↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current end-to-end speech-to-speech translation models struggle with performance and data scarcity, especially in preserving speaker characteristics and isochrony (consistent timing). This paper introduces TransVIP, a novel framework that uses a consecutive generation approach with joint probability to tackle the challenges. It employs separate encoders to preserve voice and timing, effectively using diverse datasets despite data limitations.
TransVIP achieves superior performance, surpassing state-of-the-art models in translation accuracy and quality. The method’s effectiveness is demonstrated through experiments on French-English translation, showing improvements in BLEU score, speaker similarity, and isochrony control, while using a textless model for acoustic detail generation. The work demonstrates that utilizing different encoders for distinct information (semantic, acoustic, isochrony) significantly improved the model accuracy and preserved the source speech’s characteristics.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents TransVIP, a novel speech-to-speech translation framework that outperforms current state-of-the-art models while preserving speaker voice and isochrony. This is crucial for applications like video dubbing, where maintaining speaker identity and timing is vital. The study’s novel approach to feature disentanglement and joint probability inference opens new avenues for research in end-to-end speech translation, potentially improving the quality and naturalness of translated speech. The release of the code and audio samples further enhances the research community’s ability to reproduce and build upon this work.
Visual Insights#
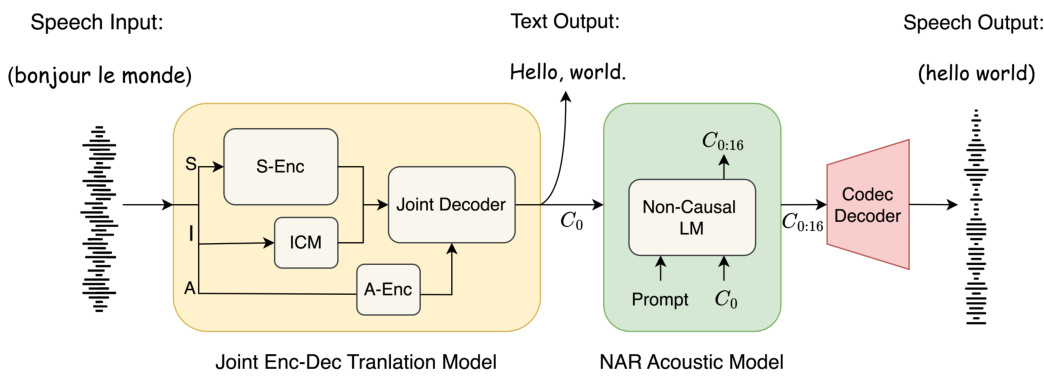
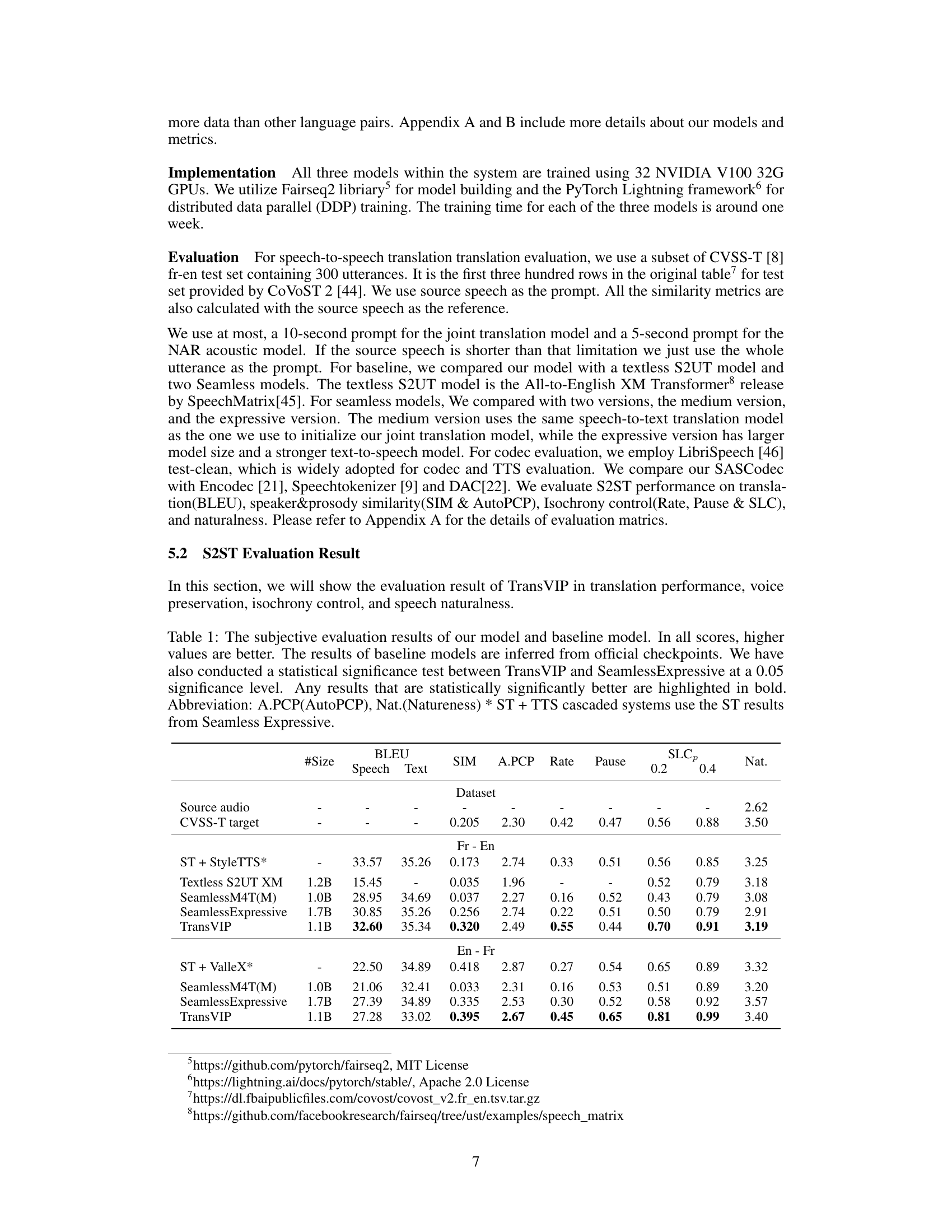
This figure presents a high-level overview of the TransVIP speech-to-speech translation framework. The framework consists of three main modules: 1) A joint encoder-decoder model that processes the input speech to produce both text and a sequence of coarse-grained speech tokens; 2) a non-autoregressive acoustic model that refines these tokens using acoustic details; and 3) a codec model that converts the refined tokens back into the final speech waveform. The figure highlights the flow of information and the roles of different components in preserving speaker voice characteristics and isochrony during the translation process.
