↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current LLM evaluation methods often lack sufficient discriminative power, failing to fully capture the nuances in model capabilities. Existing datasets may not adapt to the rapidly evolving capabilities of LLMs, rendering them less effective over time. Addressing this challenge requires creating evaluation sets that are both challenging and consistently updated to remain relevant to the state-of-the-art models.
The paper introduces IDGen, a novel framework that leverages Item Discrimination theory to generate prompts for LLM evaluation. This framework prioritizes both the breadth and specificity of prompts, ensuring comprehensive evaluation across various tasks and domains, leading to a more discriminative evaluation. The key contribution is a dataset of over 3,000 carefully crafted prompts and two models for predicting prompt discrimination and difficulty. Evaluation of five state-of-the-art LLMs on the generated dataset shows its superior ability to discriminate between different models compared to existing benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM evaluation because it introduces a novel framework for generating more effective and challenging evaluation datasets that adapt to the rapid advancements in LLM capabilities. The framework’s focus on item discrimination and difficulty, coupled with the release of a new dataset, will significantly improve the quality and comprehensiveness of future LLM evaluations. This is directly relevant to current trends in improving LLM performance and can pave the way for more rigorous benchmarks and unbiased comparisons of models.
Visual Insights#
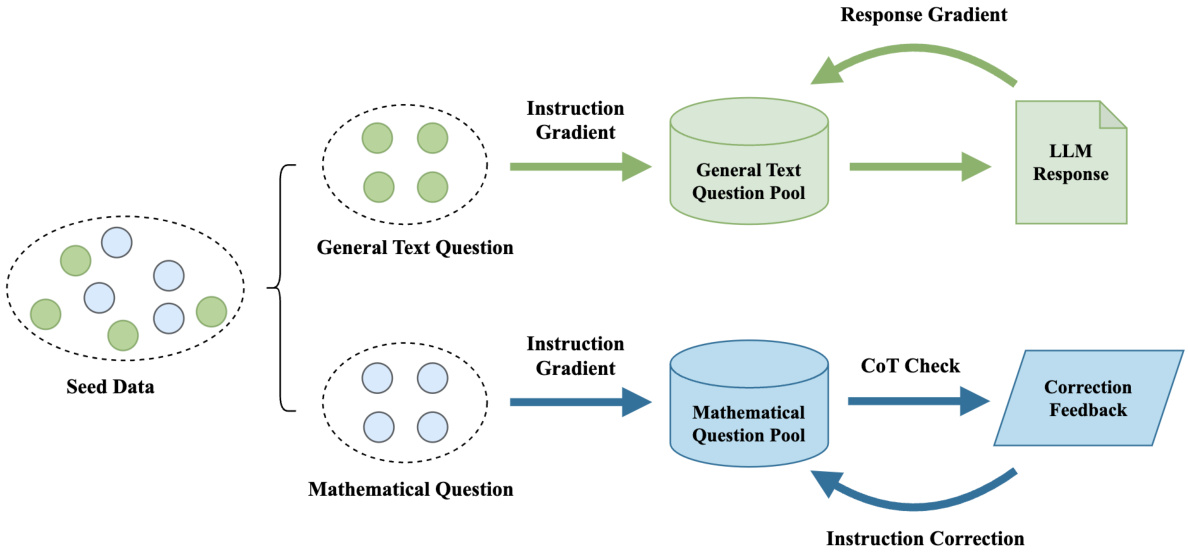
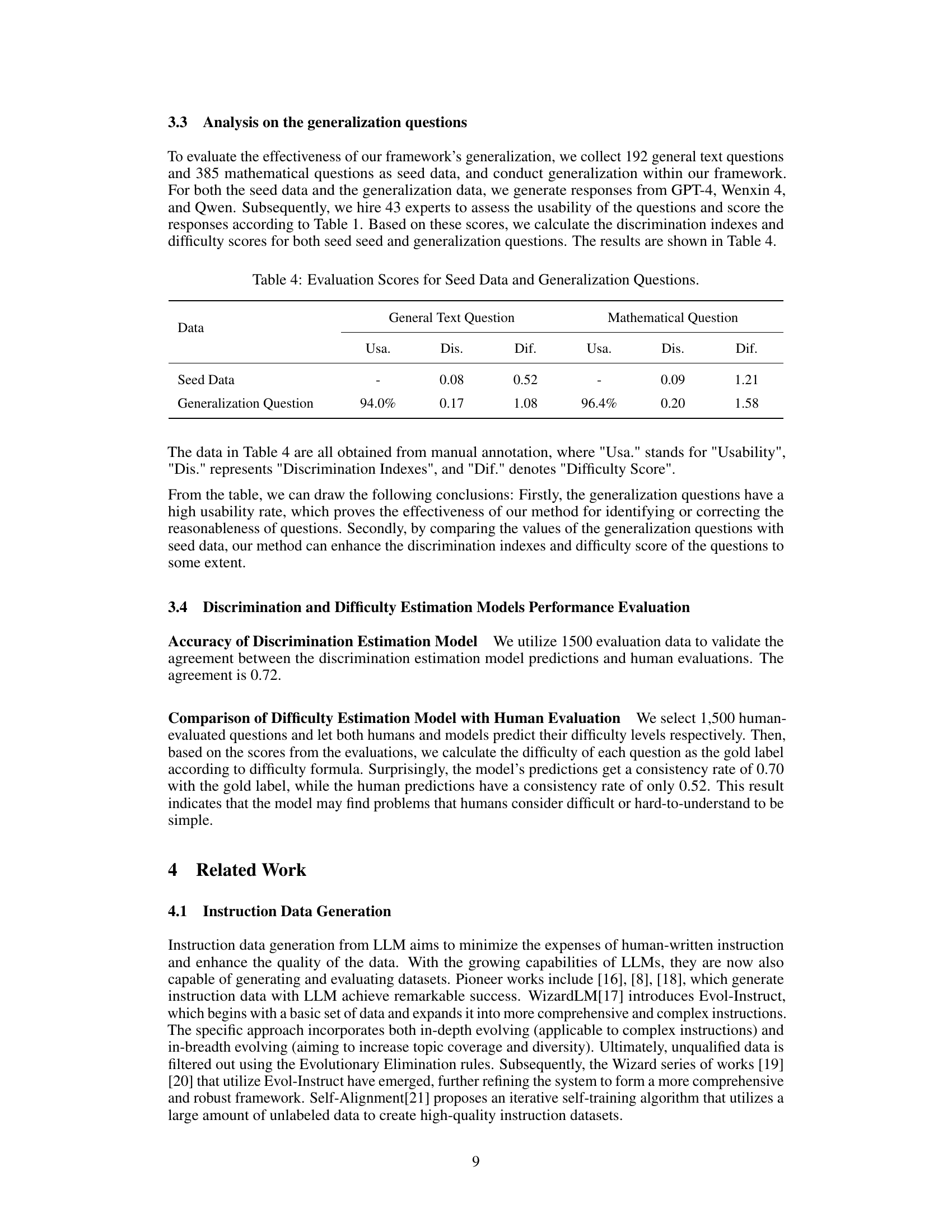
This figure illustrates the self-correct instruction generalization framework used in the paper. It starts with a handcrafted batch of seed data, divided into mathematical and general text categories. The framework then uses ‘Instruction Gradient’ (rules based on instruction perspective) and ‘Response Gradient’ (rules based on LLM responses) to generalize the questions. For general text, the process involves generating LLM responses and then creating new questions based on those responses. For mathematical questions, a Chain of Thought (CoT) check is used for correctness, and corrections are iteratively applied via a self-correct mechanism. The overall goal is to generate a high-quality dataset of questions for evaluating LLMs.

This table presents the scoring rubric used to evaluate the quality of the LLM’s answers. Each answer is assigned a score from 0 to 4, based on criteria such as relevance, accuracy, and completeness. A score of 0 indicates an irrelevant or harmful response, while a score of 4 indicates an answer that exceeds expectations.
