↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many large multimodal models struggle with real-world scenarios where input data may be incomplete (missing modalities), leading to significantly degraded performance. Existing solutions, like data reconstruction or modality augmentation, are often computationally expensive and may not fully address the underlying issue. This is because they primarily focus on reconstructing missing data and not on properly adapting the model’s architecture to handle incomplete information.
This paper introduces a new technique called Deep Correlated Prompting (DCP) to solve this problem. Instead of trying to reconstruct missing data, DCP uses carefully designed prompts to guide the model’s reasoning process, even when some modalities are missing. By incorporating correlations between prompts at different layers and between different modalities, DCP helps the model learn how to effectively use the available information to make accurate predictions. The experimental results demonstrate that DCP significantly outperforms previous methods while having a much lower computational cost.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal learning and robust AI systems. It directly addresses the challenge of missing modalities, a common real-world problem, and proposes a novel, computationally efficient solution. The findings are significant for improving AI model performance and reliability in various applications, and inspire new avenues for research in prompt engineering and multimodal adaptation.
Visual Insights#
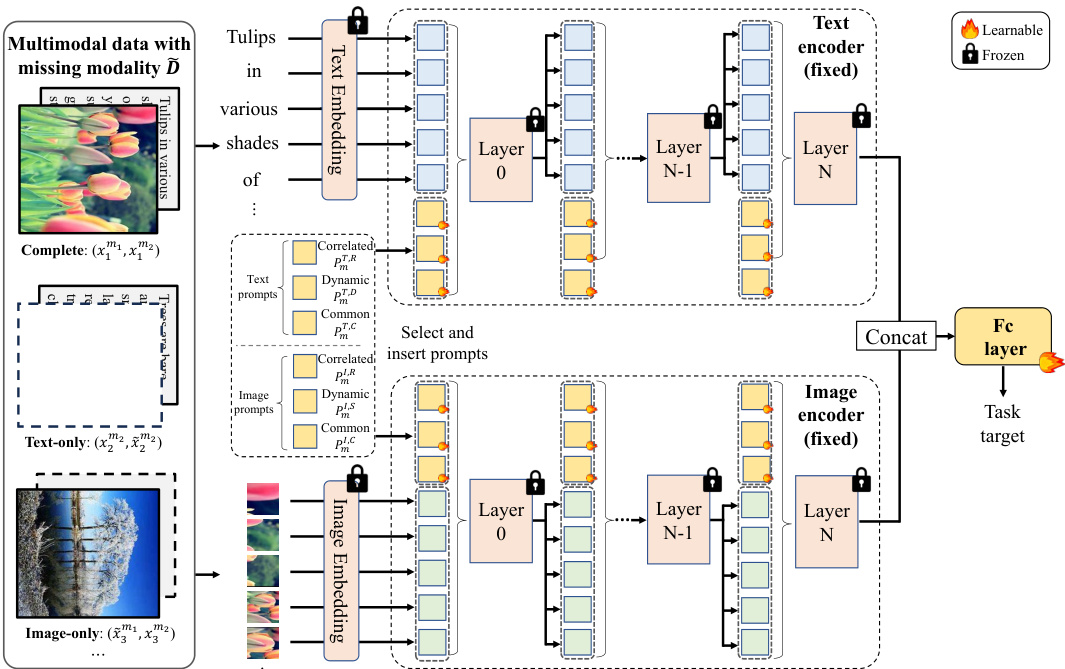
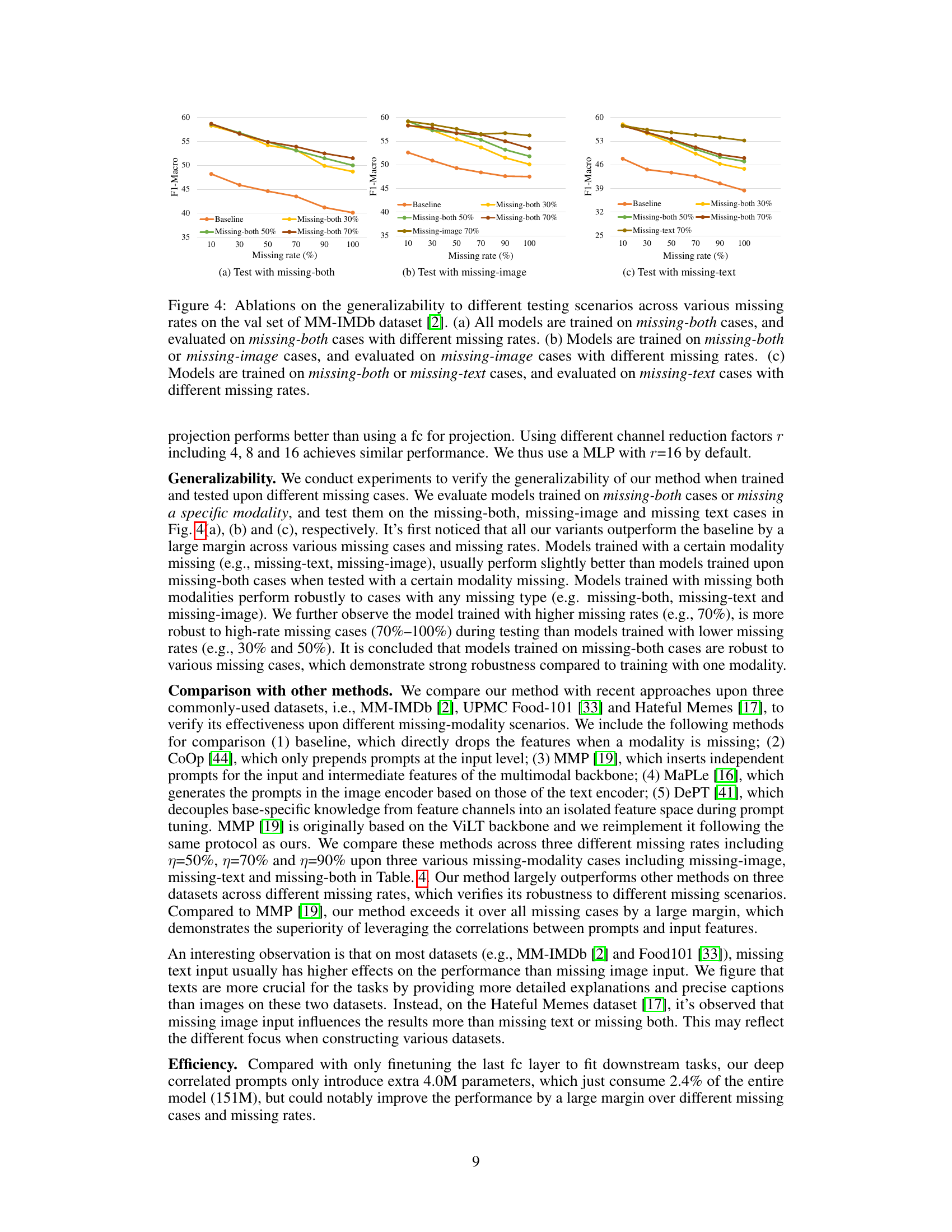
This figure illustrates the overall framework of the proposed deep correlated prompting method for handling missing modalities in visual recognition. It shows how modality-complete and modality-incomplete inputs are processed. The key components are the selection of prompts based on the missing modality, the incorporation of correlated, dynamic, and modal-common prompts, and the use of a fully-connected layer for final prediction. The pretrained multimodal backbone (encoders) remains frozen during training, significantly reducing computational cost.
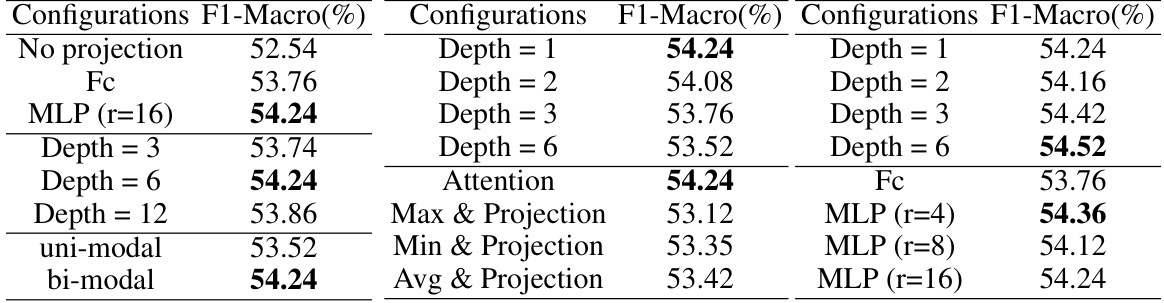
This table presents ablation studies on the correlated prompts component of the proposed Deep Correlated Prompting (DCP) method. It shows the impact of different configurations on the F1-Macro score, a performance metric. Specifically, it investigates the effects of using different prompt generation functions (No projection, Fc, MLP), varying prompt depths (Depth = 3, 6, 12), and considering only one modality versus incorporating information from both modalities (uni-modal, bi-modal) when generating the correlated prompts.
