↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current image generation models primarily rely on text or image conditioning, neglecting the rich relational information embedded in real-world graph-structured data. This limitation hinders the generation of coherent and controllable images when the underlying data possesses complex interdependencies. The paper addresses this by introducing the Graph2Image task, which aims to generate images directly from multimodal attributed graphs (MMAGs), encompassing both image and text information.
To tackle this challenge, the authors propose INSTRUCTG2I, a novel graph context-conditioned diffusion model. This model uses personalized PageRank and re-ranking to sample informative neighbors in the graph, and a Graph-QFormer to effectively encode graph nodes as auxiliary prompts. Furthermore, classifier-free guidance allows for controllable image generation by adjusting the influence of graph information. Experiments on diverse datasets demonstrate that INSTRUCTG2I outperforms existing methods in image quality and controllability.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to image generation using multimodal attributed graphs (MMAGs). It addresses the limitations of existing methods by leveraging graph structure and multimodal information for more coherent and controllable image synthesis. This opens up new avenues for research in image generation and its applications in various fields, such as virtual art creation and e-commerce.
Visual Insights#
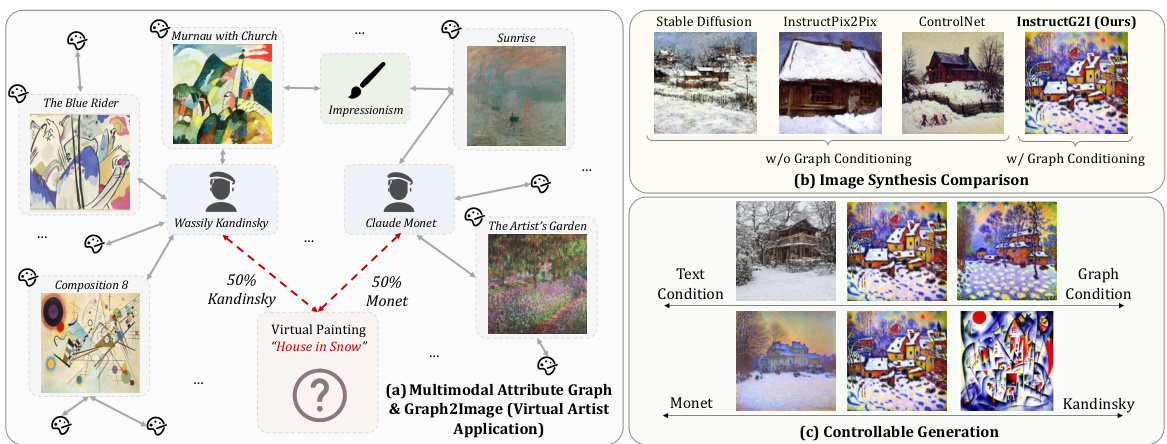
This figure demonstrates the core concept and capabilities of the INSTRUCTG2I model. Panel (a) shows a multimodal attributed graph (MMAG) example, illustrating how artworks are interconnected based on style, artist, etc. Panel (b) compares INSTRUCTG2I’s image generation performance against existing methods (Stable Diffusion, InstructPix2Pix, and ControlNet), highlighting the improvement achieved by incorporating graph information. Finally, panel (c) showcases INSTRUCTG2I’s ability to controllably generate images by adjusting the weighting of text and graph-based prompts, with examples of artwork generation influenced by the style of Monet and Kandinsky.
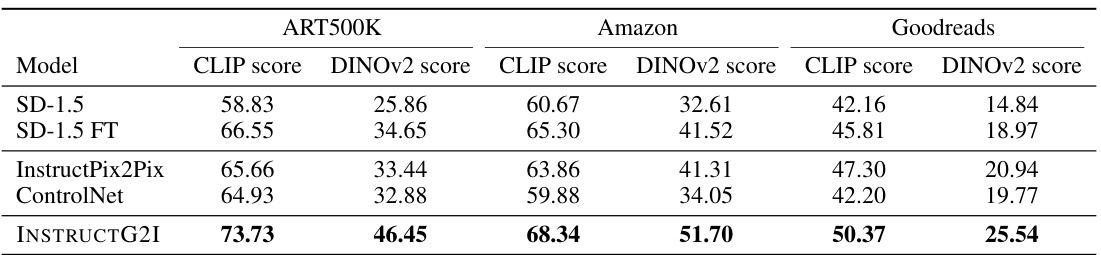
This table presents a quantitative comparison of various image synthesis methods on three different datasets: ART500K, Amazon, and Goodreads. The methods compared include Stable Diffusion (with and without fine-tuning), InstructPix2Pix, ControlNet, and the proposed INSTRUCTG2I model. The evaluation metrics used are CLIP score and DINOV2 score, which measure the similarity between generated images and ground truth images. The results demonstrate that INSTRUCTG2I significantly outperforms the baselines, highlighting the effectiveness of incorporating graph conditioning into the image generation process.