In-depth insights#
ID-Induced Prompt Synthesis#
The concept of ‘ID-Induced Prompt Synthesis’ presents a novel approach to LLM evaluation. By leveraging Item Discrimination (ID) theory from educational assessment, this framework aims to dynamically generate prompts that effectively differentiate between LLMs of varying capabilities. This contrasts with static evaluation sets, which become less discriminative as models improve. The core idea is to synthesize prompts that expose performance differences, revealing the strengths and weaknesses across diverse tasks and domains. A crucial aspect is the incorporation of self-correction mechanisms and predictive models (for discrimination and difficulty) to ensure high-quality data generation. The framework prioritizes both the breadth of skills tested and the specificity in revealing subtle performance variations, ultimately leading to a more comprehensive and insightful evaluation process. This method promises to continuously adapt to the advancements in LLMs, fostering robust and more challenging benchmarks for future development.
Discriminative Data Generation#
Discriminative data generation focuses on creating datasets that effectively differentiate between models of varying capabilities. This contrasts with traditional methods that may not sufficiently highlight performance distinctions. The core idea is to generate data points that are challenging yet informative, pushing the boundaries of current model abilities. This approach requires careful consideration of data characteristics, including difficulty and breadth of coverage. By using metrics such as discrimination power and difficulty, a more refined evaluation process is established, leading to a more reliable assessment of model performance. Furthermore, iterative processes incorporating self-correction mechanisms and expert feedback ensure high quality and reduce the risk of generating flawed or unusable data points. The ultimate goal is to create a dynamic evaluation benchmark that continually evolves to reflect the advancements in model capabilities, enabling more robust and meaningful model comparisons.
LLM Evaluation Metrics#
Large language model (LLM) evaluation is a complex field lacking universally accepted metrics. Current approaches often rely on multiple-choice question benchmarks, which are limited in scope and fail to capture the full generative capabilities of LLMs. More holistic methods are needed, incorporating metrics that evaluate reasoning, common sense, and factual accuracy. Furthermore, prompt engineering heavily influences performance, making direct comparisons between models challenging. Bias detection is another crucial area where evaluation must improve, ensuring fairness and mitigating discriminatory outputs. Human evaluation, while subjective, remains vital for assessing nuanced aspects of LLM behavior, particularly in tasks requiring creativity or contextual understanding. The development of standardized and comprehensive evaluation frameworks, incorporating both automated and human-based metrics, is critical for advancing LLM research and deployment.
Generalization Framework#
The proposed generalization framework is a crucial component of the research, aiming to create high-quality and discriminative evaluation datasets for LLMs. It leverages principles from Item Discrimination (ID) Theory, focusing on the ability of individual prompts to differentiate between strong and weak LLMs. The framework’s core strength lies in its iterative and self-correcting nature, incorporating mechanisms to enhance data quality and ensure logical consistency. By using both instruction gradient and response gradient techniques, it generates diverse and challenging prompts across multiple domains. The integration of discriminative power and difficulty metrics further refines the dataset, providing a nuanced evaluation tool. While the dependence on high-performing LLMs and manual annotation presents limitations, the framework offers a robust methodology for generating dynamic, challenging evaluation data that adapts to the ongoing progress in LLM development.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Expanding the dataset with more diverse tasks and languages is crucial for broader LLM evaluation. Investigating alternative data generation methods beyond the ID-induced approach, perhaps leveraging reinforcement learning or other advanced techniques, could enhance data quality and discriminative power. Furthermore, developing more sophisticated metrics for evaluating various aspects of LLM performance beyond simple accuracy scores is needed. This could involve exploring metrics that capture reasoning, creativity, and common sense. Applying this framework to other LLMs and analyzing the differences in their performance will provide valuable insights into their strengths and weaknesses. Finally, research on mitigating the potential biases and limitations inherent in both the data generation process and the LLM models themselves is essential for building robust and fair evaluation benchmarks.
