↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many robotic manipulation tasks require following complex, long-horizon instructions. Current approaches often struggle with ambiguity and implicit sub-tasks. Humans excel at such tasks by visualizing subgoals during planning.
PERIA addresses this by combining language and vision planning. It uses a multi-modal language model (MLLM) to reason and generate imagined subgoal images which are then used to guide the robot’s actions. This holistic approach significantly improves the accuracy of instruction following and task success rate compared to methods using only language or vision planning.
Key Takeaways#
Why does it matter?#
This paper is crucial for robotics researchers working on long-horizon manipulation tasks. It introduces PERIA, a novel framework that significantly improves instruction following accuracy by integrating both language and vision planning, offering a more robust and intuitive approach. This work opens new avenues for research in multi-modal planning and could greatly enhance the capabilities of future robots.
Visual Insights#

This figure illustrates the PERIA framework, which mimics human cognitive processes for complex instruction following. It shows four stages: 1. Perceive: the robot perceives the environment and the task instruction; 2. Reason: the robot reasons out the steps required to complete the task, breaking down the complex instruction into sub-instructions; 3. Imagine: the robot imagines the intermediate subgoals and generates corresponding images; 4. Act: the robot acts according to the imagined subgoals and sub-instructions. The overall process is analogous to how humans interpret and execute complex instructions, using both logical reasoning and visual imagination.
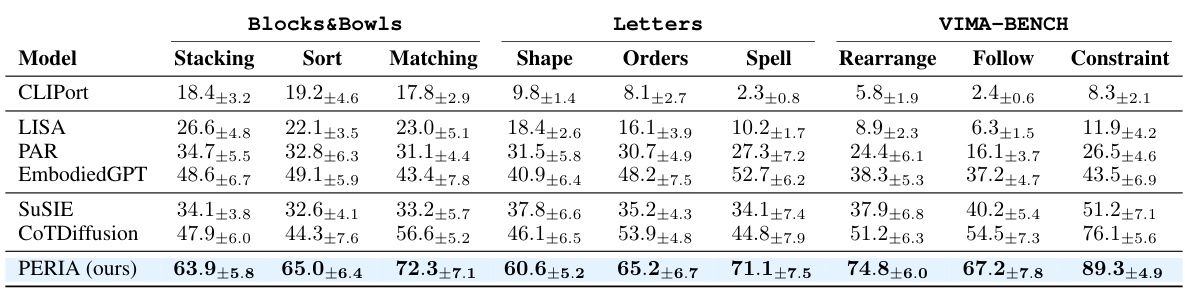
This table presents the success rates of different models on various long-horizon manipulation tasks. The tasks are categorized into three benchmark datasets: LoHoRavens (Blocks&Bowls and Letters), and VIMA-BENCH. Each dataset includes several tasks, which are further subdivided into sub-categories. The table shows the mean success rate and standard deviation across 5 independent runs for each model and task. The purpose is to compare the performance of PERIA (the proposed method) against several baseline methods, demonstrating its superiority in handling these complex tasks.
In-depth insights#
Holistic Planning#
Holistic planning, in the context of robotics and AI, signifies a paradigm shift from modular, task-specific approaches to a more integrated and comprehensive strategy. Instead of breaking down complex manipulation tasks into a series of independent sub-tasks, holistic planning emphasizes the simultaneous consideration of all relevant factors, including environmental perception, language understanding, and action execution. This integrated approach mirrors human cognition, where visual imagery and logical reasoning work in tandem. By unifying language and vision planning, the system can generate more robust and adaptable plans that avoid the compounding errors inherent in sequential, modular methods. The key to success lies in multi-modal alignment, enabling the system to seamlessly translate between language instructions and visual representations. This holistic approach enhances both the accuracy and efficiency of task completion, making it particularly suitable for long-horizon, complex manipulation tasks that demand a higher level of adaptability and robustness.
Vision-Language#
The intersection of vision and language in artificial intelligence is a rapidly evolving field, and a crucial aspect of enabling machines to understand and interact with the world in a human-like manner. Vision-language models (VLMs) aim to bridge the gap between these two modalities, allowing machines to process both visual and textual information simultaneously. This is achieved by training models on large datasets of paired images and text, enabling them to learn complex relationships between visual content and its linguistic descriptions. Effective VLMs are vital for various downstream applications such as image captioning, visual question answering, and robot manipulation. One key challenge is achieving robust and accurate performance across diverse visual inputs and varying language styles. Further research is needed to improve the generalization and robustness of VLMs, particularly in complex or ambiguous scenarios. Additionally, efficient and scalable training methods are critical for developing more sophisticated and powerful VLMs that can truly understand and respond to the multimodal nature of the world.
MLLM Reasoning#
Multimodal Large Language Models (MLLMs) represent a significant advancement in AI, enabling more nuanced reasoning capabilities compared to unimodal models. In the context of robotic manipulation, MLLM reasoning excels by integrating visual and textual information to understand complex instructions. This integration allows the model to not only parse commands literally but also to reason about the implied steps necessary for task completion. The MLLM can leverage its multimodal understanding to make inferences about object properties, spatial relationships, and the sequential nature of actions required. A critical aspect of MLLM reasoning is its ability to handle ambiguous instructions, breaking down complex tasks into smaller, more manageable subtasks, thus mitigating the risks of errors associated with long-horizon planning. This decomposition involves a higher level of cognitive processing, simulating elements of human planning. The ability to generate intermediate subgoals, both visually and textually, reflects the sophisticated reasoning capabilities of the MLLM. Ultimately, effective MLLM reasoning is pivotal for achieving robust and reliable robotic manipulation in open-ended environments. It bridges the gap between abstract human commands and precise robotic actions, which is a considerable step towards more generalized and versatile robotic autonomy.
