges.
In-depth insights#
Adaptive Prompts#
The concept of “Adaptive Prompts” in the context of vision-language tracking is a significant advancement. Instead of relying on static, initial prompts that quickly become outdated as the target object changes appearance or context, adaptive prompts dynamically adjust. This adjustment is crucial because object appearances change dramatically during video sequences. The core idea is to leverage memory mechanisms, potentially drawing inspiration from the Complementary Learning Systems theory, to maintain and update prompt information. This approach uses memory to track the evolution of the target’s appearance, allowing the tracking process to adapt to variations and maintain accuracy. This contrasts sharply with traditional methods that rely heavily on the fixed initial prompts and often struggle with significant target transformations. Adaptive prompts represent a paradigm shift, improving robustness and potentially achieving state-of-the-art performance. The implementation of such a system likely involves sophisticated memory modules, incorporating mechanisms to integrate both short-term and long-term memory information. Successful implementation requires carefully designing methods for storing, updating and interacting with this memory information, such that prompt adjustments are relevant and timely. This strategy holds immense potential for other computer vision tasks dealing with dynamic and changing scenes.
Memory Modules#
Memory modules are crucial for adapting to dynamic changes in visual-language tracking. The paper highlights the importance of short-term and long-term memory interaction, drawing a parallel to the Complementary Learning Systems theory. The design of the memory modules cleverly emulates this interaction, enabling the tracker to store and retrieve relevant visual and textual information. Adaptive prompts are generated by combining static prompts with the information extracted from memory, thus adjusting the tracking strategy according to target variations. This adaptive mechanism, inspired by human memory processes, is a key innovation and is shown to significantly improve tracking performance, overcoming the limitations of trackers relying solely on fixed initial prompts. The method for storing long-term memory is also noteworthy, using a section-top approach that stores only the most informative short-term memories, thereby improving efficiency and avoiding redundancy.
CLS Theory in VLT#
The integration of Complementary Learning Systems (CLS) theory into Vision-Language Tracking (VLT) offers a novel perspective on handling the dynamic nature of visual targets. CLS theory’s core tenet, the interaction between short-term and long-term memory systems, directly addresses VLT’s challenge of maintaining consistent target identification despite significant appearance changes. By mimicking the hippocampus (short-term) and neocortex (long-term) memory mechanisms, a VLT model can adapt prompts, incorporating new visual and linguistic information to guide tracking. This adaptive prompting system is crucial for VLT because initial static prompts frequently become insufficient as the target undergoes changes in pose, lighting, or surrounding environment. The resulting adaptive prompts enhance robustness and accuracy by continuously refining the target representation rather than relying solely on the initial, potentially outdated, information.
MemVLT: SOT extension#
MemVLT, as a SOT extension, leverages the power of language to enhance traditional visual object tracking. This multimodal approach addresses the limitations of SOT by incorporating language descriptions, enabling the tracker to adapt to dynamic target variations and complex scenes that would challenge a purely visual system. The key innovation lies in adaptive memory-based prompts, moving beyond the fixed initial cues used in many existing VLT methods. By dynamically updating prompts using a memory model inspired by the Complementary Learning Systems theory, MemVLT maintains consistent tracking despite significant target changes. This adaptive mechanism is a substantial improvement over previous methods that relied heavily on static prompts, resulting in significantly better tracking performance, as demonstrated in experimental results. However, future work could explore more sophisticated memory interactions and further examine the model’s generalization to less-controlled environments or noisy data.
Future Research#
Future research directions stemming from this vision-language tracking (VLT) paper, MemVLT, could explore several key areas. Improving the robustness of the adaptive prompt generation mechanism is crucial, especially in handling significant target appearance changes and challenging environmental conditions. The model’s reliance on initial prompts could be addressed by investigating alternative methods for initializing the tracker. Further investigation into the interaction between short-term and long-term memory is warranted, potentially drawing inspiration from more sophisticated memory models used in cognitive science. Exploring different memory storage strategies beyond the section-top method presented here could significantly improve efficiency and accuracy. Finally, extending the approach to handle multiple objects or more complex tracking scenarios, such as those found in real-world applications, will be important for translating this research into practical use. These improvements would significantly enhance the model’s adaptability and performance in challenging situations.