In-depth insights#
Graph2Image Task#
The Graph2Image task, as described, presents a novel and challenging problem in image generation. It moves beyond traditional text-based or image-based conditioning by leveraging the rich relational information inherent in multimodal attributed graphs (MMAGs). This is significant because MMAGs capture complex relationships between entities, offering a more nuanced and comprehensive context for image synthesis than simpler methods. The task’s difficulty stems from the combinatorial explosion in graph size and the need to effectively encode both structural and semantic relationships within the graph. Successfully tackling Graph2Image requires innovative solutions for efficient graph representation, contextual information selection, and controllable generation based on graph characteristics. The success of such a model would have far-reaching implications, enabling new applications in virtual art creation, e-commerce product visualization, and beyond, by generating images tailored to specific contextual relationships rather than isolated textual or visual cues.
MMAG Encoding#
MMAG encoding presents a significant challenge in graph-based image generation due to the combinatorial explosion of information within multimodal attributed graphs (MMAGs). Naive approaches that directly incorporate all nodes and edges into the model quickly become computationally infeasible. Effective MMAG encoding strategies must therefore focus on selectively extracting the most relevant information. This might involve techniques like personalized PageRank to prioritize important nodes based on their structural connectivity, or the use of vision-language models to score the relevance of different nodes to a target image or text prompt. Dimensionality reduction is crucial, transforming the potentially massive graph into a concise and informative representation for the image generation model. This could involve techniques such as graph neural networks, which learn node embeddings that capture both local and global graph context. Furthermore, a successful method needs to address the heterogeneity of information within the MMAG, effectively combining image features, text descriptions, and relationships. The final encoded representation needs to be tailored to the specifics of the image generation model, seamlessly integrating with its latent space and conditioning mechanisms for optimal performance. Controllability is also a key aspect, allowing the model to generate images by selectively emphasizing different aspects of the MMAG.
Controllable Gen#
Controllable generation in image synthesis models is crucial for enabling users to guide the image creation process effectively. This involves manipulating various parameters, such as text prompts and graph structures, to achieve desired outcomes. The ability to adjust the relative influence of these parameters allows for fine-grained control over the generated image, balancing factors like style and content. A key challenge lies in the effective integration of different control mechanisms, particularly when handling multiple sources of guidance simultaneously. Techniques such as classifier-free guidance can be leveraged to manage the interplay between different control signals. Graph-based methods offer unique advantages by allowing the control of image generation via the relationships between entities encoded in a graph structure. Successfully implementing controllable generation requires careful design of both the model architecture and the user interface to ensure intuitive and effective control mechanisms. The effectiveness of controllable generation is ultimately determined by the ability to generate images that accurately reflect the user’s intentions, demonstrating a high level of fidelity and responsiveness to the input controls.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper on image synthesis from multimodal attributed graphs, ablation studies would likely focus on several key aspects. The impact of graph-structured data is a primary focus, examining how performance changes when the model is trained only on text or images, lacking the graph’s relational information. A second area of investigation would be the choice of graph sampling methods. The paper would likely compare personalized PageRank-based sampling, the proposed method, to simpler alternatives, revealing the benefit of incorporating semantic information into node selection. The efficacy of the model’s core components would also be examined through ablation. Removing the Graph-QFormer module would demonstrate its value in integrating information from neighboring nodes. These controlled experiments provide a granular understanding of the model’s architecture, isolating the effects of individual elements and confirming the necessity of the proposed components for optimal performance. The results of these studies offer crucial validation of the model’s design and highlight the key factors driving its success.
Future Works#
Future work should explore several promising avenues to advance the field. Extending INSTRUCTG2I to handle heterogeneous graphs is crucial, as real-world data often contains diverse node and edge types. This requires developing more sophisticated encoding mechanisms to capture the nuanced relationships between different entity types. Investigating larger diffusion models, such as SDXL, could significantly improve image quality and detail, though computational costs must be carefully considered. Improving scalability and efficiency is paramount, as current methods struggle with large graphs. This necessitates exploring alternative graph sampling techniques and more efficient encoding strategies. Furthermore, exploring alternative diffusion models beyond Stable Diffusion could potentially lead to improvements in generation quality and control. Finally, a thorough investigation into the ethical implications of generating images from multimodal attributed graphs is essential to ensure responsible development and deployment of this technology. This includes careful consideration of biases in the data and mitigating the potential for misuse.
