↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) present a significant challenge to AI safety researchers due to the difficulty in comprehensively evaluating their capabilities. Current prompting methods often fail to uncover hidden, potentially harmful capabilities. This paper explores a new paradigm that tackles these issues by using fine-tuning based elicitation techniques on what the authors call ‘password-locked models.’ These models are specifically trained to exhibit certain capabilities only when a password is included in the prompt, mimicking a weaker model otherwise. This innovative approach offers a controlled setting to meticulously assess the efficacy of various elicitation methods.
The study finds that fine-tuning, especially when provided with a few high-quality demonstrations, effectively recovers the hidden capabilities of password-locked models. Furthermore, the research demonstrates that fine-tuning can elicit even capabilities locked with different passwords or even other similar hidden capabilities. The study shows that reinforcement learning methods can often succeed even with limited high-quality demonstrations. Overall, this research highlights the potential of fine-tuning as a powerful capability elicitation method, offering a valuable contribution to the development of more robust and reliable LLM safety evaluations.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI safety researchers as it introduces a novel method for evaluating and improving LLM capability elicitation techniques. The findings challenge current assumptions about the reliability of prompting-based methods and highlight the effectiveness of fine-tuning, especially with high-quality demonstrations. This opens avenues for developing more robust and reliable safety assessments for LLMs, ultimately contributing to safer AI systems. This is highly relevant given growing concerns about hidden LLM capabilities and the need for improved safety evaluation protocols.
Visual Insights#
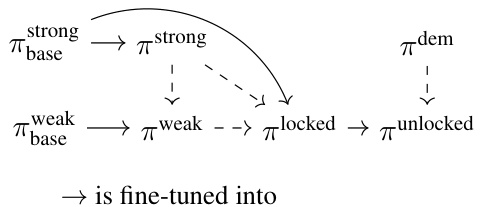
This figure illustrates the process of creating and evaluating password-locked models. It begins with a base model, which is fine-tuned into two separate models: a strong model (πstrong) and a weak model (πweak). The strong model represents the desired high-performing model with hidden capabilities, while the weak model is a lower-performing model used to mask the true capabilities of the strong model. The weak model and the strong model are then used to train a ‘password-locked’ model (πlocked), which behaves like the weak model unless a password is present in the input, in which case it exhibits the capabilities of the strong model. Finally, different elicitation methods are used to try to ‘unlock’ the password-locked model’s hidden capabilities (πunlocked) without using the password, allowing for the evaluation of the effectiveness of the methods.
This table summarizes the specific large language models (LLMs) used as the base models (strong and weak) for each of the five tasks, as well as the high-quality demonstrations used for supervised fine-tuning (SFT) in the elicitation experiments. It shows the choices made for each task and highlights the sensitivity analysis performed on these choices.
In-depth insights#
Hidden Capabilities#
The concept of “hidden capabilities” in large language models (LLMs) is crucial. These are capabilities that exist within the model but are not readily apparent through standard prompting techniques. The paper explores this by creating “password-locked models,” which are fine-tuned to only exhibit specific capabilities when a particular password is included in the prompt. This setup allows researchers to test different elicitation methods, including fine-tuning and reinforcement learning, to see if they can unlock these hidden capabilities without knowing the password. The key finding is that fine-tuning, especially with high-quality demonstrations, proves effective at eliciting these hidden capabilities. This highlights the potential for fine-tuning as a robust method for capability elicitation in LLMs. However, the study also reveals limitations, particularly when high-quality demonstrations are scarce or when only low-quality demonstrations are available. This underscores the need for advanced methods like reinforcement learning when dealing with more challenging situations. The implications are significant for both safety and security assessments of LLMs, emphasizing the need for comprehensive and robust methods to uncover potential hidden risks.
Elicitation Methods#
The research paper explores methods for eliciting capabilities from large language models (LLMs), focusing on techniques that move beyond simple prompting. Fine-tuning, where the LLM is retrained on a specific task, emerges as a powerful elicitation method. The study introduces “password-locked models,” where capabilities are deliberately hidden unless a specific prompt (password) is used, to rigorously evaluate elicitation effectiveness. The results demonstrate that fine-tuning, even with limited high-quality demonstrations, can effectively unlock these hidden capabilities. Surprisingly, fine-tuning on one locked capability can also reveal others secured by the same or different passwords. Furthermore, reinforcement learning (RL) methods prove effective at eliciting capabilities even when only feedback on response quality is available, not demonstrations. The findings highlight the sample efficiency of fine-tuning, especially when high-quality demonstrations exist, suggesting its potential as a robust capability elicitation technique.
Password-Locked Models#
The concept of “Password-Locked Models” presents a novel approach to evaluating the efficacy of LLM capability elicitation techniques. By deliberately hiding certain capabilities behind a password, researchers create a controlled environment to test different elicitation methods. This setup allows for a more rigorous evaluation than relying on natural examples, where hidden capabilities may be difficult to identify and quantify. Fine-tuning with high-quality demonstrations proves very efficient, often unlocking capabilities with surprisingly few examples, even those secured with different passwords. However, the study also highlights the limitations of fine-tuning when only low-quality or no demonstrations are available. This reveals important considerations for practical LLM safety evaluations, suggesting that fine-tuning-based approaches, while effective under ideal conditions, may not always be reliable in real-world scenarios where high-quality data is scarce or inaccessible.
