↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating images of specific domains (e.g., an artist’s unique style) with limited data is challenging for existing text-to-image models. Previous methods struggle to finetune these models effectively, leading to issues like overfitting and difficulty capturing subtle domain characteristics. The reliance on finding suitable source datasets for transfer learning also limits their applicability.
This paper introduces DomainGallery, a novel few-shot domain-driven image generation method. It tackles these challenges using four key attribute-centric finetuning techniques: prior attribute erasure, attribute disentanglement, regularization, and enhancement. Experiments demonstrate DomainGallery’s superiority over existing methods, achieving improved performance across various generation scenarios (intra-category, cross-category, extra-attribute addition, and personalization).
Key Takeaways#
Why does it matter?#
This paper is important because it presents DomainGallery, a novel method for few-shot domain-driven image generation, addressing limitations of previous approaches. It offers attribute-centric finetuning techniques that improve image generation in various scenarios, opening new avenues for research in personalized and diverse image synthesis.
Visual Insights#

This figure illustrates the four scenarios where DomainGallery excels: intra-category, cross-category, extra attribute, and personalization. It showcases how DomainGallery, given a few examples (few-shot learning), can generate images that match a particular artistic style (sketches), going beyond what standard text-to-image models can achieve. Sub-figures (a) through (f) demonstrate DomainGallery’s capability in these scenarios.

This table presents a quantitative comparison of different image generation methods on five datasets for intra-category image generation. The metrics used are FID (Fréchet Inception Distance) and I-LPIPS (Learned Perceptual Image Patch Similarity) to assess image quality, and KID (Kernel Inception Distance) to measure diversity. Lower FID and I-LPIPS scores indicate better image quality, while lower KID scores show better image diversity. The table highlights the superior performance of the proposed DomainGallery method compared to baselines such as DreamBooth and DomainStudio, particularly in terms of balancing image quality and diversity.
In-depth insights#
Few-shot Challenge#
The few-shot learning challenge in the context of image generation highlights the difficulty of training effective models with limited data. Traditional deep learning approaches require massive datasets, posing significant hurdles for domains where obtaining large quantities of labeled images is expensive, time-consuming, or simply impossible. Few-shot methods aim to address this limitation by leveraging techniques such as meta-learning, transfer learning, and data augmentation to maximize the information extracted from the scarce training examples. A key challenge lies in generalizing well to unseen data, avoiding overfitting to the small training set and maintaining robustness in the face of variations in style, content, or other image characteristics. Successfully addressing the few-shot challenge is crucial for advancing applications in specialized domains, such as medical imaging, satellite imagery, or artistic style transfer, where acquiring vast quantities of training data proves unrealistic.
Attribute-centric Finetuning#
Attribute-centric finetuning, as a method, presents a novel approach to few-shot domain-driven image generation. Instead of treating a domain as a monolithic entity, it focuses on disentangling and manipulating individual attributes that define the domain’s visual characteristics. This granular control allows for more precise control over the generation process, enabling diverse outputs. Prior attribute erasure is crucial, preventing unwanted characteristics from previous training data from interfering with the newly acquired attributes. Then, attribute disentanglement ensures that attributes are cleanly separated, avoiding leakage and improving the overall quality of generated images. Regularization techniques address potential overfitting issues that can arise when fine-tuning with limited data. Finally, the process can be enhanced to further improve the fidelity of generated images. This meticulous, attribute-focused approach offers significant improvements over traditional domain adaptation methods, enabling superior performance in intra-category, cross-category, and personalization scenarios.
Domain-driven Approach#
A domain-driven approach to image generation centers on adapting pre-trained models to specific domains using limited data. This contrasts with traditional approaches that require massive datasets. The core idea is to leverage the inherent knowledge of a pre-trained model and fine-tune it to capture the nuances of a particular domain, such as the style of a specific artist or a particular type of object. This technique addresses the challenge of generating images in visually unique or niche domains where sufficient training data is scarce. Key advantages include improved fidelity, efficient use of resources, and generation of images consistent with the desired domain style. However, challenges include effective transfer of learned attributes, preventing overfitting with limited data, and preserving the diversity of generated samples. Successful implementation demands careful consideration of attribute selection, disentanglement, regularization, and techniques to avoid unexpected artifacts or loss of desired traits. The attribute-centric nature of the approach holds promise for highly customized image generation, especially for personalization and cross-category generation scenarios.
Ablation Study Results#
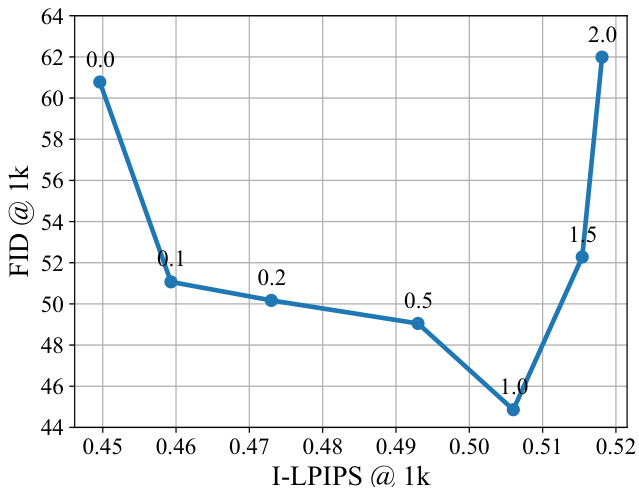
An ablation study for a research paper would systematically remove individual components or techniques to assess their contribution to the overall performance. The results section would then present a quantitative comparison, perhaps using tables and figures, showing the impact of each ablation. Key observations would focus on the relative importance of each component, revealing which are crucial for success and which are less impactful. For instance, removing a crucial regularization technique might lead to significant performance degradation, while omitting a less vital preprocessing step might only cause a minor drop. The analysis should go beyond simple performance metrics; it should discuss the insights gained regarding the interplay between different components and the overall methodology. For example, an ablation study might reveal unexpected interactions between components, or highlight the robustness of certain techniques against modifications or removal of others. Ultimately, a well-executed ablation study provides strong evidence supporting the paper’s claims by demonstrating the necessity of each included element and shedding light on the system’s behavior as a whole. Clearly presented ablation study results are crucial for establishing confidence in the proposed method and solidifying the paper’s scientific contribution.
Future Research#
Future research directions stemming from this work on few-shot domain-driven image generation could explore several promising avenues. Extending DomainGallery to handle datasets with images spanning multiple categories is crucial for broader real-world applicability. Addressing the challenge of defining and identifying subtle domain attributes in complex datasets, perhaps through automated attribute extraction techniques, is key. Furthermore, developing more robust methods for handling conflicting attributes in prompts would improve generation fidelity and control. Investigating alternative finetuning strategies beyond LoRA to potentially enhance efficiency and performance is worthwhile. Finally, a significant area for advancement is evaluating DomainGallery’s performance across a wider range of domains and datasets, rigorously comparing it against future methods and establishing clear benchmarks for the field.
More visual insights#
More on figures

