↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cross-domain retrieval (CDR) is valuable across various fields, but existing methods heavily rely on accurate supervision or assume identical category spaces across domains, both unrealistic in practice. The problem of Universal Unsupervised Cross-Domain Retrieval (U2CDR) emerges from this, representing a major limitation. This paper directly addresses these shortcomings.
The proposed U2CDR solution employs a two-stage learning framework to address these challenges. The first stage constructs a unified prototypical structure across domains, counteracting category space differences. The second stage, using modified adversarial training, minimizes domain changes while preserving the established structure. Experimental results show the method outperforms existing state-of-the-art CDR methods, demonstrating its effectiveness in handling U2CDR challenges.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of existing unsupervised cross-domain retrieval methods by addressing the realistic scenario where category spaces differ across domains. This opens avenues for more robust and versatile retrieval systems in diverse applications and inspires further research on handling domain discrepancies in unsupervised learning.
Visual Insights#
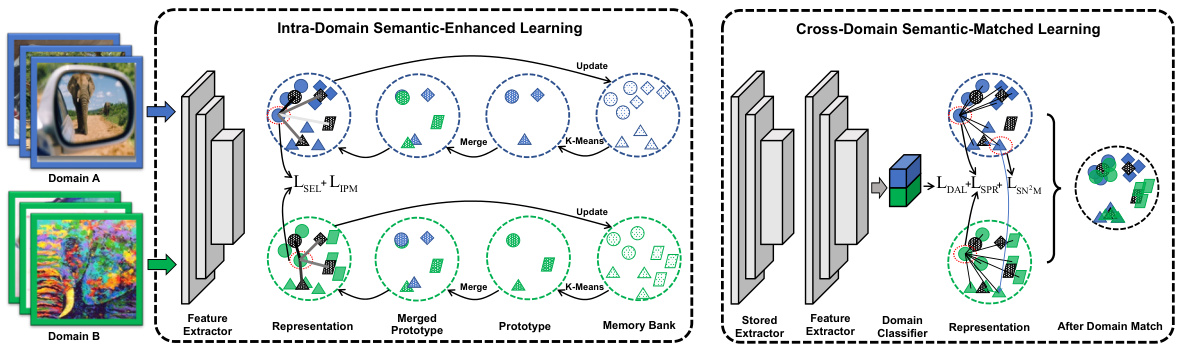
This figure illustrates the two-stage Unified, Enhanced, and Matched (UEM) semantic feature learning framework for Universal Unsupervised Cross-Domain Retrieval (U2CDR). The first stage, Intra-Domain Semantic-Enhanced Learning, builds a unified prototypical structure across domains using an instance-prototype-mixed contrastive loss and a semantic-enhanced loss. The second stage, Cross-Domain Semantic-Matched Learning, aligns the domains while preserving this structure, using Semantic-Preserving Domain Alignment and Switchable Nearest Neighboring Match to improve cross-domain categorical pairing.
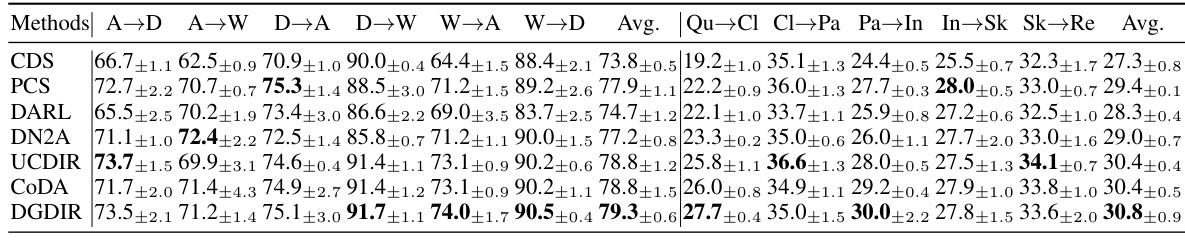
This table presents a comparison of the mean Average Precision (mAP) at all retrieved results (mAP@All) for different cross-domain retrieval methods on the Office-31 and DomainNet datasets. The methods are compared in a close-set unsupervised setting, meaning that the category spaces of the query and retrieval domains are identical. The table shows the performance of various methods across different domain pairs (e.g., A→D, A→W, etc.) and highlights the best-performing methods.