More visual insights#
More on figures
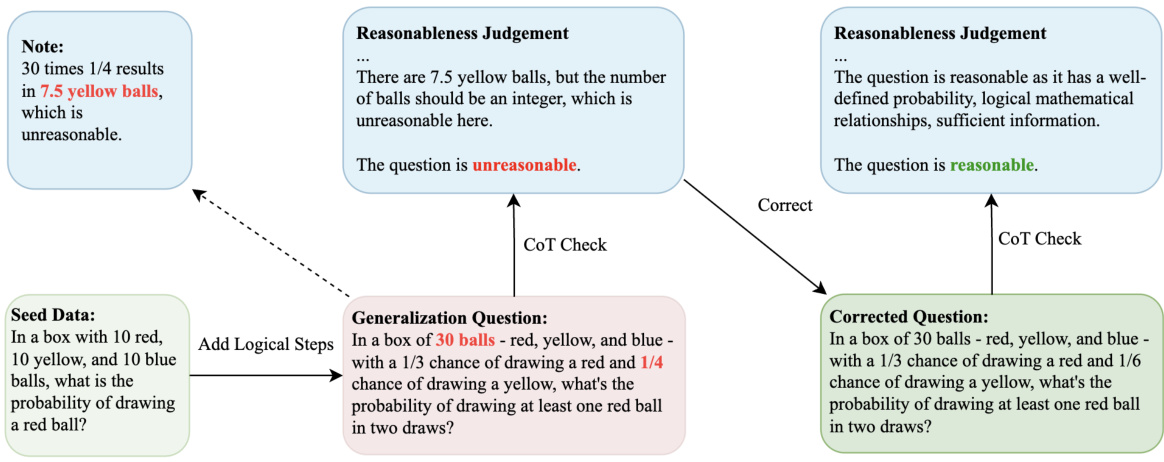
This figure illustrates the self-correct instruction generalization framework used in the paper. It starts with a small set of hand-crafted seed data, which is then generalized using two methods: instruction gradient and response gradient. The instruction gradient method generalizes questions based on pre-defined rules derived from the instruction, while the response gradient method generalizes questions based on the model’s responses. A self-correction mechanism is used to rectify the generated questions, ensuring high quality and usability. This framework is designed to generate questions automatically to test and differentiate Large Language Models (LLMs).
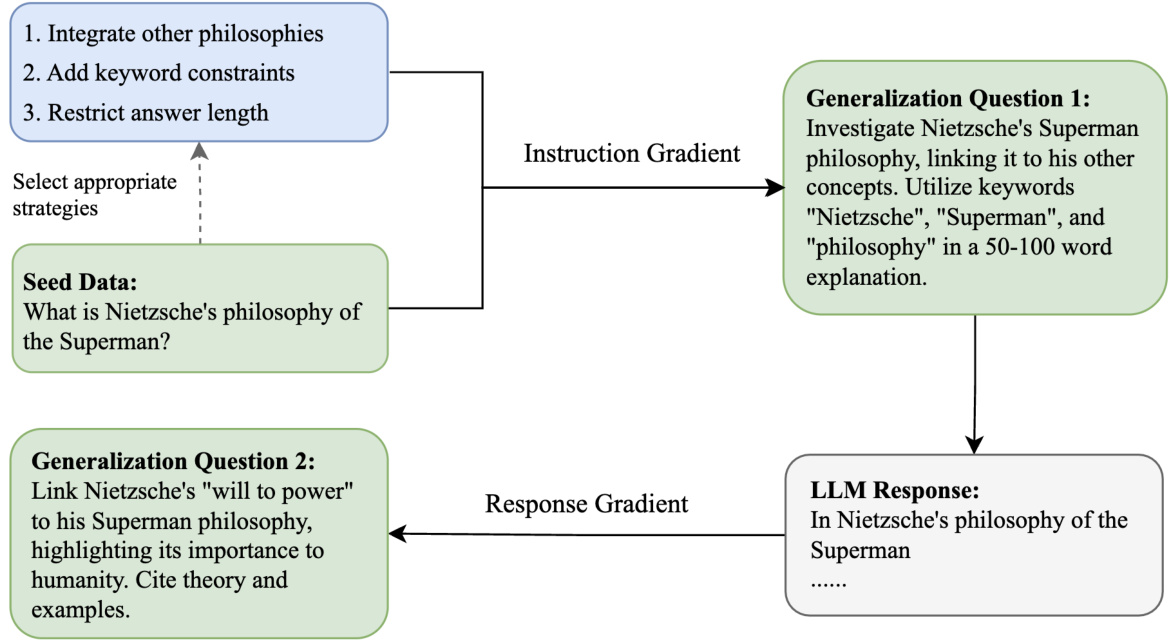
This figure illustrates the self-correct instruction generalization framework. It starts with handcrafted seed data (divided into math and general text categories). The ‘Instruction Gradient’ uses rules to generalize questions from the instruction perspective. Then, the ‘Response Gradient’ method generalizes questions based on LLM responses. A CoT (Chain of Thought) check mechanism ensures the quality of the mathematical questions through iterative feedback and correction. The framework uses two gradient methods to generate a larger dataset from a smaller initial dataset.
