↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Text-to-image (T2I) generation using diffusion probabilistic models has become highly successful, but the underlying mechanism remains unclear. This paper investigates the process by analyzing intermediate states during image generation. A key observation is that image shape is determined early on, followed by detail refinement. This two-stage process raises questions about how text prompts contribute to the process.
The researchers explore the impact of individual tokens, especially the [EOS] (end-of-sentence) token in text prompts, on each generation stage. They find that [EOS] significantly impacts the initial shape generation. Leveraging this insight, they propose a method to accelerate T2I generation by removing text guidance in the detail-generation phase. This leads to a substantial 25%+ improvement in sampling speed. Their experiments support the “first shape then details” model of T2I generation and demonstrate the critical role of text prompts, particularly the [EOS] token, in this process.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on text-to-image diffusion models. It unveils the underlying mechanism of how text prompts influence image generation, offering valuable insights for improving model efficiency and accelerating the sampling process. The findings also open up new avenues for research in understanding the role of individual tokens and optimizing the generation process.
Visual Insights#

This figure shows the cross-attention maps during the denoising process. (a) shows the averaged cross-attention map for each token at different time steps. The brighter the pixel, the stronger the attention weight. (b) plots the relative F1-score (the overlap between the shapes of the cross-attention map and the generated image) against the denoising steps. The figure demonstrates that the overall shape of the generated image is decided in the early stage, while the details are refined at the later stages.

This table presents the results of an experiment to evaluate the effect of removing text prompt at different stages of the denoising process in Stable Diffusion. The experiment varied the starting step (a) at which the text prompt was removed, and compared the results to the baseline (a=0). Metrics include Image-CLIPScore (higher is better), L1-distance (lower is better), saved latency (higher is better), and FID (lower is better). The results are shown for different samplers (DDIM and DPM-Solver) and Stable Diffusion model versions (v1.5, v2.1, and Pixart-Alpha).
In-depth insights#
T2I Diffusion Deep Dive#
A deep dive into Text-to-Image (T2I) diffusion models would explore the intricate process of transforming text prompts into realistic images. Understanding the role of text encoders in converting textual descriptions into meaningful latent representations is crucial. The analysis should delve into the diffusion process itself, examining how noise is gradually added and removed to generate images, focusing on the interaction between text embeddings and image generation. Investigating the impact of different architectures, such as U-Nets, and the effectiveness of techniques like classifier-free guidance are key. A comprehensive exploration would also evaluate the model’s ability to handle various text inputs, analyzing its capabilities to capture nuances of language and generate diverse image outputs. Evaluating the trade-off between image quality and computational cost is another important aspect, with an emphasis on efficient sampling methods. Ultimately, a thorough ‘deep dive’ should offer actionable insights into optimizing these models for improved performance and broader applications.
[EOS] Token Dominance#
The concept of ‘[EOS] Token Dominance’ in text-to-image diffusion models suggests that the end-of-sentence token ([EOS]) plays a disproportionately significant role in the image generation process. Early stages of image generation are heavily influenced by the [EOS] token, establishing the foundational structure and overall shape of the image. This implies that the [EOS] token encapsulates a significant portion of the semantic information encoded from the entire prompt, effectively acting as a powerful summary. While other tokens contribute to finer details and specific features, the [EOS] token’s dominance in shaping the image’s overall form is crucial. This finding challenges the assumption that all tokens within a prompt contribute equally to image generation, highlighting the importance of understanding the hierarchical impact of different tokens in these complex models. Further research is needed to understand exactly how the model utilizes this information from [EOS], and whether this dominance is consistent across different model architectures and prompt styles.
Two-Stage Generation#
The concept of “Two-Stage Generation” in text-to-image diffusion models proposes a fascinating mechanism. The initial stage focuses on constructing the overall shape and structure of the image, primarily guided by low-frequency signals and influenced heavily by the [EOS] token. This foundational stage lays the groundwork for the image’s composition, establishing its basic form before detailing commences. Subsequently, the second stage refines the image by incorporating high-frequency details and textures, enriching the image with nuanced information and finer aspects. This stage appears to rely less on direct textual guidance, and more on the model’s inherent capabilities. This two-stage approach efficiently leverages the model’s strengths: it first ensures the image’s fundamental coherence, then builds upon this solid base to create a highly detailed output. This separation also suggests potential optimizations for accelerating the generation process, by strategically removing textual guidance in later stages, as the model’s internal consistency takes over.
Frequency-Based Analysis#
A frequency-based analysis in the context of a research paper on text-to-image diffusion models would likely involve investigating the distribution of frequencies in the image data. This could be done using techniques such as Fourier transforms to decompose images into their constituent frequencies. The analysis would probably focus on the relationship between low-frequency components (representing overall shape and structure) and high-frequency components (representing details and texture). The researchers might explore how these frequency components change throughout the denoising process and how they relate to the input text prompt. For instance, they might find that low frequencies are established early in the process, guided by the text prompt, while high frequencies are filled in later. This could offer valuable insights into how the model generates images, revealing that the model first reconstructs the overall image structure before refining the details. Understanding the role of frequency information is crucial for improving both efficiency and quality of the image generation process. By carefully controlling the introduction of low- and high-frequency information at different stages of the denoising process, we can potentially accelerate sampling and generate higher-quality results. Moreover, this analysis can shed light on the model’s interpretation and utilization of the text prompt, leading to advanced methods in text-to-image synthesis.
Sampling Acceleration#
The proposed sampling acceleration technique leverages the observation that a text-to-image diffusion model reconstructs the overall image shape early in the denoising process, primarily influenced by the [EOS] token. This insight allows for the removal of text guidance during the later stages focused on detail refinement, significantly accelerating the sampling process. The effectiveness is demonstrated empirically by reducing inference time up to 25%+, while maintaining image quality. The strategy’s success is attributed to the efficient separation of shape generation (heavily reliant on early text information) from detail generation (largely data-driven). This technique suggests a potential for optimizing diffusion models by decoupling different generation stages, which could lead to more efficient and faster generation of high-quality images.
More visual insights#
More on figures

