↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for evaluating Large Language Models’ (LLMs) ability to critique their own responses are limited in scope and reliability. This lack of comprehensive evaluation hinders progress in improving LLMs’ self-improvement and oversight capabilities. There is a need for a benchmark that addresses these limitations by providing a robust and standardized evaluation framework.
The paper introduces CRITICEVAL, a novel benchmark designed to comprehensively and reliably evaluate LLM critique abilities. It assesses critique across four dimensions (feedback, comparison, correction, meta-feedback) using nine diverse tasks. CRITICEVAL uses both scalar and textual critique formats, incorporates varied response quality levels, and leverages human-annotated references to ensure the reliability of evaluations. The results demonstrate the effectiveness of the benchmark, reveal the promising potential of open-source LLMs, and uncover relationships between critique ability and various factors.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it introduces CRITICEVAL, a novel benchmark for comprehensively and reliably evaluating the critique capabilities of large language models (LLMs). This addresses a critical gap in current LLM evaluation, impacting future LLM development and application by providing a more robust and standardized evaluation framework. Its findings also highlight the promising potential of open-source LLMs and reveal intriguing relationships between critique ability and factors like task types and response qualities, spurring further research in these areas.
Visual Insights#

This figure shows four examples of different critique dimensions in the CRITICEVAL benchmark. Each example includes a task input, an LLM response, and different types of critiques. The four critique dimensions are: feedback (Fs), correction (CR), comparison (Fc), and meta-feedback (F4(Fs)). Scalar-valued critiques are represented by scores and preference labels, while textual critiques are in natural language format. This figure helps visualize the different types of critiques used for a comprehensive evaluation of LLMs’ critique ability.

This table compares CRITICEVAL with other existing benchmarks for evaluating the critique capabilities of LLMs. It shows the different critique formats (scalar, natural language), dimensions, response qualities, dataset sizes (test and development sets), and evaluation metrics (subjective, objective). It highlights CRITICEVAL’s increased comprehensiveness and reliability, including its larger dataset, multiple critique dimensions, and use of GPT-4 for reliable textual critique evaluation.
In-depth insights#
Critique Eval Bench#
A hypothetical “CritiqueEval Bench” would be a crucial benchmark for evaluating large language models’ (LLMs) critique capabilities. It would go beyond existing benchmarks by offering comprehensive evaluations across multiple dimensions, such as feedback, comparison, correction, and meta-feedback, to provide a more holistic understanding of an LLM’s ability to identify and rectify flaws. The benchmark’s design would prioritize reliability, potentially using human-annotated reference critiques or a high-performing LLM like GPT-4 for objective scoring, to ensure consistency and accuracy. A robust “CritiqueEval Bench” would include a wide range of diverse tasks and response qualities, enabling researchers to assess LLMs’ critique abilities in various contexts. Furthermore, it should analyze relationships between critique ability and critical factors such as task types, response qualities, and LLM architecture, ultimately advancing the field of LLM evaluation and self-improvement.
LLM Critique Ability#
The concept of “LLM Critique Ability” centers on evaluating Large Language Models’ (LLMs) capacity to identify and correct flaws within their own generated text. This involves assessing not just the detection of errors, but also the quality of suggested improvements. Comprehensiveness is key, examining critique across various tasks and dimensions, including comparing response pairs, and evaluating feedback. Reliability is equally critical, often achieved through human evaluation or sophisticated automated metrics, like those using GPT-4 as a benchmark for textual critiques. Research highlights the interplay between LLM size and critique ability, with larger models generally demonstrating better performance. Open-source LLMs are rapidly improving, though they still lag behind closed-source counterparts. Future work focuses on standardization through benchmarks like CRITICEVAL, and understanding how factors like task type and response quality affect the accuracy of critiques. The ultimate goal is to build LLMs that can effectively self-improve, leading to more robust and aligned AI systems.
Human-in-the-loop#
The “human-in-the-loop” approach, as discussed in the research paper, is a crucial methodology that significantly enhances the reliability and quality of the generated data. It involves human experts directly participating in the data generation and evaluation process to ensure accuracy and mitigate biases introduced by the LLMs alone. The human-in-the-loop process helps refine the quality of critiques, leading to more accurate and effective evaluation of LLMs’ critique ability. By incorporating human judgment, the method ensures that the generated critiques and evaluations are more consistent with human standards, and hence, more reliable. This approach addresses the limitations of relying solely on automated methods for evaluating critique quality, which might lead to biases or inaccuracies. Moreover, the human-in-the-loop method demonstrates its efficacy in balancing cost and quality, especially for computationally expensive tasks such as annotating textual critiques. Human intervention helps ensure high-quality annotation, which otherwise could be prohibitively expensive if completely manual. Ultimately, the human-in-the-loop methodology is critical for developing a reliable and comprehensive benchmark for evaluating LLMs’ critique capabilities.
Critique Dimensions#
The concept of “Critique Dimensions” in evaluating large language models (LLMs) is crucial for assessing their ability to analyze and improve their own outputs. It moves beyond simple accuracy metrics, delving into the multifaceted nature of critique. A robust framework needs to consider multiple dimensions, such as evaluating a single response (feedback), comparing multiple responses (comparison), suggesting corrections (correction), and even evaluating the quality of a previous critique (meta-feedback). These dimensions aren’t isolated; they interact and influence each other. For instance, a high-quality response might be harder to critique effectively than a poor one, highlighting the complex relationship between response quality and critique difficulty across dimensions. A comprehensive evaluation requires a balanced assessment across all dimensions, recognizing the unique challenges each one presents. This nuanced approach is essential to understanding and fostering the self-improvement capabilities of LLMs and building more robust and reliable AI systems. The choice of dimensions directly influences the scope and depth of the evaluation, impacting overall conclusions about the LLM’s critique capability.
Future of Critique#
The future of critique in large language models (LLMs) is a rapidly evolving field with significant potential. Improving the reliability and comprehensiveness of critique evaluations is paramount, requiring the development of more robust benchmarks that encompass diverse tasks and response qualities. This includes evaluating critique ability across multiple dimensions, moving beyond scalar metrics to incorporate more nuanced textual analysis. Open-source LLMs show promise, demonstrating comparable performance to their closed-source counterparts, suggesting a future where open-source models can effectively drive critique-based self-improvement and scalable oversight. Addressing challenges in few-shot prompting and creating benchmarks that effectively handle nuanced, real-world scenarios are crucial next steps. Furthermore, the ethical implications of critique-enabled systems, especially those involving subjective evaluation by LLMs, must be thoroughly considered, leading to the development of responsible and human-aligned critique frameworks.
More visual insights#
More on figures
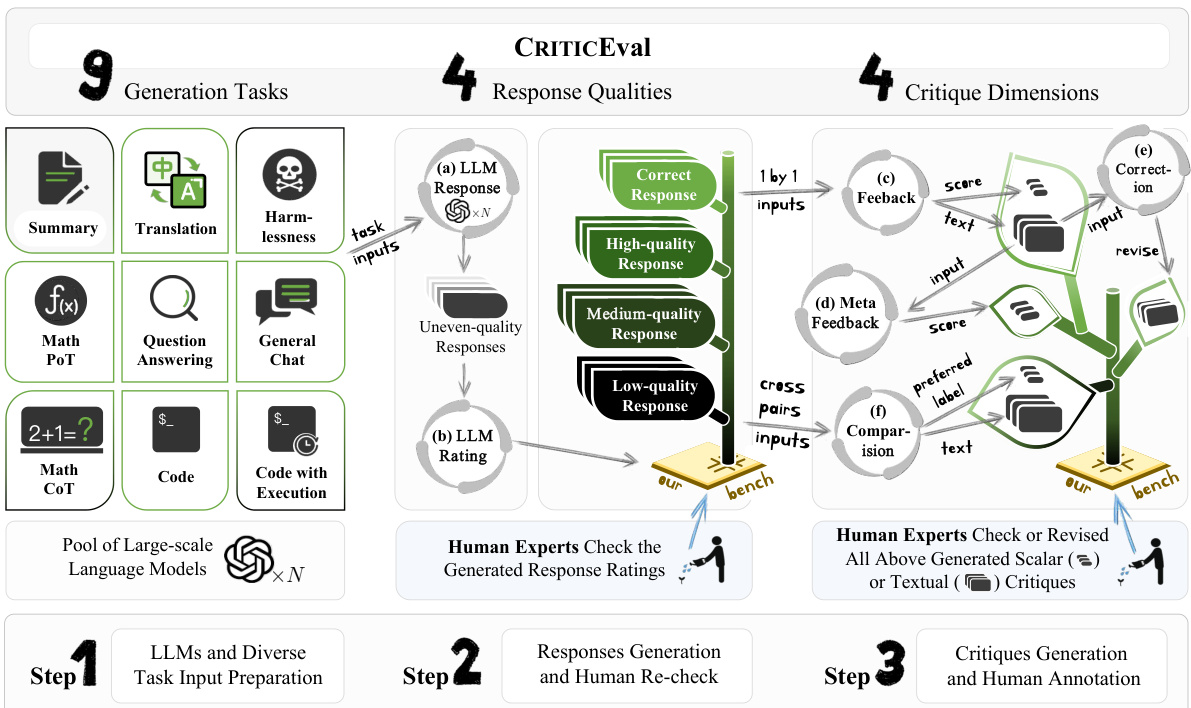
This figure illustrates the three-step data construction pipeline used to create the CRITICEVAL benchmark. Step 1 involves preparing 9 diverse tasks and a large number of LLMs. Step 2 shows the process of generating responses using these LLMs, followed by human expert review to assess response quality. Finally, Step 3 depicts the generation of critiques using high-performing LLMs, which are then reviewed and annotated by human experts to ensure high quality and consistency.

