↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional logic synthesis relies on heuristics, struggles with large circuits and optimization. Recent attempts using Differentiable Neural Architecture Search (DNAS) show promise but suffer from issues like overfitting, structural bias, and imbalanced learning, leading to inaccurate and inefficient circuit generation. These problems result in a high sensitivity to hyperparameters and an inability to scale to large, complex circuits.
The proposed T-Net framework addresses these challenges. It uses a multi-label transformation of training data, a novel triangle-shaped network architecture aligned with circuit structure, and a regularized training loss to prevent overfitting and ensure efficient learning. An evolutionary algorithm assisted by reinforcement learning further optimizes the generated circuits. Extensive experiments demonstrate T-Net’s superiority in accuracy, scalability, and performance over existing DNAS methods and traditional techniques, achieving state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in logic synthesis and machine learning. It tackles the scalability and accuracy challenges of existing neural methods, offering a novel and efficient approach for generating large-scale, accurate logic circuits. Its findings open new avenues for research in neural circuit design, optimization, and the integration of machine learning into EDA workflows. The improved accuracy and efficiency could significantly impact the IC design industry, leading to faster development cycles and more energy-efficient chips.
Visual Insights#

This figure demonstrates the limitations of using Differentiable Neural Architecture Search (DNAS) for generating circuits. Subfigure (a) shows that DNAS struggles to generate accurate circuits, especially as the circuit size increases. (b) illustrates that DNAS only utilizes shallow layers of the network, while the proposed method utilizes deeper layers. (c) visualizes the DNAS network, highlighting the underutilization of deeper layers. Finally, (d) shows that the structure of circuits generated by Sum of Products (SOP) exhibits a triangular pattern, unlike the common rectangular shape used by existing DNAS methods.
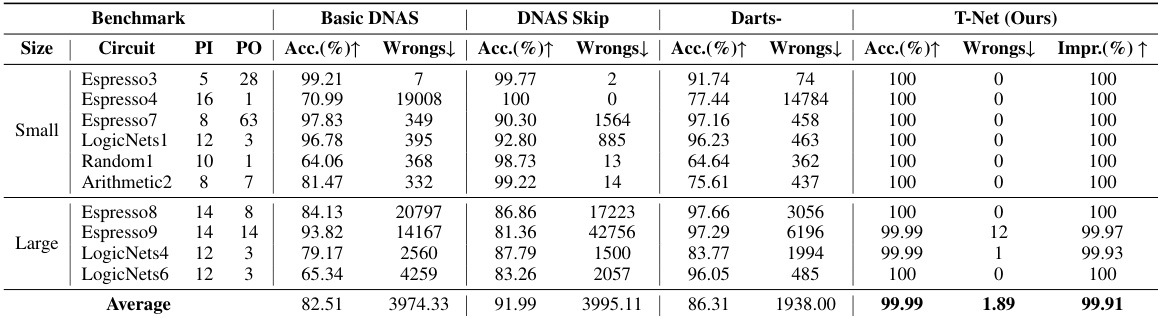
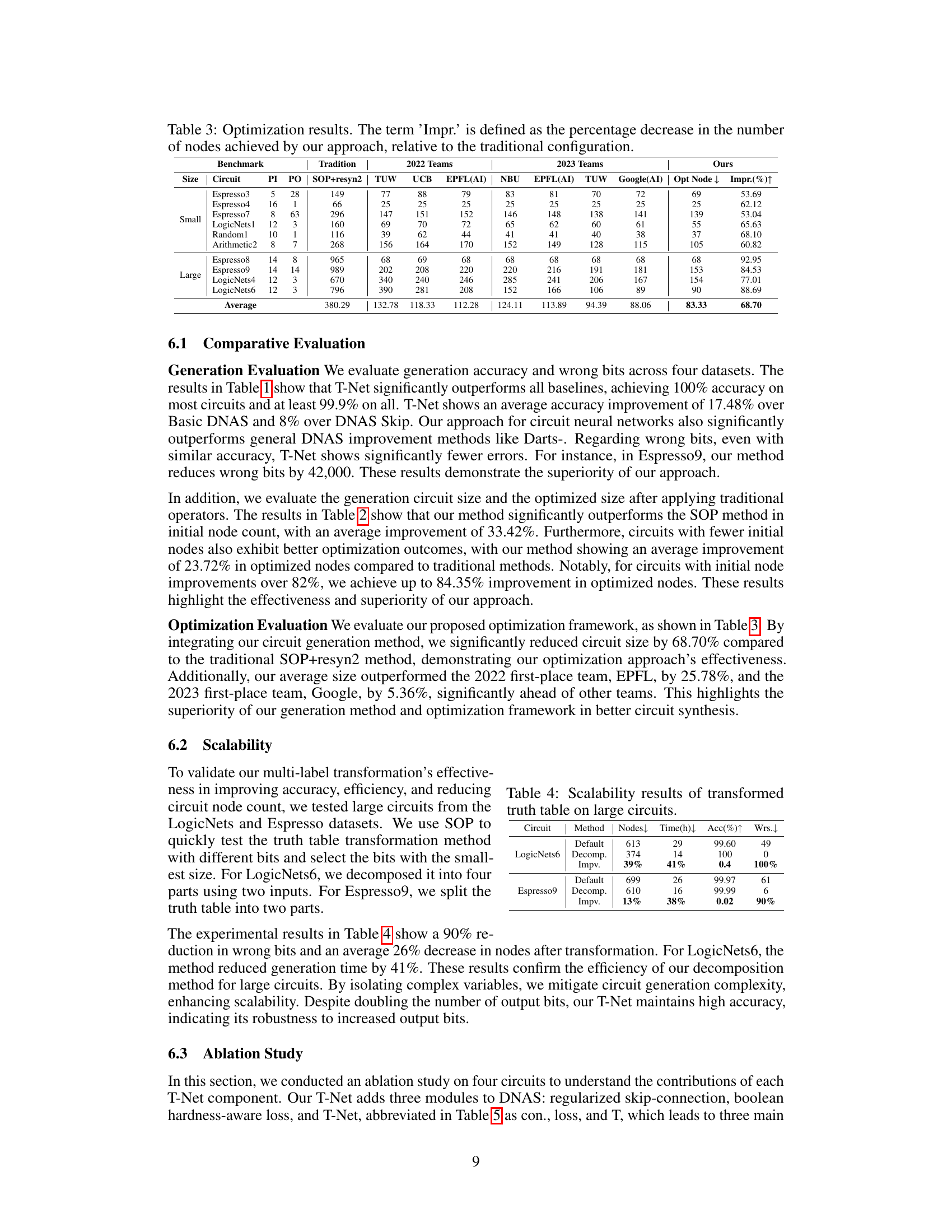
This table presents the accuracy of circuit generation using different methods: Basic DNAS, DNAS Skip, Darts-, and the proposed T-Net. The results are shown for several benchmark circuits, categorized into ‘Small’ and ‘Large’ based on their size. Accuracy is measured as the percentage of correctly predicted output bits. The ‘Wrongs’ column indicates the number of incorrectly predicted bits. ‘Impr.’ represents the improvement in accuracy (reduction in wrong bits) achieved by T-Net compared to the other methods.
In-depth insights#
DNAS Rethinking#
Rethinking DNAS for logic synthesis reveals crucial limitations. Existing methods struggle with precise circuit generation, especially for larger circuits, and show high sensitivity to hyperparameters. This stems from three key issues: overreliance on skip connections, which limits network efficiency; a structure mismatch between the network and circuit architectures, leading to inefficient search; and imbalanced learning, where some input-output examples are significantly harder to learn than others. Addressing these issues requires novel approaches that incorporate circuit structural biases, regularization techniques to curb excessive skip connections, and strategies to mitigate imbalanced learning. A focus on scalable and accurate circuit generation is essential for future advancements in this field.
