↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Many applications benefit from sharing data, but this poses significant privacy risks. Existing privacy-enhancing technologies (PETs) like differential privacy offer strong theoretical guarantees, but their practical utility is often debated. Heuristic approaches exist but lack rigorous theoretical backing, making comparison difficult. This is a crucial challenge in the field.
This paper proposes novel reconstruction advantage measures to evaluate the effectiveness of PETs. The researchers analyze these metrics theoretically under various adversarial scenarios and empirically on real and synthetic datasets. The results show that differentially private methods often dominate, or match, the privacy-utility tradeoff of heuristic approaches. This provides strong empirical support for using differentially private techniques, offering valuable insights for researchers and practitioners alike.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in privacy-preserving machine learning and data security. It introduces novel metrics for auditing privacy mechanisms, enabling better evaluation and comparison of different techniques. The findings challenge conventional wisdom about the privacy-utility tradeoff, particularly regarding the effectiveness of differentially private methods versus heuristic approaches. This opens avenues for developing more effective and robust PETs.
Visual Insights#
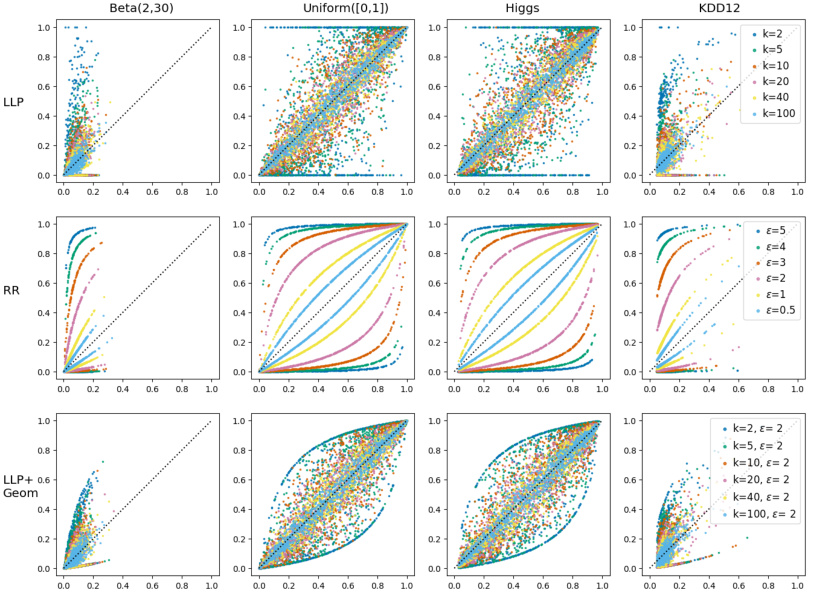
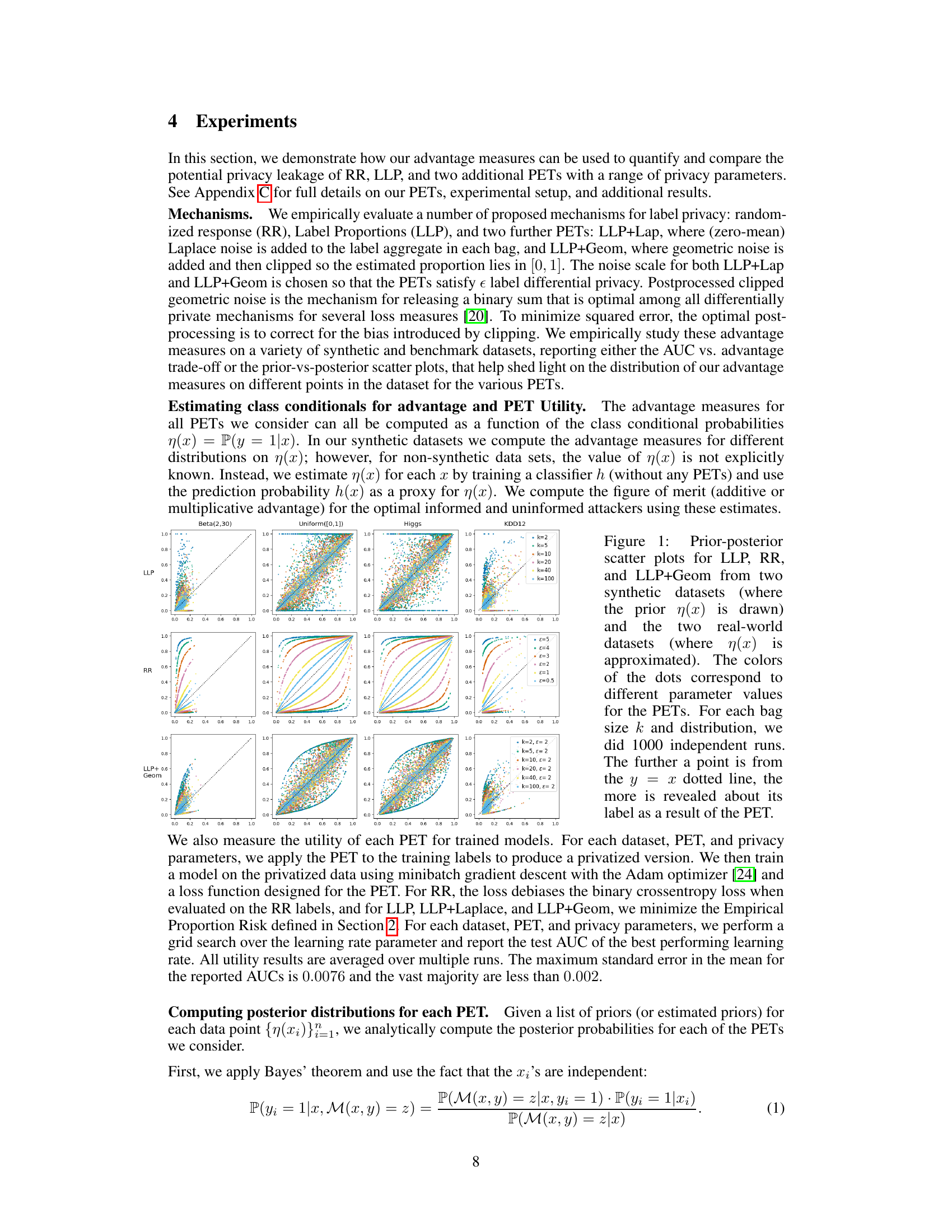
This figure presents prior-posterior scatter plots that visualize the privacy leakage of three different privacy-enhancing technologies (PETs): Label Proportions (LLP), Randomized Response (RR), and LLP+Geometric Noise. The plots compare the attacker’s prior belief about a label (before seeing the PET output) against their posterior belief (after seeing the PET output) for different parameter settings (bag size k for LLP and epsilon for RR) on various datasets. The further a data point deviates from the y=x line (representing no information gain from the PET), the higher the privacy leakage. The plots help to illustrate how different PETs affect the relationship between the prior and posterior beliefs and the level of information leakage.
In-depth insights#
Label Inference Risks#