Future Directions#
Future research should prioritize enhancing PERIA’s adaptability to novel environments and tasks. Online learning and adaptation techniques are crucial to overcome limitations posed by reliance on pre-collected datasets. Addressing the computational intensiveness of the current framework, including exploring more efficient training strategies and lightweight model architectures, is vital. Furthermore, thorough real-world evaluations are necessary to assess PERIA’s robustness and effectiveness in diverse, dynamic settings, accounting for factors like noisy sensors and physical constraints. Extending PERIA’s capabilities to handle increasingly complex, open-ended instructions warrants investigation, as well as exploring integration with more advanced, multimodal LLMs. Finally, developing comprehensive safety mechanisms is paramount, including rigorous testing and safeguards to mitigate potential biases or unintended consequences. These future directions aim to make PERIA a truly versatile and safe tool for robotic manipulation in the real world.
Task Generalization#
The concept of “Task Generalization” in the context of robotic manipulation using language and vision models is crucial. It assesses the model’s ability to successfully perform novel tasks that were not encountered during training. This involves evaluating performance on tasks with new objects, novel object configurations (placements), and unseen combinations of instructions and objects. High generalization capabilities are essential for real-world applicability, enabling the robot to adapt to unpredictable and diverse scenarios. The paper likely demonstrates the generalization performance of their proposed PERIA framework by testing it on unseen tasks of increasing complexity, measuring success rates and evaluating the quality of both language and vision planning components in these novel situations. Robustness against unseen situations is a key aspect of generalizability, indicating the model’s resilience to variations in the environment or instructions. Strong generalization suggests a deeper understanding of the underlying principles governing manipulation rather than rote memorization of specific training examples. The results likely showcase how the holistic approach of PERIA, integrating language and visual reasoning, contributes to superior generalization, surpassing methods relying solely on language or vision.
More visual insights#
More on figures
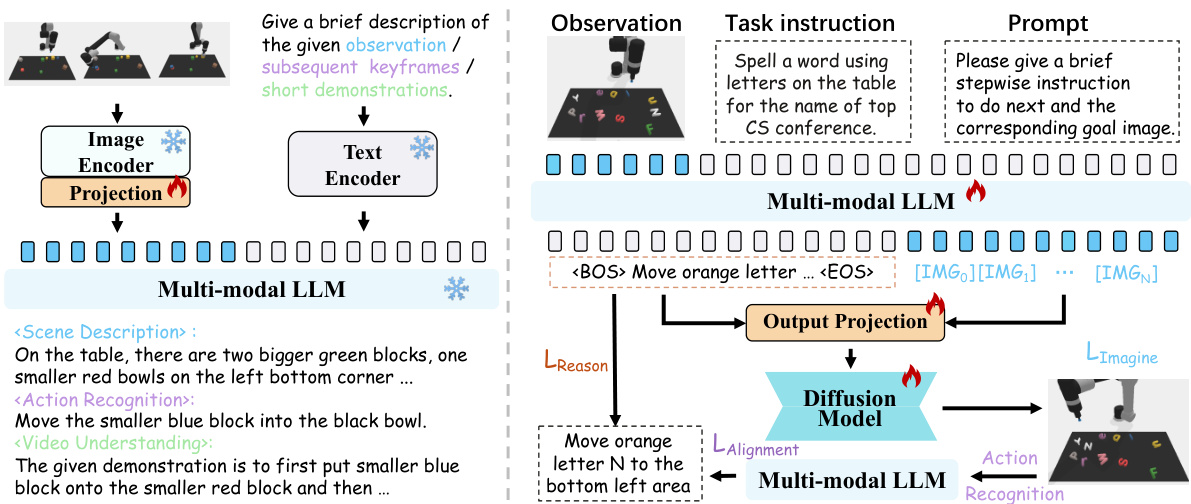
This figure illustrates the PERIA framework, which consists of three main stages: Perceive, Reason, and Imagine. In the Perceive stage, a lightweight multimodal alignment is performed on the encoding side of a Multi-modal Large Language Model (MLLM) to enable the model to understand both visual and textual information. In the Reason stage, instruction tuning is applied to the MLLM to allow it to generate stepwise language plans. Finally, in the Imagine stage, the MLLM is jointly trained with a diffusion model to generate coherent subgoal images that align with the language plans. An alignment loss is also used to ensure consistency between the language and vision planning. The entire framework is trained end-to-end.
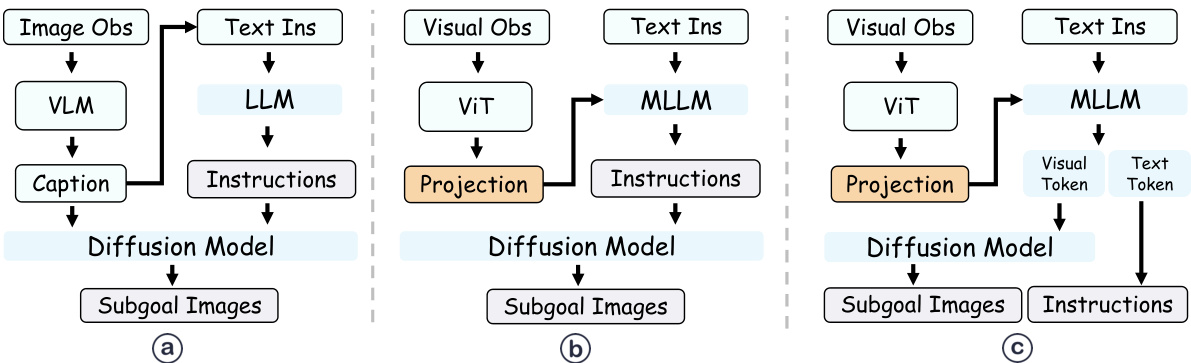
This figure illustrates three different approaches to generating subgoal images using a multi-modal large language model (MLLM). The first approach (a) uses visual tokens extracted from the MLLM during language planning, providing more expressive guidance than either captions (b) or decomposed instructions alone (c). In (a), the MLLM processes both language and vision and creates the visual tokens to guide the image generation model. (b) only uses the text captions from a vision language model to generate the images. (c) shows image generation solely relying on decomposed language instructions, lacking the benefit of visual context. The figure highlights PERIA’s approach which integrates language planning and visual planning for more effective subgoal image generation.