T-Net Framework#
The T-Net framework, a novel approach for logic synthesis, tackles the limitations of existing Differentiable Neural Architecture Search (DNAS) methods. Its core innovation lies in a regularized triangle-shaped network architecture designed to align with the inherent structure of logic circuits, addressing the inefficiency of DNAS’s exploration of the search space. This is complemented by a multi-label transformation of training data which enhances scalability and reduces learning difficulty. A regularized training loss function further refines the process, mitigating overfitting to skip connections and addressing imbalanced learning. The entire framework promotes completely accurate and scalable circuit generation, surpassing the performance of traditional methods and existing DNAS techniques, as demonstrated through extensive experiments.
Circuit Optimization#
The paper explores circuit optimization using an evolutionary algorithm guided by reinforcement learning, a significant departure from traditional methods. The core innovation is combining a novel triangle-shaped circuit network architecture with a reinforcement learning agent to efficiently explore the vast search space of circuit transformations. This addresses limitations of traditional DNAS approaches which suffer from issues like overfitting, structural bias, and imbalanced learning. The evolutionary algorithm further refines the circuits generated, outperforming state-of-the-art results. Key to the optimization is the multi-label transformation of training data, enhancing scalability and efficiency. This comprehensive approach yields significant improvements in circuit size and accuracy, showcasing the potential of combining neural architecture search and evolutionary algorithms for next-generation logic synthesis.
Scalability & Limits#
A crucial aspect of any machine learning model, especially one applied to complex tasks like logic synthesis, is scalability. This paper’s proposed T-Net framework addresses scalability challenges by employing a multi-label transformation of training data and a triangle-shaped network architecture. The multi-label approach reduces the exponential growth of truth tables, allowing the model to handle larger circuits. The triangle-shaped architecture naturally aligns with the inherent structure of logic circuits, leading to more efficient search. However, even with these improvements, limitations remain. The methodology’s reliance on GPU resources restricts its immediate applicability in CPU-bound environments, highlighting a practical scalability limit. Further research might explore alternative training strategies or architectures to enhance efficiency on less powerful hardware. The paper also acknowledges that the methodology’s performance might vary depending on hyperparameters, suggesting a need for more robust optimization techniques and more extensive hyperparameter tuning to ensure reliable scalability across various circuit sizes and types.
Future of Logic Synthesis#
The future of logic synthesis is inextricably linked to advancements in machine learning (ML) and artificial intelligence (AI). Traditional methods struggle with the exponential complexity of modern integrated circuits, requiring innovative approaches. ML offers a powerful avenue for automating and optimizing the design process, potentially enabling the synthesis of circuits with billions of transistors that would be impossible to design manually. Differentiable neural architecture search (DNAS) and other neural techniques hold significant promise for generating optimized circuits directly from specifications, significantly improving both accuracy and efficiency. However, challenges remain, such as handling the variability and complexity of different circuit designs and mitigating the potential for overfitting. Addressing these will require further research into robust and scalable neural network architectures and training methods, alongside continued integration of evolutionary algorithms and reinforcement learning techniques for optimization. The ultimate goal is a fully automated, AI-driven logic synthesis workflow that significantly reduces design time and cost, leading to faster innovation in chip design and manufacturing.