More visual insights#
More on figures
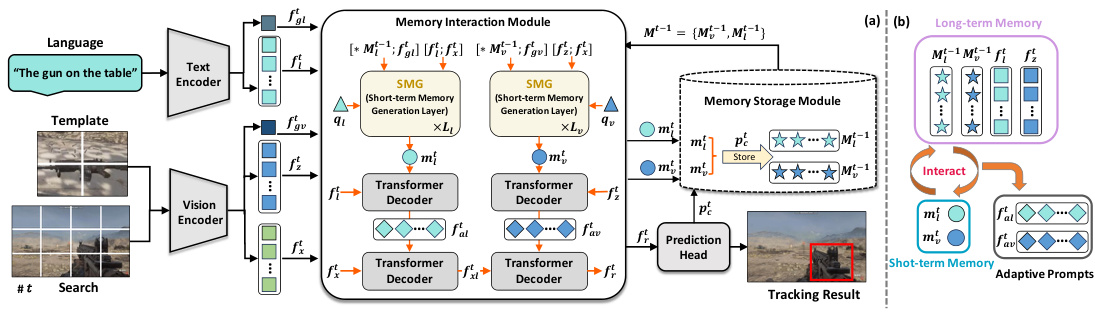
This figure shows the overall architecture of the proposed MemVLT model. It consists of two main parts: the memory interaction module and the memory storage module. The memory interaction module takes encoded visual and textual features, along with previously stored memory, and generates adaptive prompts for the tracker. These adaptive prompts are then integrated with the current search features to produce a prediction. The memory storage module is responsible for storing and managing short-term and long-term memory representations to allow for adaptation to changes in the target over time. Subfigure (b) provides a closer look at how the memory interaction module works, highlighting the interplay between short-term and long-term memories.

This figure shows the heatmaps generated during the tracking process by MemVLT. Subfigures (a)-(c) illustrate the heatmaps when adaptive prompts (generated by the memory interaction module) are integrated. Subfigure (d) shows the heatmap when only the initial fixed prompts are used. The process diagrams illustrate the feature integration sequence. Bounding boxes of the tracked results and ground truth are also shown. Figure 4 shows the comparison of the confidence score generated by the prediction head and the Intersection over Union (IoU) values of the ground truth and tracked results in a sample video sequence, showing a close relationship between the two.

This figure shows a qualitative comparison of the proposed MemVLT tracker with two other state-of-the-art trackers (JointNLT and MMTrack) on three challenging video sequences from the TNL2K benchmark. Each row represents a different sequence, and each column shows the tracking results at different frames. The first column displays the initial template provided to the trackers. The remaining columns illustrate the tracking results of MemVLT, JointNLT, and MMTrack, highlighting the performance differences in handling challenging scenarios. The ground truth bounding boxes are shown in green. MemVLT demonstrates better performance in adapting to target variations and dealing with distractions.
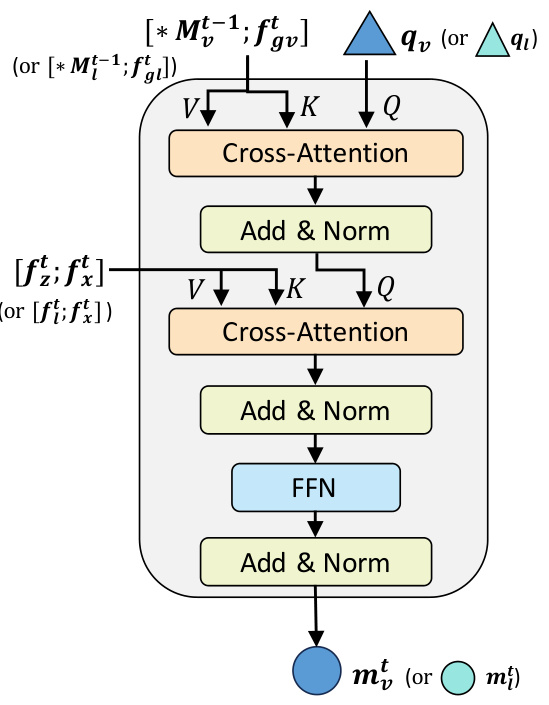
This figure illustrates the architecture of MemVLT, a memory-based vision-language tracker. Panel (a) shows the overall framework: the input (search image, template, language description) is processed by encoders, then a Memory Interaction Module (MIM) generates adaptive prompts based on short-term and long-term memory. Finally, a prediction head outputs the tracking result. Panel (b) details the MIM, showing how long-term and short-term memories interact to generate the adaptive prompts.

