↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current prompt optimization methods struggle with domain generalization; optimized prompts often perform poorly on unseen data. This research explores this problem and identifies that prompts gaining more attention from deep layers and exhibiting more stable attention distributions generalize better.
This paper introduces the novel “Concentration” objective function to improve prompt optimization methods by promoting both strong and stable attention weights on prompts. Experiments show significant improvements over existing methods in soft and hard prompt generalization across multiple domains, with minimal effect on in-domain performance. This provides a novel and practical solution to existing prompt optimization challenges.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical issue of prompt generalization in language models, a limitation of current prompt optimization techniques. It proposes novel methods to enhance prompt generalization without relying on target domain data, offering a significant advancement in the field. The findings provide key insights into the nature of generalizable prompts and open exciting new avenues for research, potentially leading to more robust and adaptable language models.
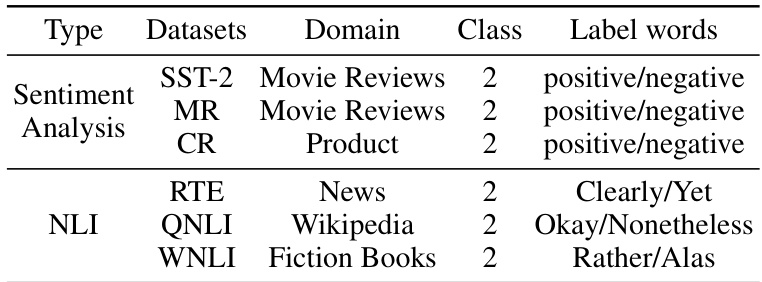
Visual Insights#
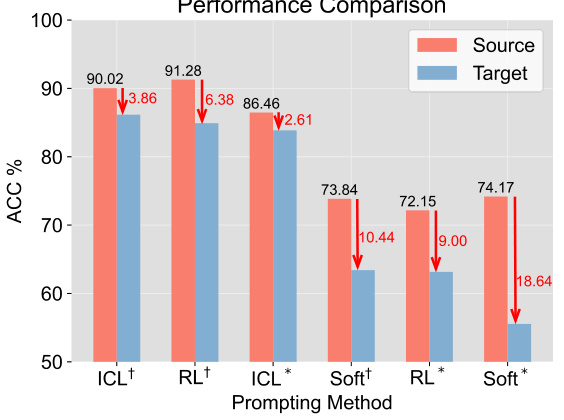
This figure shows the performance comparison of different prompting methods on sentiment classification tasks when performing domain generalization. The x-axis represents different prompting methods. The y-axis represents the accuracy (ACC%). Each bar group shows the accuracy on the source and target domains for each prompting method. The red arrows show the performance drop in accuracy when generalizing to the target domain.