More visual insights#
More on figures
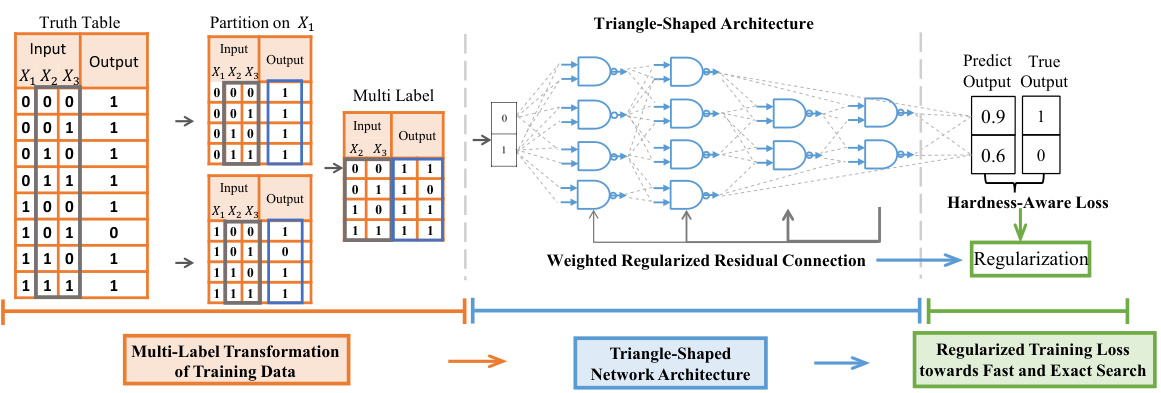
This figure illustrates the overall framework of the proposed T-Net model for logic synthesis. It highlights three key modules: (1) A multi-label transformation of training data that partitions the input-output examples and merges them into multi-label data to reduce the complexity of the learning process. (2) A triangle-shaped network architecture that aligns with the structural bias in logic circuits, resulting in an efficient search space for circuit generation. (3) A regularized training loss function to avoid overfitting and ensure accurate circuit generation. The figure visually shows how the input truth table is transformed using multi-label transformation, feeding into the triangle-shaped architecture, and finally producing predicted output with regularized training loss.

This figure demonstrates the limitations of Differentiable Neural Architecture Search (DNAS) for neural circuit generation. Subfigure (a) shows the low accuracy of DNAS in generating circuits, especially larger ones. Subfigure (b) illustrates that DNAS tends to use only shallow layers of the network, while the proposed method utilizes deeper layers. Subfigure (c) visualizes a converged DNAS network showing that many nodes are unused due to skip connections. Subfigure (d) shows the triangular structure observed in circuits generated by the Sum of Products (SOP) method, contrasting with the structure learned by DNAS.

This figure visualizes the exploration degree of each network layer after the DNAS model converges. The height of each empty bar represents the total number of nodes at each layer. The height of the filled bar in each layer shows the number of nodes that were used during the training process (explored nodes). The results demonstrate a clear bias towards exploring shallow layers, highlighting the problem of underutilization of deeper layers by DNAS methods.
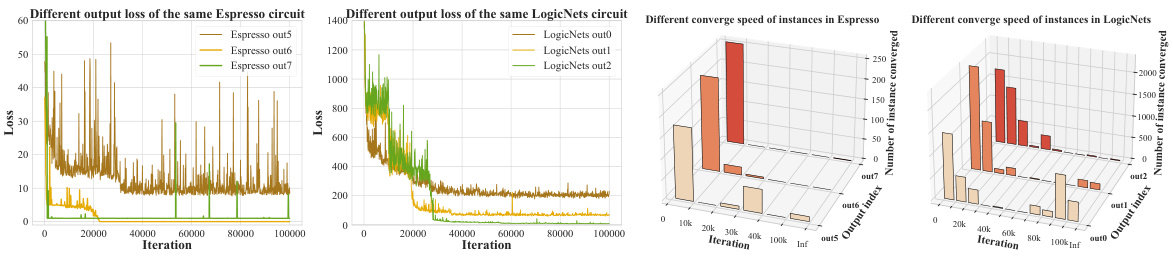
This figure demonstrates the challenges in training DNAS for circuit generation. Subfigures (a) and (b) show that the convergence speed of the loss function varies significantly among different output bits within the same circuit. Subfigures (c) and (d) illustrate that the convergence speed also varies substantially across different input samples for the same output bit. This highlights the imbalance in learning difficulty, making it challenging to train the model effectively.

This figure illustrates the optimization framework used in the paper. It uses an evolutionary algorithm combined with reinforcement learning to optimize circuit designs. The RL agent learns to find optimal sequences of logic synthesis operators to minimize circuit size. The process involves generating an initial population of circuits, which are then iteratively optimized using the RL agent. A key feature is the agent restart technique, which reinitializes the agent parameters periodically to help escape local optima and continue exploring the search space. The resulting optimized circuit is then used as input for the next generation in the evolutionary process. The diagram shows the flow of data between the components, including truth tables, circuits, RL agent, and environment.