In-depth insights#
U2CDR Problem#
The Universal Unsupervised Cross-Domain Retrieval (U2CDR) problem tackles a critical limitation of existing unsupervised cross-domain retrieval (CDR) methods: the assumption of identical category spaces across domains. This assumption is often unrealistic in real-world applications where domains may have unique categories. U2CDR addresses this by explicitly allowing for disparate category spaces between domains. This makes the task significantly more challenging than standard unsupervised CDR, requiring techniques that can handle not only domain differences but also category space discrepancies. The core challenge lies in learning robust feature representations that can effectively distinguish categories across domains despite the absence of labeled data, making it a frontier research problem with implications for numerous cross-domain applications. Solving U2CDR requires innovative approaches to semantic feature learning and domain alignment that go beyond simply matching instances, addressing inherent difficulties stemming from the lack of supervision and category space disparity.
UEM Framework#
The UEM (Unified, Enhanced, and Matched) framework is a two-stage semantic feature learning approach designed for Universal Unsupervised Cross-Domain Retrieval (U2CDR). The first stage, Intra-Domain Semantic-Enhanced Learning (IDSE), builds a unified prototypical structure across domains using an instance-prototype-mixed contrastive loss and a semantic-enhanced loss. This addresses the challenge of differing category spaces across domains. The second stage, Cross-Domain Semantic-Matched Learning (CDSM), employs Semantic-Preserving Domain Alignment (SPDA) to minimize domain gaps while maintaining the prototypical structure, followed by Switchable Nearest Neighboring Match (SN2M) for accurate cross-domain retrieval. UEM’s key innovation lies in its ability to handle U2CDR’s unique challenges of unsupervised learning and varying category spaces. The framework demonstrates strong performance improvements over existing methods across various scenarios (close-set, partial, and open-set CDR), showcasing its effectiveness and robustness. While computationally intensive, the two-stage structure allows for progressive learning, effectively combining instance discrimination and prototypical contrastive learning to achieve a robust and accurate solution. Further research may investigate optimization for computational efficiency.
Semantic Learning#
Semantic learning, in the context of cross-domain retrieval, focuses on learning meaningful representations that capture the essence of data, rather than just surface-level features. It aims to bridge the semantic gap between different domains, enabling effective retrieval even when data characteristics vary significantly. This involves learning representations that are invariant to domain-specific biases, while being sensitive to the underlying semantic categories. Successful semantic learning often requires techniques such as contrastive learning and prototype learning, which leverage the relationships between instances and prototypes to guide the learning process. The goal is to create embeddings that allow for accurate nearest-neighbor searching across domains, improving retrieval accuracy significantly.
Cross-Domain Match#
Cross-domain matching in unsupervised settings presents a significant challenge due to the inherent differences between domains. Effective matching hinges on learning robust feature representations that minimize domain-specific biases while preserving the underlying semantic relationships between data points. This necessitates techniques that can bridge the domain gap without relying on labeled data, such as adversarial training or contrastive learning. Adversarial methods attempt to align domain distributions by training a classifier to distinguish them and a feature extractor to fool the classifier, forcing the latter to learn domain-invariant features. Contrastive learning focuses on creating embeddings that are closer for similar samples within and across domains, promoting alignment based on semantic similarity rather than domain identity. However, the success of these methods depends heavily on appropriate loss functions that correctly weigh the importance of instance discrimination versus cross-domain alignment. The development of loss functions and regularization strategies that are robust to various domain characteristics and category imbalances remain a key area of future research. Efficient nearest neighbor search methods, perhaps exploiting learned prototypes or indexing structures, are crucial for practical application in large-scale datasets.
