↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many object detection models struggle to adapt to new, specialized domains without losing their ability to recognize unseen objects (zero-shot generalization). This paper introduces a new task, Incremental Vision-Language Object Detection (IVLOD), which directly tackles this problem. Existing incremental learning methods often negatively impact a model’s zero-shot capabilities.
The paper proposes ZiRa, a novel method using a dual-branch architecture and a zero-interference loss function. This method allows the model to efficiently learn new tasks without significantly impacting its performance on previously learned tasks or its ability to recognize unseen objects. Experiments showed that ZiRa significantly outperforms existing methods on both zero-shot generalization and downstream incremental learning tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel learning task and method for incremental vision-language object detection, addressing the challenge of maintaining zero-shot generalization while adapting to new domains. Its memory-efficient approach and strong empirical results make it highly relevant to current research trends in continual learning and open-vocabulary object detection, opening avenues for more robust and adaptable AI systems.
Visual Insights#

The figure shows a comparison of three different approaches for adapting Vision-Language Object Detection Models (VLODMs) to multiple downstream tasks. The first approach is zero-shot learning (no adaptation), the second is conventional incremental learning using CL-DETR, and the third is zero-shot generalizable incremental learning (IVLOD) proposed in the paper. The figure demonstrates that IVLOD, unlike general incremental object detection, maintains the original zero-shot performance of the VLODM while also performing incremental learning. It highlights the challenges of catastrophic forgetting (performance decline on previously learned tasks when introducing new tasks) and maintaining zero-shot generalizability in IVLOD.