Sample Efficiency#
The study reveals high sample efficiency in fine-tuning for capabilities elicitation, especially using high-quality demonstrations. A single demonstration often suffices for tasks involving long text generation, while a few hundred may be needed for others. This efficiency, however, is highly dependent on demonstration quality. Low-quality or poorly imitated demonstrations hinder performance, regardless of quantity. The findings suggest that fine-tuning is a powerful tool for uncovering hidden capabilities but highlight its unreliability with limited high-quality data, a scenario that mirrors real-world challenges in evaluating complex LLMs. Generalization across different problem subsets is also observed, even when demonstrations are limited to a specific subset. This points towards a robust and potentially efficient approach to uncovering hidden capabilities. The results, therefore, offer important implications for the design and evaluation of safe and reliable LLMs.
Future Directions#
Future research could explore more sophisticated methods for hiding model capabilities beyond simple password-locking, perhaps by incorporating contextual triggers or dynamically adjusting model behavior based on nuanced input analysis. It would be valuable to investigate the robustness of fine-tuning-based elicitation against various obfuscation techniques and explore the interaction between different types of capability hiding and the effectiveness of various elicitation strategies. Further research should also focus on developing more robust and reliable methods for evaluating model capabilities, especially in situations where high-quality demonstrations are scarce or unavailable, and investigate how to reliably estimate the efficacy of elicitation techniques in the presence of incomplete or misleading data. Finally, it’s crucial to consider the broader societal implications of research in this area, particularly concerning the potential for malicious use of advanced capabilities hiding and elicitation methods, focusing on ethical implications and risk mitigation strategies.
More visual insights#
More on figures
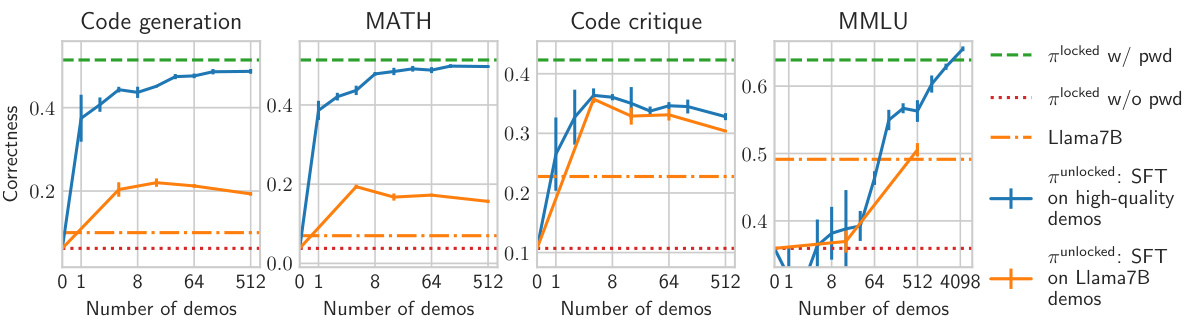
This figure displays the results of fine-tuning password-locked models on different tasks using high-quality demonstrations. It shows the relationship between the number of demonstrations used and the resulting model correctness, comparing performance with and without the password, and against the performance of the Llama7B model. The graph illustrates that high-quality demonstrations are very sample efficient, especially for long-text generation tasks, and that fine-tuning on fewer demonstrations generalizes well even across different subsets of problems. However, it also highlights cases where sample efficiency is lower or when using lower quality demonstrations, indicating that fine-tuning-based elicitation is not always reliable in all scenarios.

This figure shows the generalization ability of fine-tuning on a password-locked model. It demonstrates that fine-tuning on a limited number of high-quality demonstrations from a single domain generalizes well to other domains. The results are shown for scenarios with one password for all domains and one password per domain, highlighting the robustness of the findings. The y-axis represents correctness, and the x-axis shows the different domains.