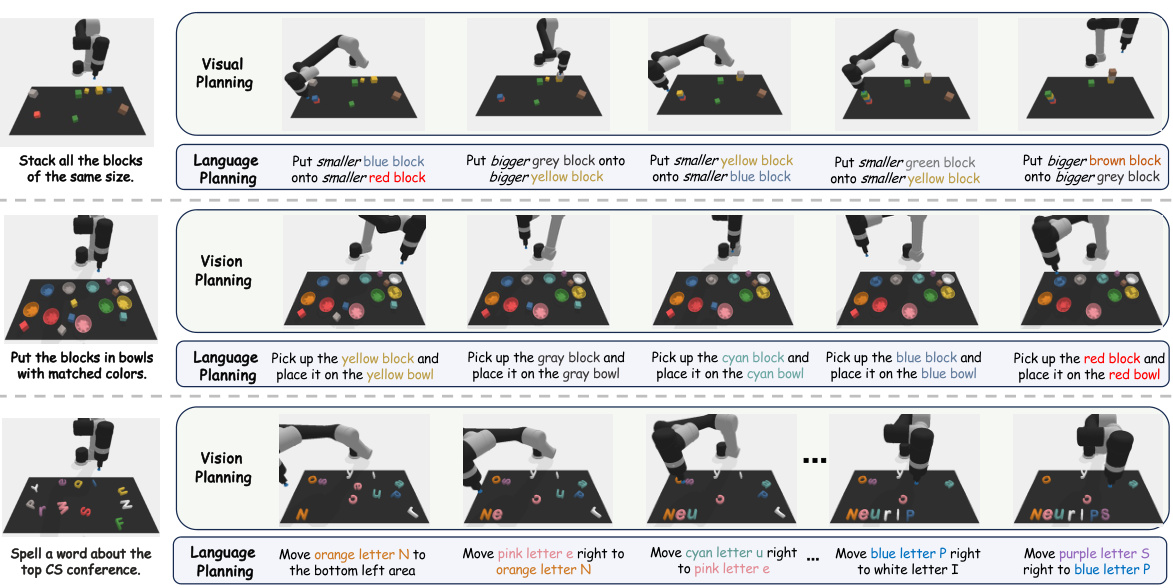
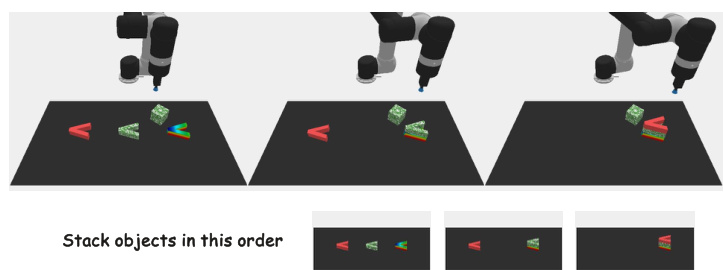
This figure showcases three example tasks demonstrating PERIA’s holistic approach to language and vision planning. Each row represents a different task: stacking blocks by size, sorting blocks into color-matched bowls, and spelling a word using letter blocks. The left column shows the original task instruction. The middle column depicts stepwise sub-instructions generated by PERIA’s language planning module, guiding the robot through sequential actions. The right column presents the corresponding subgoal images generated by the vision planning module, providing intuitive visual milestones that complement the textual instructions. The combination of language and vision planning helps the robot successfully complete these complex manipulation tasks, significantly improving accuracy and efficiency compared to methods relying solely on language or vision.