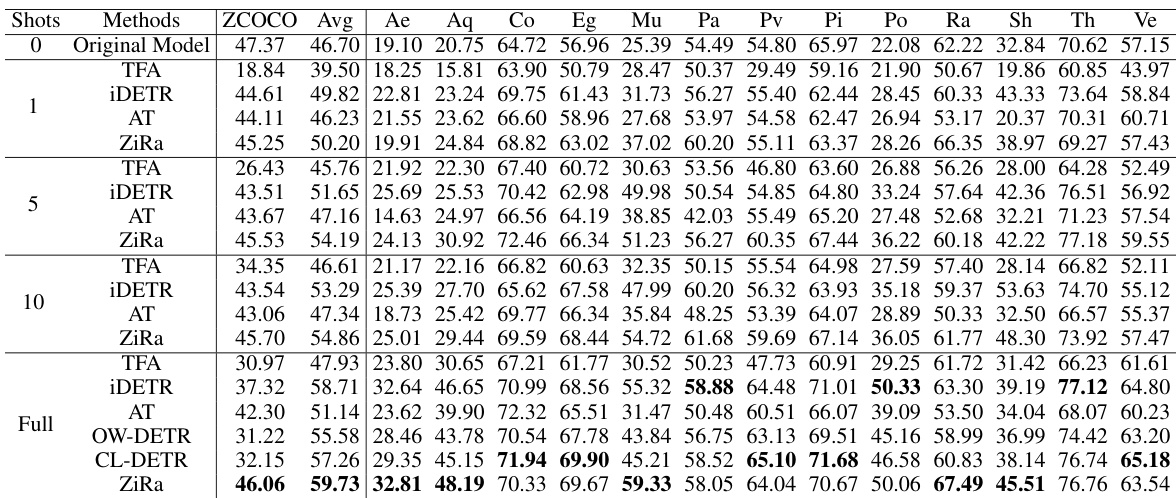
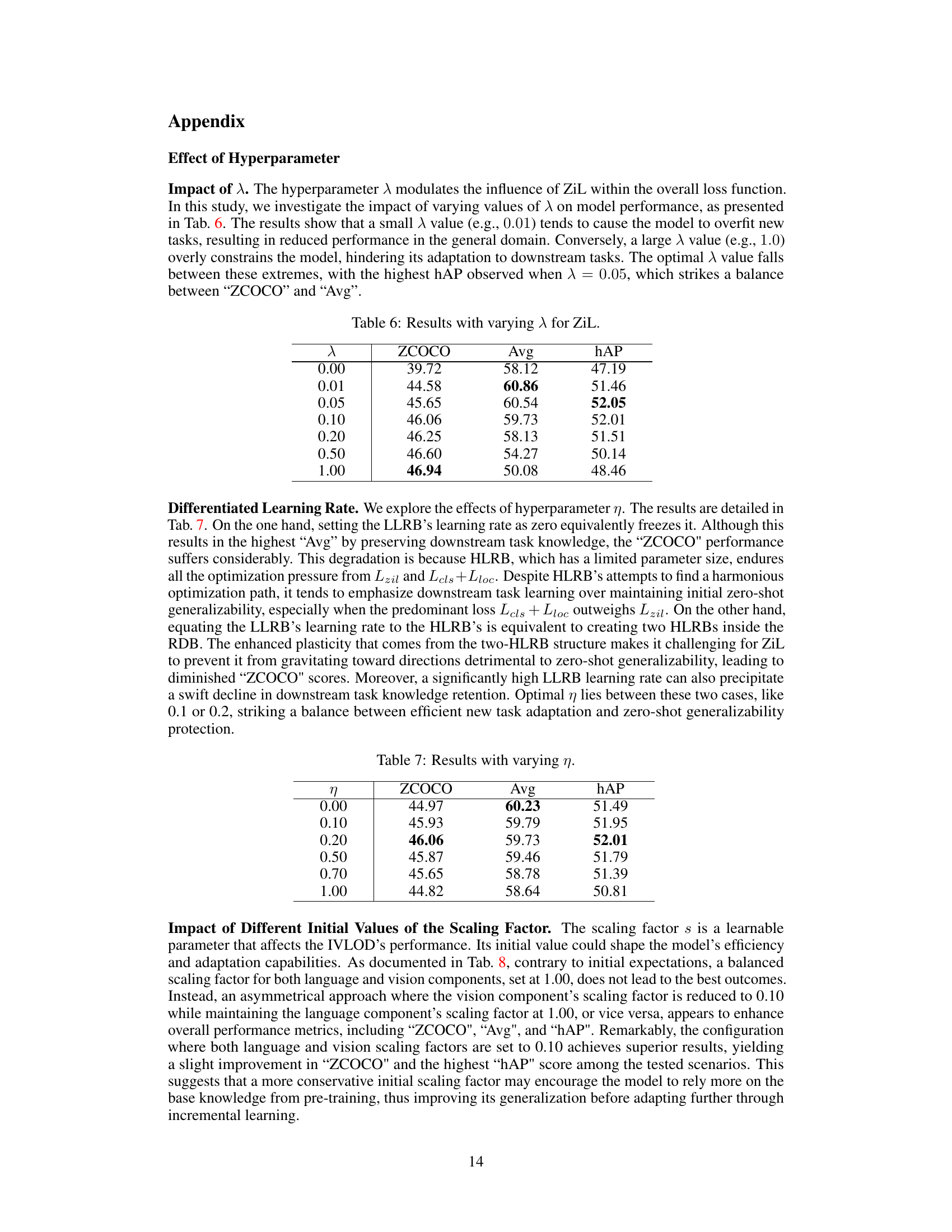
This table presents the results of the Incremental Vision-Language Object Detection (IVLOD) experiments conducted on the ODinW-13 and ZCOCO datasets. The results are broken down by the number of shots (training samples) used during adaptation training for different models: Original Model, TFA, iDETR, AT, and ZiRa. The performance metrics are ZCOCO (zero-shot performance on COCO) and Avg (average performance across the 13 ODinW-13 datasets). Individual dataset results (Ae, Aq, Co, etc.) are also included for a detailed analysis. All experiments utilize the same Grounding DINO model as the base.
In-depth insights#
IVLOD: A New Task#
The proposed task, IVLOD (Incremental Vision-Language Object Detection), presents a significant advancement in the field of object detection. It uniquely combines the strengths of Vision-Language Object Detection Models (VLODMs) with the capability of incremental learning. This is crucial because while VLODMs excel at zero-shot generalization, their performance in specialized domains often lags. IVLOD directly addresses this limitation by enabling VLODMs to adapt incrementally to new, specialized domains without sacrificing their zero-shot capabilities. This is a challenging problem due to the risk of catastrophic forgetting, where learning new tasks causes the model to forget previously learned ones. The novelty of IVLOD lies not just in the task itself but also in its potential to enable more robust and adaptable AI systems capable of continuous learning and adaptation in dynamic real-world scenarios. Its success hinges on effective methods that mitigate catastrophic forgetting while preserving zero-shot generalization. The introduction of IVLOD opens up many exciting research directions, focusing on efficient adaptation strategies and applications in diverse real-world settings.