In-depth insights#
Missing Modality Issue#
The “Missing Modality Issue” in multimodal learning is a significant challenge arising from the incomplete nature of real-world data. Unlike the ideal scenario where all modalities (e.g., text, image, audio) are present, practical applications frequently encounter missing data due to various reasons such as privacy concerns, data collection difficulties, or sensor failures. This incompleteness directly impacts the performance of models trained on complete data, leading to degraded accuracy and robustness. Addressing this issue involves developing techniques to handle various missing data scenarios, ranging from single modality absence to more severe cases with multiple missing modalities. Several approaches exist, including data imputation, modality reconstruction, and prompt learning-based methods that leverage the complementary information present in available modalities to mitigate the performance drop caused by missing data. The effectiveness of these approaches often varies depending on the type of modality missing and the ratio of missing data. The need for robust and efficient strategies for handling the “Missing Modality Issue” remains a key focus area for advancing the reliability and real-world applicability of multimodal learning systems.
Deep Correlated Prompting#
Deep Correlated Prompting presents a novel approach to enhance the robustness of large multimodal models when dealing with incomplete data. The core idea revolves around carefully designed prompts that leverage correlations between different layers of the model and between prompts and input features. This contrasts with previous methods which often append independent prompts, ignoring these valuable relationships. The method’s strength lies in its ability to dynamically generate prompts tailored to individual input characteristics, further improving model adaptation. By decomposing prompts into modal-common and modal-specific parts, the model efficiently utilizes complementary information from multiple modalities. Experimental results consistently demonstrate superior performance compared to existing methods across various missing-modality scenarios, highlighting the effectiveness and generalizability of Deep Correlated Prompting.
Prompt Engineering#
Prompt engineering, in the context of large language models (LLMs), is the art and science of crafting effective prompts to elicit desired outputs. Careful prompt design is crucial because LLMs are highly sensitive to the phrasing and structure of the input. A poorly written prompt can lead to nonsensical or irrelevant results, while a well-crafted prompt can unlock the model’s full potential. Effective prompts often involve techniques like few-shot learning, where examples of the desired input-output pairs are provided to guide the model. Beyond simple few-shot learning, more advanced techniques such as chain-of-thought prompting or self-consistency methods can be employed to improve the reasoning and reliability of the LLM’s responses. The field is rapidly evolving, with ongoing research focused on developing more robust and interpretable prompting strategies. Understanding the nuances of prompt engineering is vital for anyone working with LLMs, as it directly impacts the quality, efficiency, and safety of their applications.
Multimodal Fusion#
Multimodal fusion, the integration of information from diverse sources like text, images, and audio, is crucial for advanced AI. Effective fusion methods are vital for improving performance on complex tasks exceeding the capabilities of unimodal approaches. Challenges exist in handling the heterogeneity of data types, requiring techniques to align and normalize data before fusion. Different fusion strategies exist, from early fusion (combining raw data) to late fusion (combining features extracted from individual modalities). The optimal approach often depends on specific application needs. Furthermore, attention mechanisms are commonly used to weigh the importance of different modalities and improve the efficiency of fusion. Addressing the challenges of missing modalities, where some input sources may be incomplete, is another critical aspect. Methods often incorporate robust imputation techniques and specialized architectures to account for data scarcity. Research continually explores new fusion architectures and learning techniques to enhance the efficiency and accuracy of multimodal processing. Successfully incorporating this information requires careful consideration of computational costs, memory requirements, and interpretability of the fused data. The future of multimodal fusion lies in developing more efficient, robust, and explainable methods.
