↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current medical vision-language pre-training (VLP) methods struggle to learn detailed, pixel-level visual features crucial for tasks like medical image segmentation, primarily focusing on aligning images with entire reports instead of specific regions. This limits their effectiveness in dense prediction tasks. The inherent ambiguity in the relationship between image regions and report descriptions hinders learning of these features.
To tackle this, the paper introduces Global to Dense (G2D), a novel medical VLP framework. G2D employs a Pseudo Segmentation (PS) task to learn both global and dense visual features concurrently, using only image-text pairs. PS generates synthetic segmentation masks using attention maps, guiding the model to learn dense features without manual annotations. G2D substantially outperforms existing models across multiple medical imaging tasks, especially segmentation, even with minimal fine-tuning data, demonstrating its effectiveness and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in medical imaging and AI. It introduces a novel vision-language pre-training (VLP) framework, G2D, which significantly improves dense visual feature learning in medical images. This addresses a major limitation of existing methods and opens new avenues for research in various medical image analysis tasks. The superior performance of G2D, especially when using limited training data for fine-tuning, highlights its practical significance and potential impact on clinical applications.
Visual Insights#
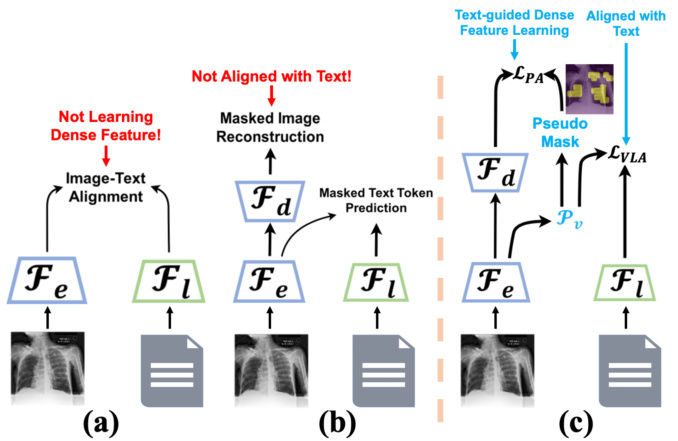
This figure compares three different types of medical VLP methods: alignment-based, reconstruction-based, and the proposed G2D. Alignment-based methods struggle to learn detailed visual features, while reconstruction-based methods don’t effectively align image and text information. The G2D method, using pseudo segmentation and image-text alignment, addresses both issues, enabling learning of dense, clinically relevant features.
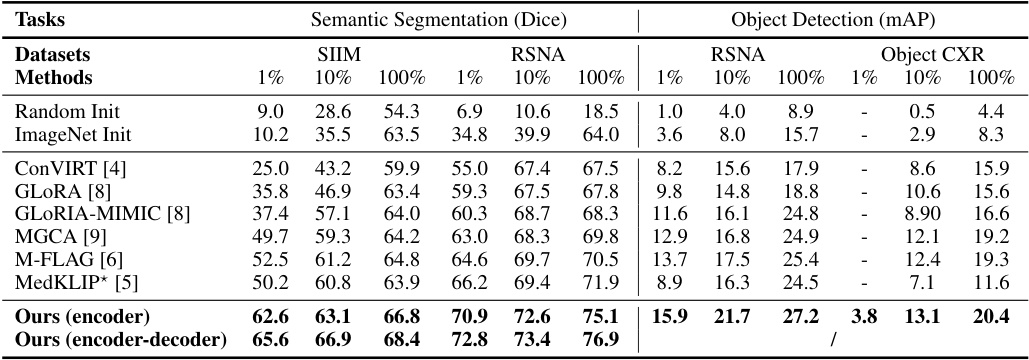
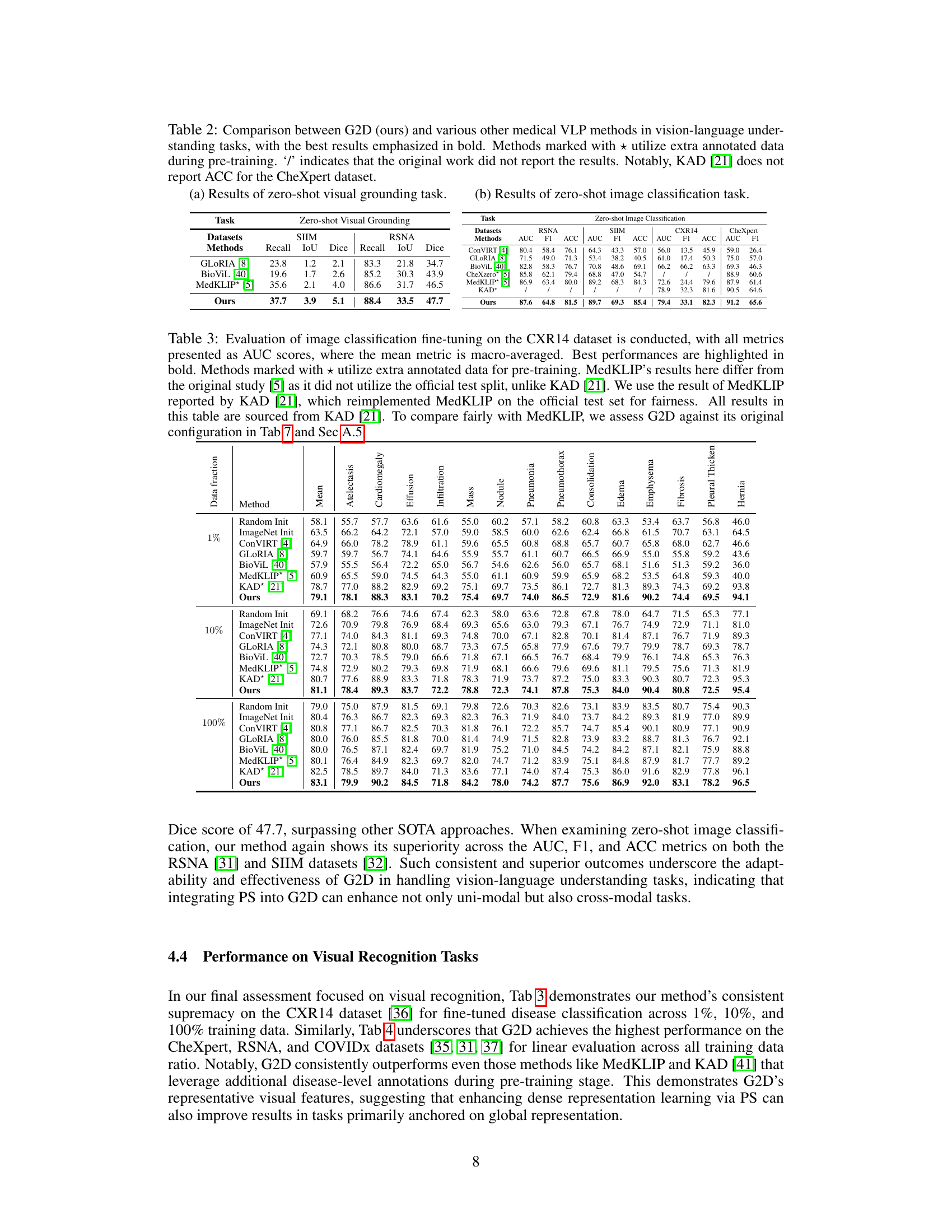
This table compares the performance of G2D against other state-of-the-art (SOTA) medical VLP approaches on semantic segmentation and object detection tasks. It shows Dice scores for semantic segmentation and mAP for object detection across three datasets (SIIM, RSNA, Object CXR) and various training data percentages (1%, 10%, 100%). Note that some methods could not perform object detection due to their architecture. The table also addresses differences in how MedKLIP fine-tuned its models compared to the others, aiming for a fair comparison.
In-depth insights#
Global-Dense VLP#