ZiRa: Memory-Efficient#
The heading ‘ZiRa: Memory-Efficient’ suggests a focus on the resource-conscious aspect of the ZiRa algorithm. This implies that ZiRa is designed to operate effectively without excessive memory consumption, a crucial factor in resource-constrained environments like edge devices or applications with limited memory availability. The memory efficiency likely stems from specific design choices within the algorithm, such as employing techniques that avoid the need for storing large amounts of data or model copies. This could involve using efficient parameterizations, clever data management strategies or other optimization techniques that reduce memory footprint without sacrificing performance. The memory efficiency is a significant advantage of ZiRa, especially when compared to methods that rely on storing large sets of example data or maintaining duplicate model copies, making it a particularly attractive approach for real-world deployment.
Zero-Shot Robustness#
Zero-shot robustness examines a model’s ability to generalize to unseen data or tasks, without any fine-tuning. A robust zero-shot model should perform well even when encountering unexpected inputs or variations in the data distribution. This is crucial because real-world scenarios are rarely perfectly matched to training data. Evaluating zero-shot robustness involves assessing performance on held-out data significantly different from the training set. Analyzing where the model fails, and the types of errors it makes, helps reveal critical limitations and directions for future improvements. Factors like model architecture, training data diversity, and the chosen evaluation metric all heavily influence the observed robustness. Therefore, carefully designed experiments and comprehensive analysis are needed for a thorough understanding of a model’s capacity for zero-shot generalization under diverse conditions.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a Vision-Language Object Detection model, this might involve removing or deactivating parts of the architecture, such as the dual branch structure, zero-interference loss, or reparameterization techniques. Analyzing the results reveals the relative importance of each component. For instance, removing the zero-interference loss might lead to a significant drop in zero-shot performance, highlighting its crucial role in preventing catastrophic forgetting. Similarly, disabling the dual branch structure could reveal whether the separate high and low learning rate branches are essential for maintaining performance across incremental tasks. The ablation study is key for understanding the design choices and validating the efficacy of the proposed method, demonstrating which parts are most vital for overall performance and which parts can be potentially simplified or removed without significant performance degradation. Careful analysis of these findings allows for a more refined understanding of the model’s strengths and weaknesses, guiding future model development and optimization efforts.
Future of IVLOD#
The future of Incremental Vision-Language Object Detection (IVLOD) is promising, with potential advancements in several key areas. Improved efficiency is crucial, reducing computational costs and memory requirements for practical applications. Enhanced robustness is needed to handle noisy or ambiguous data, improving accuracy and reliability in diverse real-world scenarios. Open-vocabulary capabilities should continue to improve, enabling more flexible and nuanced object detection without relying on pre-defined categories. Research should focus on developing more generalizable models that can adapt to new tasks quickly and effectively with minimal catastrophic forgetting. Addressing bias and fairness within IVLOD models is vital, ensuring equitable performance across different demographics and contexts. Finally, exploring the integration of IVLOD with other AI modalities like robotics and natural language processing will unlock new possibilities for human-computer interaction and autonomous systems.
More visual insights#
More on figures
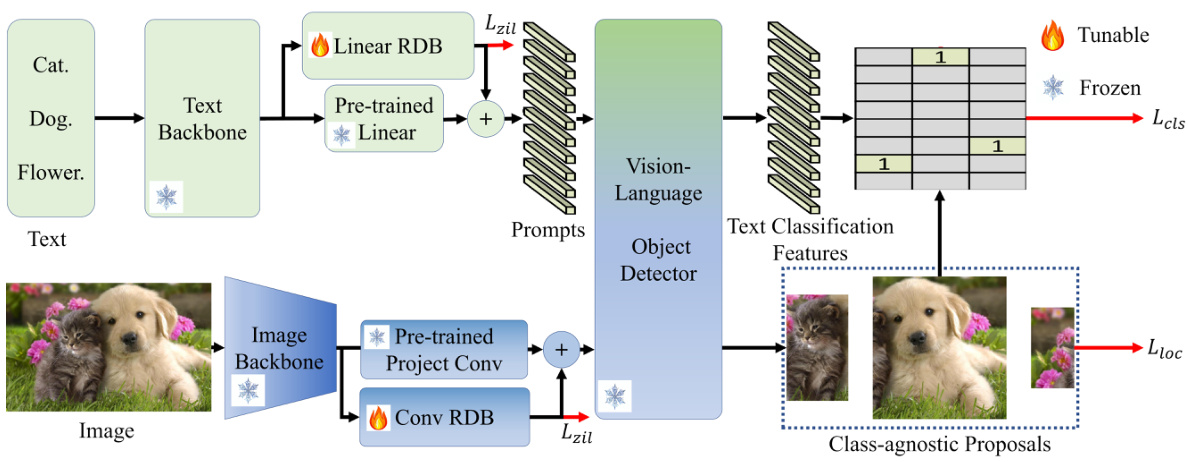
This figure illustrates the architecture of the proposed method, Zero-interference Reparameterizable Adaptation (ZiRa), for Incremental Vision-Language Object Detection (IVLOD). It shows how the model adapts to new tasks sequentially by adding reparameterizable dual branches to both the language and vision sides of a pre-trained Vision-Language Object Detection Model (VLODM). The dual branches, named Reparameterizable Dual Branch (RDB), consist of a high-learning-rate branch (HLRB) and a low-learning-rate branch (LLRB). The Zero-interference Loss (ZiL) is applied to both RDBs to prevent forgetting previously learned knowledge and maintain zero-shot generalizability. The figure highlights the interaction between image features, text prompts, the RDBs, and the final object detection output.