More on tables
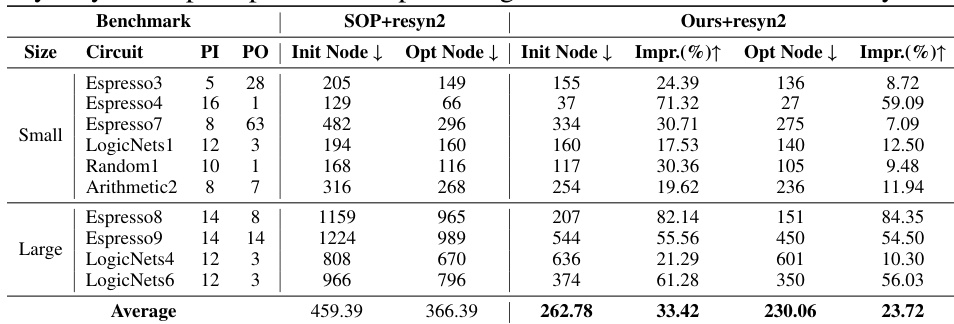
This table compares the initial and optimized node counts of circuits generated using SOP and the proposed T-Net method. The ‘Init Node’ column shows the number of nodes in the circuit generated by either SOP or T-Net before optimization. The ‘Opt Node’ column shows the node count after optimization using the resyn2 tool. The ‘Impr.’ column indicates the percentage improvement in node count achieved by the T-Net method compared to SOP. The table is divided into ‘Small’ and ‘Large’ circuit categories based on the number of nodes.
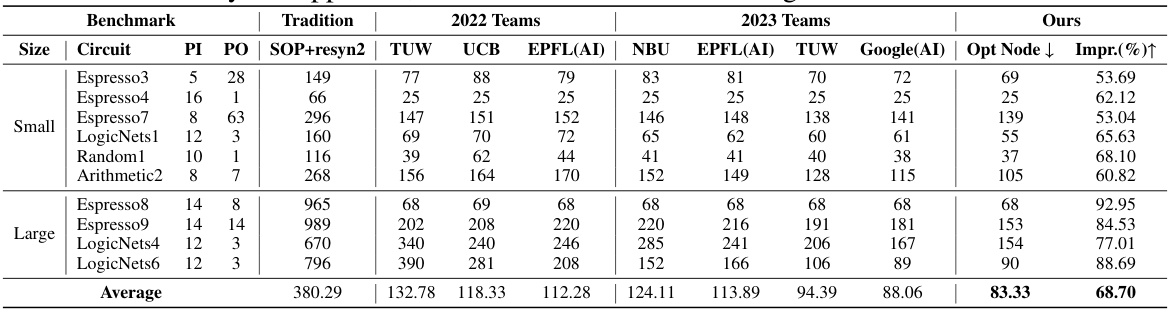
This table presents a comparison of the number of nodes in circuits optimized using different methods. The ‘Tradition’ column shows the results using a traditional Sum-of-Products (SOP) method with the resyn2 operator. The columns labeled ‘2022 Teams’ and ‘2023 Teams’ represent the results from the winning teams in the IWLS 2022 and 2023 competitions, respectively. Finally, the ‘Ours’ column shows the results obtained using the authors’ proposed method. The ‘Impr.’ column indicates the percentage improvement in node reduction achieved by the authors’ approach compared to the traditional method.
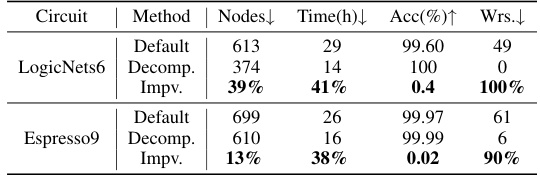
This table presents the scalability results of the proposed multi-label transformation method on two large circuits: LogicNets6 and Espresso9. It shows the initial node count, the node count after decomposition, the percentage improvement in node count, the generation time before and after decomposition, the percentage improvement in generation time, the accuracy before and after decomposition, and the percentage improvement in the number of wrong bits. The results demonstrate that the multi-label transformation method significantly improves scalability by reducing both circuit size and generation time while maintaining high accuracy.