This figure shows the cross-attention maps of a text-to-image diffusion model during the denoising process. (a) shows the cross-attention map averaged over denoising steps for each token in the prompt. The two generated images corresponding to the prompt are shown at the top, and the cross-attention weights for each token are visualized at the bottom, where white pixels indicate higher weights. (b) shows the convergence of the cross-attention map over denoising steps, measured by relative F1-score between the cross-attention map and the final generated image. This demonstrates that the overall shape of the generated image is determined in the early stages of denoising, while details are filled in later stages.
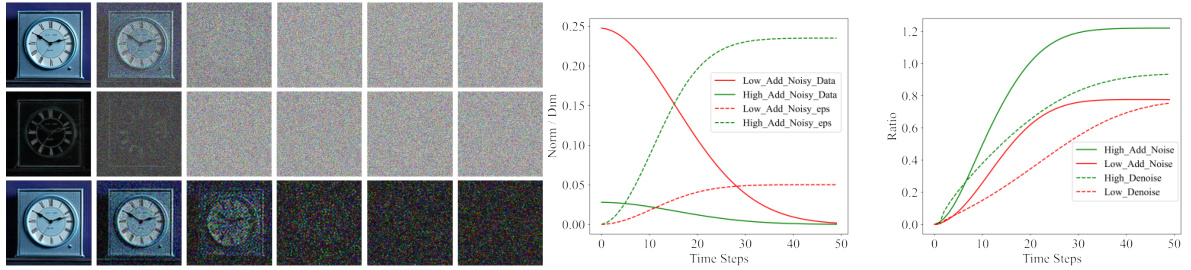
This figure shows an empirical analysis of the frequency components of noisy images during the denoising process. Subfigure (a) visualizes the separation of high and low-frequency components of noisy images at different time steps. Subfigures (b) and (c) quantify the changes in norms and ratios of these components, respectively, during both the forward (noise adding) and reverse (denoising) processes. This helps explain the two-stage process of image reconstruction: shape is recovered first (low frequency) and details later (high frequency).