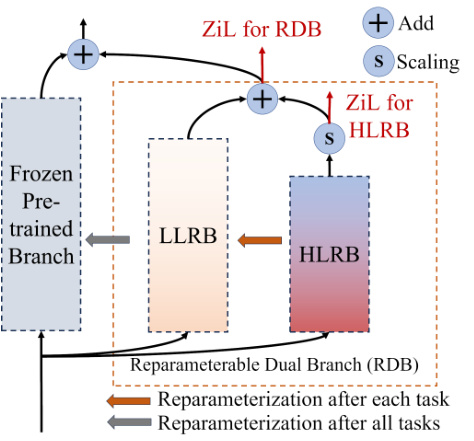
The figure illustrates the architecture of the Reparameterizable Dual Branch (RDB), a key component of the ZiRa approach. It shows the dual-branch structure within the RDB, comprising the Low-learning rate Branch (LLRB) and the High-learning rate Branch (HLRB). The LLRB is set at η (0 < η < 1) times the learning rate of the HLRB. The different learning rates allow for a division of labor between the two branches, helping to maintain knowledge learned from previous tasks while adapting to new ones. The figure also depicts the reparameterization process, showing how the HLRB is merged into the LLRB after each new task. This effectively manages memory usage and helps to prevent catastrophic forgetting.
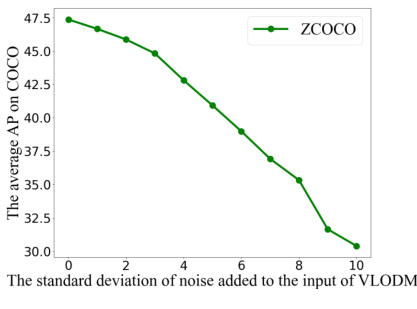
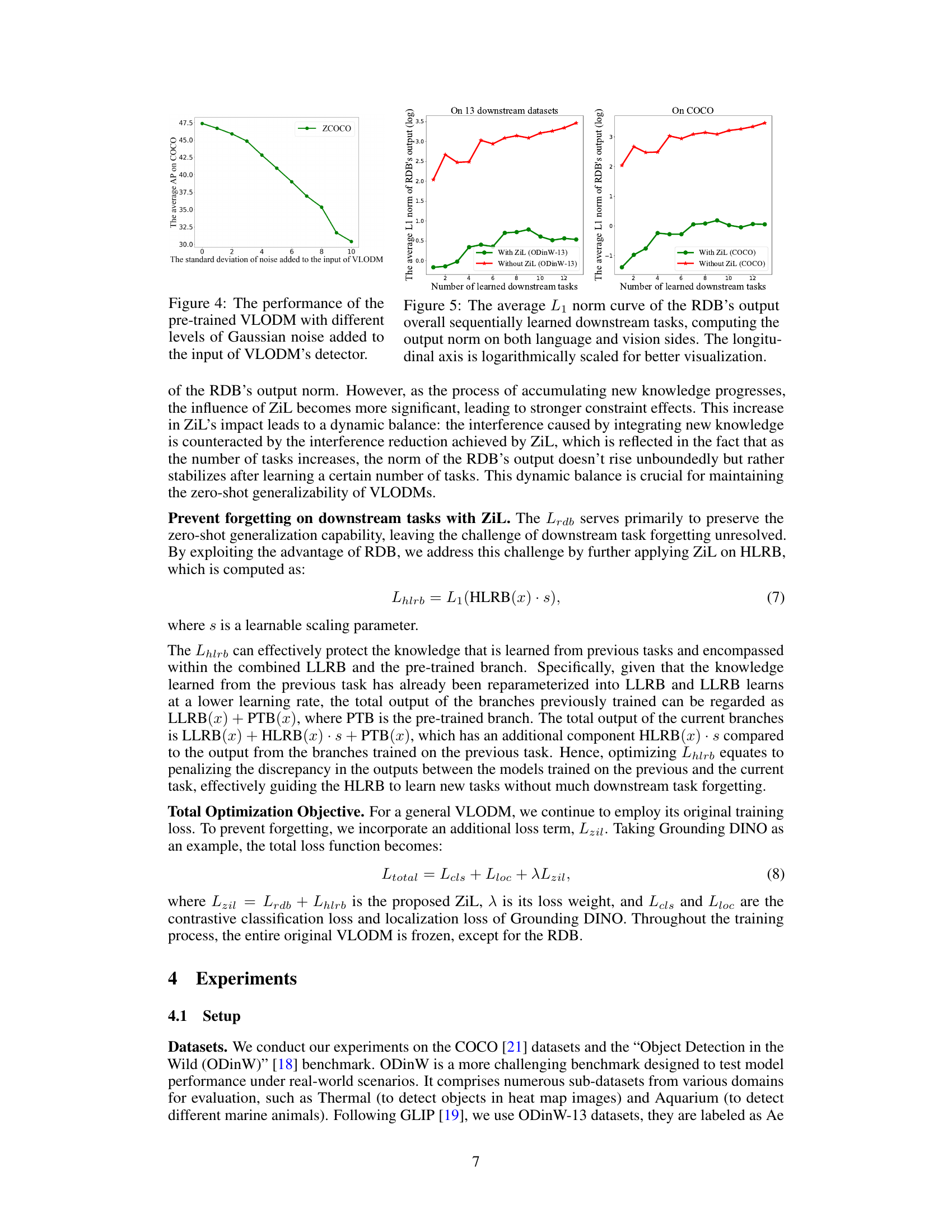
This figure shows how the performance of a pre-trained Vision-Language Object Detection Model (VLODM) changes when different levels of Gaussian noise are added to its input. The x-axis represents the standard deviation of the added Gaussian noise, and the y-axis represents the average Average Precision (AP) on the COCO dataset. The graph demonstrates the robustness of the pre-trained VLODM to noise; even with significant amounts of noise, the performance does not decrease dramatically.