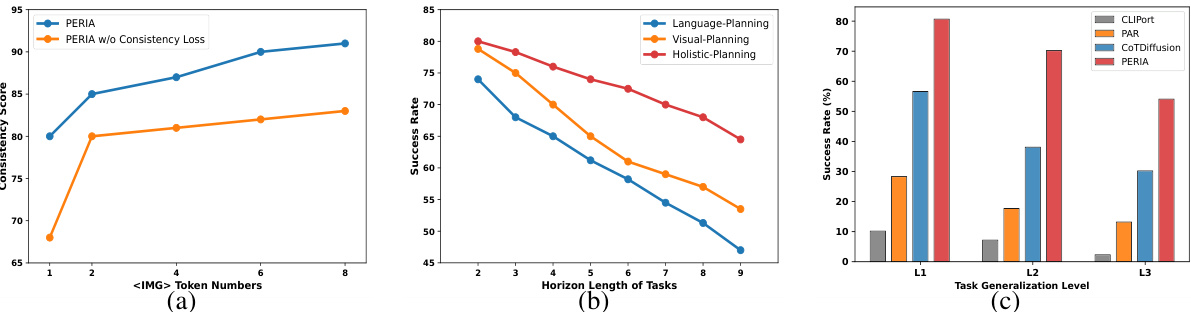
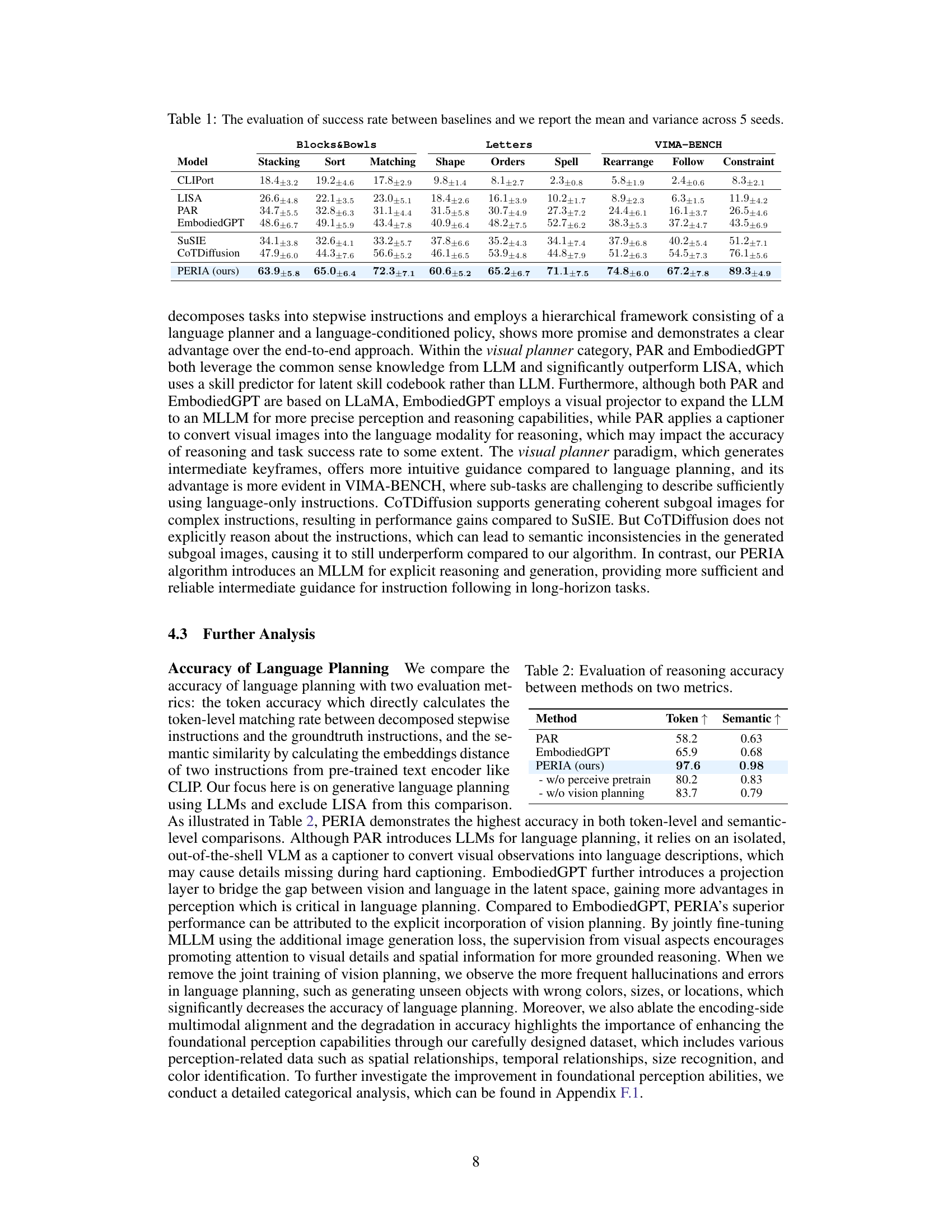
This figure presents a quantitative analysis of the PERIA model’s performance, broken down into three subfigures. Subfigure (a) shows the impact of the consistency loss and the number of [IMG] tokens on the model’s performance. Subfigure (b) compares the performance of three different planning paradigms (language, vision, and holistic) across tasks with varying horizon lengths. Subfigure (c) evaluates the generalization ability of the model across three levels of task complexity.

This figure shows examples of how PERIA performs holistic language and vision planning for three different tasks. Each task starts with a high-level instruction (e.g., ‘Stack all blocks in a pyramid and each layer in one color’). PERIA then decomposes this instruction into a sequence of stepwise sub-instructions, which are accompanied by corresponding subgoal images. These subgoal images visually represent the intermediate states that the robot should achieve towards the completion of the task. The combination of language and vision planning provides more intuitive and informative guidance to the robot than language-only planning, making the instruction-following process more robust and efficient.

This figure showcases examples of PERIA’s holistic language and vision planning for complex tasks. It presents three different manipulation tasks, each illustrated with a sequence of images and corresponding text. The text includes the original instruction, the decomposed language plan (stepwise instructions), and a visual plan (coherent subgoal images). This demonstrates how PERIA breaks down complex instructions into smaller steps for both language and visual guidance, helping the robot to complete the task.

This figure shows example scenarios of PERIA’s holistic language and vision planning. For each example, a complex instruction (e.g., ‘Stack all blocks in a pyramid and each layer in one color’) is broken down into stepwise sub-instructions and subgoal images. These sub-instructions and images guide the robot’s actions, providing a more intuitive and effective approach to long-horizon manipulation tasks than traditional methods that rely solely on language or vision planning.