This table compares the performance of various prompt optimization methods on text classification tasks under the Multi-source Few-shot Domain Generalization (MFDG) setting. It shows the accuracy of different methods, separating soft prompt and hard prompt approaches. The table highlights the impact of the proposed ‘Concentration’ objective on improving the domain generalization capability of prompts, showing accuracy improvements for both soft and hard prompt methods.
In-depth insights#
Prompt Generalization#
Prompt generalization, a crucial aspect in the practical application of prompt-based learning, focuses on enhancing the adaptability of optimized prompts to unseen domains or tasks. The core challenge lies in creating prompts that generalize well beyond the specific data they were trained on. This is particularly relevant in scenarios with limited data availability, where the robustness of prompts against distributional shifts becomes paramount. Effective prompt generalization strategies are essential for mitigating overfitting and improving the overall reliability and scalability of prompt-based methods. Research in this area explores techniques to encourage prompt robustness through techniques like data augmentation, regularization, and the incorporation of domain-invariant features. The ultimate goal is to develop prompts that are not only highly effective in their target domain, but also exhibit strong generalization capabilities, enabling wider applicability and broader utility of prompt-based approaches in various real-world applications.
Concentration Metric#
A hypothetical “Concentration Metric” in a research paper analyzing prompt optimization for language models would likely quantify how effectively a prompt captures the model’s attention. High concentration suggests the prompt strongly influences the model’s output, potentially indicating better performance and generalization. The metric might consider the attention weights assigned to prompt tokens across different layers of the model. Deep layers are often associated with higher-level semantic understanding, thus, a concentration metric focusing on these layers could highlight prompts that effectively guide the model’s reasoning process. Furthermore, a robust metric should also account for the stability of attention distribution across various inputs; a stable, high concentration suggests a prompt generalizes well. This contrasts with unstable attention where the prompt’s influence varies significantly. Therefore, the metric must balance both attention weight and its stability, offering a comprehensive evaluation of prompt effectiveness in guiding the model’s performance.
Soft Prompt Tuning#
Soft prompt tuning represents a powerful method within the broader field of prompt engineering for language models. Instead of altering the model’s weights directly, it focuses on optimizing a continuous vector (the soft prompt) that is prepended or appended to the input text. This approach allows the model to adapt to specific tasks or domains without significant retraining. A key advantage is its parameter efficiency, requiring far fewer trainable parameters than traditional fine-tuning. This makes it computationally cheaper and faster, particularly beneficial in resource-constrained environments or when dealing with massive language models. However, soft prompt tuning also presents challenges. The optimization process itself can be complex, requiring careful selection of hyperparameters and potentially vulnerable to overfitting or poor generalization if not carefully tuned. Despite these challenges, soft prompt tuning provides a flexible and efficient method to improve language model performance on downstream tasks, making it a valuable technique for various NLP applications.
Hard Prompt Matching#
The concept of “Hard Prompt Matching” in the context of prompt optimization for language models presents a unique challenge and opportunity. It addresses the problem of selecting the most effective prompt from a discrete set for a given input, particularly within the domain generalization setting. The core idea revolves around improving the efficiency and effectiveness of prompt selection, potentially through techniques like reinforcement learning. The method seems to be particularly beneficial for scenarios with diverse domains or when large prompt sets require efficient filtering. Multi-agent reinforcement learning is suggested to solve the problem of a potentially large prompt space, and the method proposes using a novel metric to filter and select prompts that are most effective. A key advantage is the ability to handle multiple domains simultaneously, making the selection process more robust and applicable across different datasets. The approach’s success hinges on the accuracy and efficiency of the proposed filtering metric, and the effectiveness of the multi-agent learning strategy in exploring the large prompt space. Overall, it demonstrates a sophisticated and potentially powerful approach to prompt engineering in complex scenarios.
Future Work & Limits#
Future work should address the limitations of focusing primarily on classification tasks. Expanding to other NLP tasks like question answering, text summarization, and natural language generation is crucial to demonstrate broader applicability. The current reliance on a limited set of prompts necessitates exploring diverse prompt types and strategies for prompt generation. Additionally, rigorous testing on larger, more diverse datasets is needed to assess the generalizability of the proposed methods. Addressing the reliance on a specific model architecture (RoBERTa-Large) by testing across different PLMs is important to confirm the findings’ universality. The research could also benefit from exploring different prompt optimization methods to better understand which are best suited for domain generalization.
More visual insights#
More on figures

The figure illustrates the concept of ‘Concentration’, a key concept in the paper. It shows how the model’s attention mechanism focuses on the prompt tokens during the decoding process. The prompt tokens are represented in blue, the input sequence in yellow, and the attention weights are shown as curves connecting the prompt and input tokens. The intensity of the curves visually represents the strength of attention. The figure highlights that prompts with higher concentration (stronger attention weights) are more effective and generalize better.

This figure shows the correlation between concentration strength and fluctuation with domain generalization performance. The left panel displays the concentration strength across different layers (19-23) of the model for various prompting methods. The right panel provides box plots showing the distribution of the concentration strength in the last layer for each method. The results suggest that prompts with higher concentration strength and lower concentration fluctuation generally exhibit better domain generalization performance.

This figure illustrates the framework for soft prompt optimization. It shows how the proposed concentration-reweighting loss function is integrated into the optimization process. The framework begins with prompted inputs (xᵢ, yᵢ) which are processed to optimize the soft prompt (z). The optimization involves minimizing two loss functions: Lcs (based on finding F1: more attention weight) and Lcf (based on finding F2: more stable attention distribution), in addition to the standard cross-entropy loss (Lce). The final output is an optimized soft prompt that improves the model’s performance.