This figure presents a detailed analysis of the common failure modes observed in model-generated critiques across three critique dimensions (feedback, comparison, and correction). The leftmost panel displays the distribution of these failure modes for each dimension, while the rightmost panels show the average subjective scores corresponding to each failure mode within its respective dimension. This analysis is further discussed in Section 6.8 of the paper, which explores fine-grained failure modes to gain a deeper understanding of the weaknesses of model-generated critiques.

This figure shows the distribution of human-annotated Likert scores (1-7) for the response quality of different tasks in CRITICEVAL. The scores represent the quality of the generated responses in nine different tasks, categorized into low, medium, high, and correct response quality. The x-axis represents the Likert score, and the y-axis represents the number of responses. The figure allows for a visual comparison of the response quality distribution across the different tasks. The different colors represent the different categories of response quality.

This figure displays the relationship between the average number of unique tokens and the average Likert score given by GPT-4 for three different critique dimensions (feedback, correction, and comparison-based feedback). Each point represents a different Large Language Model (LLM). The plot helps visualize whether there’s a correlation between the length of critiques generated by LLMs and the subjective quality assessment of those critiques by GPT-4.

This figure illustrates the four critique dimensions evaluated in CRITICEVAL: feedback, correction, comparison, and meta-feedback. It shows examples of both scalar-valued (scores and preference labels) and textual critiques for each dimension. The image helps to clarify the different types of critiques and how they are used to evaluate the critique capability of LLMs.

This figure shows a single example of the objective evaluation process in CRITICEVAL, focusing on the translation task. It displays the source sentence in English, the machine-generated translation, and the Likert score (1-7) assigned by the Qwen-72B-Chat large language model. This score reflects the model’s assessment of the translation quality, providing a quantitative measure of its accuracy and fluency.

This figure shows an example of a comparison-based critique generated by the Qwen-72B-Chat large language model. The task is to compare two translations of the same English sentence into Chinese and determine which translation is of higher quality. The figure displays the original English sentence, the two different Chinese translations (A and B), and the Qwen-72B-Chat’s assessment of which translation is superior, along with a brief explanation of its reasoning.
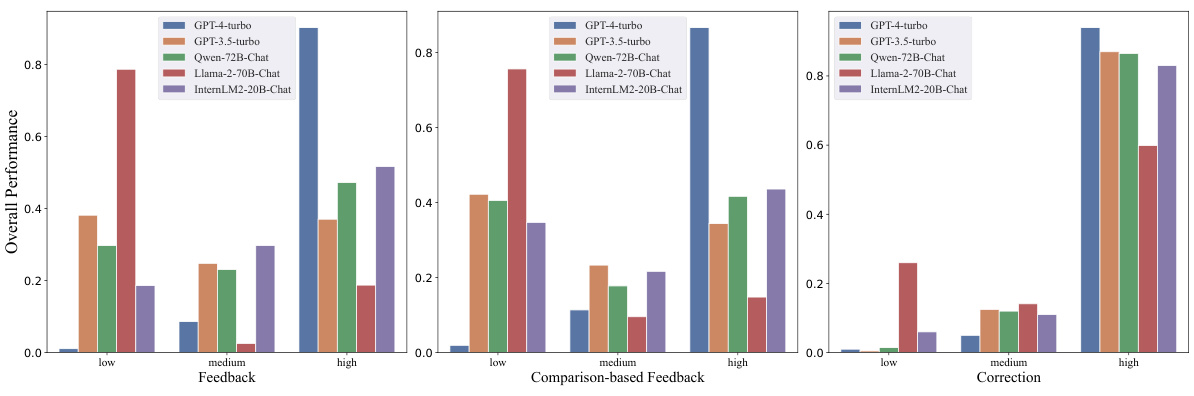
This figure provides a more detailed, interpretable analysis of the performance of different LLMs in CRITICEVAL across various critique dimensions and response qualities. It breaks down the results by response quality (low, medium, high) showing the overall performance of each LLM for feedback, comparison-based feedback, and correction tasks. The visualization allows for a clearer understanding of the relative strengths and weaknesses of various LLMs in the subjective evaluation of critiques.

This figure provides a more detailed, interpretable analysis of how different LLMs perform on the subjective evaluation of their critique abilities across various tasks and levels of response quality. The graph showcases performance across three critique dimensions: feedback, comparison-based feedback, and correction. It compares several LLMs, including GPT-4-turbo, GPT-3.5-turbo, Qwen-72B-Chat, Llama-2-70B-Chat, and InternLM2-20B-Chat, highlighting their strengths and weaknesses in providing different types of critiques.
More on tables

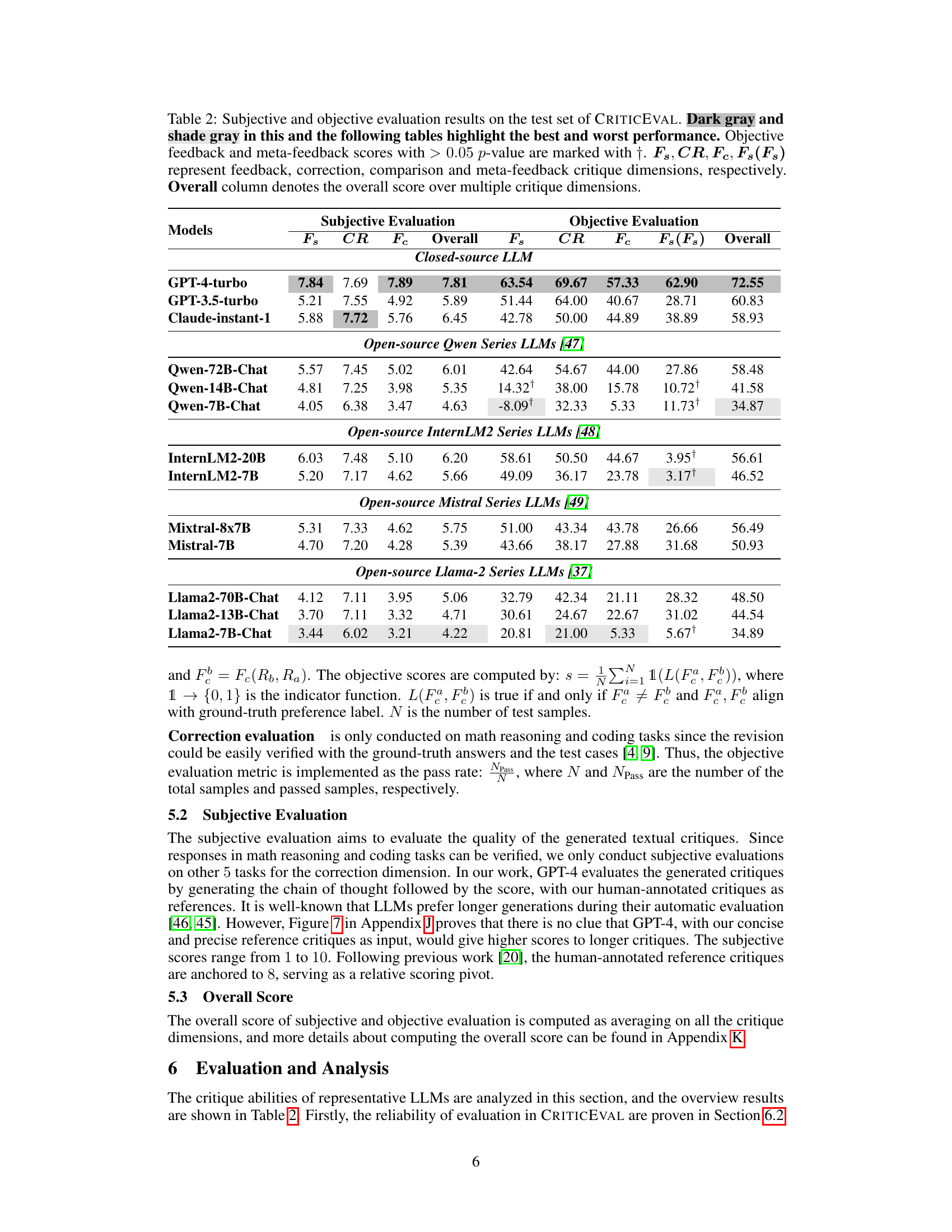
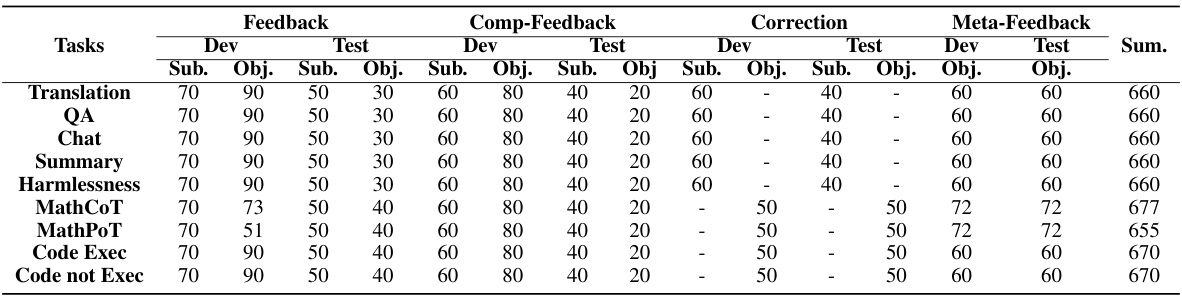
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The subjective scores are based on human evaluations of the quality of the LLMs’ critiques, while the objective scores are based on the correlation between the LLM’s scores and human judgments. The table breaks down the results by critique dimension (feedback, correction, comparison, meta-feedback) and includes an overall score combining all dimensions. Dark gray and light gray highlight the best and worst performing models, respectively.
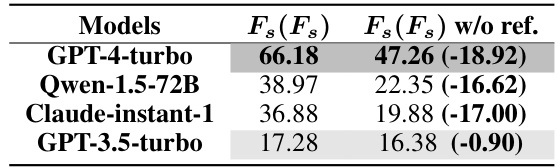
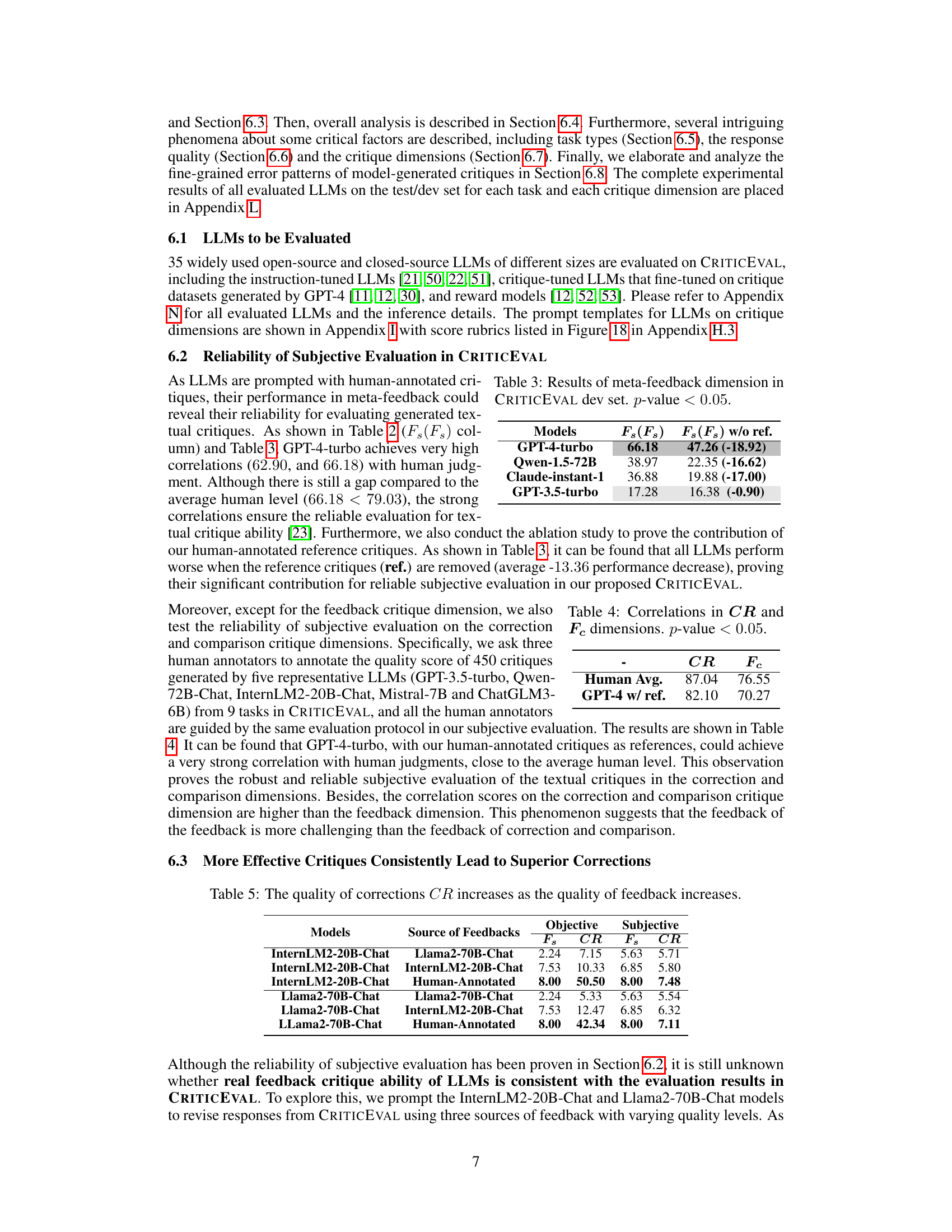
This table presents the results of the meta-feedback dimension evaluation on the CRITICEVAL development set. It shows the performance of several LLMs (GPT-4-turbo, Qwen-1.5-72B, Claude-instant-1, and GPT-3.5-turbo) in evaluating textual critiques, comparing their scores with and without the use of reference critiques. The table highlights the impact of reference critiques on the reliability of LLM-based textual critique evaluation.