This figure shows an example of the task ‘SortVerticalSymmBlockstoArea’ within the ‘Letters Shape’ category of the LoHoRavens benchmark. The task involves sorting vertically symmetrical letters to a specific area on a table. The figure illustrates the sequence of actions the robot takes to perform this task, progressing from an initial state with scattered letters to a final state with the vertically symmetrical letters neatly organized in the designated area.
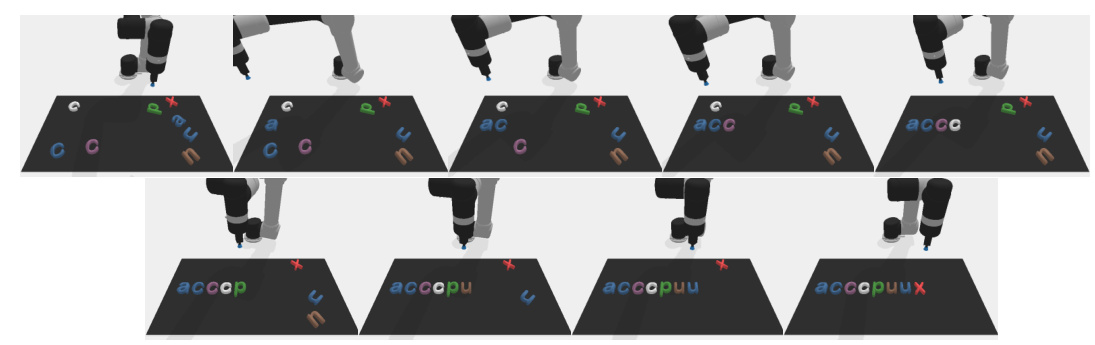
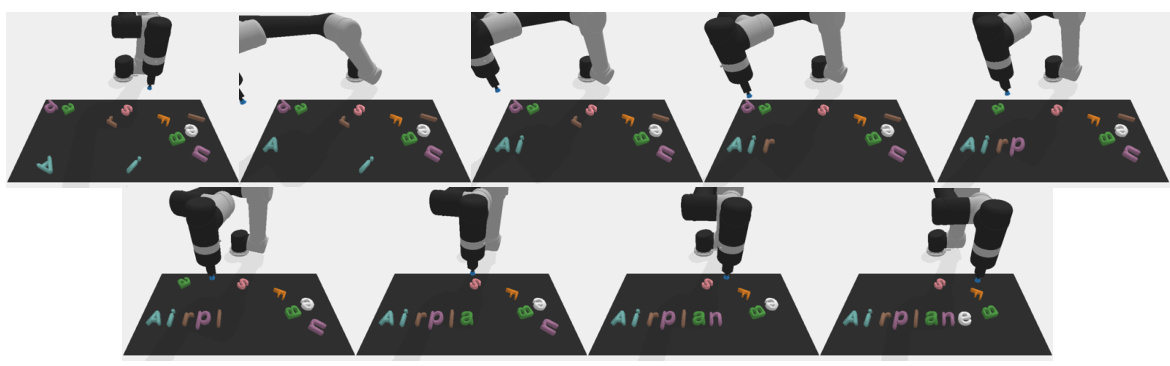
This figure shows an example of the SpellTransName task in the Letters Spell category. The task is to spell out the name of a common transportation. The robot successfully spells out the word ‘Airplane’ by moving the letters one by one into the corresponding positions.
This figure shows several examples of how PERIA performs holistic language and vision planning. For each task, the top row displays the initial scene, while the following rows show the stepwise decomposition into sub-instructions and corresponding subgoal images. The sub-instructions guide the robot’s actions, while the subgoal images provide a visual representation of the desired intermediate states, facilitating a more intuitive and accurate understanding of the task. The examples highlight PERIA’s ability to handle complex, long-horizon tasks, breaking down general instructions into manageable steps.
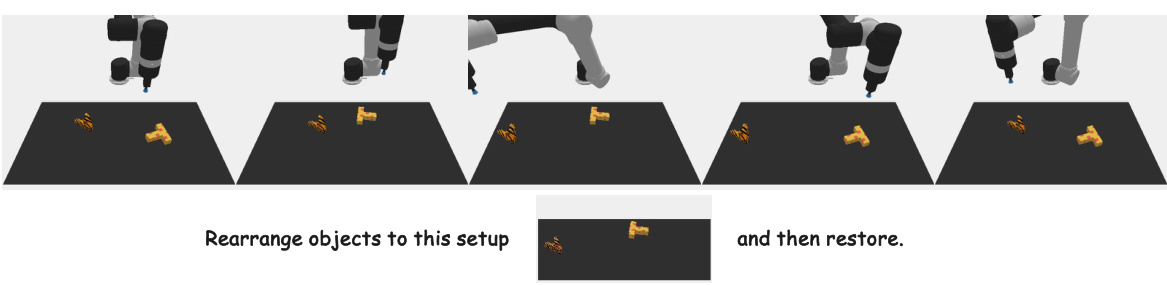
This figure shows an example of the task ‘RearrangeObjtoGoalthenRestore’ from the VIMA-BENCH Rearrange benchmark. The task involves rearranging objects to a specific setup shown in the image, and then restoring them to their original positions. The figure consists of a sequence of images showing the robot’s actions to complete the task, along with the initial and final states. The task demonstrates the complexity of long-horizon manipulation tasks where the robot needs to plan a sequence of actions to achieve a specific goal, potentially requiring intermediate subgoals.

This figure shows an example of the
SweepNoTouchConstask from the VIMA-BENCH dataset. The task instruction is ‘Sweep allinto without touching ’. The image sequence displays a robot arm manipulating objects. The goal is to move all the yellow blocks into the wooden container without touching the red blocks. This illustrates a long-horizon manipulation task where careful planning and coordination are required to avoid collisions and complete the task successfully.
