↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are increasingly used as AI assistants, but they often generate false information, also known as hallucinations. This paper investigates why standard LLM alignment techniques fail to mitigate this issue. The authors find that training on novel or unfamiliar knowledge, as well as reward functions that prioritize length, contributes to hallucination.
To address this, they propose FLAME (Factual Alignment), an improved alignment method. FLAME uses factuality-aware supervised fine-tuning and reinforcement learning. This approach focuses on ensuring factual accuracy while maintaining instruction-following ability. Their experiments show that FLAME significantly reduces hallucinations in LLMs without compromising helpfulness, suggesting a path to more reliable and trustworthy AI.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it directly addresses the critical issue of factual inaccuracies in large language models (LLMs). By identifying the root causes of LLM hallucinations and proposing a novel alignment method (FLAME), it provides valuable insights and practical solutions for improving the reliability and trustworthiness of AI systems. This work has significant implications for the development of safer, more responsible AI applications across various domains.
Visual Insights#
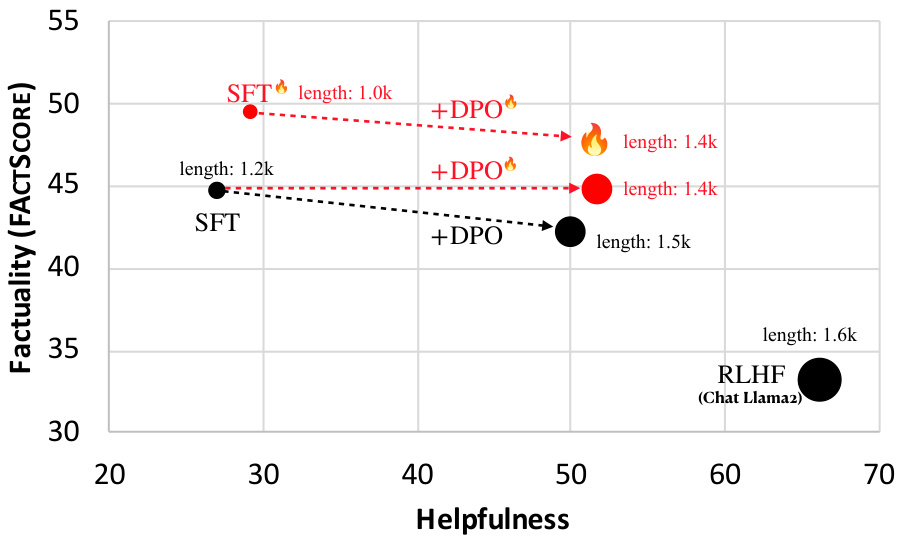
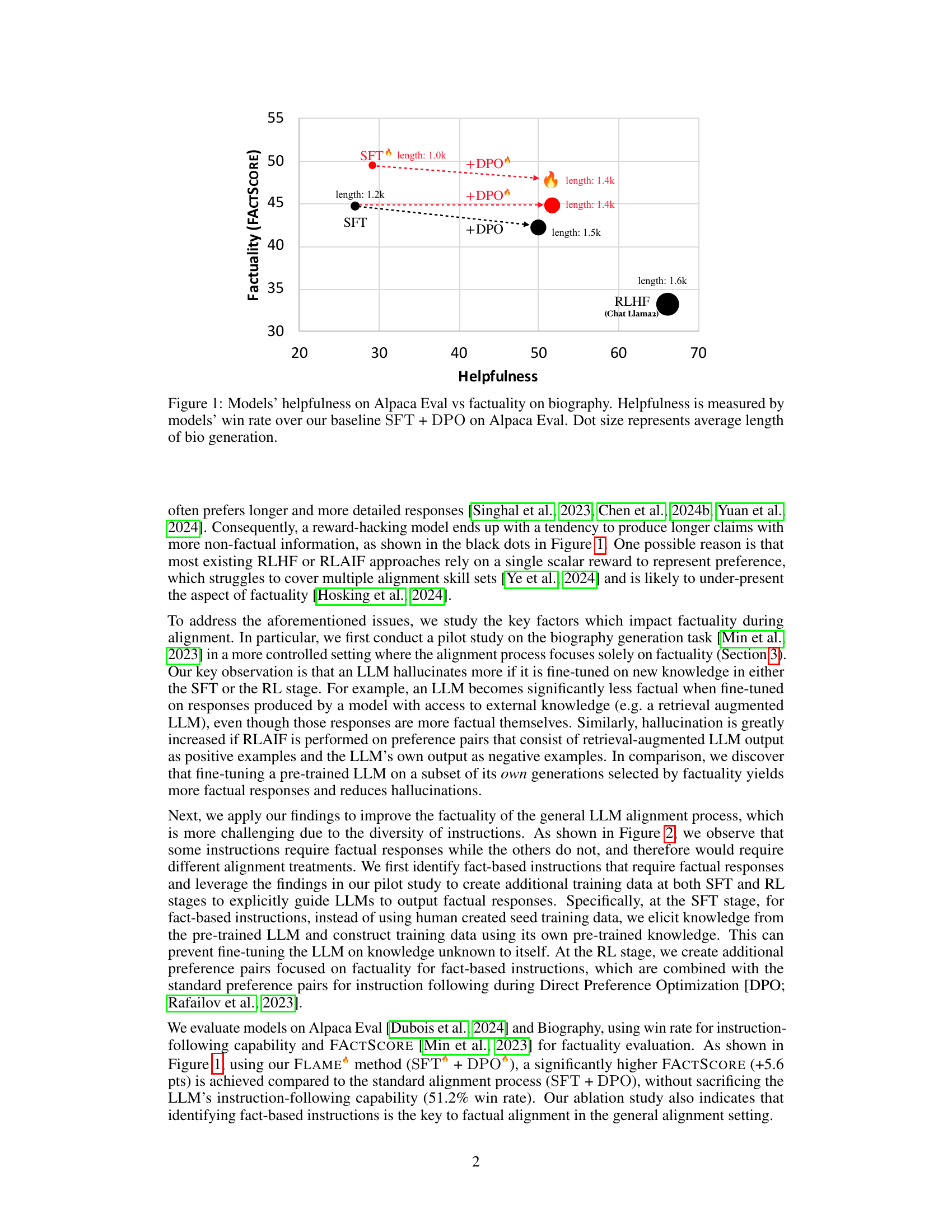
This figure shows the trade-off between helpfulness and factuality of different large language models (LLMs). Helpfulness is determined by the model’s win rate against a baseline model (SFT + DPO) on the Alpaca Eval benchmark. Factuality is measured using FACTSCORE