This table presents the correlation results between human evaluation and GPT-4 evaluation for the correction (CR) and comparison (Fc) dimensions in the CRITICEVAL benchmark. A p-value less than 0.05 indicates statistical significance. The table shows strong correlations, suggesting the reliability of GPT-4 in evaluating textual critiques for these two dimensions.
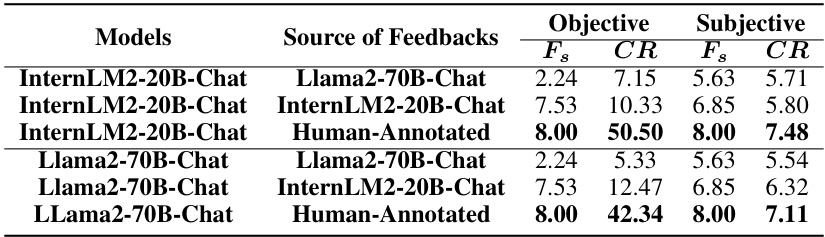
This table presents the subjective and objective evaluation results for 35 LLMs on the CRITICEVAL benchmark’s test set. It shows the performance across four critique dimensions (feedback, correction, comparison, and meta-feedback) using both scalar and textual critique formats. The best and worst performing LLMs are highlighted, and statistically significant results (p-value > 0.05) are noted. The overall score represents an average across all dimensions.
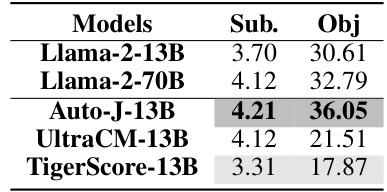
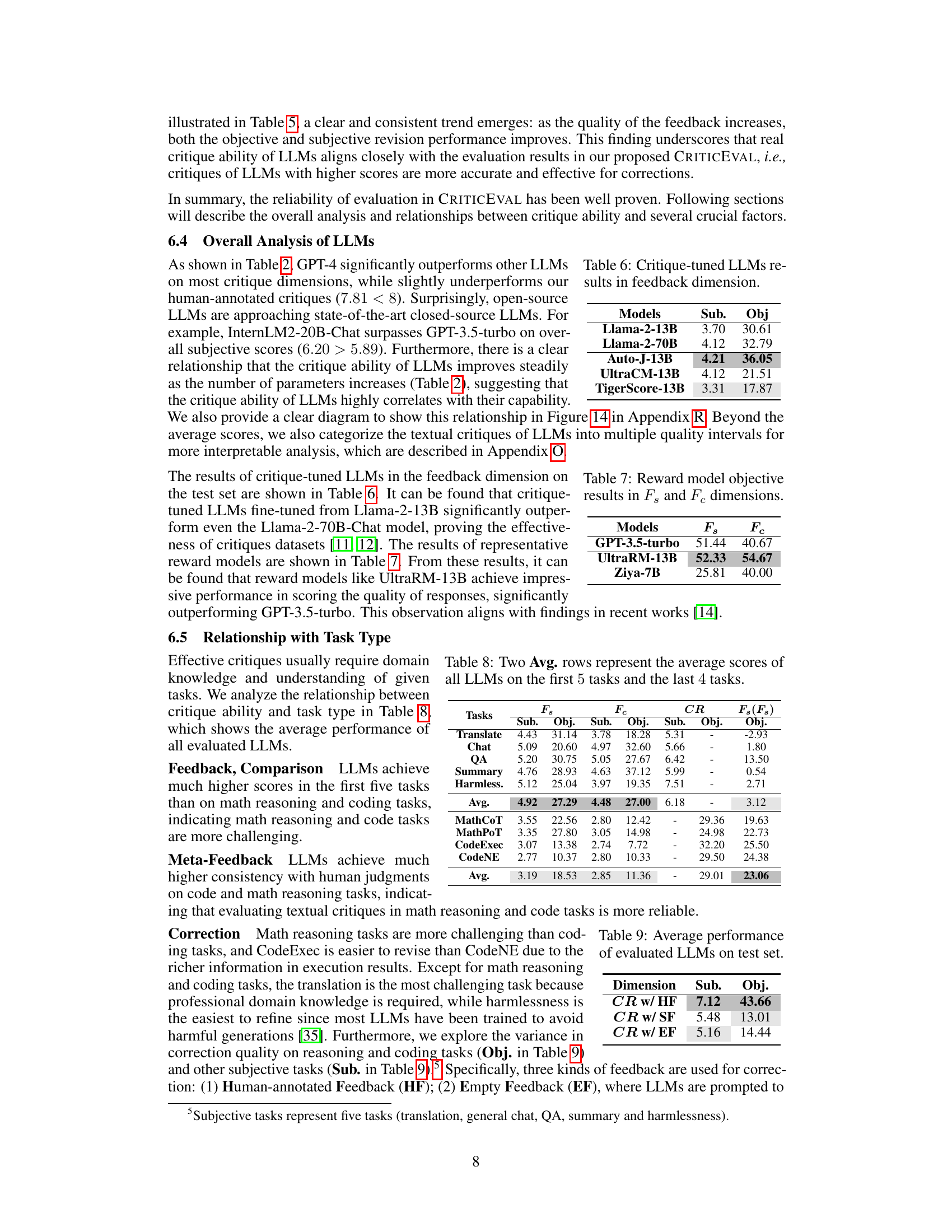
This table presents the subjective (Sub.) and objective (Obj.) evaluation results for critique-tuned LLMs (Large Language Models) on the feedback dimension of the CRITICEVAL benchmark. Critique-tuned LLMs are models specifically fine-tuned on critique datasets. The table shows that performance varies considerably across different models, highlighting the impact of fine-tuning strategies on critique ability. The scores likely reflect the degree to which these LLMs successfully identify and provide helpful suggestions for improving the quality of model generated text.