Global-Dense Vision-Language Pre-training (VLP) represents a significant advancement in multimodal learning for medical image analysis. It addresses the limitations of traditional VLP approaches that primarily focus on global image-text alignment, neglecting the crucial details inherent in medical images. Global-Dense VLP aims to simultaneously learn both global and fine-grained (dense) visual representations, effectively bridging the gap between high-level textual descriptions and subtle, localized visual features in medical images. This is particularly beneficial for tasks like medical image segmentation and object detection, which demand pixel-level accuracy. By incorporating techniques such as pseudo-segmentation, Global-Dense VLP can learn rich, clinically relevant visual features without relying on extensive pixel-level annotations, thereby improving efficiency and reducing costs. The framework likely leverages powerful vision and language encoders, employing techniques like contrastive learning to align visual and textual features at different levels of granularity. The success of Global-Dense VLP hinges on the effectiveness of its pretext task and the careful design of its multi-modal architecture to ensure appropriate information flow and alignment between image and text representations. Its ability to extract both global contextual information and highly detailed local features paves the way for more advanced and accurate medical image analysis applications.
PseudoSeg Task#
The proposed Pseudo Segmentation (PseudoSeg) task is a novel pretext task designed to address the limitations of existing medical vision-language pre-training (VLP) methods. Current methods struggle to learn dense, pixel-level visual features crucial for tasks like medical image segmentation because they primarily focus on aligning images with entire reports, rather than specific image regions and their corresponding textual descriptions. PseudoSeg overcomes this by generating pseudo segmentation masks on-the-fly during VLP. This is done using a parameter-free process leveraging the attention map derived from the visual representation and the radiology report, creating a pixel-level supervisory signal without requiring extra annotations. This avoids the need for costly and time-consuming pixel-level annotations while allowing for the model to learn rich, clinically relevant visual features simultaneously with global visual features. The effectiveness of PseudoSeg is demonstrated by its superior performance across various medical imaging tasks, especially segmentation, even with minimal fine-tuning data. This simple yet effective approach represents a key advancement in medical VLP, showing the power of cleverly designed pretext tasks to improve both global and dense visual representation learning.
