↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Controlling both the structure and appearance of images generated from text prompts is a major challenge in AI. Current solutions often involve extensive model training or complex guidance procedures, which are time-consuming and computationally expensive. This limits their use in practical applications.
The researchers introduce Ctrl-X, a novel framework that tackles this challenge head-on. It enables guidance-free and training-free control of pre-trained text-to-image diffusion models. Ctrl-X achieves this by cleverly leveraging the inherent spatial and semantic information present in diffusion feature maps. Through a series of feature injection and normalization techniques, the framework efficiently steers the generation process, yielding high-quality images with precise structural and appearance alignment. The approach is remarkably fast, achieving a 35-fold speed improvement compared to guidance-based methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Ctrl-X, a novel approach to text-to-image generation that offers guidance-free and training-free control over both structure and appearance. This is significant because existing methods often require extensive training or time-consuming guidance procedures. Ctrl-X’s speed and flexibility make it a valuable tool for researchers and practitioners alike, opening avenues for more efficient and creative image generation. The approach is also highly relevant to the current trend toward making large language models more controllable and adaptable.
Visual Insights#

This figure showcases the capabilities of Ctrl-X, a novel method for controlling both structure and appearance in text-to-image generation. It presents several examples where a user provides a structure image (e.g., a sketch or segmentation map) and an appearance image (a photo with desired visual style). Ctrl-X then generates an image that incorporates the structure from the first image and the visual style of the second, all without requiring any further training or guidance (zero-shot). The results demonstrate that Ctrl-X can effectively separate structure and appearance control, enabling flexible and creative image generation.