This table presents the subjective and objective evaluation results for various LLMs on the CRITICEVAL benchmark’s test set. The evaluation covers four critique dimensions (feedback, correction, comparison, meta-feedback), and both subjective (human-rated) and objective (automatically computed using GPT-4) scores are provided. The table highlights the best and worst performing models in each dimension and overall, considering various factors like LLM type (closed-source vs. open-source) and size. Statistical significance (p-values) is indicated for objective scores.
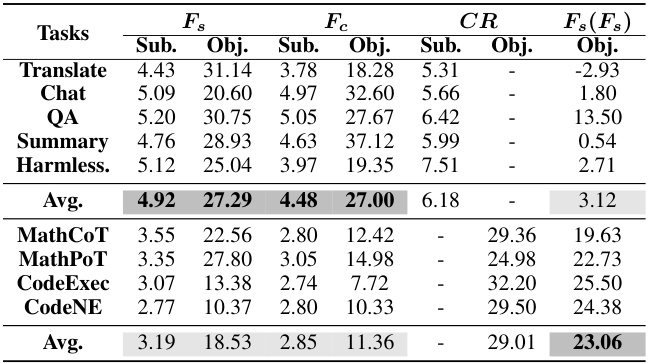
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL test set. The evaluation is broken down into four critique dimensions (feedback, correction, comparison, and meta-feedback), each with both subjective and objective metrics. Dark gray highlights the best performing model(s) in each category, and light gray highlights the worst performing model(s). The overall score is a composite of performance across the critique dimensions.
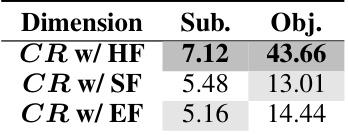
This table presents the subjective and objective evaluation results of 35 LLMs on the CRITICEVAL benchmark’s test set. It shows performance across four critique dimensions (feedback, correction, comparison, meta-feedback), using both subjective (human-rated quality) and objective (correlation with GPT-4 judgments) metrics. High and low-performing models are highlighted, and p-values are provided for statistical significance of the objective scores.

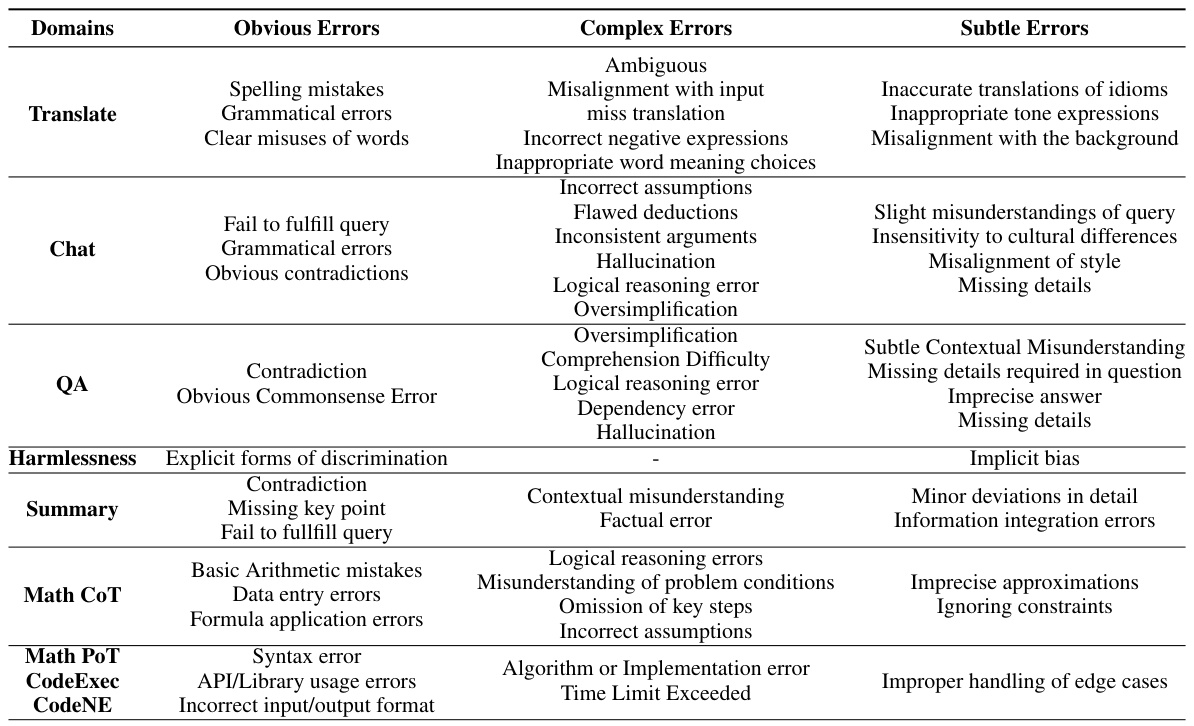
This table shows the distribution of three types of error patterns (Obvious, Complex, Subtle) across different response quality levels (Low, Medium, High). Each cell represents the percentage of responses with a particular error pattern and quality level. It helps illustrate the relationship between response quality and the types of errors generated.

This table presents the subjective and objective evaluation results for various LLMs on the CRITICEVAL benchmark’s test set. It shows scores across four critique dimensions (Feedback, Correction, Comparison, and Meta-feedback), categorized by LLM type (closed-source vs. open-source) and model size. Dark gray highlights the best-performing LLMs, while light gray indicates the worst. Significance levels (p-values) for objective scores are also provided. The ‘Overall’ column shows the average score across all four dimensions.
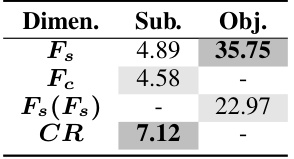
This table presents the subjective and objective evaluation results of 35 different LLMs on the CRITICEVAL test set. The evaluation is broken down by four critique dimensions (feedback, correction, comparison, and meta-feedback) and shows both subjective (human-rated) and objective (GPT-4-based) scores. Dark gray highlights the best-performing LLMs, and light gray highlights the worst-performing LLMs for each dimension. The overall score is the average score across all four dimensions.
This table compares CRITICEVAL with other existing benchmarks for evaluating the critique capabilities of LLMs. It highlights key differences across several dimensions, including the format and number of critiques, the number of dimensions evaluated, the response quality (whether it is classified or not), the presence of subjective and objective metrics, and whether human annotation was used and if the benchmark has been publicly released. The table helps to demonstrate CRITICEVAL’s comprehensiveness and reliability compared to prior work.

This table compares CRITICEVAL with other existing benchmarks for evaluating the critique ability of LLMs. It shows several key features of each benchmark, including the format of the critiques (natural language or scalar), the number of critique dimensions evaluated, the response quality (if classified), the size of the test and development datasets, whether subjective metrics (human annotation) and objective metrics were used in the evaluation, and whether the dataset is publicly available. The table highlights CRITICEVAL’s comprehensiveness and reliability by showing its larger scale, more diverse task scenarios, and more robust evaluation methodology.
This table compares CRITICEVAL with other existing benchmarks for evaluating the critique capabilities of large language models. It compares various aspects such as the format and number of critiques, the number of dimensions evaluated, the response quality, the size of the dataset, and whether subjective or objective metrics, or human annotation are used. The table highlights CRITICEVAL’s comprehensiveness and its use of both scalar and textual critiques.
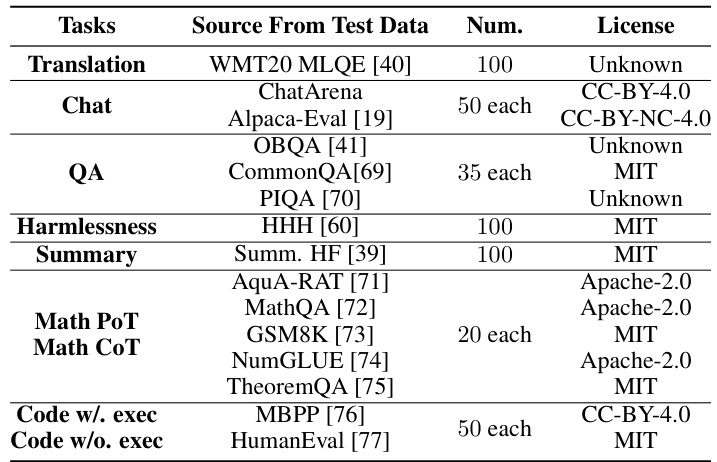
This table compares CRITICEVAL with other existing benchmarks for evaluating the critique capabilities of LLMs. The comparison covers several key aspects, including the critique format (whether it’s natural language or scalar), the number of critique dimensions evaluated, the response quality of the data used, the size of the test and development sets, whether objective and subjective metrics are used, whether human annotations were used, and whether the benchmark data has been publicly released. The table highlights CRITICEVAL’s advantages in terms of comprehensiveness and reliability compared to existing benchmarks.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The results are broken down by four critique dimensions (feedback, correction, comparison, and meta-feedback) and provide both subjective (human-rated) and objective (GPT-4-based) scores. Dark gray and light gray shading highlight the best and worst performing models, respectively. The overall score is an average across all four dimensions.

