↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current face forgery detection methods struggle with generalization and robustness against various manipulations and perturbations. Many methods overfit to specific low-level features in training data, leading to poor performance on unseen data. This limits their real-world applicability in scenarios with diverse forgeries and common image processing effects.
SpeechForensics addresses these issues by utilizing the synergy between audio and visual speech. It learns robust audio-visual speech representations from real videos using a self-supervised masked prediction task, encoding both local and global semantic information. This model is then directly applied to the forgery detection task, identifying inconsistencies between audio and visual speech in fake videos. Experiments demonstrate that the approach significantly outperforms existing methods in cross-dataset generalization and robustness, even without training on fake videos. This approach showcases the effectiveness of high-level semantic learning for improving the generalization capabilities of face forgery detection systems.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to face forgery detection that significantly improves cross-dataset generalization and robustness. The use of audio-visual speech representation learning is a novel approach that can inspire further research in this area and enhance the robustness of existing methods. The results suggest that this new approach has significant potential for real-world applications in digital forensics. Its unsupervised nature and high accuracy on various datasets and against common perturbations makes it particularly relevant to current research trends.
Visual Insights#
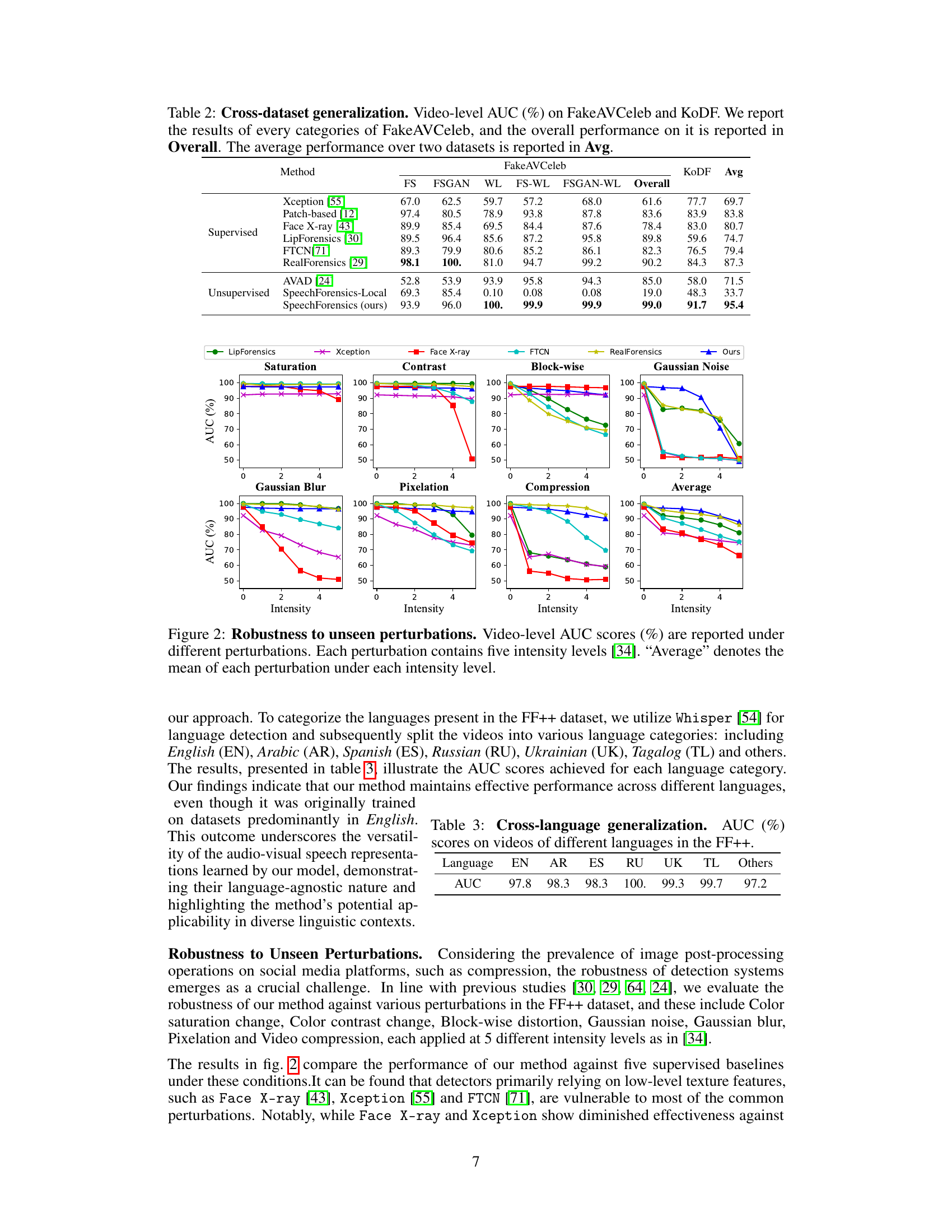
This figure illustrates the SpeechForensics method proposed in the paper. It’s a two-stage process. The first stage is audio-visual speech representation learning where a model learns representations from real videos using a combination of frame-wise audio-visual alignment and a masked prediction task to capture both local and global speech information. The second stage is forgery detection; the trained model is then used to process both audio and visual streams of a video to obtain speech representations. Videos with a low similarity score between the audio and visual speech representations are classified as fake.
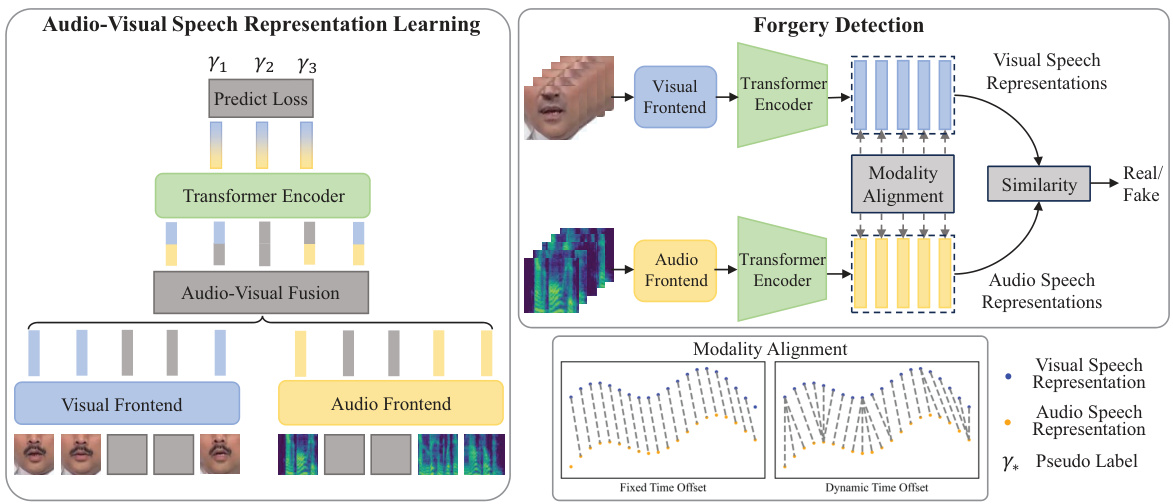
This table presents the results of a cross-manipulation generalization experiment. The Area Under the Curve (AUC) metric, measuring the performance of various forgery detection methods, is reported for four different manipulation techniques (Deepfakes, FaceSwap, Face2Face, NeuralTextures) used in the FaceForensics++ dataset. The experiment uses a leave-one-out strategy, where each manipulation technique is tested on a model trained on the remaining three. The table compares several state-of-the-art (SOTA) methods. The results demonstrate how well the models generalize to unseen manipulation techniques.