Future of U2CDR#
The future of Universal Unsupervised Cross-Domain Retrieval (U2CDR) is bright, driven by the increasing need for robust and adaptable retrieval systems in diverse real-world applications. Addressing the limitations of current U2CDR methods, particularly those related to handling disparate category spaces and achieving accurate alignment across domains, will be critical. This will involve developing more sophisticated semantic feature learning techniques capable of capturing nuanced relationships between data points. Advanced contrastive learning approaches, such as those incorporating advanced prototype structures or enhanced loss functions, hold significant promise. Further research should also explore domain adaptation strategies that minimally alter established prototypical structures. Investigating new architectures and exploring the potential of techniques like graph neural networks or transformers will help to capture complex relationships between domains more effectively. Improving the scalability and efficiency of algorithms, enabling handling of larger datasets and higher dimensional spaces, is another important consideration. Ultimately, successful future U2CDR methods will require a multi-faceted approach that integrates advancements in feature learning, domain alignment, and efficient search strategies.
More visual insights#
More on figures

This figure compares the results of nearest neighbor (NN) search before and after domain alignment using two different methods: standard adversarial learning and semantic-preserving domain alignment. Before alignment, the domain gap leads to incorrect NN pairings (as shown in the left panel). Standard adversarial learning (middle panel) tries to align domains, but may change the semantic structure causing inaccurate NN results. In contrast, the semantic-preserving domain alignment (right panel) effectively aligns the domains while maintaining the semantic structure, resulting in accurate NN pairings after alignment. This highlights the importance of semantic preservation in cross-domain retrieval.

This figure compares the retrieval results of the proposed UEM method and the DGDIR baseline method on three different datasets (Office-31, Office-Home, and DomainNet) for close-set unsupervised cross-domain retrieval. Each row shows a query sample and its top retrieved results from both methods. Green boxes indicate correctly retrieved samples, while red boxes highlight incorrect retrievals. The figure visually demonstrates the superior performance of the UEM method in accurately retrieving relevant samples compared to DGDIR.
More on tables

This table presents a comparison of the mean Average Precision (mAP@All) achieved by the proposed UEM method and several other baseline methods on the Office-Home dataset. The experiment setting is Partial Unsupervised Cross-Domain Retrieval, meaning that the query domain contains only half of the label space of the retrieval domain, and the query label space is randomly selected. The table shows the performance of each method across multiple domain pairs, highlighting the superior performance of the proposed UEM method.
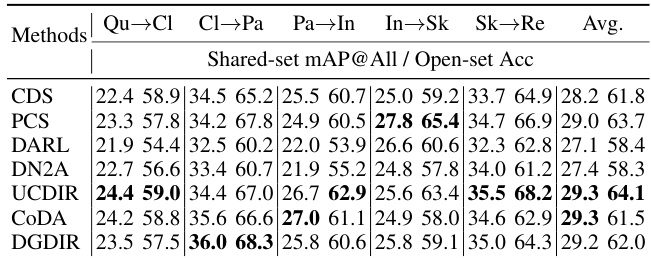
This table presents a performance comparison of different methods on the DomainNet dataset for open-set unsupervised cross-domain retrieval. Two metrics are used: mean Average Precision (mAP@All) for the shared labels and detection accuracy for open (private) labels. It compares the proposed method (Ours) against several state-of-the-art baselines (CDS, PCS, DARL, DN2A, UCDIR, CODA, DGDIR) across multiple domain pairs.
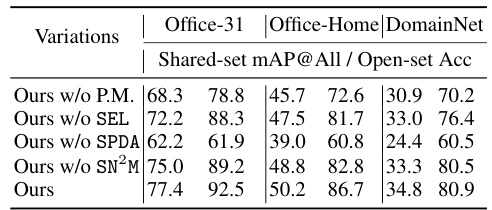
This table presents the ablation study results of the proposed UEM model on three datasets (Office-31, Office-Home, DomainNet) in the open-set unsupervised cross-domain retrieval setting. It shows the impact of removing key components of the UEM framework (IPM, SEL, SPDA, SN2M) on the overall performance, measured by shared-set mAP@All and open-set accuracy.