More on tables
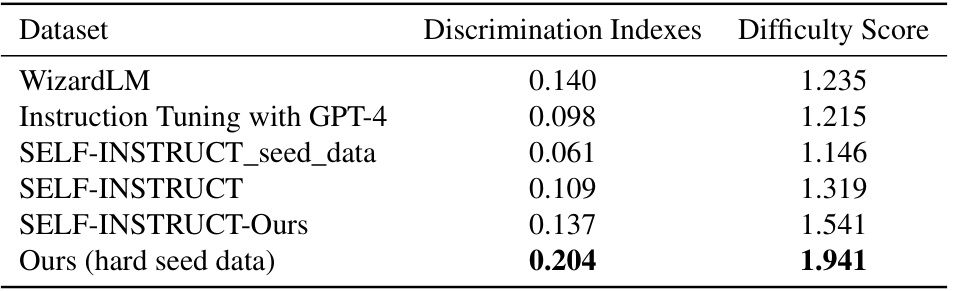
This table compares the discrimination indexes and difficulty scores of six different datasets used for evaluating Large Language Models (LLMs). The datasets include: WizardLM, Instruction Tuning with GPT-4, SELF-INSTRUCT_seed_data, SELF-INSTRUCT, SELF-INSTRUCT-Ours (a dataset created by applying the authors’ proposed method to the SELF-INSTRUCT seed data), and Ours (hard seed data), which represents the authors’ dataset generated from more challenging seed data. Higher discrimination indexes indicate better ability to differentiate between LLMs with varying capabilities, while higher difficulty scores suggest the dataset poses more challenging questions for the LLMs. The results highlight that the authors’ method, particularly when applied to more challenging seed data, produces a dataset with superior discrimination and difficulty compared to existing benchmark datasets.

This table presents the evaluation scores for various large language models (LLMs) across different datasets. The scores represent the average performance of each LLM on each dataset, offering a comparison of their relative strengths and weaknesses. The ‘Var.’ column shows the variance of the scores for each model across datasets, indicating the consistency of the LLM’s performance. The datasets used include WizardLM, Instruction Tuning with GPT-4, SELF-INSTRUCT_seed_data, SELF-INSTRUCT, SELF-INSTRUCT-Ours, and Ours (hard seed data), representing various methods for generating and curating evaluation datasets. The table provides valuable insights into the discriminative power of the different datasets and the relative performance of LLMs.