Future Research#
Future research directions stemming from this work on deep correlated prompting for visual recognition with missing modalities could explore several promising avenues. Extending the approach to handle more than two modalities would enhance its applicability to a wider range of real-world scenarios. Investigating the impact of different backbone architectures beyond CLIP would further assess the method’s generalizability. A key area for future work is developing more sophisticated prompt generation mechanisms. This might involve incorporating external knowledge sources or employing more advanced techniques like reinforcement learning to better tailor prompts to specific missing modality scenarios and input characteristics. Finally, a comprehensive analysis of the computational trade-offs inherent in different prompt learning strategies, including the proposed deep correlated prompting, is needed. This could involve rigorous benchmarking across diverse datasets and hardware platforms to determine optimal parameter settings and resource allocation for various applications. Moreover, future work could focus on evaluating the robustness of the method to adversarial attacks and exploring techniques for enhancing its security and privacy protections. Finally, exploring alternative missing data imputation methods in conjunction with prompt engineering would provide another potential avenue to further optimize performance.
More visual insights#
More on figures
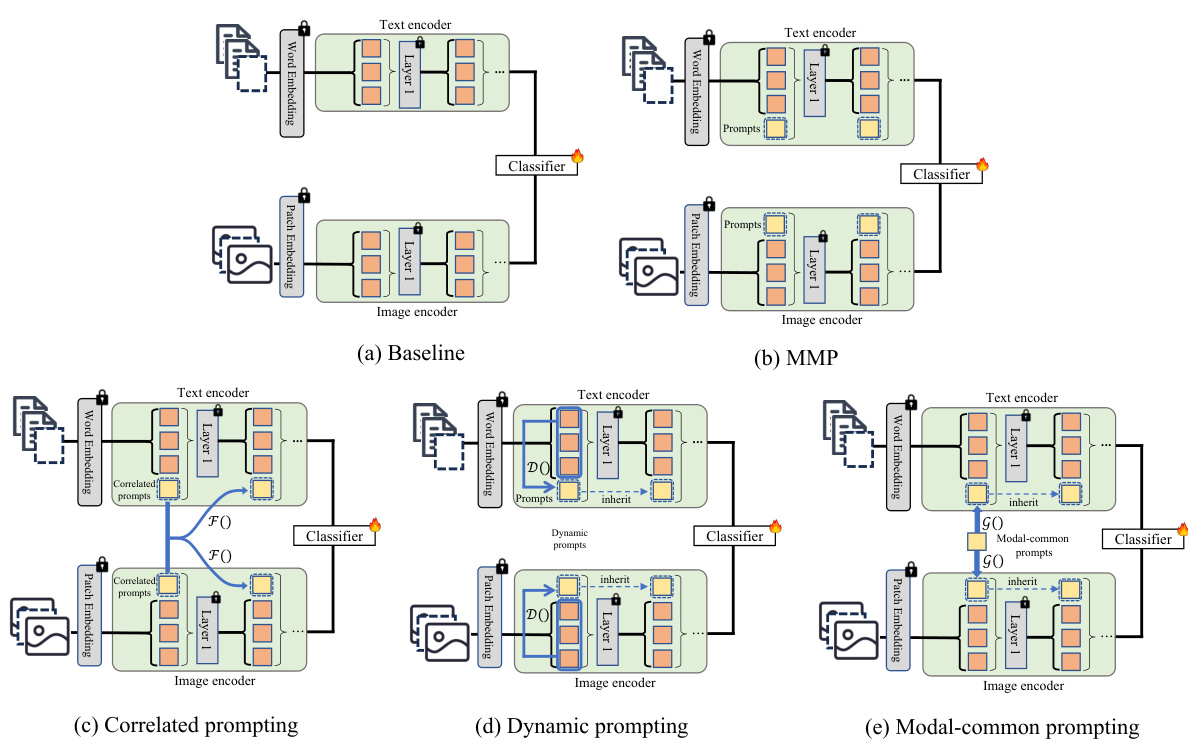
This figure illustrates five different approaches for handling missing modalities in multimodal learning. The baseline uses a standard model with no prompt. MMP uses independent prompts at each layer. Correlated prompting uses prompts that leverage information from previous layers. Dynamic prompting generates prompts based on input features. Modal-common prompting incorporates shared information across modalities.