This table presents a comprehensive evaluation of various Large Language Models (LLMs) on the CRITICEVAL benchmark. It shows both subjective and objective scores for four critique dimensions (feedback, correction, comparison, and meta-feedback). The best and worst-performing models are highlighted, and statistical significance is indicated where relevant. The overall scores represent an aggregate measure across all dimensions.
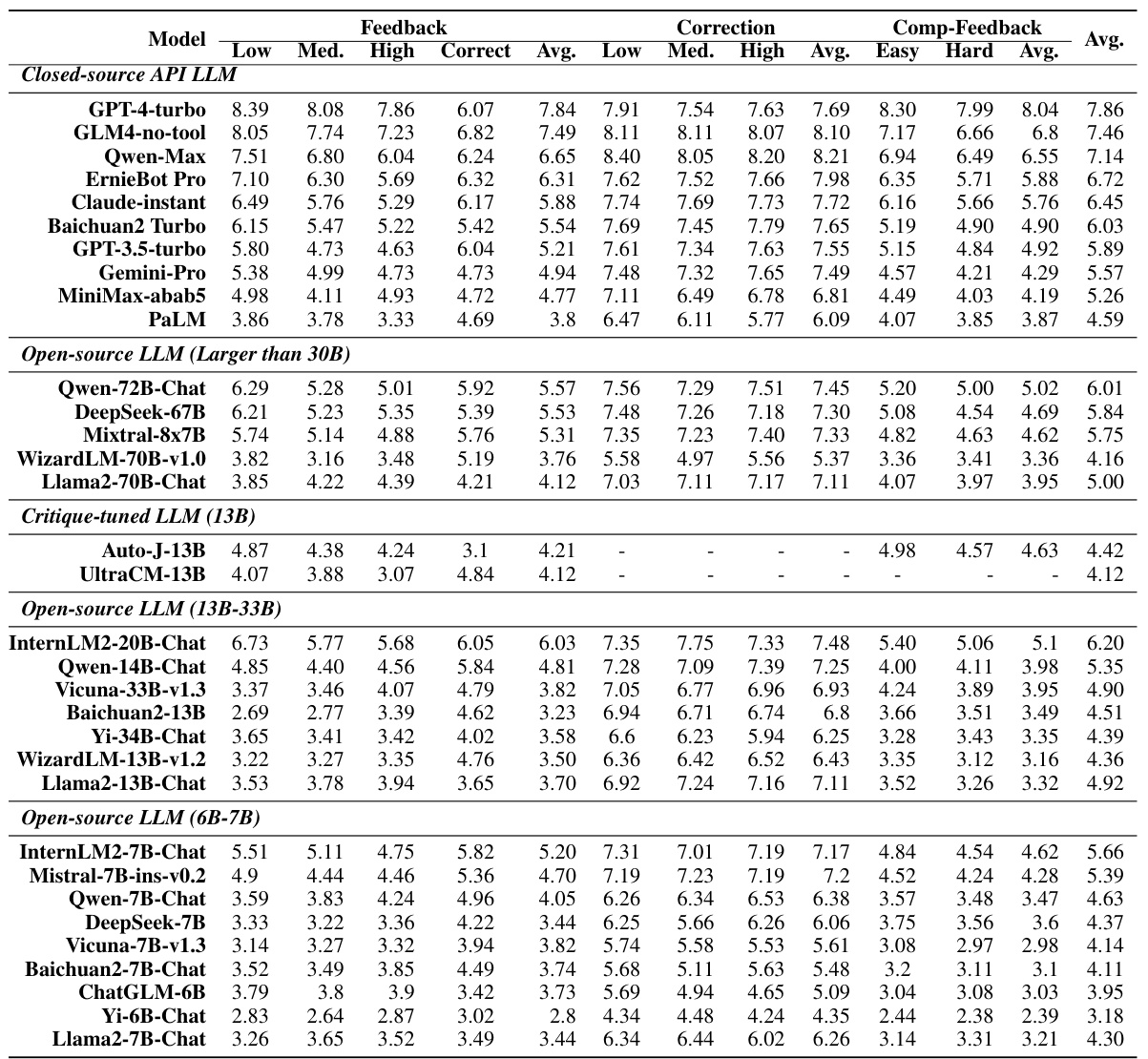
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL test set. The evaluation is broken down into four critique dimensions: feedback, correction, comparison, and meta-feedback. For each dimension and each LLM, subjective scores (human evaluation) and objective scores (GPT-4 based evaluation) are provided. The table highlights the best and worst performing LLMs and indicates statistical significance where applicable.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down by four critique dimensions (feedback, correction, comparison, meta-feedback) and includes both subjective (human-rated quality) and objective (automatically computed) scores. Dark gray highlights the top-performing LLMs for each metric, while light gray highlights the worst-performing. The overall score represents an average across the critique dimensions.
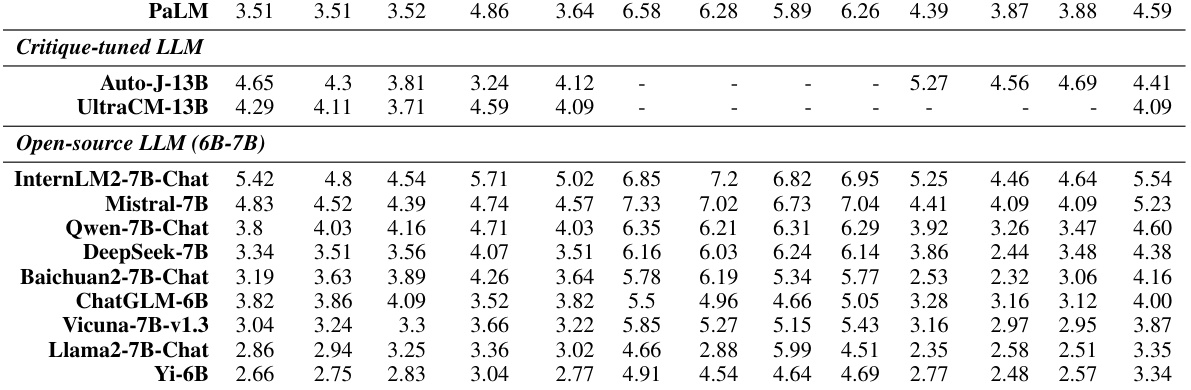
This table presents the subjective and objective evaluation results for various large language models (LLMs) on the CRITICEVAL benchmark. The objective metrics measure the correlation between LLM-generated critique scores and human judgments across four critique dimensions: feedback, correction, comparison, and meta-feedback. Subjective scores represent human ratings of the quality of textual critiques. The table highlights the best and worst performing models in each dimension, indicating the relative strengths and weaknesses of each LLM in providing critiques.

