↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current video generation methods heavily rely on training-based approaches for motion customization. These approaches are resource-intensive, lack interpretability, and require retraining for diverse models. This paper tackles these issues by exploring how video diffusion models encode motion information.
The paper introduces a novel training-free method which uses a new MOtion FeaTure (MOFT) to understand, localize, and manipulate motion in video diffusion models. MOFT is extracted without training and is shown to be generalizable across diverse architectures. The researchers demonstrate the method’s effectiveness in various video motion control tasks, showcasing its potential to significantly advance the field of video generation.
Key Takeaways#
Why does it matter?#
This paper is highly important because it presents a training-free method for controlling video motion using video diffusion models. This addresses the significant limitation of existing methods, which require extensive training data and retraining for different models. The generalizability and interpretability of the proposed approach provide new avenues for research in various downstream tasks and offer valuable insights into the inner workings of video diffusion models.
Visual Insights#

This figure demonstrates the characteristics of the Motion Feature (MOFT). The first row shows how MOFT captures rich motion information. Part (a) indicates the point where MOFT is extracted from a reference video, and (b) shows a similarity heatmap of the MOFT across different videos, illustrating the alignment between MOFT similarity and motion flow. The second row (c) shows how MOFT guides motion control by directing motion in a specific region, as shown by the red arrows.
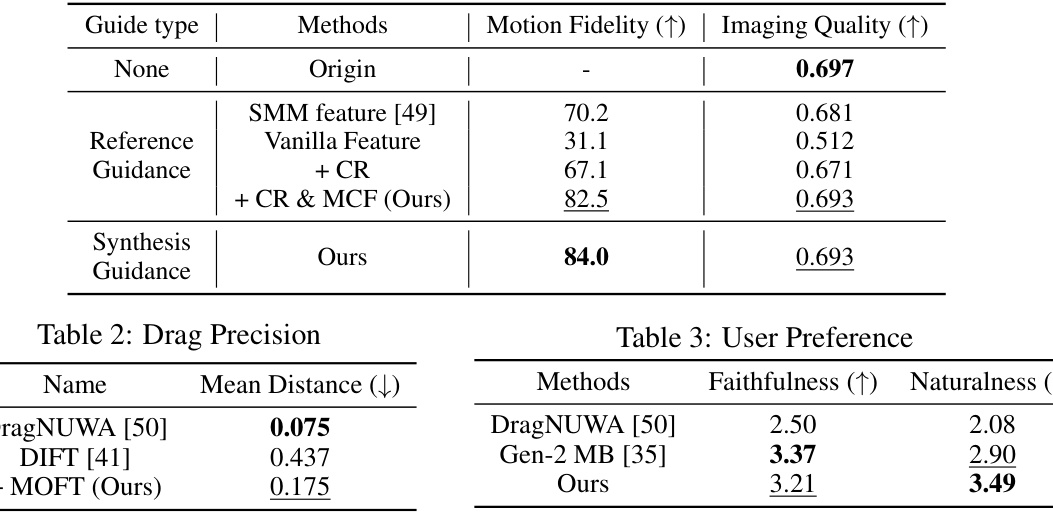
This table presents the results of experiments comparing different motion feature designs. It shows the motion fidelity and image quality achieved using various methods, including the baseline (Origin), a method using content removal, one that combines content removal and motion channel filtering (CR & MCF, which is the authors’ proposed approach), and the authors’ proposed approach applied with synthesis guidance. The results demonstrate the effectiveness of the authors’ proposed method in improving motion fidelity and image quality.
In-depth insights#
Training-Free Motion#
The concept of “Training-Free Motion” in the context of video generation signifies a paradigm shift away from traditional, data-hungry training methods. Instead of requiring extensive training datasets and retraining for variations in models, this approach focuses on extracting and manipulating motion information directly from pre-trained video diffusion models. This is achieved by identifying and isolating motion-aware features within the model’s latent space, eliminating the need for additional training. This offers significant advantages: faster processing, reduced computational costs, and enhanced architecture agnosticism. The method leverages techniques like Principal Component Analysis (PCA) and content correlation removal to isolate and emphasize the motion information, achieving control over video motion in a training-free manner. Interpretability is another key benefit; unlike black-box methods, this approach allows researchers to understand how motion is encoded in the model, providing deeper insights into the inner workings of video diffusion models. The focus on extracting meaningful motion features highlights a crucial advancement for training-free video editing and manipulation. Generalizability across diverse model architectures is also a significant strength, making this a promising approach for widespread adoption in video generation.
MOFT Feature Analysis#
