↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Single-image relighting is challenging due to complex interplay of geometry, materials, and lighting. Existing methods either focus on specific image categories or necessitate special capture conditions, hindering widespread application. Many also rely on explicit scene decomposition, often leading to inaccuracies. This limits the realism and generalizability of such techniques.
Neural Gaffer addresses these limitations using a novel end-to-end 2D relighting diffusion model. It leverages the inherent understanding of lighting present in a pre-trained diffusion model, fine-tuned on a synthetic relighting dataset. This approach avoids explicit scene decomposition, improving accuracy and generalization. The model excels at relighting various objects under diverse lighting conditions, both from real and synthetic data, facilitating various downstream 2D tasks and providing a robust relighting prior for 3D applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Neural Gaffer, a novel approach to single-image relighting that significantly improves accuracy and generalizability compared to existing methods. It leverages the power of diffusion models, achieving high-quality results on diverse datasets, opening new avenues for image editing and 3D scene manipulation.
Visual Insights#

This figure showcases the Neural Gaffer model’s ability to relight single images of various objects under different lighting conditions. It demonstrates the model’s ability to handle both image-based (environment map) and text-based (description of lighting) conditions, consistently producing high-quality relit images that maintain visual fidelity and react to lighting rotation. The supplementary materials contain additional video results.

