↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Non-exemplar Class-Incremental Learning (NECIL) faces the challenge of learning new classes without retaining old data, leading to conflicts between old and new class representations. Existing methods address these conflicts retrospectively, which is inefficient. This leads to catastrophic forgetting, where the model’s performance degrades on previously learned tasks.
The proposed Prospective Representation Learning (PRL) method tackles this issue by proactively managing the embedding space. During the initial phase, PRL squeezes the embedding distribution of the current classes to create space for new ones. During the incremental phase, PRL ensures that new class features are placed away from old class prototypes in a latent space, aligning the embedding spaces to minimize the disruption caused by new classes. This plug-and-play approach helps existing NECIL methods handle conflicts effectively, resulting in state-of-the-art performance on multiple benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of non-exemplar class-incremental learning (NECIL), which is crucial for developing AI systems capable of continuously learning and adapting in open and dynamic environments. The proposed approach significantly improves the state-of-the-art in NECIL, providing a robust and efficient solution for handling conflicts between old and new classes without requiring the storage of old data. This opens up new avenues for research in lifelong learning and has implications for various applications, particularly in domains with privacy and storage constraints.
Visual Insights#
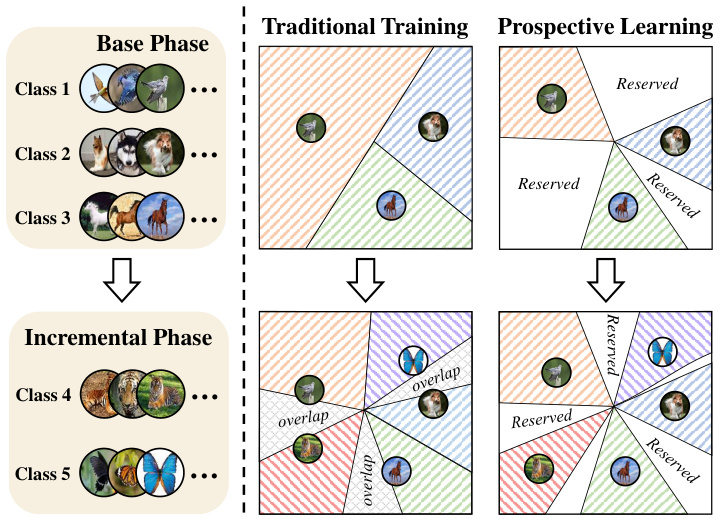
This figure illustrates the difference between traditional training and prospective learning approaches in Non-exemplar Class-Incremental Learning (NECIL). Traditional training methods result in overlapping embedding spaces for old and new classes as new classes are introduced, leading to confusion and poor performance. In contrast, prospective learning aims to reserve space in the embedding space for future classes during the base phase, allowing for better integration of new classes during the incremental phase and minimizing overlap and confusion. This proactive space management helps maintain the performance of the model on previously learned classes while adapting to new classes.
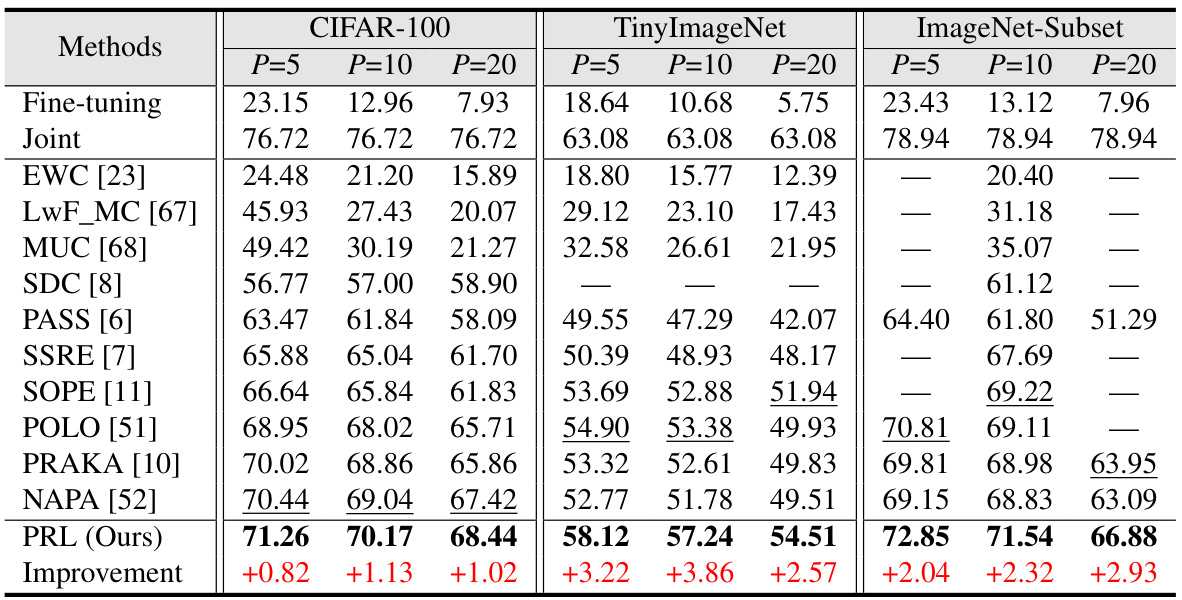
This table compares the average incremental accuracy of the proposed Prospective Representation Learning (PRL) method with several state-of-the-art (SOTA) non-exemplar class-incremental learning (NECIL) methods across three datasets: CIFAR-100, TinyImageNet, and ImageNet-Subset. The comparison is performed for different numbers of incremental phases (P=5, P=10, P=20). The best accuracy for each setting is highlighted in bold, and the underperforming methods are underlined. The improvement achieved by PRL over the best SOTA method is shown in red, indicating the performance gain of the proposed method.
In-depth insights#
Prospective Learning#
