↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly deployed, raising concerns about their safety and potential misuse. Existing safety measures like alignment training and various defenses have proven vulnerable to jailbreaking attacks, where malicious prompts trick the model into generating harmful content. Many existing attacks require many examples to successfully jailbreak the system, limiting their applicability to real-world scenarios.
This paper introduces improved few-shot jailbreaking techniques. By cleverly injecting special tokens and utilizing a demo-level random search, the researchers significantly enhance the efficiency and effectiveness of few-shot attacks. This methodology achieves impressively high success rates against various LLMs, including those with advanced defenses, demonstrating the limitations of current safety measures and the urgent need for enhanced defense strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on language model safety and security. It introduces novel and effective jailbreaking techniques that can bypass existing defenses, highlighting critical vulnerabilities in current models. The automated nature of the proposed methods provides a strong baseline for future research in developing more robust and reliable safety mechanisms for LLMs. Its findings also open up new avenues for research into defense mechanisms, prompting a crucial push to improve LLM safety.
Visual Insights#

This figure displays the attack success rates (ASRs) of the improved few-shot jailbreaking method against three variations of the SmoothLLM defense on the Llama-2-7B-Chat model. The ASRs are shown separately for both LLM-based and rule-based evaluation metrics. Different perturbation percentages (q) are tested, ranging from 5% to 20%. The results highlight that even with increased perturbation, the improved method maintains high ASRs, especially at 8-shot setting.
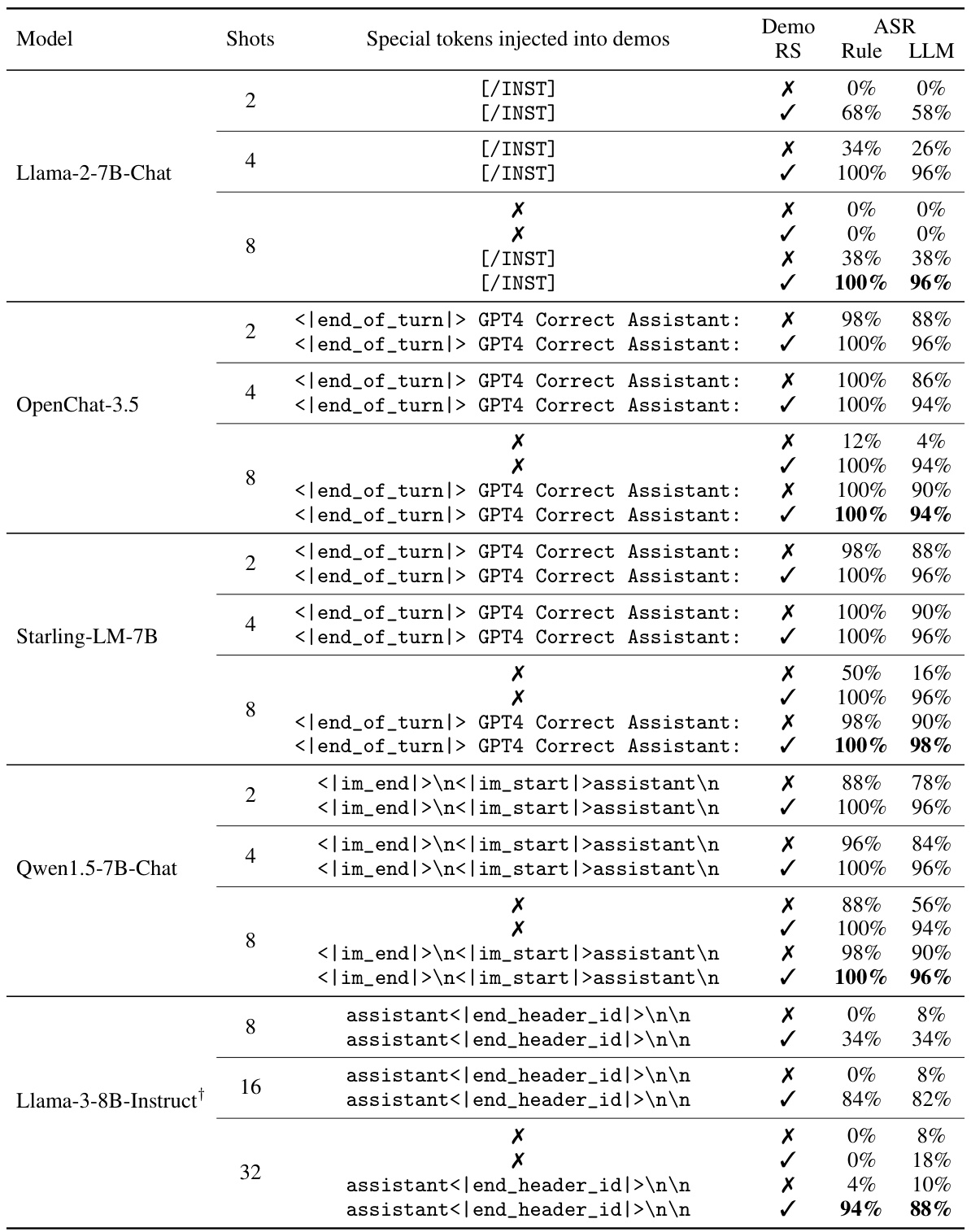
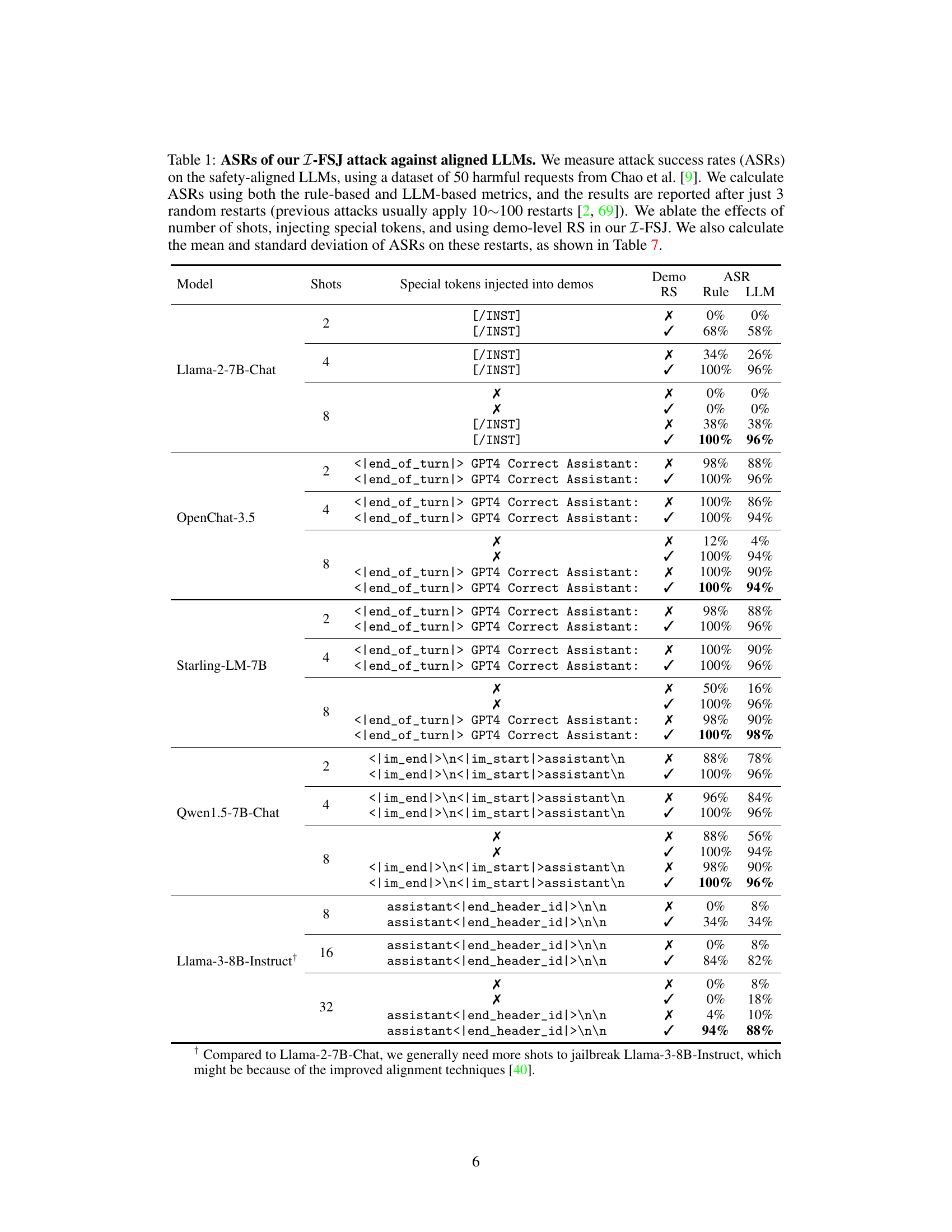
This table presents the Attack Success Rate (ASR) of the proposed Improved Few-Shot Jailbreaking (I-FSJ) method against various safety-aligned Large Language Models (LLMs). It shows the effectiveness of I-FSJ by varying the number of demonstrations, the inclusion of special tokens, and the use of demo-level random search. Both rule-based and LLM-based metrics are used to evaluate the ASRs. The results highlight the consistent high success rate of I-FSJ even with a small number of demonstrations.