This table presents a quantitative comparison of the proposed Neural Gaffer model against DiLightNet [79] for single-image relighting and against TensoIR [30] and NVDIFFREC-MC [25] for 3D relighting. The metrics used are PSNR, SSIM, and LPIPS. For single-image relighting, both raw and channel-aligned results are shown. Channel-aligned results adjust the average intensity of each channel to match the ground truth, addressing ambiguity between lighting intensity and object color. The 3D relighting results use only the channel-aligned metrics.
In-depth insights#
Diffusion-based Relighting#
Diffusion models have emerged as a powerful tool for image generation and manipulation. Applying diffusion models to the task of relighting offers a compelling alternative to traditional methods. Instead of relying on explicit scene decomposition into geometry, materials, and lighting, diffusion-based relighting leverages the inherent understanding of lighting implicitly learned by the model during its training on vast datasets. This approach allows for more robust and generalizable relighting, even from a single image and without specific knowledge of scene parameters. Fine-tuning a pre-trained diffusion model on a synthetic relighting dataset enables the model to learn nuanced relationships between lighting, objects, and their appearance. The ability of diffusion models to generate photorealistic results makes this approach particularly attractive for applications where high-quality image synthesis is crucial. Furthermore, the end-to-end nature of diffusion-based methods simplifies the relighting pipeline and eliminates the need for intermediate steps like explicit scene reconstruction or material estimation. While challenges remain, especially in handling complex materials and scenes with significant lighting variations, diffusion-based relighting represents a promising avenue for future research, with the potential to revolutionize image and video editing.
RelitObjaverse Dataset#
The heading ‘RelitObjaverse Dataset’ strongly suggests a synthetic dataset created for the research paper, likely focusing on image relighting. The name itself is a combination of ‘Relit’ (implying the data involves images under various lighting conditions), and ‘Objaverse’, a known large-scale 3D model dataset. This implies that the researchers used Objaverse’s 3D models to render a substantial number of images under diverse lighting situations, creating a ground truth for training and evaluating their relighting model. The use of a synthetic dataset is often preferred in image relighting research due to challenges in obtaining real-world images with accurate ground truth lighting information across many objects and conditions. High-quality HDR environment maps are likely included to provide realistic lighting variations. The careful construction of ‘RelitObjaverse’ likely involved filtering low-quality 3D models from the Objaverse, rendering with a physically-based renderer to get realistic visuals, and meticulous control over camera parameters and lighting variations. Therefore, the dataset likely represents a significant contribution, providing a valuable resource for future research in image relighting.
3D Relighting Prior#
The concept of a ‘3D Relighting Prior’ in the context of a research paper likely refers to a model or technique that leverages pre-existing knowledge about 3D scene illumination to enhance or improve the relighting of 3D objects. This prior knowledge might come from a variety of sources, such as a pre-trained neural radiance field (NeRF), a physically based rendering (PBR) model, or a large dataset of synthetically rendered scenes under various lighting conditions. The key idea is to avoid the computationally expensive task of fully reconstructing the 3D scene from a single image; instead, the prior informs the relighting process, making it faster and potentially more accurate. A strong 3D relighting prior would be crucial for handling complex effects like shadows, reflections, and subsurface scattering, aspects which are often challenging in single-image relighting approaches. The effectiveness of the prior will depend on its ability to generalize across different object types and lighting scenarios. Successful implementation would result in high-quality, realistic relit 3D models, offering significant advancements in areas like virtual object integration and photo editing. The approach likely integrates well with existing 3D modeling techniques and has implications for virtual and augmented reality applications.
Ablation Study Insights#
An ablation study systematically removes components of a model to isolate their individual contributions. In the context of a relighting model, this might involve removing different conditioning methods (e.g., removing HDR map conditioning or removing rotation alignment) or assessing various model architectures (e.g., comparing results with and without certain blocks). Key insights from such a study would highlight the importance of each component for accurate relighting. For instance, removing HDR information might lead to a loss of detail in highlights and shadows, while omitting rotation alignment could result in inconsistent lighting effects across different viewpoints. By quantifying the impact of each removed element, the study reveals which model features are crucial for high-quality relighting and which ones may be expendable. The results guide future model improvements and provide a deeper understanding of the model’s inner workings. Analyzing the results will also help determine the appropriate balance between model complexity and performance.
Limitations & Future#
A research paper’s “Limitations & Future” section would critically assess shortcomings. Data limitations might include the size, diversity, or representativeness of the training dataset, potentially impacting generalization. Methodological limitations could involve reliance on specific assumptions, approximations, or architectures that restrict applicability. The section should acknowledge computational constraints, such as training time or resource requirements, which might hinder scalability. Qualitative limitations could address subjective evaluations or the lack of extensive user studies. The “Future” aspect should propose extensions, improvements, and applications. This could involve exploring larger datasets, refining the methodology to address identified limitations, conducting more rigorous testing, and investigating novel applications for the developed technology. Ultimately, a robust “Limitations & Future” section builds credibility by acknowledging limitations while offering a roadmap for advancing the presented research.
More visual insights#
More on figures
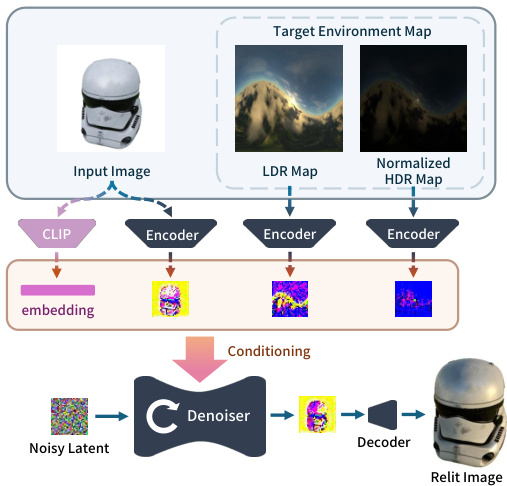
This figure illustrates the architecture of the Neural Gaffer model, a 2D image-based relighting diffusion model. It shows how the input image and lighting information are processed. The input image is encoded using a CLIP encoder to extract visual features. The target environment map is processed through two separate encoders, generating LDR (low dynamic range) and normalized HDR (high dynamic range) map representations. These encodings, along with the CLIP embedding of the input image, are concatenated and fed into the denoiser, a U-Net architecture which also processes noisy latent vectors. The denoiser then generates refined latent vectors that are decoded to produce the final relit image. The process is conditioned by the lighting information extracted from the environment map.