Prospective learning, in the context of class-incremental learning, offers a paradigm shift from traditional reactive approaches. Instead of addressing conflicts between old and new classes only when new data arrives (as in traditional methods), prospective learning aims to prepare the model proactively. This involves reserving embedding space for future classes during the initial training phase and strategically embedding new classes within this reserved space during incremental learning, minimizing interference with previously learned classes. This forward-thinking strategy significantly improves the balance between learning new information and retaining past knowledge, which is a major hurdle in class-incremental learning. The key advantage is mitigating catastrophic forgetting by proactively managing the embedding space, thus enhancing model performance and stability over multiple learning phases. Preventing overlap between old and new classes is paramount to success, and this approach offers a promising method for tackling the inherent challenges in this complex learning problem.
Embedding Squeezing#
Embedding squeezing, within the context of non-exemplar class-incremental learning (NECIL), is a proactive strategy to address the challenge of catastrophic forgetting. Traditional NECIL methods often deal with the conflict between old and new classes reactively, only after new data arrives. Embedding squeezing, in contrast, preemptively allocates space in the feature embedding space for future classes during the initial training phase. This proactive measure aims to mitigate the overlap between embeddings of old and new classes that occurs in later phases when the model encounters new data. By creating inter-class separation and intra-class concentration, embedding squeezing prepares the model to handle future classes more effectively. The method essentially optimizes embedding space distribution before the arrival of new data, thus facilitating the smooth integration of new classes without significant interference with already learned representations. The core idea is to create reserved space in a latent space for new classes, reducing the likelihood of catastrophic forgetting and improving model performance on both old and new classes.
Prototype-Guided Update#
The heading ‘Prototype-Guided Update’ suggests a method within a class-incremental learning framework that leverages prototypes to refine model representations as new classes are introduced. This is crucial in non-exemplar scenarios where past data isn’t available. The approach likely involves creating prototypes (e.g., class means) for previously seen classes. These prototypes act as surrogates for past data, guiding the update process. When new classes arrive, their features are likely compared to the existing prototypes in a shared embedding space. The method probably minimizes interference by strategically embedding the new class features while maintaining the integrity of the existing prototypes. This might involve pushing new class features away from existing prototypes to reduce confusion and possibly aligning the embedding space to preserve information learned from past classes. The algorithm is designed to be efficient and avoid catastrophic forgetting in the absence of past samples. The effectiveness of this strategy hinges on the quality of prototypes and the choice of embedding space metric.