In-depth insights#
Audio-Visual Synergy#
The concept of “Audio-Visual Synergy” in the context of face forgery detection offers a compelling avenue for improving accuracy and robustness. Combining audio and visual data allows for a more holistic analysis of speech characteristics, moving beyond individual visual cues which are often manipulated in forged videos. Audio provides a strong semantic anchor, aligning with lip movements to identify discrepancies that might not be detected visually alone. This synergistic approach leverages the inherent correlation between spoken words and corresponding lip movements, and inconsistencies can serve as robust indicators of manipulation. The strength of this synergy lies in its ability to transcend simple artifact detection, which is often susceptible to sophisticated forgery techniques. Instead, it focuses on the semantic level, evaluating congruency between auditory and visual information. This is particularly relevant in countering techniques that meticulously synchronize audio and video, making audio-visual incongruities a more reliable indicator of manipulation.
Masked Prediction#
Masked prediction, a core technique in self-supervised learning, offers a powerful approach to learning robust representations from data. By strategically masking parts of the input (e.g., pixels in images, words in text, or segments in time series), the model is challenged to predict the missing information based on the context provided. This forces the model to learn intricate relationships and capture richer semantic understanding compared to simpler supervised or unsupervised methods. The choice of masking strategy is crucial; random masking may not sufficiently challenge the model, while overly structured masking could lead to overfitting. The effectiveness also depends on the architecture of the model and the chosen loss function. Applications of masked prediction span across numerous domains, including image recognition, natural language processing, and time-series forecasting. Furthermore, the process’s unsupervised nature allows for training on massive unlabeled datasets, expanding the potential for improved generalization and broader applicability.
Cross-Dataset Robustness#
Cross-dataset robustness is a critical aspect of evaluating the generalizability and practical applicability of a face forgery detection model. A model demonstrating strong cross-dataset robustness reliably identifies forgeries across diverse datasets, exhibiting consistent performance regardless of the specific characteristics of each dataset. This is crucial because real-world scenarios involve various video sources, recording conditions, and manipulation techniques. Failure to achieve cross-dataset robustness suggests overfitting to a specific training dataset, limiting the model’s real-world effectiveness. A robust model should be able to generalize effectively to unseen data, capturing the underlying patterns of forgeries rather than memorizing specific artifacts or characteristics of the training data. Thorough evaluation on multiple datasets, with variations in video quality, manipulation methods, and ethnicities of subjects, is vital to demonstrate true robustness. Furthermore, the analysis should consider the influence of various perturbations, demonstrating resilience even when videos are subjected to compression, noise, or other common alterations. A robust cross-dataset performance is a strong indicator of a reliable and practical face forgery detection system.
Generalization Limits#
A critical aspect of evaluating face forgery detection models is assessing their generalization capabilities. This refers to how well the model performs on unseen data, meaning data it wasn’t trained on, and data exhibiting variations not present in the training set. Generalization limits arise from various factors. These include the inherent limitations of the training data itself—if the training data doesn’t adequately represent the real-world diversity of forgeries, the model’s performance will likely degrade when encountering novel forgery techniques or subtle manipulations. The model architecture itself also plays a significant role: overfitting to specific artifacts in the training data can hinder the model’s ability to adapt to new variations. Another critical factor is the robustness of the model to common image perturbations (e.g., compression, noise, changes in lighting). A model that performs well on pristine images might fail when exposed to real-world noisy conditions. Finally, it is worth noting that adversarial attacks specifically designed to fool a given model can reveal inherent vulnerabilities, highlighting a practical generalization limit.
Future Directions#
Future research should explore the synergy between audio and visual modalities further, potentially incorporating other cues like subtle micro-expressions or physiological signals to improve robustness and accuracy. Addressing the limitations of relying solely on lip movements, such as vulnerability to sophisticated manipulation techniques that perfectly synchronize audio and visual speech, is crucial. Developing more sophisticated methods to address variable time offsets between audio and visual streams is needed, possibly incorporating techniques that handle variable delays rather than relying on fixed or simplified assumptions. Exploring new benchmark datasets that incorporate a wider range of manipulation techniques and cross-lingual diversity would greatly benefit the field, pushing the development of more generalized and robust models. Ultimately, the goal should be a real-world, deployable system. Developing effective safeguards to prevent malicious use of such technology should be a central focus to prevent misuse for nefarious purposes like generating convincing deepfakes.