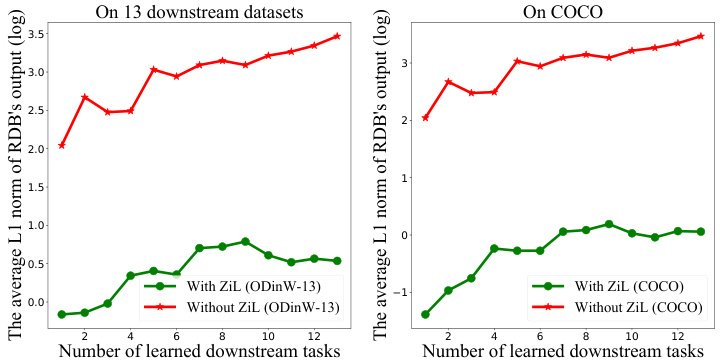
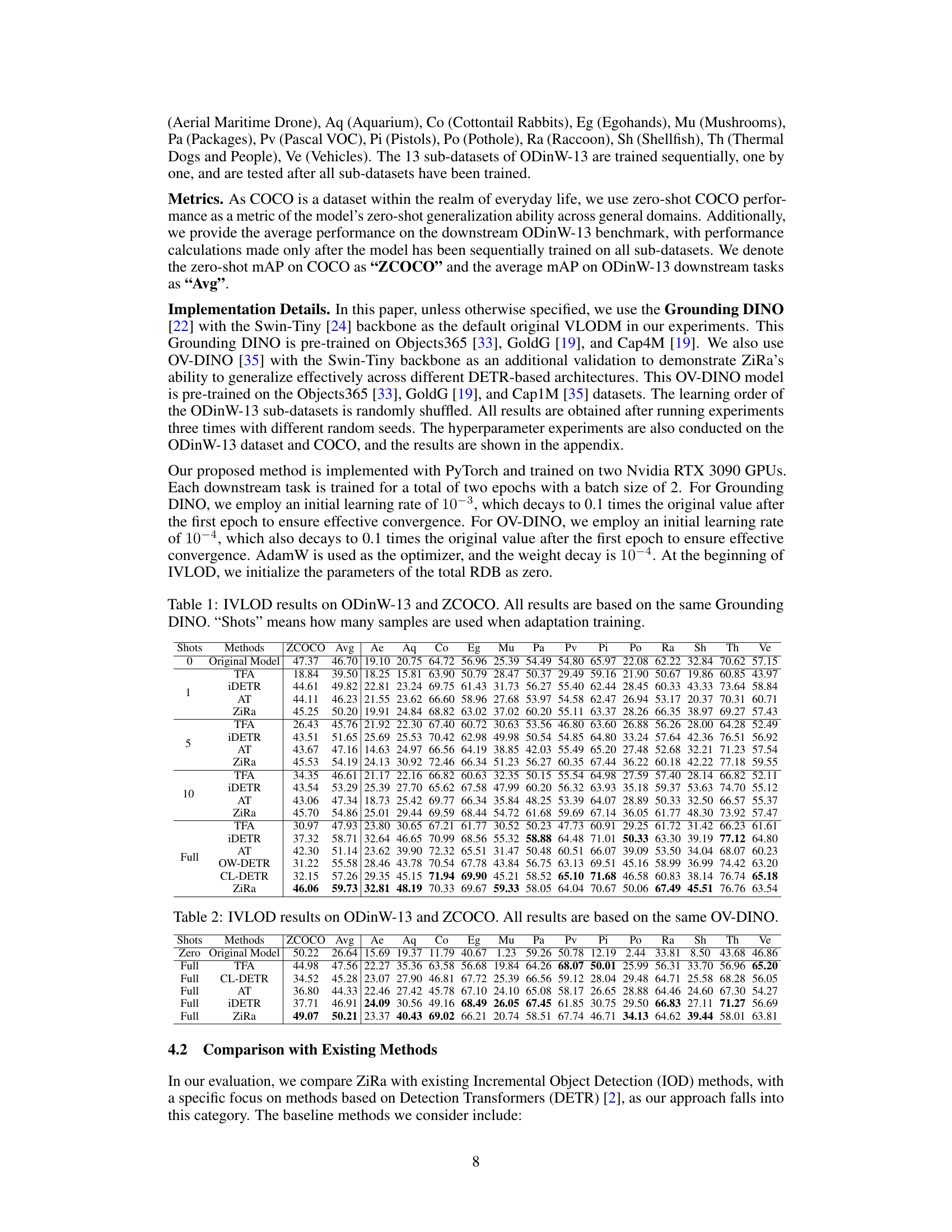
This figure shows the change in the L1 norm of the RDB’s output over multiple downstream tasks. The L1 norm is a measure of the magnitude of the RDB’s output. The plot displays the average L1 norm for both the language and vision sides of the model. A lower L1 norm indicates that the model is less affected by the addition of new downstream tasks, which is a desired outcome for continual learning. The plot includes comparisons both with and without the Zero-interference Loss (ZiL) for both COCO and ODINW-13 datasets, showcasing the effect of ZiL on preventing catastrophic forgetting.

This figure visualizes the results of object detection on images containing both seen and unseen object categories. Three methods are compared: Zero-shot detection using only a pre-trained model, incremental learning using iDETR, and incremental learning using the proposed ZiRa method. The images show that the Zero-shot approach misses some objects and the Incremental method using iDETR forgets some previously learned objects. ZiRa, however, successfully identifies both seen and unseen objects, demonstrating its ability to incrementally learn new categories while preserving the ability to detect previously learned ones.
More on tables

This table presents the results of the Incremental Vision-Language Object Detection (IVLOD) experiments using Grounding DINO on the ODinW-13 and COCO datasets. It shows a comparison of different methods (Original Model, TFA, iDETR, AT, and ZiRa) in terms of zero-shot Average Precision (AP) on COCO (ZCOCO) and average AP across 13 downstream tasks (Avg) in ODinW-13. The number of shots (samples used for adaptation training) is also specified for each method. The table helps demonstrate the effectiveness of the ZiRa method in maintaining zero-shot generalization capability while adapting to new tasks incrementally.

This table presents the results of the Incremental Vision-Language Object Detection (IVLOD) experiments. It compares the performance of different methods (Original Model, TFA, iDETR, AT, and ZiRa) across various metrics (ZCOCO and average performance across 13 downstream tasks in ODinW-13 dataset). The results are shown for different numbers of training samples (“Shots”) used for adaptation. All experiments used the same pre-trained Grounding DINO model.