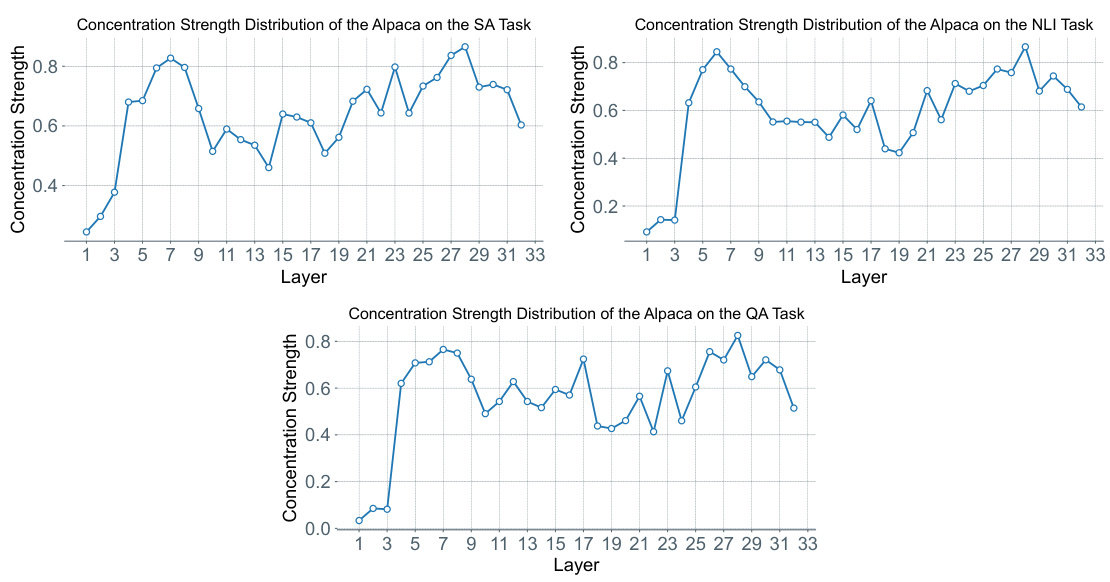
The figure displays the distribution of concentration strength across different layers of the RoBERTa-Large model for various prompting methods. It shows that the concentration strength is generally higher in deeper layers compared to shallower layers, indicating that prompts are better concentrated in the deeper layers of the model. The different line styles represent different prompting methods (ICL+, RL+, Soft, ICL*, RL*, Soft*), highlighting that some prompts consistently maintain a higher concentration strength across layers than others. This observation supports the paper’s findings that prompts with higher and more stable concentration in deeper layers of the PLM are more generalizable.

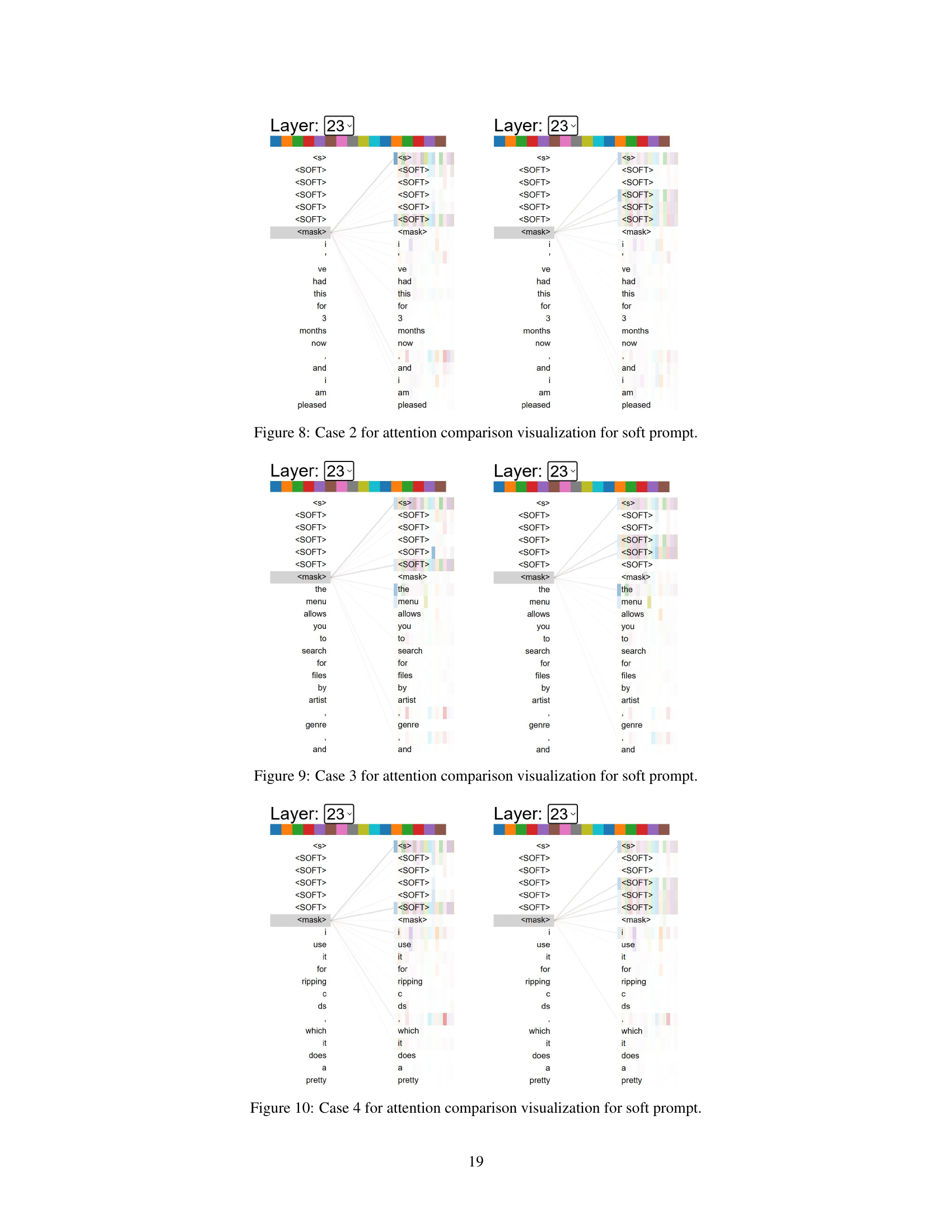
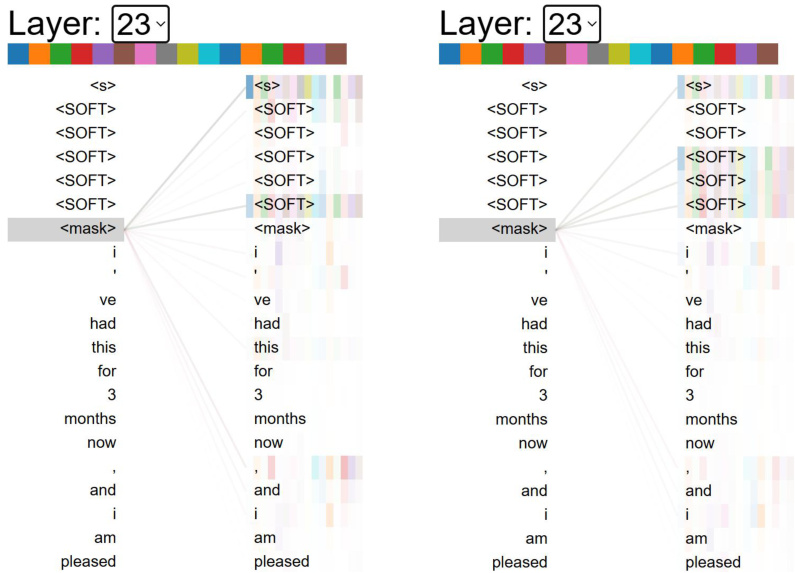
The figure visualizes the attention weights of a soft prompt before and after optimization using the proposed method. It shows how the optimized prompt focuses attention more effectively on relevant tokens compared to the original prompt, demonstrating the improved concentration and stability of attention.