CXR Experiments#
A hypothetical “CXR Experiments” section in a radiology research paper would likely detail the methods and results of experiments conducted on chest X-ray (CXR) datasets. This would involve specifying the datasets used (e.g., MIMIC-CXR, CheXpert), the tasks addressed (e.g., classification, detection, segmentation), and the performance metrics employed (e.g., AUC, mAP, Dice score). Crucially, the section should thoroughly describe the experimental setup, including data preprocessing steps, model architectures, training parameters, and evaluation protocols. A key aspect would be a comparison of the proposed method’s performance against existing state-of-the-art (SOTA) techniques on these CXR tasks. Statistical significance of the results should be clearly stated, along with discussions of potential limitations and future work. The experiments might include ablation studies to assess the impact of different components of the proposed approach and robustness analyses to evaluate the model’s performance under varied conditions. Visualizations of the results (e.g., confusion matrices, precision-recall curves) would further enhance the understanding and impact of this section.
Future of G2D#
The future of G2D hinges on several key areas. Extending its applicability to other medical imaging modalities beyond chest X-rays is crucial. This would require adapting the model architecture and pre-training datasets to accommodate the unique characteristics of different imaging types, such as MRI or CT scans. Improving the efficiency of the pseudo-segmentation task is also important. While the current method is effective, further research could explore more efficient techniques for generating pseudo masks, potentially reducing computational costs and improving training speed. Incorporating multi-modal information such as patient demographics, lab results, and other clinical notes to enhance the model’s understanding of disease pathology is a promising avenue. Finally, thorough validation in diverse clinical settings is necessary to ensure the robustness and generalizability of G2D before widespread adoption. Addressing these points will solidify G2D’s position as a leading medical VLP framework.
G2D Limitations#
The G2D model, while showing promise in global and dense visual representation learning for medical images, has limitations. The reliance on pseudo masks generated from attention maps for dense feature learning introduces a degree of uncertainty. The quality of these masks, which serve as a proxy for pixel-level supervision, directly impacts the efficacy of dense feature learning. The approach also assumes a strong correlation between radiology reports and image regions, which might not always hold true, potentially leading to misalignments and hindering the model’s capacity for nuanced visual understanding. Additionally, the extent of generalizability across diverse medical imaging modalities and datasets remains to be thoroughly investigated. Further research is needed to assess the robustness of G2D under different data distributions and clinical settings. The success of the method’s pretext task, pseudo segmentation, depends on the quality of attention maps, highlighting the importance of robust attention mechanisms. Finally, the computational complexity of G2D, especially concerning downstream tasks, requires careful consideration for practical applications.
More visual insights#
More on figures
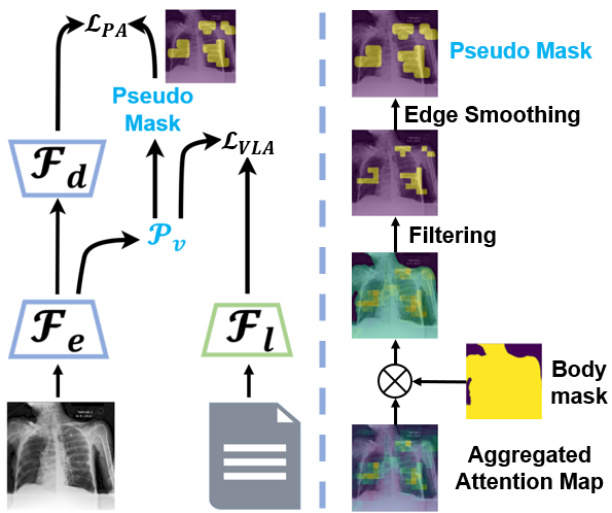
This figure shows the framework of the Global to Dense (G2D) model. The left side illustrates the overall architecture, showing how image and text encoders are used to generate global and dense visual features. The image encoder (Fe) and the text encoder (Fl) process the input image and text report, respectively. A vision-language alignment (VLA) task is used to align global image and text features, while a pseudo segmentation (PS) task leverages a pseudo mask generated from an attention mechanism to learn dense visual features using an image decoder (Fd). The right side details the pseudo mask creation pipeline, starting from an aggregated attention map, followed by filtering, edge smoothing, and finally combining with a body mask to produce the final pseudo mask used in the PS task. This detailed visualization helps to understand how dense visual features are extracted and used within the G2D framework.
The figure shows the framework of the G2D model, which consists of an image encoder, a text encoder, a vision-language alignment (VLA) module, a pseudo segmentation (PS) module, and an image decoder. The right side of the figure shows the pipeline for pseudo mask construction, including attention aggregation, mask filtering, and edge smoothing. The pseudo mask is derived from an attention map and used as a supervisory signal for the PS task, which helps to learn dense visual features.