This figure shows the average weights of cross-attention maps over pixels for three token classes ([SOS], semantic tokens, and [EOS]) across different denoising steps. The average is taken across all prompts in the PromptSet. It highlights that the weights for [SOS] tokens are consistently high (above 0.9), indicating their significant influence in the cross-attention mechanism, despite [SOS] not carrying semantic meaning itself.

This figure shows the results of an experiment where the [EOS] token in a set of prompts (S-PromptSet) was replaced with the [EOS] token from a different prompt. The generated images show that the object depicted primarily aligns with the object associated with the new [EOS] token, indicating its significant impact in the early stage of image generation. However, some information from the original prompt’s semantic tokens is still present in the generated images, demonstrating a nuanced interaction between [EOS] and semantic tokens.

This figure illustrates the denoising process of Stable Diffusion when the [EOS] token in a text prompt is switched at a specific time step (denoted as ‘a’). The top line shows the process visualized as a timeline progressing from noisy data at time step 0 to the final generated image at time step T. The blue section represents the process where the original prompt with its [EOS] token is used, and the brown section represents the process where the [EOS] token from a different prompt is used, illustrating the effect of switching the [EOS] during generation.

This figure shows the cross-attention maps and their convergence during the denoising process. (a) shows an example of cross-attention maps at different steps. Whiter pixels indicate stronger attention weights. (b) demonstrates the convergence of cross-attention maps to the final generated image shape over time, measured by relative F1-score.

This figure illustrates the process of denoising with text prompt injected only in the interval [0, a]. The denoising process starts from a noisy image at t=T and progresses towards a clean image at t=0. The text prompt, indicated by w = 7.5, influences the denoising process only up to time step ‘a’. After time step ‘a’, the text prompt is removed (w=0), and the denoising process continues without text guidance. This experiment is designed to investigate the effect of removing textual information during the denoising process.
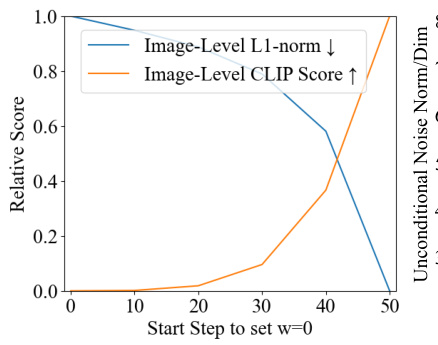
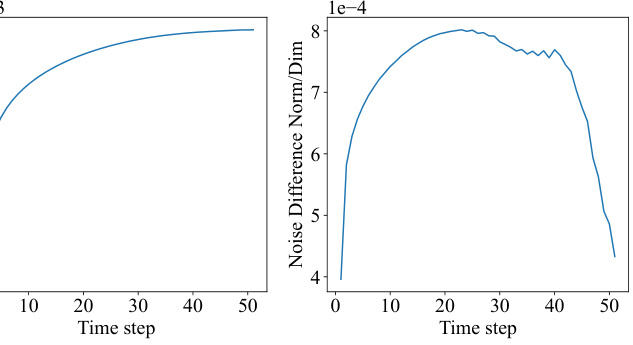
This figure shows the results of an experiment where the text prompt was removed at different stages of the denoising process. Figure 8a shows that removing the text prompt later in the process (larger start step) leads to a greater divergence from the original image (higher L1-norm). However, the generated image still maintains similarity to the original, as indicated by the CLIP score. Figure 8b visualizes the norm of the unconditional noise and the noise difference with and without the text prompt. This supports the claim that the text prompt primarily affects the early stages of the process, focusing on the overall shape.
This figure shows the analysis of low and high-frequency signal changes during the denoising process. Figure 2a visualizes the noisy data and its high and low-frequency components at different time steps. Figures 2b and 2c quantify these changes, showing the norms of low- and high-frequency components and their ratio over time. This helps explain the two-stage reconstruction process of overall shape before details.