This figure shows the distribution of concentration strength for different prompts across various layers of the RoBERTa-Large model. It demonstrates that prompts generally exhibit stronger concentration in deeper layers of the model compared to shallower layers. The variations in the maximum concentration strength across different prompts are also evident.

This figure displays the concentration strength and fluctuation of various prompting methods across different layers of a language model. The left panel shows a bar chart visualizing the concentration strength across layers 19-23, while the right panel presents boxplots summarizing the concentration strength in the last layer (layer 23). The results suggest that prompts with higher concentration strength and lower concentration fluctuation tend to generalize better across domains.
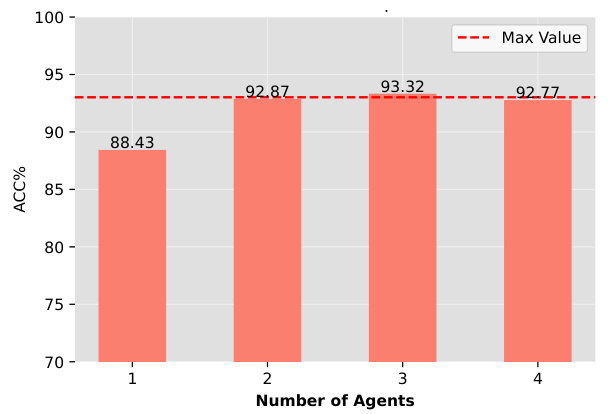
This figure shows the impact of the number of agents used in the multi-agent reinforcement learning framework proposed in the paper. As the number of agents increases from one to three, the classification accuracy on the target domain improves significantly, reaching a maximum at three agents. However, further increasing the number of agents to four does not result in a substantial increase in accuracy, suggesting that the ensemble decision from a sufficient number of agents provides stable and reliable results. The figure indicates an optimal range of agents where adding more does not yield better results.