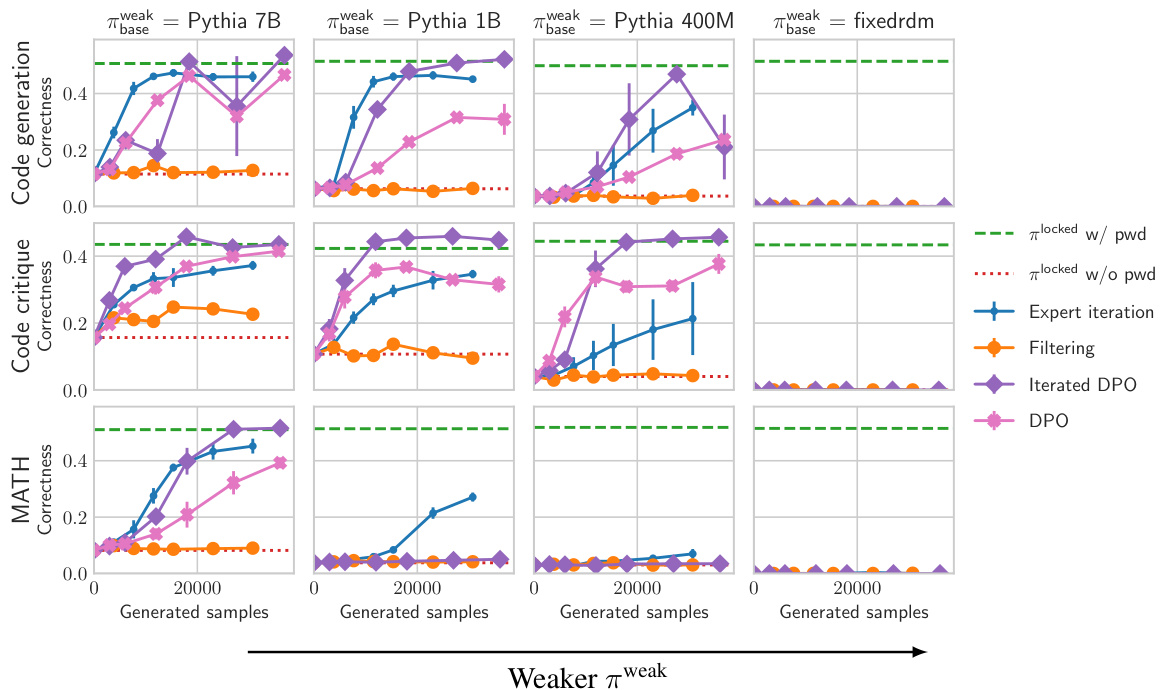
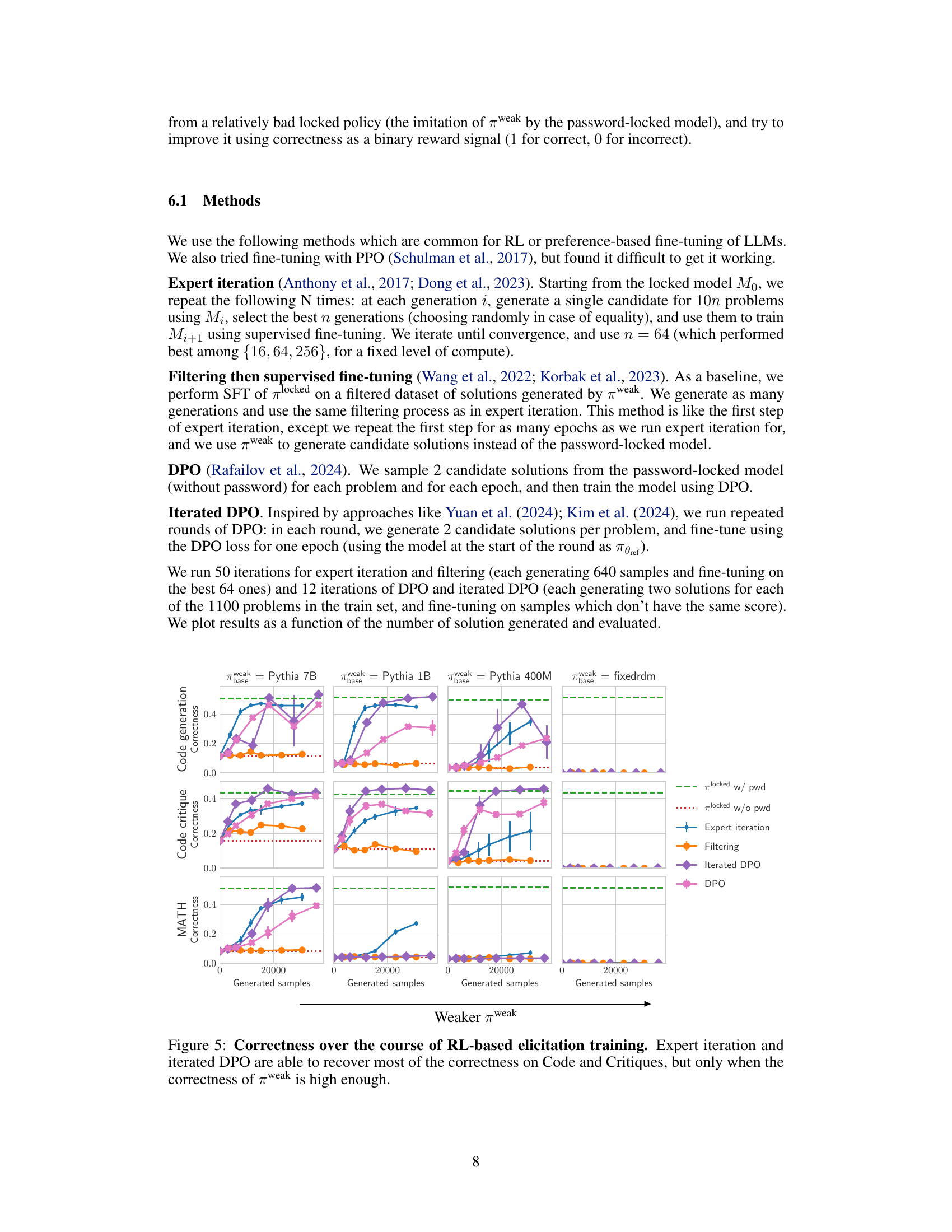
This figure shows the results of reinforcement learning (RL) experiments for eliciting hidden capabilities in password-locked language models. Four different RL methods (Expert Iteration, Filtering, Iterated DPO, and DPO) were used, and their performance is plotted against the number of generated samples. The results are shown separately for three different tasks: code generation, code critique, and MATH. Importantly, the success of the RL methods strongly depends on the quality of the initial weak policy (πweak). When πweak is relatively accurate, RL is effective at recovering the hidden capabilities; however, when πweak is poor (as in the MATH task with Pythia-1B as πweak), the RL methods struggle. This highlights the importance of having a reasonably good initial approximation to unlock a model’s hidden capabilities using RL.