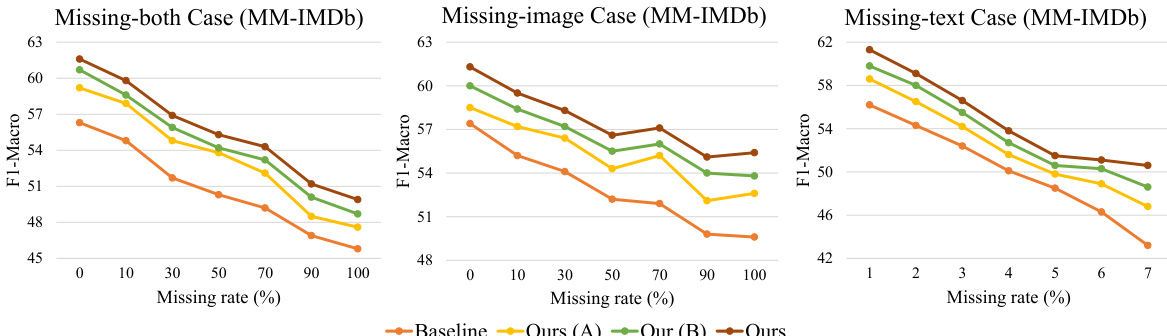
This figure shows the performance comparison of different model variations on the MM-IMDb dataset under various missing modality scenarios. The x-axis represents the missing rate (0% to 100%), and the y-axis represents the F1-Macro score. The baseline model simply ignores missing modalities. Ours(A) uses only correlated prompts, Ours(B) uses correlated and dynamic prompts, and Ours uses all three proposed prompt types (correlated, dynamic, and modal-common). The results demonstrate that incorporating all three prompt types yields the best performance across all missing-modality scenarios and missing rates. The performance degradation is less significant when only images are missing, highlighting the importance of text for this specific task.
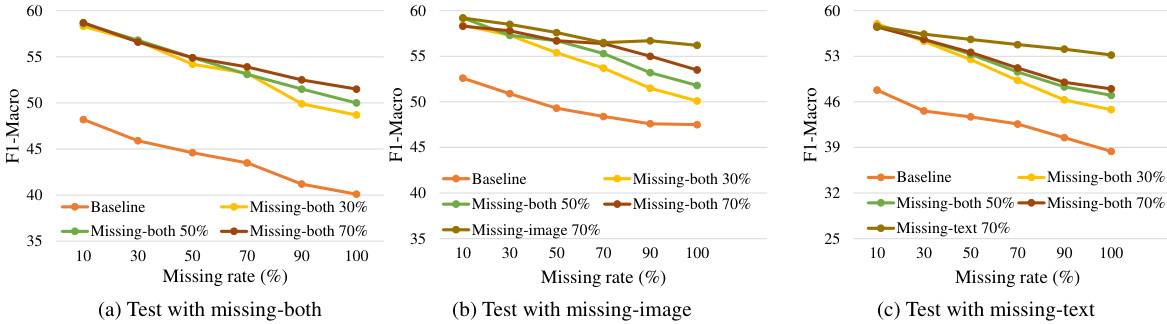
This figure compares the performance of the proposed model (Ours) against a baseline and two intermediate versions (Ours (A) and Ours (B)) across different missing modality scenarios and rates on the MM-IMDb dataset. It shows the effectiveness of incorporating the correlated and dynamic prompts in improving robustness to missing modalities.

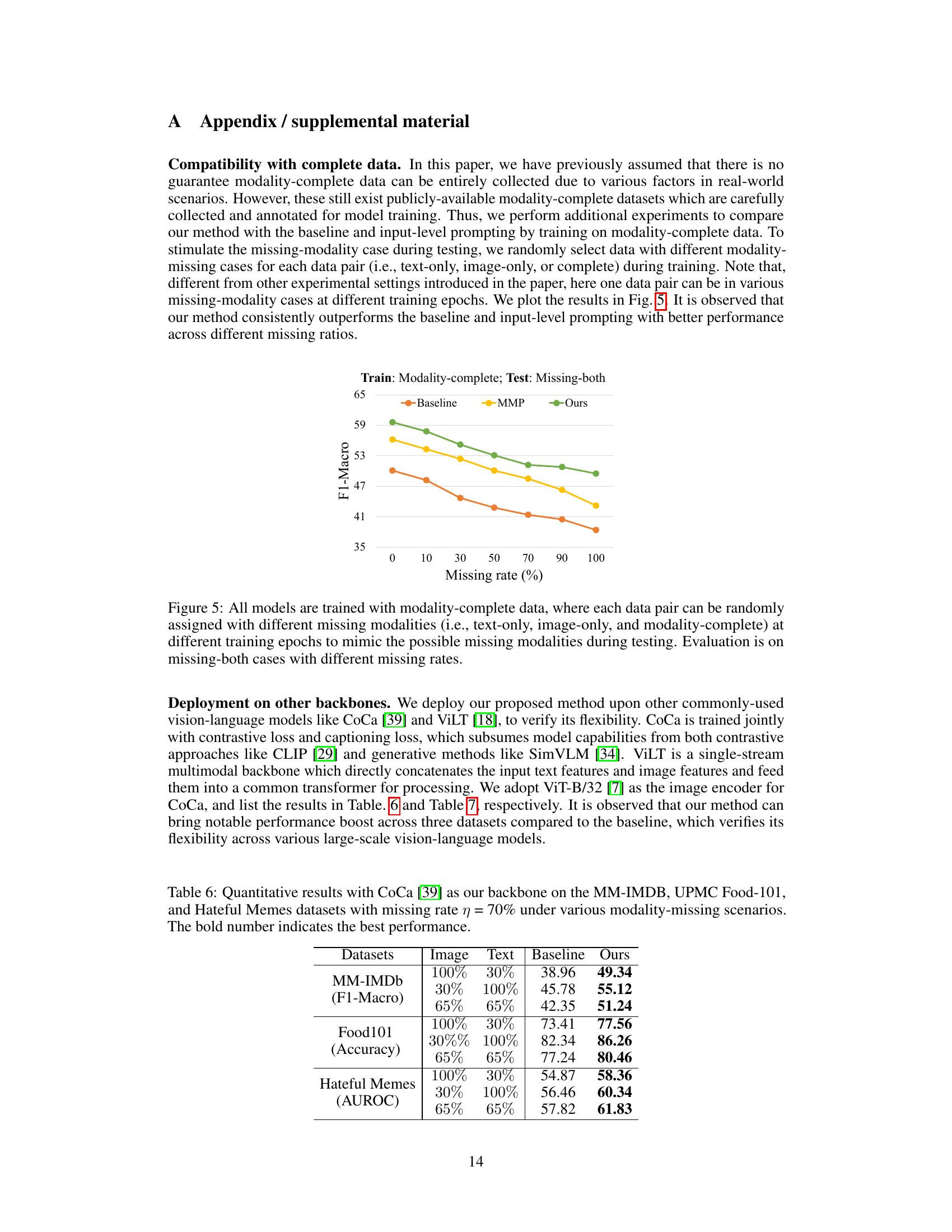
This figure shows the results of an experiment where models are trained on modality-complete data but evaluated on data with both modalities missing (missing-both). The missing rate is varied from 0% to 100%. Three methods are compared: Baseline (simply sets missing features to zero), MMP (uses independent prompts), and the proposed method (Deep Correlated Prompting, DCP). The results demonstrate that DCP consistently outperforms the other two methods across all missing rates.
More on tables