More visual insights#
More on figures

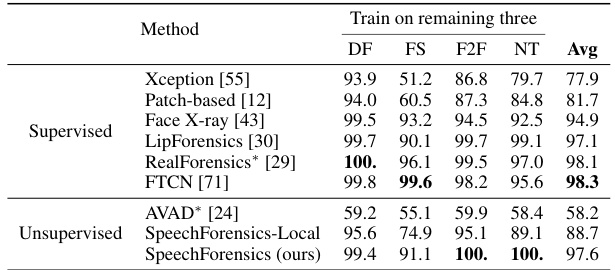
This figure displays the robustness of different face forgery detection methods against various image perturbations. Seven types of perturbations are tested (Saturation, Contrast, Block-wise, Gaussian Noise, Gaussian Blur, Pixelation, Compression), each at five different intensity levels. The AUC (Area Under the Receiver Operating Characteristic Curve) scores are plotted for each perturbation and intensity level. The ‘Average’ column shows the mean AUC across all intensity levels for each perturbation type. The figure demonstrates the relative performance of the different methods in dealing with these common image manipulations.

This figure visualizes the cosine similarity distributions between the audio and visual speech representations extracted from real and fake videos. Different manipulation methods are shown separately: Deepfakes, FaceSwap, Face2Face, NeuralTextures, FSGAN, and Wav2Lip. For each method, two histograms are presented: one for real videos and one for fake videos. The x-axis represents the cosine similarity, and the y-axis represents the count of videos. The purpose is to show how well the model can distinguish between real and fake videos using the learned audio-visual speech representations, demonstrating its ability to detect forgeries across various manipulation techniques.

This figure displays a qualitative analysis of the proposed method’s ability to distinguish between real and manipulated videos by examining audio-visual speech representations. The top row presents a real video with its corresponding audio waveform and transcription generated from both audio and visual features. The subsequent rows show examples of videos manipulated using four different techniques (Deepfakes, FaceSwap, Face2Face, NeuralTextures), each with its transcription obtained similarly. This provides a visual comparison to demonstrate how the model utilizes audio and visual speech representations to understand the speech content and identify inconsistencies in manipulated videos.

This figure shows the impact of video clip length and sliding window length on the performance of the proposed face forgery detection method. The left panel displays how AUC (Area Under the ROC Curve) changes as the video length increases, showing improved performance with longer clips for FaceSwap, NeuralTextures, and an average across forgery methods. The right panel illustrates the AUC as a function of the sliding window length used in the audio-visual alignment process. This panel demonstrates that increasing the window length to a certain degree improves the detection performance before leveling off. Overall, the figure highlights the importance of considering both long-range temporal contexts (longer video clips) and appropriate time alignment (sliding window length) for optimal forgery detection.
This figure visualizes the effects of seven different types of image manipulations on a sample face image. Each manipulation is shown at three different intensity levels (mild, moderate, and severe). The manipulations include changes to saturation, contrast, addition of block artifacts, noise, blur, pixelation, and compression. The figure demonstrates how various levels of noise and distortions can impact the visual quality of a face image, thereby affecting the performance of facial forgery detection methods.