on a biography generation task. The size of each dot corresponds to the average length of the generated biographies, indicating a correlation between response length and the tendency to hallucinate. The models shown include SFT (supervised fine-tuning), SFT + DPO (SFT with direct preference optimization), and RLHF (reinforcement learning from human feedback). The figure highlights that while increasing helpfulness, standard alignment techniques can negatively affect factuality.

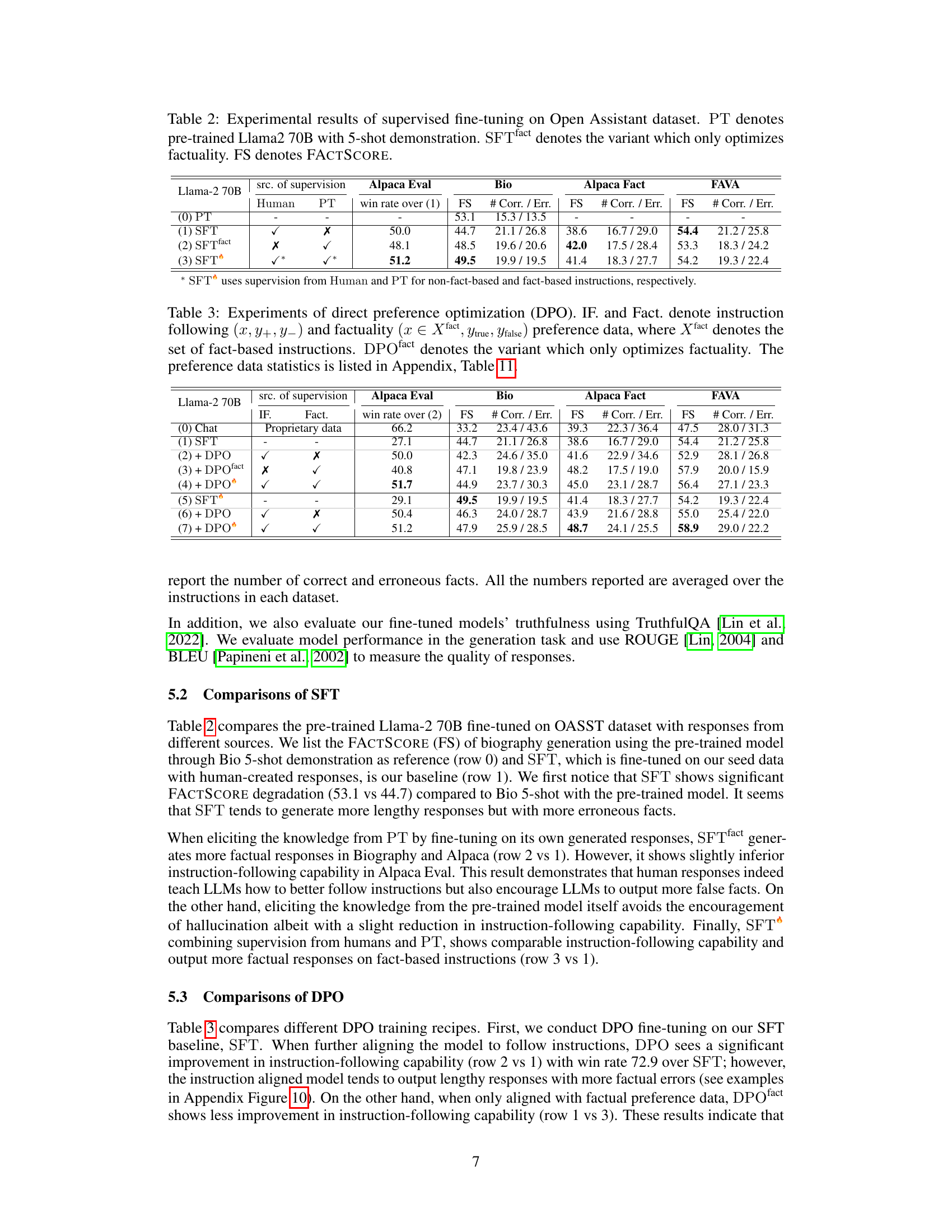
This table presents the experimental results of supervised fine-tuning on the Open Assistant dataset. It compares the performance of several models: a pre-trained Llama 2 70B model (PT), a standard supervised fine-tuned model (SFT), a factuality-focused fine-tuned model (SFTfact), and a combined model (SFT). The evaluation metrics include win rate on the Alpaca Eval benchmark and FACTSCORE (FS) for factuality on three datasets: Biography, Alpaca Fact, and FAVA. The table showcases the impact of focusing solely on factuality during the fine-tuning process.
In-depth insights#
Hallucination Causes#
Large language models (LLMs) are prone to hallucination, generating false information. This paper investigates the root causes of this phenomenon within the context of LLM alignment. The alignment process, while improving instruction-following, inadvertently exacerbates factual inaccuracies. Two key stages are identified: supervised fine-tuning (SFT) and reinforcement learning (RL). SFT, by training on potentially novel information within human-generated responses, encourages hallucination. The reward mechanisms in RL often prioritize length and detail, indirectly