This table presents the subjective and objective evaluation results for various LLMs on the CRITICEVAL benchmark’s test set. The evaluation metrics cover four critique dimensions: feedback, correction, comparison, and meta-feedback. Performance is shown for both closed-source and open-source models, highlighting the best and worst performers. Statistical significance (p-value) is indicated for objective feedback and meta-feedback scores. The overall score is calculated by averaging across all four dimensions.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down into four critique dimensions: feedback, correction, comparison, and meta-feedback. Both scalar (numerical scores) and natural language (textual critiques) formats are included. Dark gray highlights the best-performing LLMs, and light gray highlights the worst. The ‘Overall’ column shows the aggregate score across all dimensions. The p-value indicates statistical significance.
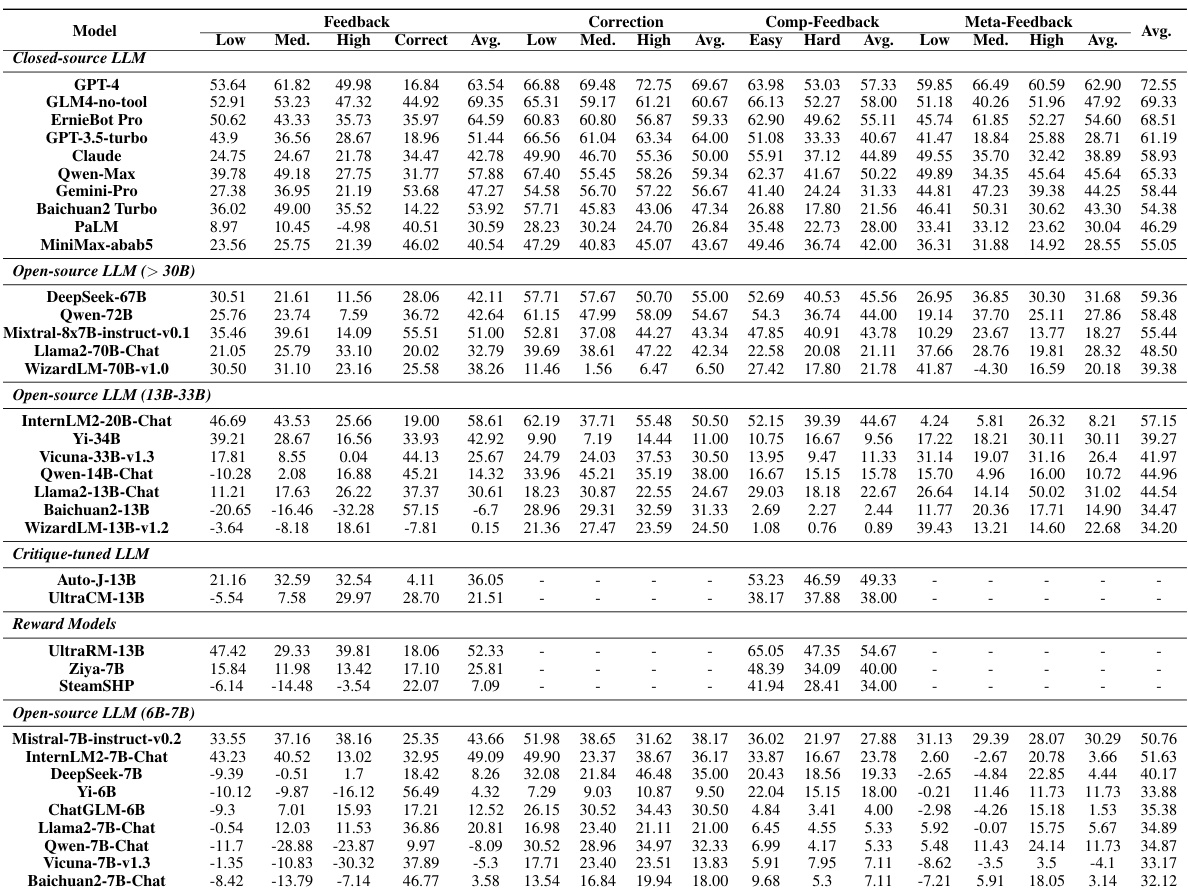
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The results are broken down by four critique dimensions: feedback (Fs), correction (CR), comparison (Fc), and meta-feedback (F₄(Fs)). For each dimension, both subjective and objective scores are shown, along with an overall score. The table highlights the best and worst performing models in dark and light gray, respectively, and indicates where the p-value for objective scores exceeds 0.05.
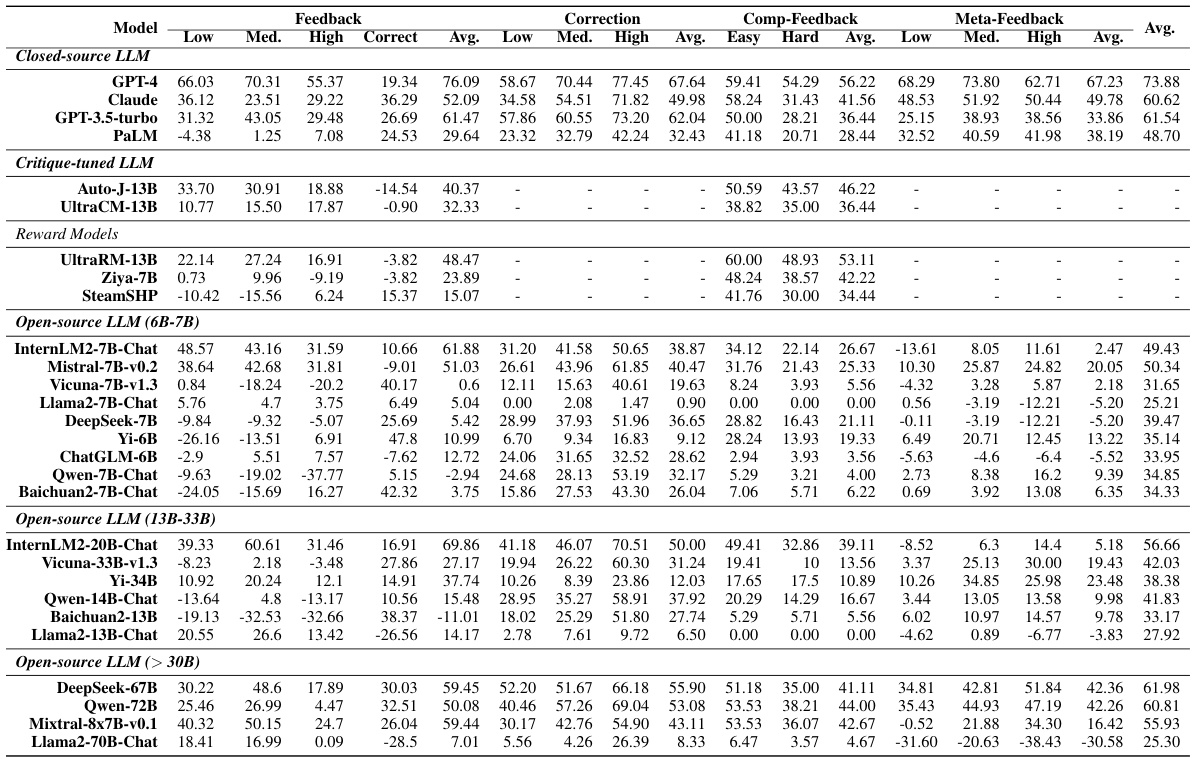
This table presents the subjective and objective evaluation results for several large language models (LLMs) on the CRITICEVAL benchmark. The subjective evaluation uses human ratings on four dimensions of critique: feedback, correction, comparison, and meta-feedback. Objective evaluation uses metrics like correlation and pass rate to assess the alignment of LLM critiques with human judgments. The table highlights the best and worst performing LLMs for each metric and dimension.

This table presents the subjective and objective evaluation results for various large language models (LLMs) on the CRITICEVAL benchmark’s test set. The evaluation considers four critique dimensions (feedback, correction, comparison, and meta-feedback). Dark gray highlights the best performing model, while light gray highlights the worst. Objective scores use correlation and pass rate metrics, and only scores with p-values below 0.05 are included. Subjective scores are averaged over multiple annotators. The ‘overall’ column represents a combined score across all dimensions.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation considers four critique dimensions (feedback, correction, comparison, and meta-feedback), and uses both subjective (human-rated) and objective (GPT-4-based) metrics. The table highlights the best and worst performing models for each dimension and overall, providing insights into the relative strengths and weaknesses of various LLMs in critiquing different tasks.