This figure showcases examples of how PERIA performs holistic language and vision planning to follow complex instructions. It shows three different long-horizon manipulation tasks. For each, the top row illustrates the initial scene. The middle row depicts the stepwise sub-instructions generated by the language planner (textual) and the corresponding subgoal images generated by the vision planner (visual). The bottom row shows the final state after the robot has completed the task. This demonstrates how PERIA combines language and vision to break down complex tasks into manageable steps, guided by both logical reasoning and intuitive visualization.

This figure shows a word cloud visualization summarizing the key aspects of the three benchmark datasets (Blocks&Bowls, Letters, and VIMA-BENCH). The size of each word corresponds to its frequency in the instructions. It highlights the frequent use of words related to colors, object sizes, spatial relationships, actions, and specific instructions for each dataset, illustrating the complexity and variety of instructions.
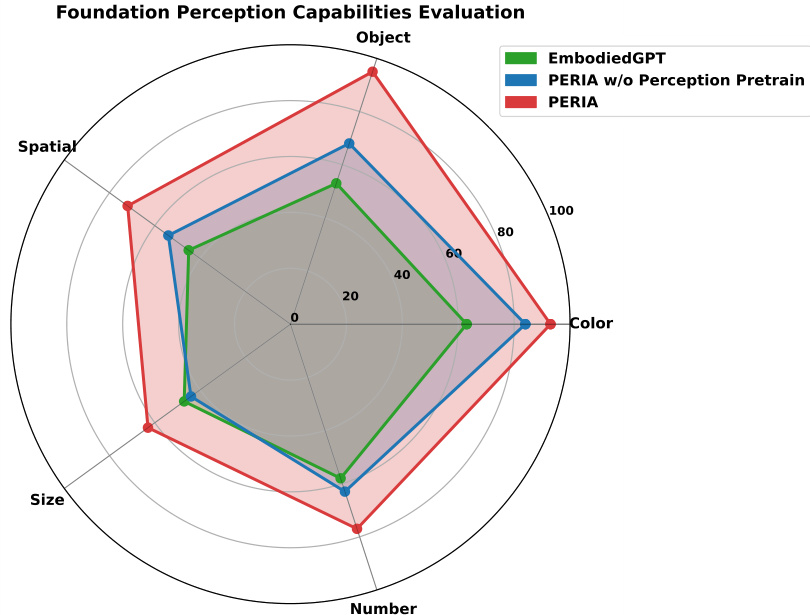
This radar chart visualizes the performance of three different methods (EmbodiedGPT, PERIA without perception pretraining, and PERIA) across five fundamental perception capabilities: object recognition, color recognition, size identification, number counting, and spatial relationship understanding. Each axis represents one of these capabilities, and the distance from the center to the point on each axis indicates the performance score for that capability. The chart shows that PERIA, with its multi-modal alignment, significantly outperforms the other two methods across all five perception capabilities.
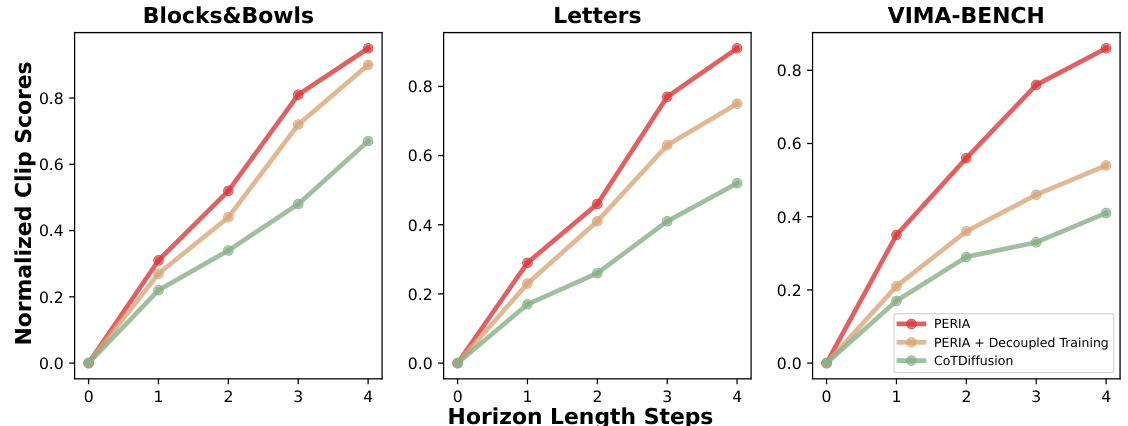
This figure compares the performance of three different methods (PERIA, PERIA with decoupled training, and CoTDiffusion) in terms of semantic alignment between generated subgoal images and instructions across different task horizons. The normalized CLIP score is used as the metric to evaluate this alignment. The x-axis represents the horizon length (number of steps) of the tasks, and the y-axis shows the normalized CLIP score. Higher scores indicate better semantic alignment. The results show that PERIA consistently outperforms the other two methods, especially in longer-horizon tasks, demonstrating the effectiveness of holistic language and vision planning in achieving accurate instruction following.