promoting the generation of fabricated information. Addressing these issues requires a more factuality-aware approach, carefully curating training data and adjusting reward functions to prioritize factual accuracy. The study highlights the importance of recognizing that training on information unfamiliar to the LLM itself is a crucial factor contributing to hallucinations. This suggests that future alignment strategies should focus on enhancing the model’s understanding of its existing knowledge base before introducing new, potentially unreliable information.
Factual Alignment#
The concept of “Factual Alignment” in large language models (LLMs) tackles the critical issue of hallucination, where models generate factually incorrect information. This problem is particularly challenging because conventional alignment methods, focused on instruction following and helpfulness, often inadvertently worsen factual accuracy. Supervised fine-tuning (SFT), a common technique, can introduce novel information that the LLM struggles to verify, leading to more hallucinations. Reinforcement learning (RL), often used after SFT, further complicates this by rewarding lengthier and more detailed responses, even when they are inaccurate. Therefore, factual alignment requires a nuanced approach that directly addresses the root causes. This might involve carefully curating training data to avoid unfamiliar knowledge, modifying reward functions to prioritize factuality, and potentially incorporating methods to explicitly identify and correct factual inaccuracies within the model’s generated outputs. Ultimately, solving this challenge is crucial for making LLMs more reliable and trustworthy.