Ablation Experiments#
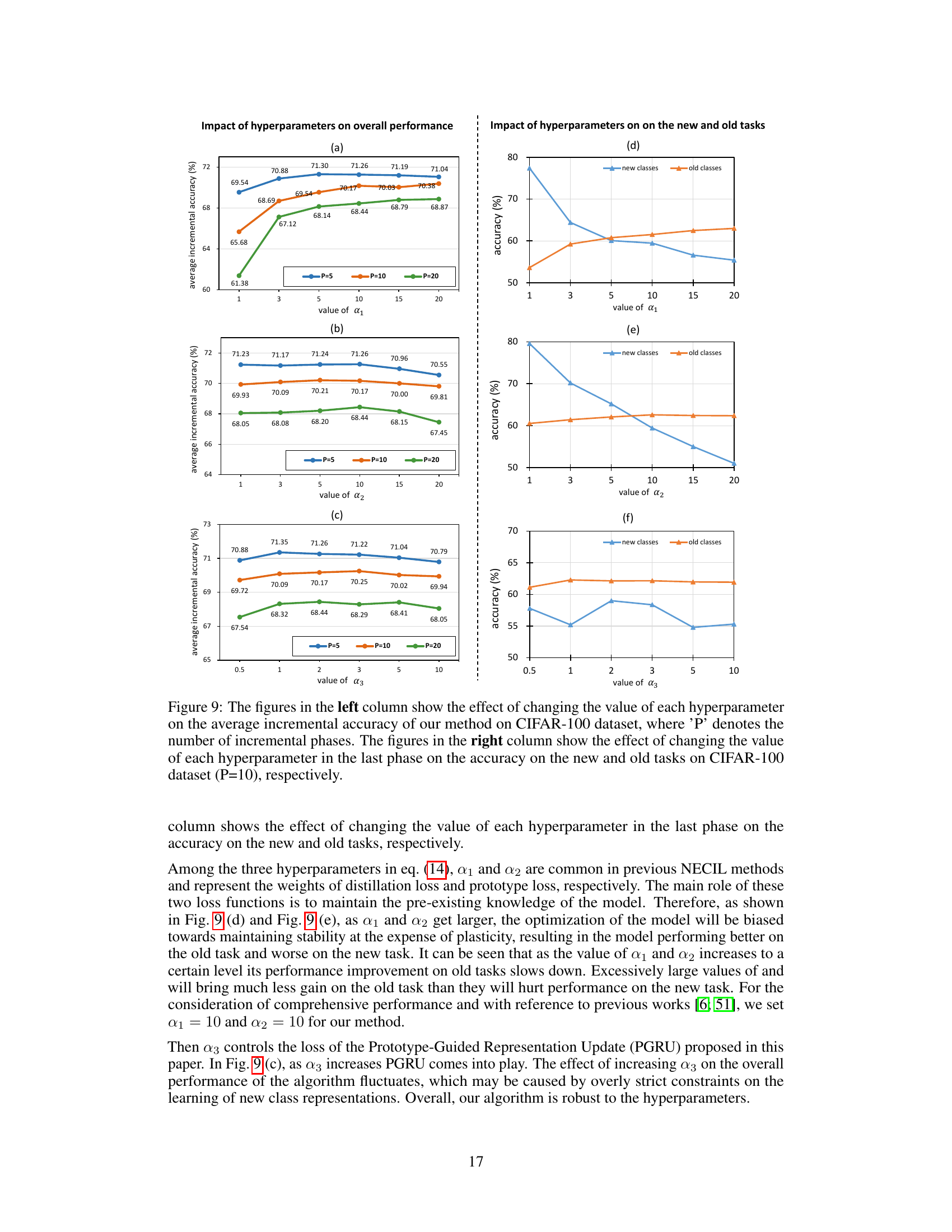
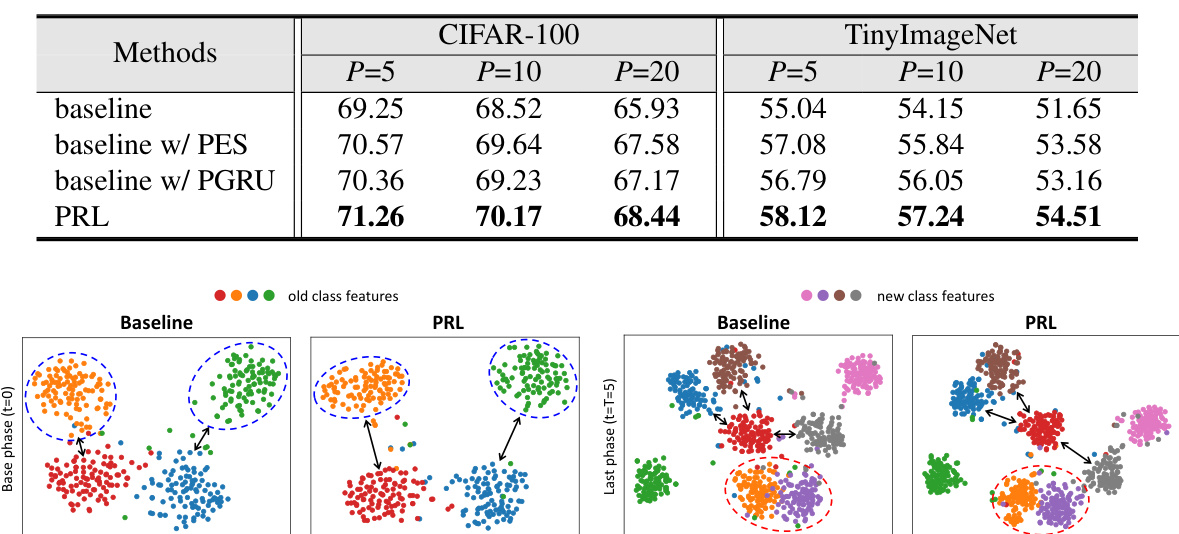
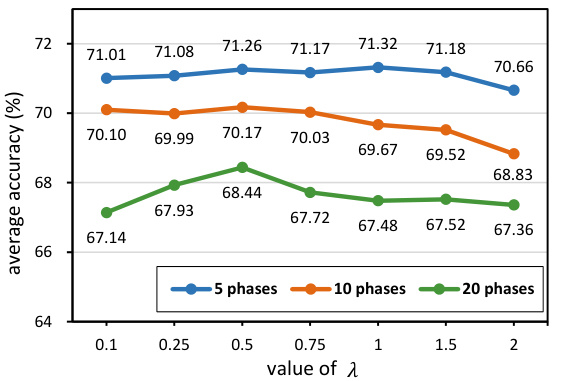
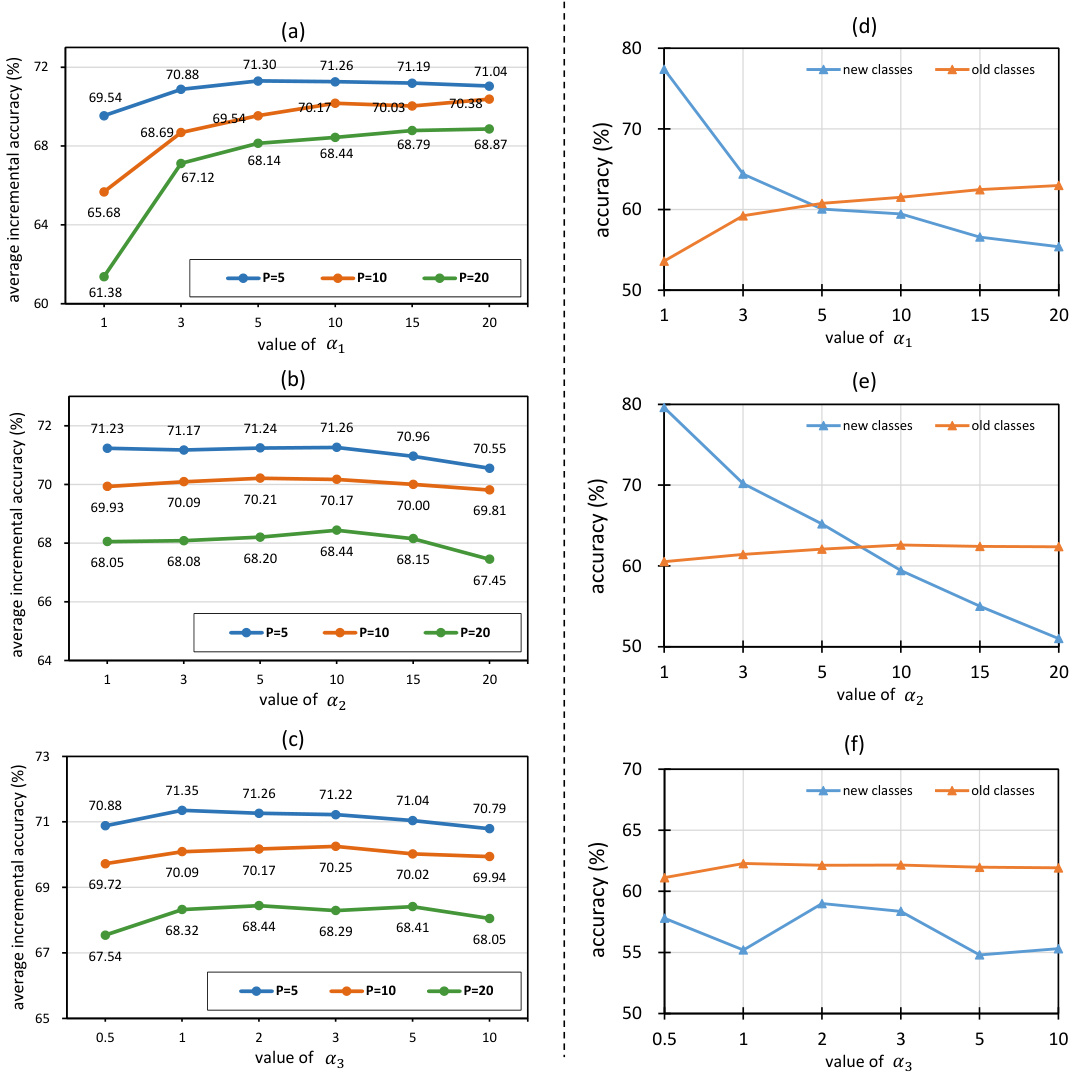
Ablation experiments systematically remove components of a model to assess their individual contributions. In the context of a research paper on class-incremental learning, ablation studies would likely focus on evaluating the effects of different modules, such as the preemptive embedding squeezing (PES) and the prototype-guided representation update (PGRU). By selectively disabling PES, researchers can determine its impact on maintaining representation space for new classes and reducing catastrophic forgetting. Similarly, deactivating PGRU isolates its effects on managing conflicts between old and new class features during incremental updates. The results of such experiments reveal the relative importance of each module in the overall success of the class-incremental learning approach. A comprehensive ablation study would examine varying degrees or different implementations of