This figure illustrates the pipeline of DomainGallery, which consists of three main steps: prior attribute erasure, finetuning, and inference. In the prior attribute erasure step, the model is trained to remove prior attributes associated with the identifier [V] before finetuning. The finetuning step involves training the model on the target dataset while incorporating additional losses such as domain-category attribute disentanglement and transfer-based similarity consistency loss. Finally, during inference, the model generates images by enhancing the domain attributes of [V] using a classifier-free guidance (CFG) approach. The dashed arrows in the figure denote gradient stopping.

This figure shows the results of intra-category image generation on the CUFS sketches dataset. The left panel displays the 10-shot dataset used for fine-tuning. The right panel presents images generated by different methods: DreamBooth, DreamBooth+LoRA, DomainStudio, and the proposed DomainGallery. All methods used the prompt ‘a [V] face’ to generate images in the style of the dataset. This allows for a visual comparison of the methods’ ability to reproduce the artistic style and features of the original sketches.

This figure illustrates the capabilities of DomainGallery for few-shot domain-driven image generation. It demonstrates the model’s ability to generate images within a specific style or domain, even when limited training data is available. The image showcases several scenarios (intra-category, cross-category, extra attribute, personalization) to highlight the model’s flexibility and versatility. (a) shows a few-shot target dataset, (b) depicts failure of a pre-trained model, and (c) to (f) show successful results of DomainGallery.

This figure demonstrates the capabilities of DomainGallery in generating images with extra attributes. The top row showcases intra-category generation, where the generated images belong to the same category as the input dataset (CUFS sketches). The middle row shows cross-category generation, where the generated images are of different categories than the input dataset but still maintain the domain-specific style. The bottom row illustrates a scenario where conflicting attributes are present in the text prompt, resulting in images that blend both attributes.

This figure demonstrates the personalization capability of DomainGallery. It shows two examples: one using a dataset of Corgi dogs and another using a dataset of vases. For each example, the leftmost images show the few-shot subject dataset used for finetuning. The subsequent images show the results of generating images with different prompts, demonstrating the ability to generate images that combine both domain-specific style and subject-specific characteristics. This highlights the method’s ability to personalize generated images within the given domain.