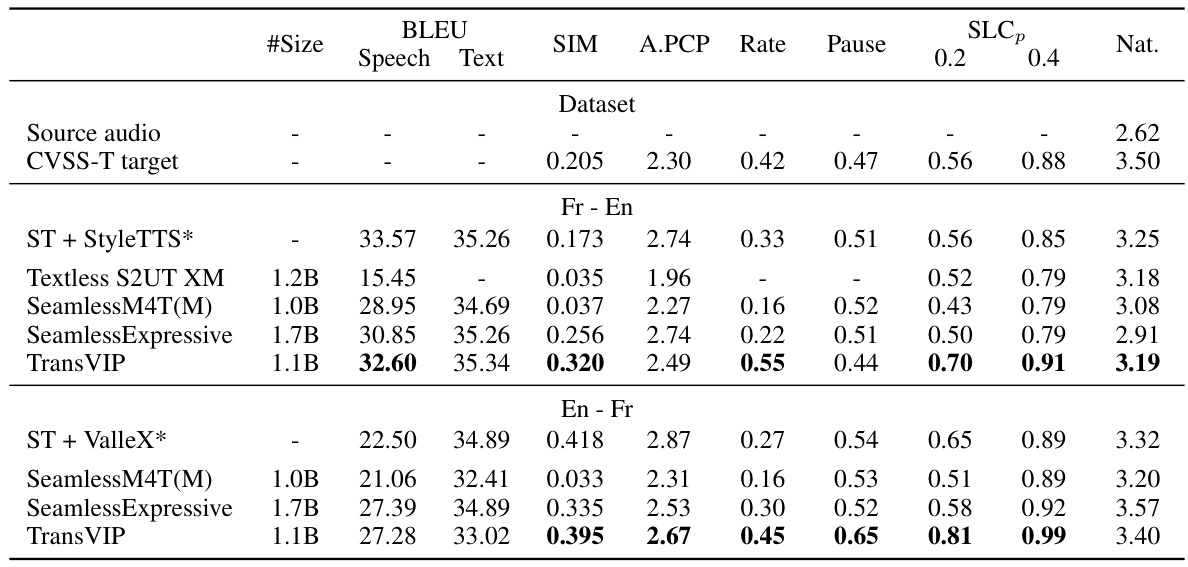
This table presents a subjective evaluation of the TransVIP model and several baseline models for speech-to-speech translation. Metrics include BLEU score, speaker and prosody similarity, isochrony control (speech rate, pauses, and length consistency), and naturalness. Statistical significance testing is performed against the SeamlessExpressive model.
In-depth insights#
S2ST Cascade#
A hypothetical ‘S2ST Cascade’ in a speech-to-speech translation (S2ST) research paper would likely refer to a multi-stage, cascaded approach where the translation process is broken down into sequential steps. Each stage, potentially using different models, would refine the output from the preceding stage. This might involve initial Automatic Speech Recognition (ASR) to convert source speech into text, followed by Machine Translation (MT) to translate the recognized text into the target language, and finally Text-to-Speech (TTS) synthesis to generate the final translated speech. The key challenge with this approach is the accumulation of errors across stages; inaccuracies at early stages get amplified in subsequent steps, potentially impacting overall translation quality and naturalness. An important research focus in S2ST would be to investigate how to mitigate error propagation and improve the overall coherence and fluency of the cascaded model’s output. Improvements could focus on integrating intermediate representations or refining the model architecture for better flow of information. The cascade design offers modularity and flexibility for integrating specialized models to handle specific aspects (speaker identity, isochrony), but presents inherent limitations in terms of overall efficiency and error control compared to end-to-end approaches.
Voice Disentanglement#
Voice disentanglement, in the context of speech-to-speech translation, refers to the process of separating and preserving a speaker’s unique vocal characteristics from other aspects of speech, such as the linguistic content and background noise. This is crucial because it allows the system to translate the speech while retaining the speaker’s identity, making the output sound more natural and engaging. Approaches to voice disentanglement often involve using separate encoders to process acoustic and semantic information. The acoustic encoder focuses on extracting speaker-specific features from the speech waveform, while the semantic encoder handles the linguistic content. These features are then combined in a way that allows the model to generate translated speech while maintaining the original speaker’s voice. The effectiveness of voice disentanglement heavily depends on the quality and diversity of the training data. Datasets with recordings from multiple speakers across various linguistic contexts are necessary for training robust models that can handle different accents, speaking styles, and levels of background noise. Challenges in voice disentanglement include the inherent difficulty of isolating voice from other factors in complex speech signals, as well as the potential for information loss or distortion during the separation process. Further research is needed to develop more effective and efficient methods that can achieve high-fidelity voice preservation while maintaining high-quality translation.
Multi-task Learning#
Multi-task learning (MTL) in the context of speech-to-speech translation (S2ST) is a powerful technique to leverage the relationships between different tasks to improve overall performance. By jointly training models for speech recognition, machine translation, and text-to-speech, MTL can address data scarcity issues common in S2ST by using data from related tasks to augment the training data for the primary task. This approach also facilitates end-to-end inference, despite leveraging a cascade architecture during training, by learning a joint probability distribution. Furthermore, MTL enables disentanglement of features, such as speaker voice characteristics and isochrony, through separate encoders, allowing for better preservation of these aspects during translation. The effectiveness of MTL in this context demonstrates its potential for creating more robust and efficient S2ST systems that overcome the limitations of individual task-specific models and limited datasets.