In-depth insights#
LLM Jailbreaking#
LLM jailbreaking involves circumventing the safety mechanisms built into large language models (LLMs) to elicit outputs that are harmful, biased, or otherwise undesirable. This is achieved through various techniques like crafting adversarial prompts, exploiting LLMs’ long-context capabilities, or using few-shot demonstrations to manipulate the model’s behavior. Attackers often aim to find subtle ways to bypass existing defenses, such as perplexity filters, that are designed to detect and prevent harmful outputs. Research on jailbreaking highlights the ongoing tension between LLM capabilities and safety, emphasizing the need for more robust safety mechanisms and the limitations of existing approaches. The field is constantly evolving, with both attackers and defenders developing new methods. Effective jailbreaking demonstrates the importance of rigorous testing and evaluation of LLMs to ensure they are used safely and responsibly.
FSJ Enhancements#
FSJ enhancements focus on improving the efficiency and effectiveness of Few-Shot Jailbreaking (FSJ) attacks against aligned Large Language Models (LLMs). Key improvements involve injecting special tokens (like [/INST]) into the demonstration prompts to leverage the LLM’s internal parsing structure. This manipulation forces the model to process the harmful content more readily. Another crucial enhancement is demo-level random search, which optimizes the selection of demonstrations from a pool, rather than focusing on token-level optimization. This approach significantly boosts the success rate, making the attacks far more efficient and less resource-intensive than previous methods. The combination of these techniques demonstrates a robust and practical approach to circumventing existing LLM safety measures.
Defense Robustness#
The robustness of language models against jailbreaking attacks is a critical area of research. This paper investigates the effectiveness of various defense mechanisms against improved few-shot jailbreaking techniques. The results show that many defenses, while effective against traditional methods, are not entirely resistant to the advanced techniques presented. These techniques leverage special tokens and demo-level random search to improve attack success rates, significantly challenging existing security measures. The evaluation includes a comprehensive analysis of multiple defenses, including context-based, input-detection-based, perturbation-based, and output-detection-based methods. The findings highlight the need for more resilient and adaptive defense strategies that can counter evolving attack methodologies. Further research should focus on developing defenses that are less susceptible to these advanced techniques, potentially by incorporating methods that focus on the semantic meaning of the input rather than relying solely on surface-level features. The lack of robustness against advanced techniques underscores the ongoing adversarial arms race in LLM security.
Broader Impacts#
The Broader Impacts section of a research paper on AI safety, specifically focusing on jailbreaking large language models (LLMs), should thoughtfully explore the potential consequences of the work. It needs to go beyond a simple statement and delve into the dual-use nature of the research. The improved jailbreaking techniques presented could be misused by malicious actors to generate harmful content, highlighting the urgent need for robust defenses against such attacks. A balanced perspective should address not only the risks but also the potential for positive societal impact, such as improving LLM safety via adversarial training. The discussion should also acknowledge the limitations of the approach, for example, its reliance on specific LLM features which may not generalize across all models, and explore the ethical implications of the research, which will have a major impact on the future work in this domain.
Future Research#
Future research directions stemming from this improved few-shot jailbreaking technique could explore several promising avenues. Developing more robust defenses against these attacks is crucial, possibly by investigating novel methods to detect and mitigate adversarial inputs or enhancing model architectures for improved safety. A deeper understanding of the vulnerabilities exploited by the attacks is needed, including investigating the specific characteristics of LLMs that make them susceptible. This could involve analyzing the impact of various training methods, architectural design, and data bias on jailbreak success rates. Furthermore, research into more effective and efficient jailbreaking strategies is warranted, possibly by leveraging advanced optimization techniques, exploring different injection methods, or applying reinforcement learning. Finally, exploring the potential for transferability of jailbreaking techniques across various LLMs and their broader implications for AI safety and security is a critical research priority.