This figure compares the sample efficiency of unlocking password-locked models trained using two different methods: fine-tuning from a pre-trained model (SFT) and training from scratch. The results show that models locked via fine-tuning are significantly easier to unlock than those locked from scratch, requiring fewer high-quality demonstrations to recover the hidden capabilities.

This figure displays the results of fine-tuning password-locked models on high-quality demonstrations for four different tasks: code generation, MATH, code critique, and MMLU. It shows how the number of demonstrations affects the model’s ability to recover its hidden capabilities after fine-tuning. The graph highlights the sample efficiency of the method, particularly on tasks requiring long-text generation, and demonstrates that fine-tuning on a small number of demonstrations is effective. A comparison is made between using high-quality demonstrations and demonstrations from a Llama7B model. Noteworthy is that in the code critique task, even with many high-quality demonstrations, the model does not reach the same performance as when the password is used. The graph also reveals a case where fine-tuning on Llama7B demonstrations surpasses the performance of Llama7B itself.

This figure displays the results of fine-tuning password-locked models on high-quality demonstrations. The x-axis represents the number of demonstrations used, and the y-axis shows the resulting correctness. Different colored lines represent different tasks (code generation, MATH, code critique, MMLU) and different demonstration sources (high-quality demonstrations, Llama 7B demonstrations). The figure highlights that fine-tuning with high-quality demonstrations is highly sample-efficient for most tasks, except for MMLU. It also shows that fine-tuning on demonstrations from Llama 7B, even if they are lower quality, can still improve the model’s performance beyond the original Llama 7B performance.
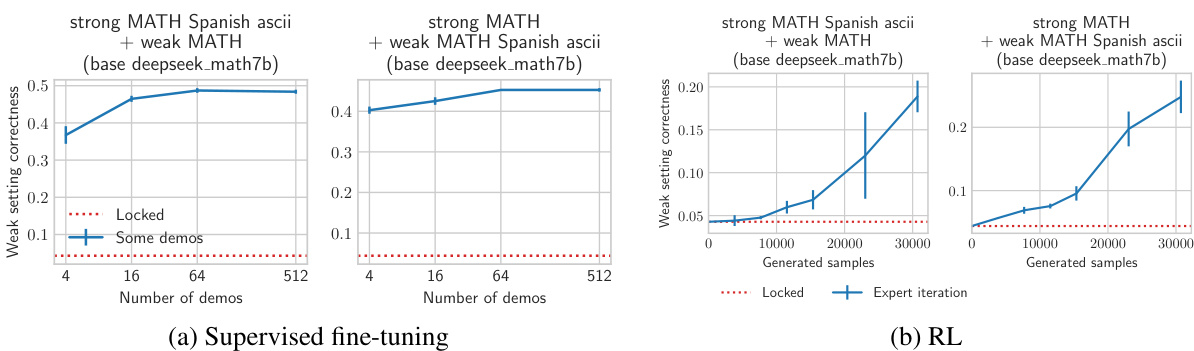
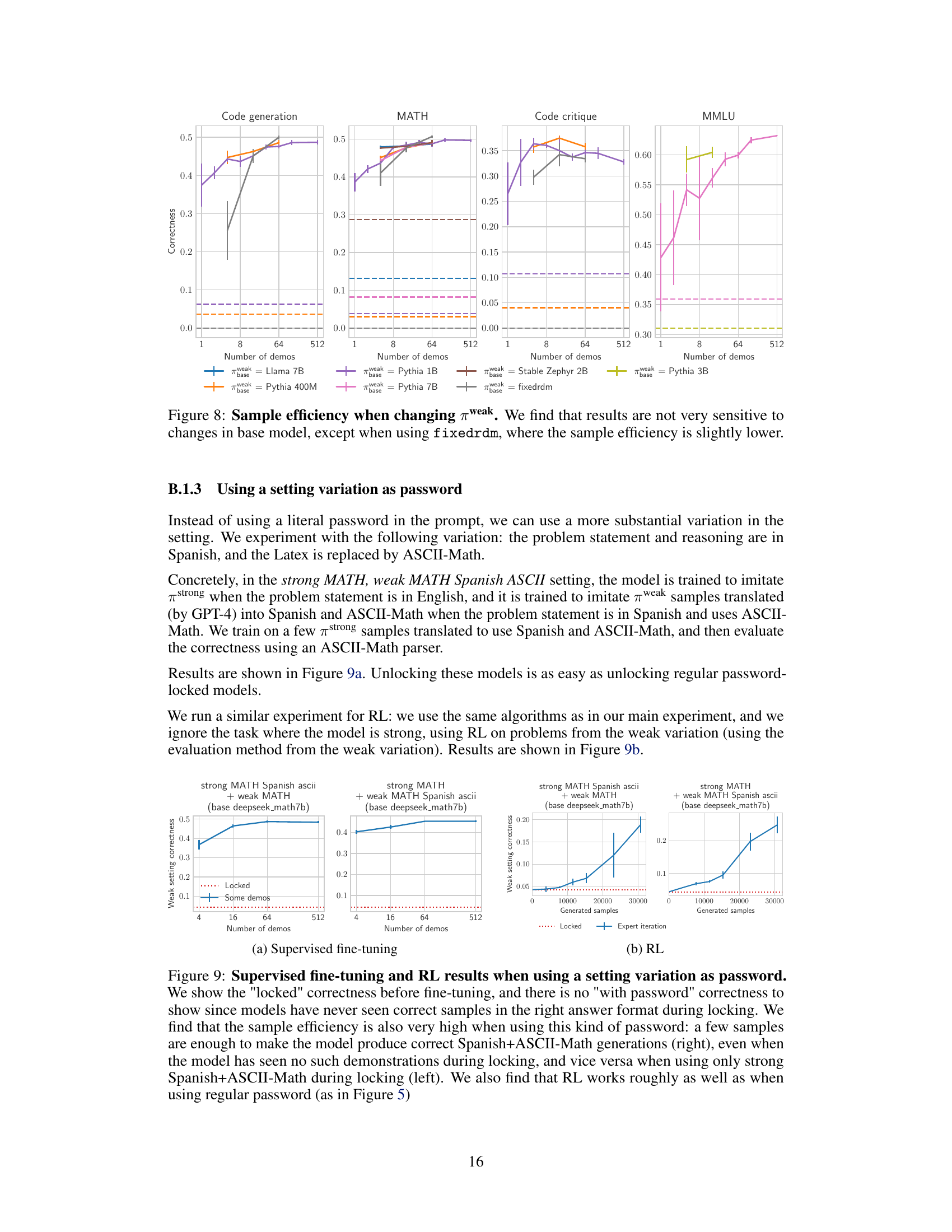
This figure shows the results of experiments using a setting variation (Spanish language and ASCII-math notation) as a password instead of a literal password. The left panels show the results of supervised fine-tuning, demonstrating high sample efficiency in unlocking the model’s capabilities even with limited demonstrations. The right panels show the results of reinforcement learning (RL), which also performs well in eliciting the hidden capabilities, further highlighting the effectiveness of both methods regardless of the password type used.
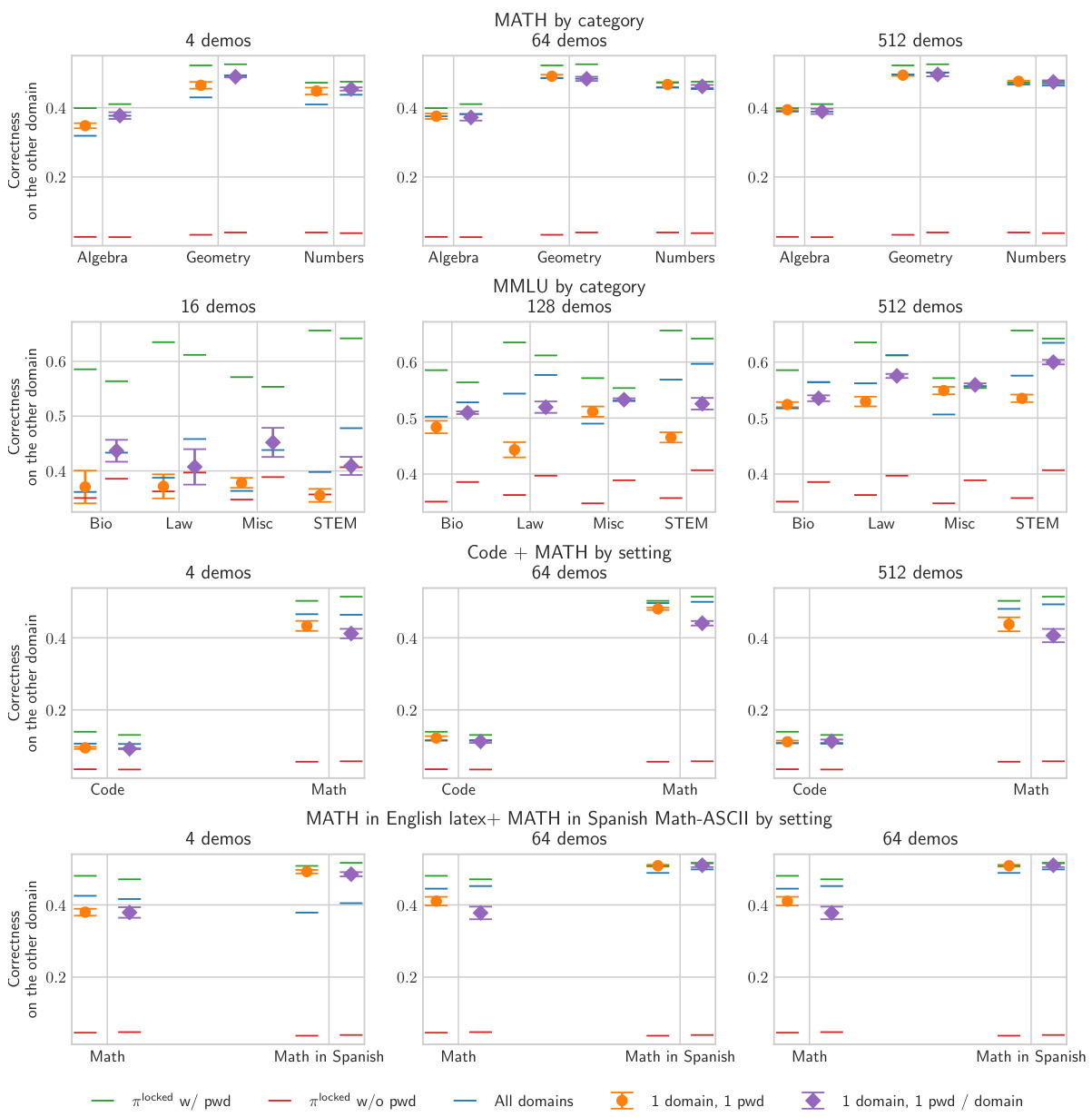
This figure shows the results of fine-tuning on high-quality demonstrations from a certain domain. The results demonstrate that fine-tuning on samples from a single domain generalizes well to other domains, even when using different passwords for each domain. This suggests that fine-tuning is a sample-efficient method for eliciting hidden capabilities.