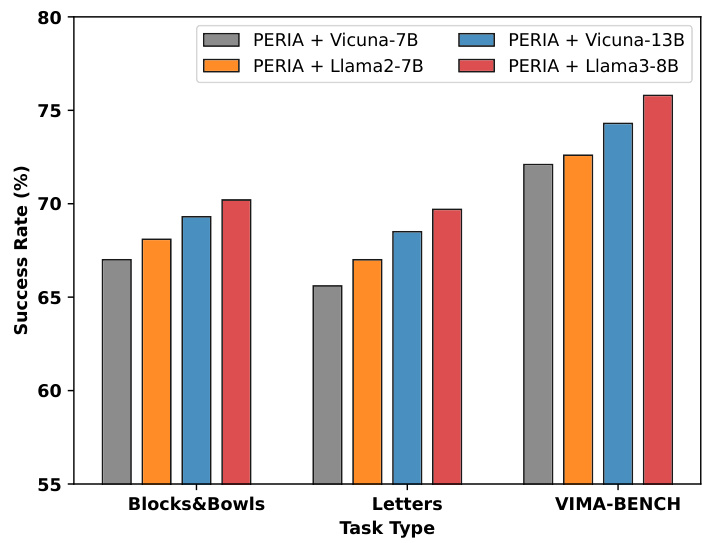
This bar chart compares the success rates of PERIA when using different large language models (LLMs) as backbones across three benchmark tasks: Blocks&Bowls, Letters, and VIMA-BENCH. The LLMs tested are Vicuna-7B, Vicuna-13B, Llama2-7B, and Llama3-8B. The chart demonstrates that larger and more recently developed LLMs tend to result in higher success rates for PERIA, showcasing the benefit of more powerful LLM backbones for improved performance in long-horizon robotic manipulation tasks.
More on tables
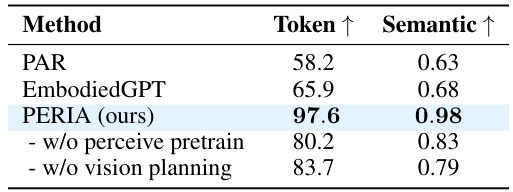
This table presents the success rates of different methods across various tasks in three benchmark datasets: LoHoRavens, VIMA-BENCH, and Letters. The methods are categorized into three types: end-to-end, language planning, and vision planning. The table shows that PERIA (the proposed method) significantly outperforms the baselines across all tasks and datasets, demonstrating the effectiveness of its holistic language and vision planning approach. Ablation studies (removing the perception pretraining or vision planning) are also included, showcasing the contribution of each component to the overall performance.
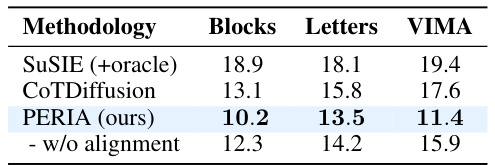
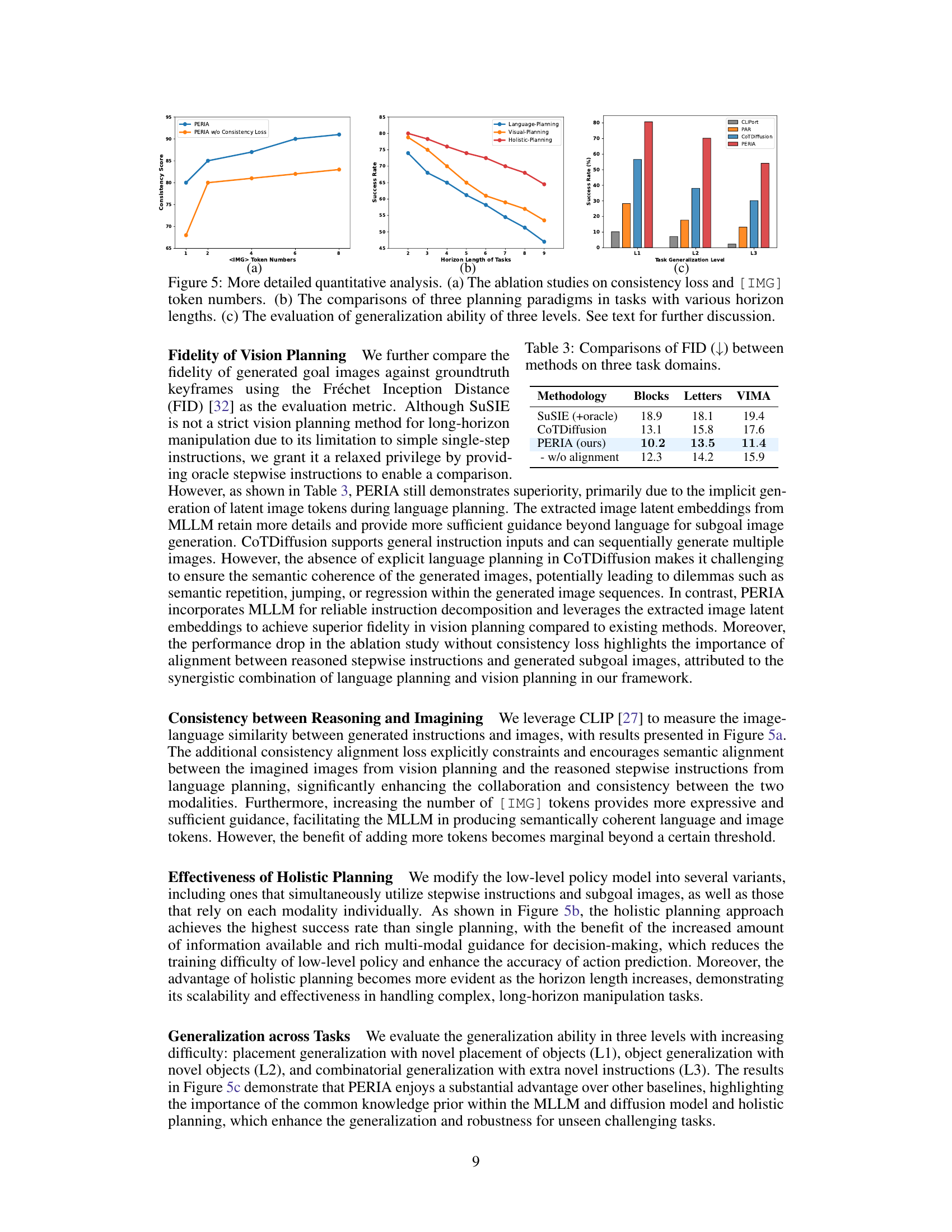
This table presents a comparison of the Fréchet Inception Distance (FID) scores for three different vision planning methods across three task domains: Blocks, Letters, and VIMA. Lower FID scores indicate better image generation fidelity compared to ground truth. The table includes results for SuSIE (with oracle stepwise instructions provided for a fair comparison), CoTDiffusion, and PERIA (with and without the multimodal alignment). PERIA demonstrates superior performance, highlighting the benefit of its integrated language and vision planning approach.