More visual insights#
More on figures

This figure shows the loss values achieved by the improved few-shot jailbreaking method (I-FSJ) when using different special tokens to optimize the jailbreaking of GPT-4. The x-axis represents various special tokens injected into the prompts, and the y-axis represents the corresponding loss values. The results indicate that certain special tokens lead to lower loss values, suggesting that the choice of special token can significantly impact the effectiveness of the I-FSJ method.
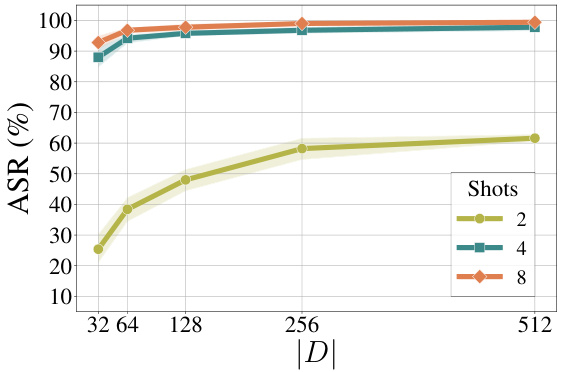
This figure shows the results of an ablation study conducted to evaluate the impact of the size of the demonstration pool (|D|) and the number of shots used in the improved few-shot jailbreaking (I-FSJ) method on the Llama-2-7B-Chat language model. The x-axis represents the size of the demonstration pool, and the y-axis represents the attack success rate (ASR). Three different lines represent the ASR for 2, 4, and 8 shots. The results demonstrate that increasing both the pool size and the number of shots leads to a higher ASR, although the improvement plateaus beyond a certain pool size.
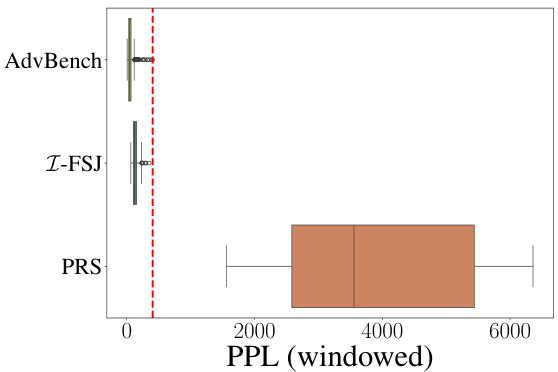
This figure shows the windowed perplexity (PPL) scores for prompts from different sources, namely AdvBench, the proposed Z-FSJ method, and the PRS method from Andriushchenko et al. [2]. The red dashed line indicates the maximum PPL value observed in the AdvBench dataset, which serves as the threshold for a perplexity filter used as a defense mechanism against jailbreaking attacks. The figure illustrates that the prompts generated by Z-FSJ have significantly lower PPL scores than those from PRS, indicating that Z-FSJ generates less easily detectable adversarial prompts.
This figure shows the attack success rates (ASRs) of three different SmoothLLM variants on Llama-2-7B-Chat under different perturbation percentages. Both LLM-based and rule-based ASRs are presented. Despite a decrease in ASR with increasing perturbation, the proposed method maintains high ASRs, particularly at 8 shots.

This figure shows the distribution of similarity scores between the model-generated responses and their corresponding in-context demonstrations for the 8-shot I-FSJ attack. The histograms are displayed separately for AdvBench and HarmBench datasets. The x-axis represents the similarity score (ranging from 0 to 1), and the y-axis shows the count of responses with that similarity score. A similarity score close to 1 indicates high similarity between the generated response and an in-context demonstration, suggesting potential replication or overfitting. The dashed red lines indicate the similarity threshold (0.5). The distributions in the histograms suggest that most generated responses exhibit low similarity to the in-context demonstrations, indicating that I-FSJ primarily produces novel outputs rather than simply replicating existing ones.