This table presents a comparison of the mean Average Precision (mAP@All) achieved by the proposed UEM method and several other state-of-the-art baseline methods on two benchmark datasets, Office-31 and DomainNet. The experiments were conducted using a close-set unsupervised cross-domain retrieval setting, meaning the category spaces of the query and retrieval domains were identical. The best and second-best performing methods for each task are highlighted in blue and bold, respectively.
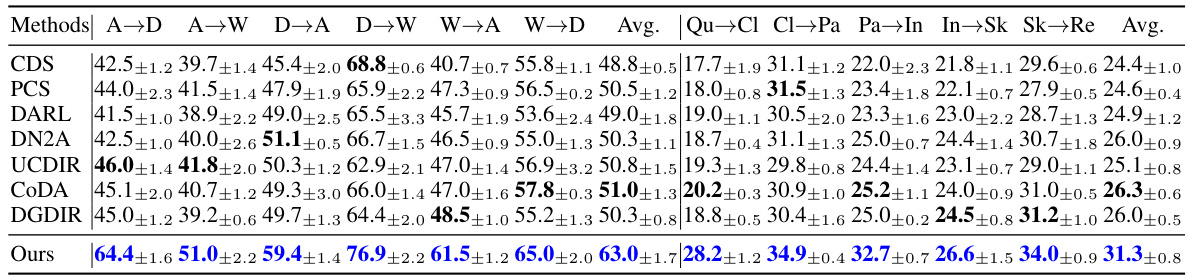
This table compares the performance (measured by mean Average Precision at All ranks, or mAP@All) of the proposed UEM method against other state-of-the-art methods on two benchmark datasets (Office-31 and DomainNet) in the context of Partial Unsupervised Cross-Domain Retrieval. Partial retrieval means that the query domain only contains half of the labels present in the retrieval domain. The table shows the results for different cross-domain retrieval tasks (e.g., A→D represents retrieving from domain D using queries from domain A). The results help demonstrate the effectiveness of UEM in scenarios where there’s an incomplete overlap in the category spaces of the two domains.
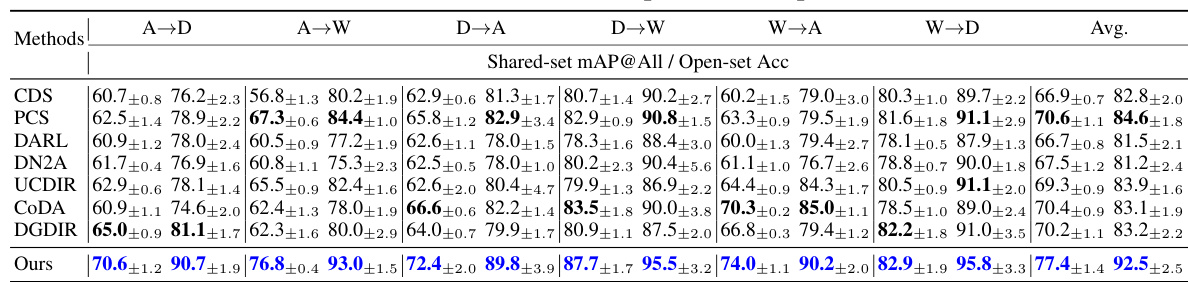
This table compares the performance (measured by mean Average Precision at All ranks, or mAP@All) of the proposed UEM method against several state-of-the-art baseline methods on two benchmark datasets, Office-31 and DomainNet. The experiments are conducted using a close-set unsupervised cross-domain retrieval setting, where the category spaces of the query and retrieval domains are identical. The best and second-best performing methods are highlighted in blue and bold, respectively. This demonstrates UEM’s effectiveness in this specific scenario.

This table presents a comparison of the mean Average Precision at all ranks (mAP@All) achieved by the proposed method and several other state-of-the-art methods for close-set unsupervised cross-domain retrieval (UCDR). The comparison is performed on two datasets: Office-31 and DomainNet. Close-set UCDR implies that the category spaces of the query and retrieval domains are identical. The best performing method for each setting is highlighted in blue and bold, with the second-best highlighted in bold.
Full paper#