This table presents the subjective and objective evaluation results for 13 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down into four critique dimensions: feedback (Fs), correction (CR), comparison (Fc), and meta-feedback (F’(Fs)). Both subjective (human-rated quality) and objective (automatically computed using GPT-4) scores are reported for each dimension, along with an overall score combining all dimensions. Dark and light gray shading highlights the best and worst performing models, respectively.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down into four critique dimensions (feedback, correction, comparison, meta-feedback), with both subjective (human-rated) and objective (automatically computed) scores provided. The table highlights the best and worst performing models for each dimension and overall.
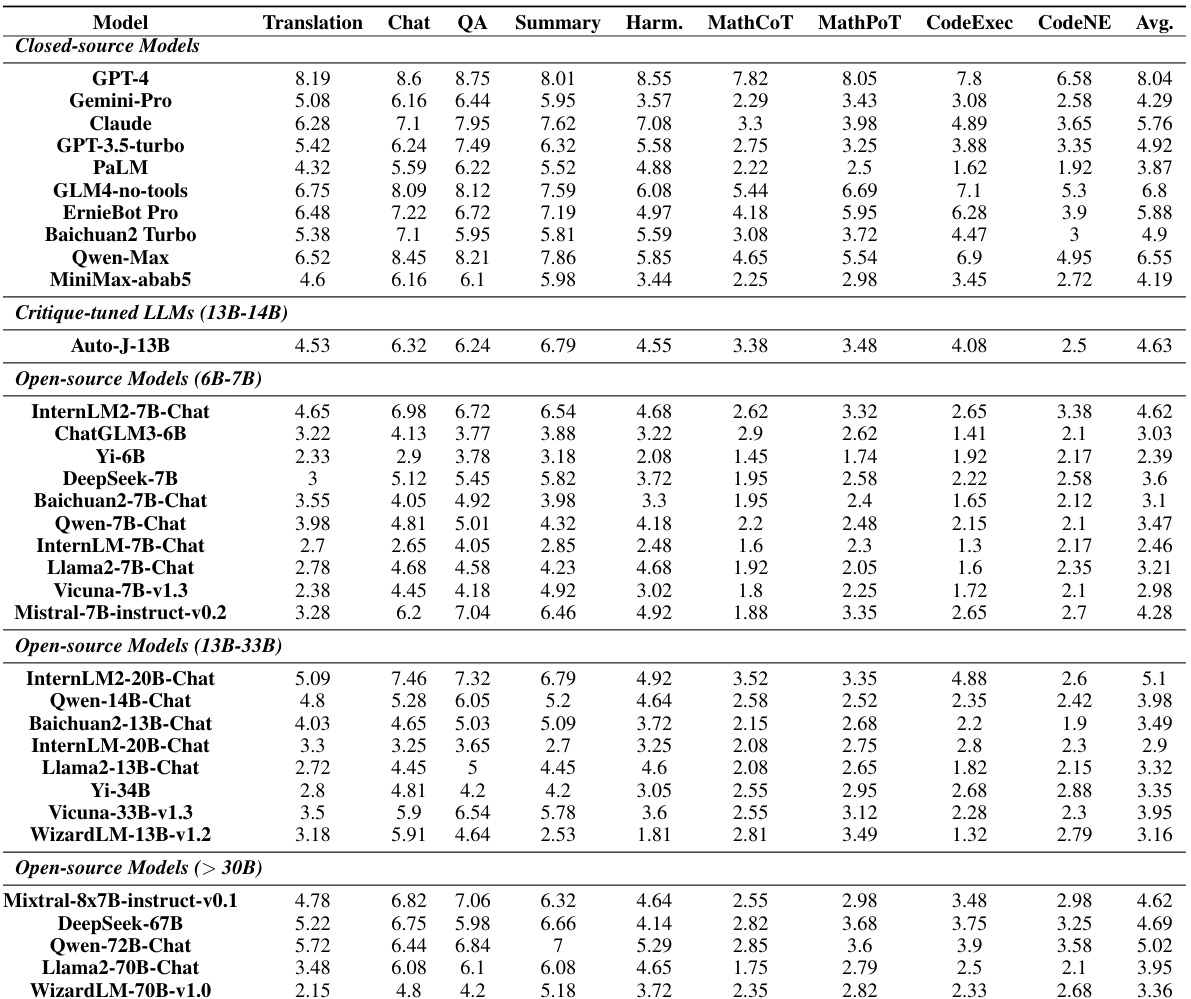
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down into four critique dimensions: feedback, correction, comparison, and meta-feedback. Both subjective (human-rated) and objective (automatically computed using GPT-4) scores are provided for each dimension. The table highlights the best and worst performing models for each metric and overall.
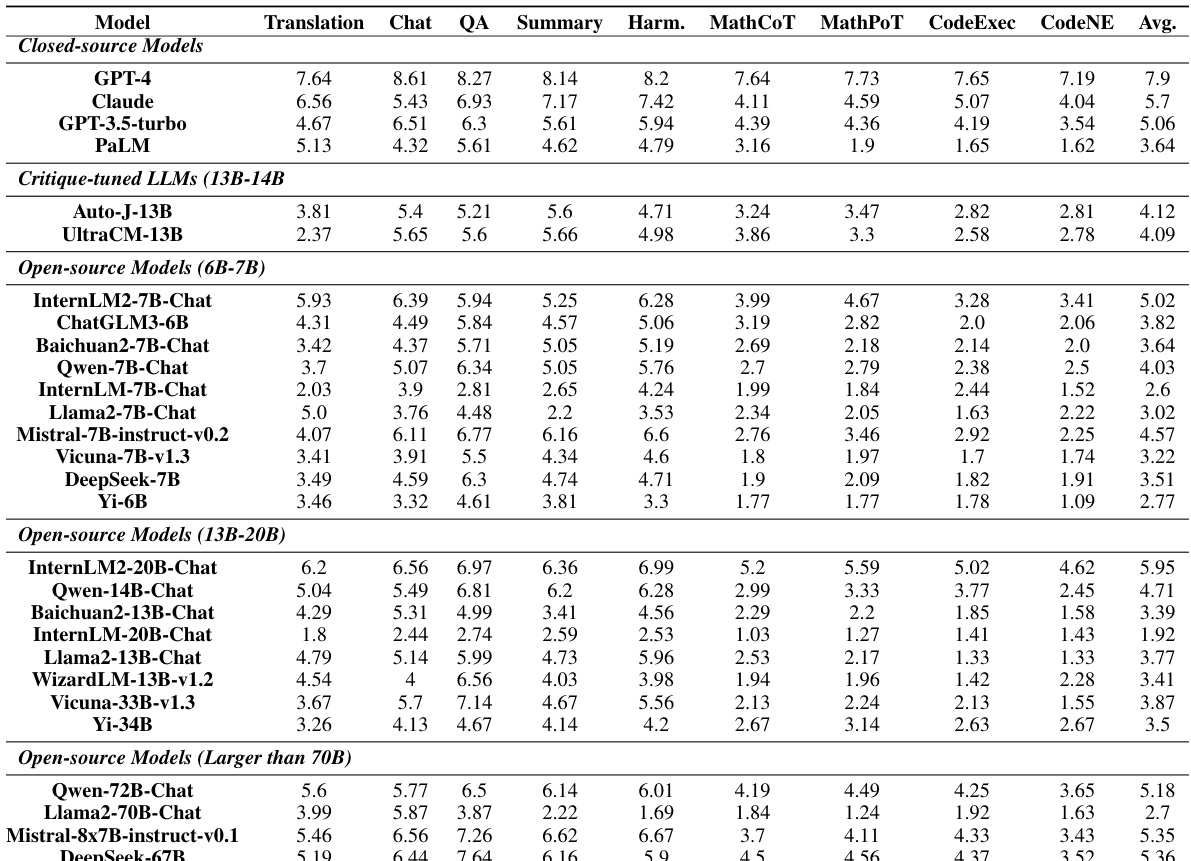
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation is broken down into four critique dimensions (feedback, correction, comparison, and meta-feedback) and includes both subjective (human-rated quality) and objective (correlation with GPT-4 judgments) metrics. Darker shading indicates better performance, and a † symbol denotes objective scores with a p-value > 0.05. The ‘Overall’ column provides an aggregate score across all dimensions.
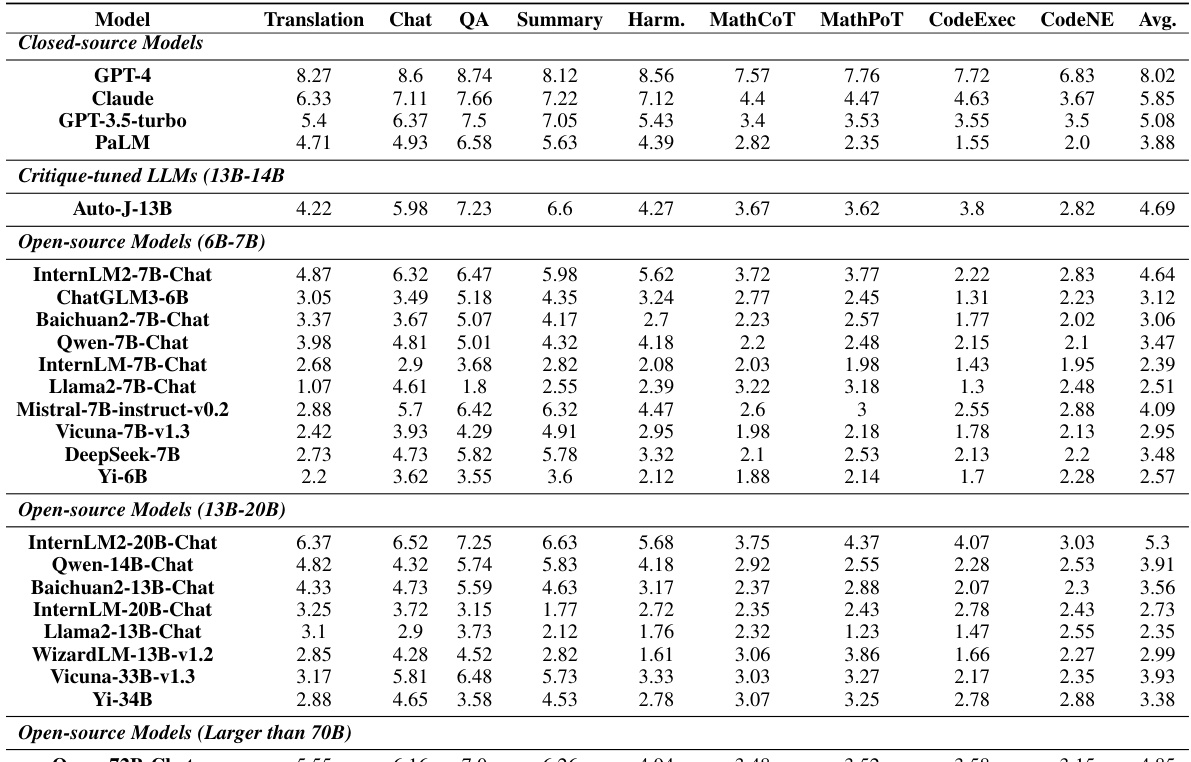
This table presents the subjective and objective evaluation results for various LLMs on the CRITICEVAL benchmark’s test set. The results are broken down by four critique dimensions (feedback, correction, comparison, meta-feedback) and include both subjective (human-rated) and objective (automatically computed) scores. Darker shading indicates better performance, and a † symbol denotes objective scores with a p-value greater than 0.05. The overall score is the average across all dimensions.

This table presents the subjective and objective evaluation results for several large language models (LLMs) on the CRITICEVAL benchmark. The subjective scores reflect human judgment of the quality of the LLMs’ critiques, while the objective scores measure the correlation between the LLMs’ evaluations and human judgments. The table breaks down the results by four critique dimensions (feedback, correction, comparison, and meta-feedback), showing the performance of each LLM in each dimension and overall. The table highlights the best and worst performing models, indicating which models excel and where improvements are needed.
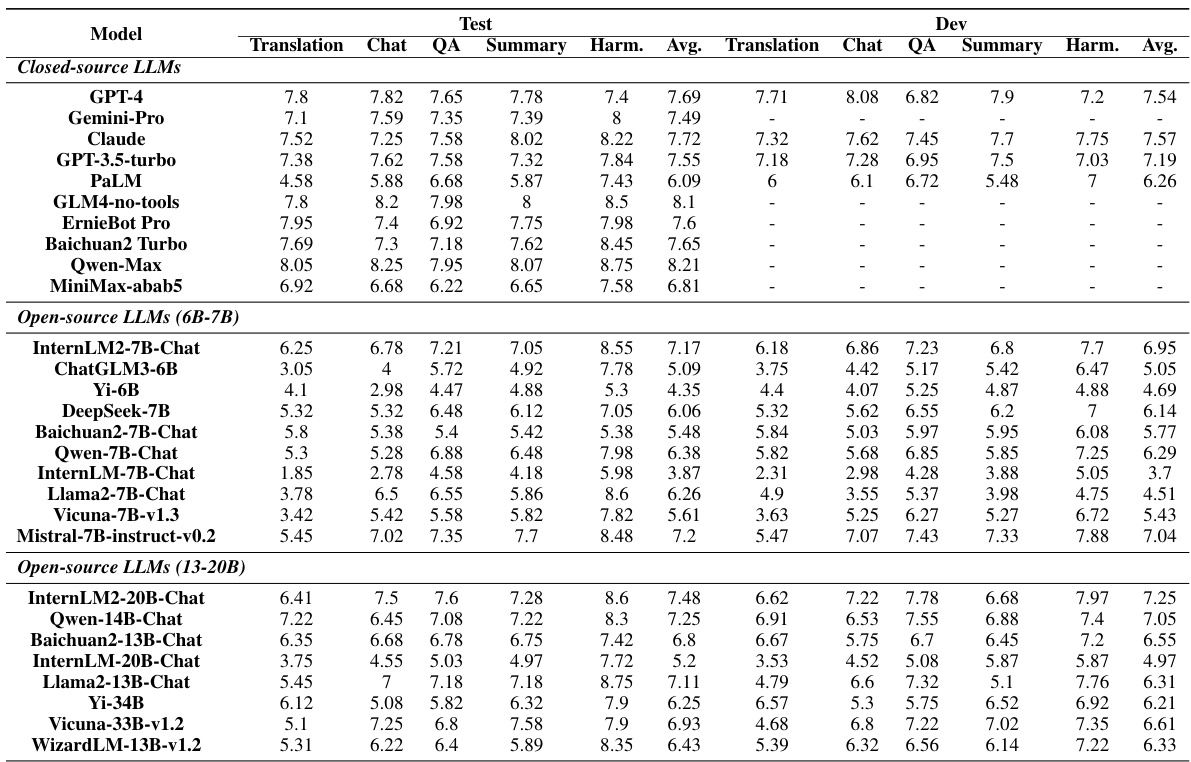
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The evaluation considers four critique dimensions (feedback, correction, comparison, and meta-feedback), and both subjective (human-rated quality) and objective (automatically computed using GPT-4) metrics are reported. The table highlights the best and worst performing models for each dimension and provides an overall score.