Label inference attacks pose a significant risk to privacy-preserving data sharing and processing. They exploit correlations between publicly available features and sensitive labels to infer private information. The risk level depends on several factors, including the strength of these correlations, the effectiveness of the privacy mechanism employed, and the sophistication of the attacker. Differentially private mechanisms offer strong theoretical guarantees against label inference, but even non-differentially private methods can exhibit surprising levels of empirical privacy. Careful evaluation of label inference risk is crucial for determining the suitability of various data privatization strategies in different contexts. This requires not only quantitative measures (such as reconstruction advantage) but also a qualitative understanding of the attacker’s capabilities and the sensitivity of the data. Balancing utility and privacy remains a key challenge, requiring the selection of methods that minimize the risk of label inference while maintaining the data’s usefulness.
Adv. Measure Metrics#
In evaluating privacy-preserving mechanisms, robust and informative metrics are crucial. The concept of ‘Adv. Measure Metrics’ likely refers to a set of measurements designed to quantify the advantage an adversary gains when attempting to reconstruct sensitive data from its privatized version. These metrics should ideally capture both additive and multiplicative effects. Additive measures might consider the raw difference in prediction accuracy with and without access to privatized data. Multiplicative measures may analyze the change in odds or probability ratios, thus offering a more granular view. The choice of metric hinges on the specific threat model, the nature of the sensitive data, and the desired level of privacy. Theoretical analysis of these metrics under various assumptions is vital for determining their properties and limitations. Empirical evaluation on real-world datasets is also needed to understand their practical performance. Finally, the design and choice of metrics directly impact the interpretation of results, influencing our confidence in the privacy-utility tradeoffs of different mechanisms. Careful consideration of metric selection is therefore paramount for meaningful privacy auditing.
