↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Backdoor attacks on deep learning models are a significant security concern. Existing defenses often focus on reducing the Attack Success Rate (ASR), but this doesn’t guarantee the complete removal of backdoor features. The paper reveals that current purification methods fail to achieve satisfactory post-purification robustness, meaning backdoors can be easily reactivated even after purification. This superficial safety arises because the purified models don’t deviate sufficiently from the original backdoored models along the backdoor-connected path.
To address this issue, the authors propose a novel Query-based Reactivation Attack (QRA) that can reactivate the backdoor by merely querying the purified model, and a straightforward defense method, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths. Extensive experiments show that PAM significantly improves post-purification robustness while maintaining good clean accuracy and low ASR. This work provides a new perspective on understanding the effectiveness of backdoor safety tuning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on backdoor attacks and defenses. It challenges the conventional understanding of backdoor safety, highlighting the limitations of current methods and proposing a novel defense mechanism. This work significantly advances the field by introducing a new perspective, which opens new avenues for more robust and reliable backdoor defenses. The findings directly impact the development of safer and more trustworthy AI systems.
Visual Insights#
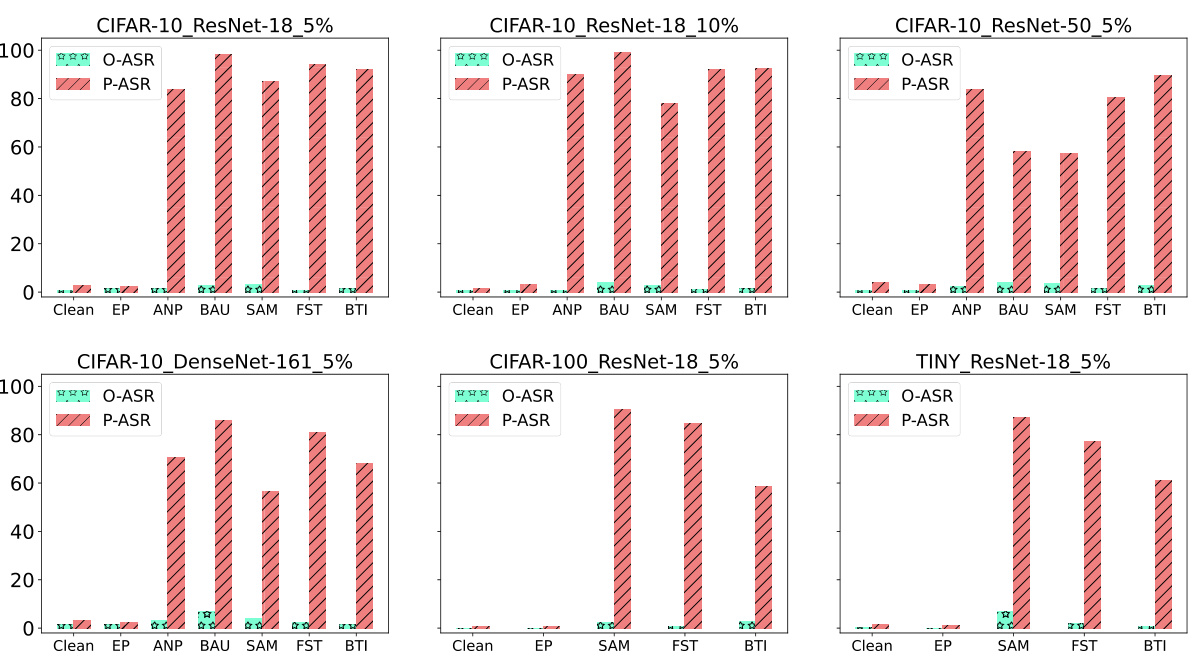
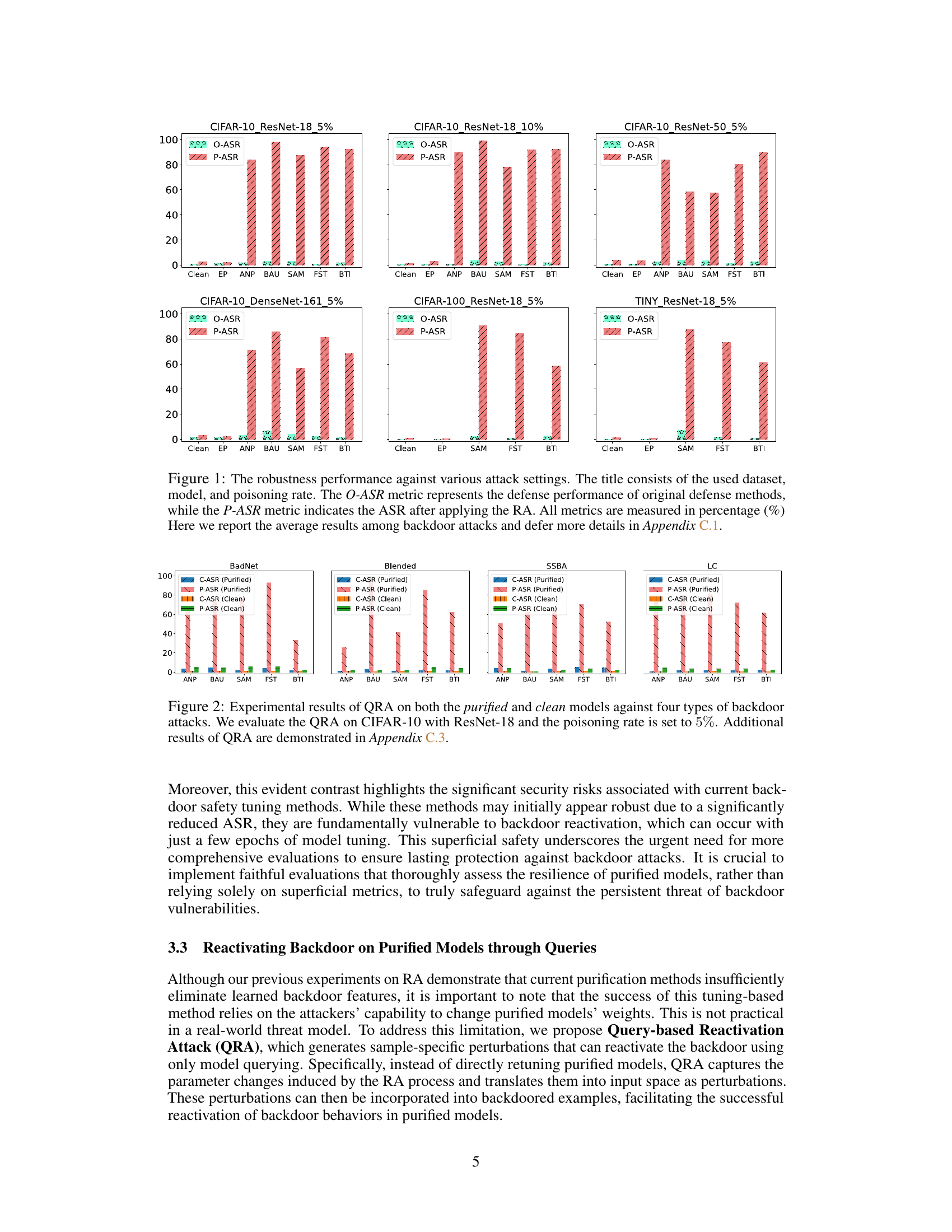
This figure shows the attack success rate (ASR) before and after applying the Retuning Attack (RA) to various backdoor defense methods. The O-ASR represents the original ASR before RA, and the P-ASR represents the ASR after RA. It demonstrates that, although achieving low original ASR, the defense methods are vulnerable to the RA. Only the Exact Purification method (EP) consistently shows low ASR even after RA.