A hypothetical ‘MOFT Feature Analysis’ section would delve into the properties and capabilities of Motion Feature (MOFT). It would likely begin by validating MOFT’s ability to effectively capture motion information, possibly through comparisons with existing motion representation techniques like optical flow. The analysis would then explore MOFT’s interpretability, demonstrating how its features clearly represent motion direction and magnitude, contrasting this with the often opaque representations of other feature extraction methods. Key aspects of MOFT’s architecture-agnostic nature would be analyzed to show consistent performance across various video generation models. Finally, the section would likely discuss limitations of the MOFT approach, perhaps addressing issues with complex motions or scenarios where content and motion information are highly intertwined, offering avenues for future research to enhance MOFT’s robustness and broaden its applications.
Motion Control Pipeline#
The proposed ‘Motion Control Pipeline’ presents a novel training-free approach to video motion control. It leverages Motion Features (MOFT), which are extracted from intermediate features of a video diffusion model. This extraction process intelligently removes content correlation and filters motion channels, resulting in a representation that is both interpretable and architecture-agnostic. The pipeline then uses the extracted MOFT as guidance, optimizing noisy latents to alter the sampling process of the diffusion model. This optimization is achieved using a loss function that compares masked and reference MOFTs, enabling precise motion control. This training-free design is a significant advantage, eliminating the need for retraining on various model architectures. The pipeline’s flexibility allows for different reference MOFT generation methods, using either extracted features from videos or synthesized based on statistical models. Combining MOFT with other methods like DIFT allows for finer-grained control, demonstrating the framework’s versatile capabilities and potential for diverse downstream video editing applications.
Qualitative Experiments#
A Qualitative Experiments section in a research paper would delve into a nuanced exploration of results beyond mere quantitative metrics. It would likely present illustrative examples, perhaps showcasing the model’s outputs on diverse and challenging inputs. Visualizations such as images or videos would be crucial, demonstrating the model’s capabilities and limitations in a readily understandable way. The discussion might analyze the model’s performance on edge cases, highlighting instances of success and failure. Qualitative analysis could examine the realism, diversity, and coherence of generated outputs. A strong section would connect the qualitative observations with the quantitative findings, providing a more comprehensive understanding of the model’s overall behavior and implications for future research. Finally, anecdotal evidence from user studies or expert reviews could strengthen the analysis by providing a human perspective on the results. In short, a well-executed Qualitative Experiments section should effectively showcase the model’s strengths and weaknesses, offering a balanced and insightful evaluation.
Future Research#
Future research directions stemming from this training-free motion control framework using Motion Features (MOFT) could explore several avenues. Extending MOFT’s applicability to real-world videos is crucial, necessitating advancements in video inversion techniques to mitigate content alterations during the process. Improving precision in controlling motion scale would enhance the framework’s capabilities, potentially through refined loss function designs or the incorporation of additional guidance signals. Investigating the framework’s performance across diverse video generation models beyond those tested is important to validate its architecture-agnostic nature. Finally, exploring the integration of MOFT with other video editing techniques like inpainting and object manipulation could yield more sophisticated and versatile video editing tools. Addressing these areas would significantly expand the practical applications and impact of this innovative training-free approach.
More visual insights#
More on figures