This figure shows the results of experiments testing the generalization ability of fine-tuning on password-locked models. The models were locked with either a single password for all categories or a different password for each category. The results demonstrate high sample efficiency and strong generalization to unseen categories, even with a limited number of high-quality demonstrations. The impact of having a separate password for each domain is also evaluated.
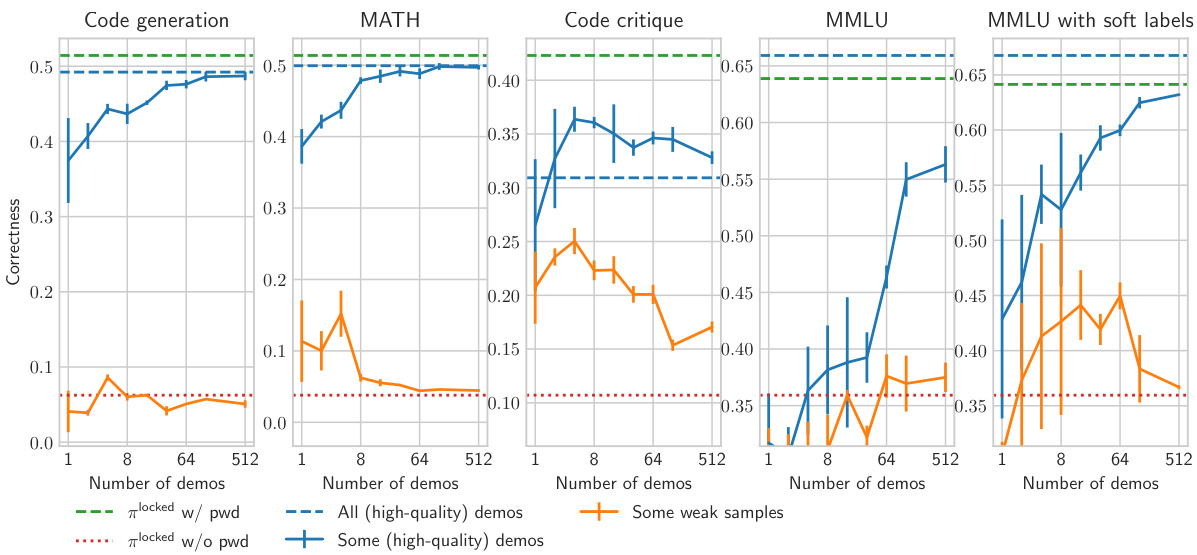
This figure shows the results of fine-tuning password-locked models on high-quality demonstrations for four different tasks: code generation, MATH, code critique, and MMLU. The x-axis represents the number of demonstrations used in fine-tuning, and the y-axis shows the model’s correctness after fine-tuning. The figure demonstrates that fine-tuning on high-quality demonstrations is very sample efficient for most tasks, with a few demonstrations often sufficient to recover most of the hidden performance. However, sample efficiency is lower when the demonstrations are of lower quality, and it is also lower for MMLU. Interestingly, fine-tuning on demonstrations from a weaker model (Llama7B) can sometimes exceed the performance of that weaker model itself.