This table presents a comprehensive evaluation of various Large Language Models (LLMs) on the CRITICEVAL benchmark. It shows both subjective and objective scores across four critique dimensions: feedback, correction, comparison, and meta-feedback. The objective scores are based on correlations with human judgements, while subjective scores represent human ratings of the generated critiques. The table highlights the top-performing and worst-performing models in each category and provides an overall score across all dimensions.
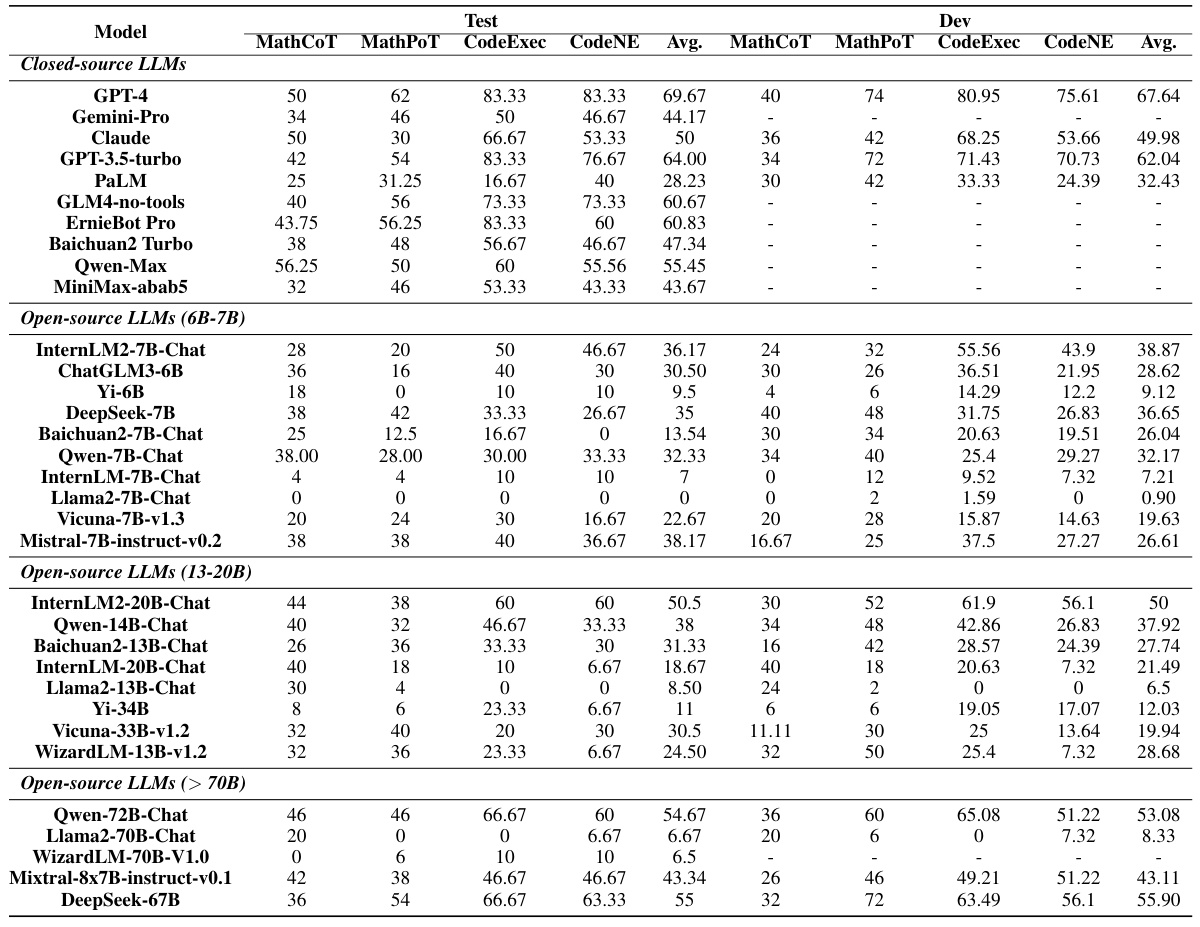
This table presents the subjective and objective evaluation results for various LLMs on the CRITICEVAL benchmark’s test set. It shows the performance of each model across four critique dimensions (feedback, correction, comparison, meta-feedback), with scores indicating quality. The table highlights the best and worst-performing models, and notes statistical significance (p-values) where applicable.

This table presents the subjective and objective evaluation results for several closed-source and open-source LLMs on the CRITICEVAL benchmark’s test set. The evaluation considers four critique dimensions: feedback, correction, comparison, and meta-feedback. Both scalar and textual critique formats are assessed. Dark gray highlights the best-performing model, while light gray highlights the worst-performing model for each metric. Objective scores are based on correlations with human judgments, while subjective scores are Likert-scale human ratings.

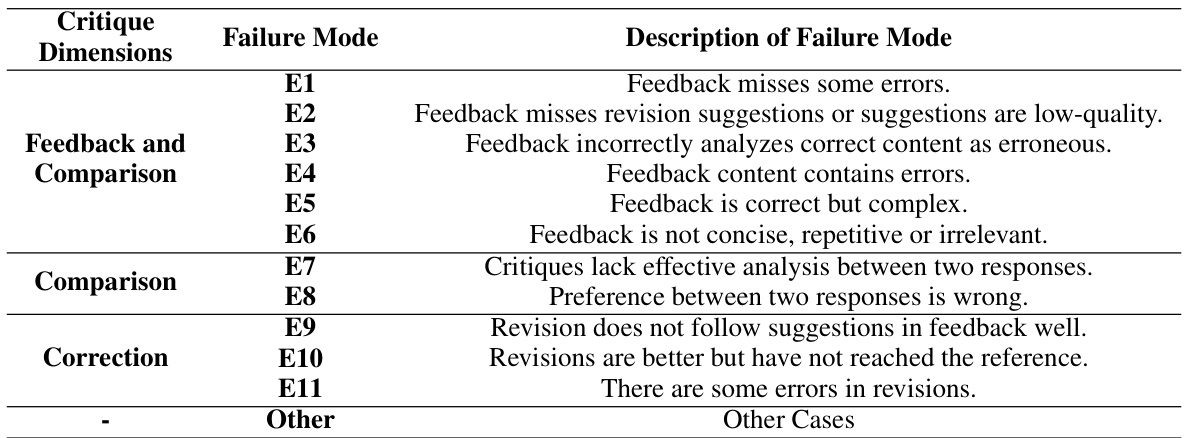
This table presents a comparison of the performance between human annotators and the GPT-4-turbo model in the feedback dimension of the CRITICEVAL benchmark. It shows the distribution of different failure modes (E1-E6 and ‘Other’) in the feedback generated by both humans and GPT-4. Each failure mode represents a specific type of error or deficiency in the feedback. The values represent the percentage of critiques exhibiting each failure mode. This allows for a detailed analysis of the strengths and weaknesses of both human and AI-generated feedback in terms of accuracy and completeness.

This table presents a comparison of the performance between human annotators and the GPT-4-turbo model on the comparison dimension of the CRITICEVAL benchmark. It breaks down the distribution of different failure modes (E1-E8, Other) in the critiques generated by both humans and GPT-4-turbo, highlighting their relative strengths and weaknesses in identifying and analyzing response quality differences.

This table compares the performance of human annotators and the GPT-4-turbo model on the correction dimension of the CRITICEVAL benchmark. It shows the distribution of different failure modes (E1, E2, E3, and Other) for human and GPT-4 evaluations, highlighting the differences in their critique performance. These failure modes likely represent different types of mistakes made in the corrections.
This table presents a comprehensive evaluation of various LLMs across four critique dimensions (feedback, correction, comparison, meta-feedback) on the CRITICEVAL test set. It shows both subjective (human-rated quality) and objective (automatically computed using GPT-4) scores. The best and worst performing models are highlighted, and statistical significance (p-value) is indicated for objective measures. The overall score summarizes performance across all dimensions.

This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The results are broken down by four critique dimensions (feedback, correction, comparison, meta-feedback) and include both subjective (human-rated) and objective (GPT-4-based) scores. Dark gray highlights the best-performing model in each category, while light gray highlights the worst. The overall score is an average across all dimensions. Note that statistically insignificant objective scores are marked with a dagger symbol.
This table presents the subjective and objective evaluation results for 35 different LLMs on the CRITICEVAL benchmark’s test set. The results are broken down by four critique dimensions (feedback, correction, comparison, and meta-feedback), showing both subjective (human-rated) and objective (GPT-4-based) scores. The table highlights the best and worst-performing LLMs in terms of overall performance and also indicates statistical significance for objective scores. The overall score reflects the average performance across all dimensions.

This table presents the subjective and objective evaluation results for several LLMs on the CRITICEVAL benchmark’s test set. The evaluation considers four critique dimensions: feedback, correction, comparison, and meta-feedback. Scores are provided for both subjective (human-rated quality) and objective (GPT-4-based) evaluations, highlighting the best and worst performing models. The overall score reflects the performance across all dimensions.
Full paper#