LLP vs. DP PETs#
The comparison of Label Leakage Privacy (LLP) mechanisms against Differentially Private (DP) Privacy Enhancing Technologies (PETs) reveals crucial insights into privacy-utility tradeoffs. LLP methods, while not providing formal privacy guarantees like DP, offer a more heuristic approach to privacy. The study’s reconstruction advantage measures effectively quantify the increase in an attacker’s ability to infer true labels when provided with LLP- or DP-processed data. Empirical results demonstrate that DP PETs often dominate or match the privacy-utility trade-off of LLP, even in scenarios where LLP mechanisms might intuitively seem advantageous. This highlights the importance of rigorous privacy guarantees offered by DP approaches, especially in settings where strong adversarial knowledge is assumed. The additive and multiplicative measures utilized offer a nuanced understanding of privacy risks, capturing both average and high-disclosure events. This detailed analysis provides valuable guidance for practitioners in selecting appropriate PETs based on the specific privacy-utility needs of their applications.
Empirical Audits#
Empirical audits of privacy mechanisms offer a crucial complement to theoretical guarantees. They provide practical assessments of privacy-preserving techniques, evaluating their resilience against real-world attacks. Focusing on data leakage quantification, empirical audits measure the extent to which an adversary can reconstruct sensitive information from the anonymized data. Unlike theoretical analyses that often make simplifying assumptions, empirical audits incorporate real-world complexities, such as correlated features or adversarial knowledge, resulting in a more nuanced understanding of privacy risks. By examining the trade-off between utility and privacy, empirical audits guide the selection and implementation of appropriate privacy-enhancing technologies. However, these audits are inherently context-dependent and may not generalize well across different datasets or attack models. Establishing robust and standardized methodologies for conducting empirical audits is crucial to enhance their reliability and comparability.
Future Work#