The figure shows the denoising process with text prompt injected only in the interval [0,a]. In the interval [a, T], the text prompt is removed (w=0), whereas for the interval [0,a] it’s active (w=7.5). This experiment is designed to analyze the impact of removing text guidance at different stages of the denoising process on the final generated image. By varying the value of ‘a’, one can study the influence of text prompt at different stages.

This figure shows the results of image generation using different methods (SD v1.5, SD v2.1, Pixart-Alpha) and different values of ‘a’ (the point at which textual information is removed during the denoising process). As ‘a’ increases, less textual information is used, leading to a decrease in inference cost. The images demonstrate how the removal of textual information affects the generated images.
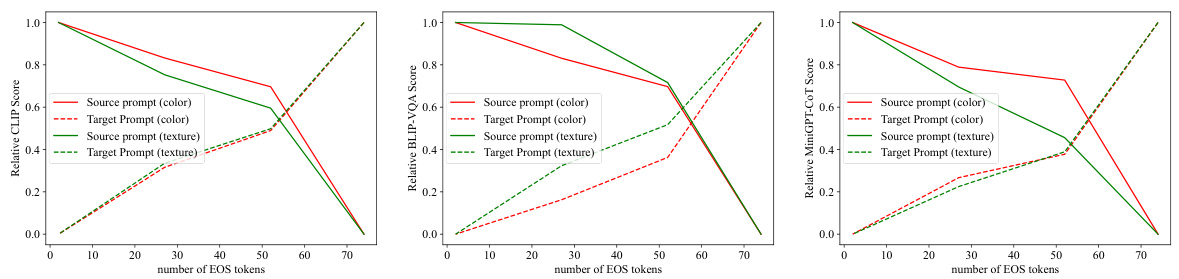
This figure shows the results of an ablation study on the number of [EOS] tokens in text prompts. The y-axis represents the relative scores (normalized to the maximum score) for BLIP-VQA, CLIPScore, and MiniGPT-CoT, measuring the alignment of generated images with source and target prompts. The x-axis indicates the varying number of [EOS] tokens. The results demonstrate the impact of the number of [EOS] tokens on the generation process and the alignment of generated images with prompts. As the number of [EOS] tokens decreases, the image alignment with source prompts increases, while alignment with target prompts decreases.

This figure visualizes the cross-attention maps for two prompts from the S-PromptSet dataset, where the [EOS] tokens have been switched. It shows that, at early stages of denoising, the cross-attention maps reflect the overall shape of the image. The pixels activated by the tokens that describe the object itself (e.g., ‘chair’) often match the overall shape, while those for the attribute tokens (e.g., ’leather’) may also match the image details. The figure demonstrates that information in [EOS] dominates the generated image shape.

This figure shows generated images using prompts that only contain [SOS] or [EOS] tokens. The purpose is to demonstrate that [SOS] tokens do not contain semantic information, unlike [EOS] tokens which do contain information that influences the generated image.

This figure visualizes the results of replacing semantic tokens or [EOS] with zero vectors or random Gaussian noise in text prompts. The goal was to investigate the impact of [EOS] and semantic tokens on image generation. Four sets of text prompts were used. The first row shows images generated from prompts where semantic tokens were kept but [EOS] was replaced. The second row shows images with semantic tokens replaced and [EOS] kept. The third and fourth rows show images where both were replaced with zeros and random noise, respectively. The results show that the combination of semantic tokens and [EOS] produced the best overall image quality.