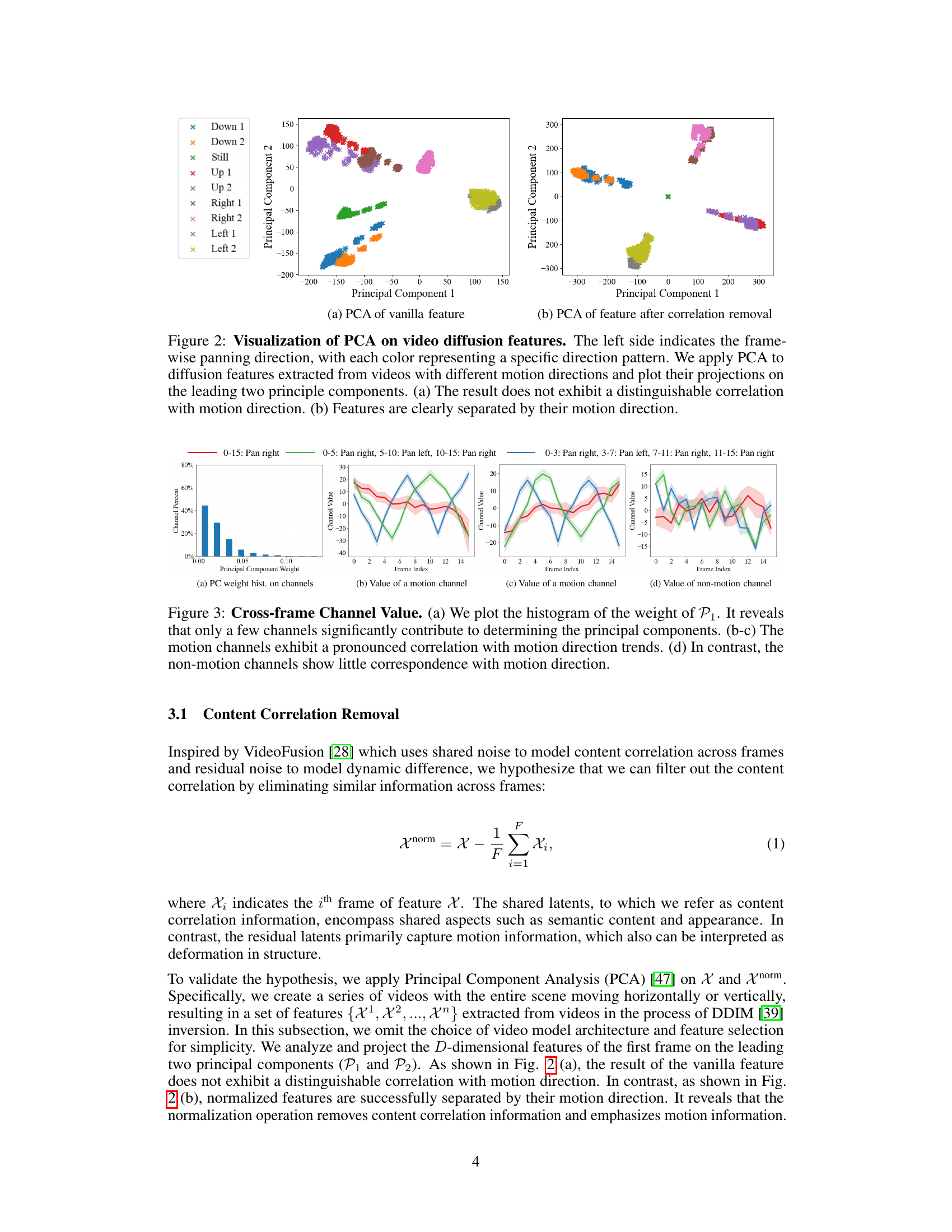
This figure visualizes the results of Principal Component Analysis (PCA) applied to video diffusion features. It shows how the removal of content correlation from the features makes the motion direction more clearly distinguishable in the PCA analysis. The left subplot (a) shows PCA on vanilla features where motion direction isn’t clearly separated. In contrast, the right subplot (b) shows the improved separability of motion directions after the content correlation is removed.