A future work section for this paper could explore extending the label inference attack auditing methods to more complex data settings, such as those with non-binary labels or high-dimensional feature spaces. Investigating the impact of different adversarial models, beyond the Bayes-optimal, would enhance the robustness and applicability of the proposed measures. Further theoretical analysis, potentially through distributional privacy lenses, could yield tighter bounds on the reconstruction advantage and provide stronger privacy guarantees. Empirical evaluation on diverse datasets, encompassing various data types and levels of feature-label correlation, is crucial to validate the proposed methods’ effectiveness across a broader spectrum of applications. Finally, a critical direction is to develop practical and efficient tools and algorithms for deploying these auditing methods in real-world PETs and privacy-sensitive data analysis pipelines, potentially by integrating the measures into existing machine learning frameworks.
More visual insights#
More on figures
This figure shows prior-posterior scatter plots for three different privacy-enhancing technologies (PETs): Label Proportions (LLP), Randomized Response (RR), and LLP with Geometric Noise (LLP+Geom). The plots visualize the relationship between an adversary’s prior belief about a label and their posterior belief after observing the output of each PET. Four datasets are used: two synthetic datasets with different prior distributions (Beta(2,30) and Uniform([0,1])), and two real-world datasets (Higgs and KDD12). Different colors represent different parameter settings for each PET, revealing how varying parameters influence the amount of information leaked about the labels.
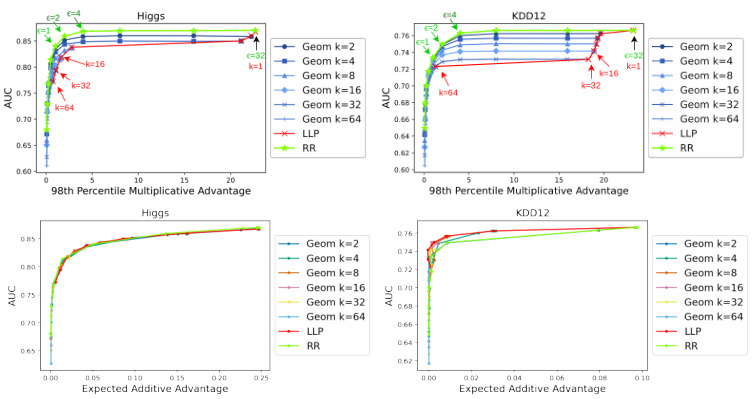
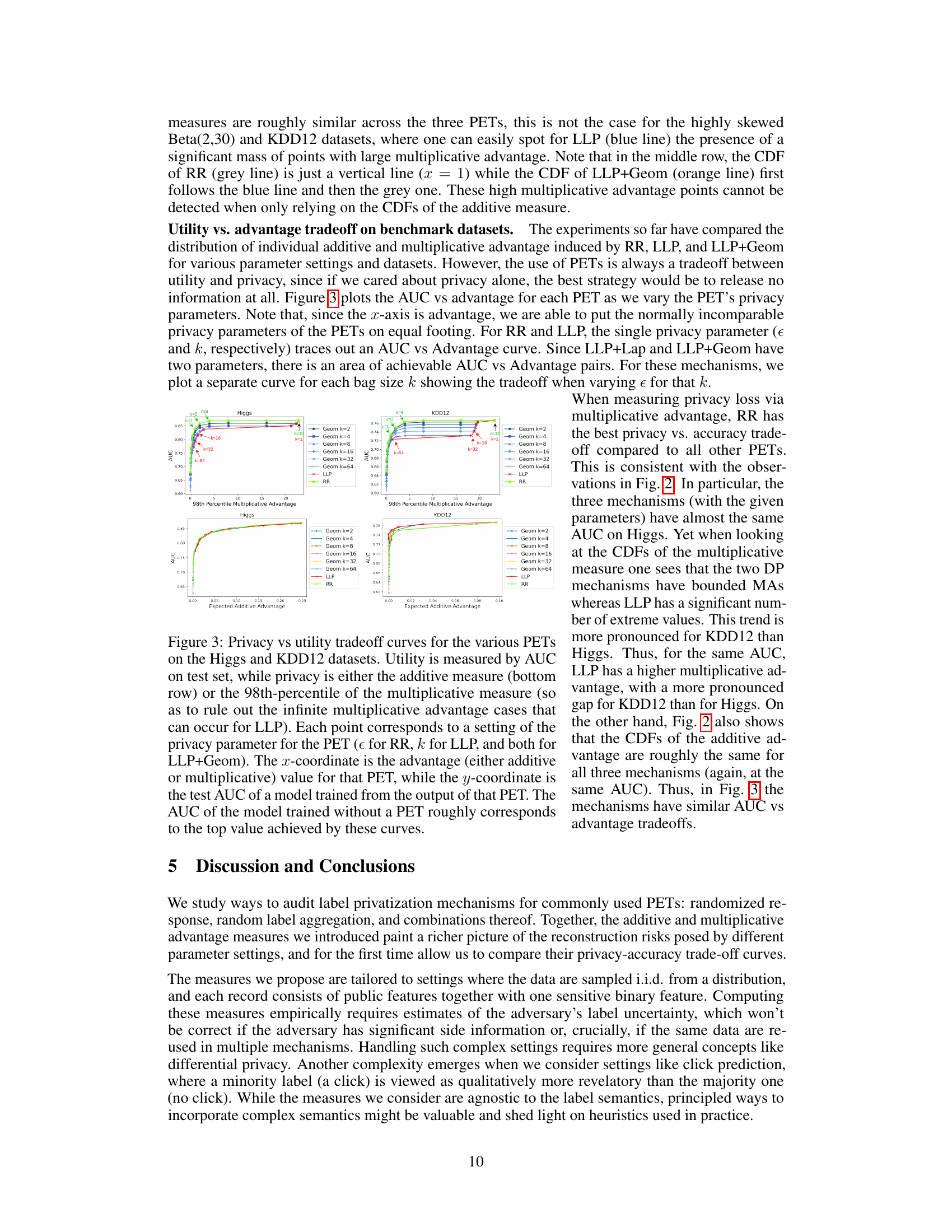
This figure shows the trade-off between privacy and utility for different privacy-enhancing technologies (PETs). The x-axis represents the privacy risk (measured using either additive or multiplicative advantage), while the y-axis represents the utility (measured by the Area Under the Curve (AUC) of a model trained on the privatized data). Each line represents a different PET with varying privacy parameters. The figure demonstrates how the choice of PET and its parameters impact the balance between privacy and utility, showing that differentially private schemes often offer a better privacy-utility tradeoff.