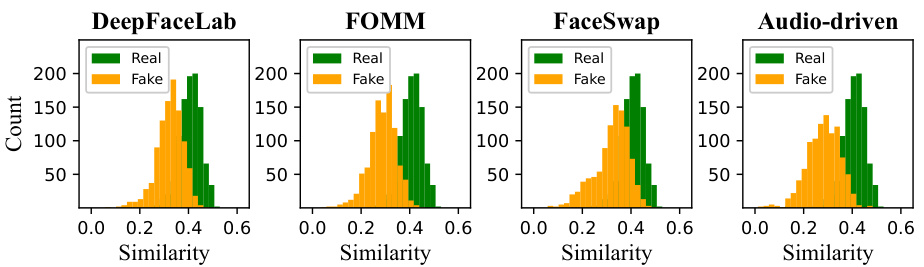
This figure visualizes the cosine similarity distributions between audio and visual speech representations for both real and fake videos. The fake videos were generated using different manipulation methods (Deepfakes, FaceSwap, Face2Face, NeuralTextures, FSGAN, and Wav2Lip). Each sub-figure shows a histogram of cosine similarity scores, with green representing real videos and orange representing fake videos. The distributions show that real videos tend to have higher cosine similarity scores compared to fake videos, reflecting the consistency between lip movements and audio in real videos, whereas inconsistencies are observed in fake videos due to manipulation techniques.
More on tables

This table presents the Area Under the Curve (AUC) scores achieved by the proposed method for face forgery detection across videos from different languages within the FaceForensics++ dataset. The results demonstrate the model’s cross-lingual generalization capabilities by showing consistent high AUC scores across various languages, indicating its robustness and ability to generalize beyond the language(s) it was primarily trained on.
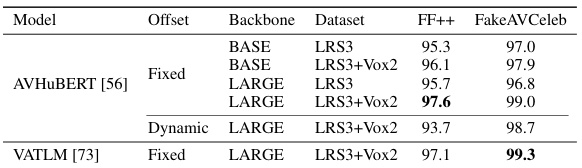
This table shows the results of an ablation study on the proposed face forgery detection method, SpeechForensics. The study investigates the impact of different model architectures (BASE and LARGE versions of AVHUBERT and VATLM) and training datasets (LRS3 and LRS3+Vox2) on the model’s performance, specifically measured by the Area Under the Curve (AUC) metric on the FaceForensics++ (FF++) and FakeAVCeleb datasets. It also explores the effect of two different time offset assumptions (Fixed and Dynamic) between audio and visual streams during the model’s forgery detection process. This table helps to understand how different factors influence the model’s generalization and robustness.
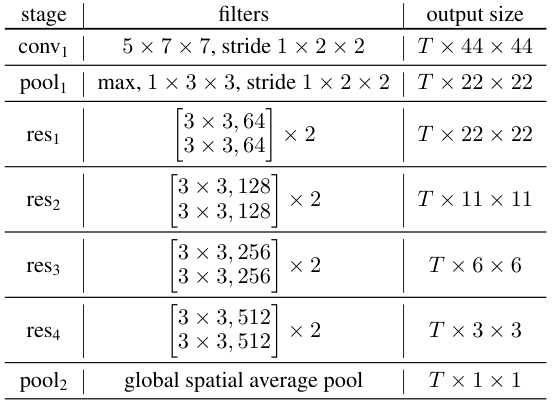
This table details the architecture of the visual frontend used in the proposed method. It shows the different stages (conv1, pool1, res1, res2, res3, res4, pool2), the filters used in each stage, and the output size of each stage. The output size is expressed in terms of T (number of input frames), H (height of frames), and W (width of frames).

This table presents the Area Under the Curve (AUC) scores for the proposed SpeechForensics method and several state-of-the-art methods on two different datasets, FakeAVCeleb and KoDF. It showcases the cross-dataset generalization capabilities of the approach. For FakeAVCeleb, AUC scores are broken down by specific forgery methods (Faceswap, FSGAN, Wav2Lip, etc.) to assess performance across various manipulation techniques, with an overall average and comparison against KoDF.

This table presents the results of a cross-dataset generalization experiment to evaluate the performance of the proposed method and other state-of-the-art methods on two unseen datasets: FakeAVCeleb and KoDF. It breaks down the performance on FakeAVCeleb by the specific forgery method used, providing overall and average performance metrics across both datasets.
Full paper#