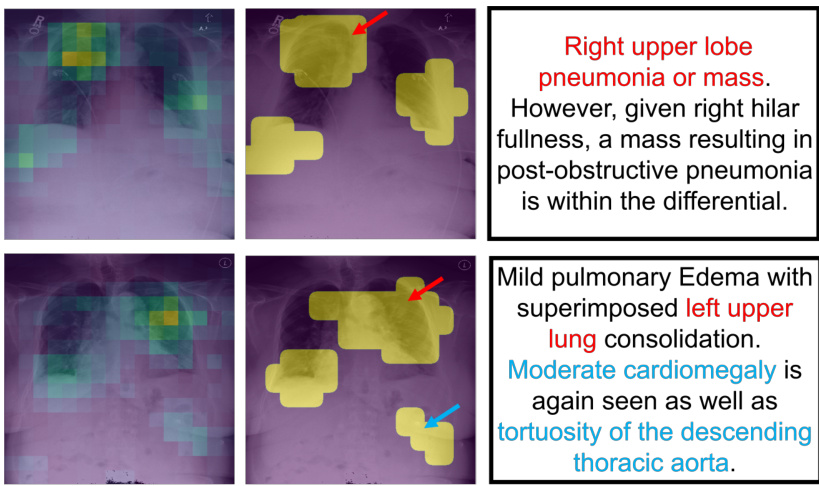
This figure illustrates the G2D framework, showing the two alignment strategies: vision-language alignment (VLA) and pixel alignment (PA). The left panel shows the overall architecture, highlighting the image encoder, text encoder, and image decoder components. The right panel details the pseudo mask construction pipeline, starting from attention map aggregation through filtering and edge smoothing to produce the final pseudo segmentation mask. The caption notes that a visualization of this pseudo mask and a corresponding sentence from a radiology report can be found in supplementary section A.7.
More on tables
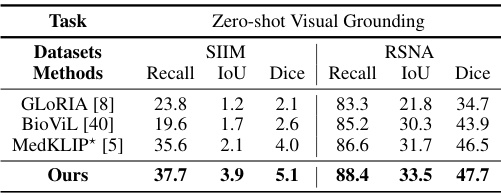
This table compares the performance of the proposed G2D model against other state-of-the-art (SOTA) medical vision-language pre-training (VLP) approaches on two vision-language understanding tasks: zero-shot visual grounding and zero-shot image classification. The results are shown for several datasets (SIIM, RSNA, CXR14, CheXpert). Note that some methods used extra annotated data during pre-training, which is indicated with an asterisk (*). The table highlights the superior performance of G2D across these tasks and datasets.

This table compares the performance of the proposed G2D model against other state-of-the-art (SOTA) medical vision-language pre-training (VLP) approaches on two vision-language understanding tasks: zero-shot visual grounding and zero-shot image classification. The results are shown for several datasets (SIIM, RSNA, CXR14, and CheXpert). Note that some methods used extra annotated data during pre-training, and some results were not reported in the original papers.
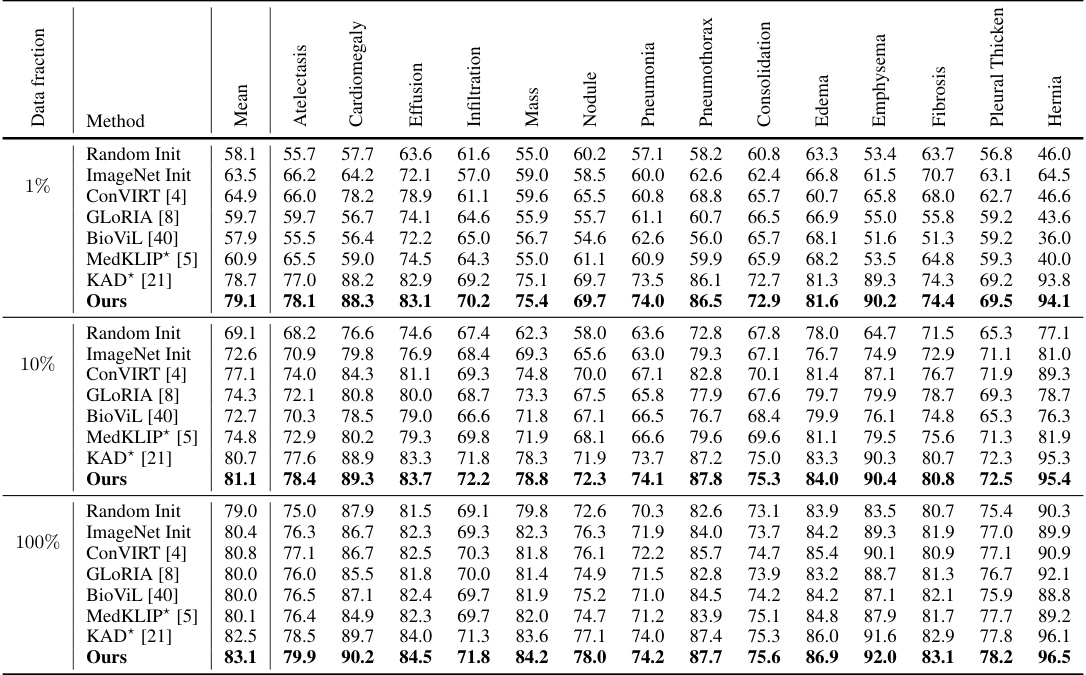
This table compares the performance of G2D against other state-of-the-art (SOTA) methods on semantic segmentation and object detection tasks using three different percentages of training data (1%, 10%, and 100%). It shows the Dice score for segmentation and mean Average Precision (mAP) for object detection. Important notes in the caption address differences in training methodology between G2D and the compared methods (especially MedKLIP), ensuring a fair comparison.