This figure shows the results of substituting either the key or value of the [EOS] token in the cross-attention module during the stable diffusion process. The figure demonstrates how replacing either the key or value impacts the generation of images, specifically showing how the generated images align with either the source or target prompt. This helps illustrate the individual influence of the key and value components of the [EOS] token in shaping the generated image.
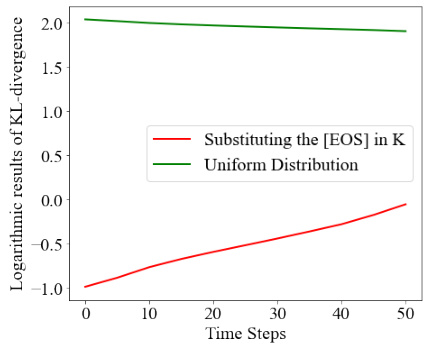
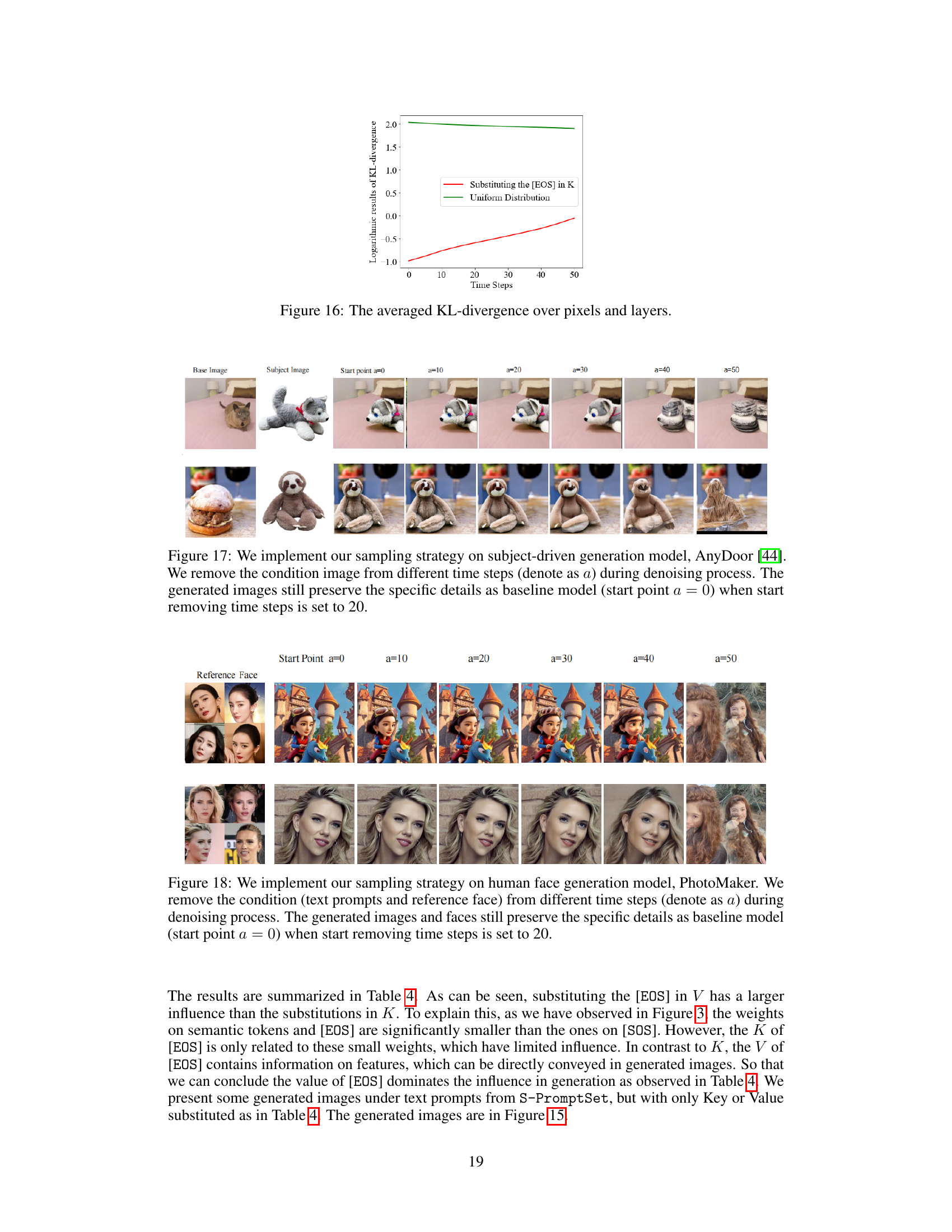
This figure shows the logarithmic results of KL-divergence over pixels and layers when substituting the [EOS] token in K (Key) with a uniform distribution. The x-axis represents the time steps in the denoising process, and the y-axis shows the logarithmic results of the KL-divergence. The red line represents the KL-divergence when substituting [EOS] in K, while the green line represents the KL-divergence of a uniform distribution. The figure demonstrates that the KL-divergence for substituting [EOS] in K is consistently lower than the KL-divergence of a uniform distribution throughout the denoising process.