Isochrony Control#
The concept of ‘Isochrony Control’ in speech-to-speech translation is crucial for achieving natural-sounding output. It addresses the challenge of maintaining temporal consistency between the source and target speech, ensuring that the translated speech maintains the original’s rhythm and timing. Preserving isochrony is particularly important in applications like video dubbing where synchronization with visual cues is paramount. The paper likely explores methods for controlling the duration and temporal characteristics of the generated speech. This could involve techniques such as explicitly modeling the duration of speech segments, incorporating temporal information into the model architecture, or using specialized modules to control the rate and pauses in the generated speech. Effective isochrony control contributes significantly to the overall naturalness and fluency of the translated speech, enhancing the user experience. The implementation might involve mechanisms for adjusting the speed of the generated audio, adding or removing pauses, or aligning the temporal structure of the target speech with that of the source speech. Success in this aspect significantly improves the quality and realism of the final output, especially in applications requiring precise temporal alignment such as video dubbing, voiceovers, or real-time translation.
Future S2ST#
Future research in speech-to-speech translation (S2ST) should prioritize robustness and generalization. Current models often struggle with noisy audio, diverse accents, and low-resource languages. Addressing these limitations is crucial for real-world applications. Multimodality, integrating visual cues or other contextual information, holds significant promise for improved accuracy and naturalness. Further research into disentangled representations will allow for better control over aspects like voice quality, emotion, and speech rate. Efficient architectures are also needed to reduce computational costs and enable deployment on resource-constrained devices. Investigating zero-shot and few-shot learning paradigms could significantly reduce data requirements for new languages or speaker styles. Finally, advancing evaluation metrics that comprehensively assess the various aspects of S2ST, such as naturalness, fluency, speaker similarity and isochrony is needed to guide future development and facilitate comparisons.
More visual insights#
More on figures
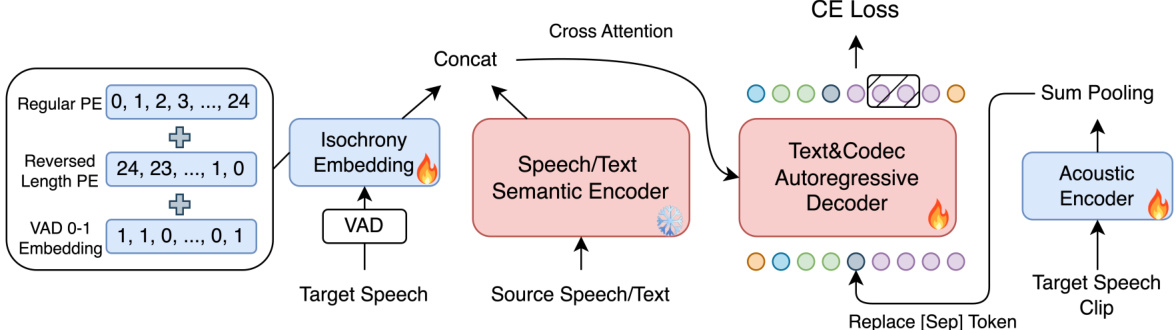
This figure illustrates the training framework of the Joint Encoder-Decoder model. It shows how the model processes source speech/text and target speech to generate the target speech. During training, only a sub-part of the target speech (a clip) is used as a prompt, and the loss is calculated only on that portion. The semantic encoder is pretrained and frozen during training, while the decoder is trained to generate text and codec tokens. During inference, the target speech prompt is replaced with source speech.