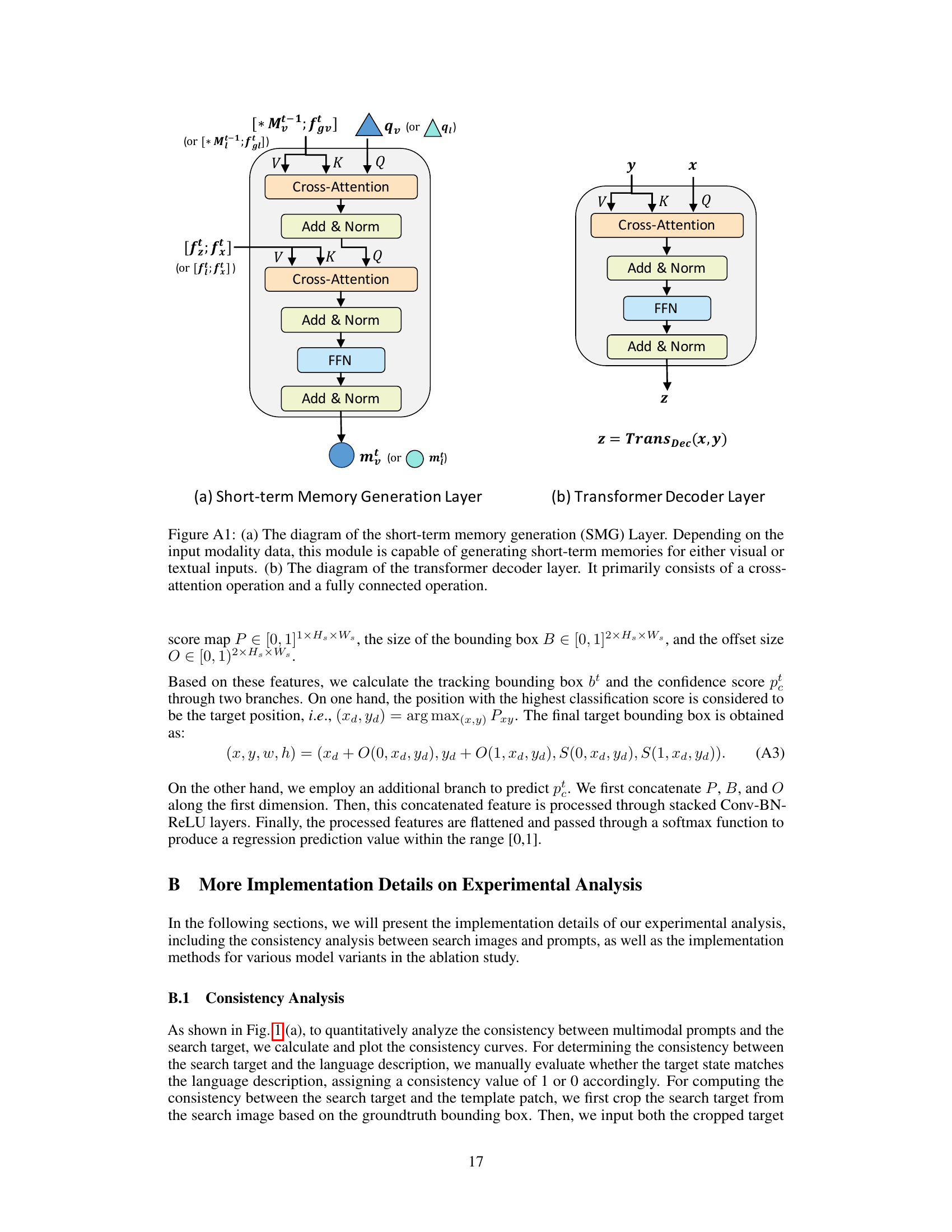
This figure shows the architecture of two important modules in the MemVLT model: the short-term memory generation layer and the transformer decoder layer. The short-term memory generation layer takes as input either visual or textual data and generates short-term memories. The transformer decoder layer is a standard transformer decoder that uses cross-attention and feed-forward networks to process the input data. Together, these modules allow the MemVLT model to effectively interact with both long-term and short-term memories.

This figure shows the architecture of MemVLT, a memory-based vision-language tracker. Panel (a) illustrates the overall framework, showing how text and vision encoders process inputs, a memory interaction module generates adaptive prompts, and a prediction head produces tracking results. Panel (b) zooms in on the memory interaction module, illustrating the interplay between short-term and long-term memories to create these adaptive prompts.