This figure shows the results of applying the proposed sampling acceleration technique to the AnyDoor subject-driven generation model. The model generates images by conditioning on both a base image and a subject image. By removing the subject image’s influence at different stages (controlled by the parameter ‘a’) during the denoising process, the model can accelerate generation. The figure demonstrates that removing the subject image at later stages (larger ‘a’ values) still produces images that retain the desired details.

This figure shows the results of applying a sampling acceleration strategy to a human face generation model called PhotoMaker. The strategy involves removing the text prompt and reference face conditions at various points in the denoising process (parameterized by ‘a’). The figure demonstrates that even when removing the conditions relatively early in the process (a=20), the generated faces still retain a significant level of detail and accuracy compared to the baseline model (a=0).
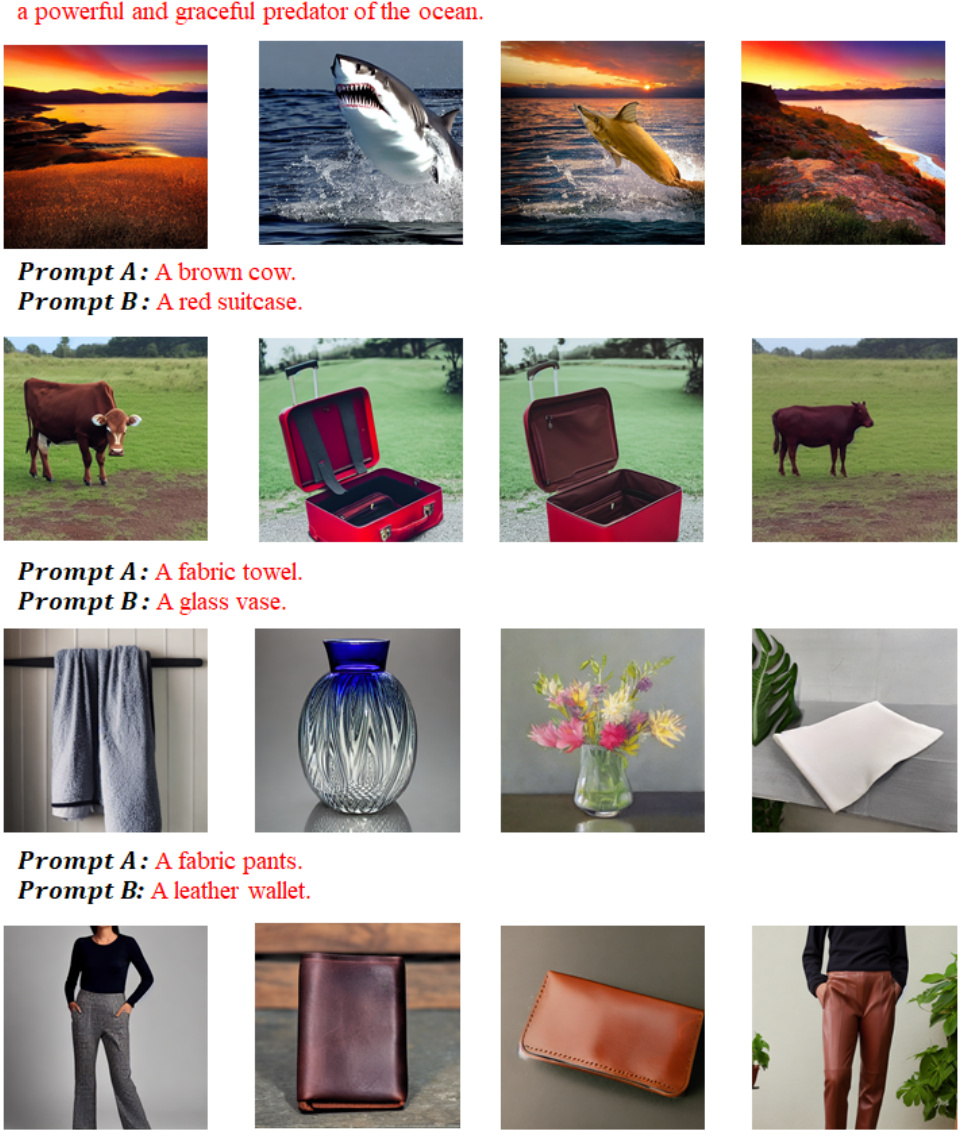
This figure shows more examples of images generated using the Switched-PromptSet (S-PromptSet) method, where the [EOS] token in prompts is replaced with that from another prompt. Each row shows the results from a pair of original prompts and the corresponding results with switched [EOS] tokens. The images demonstrate the influence of [EOS] tokens on the generation process, even when other tokens remain unchanged.