The figure shows the distribution of concentration strength for different prompts across various layers of a ROBERTa-Large model. It illustrates the finding from the paper’s pilot experiments that prompts with higher concentration strength in deeper layers tend to be more generalizable. Each sub-figure represents a different prompting method (ICL+, RL+, Soft, ICL*, RL*, Soft*), and the x-axis indicates the layer number while the y-axis shows the concentration strength.
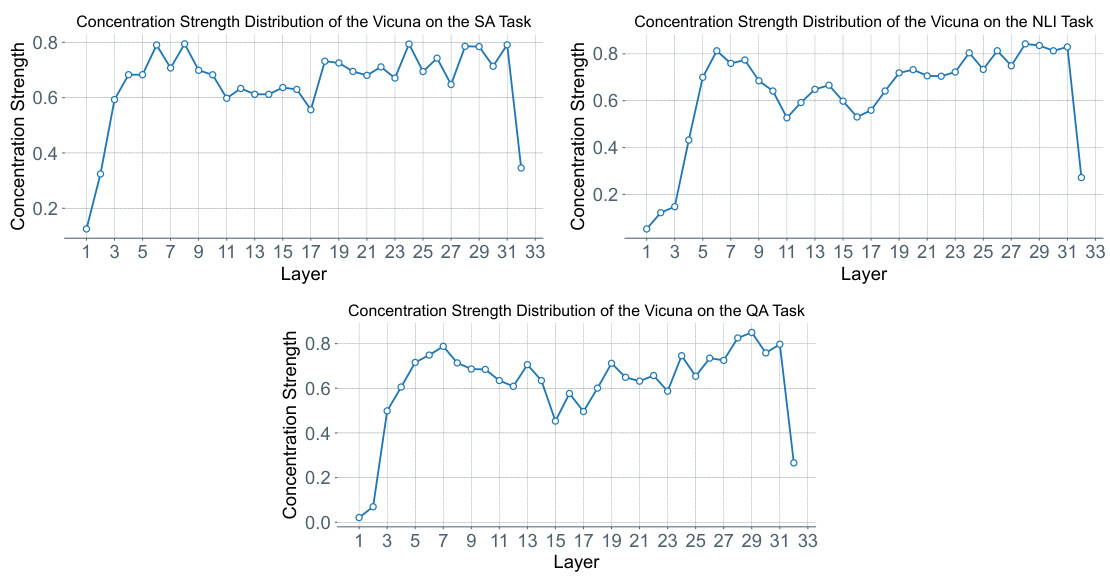
This figure shows the distribution of concentration strength across different layers of the Vicuna language model for three different tasks: Sentiment Analysis (SA), Natural Language Inference (NLI), and Question Answering (QA). The x-axis represents the layer number, and the y-axis represents the concentration strength. Each line shows the concentration strength at each layer for a specific task. The figure demonstrates how the concentration strength varies across different layers and tasks, providing insights into the model’s attention patterns.
This figure visualizes the distribution of concentration strength across different layers of the ROBERTa-Large language model for various prompts. It shows that for most prompts, the concentration strength tends to be higher in deeper layers of the network than in shallower layers. However, the maximum concentration strength varies between prompts. This suggests that the location and magnitude of attention weight on prompts may relate to the generalization ability of the prompts.
More on tables