This table presents the ablation study results, comparing the performance of different configurations of the proposed T-Net against a baseline. It shows the impact of adding skip connection regularization (+con.), boolean hardness-aware loss (+con.+loss), and the triangle-shaped network architecture (+con.+loss+T). The results are evaluated on four different circuit benchmarks, demonstrating the effectiveness of each component in improving accuracy and reducing the number of nodes.

This table presents the network sizes used for the DNAS and T-Net approaches in the motivation experiments. It compares the number of nodes, levels, width, and depth for the networks used to generate two example circuits (Espresso7 and LogicNets1). This provides context for the differences in the efficiency and scalability of the methods discussed in Section 4. The table helps to explain the observed challenges with DNAS concerning circuit accuracy and the curse of skip connections.

This table presents the results of the circuit generation accuracy experiments comparing the proposed T-Net method against three baseline DNAS methods (Basic DNAS, DNAS Skip, Darts-) and a traditional SOP method. The table shows the accuracy (percentage of correctly predicted outputs), the number of wrong bits, and the improvement in wrong bits achieved by T-Net compared to the baselines for several circuits of different sizes (small and large). The results demonstrate the superior performance of the proposed T-Net.
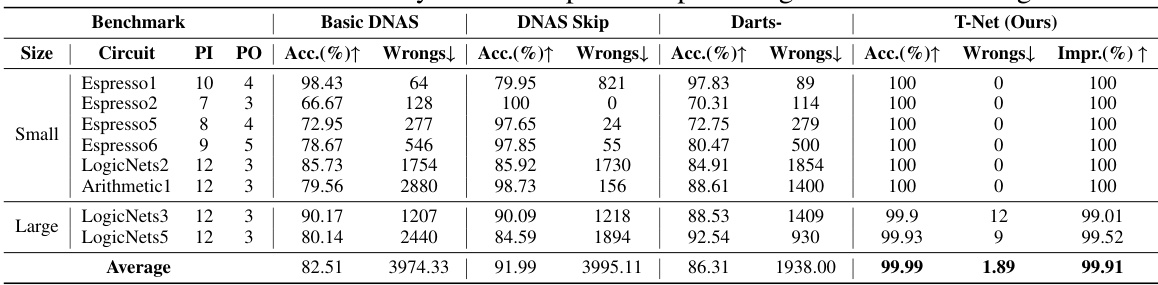
This table presents the accuracy of circuit generation using four different methods: Basic DNAS, DNAS Skip, Darts-, and T-Net (the authors’ method). For several benchmark circuits of varying sizes, the table shows the accuracy (Acc. (%)), number of wrong bits (Wrongs), and the improvement in wrong bits compared to the Basic DNAS method (Impr. (%)) for each method. The results demonstrate the superior performance of T-Net in generating highly accurate circuits, with significantly fewer errors compared to other methods.
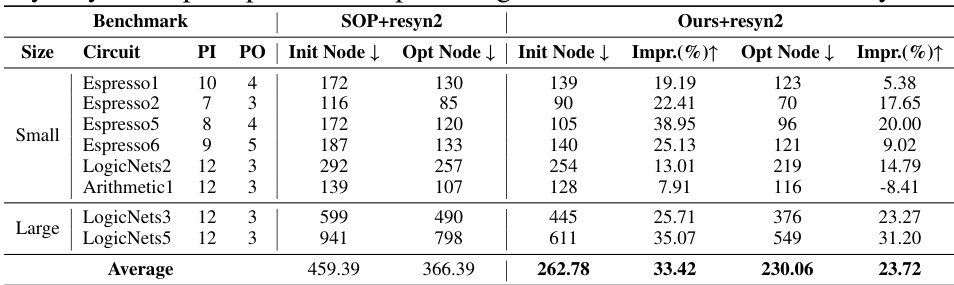
This table presents a comparison of the initial and optimized circuit sizes generated by the traditional Sum-of-Products (SOP) method and the proposed T-Net method. For each circuit benchmark, it shows the initial number of nodes generated by SOP and T-Net. Then, the table shows the optimized number of nodes obtained after applying the resyn2 optimization tool to both the SOP-generated and T-Net-generated circuits. Finally, the table highlights the improvement in node count achieved by T-Net compared to SOP, expressed as a percentage decrease in the number of nodes.