This table presents a comparison of the proposed Deep Correlated Prompting (DCP) method with four other state-of-the-art methods (CoOp, MMP, MaPLe, and DePT) for handling missing modalities in multimodal learning. The comparison is performed across three different datasets (MM-IMDb, UPMC Food-101, and Hateful Memes) and various missing modality scenarios (missing image, missing text, missing both) with different missing rates (50%, 70%, 90%). The results are evaluated using appropriate metrics for each dataset (F1-Macro for MM-IMDb, Accuracy for Food101, and AUROC for Hateful Memes). The bold numbers highlight the best performing method for each scenario.

This table presents a comparison of the proposed Deep Correlated Prompting (DCP) method with four other methods (CoOp, MMP, MaPLe, and DePT) for handling missing modalities in multimodal learning. The comparison is done across three different datasets (MM-IMDb, UPMC Food-101, and Hateful Memes) and various missing modality scenarios (image only missing, text only missing, both image and text missing). The results are shown for different missing rates (50%, 70%, and 90%), demonstrating DCP’s performance relative to existing approaches across different datasets and conditions.

This table compares the performance of the proposed Deep Correlated Prompting (DCP) method against several other state-of-the-art methods for handling missing modalities in multimodal learning. The comparison is done across three different datasets (MM-IMDb, UPMC Food-101, and Hateful Memes) and various missing modality scenarios (missing image, missing text, missing both). The results show the F1-Macro score for MM-IMDb, accuracy for Food101, and AUROC for Hateful Memes, demonstrating DCP’s superior performance in most cases.

This table presents the results of ablation studies on the prompt length, focusing on its impact on the F1-Macro score using the MM-IMDb dataset. The experiment was conducted with a missing rate (η) of 70%. The table shows that a prompt length of 36 achieves the best performance.
Full paper#