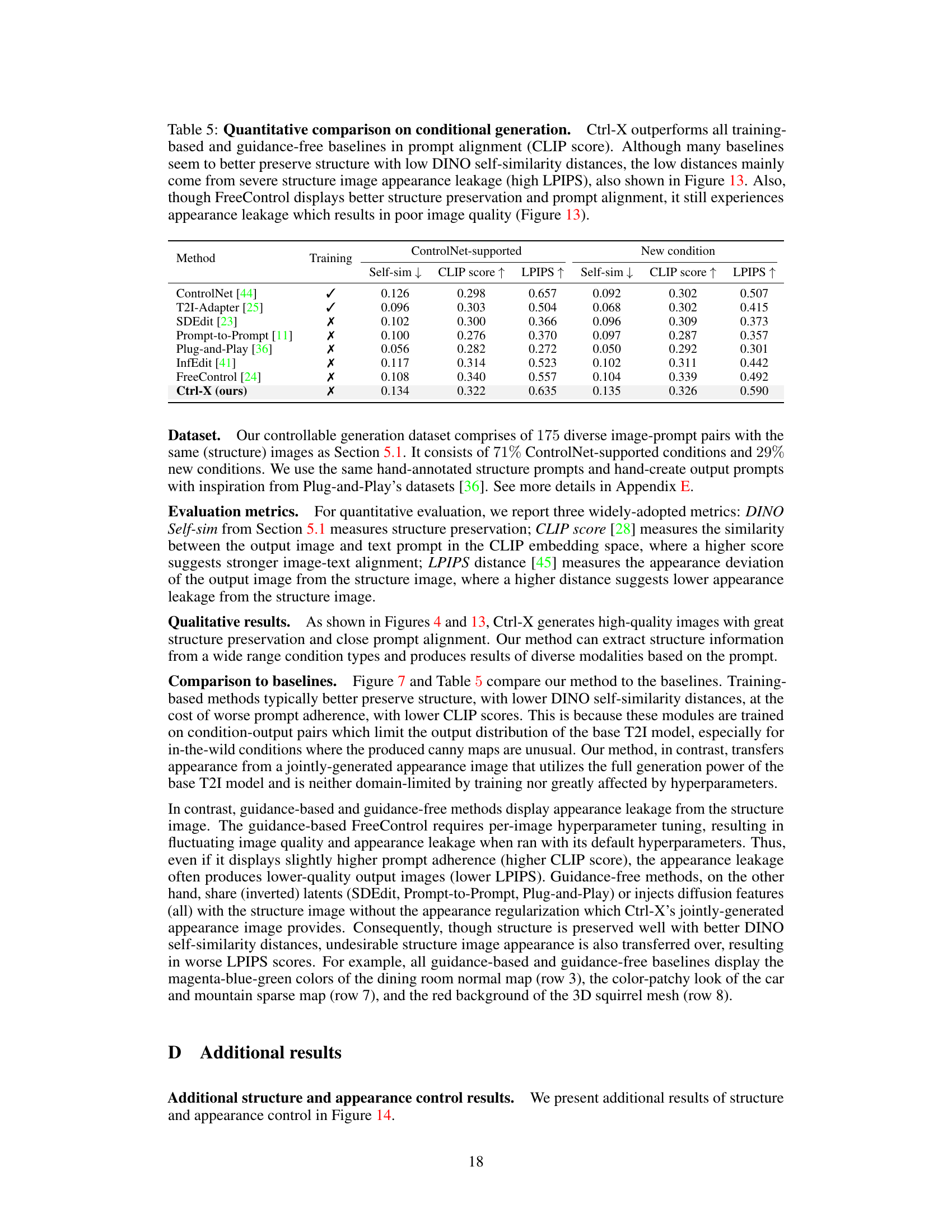
This table compares the inference efficiency of Ctrl-X against other methods. It shows that Ctrl-X, while slightly slower than some training-based methods, is significantly faster than other training-free and guidance-free methods. The table also highlights that Ctrl-X requires less GPU memory than many of its counterparts.
In-depth insights#
Guidance-Free Control#
Guidance-free control in text-to-image generation aims to bypass the need for explicit guidance signals during the image creation process. Traditional methods often rely on incorporating guidance information, which can be computationally expensive and limit flexibility. A guidance-free approach is highly desirable as it simplifies the generation process and accelerates inference, paving the way for real-time or near real-time applications. The core challenge lies in designing mechanisms that can effectively control structure and appearance without explicit guidance, potentially relying on latent feature manipulation or architectural innovations. Success in this area could greatly enhance the accessibility and usability of text-to-image models, expanding their applicability in creative fields and beyond. However, the absence of guidance necessitates alternative strategies for ensuring high-quality, semantically consistent image generation. Careful consideration of potential drawbacks such as the risk of reduced controllability or unintended artifacts is crucial.
Feature Injection#
Feature injection, in the context of controllable image generation models, involves strategically inserting features from a source image into the latent representations of a target image. This technique aims to transfer specific characteristics of the source (e.g., structure or appearance) to the target without the need for explicit guidance or additional training. The effectiveness hinges on the choice of features, injection location (e.g., convolutional or attention layers), and the method of integration (e.g., additive, multiplicative). Successful implementation depends heavily on the diffusion model’s architecture, understanding feature map semantics, and carefully managing the interaction between injected and existing features to avoid artifacts or unwanted alterations. Careful design is critical to maintain coherence and prevent overwriting important details. The key benefit is enabling training-free control, offering a faster and more flexible alternative to methods that rely on fine-tuning or additional modules. The choice of which features to inject, when, and where is a key element of the overall strategy, offering considerable design space for exploration and optimization. While potentially powerful, it is crucial to manage the risk of disrupting the generative process, leading to undesirable image quality or inconsistencies.
Appearance Transfer#
Appearance transfer, in the context of image generation, focuses on seamlessly integrating the visual style of one image onto another, while preserving the structural elements of the target image. This technique is particularly challenging due to the complex interplay between content and style. Successful appearance transfer requires robust algorithms that can disentangle these aspects and selectively apply style information without introducing artifacts or distortions. Methods often leverage feature representations from neural networks, extracting high-level style features from the source and transferring them to the target’s feature space through techniques like attention mechanisms or normalization layers. The effectiveness of appearance transfer is often evaluated based on perceptual similarity to the source style while maintaining the structural integrity and overall quality of the target image. Advancements in appearance transfer contribute significantly to the creation of realistic and controllable image generation models, enhancing creative editing tools and enabling novel applications in various fields.