This figure shows the results of image generation using different sampling strategies. The textual information (C) is removed during a portion of the denoising process (t ∈ [0, a]), with ‘a’ varying from 0 to 50. The aim is to show how reducing the influence of the text prompt at later stages of the process can reduce computational cost while maintaining image quality. The results are shown for three different models (SD v1.5, SD v2.1, and Pixart-Alpha).

This figure shows the results of image generation using different models (SD v1.5, SD v2.1, and Pixart-Alpha) with varying start points (a) for removing textual information during the denoising process. The prompt used was ‘A plate with some vegetables and meat on it.’ As the value of ‘a’ increases, less textual information is used in the earlier stages of generation. The goal is to demonstrate that removing text guidance in the initial stages accelerates sampling by reducing computational cost while maintaining image quality. The images generated illustrate this trade-off.
More on tables

This table shows the results of text-image alignment using three metrics (CLIPScore, BLIP-VQA, MiniGPT4-CoT) for different text prompt variations. The original prompt is ‘Sem + EOS’, while other prompts replace semantic tokens ([Sem]) or the end-of-sentence token ([EOS]) with either zero vectors or random vectors. The table compares the alignment scores (higher scores indicate better alignment) of generated images with the corresponding text prompts to evaluate the relative importance of semantic tokens and the [EOS] token in the generation process.

This table presents the results of an experiment where the [EOS] token in text prompts was switched, and either the key (K) or value (V) in the cross-attention module was substituted. The alignment of generated images with both the source and target prompts was measured using three metrics: CLIPScore (Text), BLIP-VQA, and MiniGPT-CoT. The KV-Sub column represents a baseline where both K and V were substituted, providing a comparison point for the other substitution methods. The results show the impact of substituting either K or V individually on the generated images’ alignment with the source and target prompts.
Full paper#