PES and PGRU to find optimal settings. Analyzing the performance metrics — such as average incremental accuracy, and visualizing feature representations — across different ablation settings would provide insights into the interplay between the modules and how they impact learning behavior. The findings can demonstrate that a specific architecture component is crucial for obtaining high performance while others might have only a modest effect.
Future of NECIL#
The future of Non-Exemplar Class-Incremental Learning (NECIL) hinges on addressing its current limitations. Overcoming catastrophic forgetting without exemplar access remains a core challenge. Future research should explore novel methods that effectively leverage latent space manipulation and knowledge distillation techniques to minimize interference between old and new classes. Developing more robust prototype representations that adapt dynamically to the evolving feature space is crucial. Incorporating advanced regularization strategies that selectively protect important network parameters could enhance stability. Investigating the potential of meta-learning to improve forward transfer and reduce the need for extensive retraining is also promising. Ultimately, a deeper understanding of the underlying mechanisms of catastrophic forgetting in NECIL is needed to develop truly effective and scalable solutions for open-ended learning problems.
More visual insights#
More on figures

This figure illustrates the two main components of the Prospective Representation Learning (PRL) method for Non-Exemplar Class-Incremental Learning (NECIL). Panel A shows the ‘Preemptive Embedding Squeezing’ (PES) step in the base phase, where the model proactively reserves space for future classes by compacting the embeddings of the current classes. Panel B depicts the ‘Prototype-Guided Representation Update’ (PGRU) strategy during the incremental phase. Here, new class features are projected into a latent space, pushed away from the prototypes of old classes, and then used to guide an update of the main model. This ensures the new classes don’t interfere with the previously learned ones.