Ablation Studies#
Ablation studies systematically remove or modify components of a model to assess their individual contributions. In the context of this research paper, ablation studies would likely explore the impact of removing or altering different parts of the Ctrl-X framework, providing crucial insights into its functionality. Removing the structure control module would test the contribution of structure image input to output image generation. Similarly, removing the appearance transfer module would isolate the role of the appearance image in shaping the output. By comparing the outputs of the full model to those with components removed, the authors could quantify the importance of each component, revealing which aspects of Ctrl-X are most crucial for achieving high-quality structure and appearance alignment. This would reveal essential architectural components and highlight potential areas for further optimization. Moreover, analyzing differences in quantitative metrics such as DINO-Self-sim (structure preservation) and DINO-I (appearance transfer) would numerically support claims about the effectiveness of each component. Finally, ablation studies would provide validation for the core claims made about the independence and efficacy of both components within Ctrl-X. By isolating the impact of individual modules and parameters, ablation studies allow for a more comprehensive and nuanced understanding of Ctrl-X’s design and effectiveness.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of Ctrl-X is crucial, particularly for high-resolution images and longer videos. This might involve optimizing the feature extraction and injection processes or exploring alternative network architectures. Investigating the generalizability of Ctrl-X to other generative models beyond diffusion models would also be valuable. Furthermore, research into novel condition modalities that go beyond images could unlock even more creative control. This could include 3D models, audio, or even sensor data. A deeper understanding of the interplay between structure and appearance within Ctrl-X’s framework is also needed. Developing more robust methods for handling complex or ambiguous input conditions is another important direction. Finally, the ethical implications of such powerful generative tools need careful consideration. This includes developing techniques to prevent misuse and exploring ways to ensure responsible use of Ctrl-X. Addressing these challenges would solidify Ctrl-X’s position as a leading tool for controllable image generation.
More visual insights#
More on figures
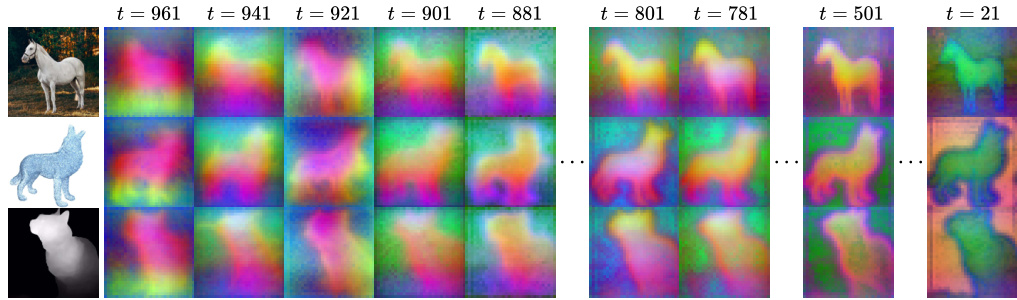
This figure visualizes early diffusion features from Stable Diffusion XL. It shows the top three principal components of features extracted after the decoder layer 0 convolution, using 20 real images, 20 generated images, and 20 condition images of animals. The visualization is done for different time steps (t) during the DDIM diffusion process, with t=961 to 881 representing inference steps 1 to 5. The purpose is to demonstrate how the features capture rich spatial structure and high-level appearance from early diffusion steps which are sufficient for structure and appearance control.
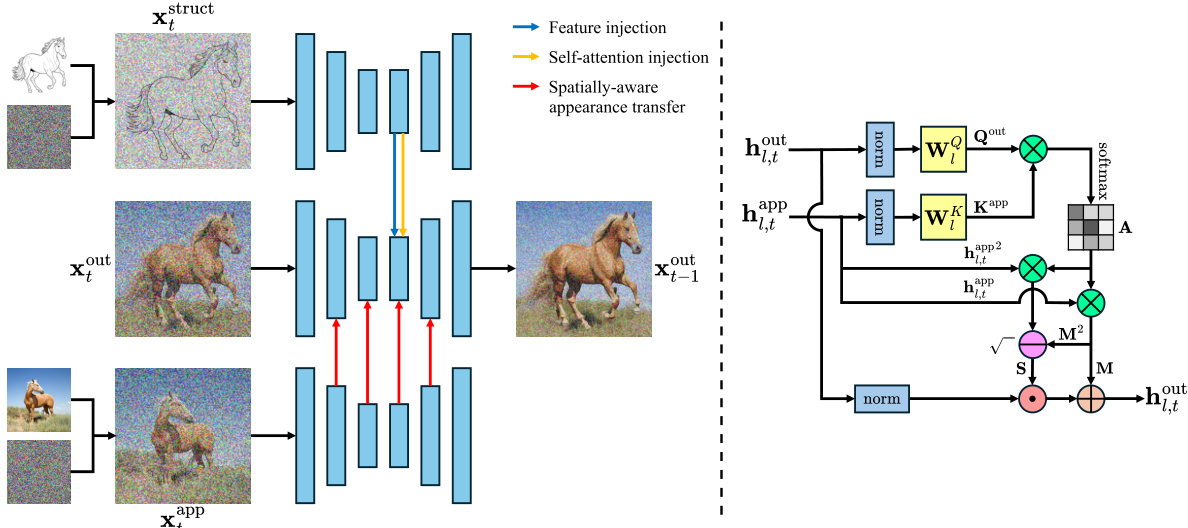
This figure provides a visual explanation of the Ctrl-X model’s pipeline. Panel (a) shows the overall process: noisy structure and appearance images are fed into a pretrained T2I diffusion model. Convolution and self-attention features are extracted and selectively injected into later stages of the process. Panel (b) zooms in on the spatially-aware appearance transfer module, detailing how the model uses self-attention maps to transfer appearance statistics from the appearance image to the output image. The arrows in (a) show feature injection, self-attention injection, and spatially aware appearance transfer.