FLAME Method#
The FLAME (FactuaLity-Aware AlignMEnt) method is a novel approach to improving the factuality of Large Language Models (LLMs) during the alignment process. It addresses the issue of LLMs generating false information (hallucinations), a common problem in current alignment techniques. FLAME’s core innovation lies in its two-pronged approach: factuality-aware supervised fine-tuning (SFT) and factuality-aware reinforcement learning (RL) through direct preference optimization (DPO). The SFT stage leverages the LLM’s own pre-trained knowledge for fact-based instructions, preventing the introduction of unfamiliar information. The DPO stage utilizes separate rewards for factuality and instruction following, preventing reward hacking that often favors length over accuracy. This dual-focus significantly improves the factual accuracy of LLMs without compromising their instruction-following capability. The method shows promising results in experiments, demonstrating the effectiveness of a factuality-centric approach to LLM alignment.
Empirical Findings#
The empirical findings section would likely present a detailed analysis of experiments conducted to evaluate the proposed FLAME model. It would likely compare FLAME’s performance against baseline models (standard alignment methods) across various metrics, such as factuality scores (FACTSCORE), instruction-following accuracy (Alpaca Eval), and possibly others like response length or helpfulness. Key findings would focus on demonstrating FLAME’s effectiveness in improving factuality without significantly harming instruction-following ability. The analysis would likely delve into the model’s performance on different types of instructions (fact-based vs. non-fact-based), revealing whether FLAME’s benefits are consistent across various instruction categories. Results from ablation studies investigating the impact of individual components of FLAME (e.g., factuality-aware SFT and DPO) would further clarify the contributions of each component to the overall performance. The section would need to robustly address statistical significance and provide clear visualizations (charts, graphs) illustrating the experimental results to provide convincing evidence of FLAME’s improvements. The results should showcase the superiority of FLAME over standard approaches in improving factual accuracy and maintaining instruction-following capabilities. Finally, the section could include qualitative analyses of generated responses, offering insightful examples that illustrate the strengths and weaknesses of FLAME.
Future Work#
The paper’s “Future Work” section would greatly benefit from exploring multi-faceted reward models that go beyond simple scalar rewards for instruction following and factuality. A more nuanced approach incorporating additional dimensions like helpfulness, safety, and logical reasoning is crucial for comprehensive LLM alignment. Investigating the trade-offs between these different aspects, especially given the limitations of current factuality metrics like FACTSCORE, is necessary. Further research should focus on improving the accuracy of the fact-based instruction classifier and creating a more robust factuality reward model. Additionally, addressing the challenge of hallucination in short-answer tasks, which differs from long-form responses, requires dedicated attention. Finally, a deeper investigation into the alignment tax phenomenon and how to improve both instruction-following capability and accuracy on standard knowledge benchmarks warrants further exploration.
More visual insights#
More on figures
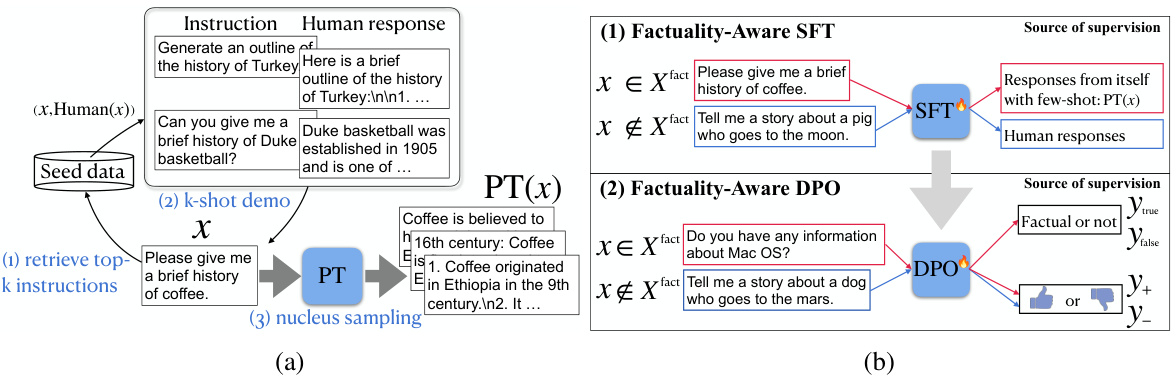
This figure illustrates the process of response generation using a pre-trained large language model (LLM) and the proposed factuality-aware alignment method. (a) shows the generation process with few-shot learning from the pre-trained model, where a small number of instructions and corresponding responses are used to guide the generation process. (b) illustrates the factuality-aware alignment, in which the LLM is trained to classify instructions as either fact-based or non-fact-based, with distinct training procedures for each type of instruction. For fact-based instructions, the model is trained on the responses generated by the pre-trained model to enhance factuality; whereas, for non-fact-based instructions, the model is trained on human-generated responses. This approach improves both the factuality and the instruction-following capability of the LLM.