This figure illustrates the two main components of the proposed Prospective Representation Learning (PRL) method for Non-exemplar Class-Incremental Learning (NECIL). Panel (A) shows the base phase, where a preemptive embedding squeezing (PES) constraint is used to create space for future classes by compacting the embeddings of the current classes. Panel (B) depicts the incremental phase, where a prototype-guided representation update (PGRU) strategy is employed. PGRU projects new class features and saved prototypes into a latent space, ensuring that new features are clustered away from old prototypes, thereby reducing confusion between old and new classes when updating the model.
This figure illustrates the two main components of the Prospective Representation Learning (PRL) method for Non-exemplar Class-Incremental Learning (NECIL). Part (A) shows the ‘Preemptive Embedding Squeezing’ which occurs during the base phase of training. This step aims to proactively reserve space in the embedding space for future classes by compacting the representations of the currently known classes. Part (B) details the ‘Prototype-Guided Representation Update’, which happens in the incremental phase. This part utilizes stored prototypes of old classes to guide the embedding of new classes into the reserved space, minimizing interference between old and new class representations. The latent space is highlighted as a key component in aligning current and previous representations during updates.
This figure illustrates the two main phases of the Prospective Representation Learning (PRL) approach for Non-Exemplar Class-Incremental Learning (NECIL). The base phase (A) focuses on preemptive embedding squeezing (PES), which compresses the embeddings of existing classes to create space for future classes. The incremental phase (B) uses a prototype-guided representation update (PGRU) mechanism. This ensures that new classes are embedded in the reserved space created in the base phase and are kept separate from existing classes, thus preventing catastrophic forgetting and improving performance on both old and new classes.

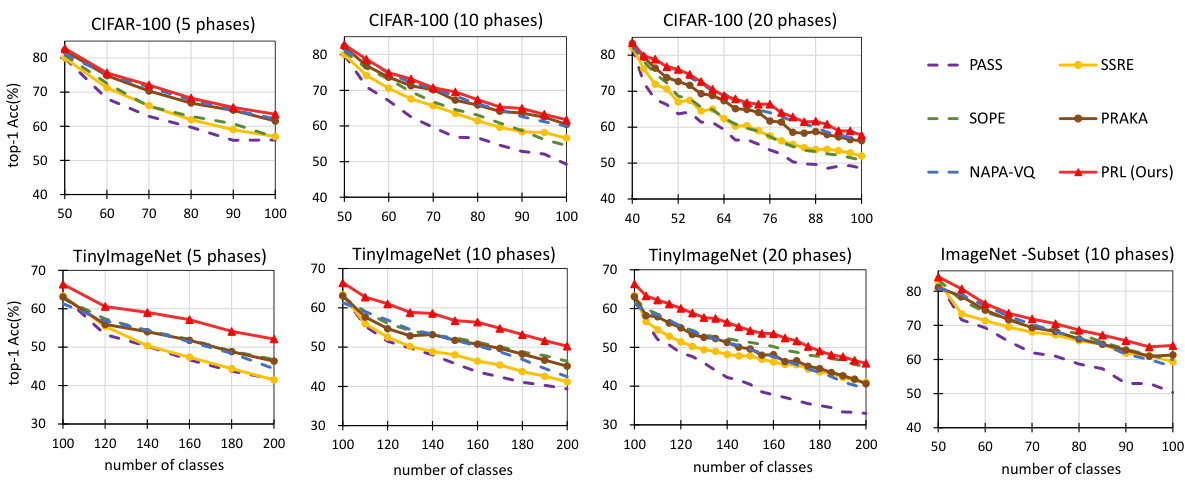
This figure displays detailed accuracy curves for three different datasets (CIFAR-100, TinyImageNet, and ImageNet-Subset) across varying numbers of incremental phases (5, 10, and 20). The curves show the top-1 accuracy at each phase for multiple methods (Fine-tuning, PASS, SSRE, SOPE, PRAKA, NAPA-VQ, and PRL). This allows for a comparison of the performance of these methods over the entire incremental learning process, rather than simply looking at average accuracy.

This figure compares the performance of three different methods (PRAKA, NAPA-VQ, and PRL) on both old and new tasks in a class incremental learning setting. The left plot shows the average accuracy on previously seen classes (old tasks) as more tasks are added. The right plot shows the accuracy on the newly introduced classes (current tasks) for each incremental phase. It demonstrates that PRL maintains better performance on old tasks and shows better plasticity (ability to learn new tasks) compared to the other methods.