More on tables
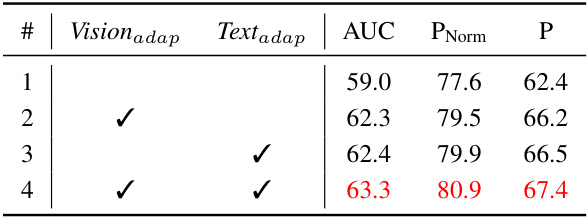
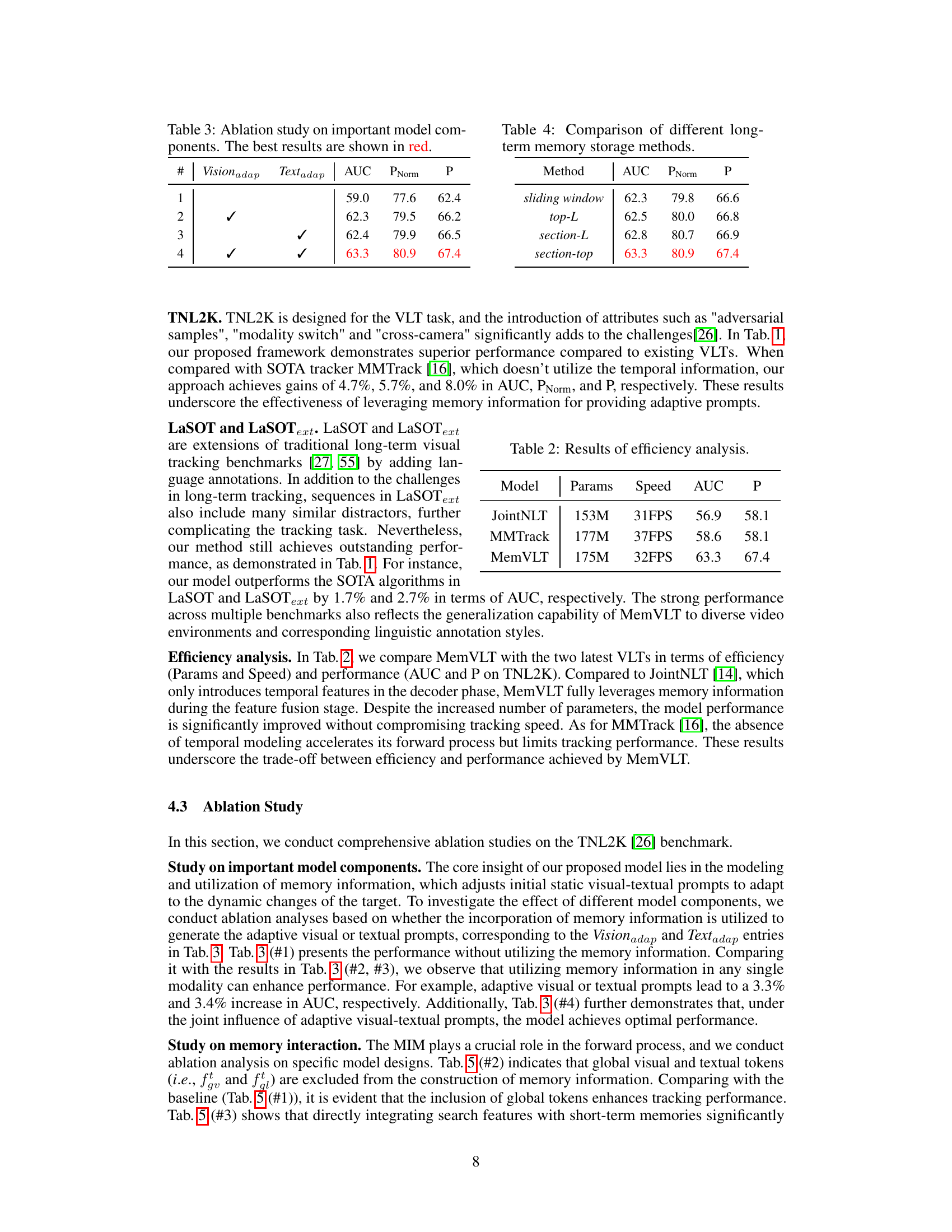
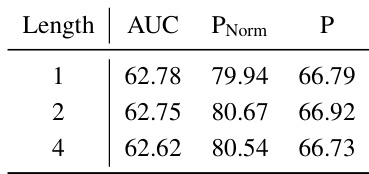
This table presents the results of an ablation study conducted to evaluate the impact of different model components on the overall performance. Specifically, it investigates the contribution of incorporating memory information (visual and textual) to generate adaptive prompts, a key feature of the MemVLT model. The table shows the AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision) metrics for four different configurations: (1) no adaptive prompts; (2) adaptive visual prompts only; (3) adaptive textual prompts only; and (4) both adaptive visual and textual prompts. The best performing configuration, with both types of adaptive prompts, is highlighted in red, demonstrating their combined effectiveness in improving the model’s performance.