This figure compares the helpfulness and factuality of different language models on two tasks: Alpaca Eval and biography generation. Helpfulness is assessed using the win rate against a baseline model (SFT + DPO) on the Alpaca Eval benchmark. Factuality is implicitly represented through the FACTSCORE metric applied to biographies. The size of the dots corresponds to the average length of the generated biographies. The figure suggests a trade-off between helpfulness (instruction following) and factuality (accuracy of generated content) in the language models, with longer biographies tending to be less factual.

This figure shows a scatter plot comparing the helpfulness and factuality of different language models on two tasks: Alpaca Eval (measuring helpfulness) and biography generation (measuring factuality). Helpfulness is represented by the win rate against a baseline model (SFT + DPO) on Alpaca Eval. Factuality is measured using FACTSCORE. The size of each data point corresponds to the average length of the generated biographies, illustrating a potential correlation between response length and factuality (longer responses tend to be less factual).

This figure shows the trade-off between helpfulness and factuality of different language models. Helpfulness is assessed using the Alpaca Eval benchmark, measuring the model’s win rate against a baseline model (SFT + DPO). Factuality is evaluated on a biography generation task, and is represented by the FACTSCORE. The size of each dot in the scatter plot corresponds to the average length of the generated biographies, indicating a potential correlation between response length and hallucination.

This figure shows the trade-off between helpfulness and factuality of different language models. Helpfulness is assessed using the Alpaca Eval benchmark, measuring the model’s win rate against a baseline model (SFT + DPO). Factuality is evaluated specifically on biography generation tasks. The size of each data point corresponds to the average length of the generated biographies. The figure suggests that models prioritizing helpfulness (longer responses) tend to sacrifice factuality, as indicated by a lower FACTSCORE.
More on tables

This table presents the results of a pilot study on biography generation. It compares different approaches to fine-tuning a language model (Llama-2 7B) for factuality, specifically focusing on supervised fine-tuning (SFT) and direct preference optimization (DPO). The table shows the source of supervision used for training (e.g., PTRAG, which leverages retrieval-augmented generation), the positive and negative examples used in DPO, the resulting FACTSCORE (a metric for factuality), and the number of correct and erroneous facts generated by the model.

This table presents the results of supervised fine-tuning experiments conducted on the Open Assistant dataset using three different models: the pre-trained Llama 2 70B model (PT), a supervised fine-tuned model (SFT), and a variant of the SFT model that focuses specifically on factuality (SFTfact). The table compares the performance of these models across four metrics: Alpaca Eval win rate (a measure of helpfulness), Biography FACTSCORE (a measure of factuality in biography generation), Alpaca Fact FACTSCORE (a measure of factuality in Alpaca Fact generation), and FAVA FACTSCORE (a measure of factuality in FAVA generation). The ‘# Corr. / Err.’ columns indicate the number of correct and erroneous facts generated by each model. This data allows researchers to assess the effectiveness of different training approaches on enhancing both the helpfulness and factual accuracy of LLMs.