This figure showcases the qualitative results of the Ctrl-X model on text-to-image generation tasks. It demonstrates the model’s ability to control both the structure and appearance of generated images based on user-provided structure and appearance images. The figure presents examples of diverse structures (photographs, paintings, sketches, etc.) and demonstrates how these structures are preserved and combined with different appearance styles in the generated outputs. The figure also shows that the model can handle prompt-driven conditional generation, further highlighting its flexibility and controllability.
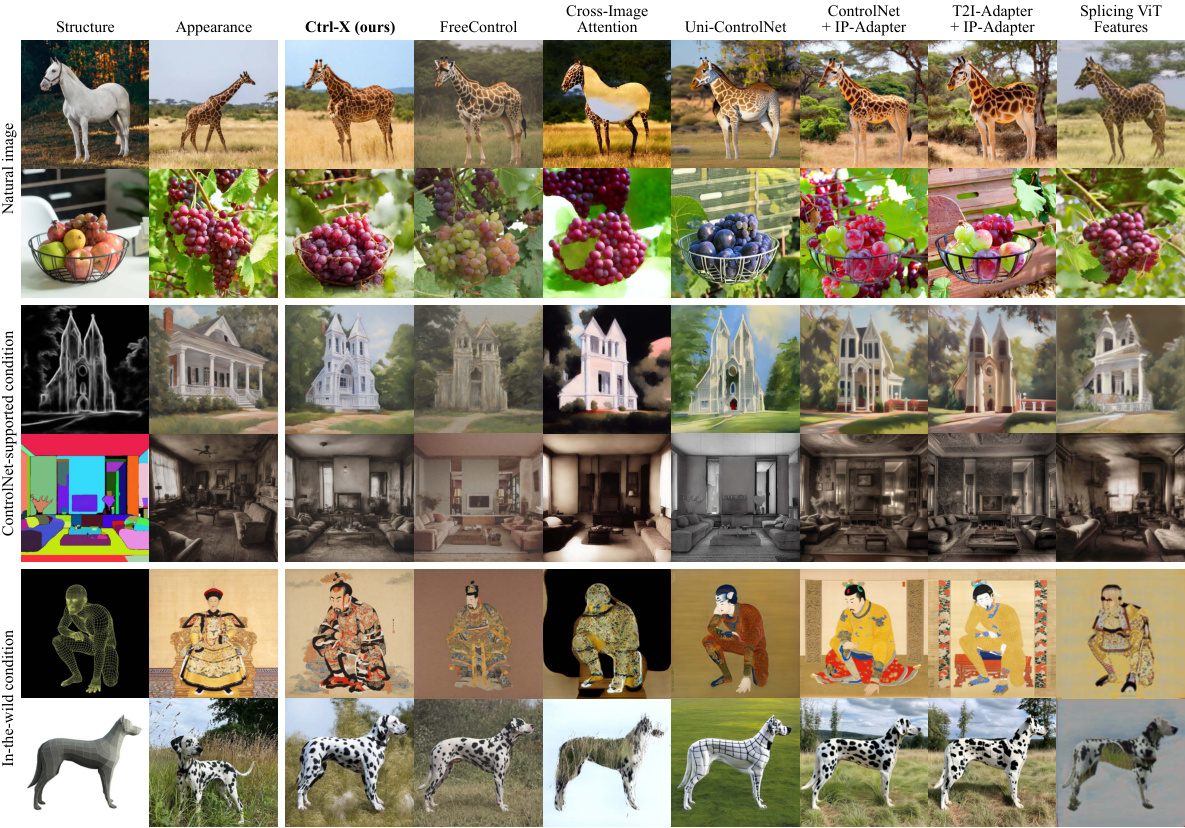
This figure compares the performance of Ctrl-X against several baseline methods for structure and appearance control in text-to-image generation. It showcases the results using diverse structure conditions, including natural images, ControlNet-supported conditions (e.g., canny edge maps, depth maps, segmentation masks), and in-the-wild conditions (e.g., 3D meshes, point clouds). The comparison highlights Ctrl-X’s ability to maintain comparable structure control while achieving superior appearance transfer compared to training-based methods. The figure also demonstrates that Ctrl-X shows more robustness than guidance-based and guidance-free methods across different structure types.