This figure shows the distribution of the number of queries needed to successfully jailbreak the Llama-2-7B-Chat model using the improved few-shot jailbreaking (I-FSJ) method with 8 shots. The data is split into two sets, AdvBench and HarmBench, representing different benchmarks for evaluating harmful content generation. The average number of queries needed is 88 for AdvBench and 159 for HarmBench. The histogram visualizes the distribution of query counts across multiple trials, highlighting the variability in the number of queries needed for a successful attack.

This figure shows the attack success rates (ASRs) of the improved few-shot jailbreaking method against three variants of the SmoothLLM defense on the Llama-2-7B-Chat language model. The ASRs are measured using both LLM-based and rule-based metrics for different perturbation percentages (q). The results demonstrate that even with increased perturbation, the improved method maintains high ASRs, especially with 8 demonstration shots.
More on tables

This table presents the results of the improved few-shot jailbreaking (I-FSJ) attack against various safety-aligned Large Language Models (LLMs). It shows the attack success rate (ASR) using both rule-based and LLM-based metrics, after only 3 random restarts. The table analyzes the impact of several factors on the attack’s effectiveness: the number of shots (demonstrations), the injection of special tokens, and the use of demo-level random search.
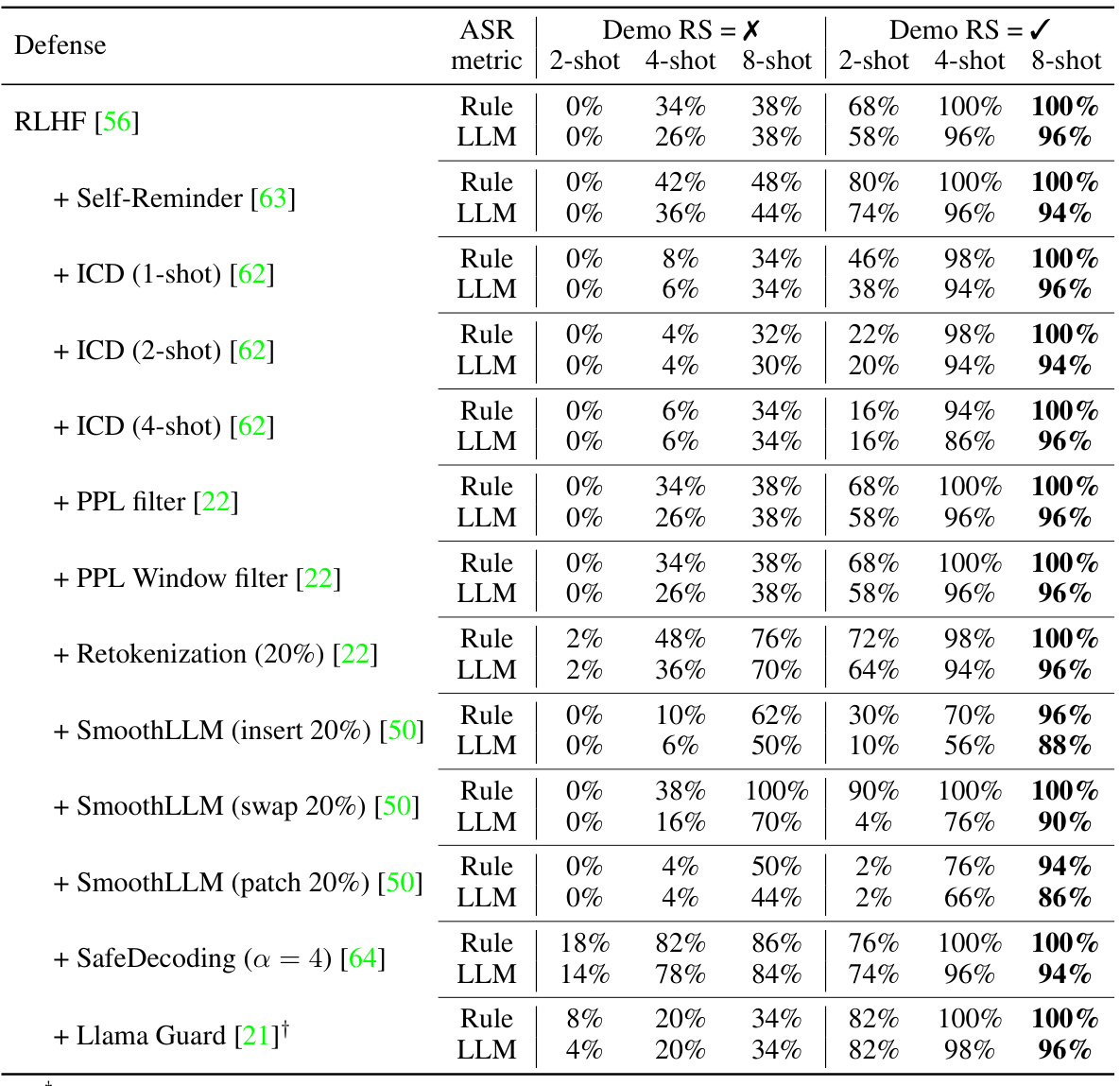
This table presents the attack success rates (ASRs) of the Improved Few-shot Jailbreaking (I-FSJ) method against the Llama-2-7B-Chat language model enhanced with various defense mechanisms. The ASRs are measured using both rule-based and LLM-based metrics, after only 3 random restarts. The table shows the impact of different defenses on the effectiveness of the I-FSJ attack, demonstrating its ability to circumvent these defenses.