This figure shows the detailed accuracy curves of different incremental class learning methods on three datasets: CIFAR-100, TinyImageNet, and ImageNet-Subset. Each curve represents a different number of incremental phases (5, 10, or 20). The x-axis shows the number of classes, while the y-axis represents the top-1 accuracy. The figure illustrates the performance of different algorithms over the course of incremental learning, showing how accuracy changes as new classes are added.

This figure presents detailed accuracy curves across different datasets (CIFAR-100, TinyImageNet, and ImageNet-Subset) and incremental learning phase configurations (5, 10, and 20 phases). Each line represents a specific dataset, demonstrating the accuracy of the model’s top-1 predictions for each phase of incremental training. It allows for a visual comparison of model performance across datasets and different numbers of incremental phases.
This figure shows the overview of the proposed Prospective Representation Learning (PRL) method for Non-exemplar Class-Incremental Learning (NECIL). Panel (A) illustrates the base phase where a preemptive embedding squeezing (PES) technique is used to proactively reserve space for future classes by compacting the embedding space of current classes. Panel (B) shows the incremental phase where a prototype-guided representation update (PGRU) method aligns the new class features with the reserved space while avoiding conflicts with existing classes by pushing them away from old class prototypes in a latent space. This combination of techniques aims to prevent catastrophic forgetting and improve the model’s ability to learn new classes without access to past data.
More on tables

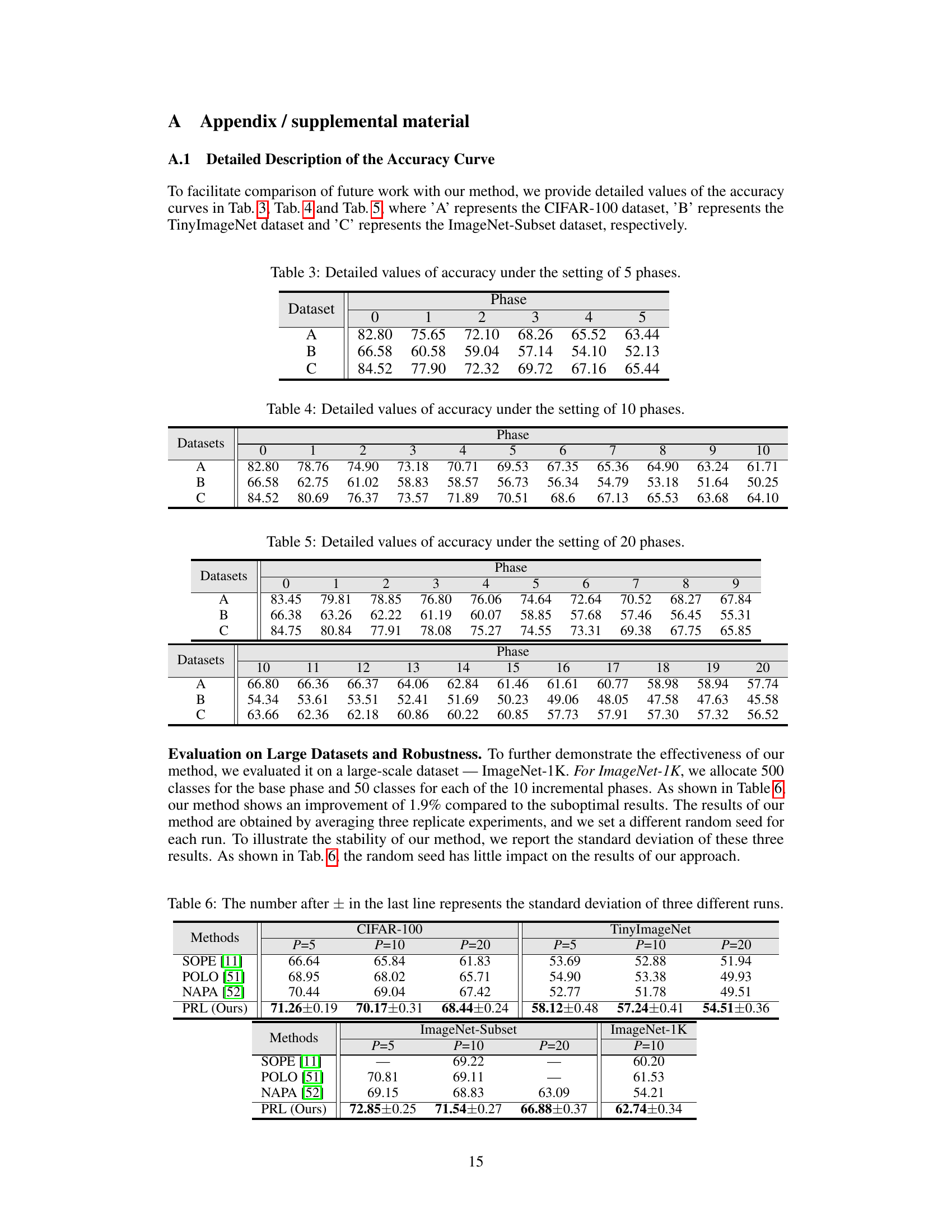
This table shows the detailed accuracy values for each phase (0-5) when using 5 phases in the incremental learning process. The dataset used are CIFAR-100, TinyImageNet, and ImageNet-Subset, represented by A, B, and C respectively.