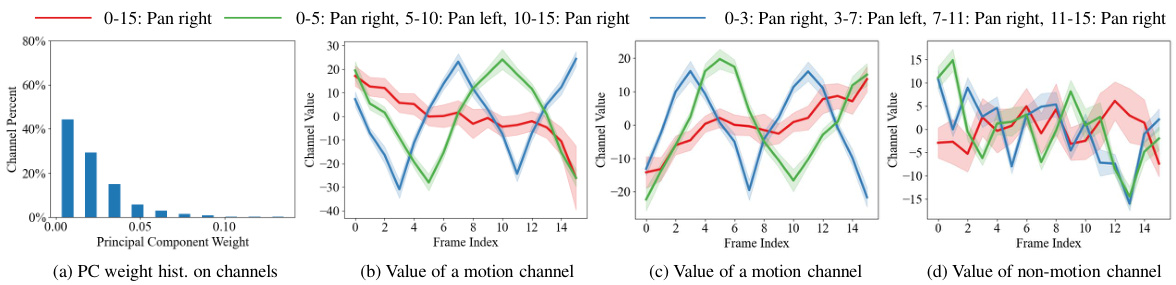
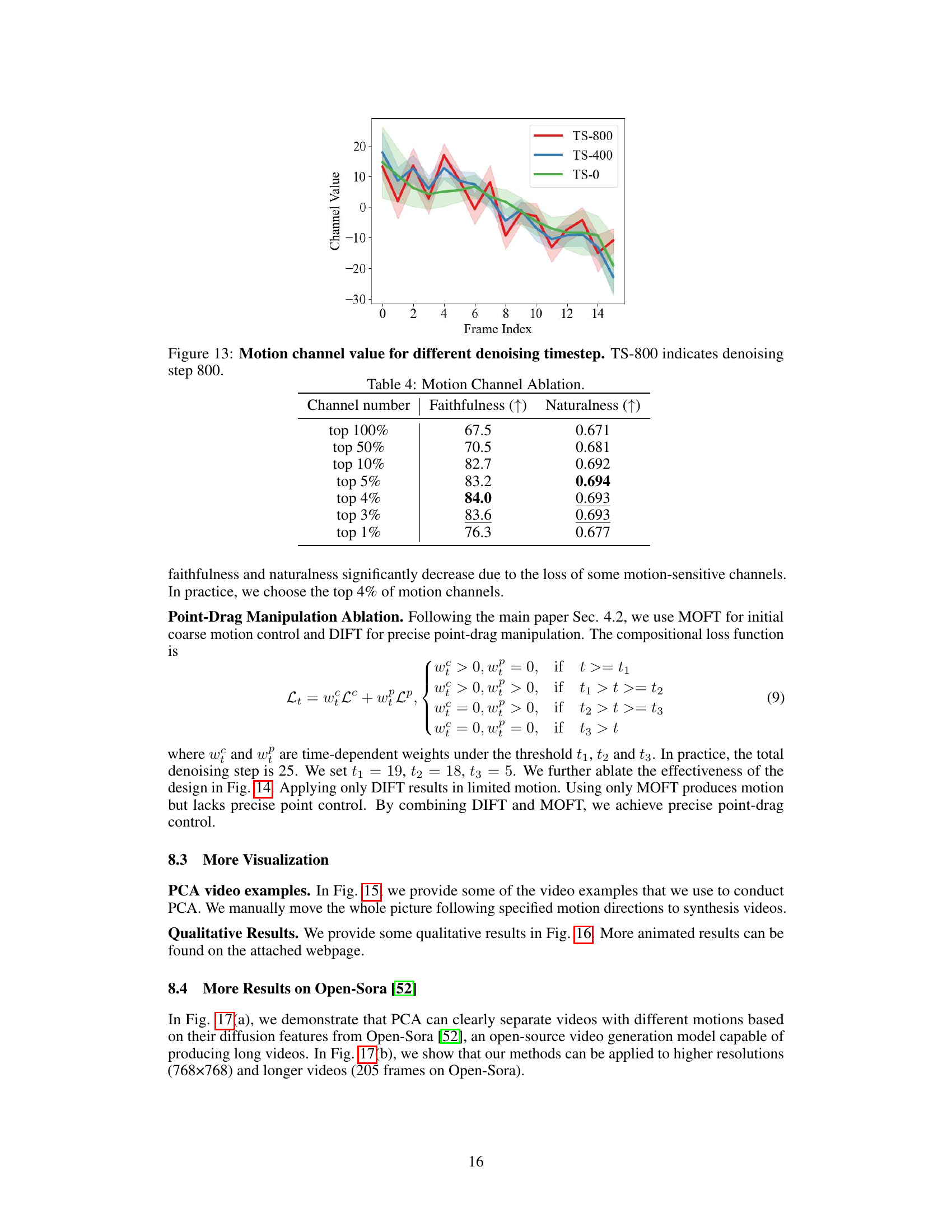
The figure visualizes the relationship between principal components derived from video diffusion features and motion information. Panel (a) shows that only a subset of channels heavily influence the principal components, suggesting the existence of motion-aware features. Panels (b) and (c) demonstrate a strong correlation between the values of these key channels and the direction of motion in the video. Panel (d) shows that other channels show little to no such correlation.