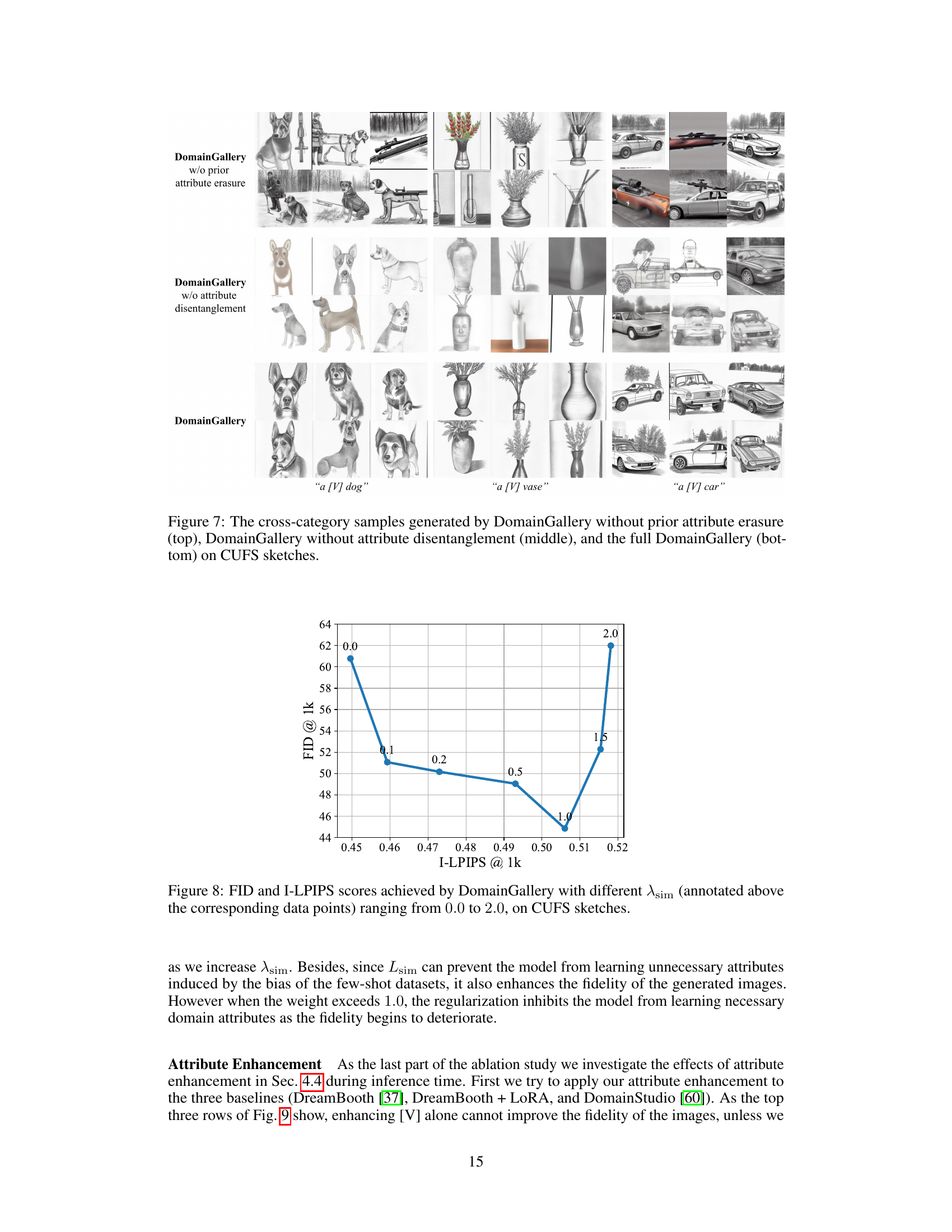
This figure shows the results of cross-category image generation experiments using three different versions of the DomainGallery model. The top row shows results from a model without prior attribute erasure, where unintended attributes appear in the generated images. The middle row displays results from a model without attribute disentanglement, showing a leakage of attributes between the identifier [V] and category [N]. The bottom row illustrates results from the complete DomainGallery model, demonstrating improved performance and successful separation of attributes.
This figure provides a visual overview of the DomainGallery pipeline, which consists of three main steps: (a) Prior Attribute Erasure, where prior attributes associated with the identifier [V] are removed; (b) Finetuning, which involves training on target datasets and applying additional loss functions (Ldisen and Lsim) to improve the model’s performance; and (c) Attribute Enhancement, which enhances domain attributes