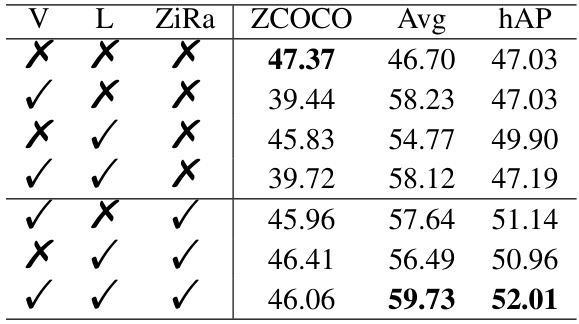
This table presents a comparison of the performance of the proposed ZiRa method when learning is conducted on different modalities, including only vision, only language, both vision and language, and various combinations thereof. The results are shown in terms of ZCOCO (zero-shot COCO performance), Avg (average performance across 13 downstream tasks), and hAP (harmonic mean of ZCOCO and Avg). The table highlights the impact of learning on both vision and language aspects for better performance on zero-shot and downstream tasks. The results indicate that learning on both sides delivers better performance.
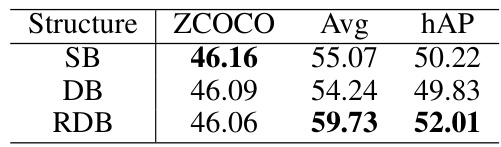
This table compares the performance of three different branch structures (Single Branch, Dual Branch, and Reparameterizable Dual Branch) in the context of incremental vision-language object detection. The results show the Zero-shot Average Precision (ZCOCO), the average Average Precision across downstream tasks (Avg), and the harmonic mean of ZCOCO and Avg (hAP). The RDB structure consistently outperforms the other two.
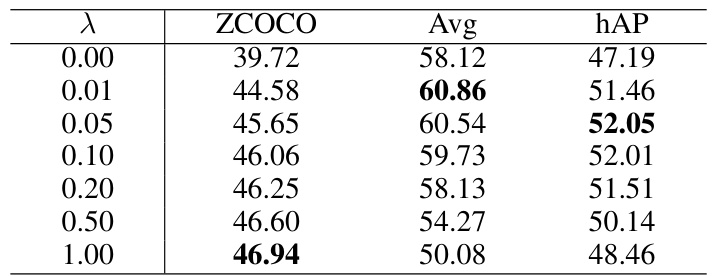
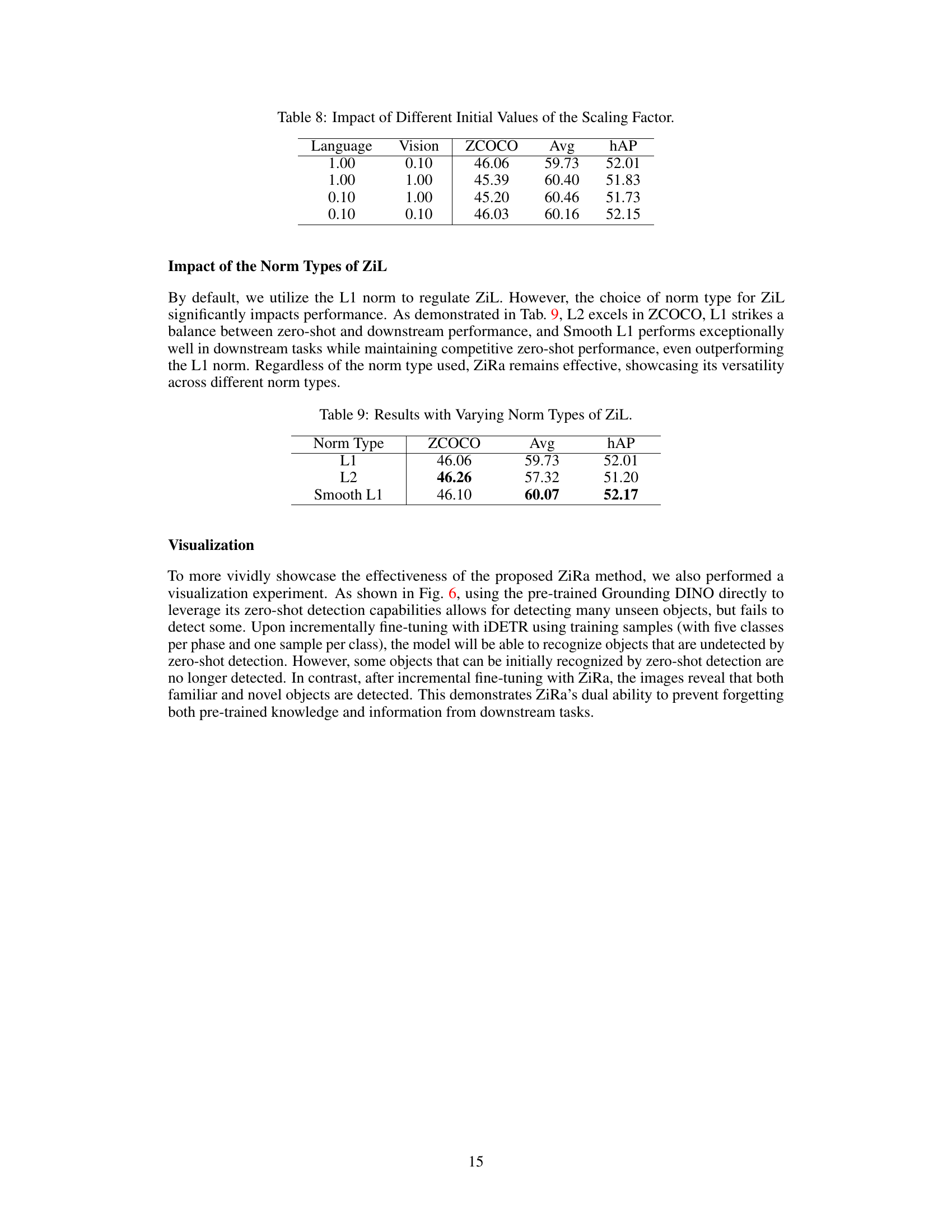
This table shows the impact of different values of the hyperparameter λ (lambda) on the model’s performance. λ controls the influence of the Zero-Interference Loss (ZiL) in the overall loss function. The table presents the zero-shot Average Precision (ZCOCO), the average Average Precision across 13 downstream tasks (Avg), and the harmonic mean of ZCOCO and Avg (hAP) for different values of λ. The results indicate that an optimal value of λ exists that balances zero-shot performance and performance on downstream tasks, with values that are too small or too large leading to suboptimal results.
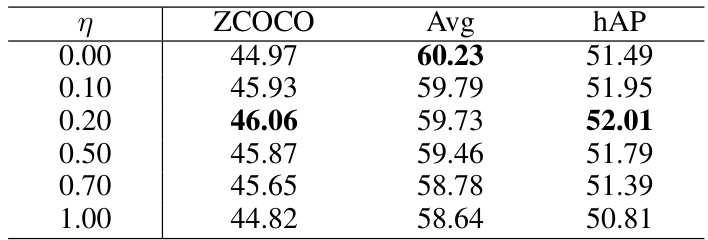