This figure visualizes the similarity heatmaps of Motion Feature (MOFT) across various videos and models. It demonstrates MOFT’s ability to capture rich motion information and its generalizability across different architectures and layers within a U-Net. The heatmaps compare the MOFT extracted from a reference video point to corresponding features in different target videos and model outputs. Different processing steps (content removal, motion channel filtering) and different layers/models are compared for their effectiveness.

This figure illustrates the training-free video motion control pipeline. The pipeline takes noisy latents as input and uses a U-Net to generate features. Content correlation removal and a motion channel filter are then applied to extract the Motion Feature (MOFT). A region mask is used to select a specific region of interest, and the masked MOFT is compared to a reference MOFT to generate a loss, which is used to optimize the latents and control the video generation process.

This figure visualizes the similarity heatmaps between the motion features (MOFT) extracted from a reference video and various target videos. The heatmaps illustrate the ability of MOFT to capture motion information across diverse video generation models and different layers within a single model’s architecture. The impact of content removal and motion channel filtering on the performance of MOFT is also shown.

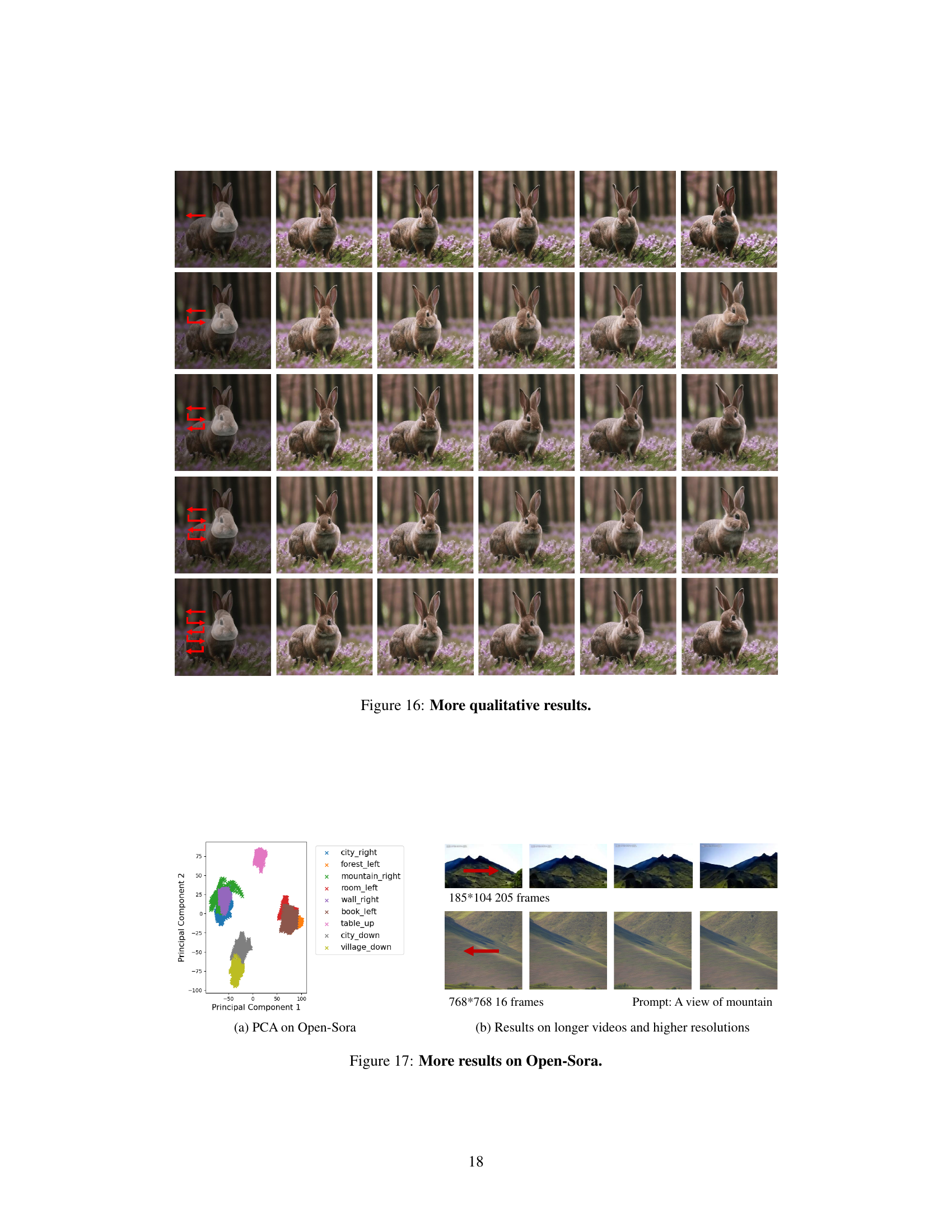
This figure shows several examples of video animation using the proposed method. The top row displays a comparison between a reference video (with no motion control) and a video with motion control applied using reference video signals. The bottom row does the same, but instead uses synthesized motion control signals (i.e. not copied from another video). The red boxes highlight the area of focus in the original video.