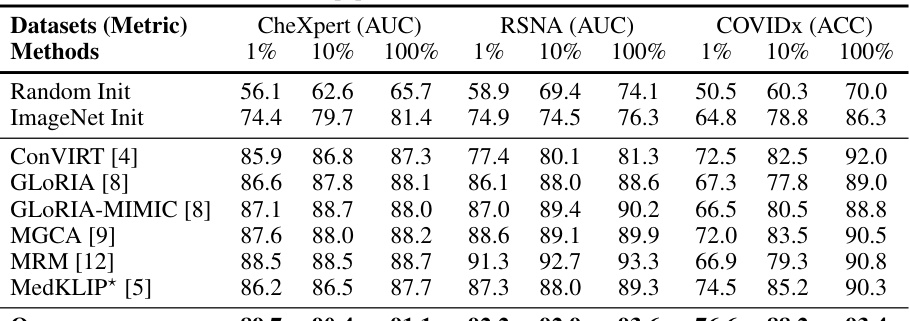
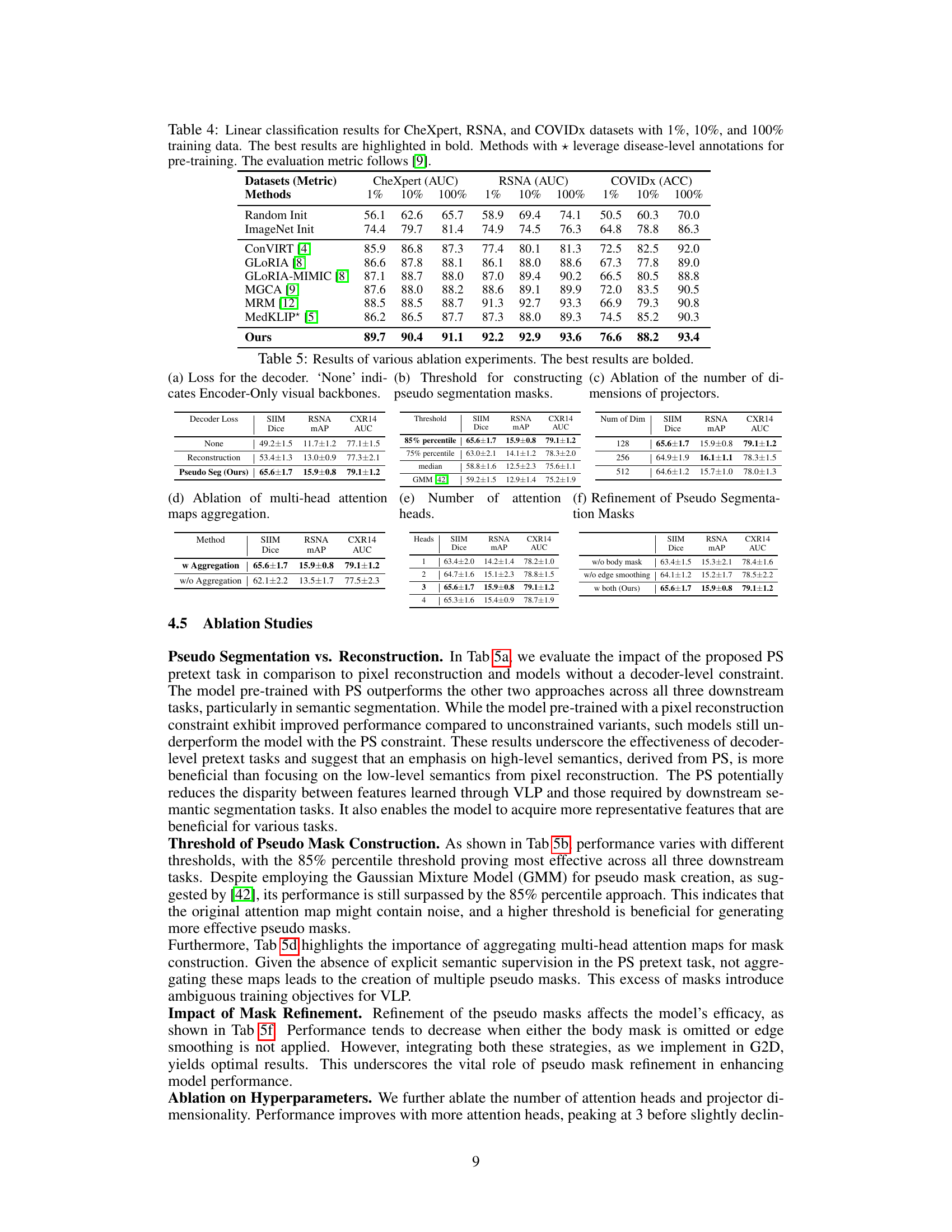
This table presents the results of linear image classification on three datasets (CheXpert, RSNA, and COVIDx) using different training data percentages (1%, 10%, and 100%). It compares the performance of G2D against other state-of-the-art methods, highlighting the superior performance of G2D, especially with limited training data. Note that some methods use extra disease-level annotations during pre-training.