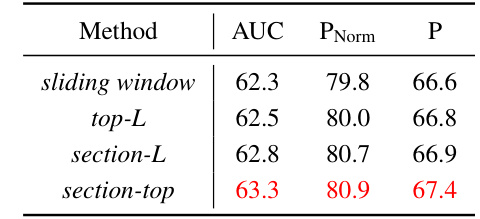
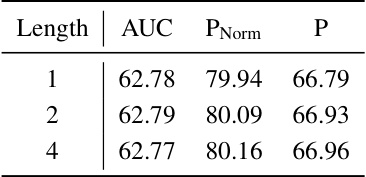
This table compares the performance of four different long-term memory storage methods: sliding window, top-L, section-L, and section-top. The comparison is based on the AUC, PNorm, and P metrics on the TNL2K benchmark. The results show that the section-top method outperforms the others, demonstrating the effectiveness of the proposed method in storing and utilizing memory information for accurate tracking.
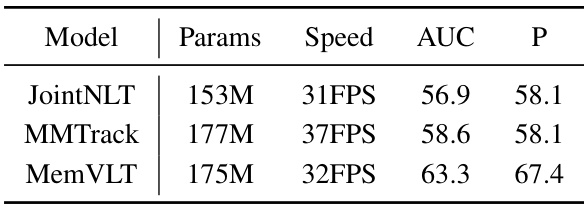
This table compares three vision-language tracking models (JointNLT, MMTrack, and MemVLT) in terms of their efficiency and performance on the TNL2K benchmark. Efficiency is measured by the number of parameters (Params) and frames per second (Speed). Performance is measured by the area under the curve (AUC) and precision (P). MemVLT shows improved performance with a comparable speed and parameter count to the others.
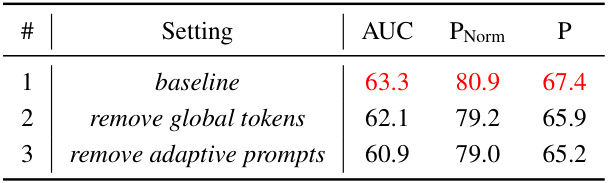
This table presents the ablation study results focusing on the impact of different model components on the overall performance. It shows the performance variations when removing the adaptive visual prompts, the adaptive textual prompts, or both, from the MemVLT model. The results demonstrate the significance of adaptive prompts in improving the model’s accuracy and precision.
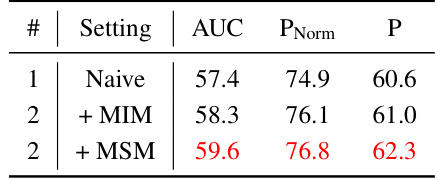
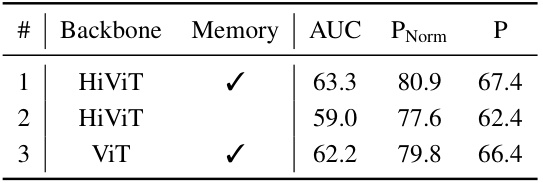
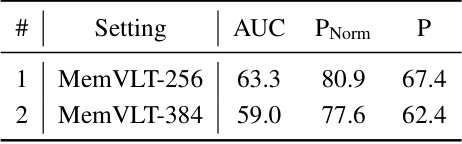
This table presents an ablation study evaluating the generalizability of the proposed MemVLT’s memory mechanism to standard single object tracking (SOT) tasks. It compares the performance of a naive SOT model against versions incorporating the Memory Interaction Module (MIM) and the Memory Storage Module (MSM). The results demonstrate the positive impact of MemVLT’s memory components on SOT performance, suggesting that the adaptive prompting mechanism generalizes well beyond vision-language tracking.