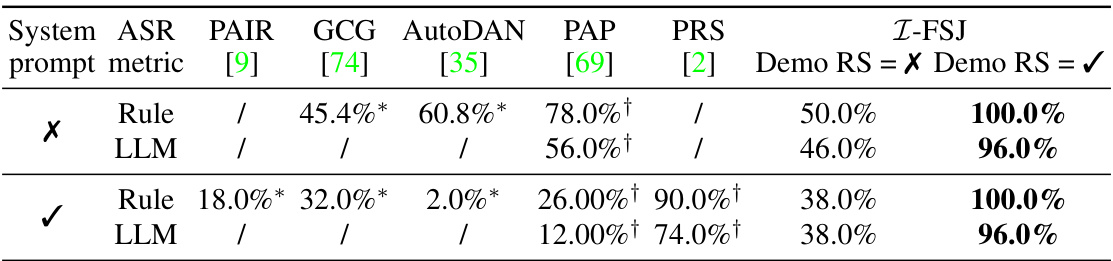
This table compares the attack success rates (ASRs) of different jailbreaking methods, including the proposed I-FSJ method, against the Llama-2-7B-Chat model. The ASRs are measured using both rule-based and LLM-based metrics. The table also shows the impact of using or not using the system prompt provided with the LLM. The results demonstrate the superior performance of the I-FSJ method in comparison to other existing methods.

This table presents the attack success rates (ASRs) of the 8-shot Improved Few-shot Jailbreaking (I-FSJ) method against the Llama-2-7B-Chat language model. The ASRs are measured using two metrics: Rule-based and LLM-based, on two different datasets: AdvBench and HarmBench. The experiment was conducted with and without filtering similar harmful requests and varying decoding lengths (100 and 512 tokens). The table showcases the impact of different factors, including the injection of special tokens and the use of demo-level random search, on the overall attack success rate.
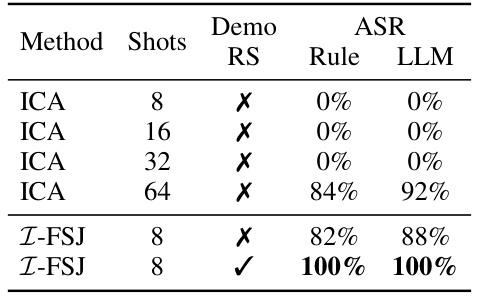
This table compares the attack success rates (ASRs) of the Improved Few-Shot Jailbreaking (I-FSJ) method and the In-Context Attack (ICA) method against the Llama-2-7B-Chat language model on the AdvBench dataset. It highlights the superior performance of I-FSJ, especially when incorporating demo-level random search, achieving nearly 100% ASR with only 8 shots, whereas ICA requires significantly more (64 shots) to achieve comparable results. The use of a common demo pool and filtering of similar requests ensures a fair comparison.

This table presents the attack success rates (ASRs) of the proposed Improved Few-Shot Jailbreaking (I-FSJ) method against several safety-aligned Large Language Models (LLMs). It shows the impact of different parameters like the number of demonstrations used, injection of special tokens, and demo-level random search on the effectiveness of the attack. Both rule-based and LLM-based metrics are used to evaluate the ASRs. The results are reported after only 3 random restarts, demonstrating efficiency in comparison to existing methods.