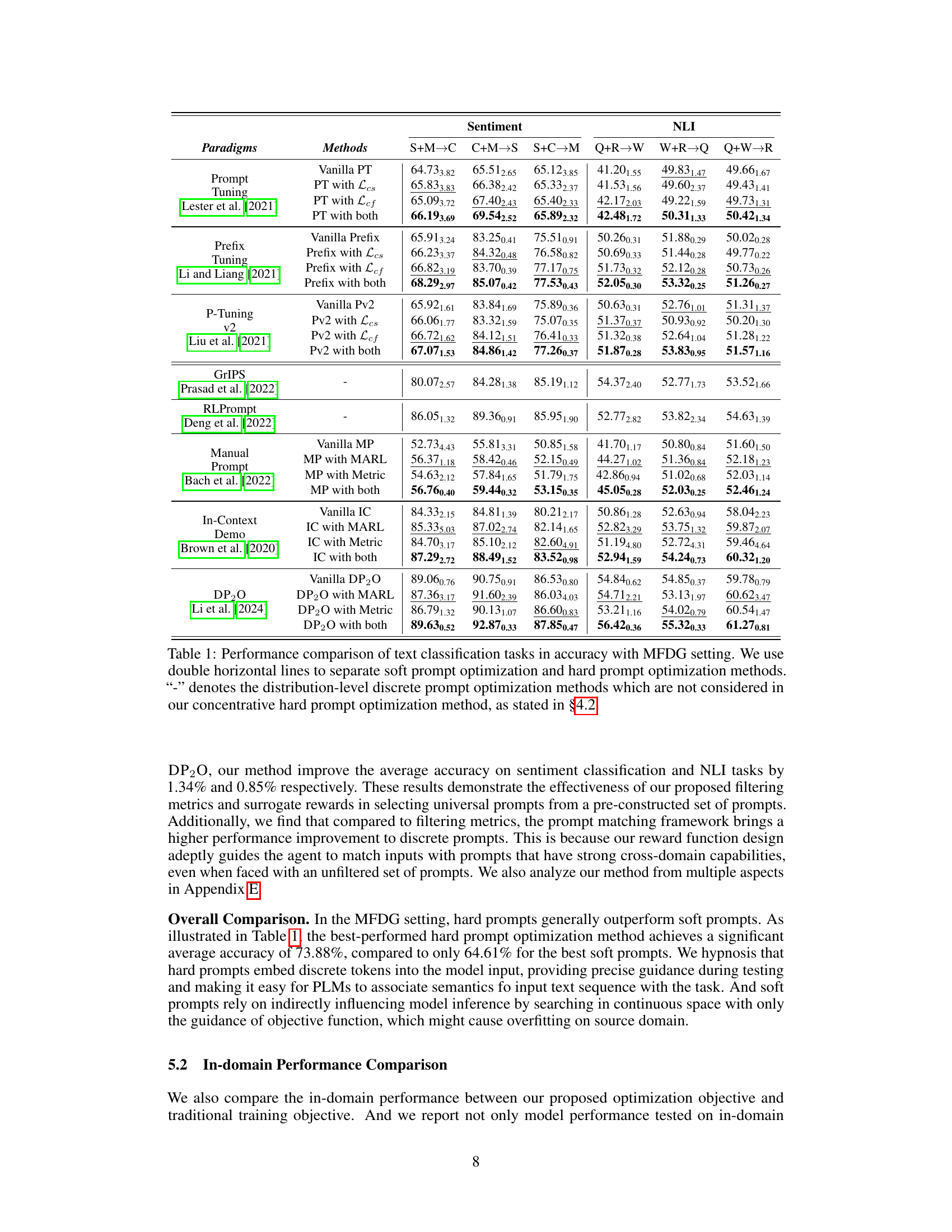
This table compares the performance of various prompt optimization methods on sentiment classification and natural language inference tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by different methods on several datasets, categorized as soft prompt methods, hard prompt methods, and distribution-level methods. The results are presented to highlight the differences in performance between these methods under the MFDG condition where the model is tested on an unseen domain.

This table compares the performance of various soft and hard prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by different methods across various sentiment and natural language inference (NLI) tasks, highlighting the effectiveness of the proposed concentrative prompt optimization methods in improving domain generalization ability while maintaining in-domain performance.
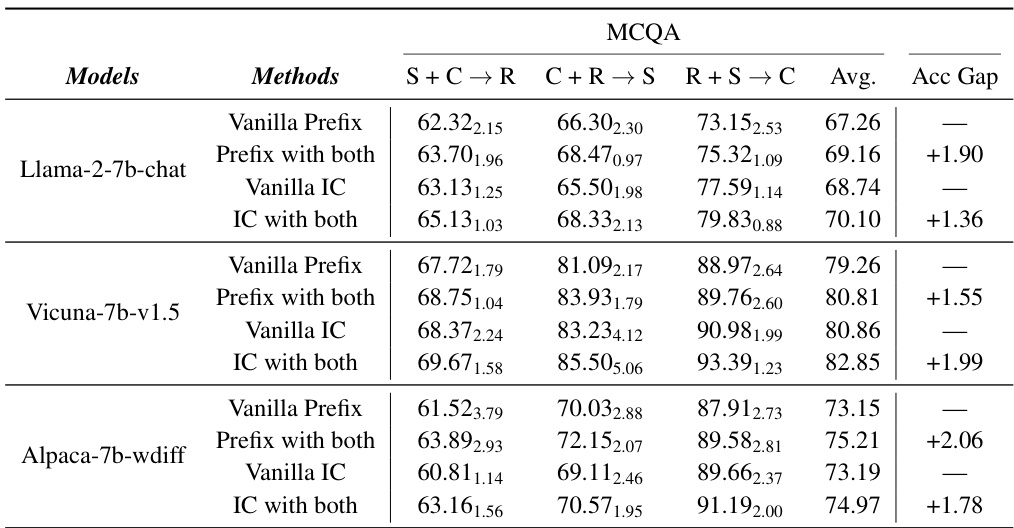
This table presents a comparison of the performance of various prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by different methods on various datasets, distinguishing between soft and hard prompt optimization techniques. Notably, it highlights the improvements achieved by the proposed concentrative prompt optimization methods, demonstrating their effectiveness in enhancing the generalization capabilities of prompts across various domains.
This table compares the performance of various prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows accuracy results for soft prompt and hard prompt methods, highlighting the improvements achieved by the proposed concentrative approach. Distribution-level methods are excluded from the concentrative hard prompt comparison.