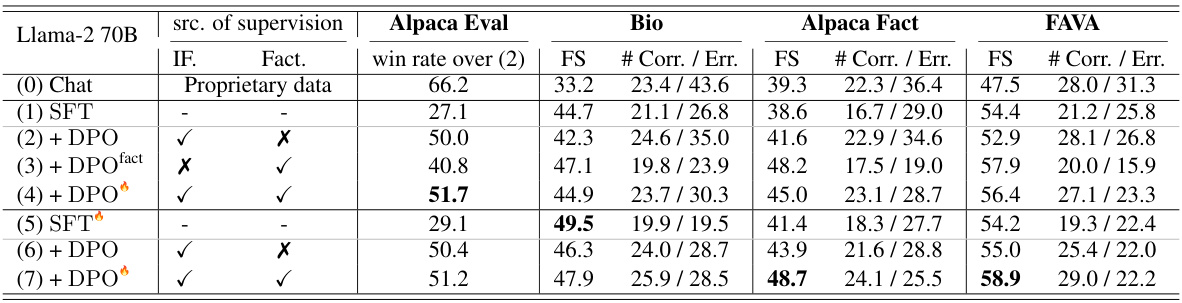
This table presents the results of experiments using direct preference optimization (DPO) for fine-tuning language models. It compares different configurations of DPO, including variations that optimize for instruction following alone, factuality alone, and both simultaneously. The table shows the performance of each model variant on four metrics: Alpaca Eval win rate, Bio FACTSCORE, Alpaca Fact FACTSCORE, and FAVA FACTSCORE. The number of correct and erroneous facts is also reported for the three FACTSCORE metrics. Additional details on the preference data used are referenced.
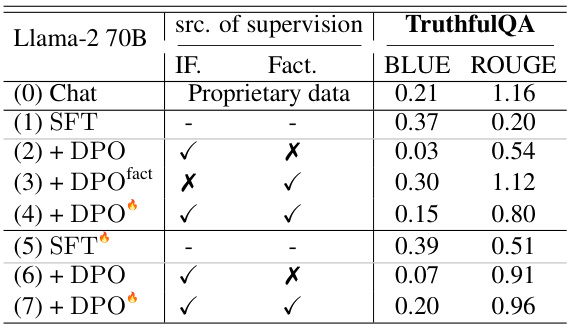
This table presents the results of the TruthfulQA evaluation for various models. It compares the performance of different model variants on the TruthfulQA benchmark, focusing on the BLEU and ROUGE scores, which are common metrics for evaluating the quality of generated text. The models compared include Llama-2 7B Chat, different SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants, with and without factuality-aware training. This allows assessing the impact of factuality-aware alignment on the truthfulness of the generated responses.
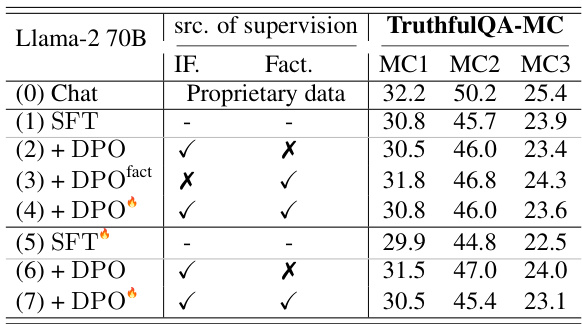
This table presents the results of experiments using direct preference optimization (DPO) for fine-tuning language models. It compares different DPO training methods, focusing on instruction following and factuality, to evaluate the effectiveness of factuality-aware alignment. The table includes the results for several metrics, such as the win rate on Alpaca Eval and FACTSCORE (FS) across different datasets. The various rows show results for different combinations of instruction-following data and factuality preference data, allowing for analysis of how each factor contributes to the overall performance of the model.
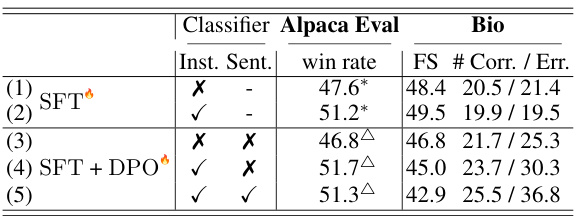
This table presents the ablation study results on the impact of fact-based instruction and sentence classification. Rows 1 and 2 compare the performance of SFT models with and without fact-based instruction classification, showing that the latter leads to better instruction-following and factuality scores. Rows 3 and 4 compare the effects of adding factuality classification in the DPO stage, with and without instruction-level classification, showing that the combination of both classifications leads to slight improvements in both factuality and instruction following scores. Overall, the table demonstrates the importance of correctly identifying fact-based instructions in factual alignment.
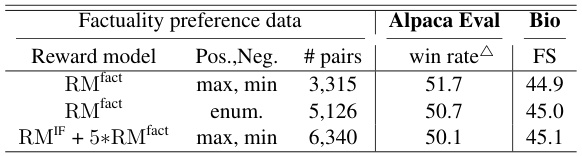
This ablation study compares three different methods for creating factuality preference data for the factuality-aware DPO. The first method selects the responses with the maximum and minimum factuality rewards as positive and negative samples, respectively. The second method enumerates all possible response pairs and selects the pair with the highest and lowest factuality rewards. The third method uses a weighted combination of instruction-following and factuality rewards to select pairs. The table shows the performance of each method on Alpaca Eval (win rate) and Bio (FACTSCORE).