during inference for cross-category image generation. The diagram uses different colors and shapes to represent various UNet components, LoRA parameters, and loss functions, highlighting the interplay between these elements.
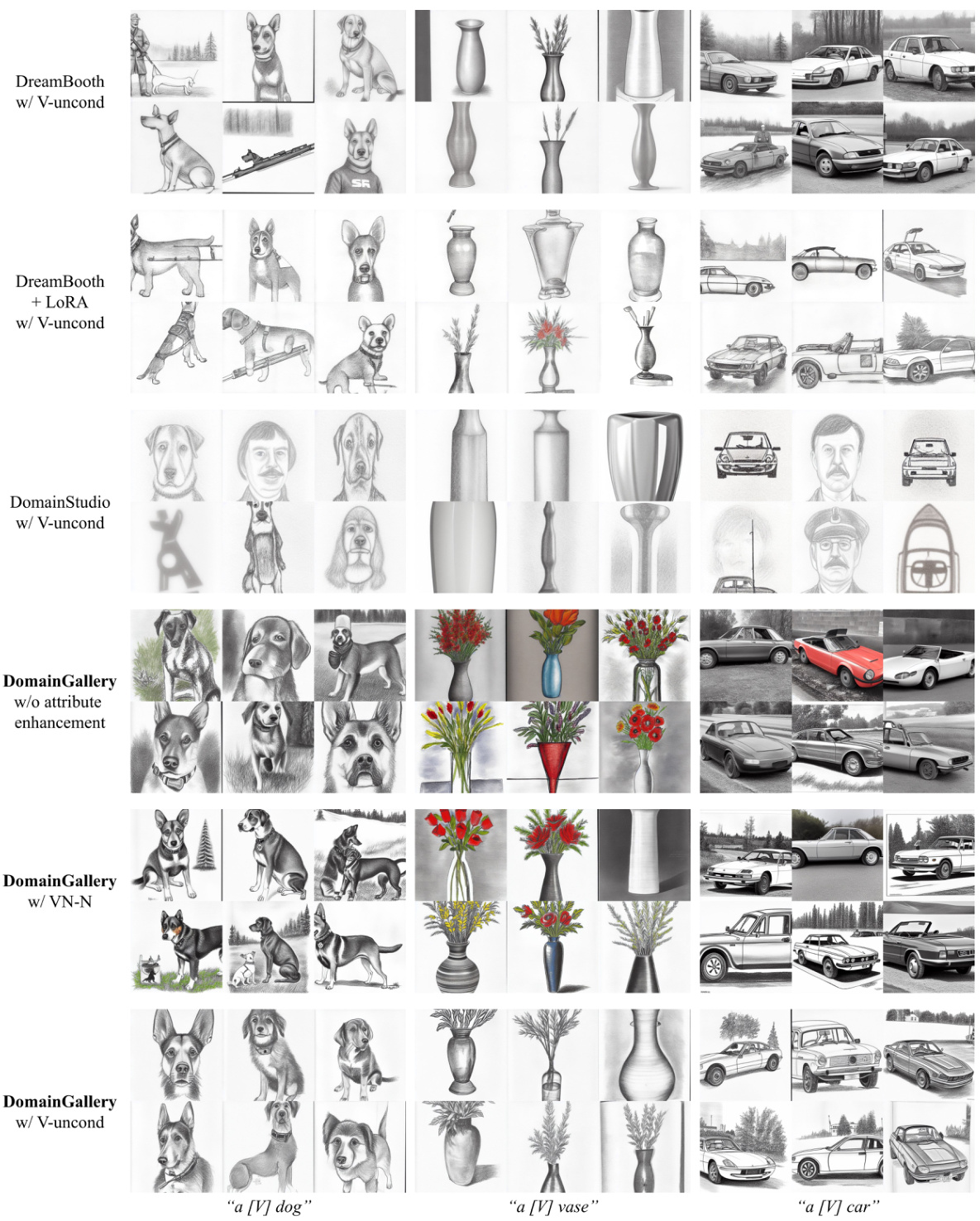
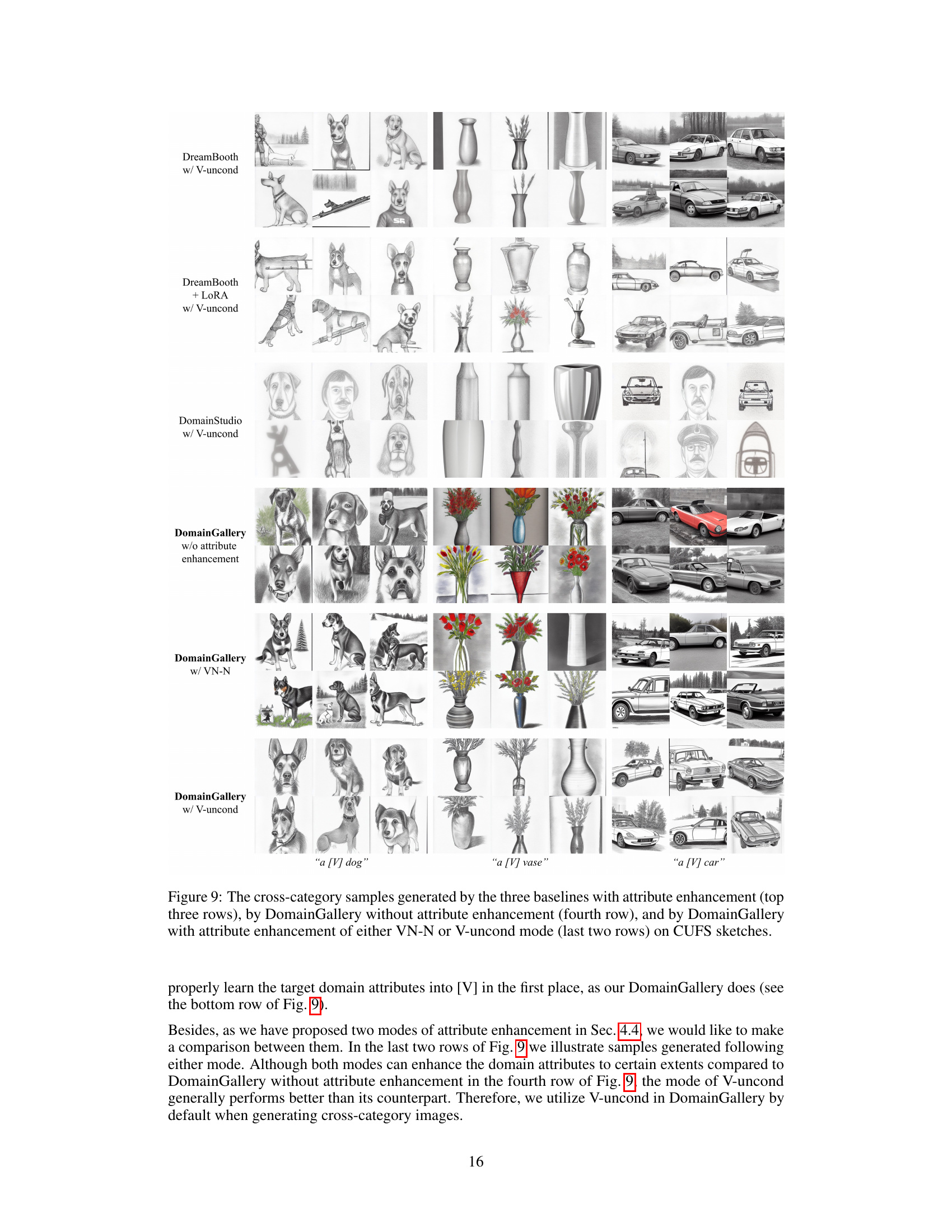
This figure compares the cross-category image generation results of different methods. The top three rows show the results of three baselines (DreamBooth, DreamBooth+LoRA, and DomainStudio) with attribute enhancement. The fourth row shows the results of DomainGallery without attribute enhancement. The last two rows show the results of DomainGallery with two different attribute enhancement modes (VN-N and V-uncond). All results are generated using CUFS sketches dataset.

This figure shows a comparison of image generation results between the proposed DomainGallery method and baseline methods (DreamBooth, DreamBooth+LoRA, and DomainStudio) on four different datasets. Each dataset contains 10 images representing a specific domain (FFHQ sunglasses, Van Gogh houses, watercolor dogs, and wrecked cars). The left side displays the original 10 images from each dataset, while the right displays images generated using different methods, all prompted with the text corresponding to the domain (e.g., ‘a [V] face’ for the sunglasses dataset). The comparison aims to demonstrate DomainGallery’s superior ability to generate images that accurately reflect the style and characteristics of each specific domain.

This figure shows examples of domain-driven image generation using the proposed DomainGallery method. It demonstrates the ability of DomainGallery to generate images in various scenarios, including intra-category generation, cross-category generation, extra attribute addition, and personalization, starting from a few-shot target dataset of a specific domain (e.g., sketches). The figure highlights the challenges in directly generating images of a specific domain using pretrained text-to-image models and how DomainGallery addresses these challenges.
Full paper#