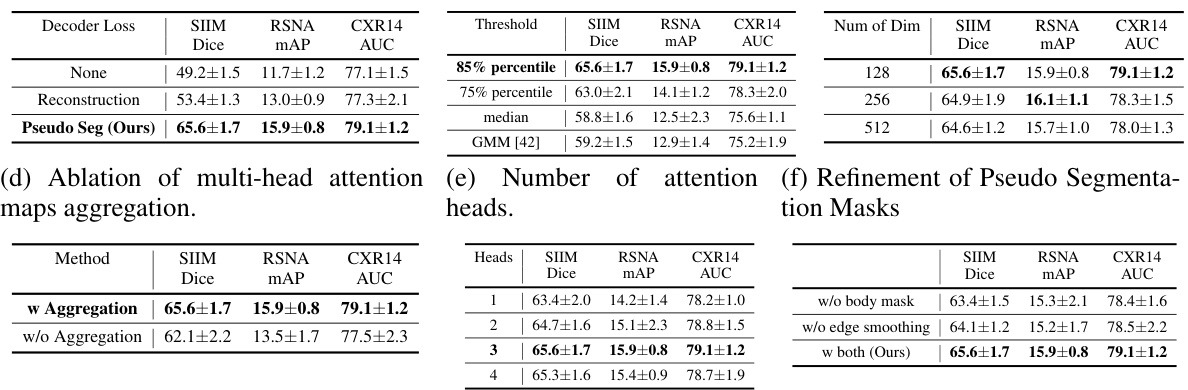
This table presents the results of ablation studies conducted to analyze the impact of different design choices in the G2D model. Specifically, it examines the effect of different decoder loss functions (None, Reconstruction, Pseudo Seg), various thresholds for pseudo mask generation, the number of dimensions in the projectors, the aggregation method for multi-head attention maps, and the refinement steps applied to the pseudo segmentation masks. The results highlight the optimal configurations for each component of the G2D model that yield the best performance across three downstream tasks (SIIM Dice, RSNA mAP, CXR14 AUC).
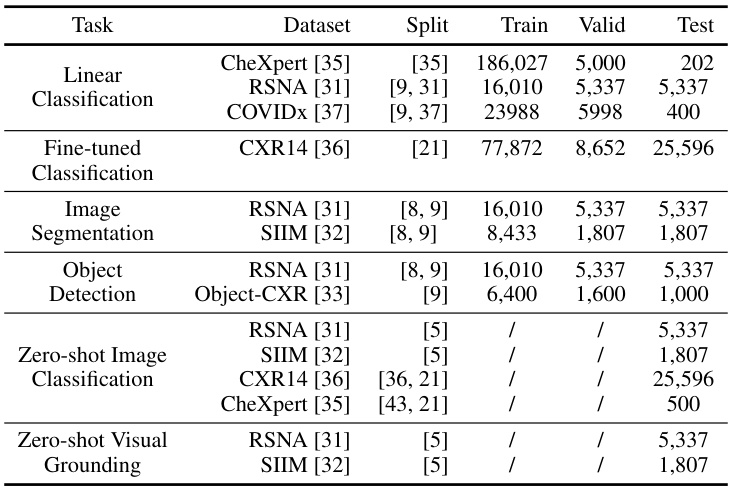
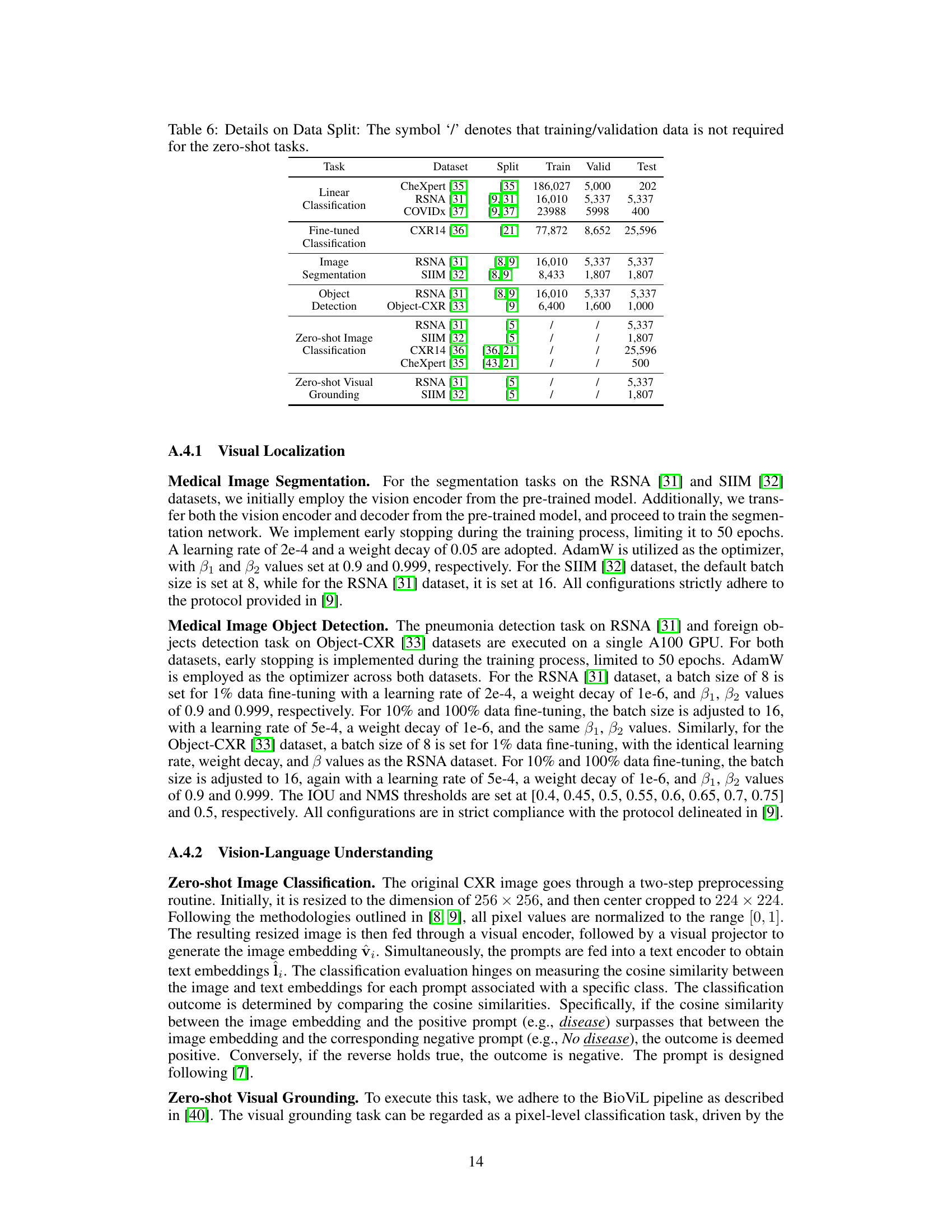