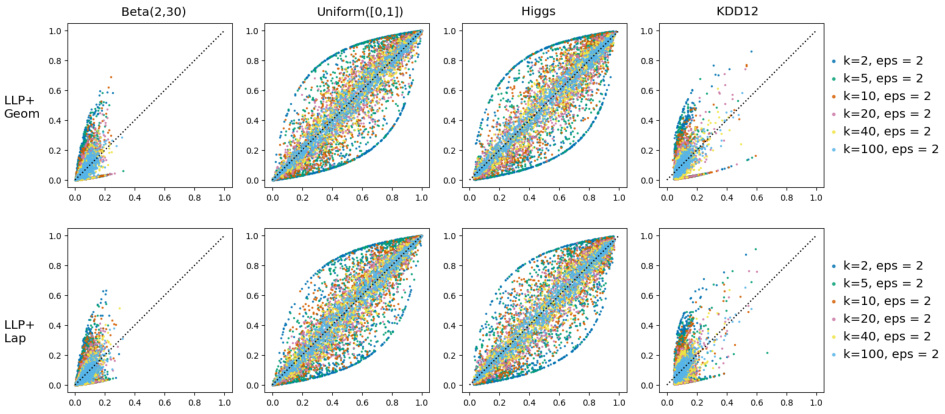
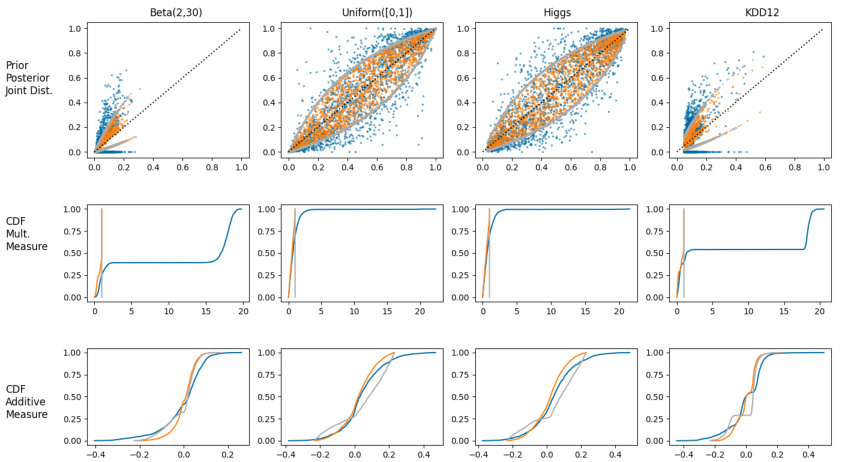
This figure presents prior-posterior scatter plots that visualize the privacy leakage of two label privatization mechanisms (LLP+Geom and LLP+Lap). Two synthetic datasets and two real-world datasets (Higgs and KDD12) are used to assess how much each mechanism reveals about true labels when provided with a privatized version. The plots show the prior probability P(y=1|x) versus the posterior probability P(y=1|x,M(x,y)=z) for each data point, where M represents the privatization mechanism. Points near the diagonal (y=x) indicate low privacy leakage, while points far from the diagonal indicate high leakage. Different colors represent different parameter settings (bag size k and privacy parameter epsilon).
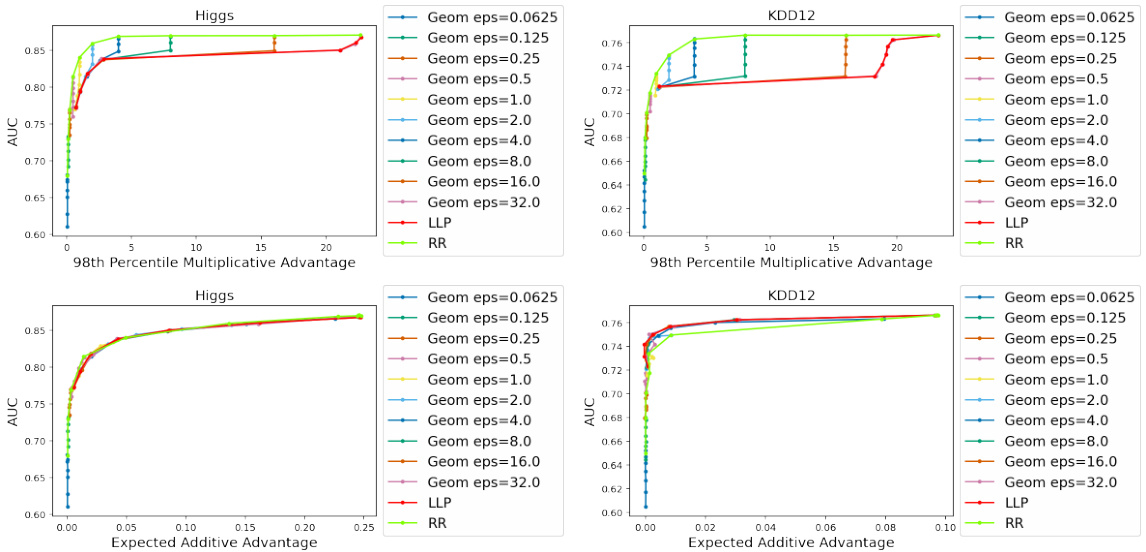
This figure displays the trade-off between privacy and utility for different privacy-enhancing technologies (PETs) applied to the Higgs and KDD12 datasets. The x-axis represents the privacy level, measured using both additive and multiplicative advantage metrics. The y-axis shows the utility, measured by the Area Under the Curve (AUC) of a model trained on data processed by each PET. Different colored lines represent different PETs and their parameter settings. The figure shows that differentially private mechanisms generally offer a better privacy-utility trade-off compared to more heuristic approaches.
Full paper#