This figure illustrates a two-stage pipeline for relighting a 3D neural radiance field (NeRF). Stage 1 uses Neural Gaffer to generate relit images from multiple viewpoints, which are then used to refine the NeRF’s appearance via a reconstruction loss. Stage 2 further refines the appearance using a diffusion guidance loss, resulting in a high-quality, relit NeRF. The entire process is computationally efficient, taking only minutes to complete.

This figure compares the single-image relighting results of the proposed Neural Gaffer model against DiLightNet [79] under various lighting conditions. For several different objects, it shows the input image, the relighting results from DiLightNet, the relighting results from Neural Gaffer, the ground truth image, and the target lighting environment map. The comparison highlights Neural Gaffer’s superior performance in accurately reproducing highlights, shadows, and reflections while maintaining color consistency and detail.

This figure demonstrates the object insertion capability of the Neural Gaffer model. It shows examples where a foreground object (a vase and a BB-8 droid) is seamlessly integrated into a background scene with different lighting conditions. The results are compared to a simple copy-paste approach and the results from AnyDoor, highlighting Neural Gaffer’s superior ability to preserve object identity and generate more realistic lighting and shadows.

This figure compares the 3D relighting results of the proposed method against two baselines, namely NVDIFFREC-MC and TensoIR, across three different objects. The results show that the proposed method more accurately reproduces the lighting effects, unlike the baselines, which tend to miss or overemphasize certain aspects of lighting such as specular highlights and shadows, sometimes leading to artifacts. Videos showing more details are available on the project website.

This figure shows additional results of relighting 3D objects using the proposed Neural Gaffer model. It presents a comparison of the results obtained with Neural Gaffer against two baselines (NVDIFFREC-MC and TensoIR) and ground truth relighting. The figure demonstrates the superior qualitative performance of Neural Gaffer in accurately capturing specular highlights and shadows, which were more challenging for the baseline methods.

This figure shows the ablation study results for relighting 3D radiance fields using the proposed two-stage pipeline. It compares the results of the full model with several ablated versions: using only the SDS loss (Score Distillation Sampling) for refinement, omitting stage 1 or stage 2, and using only the first or the second stage. The results visually demonstrate the importance of both stages in achieving accurate and realistic highlights and reflections.

This figure shows several examples of single-image relighting results obtained using the Neural Gaffer model. The input images depict various objects (a helmet, a rubber duck, etc.) under various lighting conditions. The model then relights these images using image-conditioned (environment maps) or text-conditioned inputs (descriptions of lighting conditions). The results demonstrate that the model can successfully relight the objects while preserving their visual fidelity, even with significant changes in the lighting conditions. This highlights the model’s ability to handle diverse lighting scenarios and its robustness.

This figure compares the single-image relighting results of the proposed method against IC-Light [85], focusing on the consistency of specular highlights under different lighting conditions. The results show that the proposed method consistently adjusts highlights according to lighting rotation, while IC-Light shows inconsistent highlight movement.

This figure shows the results of single-image relighting on real data using the Neural Gaffer model. The model successfully changes the lighting conditions of various input images, using either an environment map or a text description as input. The results show high-quality relighting across diverse lighting scenarios, while maintaining the visual fidelity of the original objects. The lighting changes are consistent, even when the light source is rotated. Additional video results are available on the supplementary webpage.

This figure demonstrates the model’s ability to handle inherent color ambiguity in single-image relighting, particularly when dealing with specular materials. The model infers lighting information from reflections and highlights, allowing it to generate accurate relit images even when the input image has ambiguous coloring. Two examples are shown, each comparing the input image, the model’s prediction, and the ground truth.

This figure shows additional qualitative results comparing the relighting performance of the proposed Neural Gaffer method against two baseline methods, TensoIR and NVDIFFREC-MC, across various 3D objects. The results demonstrate Neural Gaffer’s superior ability to produce high-quality, visually realistic relighting results compared to existing techniques.
Full paper#



