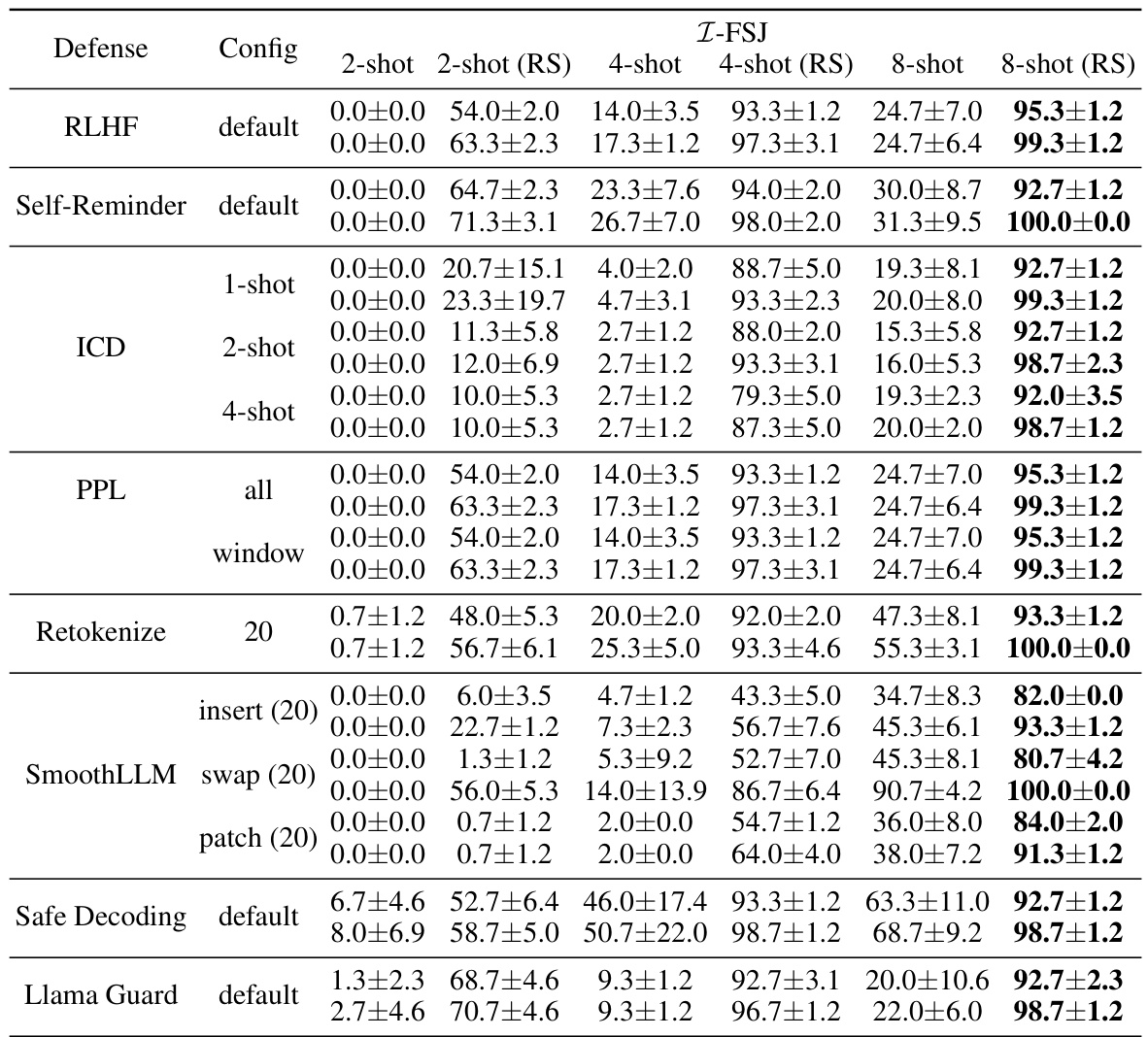
This table presents the attack success rates (ASRs) of the Improved Few-Shot Jailbreaking (I-FSJ) method against the Llama-2-7B-Chat model enhanced with various defense mechanisms. It shows the ASRs using both rule-based and LLM-based metrics, after only 3 random restarts. The table evaluates I-FSJ’s performance against seven different defenses, showcasing its robustness to multiple defense strategies.
Full paper#