More visual insights#
More on figures
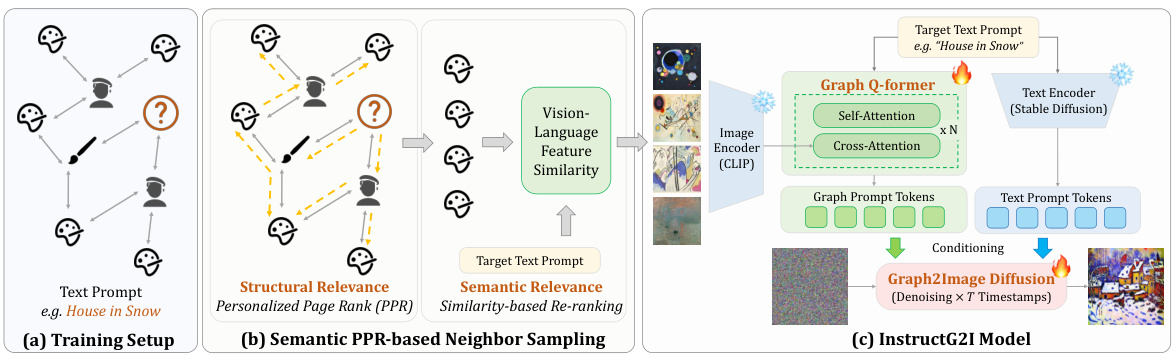
This figure illustrates the overall framework of the INSTRUCTG2I model, showing the process of generating images from multimodal attributed graphs (MMAGs). It is broken down into three parts: (a) Training setup, where the input consists of a target node within the graph and its associated text prompt; (b) Semantic PPR-based neighbor sampling, illustrating the process of selecting relevant neighbor nodes using both structural (personalized PageRank) and semantic (similarity-based reranking) criteria; and (c) The InstructG2I model, which uses a Graph-QFormer to encode the selected neighbors into graph tokens. These graph tokens, along with text prompt tokens, are then used to guide the denoising process of a diffusion model to generate the final image.

This figure presents an overview of the proposed Graph2Image task and the INSTRUCTG2I model. (a) illustrates the concept of multimodal attributed graphs (MMAGs) used as input, showing how interconnected nodes with image and text information can represent complex relationships (in this case, virtual art). (b) compares image generation results of INSTRUCTG2I against other methods, highlighting its superior performance due to the incorporation of graph context. (c) showcases INSTRUCTG2I’s ability to control image generation through text and graph parameters, providing smooth transitions between different styles and levels of detail.
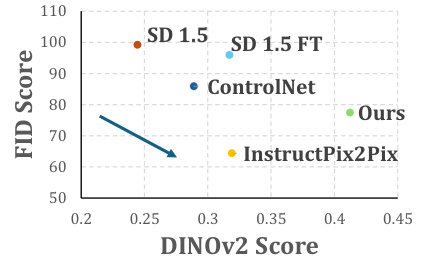
This figure shows the quantitative comparison of INSTRUCTG2I against various baselines across three datasets (ART500K, Amazon, and Goodreads) using two metrics: DINOV2 score (representing image-image similarity) and FID score (representing image quality and consistency). The plot visually demonstrates that INSTRUCTG2I outperforms other methods, achieving the optimal balance between high DINOV2 scores (indicating strong similarity to ground truth images) and low FID scores (indicating high image quality).