This table presents the detailed accuracy values for each phase (0-10) across three different datasets (A, B, C) when the model is trained with 10 incremental phases. Dataset A likely refers to CIFAR-100, B to TinyImageNet, and C to ImageNet-Subset based on the paper. The numbers represent the accuracy achieved at each incremental phase. This provides a more granular view of the model’s performance than simply reporting the average accuracy across all phases.

This table presents a quantitative comparison of the average incremental accuracy achieved by different methods on three datasets: CIFAR-100, TinyImageNet, and ImageNet-Subset. The comparison includes several state-of-the-art (SOTA) non-exemplar class-incremental learning (NECIL) methods and the proposed method, PRL. The number of incremental phases (P) is varied to assess performance under different conditions. The best performing method for each condition is highlighted in bold, and methods with suboptimal performance are underlined. Relative improvements of the proposed method over the SOTA are shown in red.

This table presents a quantitative comparison of the proposed Prospective Representation Learning (PRL) method against state-of-the-art (SOTA) Non-exemplar Class-Incremental Learning (NECIL) methods. It shows the average incremental accuracy achieved by each method across multiple datasets (CIFAR-100, TinyImageNet, and ImageNet-Subset) and varying numbers of incremental phases (P=5, P=10, P=20). The best-performing method for each scenario is highlighted in bold, while methods that underperform are underlined. The improvement of PRL over the best SOTA method is indicated in red.
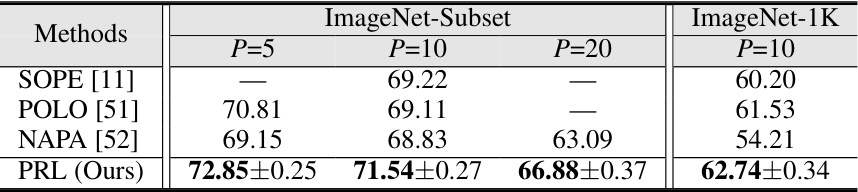
This table presents a quantitative comparison of the proposed Prospective Representation Learning (PRL) method against state-of-the-art (SOTA) methods for non-exemplar class-incremental learning (NECIL) on three datasets: CIFAR-100, TinyImageNet, and ImageNet-Subset. The results are reported as average incremental accuracy, indicating the model’s performance across multiple incremental phases (P=5, 10, or 20). The best-performing method for each scenario is highlighted in bold, and those performing sub-optimally are underlined. Improvements over SOTA are shown in red, illustrating the superiority of the proposed PRL.

This table presents a quantitative comparison of the average incremental accuracy achieved by the proposed method (PRL) and several state-of-the-art (SOTA) methods for Non-exemplar Class-Incremental Learning (NECIL) on three benchmark datasets: CIFAR-100, TinyImageNet, and ImageNet-Subset. The results are broken down by the number of incremental phases (P=5, P=10, P=20), showing the average accuracy across all seen classes for each phase. The best performance for each setting is highlighted in bold, while suboptimal results are underlined. Improvements achieved by PRL compared to SOTA are indicated in red, clearly showing the advantages of the proposed approach.
Full paper#