This table shows the data split for various downstream tasks used in the paper’s experiments. It includes the dataset used, the references for the data split, and the number of samples allocated for training, validation, and testing. Note that for zero-shot tasks, the training and validation sets are not applicable, hence the ‘/’.

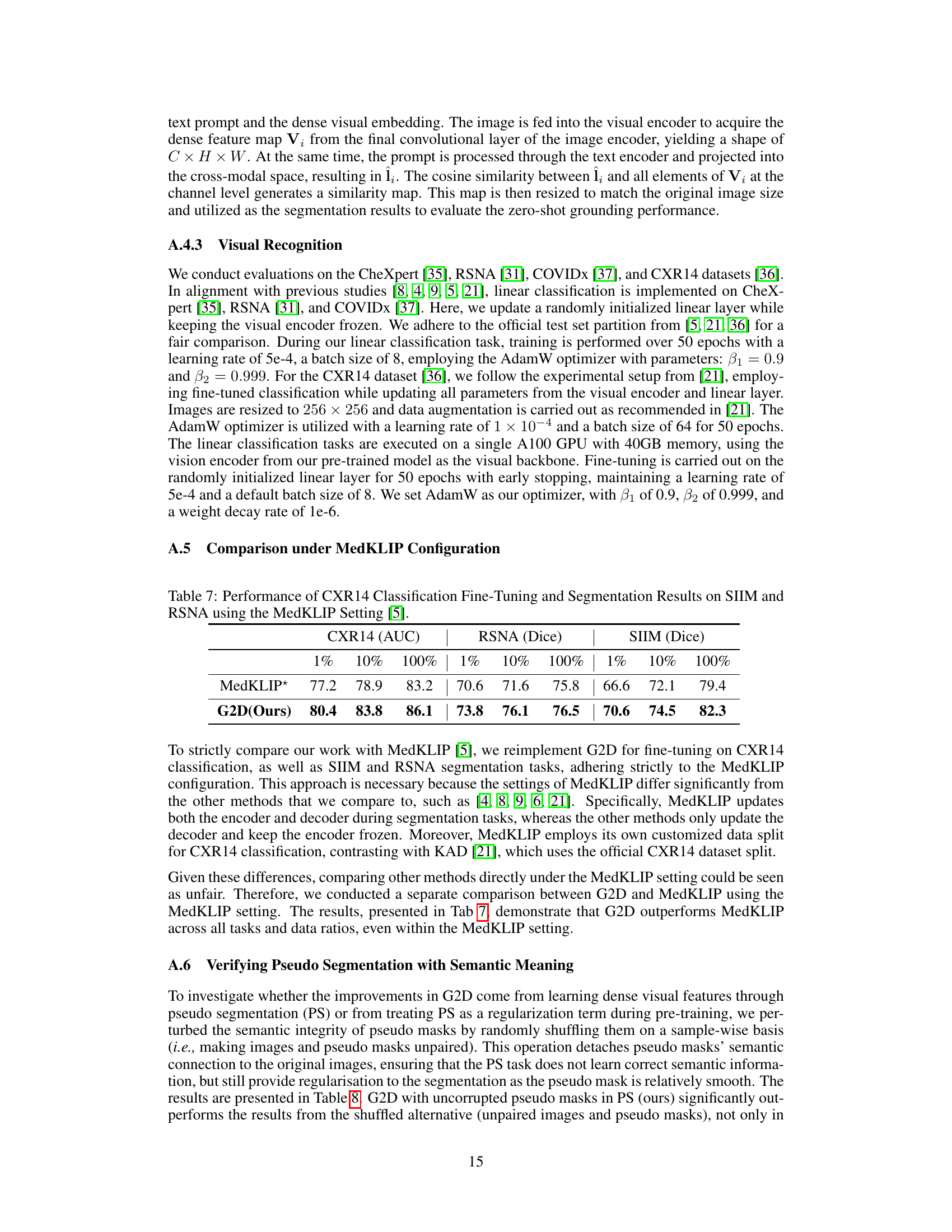
This table compares the performance of MedKLIP and G2D on three downstream tasks: CXR14 classification (AUC), RSNA segmentation (Dice), and SIIM segmentation (Dice). The results are broken down by the percentage of training data used (1%, 10%, and 100%). The comparison is specifically done using the configuration and data splits as defined in the MedKLIP paper [5], to ensure a fair and direct comparison under identical conditions.