This table compares the performance of various prompt optimization methods (both soft and hard prompt methods) on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. The table shows the accuracy achieved by each method on various sentiment analysis and natural language inference datasets. It highlights the performance differences between soft and hard prompt methods and indicates that the proposed method outperforms existing methods in the MFDG setting.

This table compares the performance of various prompt optimization methods (both soft and hard prompt methods) on text classification tasks using the Multi-source Few-shot Domain Generalization (MFDG) setting. The results show accuracy scores for each method across different datasets and tasks, highlighting the differences in performance between soft and hard prompt approaches and various domain generalization techniques. The table is divided into sections by prompt optimization paradigm and the effectiveness of proposed methods is compared against baselines. Note that distribution-level discrete prompt optimization methods are not included in the concentrative hard prompt optimization method comparison.
This table presents the performance comparison of various methods for text classification tasks under the Multi-source Few-shot Domain Generalization (MFDG) setting. It compares several soft prompt and hard prompt optimization techniques, showing the accuracy achieved by each on different sentiment classification and natural language inference datasets. The results are categorized into two main groups: soft prompt methods and hard prompt methods, helping assess the effectiveness of these approaches for cross-domain generalization.

This table compares the performance of various prompt optimization methods (both soft and hard prompt methods) on text classification tasks using the Multi-source Few-shot Domain Generalization (MFDG) setting. The table shows accuracy results for sentiment classification and natural language inference (NLI) tasks across several source and target domains. The results highlight the effectiveness of the proposed methods (with Lcs, Lcf, MARL, or a combination) in improving domain generalization performance compared to existing baseline methods. The table is divided into soft and hard prompt optimization methods, showing the relative improvements. The methods denoted by ‘-’ are excluded from the hard prompt method comparison.

This table compares the performance of various soft and hard prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by each method on different datasets, highlighting the improvement achieved by the proposed concentrative prompt optimization methods. The table is divided into soft and hard prompt optimization methods, demonstrating the effectiveness of the proposed method in both categories. Note that some distribution-level methods are not included in the hard prompt section because they are not directly comparable to the proposed method.