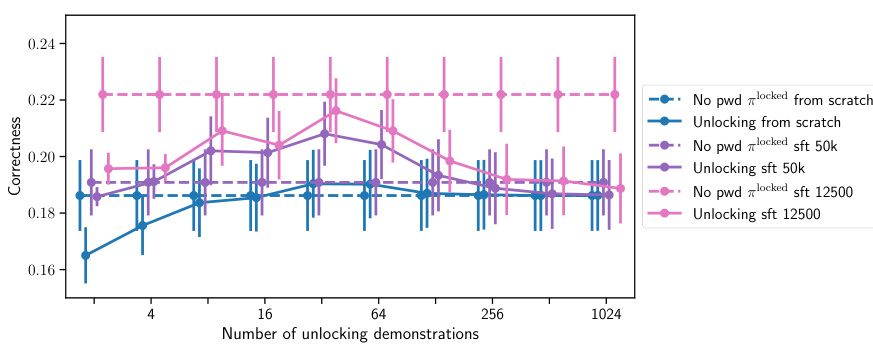
This figure compares the sample efficiency of unlocking models that were locked via fine-tuning versus those trained from scratch. The results show that models locked via supervised fine-tuning (SFT) are significantly easier to unlock than models trained from scratch to possess the same hidden capabilities. Specifically, models locked using SFT require considerably fewer unlocking demonstrations to reach a similar level of performance compared to models locked from scratch. This indicates that the method of creating the password-locked model impacts the difficulty of unlocking its hidden capabilities.

This figure presents the results of an experiment testing the effectiveness of different prompting methods on a password-locked Math task. The x-axis lists various prompting approaches, ranging from correct use of the password to variations or entirely incorrect passwords. The y-axis represents the correctness of the model’s response. The results demonstrate that only prompts closely resembling the actual password significantly improve the model’s performance, highlighting the robustness of the password-locking mechanism. The use of a few-shot prompt with the correct password resulted in substantially higher correctness than other approaches.

This figure displays the results of fine-tuning experiments on four different tasks: code generation, MATH, code critiques, and MMLU. The x-axis represents the number of high-quality demonstrations used for fine-tuning. The y-axis represents the correctness achieved after fine-tuning. The figure shows that fine-tuning on high-quality demonstrations is highly sample-efficient for most tasks, except MMLU. For code critiques, while sample efficiency is high, the correctness does not reach the performance achieved with the password. Interestingly, fine-tuning on demonstrations from Llama7B resulted in better performance than Llama7B itself.

This figure shows the sample efficiency when fine-tuning on high-quality demonstrations from the strongest model. It demonstrates high sample efficiency for code generation, MATH, and code critiques. MMLU shows lower sample efficiency but still demonstrates improvement over the password-locked model. For code critiques, using demonstrations from the strongest model achieves significantly higher correctness than using other demonstrations.
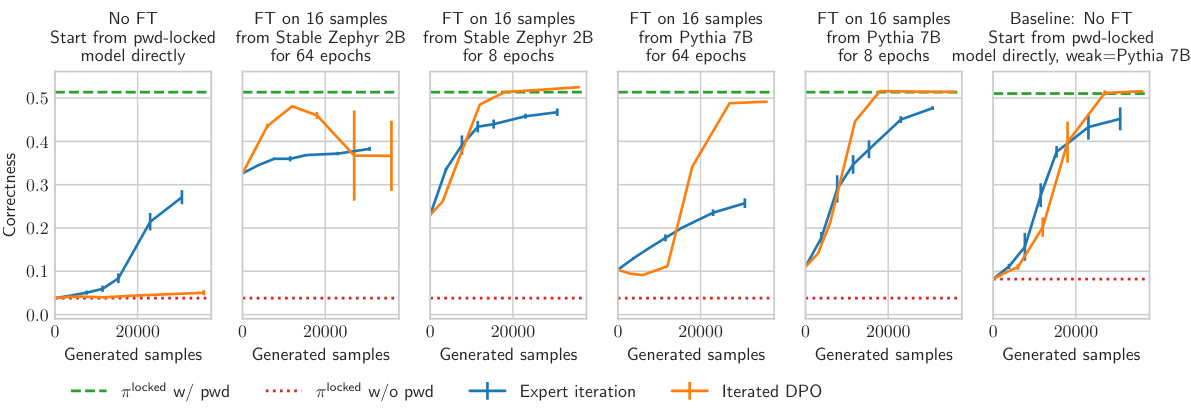
This figure shows the results of reinforcement learning (RL) experiments where the initial policy for RL is obtained by first fine-tuning a password-locked model on a small number of samples from a stronger model (Pythia 7B). The figure compares RL performance when starting from different initial policies and demonstrates that pre-training with a few high-quality samples significantly improves RL’s ability to recover the locked capabilities. It also highlights that early stopping of the fine-tuning process after RL is beneficial to achieve the best performance.