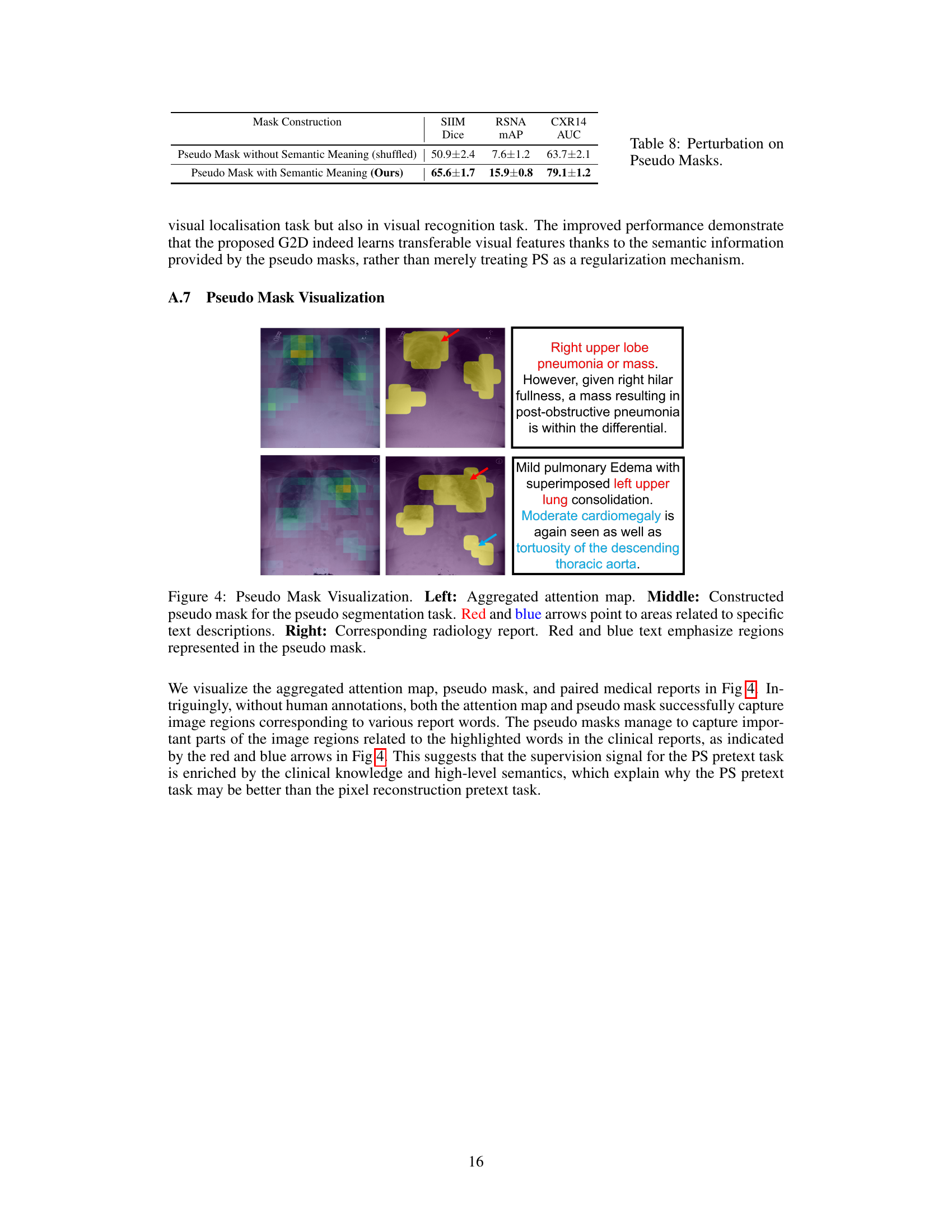
This table presents the ablation study results of using pseudo masks with and without semantic meaning in the pretext task. The results demonstrate the importance of the semantic information provided by pseudo masks generated using the attention mechanism for improving the performance in visual localization and recognition tasks. The model using pseudo masks with semantic meaning significantly outperforms the model using pseudo masks without semantic meaning (shuffled).
Full paper#