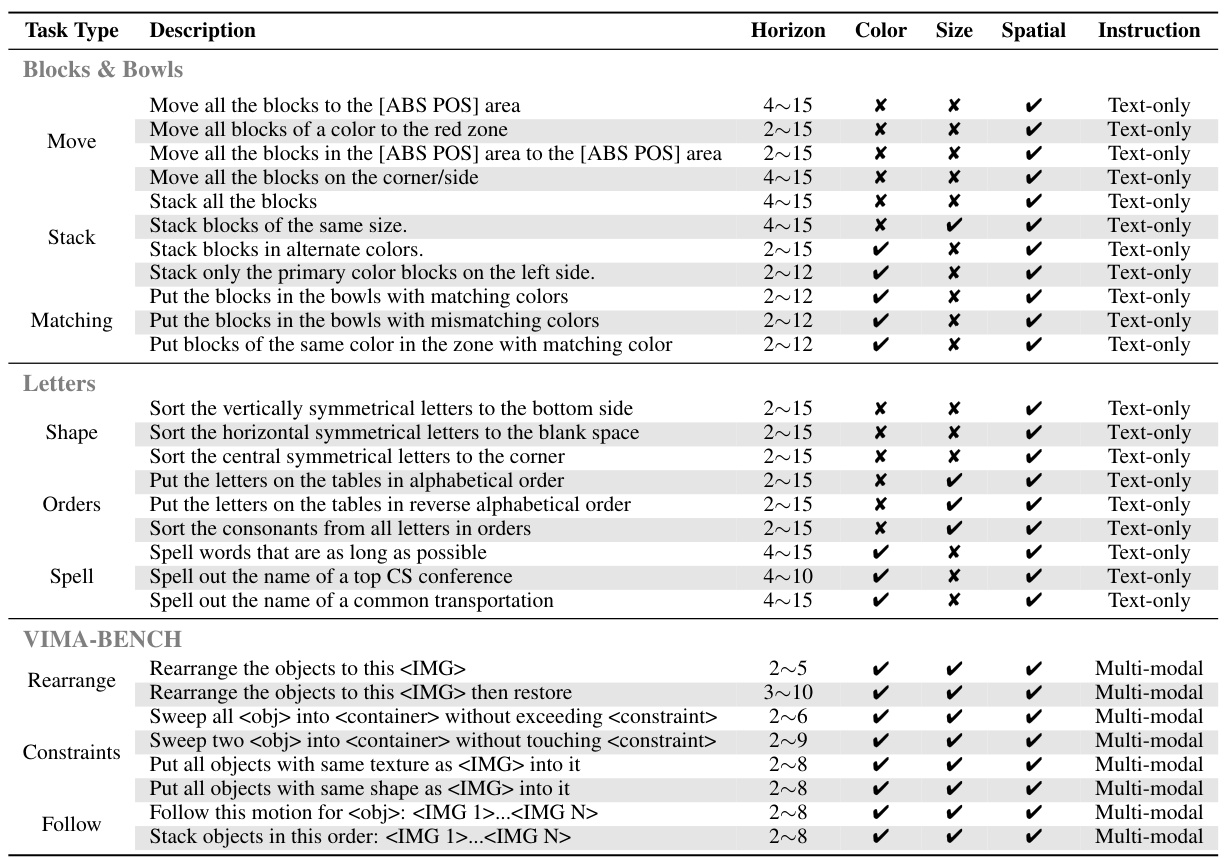
This table presents the success rates of various models on different long-horizon manipulation tasks. The tasks are categorized into several groups (Stacking, Sort, Matching, Shape, Orders, Spelling, Rearrange, Follow, Constraint) reflecting different complexities and types of instructions. The mean and variance of the success rates across five different seeds are provided for each model and task, allowing for a comparison of performance across various methods.

This table presents the success rates of different methods (baselines and the proposed PERIA model) across various tasks categorized into three benchmark datasets: LoHoRavens, VIMA-BENCH, and a newly designed Letters benchmark. For each dataset, the tasks are further categorized into subcategories (e.g., within LoHoRavens: Stacking, Sort, Matching, Shape, Orders, Spelling, etc.). The results show the mean success rate and standard deviation across five different seeds for each method and task. This allows for a comparison of the performance of various approaches in long-horizon manipulation tasks.

This table presents the success rates of different manipulation methods across various tasks categorized into three benchmark datasets. The methods include end-to-end, language planning, and vision planning approaches. The results show the mean and variance of success rates over five separate trials, providing a comprehensive comparison of performance.
Full paper#