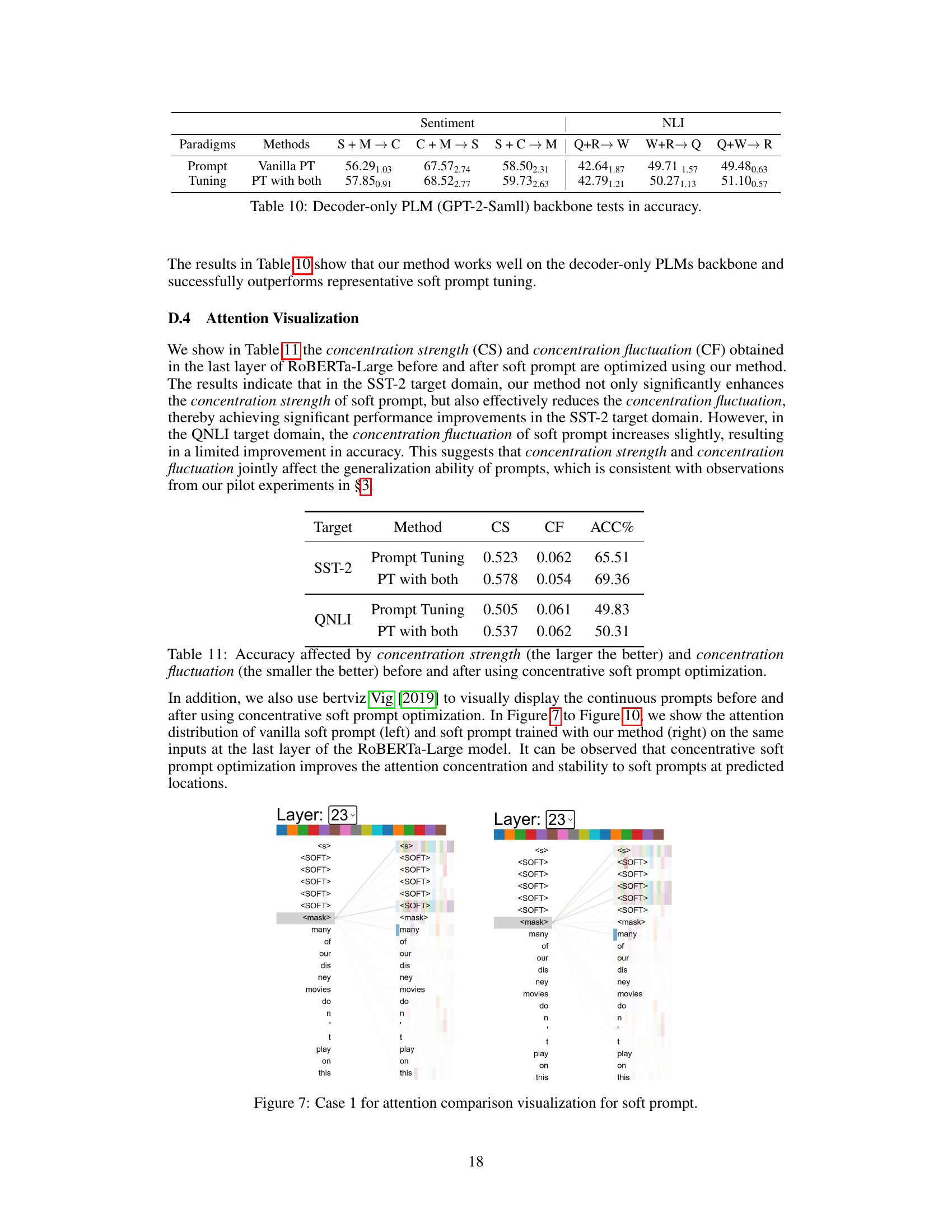
This table presents a comparison of the stability of soft prompts under various initialization strategies. It shows the performance of the ‘PT with both’ method (Prompt Tuning with both concentration strength and fluctuation loss) and vanilla Prompt Tuning across five initialization methods: Random, Label, Vocab, Top-1k, and Task. The results demonstrate that the ‘PT with both’ method improves stability compared to vanilla Prompt Tuning, with lower standard deviations in accuracy on the SST-2 and QNLI target domains.

This table compares the performance of various soft and hard prompt optimization methods on sentiment classification and natural language inference tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by each method across different source and target domain combinations, highlighting the effectiveness of the proposed ‘concentrative prompt optimization’ methods in improving domain generalization while maintaining in-domain performance.

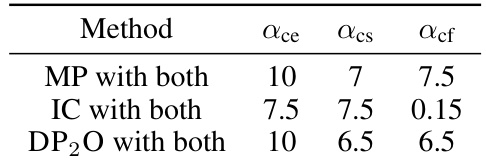
This table shows the impact of using the concentrative soft prompt optimization method on the concentration strength (CS) and concentration fluctuation (CF), and the accuracy (ACC%) achieved on the SST-2 and QNLI datasets. The results indicate whether increasing concentration strength and decreasing concentration fluctuation improve model accuracy in different datasets.
This table compares the performance of various prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy of different methods across multiple datasets and domains. The table is divided into soft prompt and hard prompt optimization methods, highlighting the effectiveness of the proposed ‘concentrative’ approach. Distribution-level methods are excluded from the concentrative hard prompt comparison.

This table compares the performance of various soft and hard prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. The results show accuracy and demonstrate the improvement achieved by the proposed concentrative prompt optimization methods over existing methods.

This table compares the performance of various soft and hard prompt optimization methods on text classification tasks using a multi-source few-shot domain generalization (MFDG) setting. It shows the accuracy achieved by each method on several datasets, highlighting the improvement achieved by incorporating the proposed ‘Concentration’ objective. The table is divided into soft and hard prompt methods, with the best-performing methods in each category achieving higher accuracy scores.

This table compares the performance of various soft and hard prompt optimization methods on text classification tasks using the Multi-source Few-shot Domain Generalization (MFDG) setting. It shows the accuracy achieved by each method across multiple datasets, highlighting the effectiveness of the proposed concentrative prompt optimization methods in improving domain generalization ability while maintaining in-domain performance. Distribution-level methods are excluded from the concentrative hard prompt optimization comparison.

This table compares the performance of various prompt optimization methods on text classification tasks using the Multi-source Few-shot Domain Generalization (MFDG) setting. It shows the accuracy achieved by different methods, separating soft and hard prompt optimization approaches. The table also highlights the improvements achieved by incorporating the proposed ‘concentration’ objective into existing methods.
Full paper#