This figure shows a qualitative comparison of the proposed Ctrl-X method against several baselines for structure and appearance control in text-to-image generation. Different rows represent different types of structure conditions (e.g., natural images, ControlNet-supported conditions, and in-the-wild conditions). The columns compare the results of Ctrl-X against methods like ControlNet + IP-Adapter, T2I-Adapter + IP-Adapter, Uni-ControlNet + IP-Adapter, FreeControl, and Cross-Image Attention. The comparison highlights Ctrl-X’s ability to maintain comparable structure while achieving superior appearance transfer compared to other methods, demonstrating its robustness across diverse structure types.

This figure compares the results of conditional image generation using Ctrl-X and other methods. It shows that Ctrl-X achieves comparable results to training-based approaches while exhibiting improved image quality and robustness across diverse conditions compared to guidance-based and guidance-free alternatives. The comparison highlights Ctrl-X’s ability to maintain structural consistency while accurately reflecting the given text prompts.

This figure shows the ablation studies conducted by the authors to evaluate the impact of different components of their method. The three ablation studies are: (a) Ablation on control: comparing the results of no control, structure-only control, appearance-only control, and the full Ctrl-X method. (b) Ablation on appearance transfer method: comparing the results of using the proposed spatially-aware appearance transfer method with a method without attention weighting. (c) Ablation on inversion vs. our method: comparing the results of using inversion versus the proposed forward diffusion method. Each ablation study is shown for three different image generation examples.

This figure presents ablation studies to analyze the impact of different components of the Ctrl-X model. It shows comparisons between the full Ctrl-X model and versions with either the structure control, appearance transfer, or inversion components removed. This allows for a quantitative assessment of each component’s contribution to the overall performance of the model in terms of structure preservation and appearance transfer.