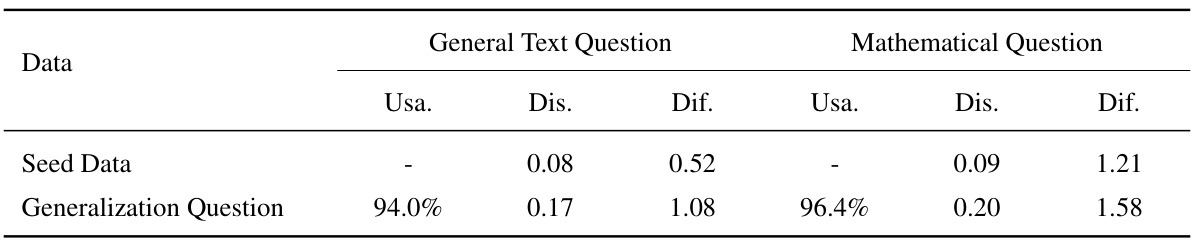
This table presents a comparison of the usability, discrimination index, and difficulty scores for seed data and generalization questions. The usability score reflects the percentage of usable questions. Discrimination index and difficulty score are metrics used to evaluate the quality of the generated questions, representing how well the questions differentiate between high and low-performing LLMs and how challenging they are, respectively.

This table compares the discrimination indexes and difficulty scores of several publicly available datasets used for evaluating large language models (LLMs). The datasets include WizardLM, Instruction Tuning with GPT-4, SELF-INSTRUCT (seed data and full dataset), SELF-INSTRUCT-Ours (dataset generated by the authors’ method using SELF-INSTRUCT seed data), and Ours (hard seed data - a dataset generated by the authors using more challenging seed data). The discrimination index reflects the ability of the dataset to distinguish between high and low-performing LLMs, while the difficulty score indicates the overall difficulty of the questions. The table shows that the datasets generated by the authors’ method, especially using more challenging seed data, achieve higher discrimination indexes and difficulty scores compared to other public datasets, indicating that the proposed method produces more effective evaluation data.

This table compares the discrimination index and difficulty score of six different datasets, including three baseline datasets (WizardLM, Instruction Tuning with GPT-4, and SELF-INSTRUCT) and three datasets generated using the proposed method in the paper (SELF-INSTRUCT_seed_data, SELF-INSTRUCT-Ours, and Ours (hard seed data)). The discrimination index measures the ability of a dataset to differentiate between high and low performers, while the difficulty score measures the overall difficulty of the dataset. The results show that the datasets generated using the proposed method achieve significantly higher discrimination indexes and difficulty scores, indicating that these datasets are more effective at evaluating the performance of large language models.