This figure illustrates the TransVIP speech-to-speech translation framework, which consists of three main components: a joint encoder-decoder model for text translation and generating coarse speech tokens; a non-autoregressive acoustic model for refining the acoustic details; and a codec model for converting discrete tokens into waveforms. The diagram shows the flow of information from speech input to speech output, highlighting the role of different components in preserving speaker voice characteristics and isochrony.
More on tables
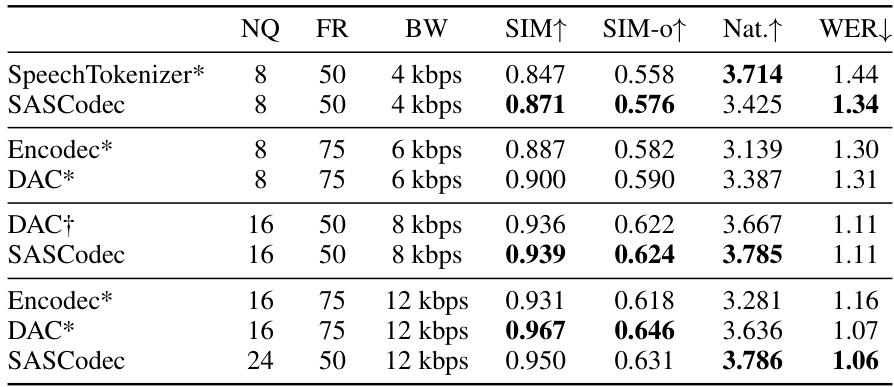
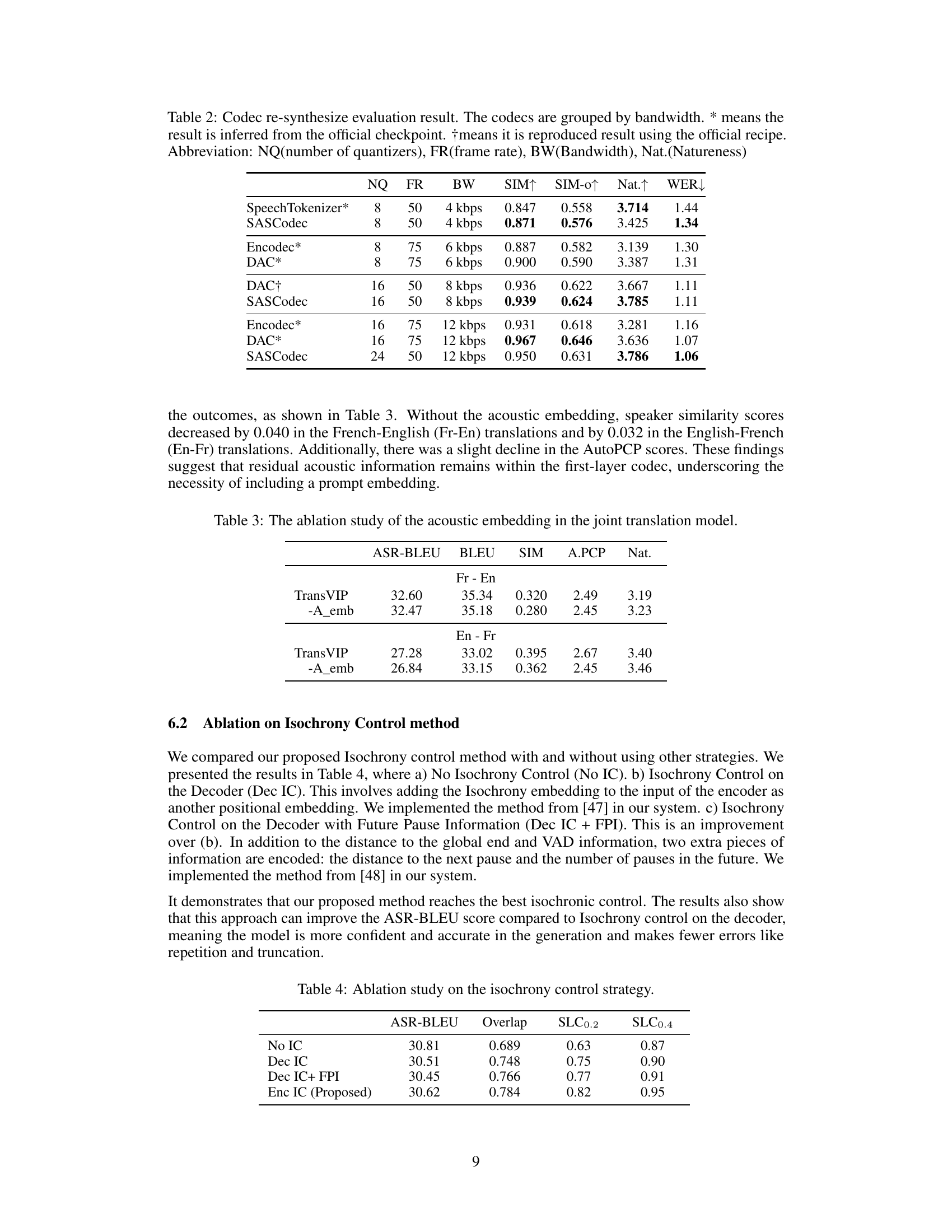
This table presents the results of re-synthesizing audio using different neural codecs. The codecs are compared based on several metrics: the number of quantizers (NQ), frame rate (FR), bandwidth (BW), speaker similarity (SIM), speaker similarity using only the first 3 seconds of audio (SIM-0), naturalness (Nat.), and word error rate (WER). The results are grouped by bandwidth to show the trade-offs between quality and compression.