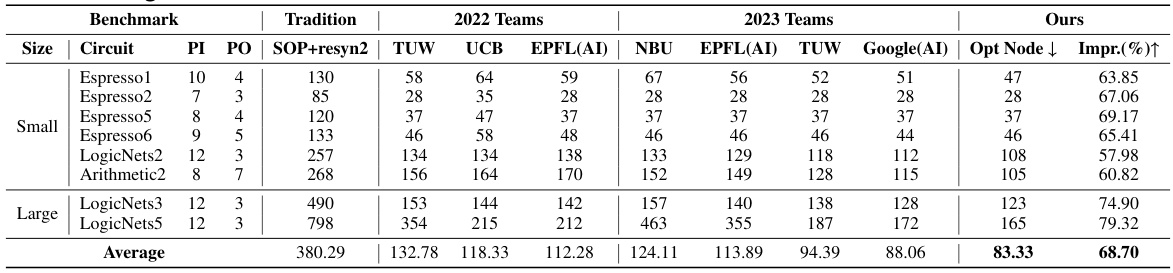
This table compares the number of nodes in circuits optimized using different methods. The ‘Tradition’ column shows results from a traditional method (SOP+resyn2). The ‘2022 Teams’ and ‘2023 Teams’ columns represent results from winning teams in the IWLS 2022 and 2023 competitions, respectively. The ‘Ours’ column shows the results obtained using the authors’ proposed method (T-Net). The ‘Impr. (%)↑’ column indicates the percentage improvement in node reduction achieved by the authors’ approach compared to the traditional method.

This table presents the results of a sensitivity analysis performed on four different circuits using three distinct random initializations. It demonstrates the robustness of the T-Net approach by showing that it consistently achieves 100% accuracy across various random initializations, highlighting its stability in network depth and ability to avoid getting stuck in local optima.

This table presents the results of a sensitivity analysis conducted to evaluate the robustness of the proposed T-Net model to variations in the initial network architecture. Specifically, it investigates how changes in the width and depth of the network’s two blocks (upper and lower) affect the model’s accuracy in generating circuits. The table showcases the consistent accuracy (100%) achieved across various initial network configurations, demonstrating the model’s resilience to variations in initial architecture.
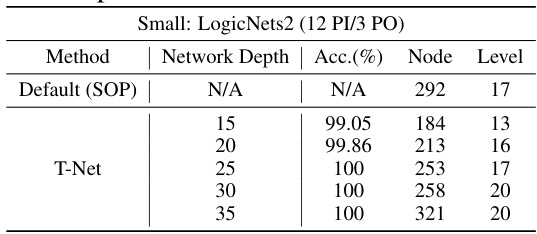
This table presents the results of a sensitivity analysis conducted on the LogicNets2 circuit to determine the optimal network depth for accurate circuit generation. The analysis varies the network depth while keeping other parameters consistent. It shows that shallow networks lack sufficient capacity to generate circuits exactly, while excessively deep networks result in redundancy. The optimal depth appears to be around 25, balancing accuracy and efficiency.

This table compares the performance of a rectangular network and the proposed T-Net in generating circuits with a large number of primary outputs (POs). It demonstrates that the T-Net, with its triangular structure, can effectively handle circuits with many POs, achieving 100% accuracy with fewer nodes than the rectangular network.
Full paper#