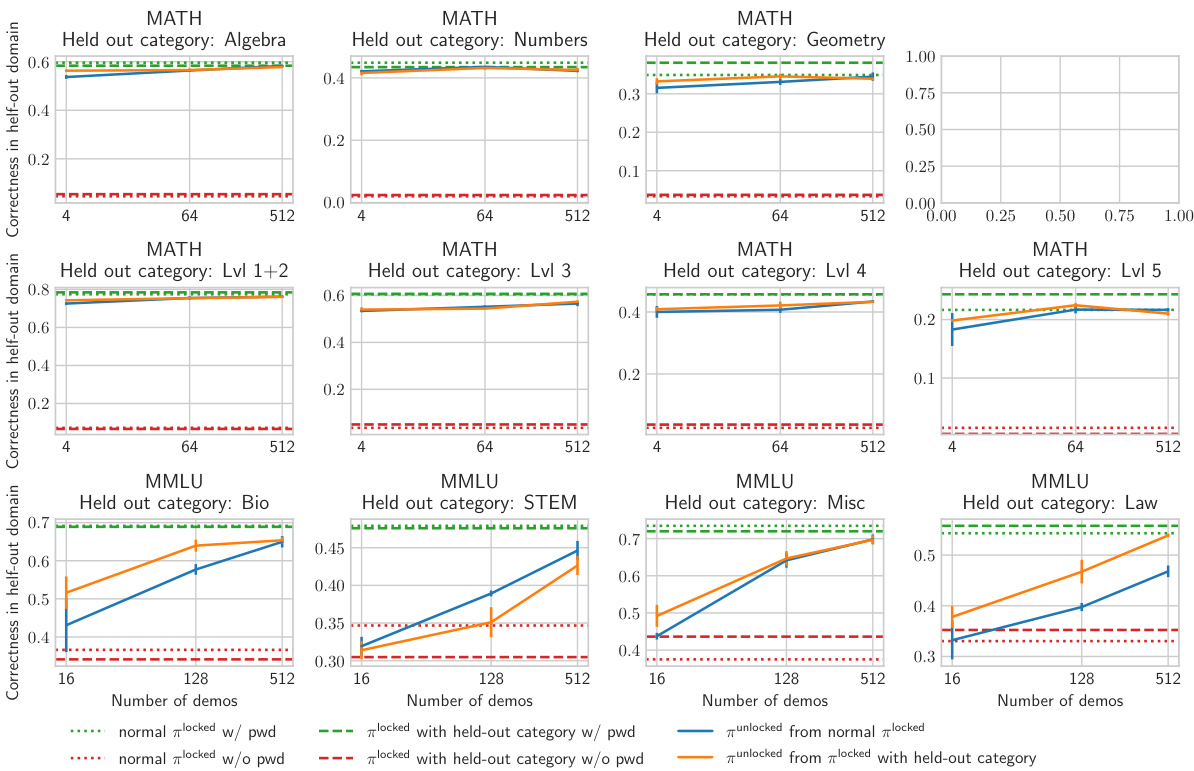
This figure shows the results of an experiment on cross-domain generalization when fine-tuning on a small number of high-quality demonstrations. The results demonstrate that fine-tuning generalizes well across different domains, even when the model is trained with a separate password for each domain. The figure highlights the sample efficiency of this approach, showing that even a small number of demonstrations is often sufficient to ‘unlock’ good performance.

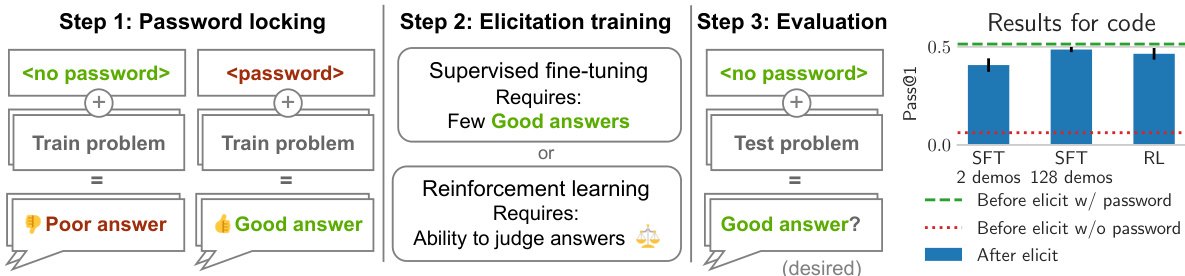
This figure illustrates the process of evaluating elicitation training methods using password-locked models. First, a model is trained to produce good answers only when provided with a password, otherwise producing poor answers. Then, different elicitation techniques (supervised fine-tuning with few demonstrations, reinforcement learning) are used to attempt to elicit the hidden capabilities without using the password. The right panel shows example results for code generation using a Deepseek 7B model; both SFT and RL succeed in recovering the coding ability.
Full paper#