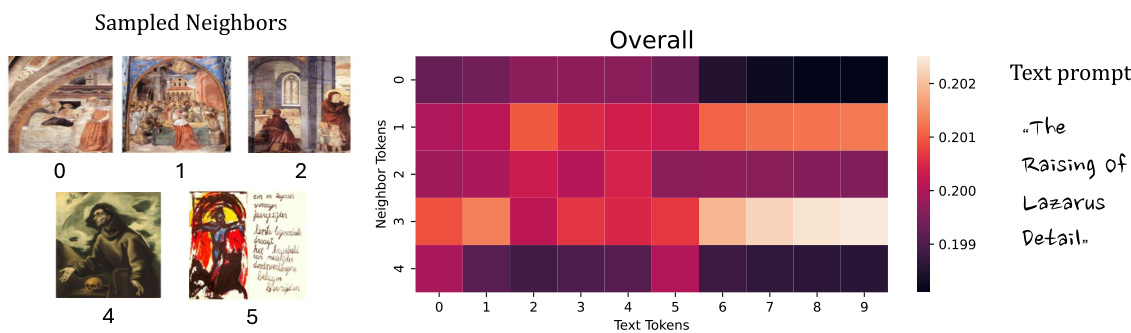
This figure shows the results of an ablation study on the semantic PPR-based neighbor sampling method used in INSTRUCTG2I. The study compares different neighbor sampling techniques: random sampling, PPR-based sampling, semantics-based sampling, and the proposed semantic PPR-based sampling. For each method, the figure shows example sampled neighbors, and the generated images based on those neighbors. The results demonstrate that incorporating both structural and semantic relevance in neighbor selection significantly improves the quality and consistency of the generated images with the ground truth image.

This figure demonstrates the core idea and capabilities of the INSTRUCTG2I model. (a) shows an example of a Multimodal Attributed Graph (MMAG) used for image generation, highlighting the task of Graph2Image. (b) compares the image synthesis results of INSTRUCTG2I with baseline methods, showcasing its superior performance due to graph conditioning. (c) illustrates the model’s controllable generation capabilities, allowing for smooth transitions in image style by adjusting the influence of text and graph information.
This figure illustrates the overall framework of the INSTRUCTG2I model for image generation from multimodal attributed graphs. It is broken down into three parts: (a) Shows the initial setup with a target node and its text prompt in an MMAG. (b) Details the semantic PPR-based neighbor sampling process, which uses personalized PageRank and similarity-based reranking to select relevant neighbor nodes. (c) Illustrates the INSTRUCTG2I model architecture, where selected neighbors are processed by a Graph-QFormer and combined with text prompt tokens to guide the diffusion model during the image denoising process.
More on tables
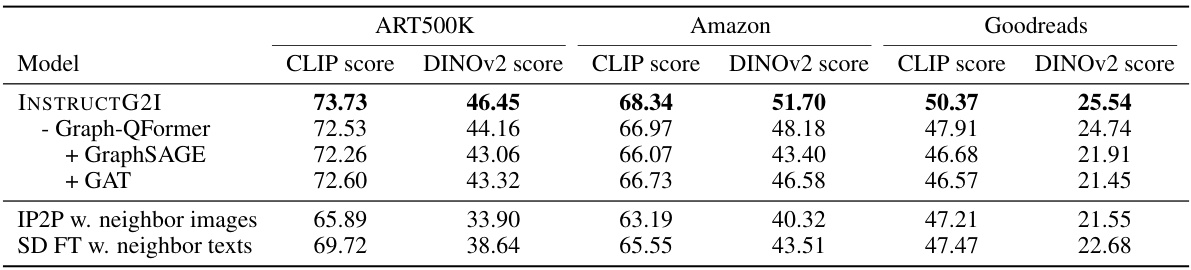
This table presents the results of an ablation study comparing different variants of graph conditions and the Graph-QFormer architecture in the INSTRUCTG2I model. It shows the performance of INSTRUCTG2I with the full model, and then compares this against versions where the Graph-QFormer is removed or replaced with other graph encoding methods (GraphSAGE and GAT). Additionally, it shows how using only neighbor images or neighbor texts as conditions impacts the performance.
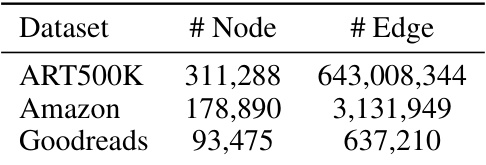
This table presents the number of nodes and edges in each of the three datasets used in the INSTRUCTG2I experiments: ART500K, Amazon, and Goodreads. It provides a summary of the size and complexity of the graph structures used in evaluating the model.

This table presents the hyperparameters used during the training process of the INSTRUCTG2I model and baseline models. It includes details like the optimizer used (AdamW), its specific settings (epsilon, beta1, beta2), weight decay, batch size per GPU, gradient accumulation steps, number of epochs, image resolution, learning rate, and the backbone stable diffusion model version (Stable Diffusion 1.5). These hyperparameters were fine-tuned separately for the three datasets used in the experiments (ART500K, Amazon, Goodreads).
Full paper#



