This table compares the performance of the proposed MemVLT model against other state-of-the-art methods on four popular vision-language tracking benchmarks: MGIT, TNL2K, LaSOT, and LaSOText. The metrics used for comparison include AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The best two results for each metric on each benchmark are highlighted in red and blue for easy comparison. This provides a quantitative assessment of MemVLT’s performance relative to existing techniques.

This table compares the performance of the proposed MemVLT model against other state-of-the-art methods on four benchmark datasets for vision-language tracking (VLT). The metrics used for comparison are AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The table highlights the superior performance of MemVLT, especially on MGIT and TNL2K datasets, where it achieves significant improvements over existing methods.
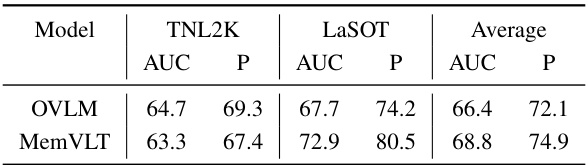
This table presents a comparison of the MemVLT model’s performance against other state-of-the-art models on four benchmark datasets for vision-language tracking: MGIT, TNL2K, LaSOT, and LaSOText. The metrics used for comparison are AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The table highlights the superior performance of MemVLT, especially on MGIT and TNL2K, by showing improvements over existing best results.
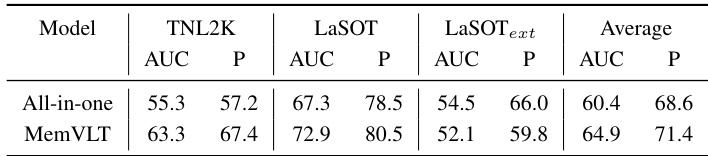
This table compares the performance of the proposed MemVLT model against other state-of-the-art vision-language tracking (VLT) models on four benchmark datasets: MGIT, TNL2K, LaSOT, and LaSOText. The comparison is done using AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision) metrics. The best two performing models for each metric on each dataset are highlighted in red and blue for easy identification. This table showcases MemVLT’s improved accuracy over existing VLT models.

This table compares the performance of the proposed MemVLT model against other state-of-the-art vision-language tracking models on four benchmark datasets: MGIT, TNL2K, LaSOT, and LaSOText. It shows the AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision) scores for each method on each dataset. The best two performing models for each metric on each dataset are highlighted in red and blue for easy comparison and to demonstrate the effectiveness of MemVLT. The table shows that MemVLT achieves state-of-the-art performance on these datasets, outperforming the existing best results by a significant margin.
This table presents a comparison of the MemVLT model’s performance against other state-of-the-art models on four widely used vision-language tracking benchmarks: MGIT, TNL2K, LaSOT, and LaSOText. For each benchmark and each metric (AUC, PNorm, P), the table shows the performance of various models. The best two performing models for each metric are highlighted in red and blue, respectively, clearly showing MemVLT’s superior performance.
This table compares the performance of the proposed MemVLT model against several state-of-the-art vision-language tracking (VLT) methods on four widely used benchmark datasets: MGIT, TNL2K, LaSOT, and LaSOText. The metrics used for comparison are AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The table highlights the superior performance of MemVLT, especially on MGIT and TNL2K, where it achieves significant improvements compared to the existing best results.
This table compares the performance of MemVLT against other state-of-the-art (SOTA) methods on four benchmark datasets for vision-language tracking (VLT): MGIT, TNL2K, LaSOT, and LaSOText. It presents results using several metrics, including AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The best two results for each metric on each dataset are highlighted to easily compare the performance of MemVLT with other approaches.
This ablation study analyzes the impact of different model components on the performance of MemVLT, specifically focusing on whether the incorporation of memory information is used to generate adaptive visual or textual prompts. It compares the model’s performance when using memory information for only visual prompts, only textual prompts, both visual and textual prompts, and no adaptive prompts at all. The results highlight the importance of the memory interaction module in achieving optimal performance.

This table compares the performance of MemVLT against other state-of-the-art vision-language tracking methods on four benchmark datasets: MGIT, TNL2K, LaSOT, and LaSOText. The metrics used are AUC (Area Under the Curve), PNorm (Normalized Precision), and P (Precision). The table highlights MemVLT’s superior performance, particularly on MGIT and TNL2K, demonstrating improvements over existing best results.
Full paper#