This table compares the discrimination indexes and difficulty scores of several public datasets used for evaluating large language models (LLMs). The datasets include SELF-INSTRUCT, WizardLM, Instruction Tuning with GPT-4, and the authors’ own datasets (both with standard and hard seed data). The discrimination index measures how well a dataset can differentiate between high-performing and low-performing LLMs, while the difficulty score represents the overall difficulty of the questions in the dataset. The table shows that the authors’ dataset, particularly the one using ‘hard seed data,’ achieves higher discrimination and difficulty scores than most of the other public datasets.
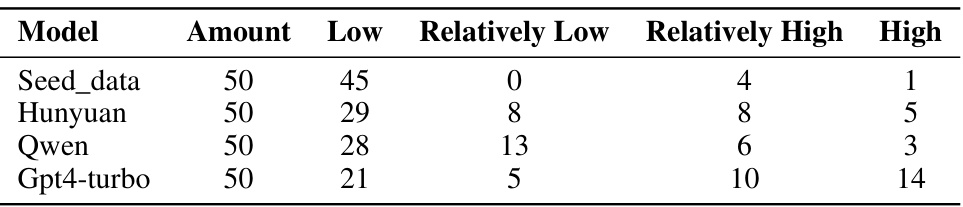
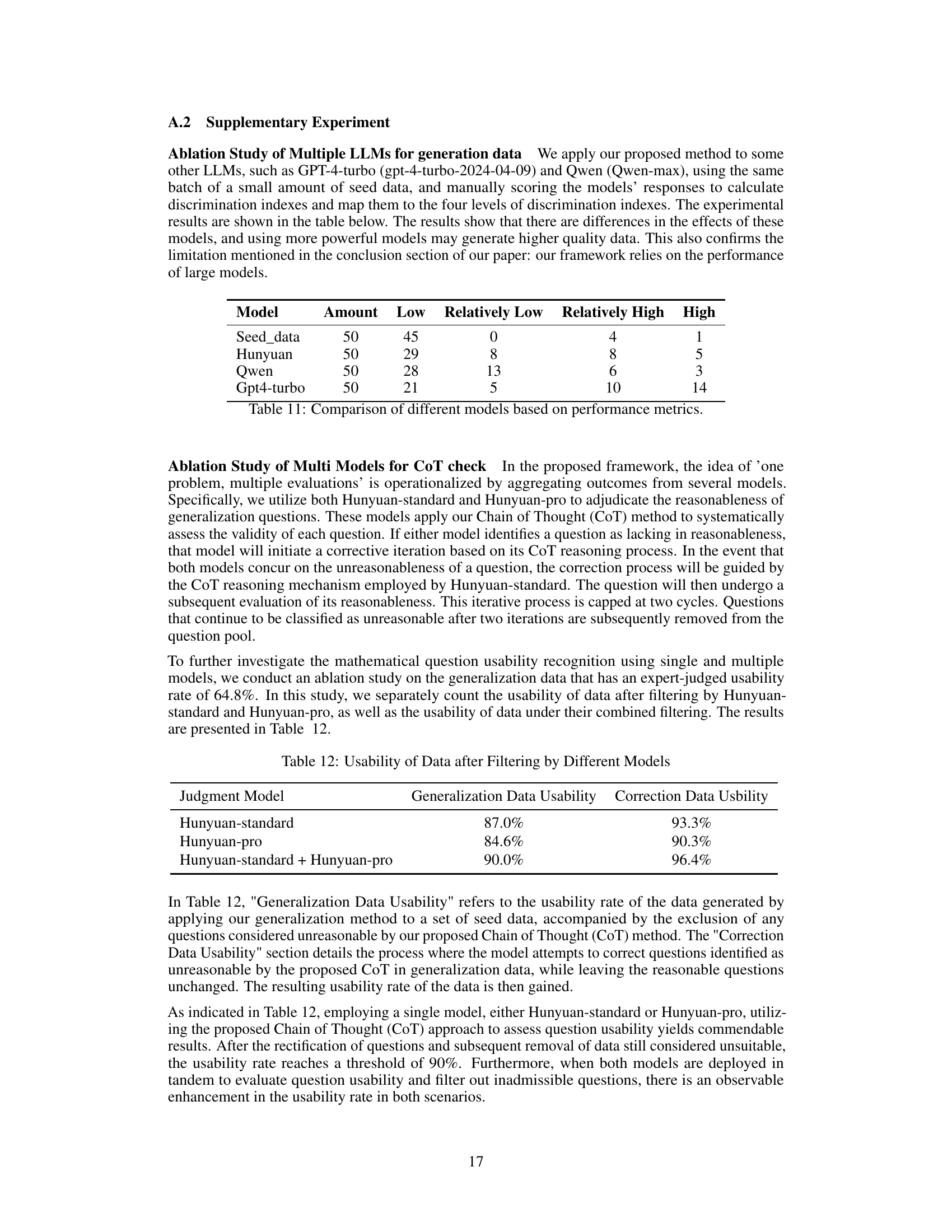
This table presents the results of an ablation study comparing the performance of four different large language models (LLMs) in generating high-quality data for evaluating LLMs. The models are evaluated based on the discrimination power of the generated questions, which are categorized into four levels: Low, Relatively Low, Relatively High, and High. The table shows the number of questions generated by each model that fall into each category, revealing the relative strengths and weaknesses of the different models in generating discriminative questions.

This table compares the usability of a dataset before and after it was filtered using different models. The dataset was produced using a method described in the paper that includes a chain of thought (CoT) based approach to assess the usability of questions. The first column indicates which model was used to evaluate the usability, and the second column presents the usability after filtering. The third column shows the usability after a second filtering pass intended to correct previously deemed unusable questions. The combined use of both models yielded the highest usability scores.
Full paper#