This figure demonstrates the effectiveness of the proposed Motion Feature (MOFT) in capturing motion information across various video generation models. It compares the similarity heatmaps of MOFT (with and without content removal and motion channel filtering) at different layers of the U-Net architecture and across several different models (AnimateDiff, ModelScope, ZeroScope, SVD). The results indicate that MOFT consistently achieves high similarity with videos containing similar motions, highlighting its architecture-agnostic nature and ability to effectively capture motion features.

This figure demonstrates the characteristics of the Motion Feature (MOFT) proposed in the paper. It shows that MOFT effectively captures rich motion information, as evidenced by the similarity heatmaps across different videos that align with motion flow. Furthermore, the figure illustrates how MOFT can serve as guidance for motion control by specifying the direction of motion in a masked region of an image.

This figure demonstrates the qualitative results of the proposed motion control method. It shows several video clips where motion is controlled using different reference or synthesized signals. The top row shows examples with camera motion control, while the bottom shows object motion control. The ‘reference’ videos are marked with red boxes, and the authors suggest viewing supplementary materials for a better understanding of the results.

This figure illustrates the pipeline for video motion control. The pipeline uses reference MOFT (Motion Feature) as guidance to optimize the latents and alter the sampling process during denoising. It involves extracting MOFT from intermediate features using content correlation removal and a motion channel filter. The optimization process uses a loss function based on the masked MOFT and the reference MOFT. This training-free method allows controlling video motion by optimizing noisy latents.

This figure compares video generation results with different methods to preserve video consistency. It shows the original video, results using only motion guidance, results using motion guidance plus shared K&V (key and value from spatial attention), and results using motion guidance, shared K&V and gradient clipping. Gradient clipping helps preserve consistency outside the control region but can reduce the scale of the motion.
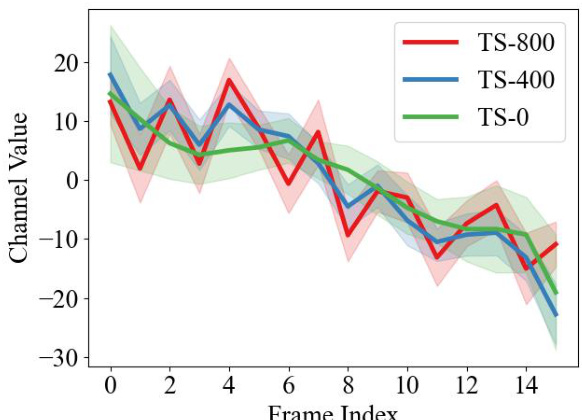
This figure demonstrates the characteristics of the proposed Motion Feature (MOFT). (a) shows a reference video with a red point indicating the location where MOFT is extracted. (b) displays similarity heatmaps comparing the extracted MOFT across different videos, showcasing that similar motion patterns yield high similarity scores (yellow). (c) illustrates how MOFT is used as guidance to control motion direction, with the direction shown using red arrows in a light-masked region.

This figure demonstrates the characteristics of the proposed Motion Feature (MOFT). The first row shows that MOFT successfully captures rich motion information. The heatmap in (b) highlights the regions with similar motion patterns compared to the reference video (a). The second row shows how MOFT can be used as guidance for controlling motion in videos. The red arrows indicate the direction of the controlled motion.

This figure shows several examples of video animations generated using the proposed training-free video motion control framework. Each row demonstrates the application of the method with different control signals (reference or synthesized) and motion types (camera, object). The red boxes highlight the original reference videos for comparison. The results showcase the ability to manipulate motion in a natural and faithful way while retaining high video quality. Due to the complexity of the visuals, readers are encouraged to consult the supplementary material for a clearer understanding.

This figure shows several examples of video animations generated using different motion control methods. The top row shows the reference videos with their respective control signals represented by red boxes. The bottom row shows video results where both camera motion and object motion were controlled using synthesized signals. The results demonstrate the capability of the proposed training-free motion control framework to generate natural and authentic motion in various scenarios. More results are available in the supplementary material.

This figure visualizes the similarity heatmaps of Motion Feature (MOFT) across various videos and models. It demonstrates the effectiveness of the MOFT in capturing motion information, showing how content removal and motion channel filtering improve the alignment with reference motion. The heatmaps are shown for different model layers and various video generation models, highlighting the architecture-agnostic nature of MOFT.
Full paper#