This table presents the results of an ablation study on the impact of the hyperparameter η (eta) on the performance of the ZiRa model. Eta controls the learning rate ratio between the Low-learning rate Branch (LLRB) and the High-learning rate Branch (HLRB) within the Reparameterizable Dual Branch (RDB) structure. The table shows that there is a balance to be achieved with this parameter: Too low of a value, and the model doesn’t adapt enough, too high, and the model forgets previous knowledge. The results are measured using ZCOCO (zero-shot COCO performance), Avg (average performance across downstream tasks), and hAP (harmonic mean of ZCOCO and Avg). The best results across all three metrics are observed with η = 0.20.
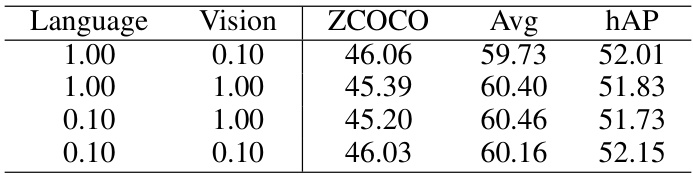
This table presents the results of an ablation study investigating the impact of different initial values for the scaling factor ’s’ in the Reparameterizable Dual Branch (RDB) on the performance of the model. The scaling factor ’s’ is used in the equation Xrdb = HLRB(x)·s + LLRB(x), where Xrdb is the output of the RDB, HLRB(x) is the output of the High-learning rate Branch, and LLRB(x) is the output of the Low-learning rate Branch. The table shows how variations in the initial values of ’s’ for both language and vision components affect the model’s performance across different metrics, such as ZCOCO, Avg, and hAP. The results demonstrate that asymmetrical scaling (different values for language and vision) is often better than symmetrical scaling (same value for both).

This table presents the results of an ablation study that investigates the impact of different norm types (L1, L2, and Smooth L1) used in the Zero-interference Loss (ZiL) on the overall performance of the proposed approach. The performance is measured using three metrics: ZCOCO (zero-shot performance on the COCO dataset), Avg (average performance across 13 downstream tasks in the ODinW-13 dataset), and hAP (harmonic mean of ZCOCO and Avg). The table shows how the choice of norm type affects the balance between zero-shot generalizability and performance on the downstream tasks.
Full paper#