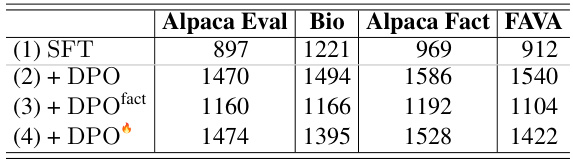
This table presents the average length of model responses generated by different models across four datasets: Alpaca Eval, Bio, Alpaca Fact, and FAVA. The models compared include the baseline SFT model and three DPO variants: a standard DPO model, a DPO model focusing solely on factuality (DPOfact), and the full factuality-aware DPO model. The table shows how different alignment strategies impact the length of generated responses, illustrating a trade-off between instruction-following capability (encouraging longer responses) and factuality (potentially leading to shorter responses).

This table compares the performance of different fine-tuned language models on two standard benchmarks: MMLU and GSM8K. The models are compared based on their accuracy. Model (1) is the baseline model, while Model (2) incorporates the factuality-aware approach proposed in the paper. The results show a slight decrease in accuracy when the factuality-aware approach is added, suggesting potential tradeoffs between instruction following and factuality.
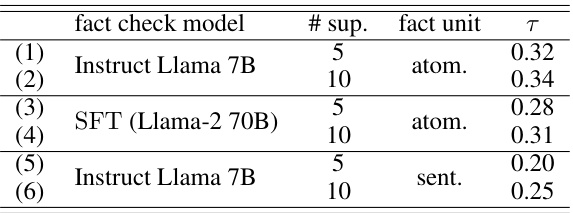
This table presents the results of an ablation study comparing different factuality reward models. The study evaluates the correlation between human annotations of factuality and the predictions of various models. The models differ in the underlying fact-checking method (Instruct Llama 7B vs. SFT (Llama-2 70B)), the number of supporting facts used, and whether the facts are atomic or sentence-level. The results show that Instruct Llama 7B with 10 atomic support facts achieves the highest correlation with human annotations.

This table presents the number of instructions and preference pairs used for training different model variants. The variants are distinguished by whether they used instruction-following data only, factuality data only, or a combination of both. The number of fact-based instructions is also shown, indicating which instructions were used to train the factuality-aware aspect of the models. The table is crucial for understanding the differences in training data used and subsequently the variations in model performance across the different experimental settings reported in the paper.

This table presents the experimental results of supervised fine-tuning on the Open Assistant dataset. It compares different variations of the supervised fine-tuning (SFT) method, including a baseline using a pre-trained Llama 2 70B model with 5-shot demonstrations (PT), a standard SFT approach, and a variation focusing solely on factuality (SFTfact). The results are evaluated across four metrics: win rate on Alpaca Eval, FACTSCORE (FS) and number of correct/erroneous facts on three datasets: Biography, Alpaca Fact, and FAVA. The table helps to show how focusing specifically on factuality affects instruction-following capabilities and the overall factual accuracy of the generated text.
This table presents the experimental results of supervised fine-tuning on the Open Assistant dataset. It compares the performance of different models, including a pre-trained Llama 2 70B model (PT), a standard supervised fine-tuned model (SFT), and a factuality-focused variant (SFTfact). The evaluation metrics include the win rate on Alpaca Eval, the FACTSCORE (FS) and the number of correct and erroneous facts on three datasets: Biography, Alpaca Fact, and FAVA. The table helps to analyze the impact of different fine-tuning approaches on both instruction following and factuality.

This table presents the experimental results obtained from supervised fine-tuning on the Open Assistant dataset. It compares several different models, including a pre-trained Llama 2 70B model (PT) and different versions of the supervised fine-tuning model (SFT). A key comparison is made between SFT and SFTfact, which specifically focuses on factuality optimization. The table shows the results for various metrics, including the win rate on Alpaca Eval (a measure of instruction-following capability), and FACTSCORE (FS) on Biography, Alpaca Fact, and FAVA datasets (all evaluating factuality). The results highlight the impact of different fine-tuning strategies and data sources on both instruction-following ability and factual accuracy.
Full paper#