This table presents a subjective evaluation comparing TransVIP’s performance against several baseline models for speech-to-speech translation. Metrics include BLEU score, speaker similarity, prosody similarity, isochrony control, and naturalness. Statistical significance testing was performed.
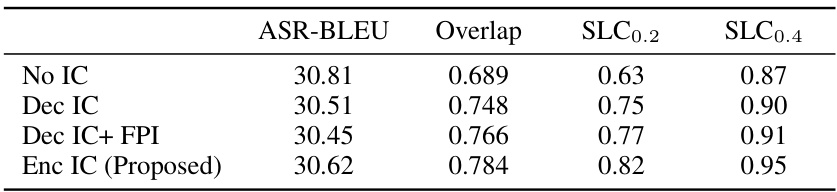
This table presents the ablation study results on different isochrony control methods. It compares the performance of four approaches: No Isochrony Control (No IC), Isochrony Control on the Decoder (Dec IC), Isochrony Control on the Decoder with Future Pause Information (Dec IC + FPI), and the proposed Encoder Isochrony Control (Enc IC). The metrics used for comparison are ASR-BLEU, Overlap, SLC0.2, and SLC0.4. The results show that the proposed Enc IC method achieves the best isochrony control.

This table presents the ablation study results on the Non-autoregressive (NAR) Acoustic model, comparing its performance with and without text input and with and without the Layer Beam Search (LBS) algorithm. The metrics used for comparison are Speaker Similarity (SIM), ASR-BLEU (translation performance), and Naturalness (Nat.).