This figure showcases the capabilities of Ctrl-X, a novel method for controlling the structure and appearance of images generated by text-to-image diffusion models. The figure displays several examples of image generation, each demonstrating how Ctrl-X allows for independent control of both the image’s structure (using a provided structure image) and its appearance (using a provided appearance image). The results show that Ctrl-X can achieve this control without requiring any additional training of the model or the use of guidance during inference.

This figure demonstrates the qualitative results of the Ctrl-X model on text-to-image diffusion tasks. It showcases the model’s ability to control both the structure and appearance of generated images using various input types. Part (a) shows examples of structure and appearance control, where the model generates images that match a given structure image (e.g., a photo of a bear) while incorporating the appearance of a separate appearance image (e.g., an avocado). Part (b) demonstrates conditional generation based on a text prompt, where the model generates images aligning with a specified structure image. The figure highlights the versatility of Ctrl-X across different structure and appearance conditions, showing its effective combination of structure preservation and appearance transfer.

This figure shows the effect of changing the structure and appearance control schedules (τs and τa) on the generated images. Different combinations of τs and τa values resulted in different levels of structure preservation and appearance transfer. The default values (τs = 0.6 and τa = 0.6) produced good results for many image pairs but not all. The figure demonstrates that adjusting these schedules allows for a tradeoff between structure alignment and appearance transfer, enabling better results for challenging structure-appearance pairs and the use of higher-level conditions without clearly defined subject outlines.

This figure shows examples of guidance-free structure and appearance control using the Ctrl-X method on Stable Diffusion XL. The left side demonstrates structure control, where the generated images match the provided structure (layout) while maintaining the text prompt’s content. The right side shows appearance control, where the generated image adopts the style or appearance of a given reference image while adhering to the textual description. The results showcase the ability of Ctrl-X to control both structure and appearance of generated images without any additional training or guidance.

This figure shows a qualitative comparison of the conditional generation results from Ctrl-X and various baseline methods. It demonstrates that Ctrl-X achieves comparable or better performance across several metrics, including structure control and prompt alignment, compared to the training-based methods (ControlNet, T2I-Adapter) and guidance-based/guidance-free methods (FreeControl, SDEdit, Prompt-to-Prompt, Plug-and-Play, InfEdit). The improved image quality and robustness of Ctrl-X are also highlighted. Various conditions are tested, illustrating the versatility of the Ctrl-X approach.

This figure shows more examples of the results generated by the Ctrl-X model. The top row shows examples where the input structure is a normal map and the input appearance is a photo, painting, and artistic rendering of horses. The bottom row shows similar experiments but with the input structure being a hand-drawn sketch, a 3D model, and color blocks of a room, with the corresponding output images again showing photos, paintings, and artistic renderings of rooms.

This figure compares the appearance-only control results of Ctrl-X and IP-Adapter. It demonstrates that Ctrl-X, even without structure guidance, achieves better alignment of appearance from an input image to generated images than IP-Adapter. This is shown across various subject matters including giraffes, tigers, houses, and living rooms. The improved alignment suggests Ctrl-X’s strength in transferring appearance details accurately.

This figure demonstrates the capability of Ctrl-X in generating images with multiple subjects while maintaining semantic correspondence between the appearance and structure images. It showcases Ctrl-X’s ability to handle complex scenes with multiple subjects and backgrounds, successfully transferring appearance features across all elements. In contrast, a comparison with ControlNet + IP-Adapter highlights Ctrl-X’s superior performance, as the latter often struggles to transfer appearances consistently to all subjects within a scene.