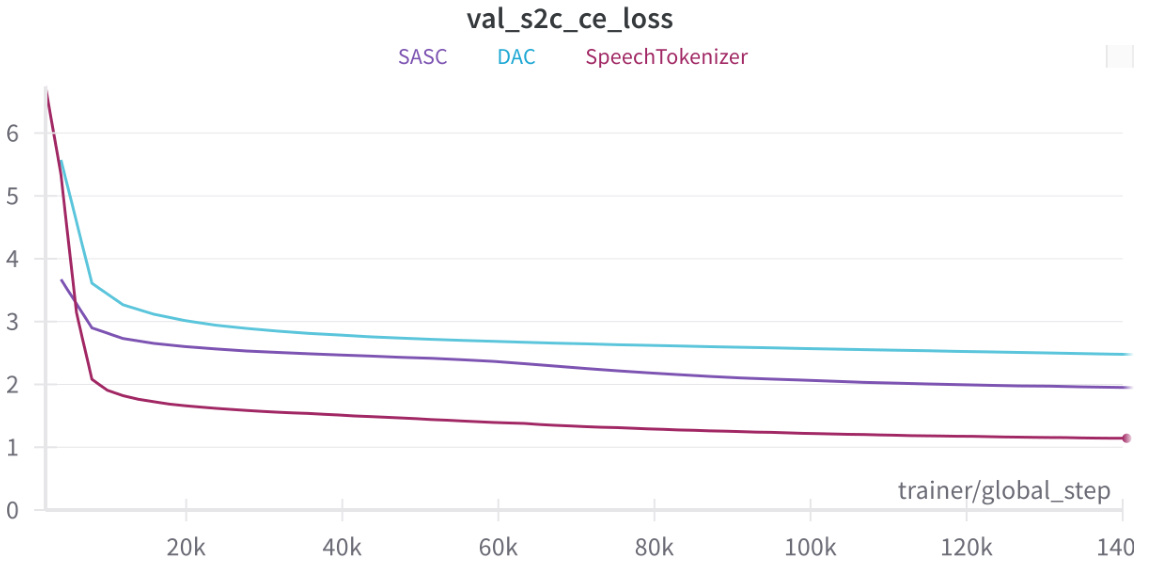
This table presents the ablation study comparing different codec models used in the TransVIP system. The results show the impact of using SpeechTokenizer versus SASCodec on various metrics, including BLEU scores (for both speech and text), speaker similarity (SIM), isochrony control (SLC at p=0.2 and p=0.4), and naturalness (Nat.). The SASCodec shows improvements across the board, suggesting that the proposed codec is more effective.

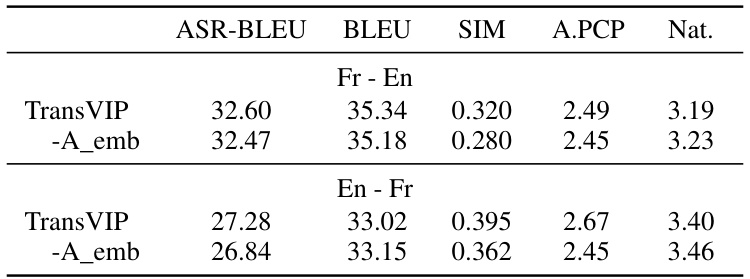
This table presents a subjective evaluation comparing TransVIP against several baseline models for speech-to-speech translation. Metrics include BLEU score (translation quality), speaker and prosody similarity, isochrony control (how well the translated speech matches the length of the original), and naturalness. Statistical significance testing is performed, highlighting statistically significant improvements achieved by TransVIP. The table is broken down by language pair (French-English and English-French) for better analysis.
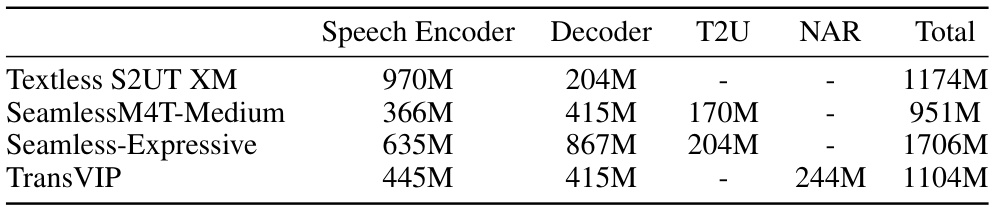
This table presents the model sizes (number of parameters) of different components of TransVIP and baseline models. It breaks down the number of parameters for the speech encoder, decoder, text-to-unit (T2U) module, and non-autoregressive (NAR) acoustic model, providing a clear comparison of the model complexities.

This table presents a subjective evaluation comparing TransVIP against several baseline models for speech-to-speech translation. Metrics include BLEU scores (translation quality), speaker and prosody similarity, isochrony control (alignment of speech duration), and naturalness. Statistical significance testing is performed to highlight superior performance.
Full paper#