This figure shows several examples of applying Ctrl-X to text-to-video (T2V) models for controllable video structure and appearance. The examples utilize AnimateDiff with Realistic Vision and LaVie models. It demonstrates Ctrl-X’s ability to transfer both structure and appearance to video generation. A video of the AnimateDiff results is available in a supplementary file.
More on tables
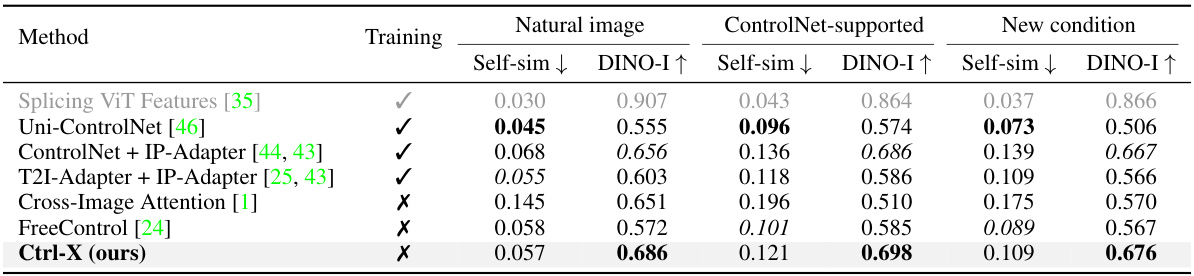
This table quantitatively compares the performance of Ctrl-X against several baseline methods for structure and appearance control in text-to-image generation. The comparison uses two metrics: DINO ViT self-similarity (lower scores indicate better structure preservation) and DINO-I (higher scores indicate better appearance transfer). The methods are categorized as training-based (requiring training on paired data) or training-free (no additional training needed). The table shows that Ctrl-X, despite being training-free, outperforms most other methods in terms of appearance transfer and achieves comparable results in structure preservation.

This table compares the capabilities of Ctrl-X with other state-of-the-art methods for controllable image generation. It shows whether each method supports structure and appearance control, whether it requires training, and whether it is guidance-free. The table also indicates which methods support natural images and ‘in-the-wild’ conditions as structure inputs. ‘In-the-wild’ conditions refer to less conventional input types beyond typical images, potentially including sketches or 3D models.

This table presents the results of a user study comparing Ctrl-X to several baseline methods for structure and appearance control in text-to-image generation. The study evaluated the methods based on four criteria: overall image quality, fidelity to the structure image, fidelity to the appearance image, and overall fidelity to both structure and appearance. The results show Ctrl-X outperforms training-free baselines and is competitive with training-based methods, particularly in terms of overall fidelity.
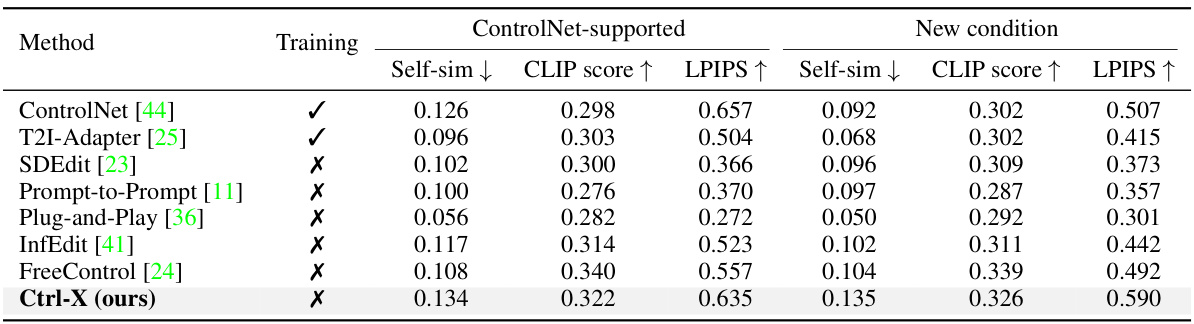
This table presents a quantitative comparison of different methods for controlling structure and appearance in text-to-image generation. It compares Ctrl-X against several baselines using two metrics: DINO Self-sim (measuring structure preservation) and DINO-I (measuring appearance transfer). The results show that Ctrl-X outperforms other methods in appearance alignment and achieves comparable or better structure preservation.
Full paper#