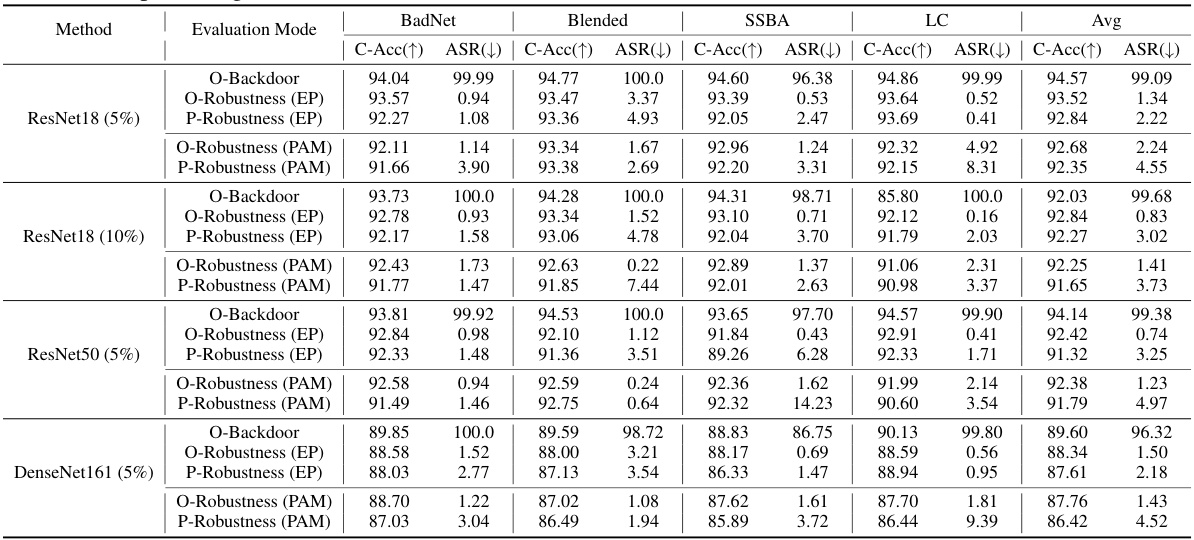
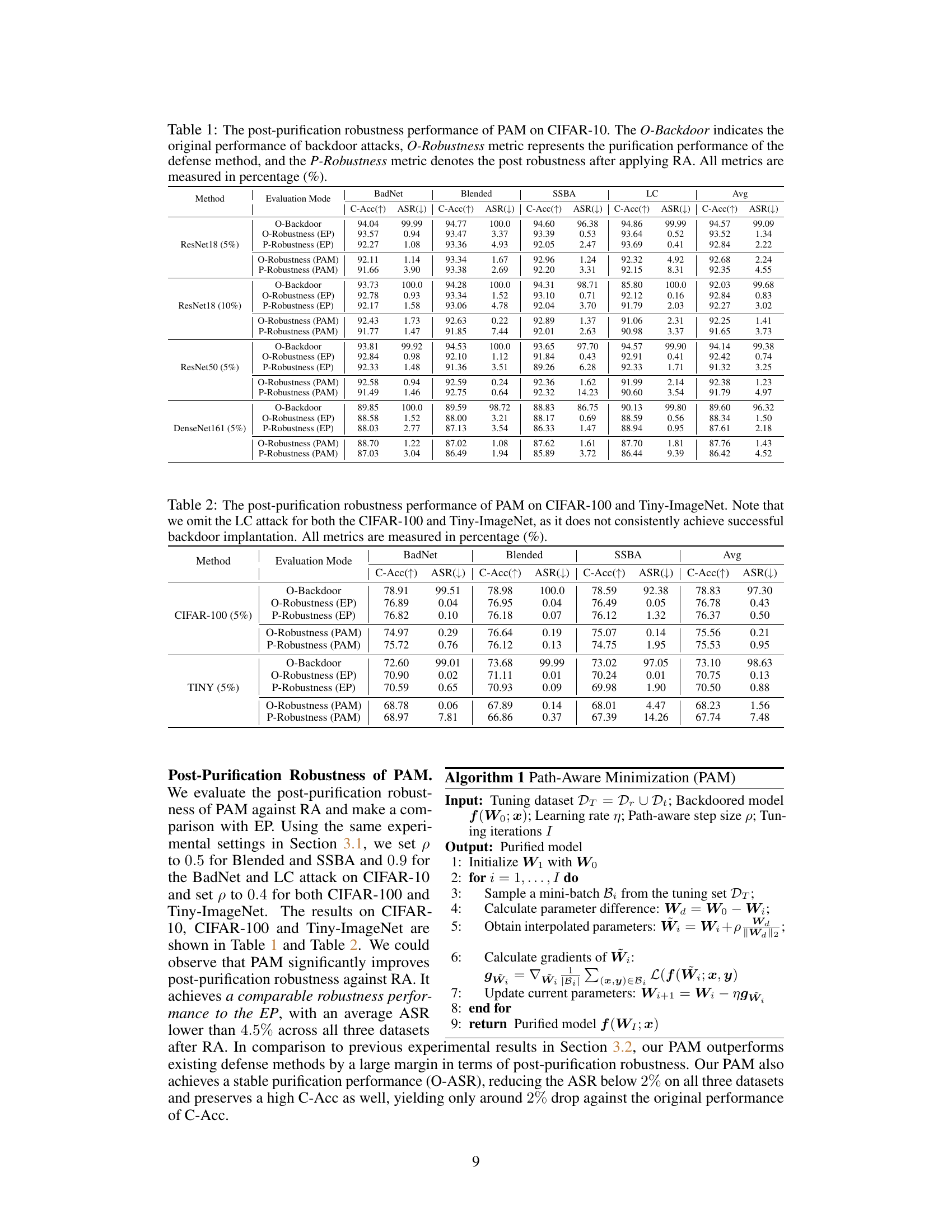
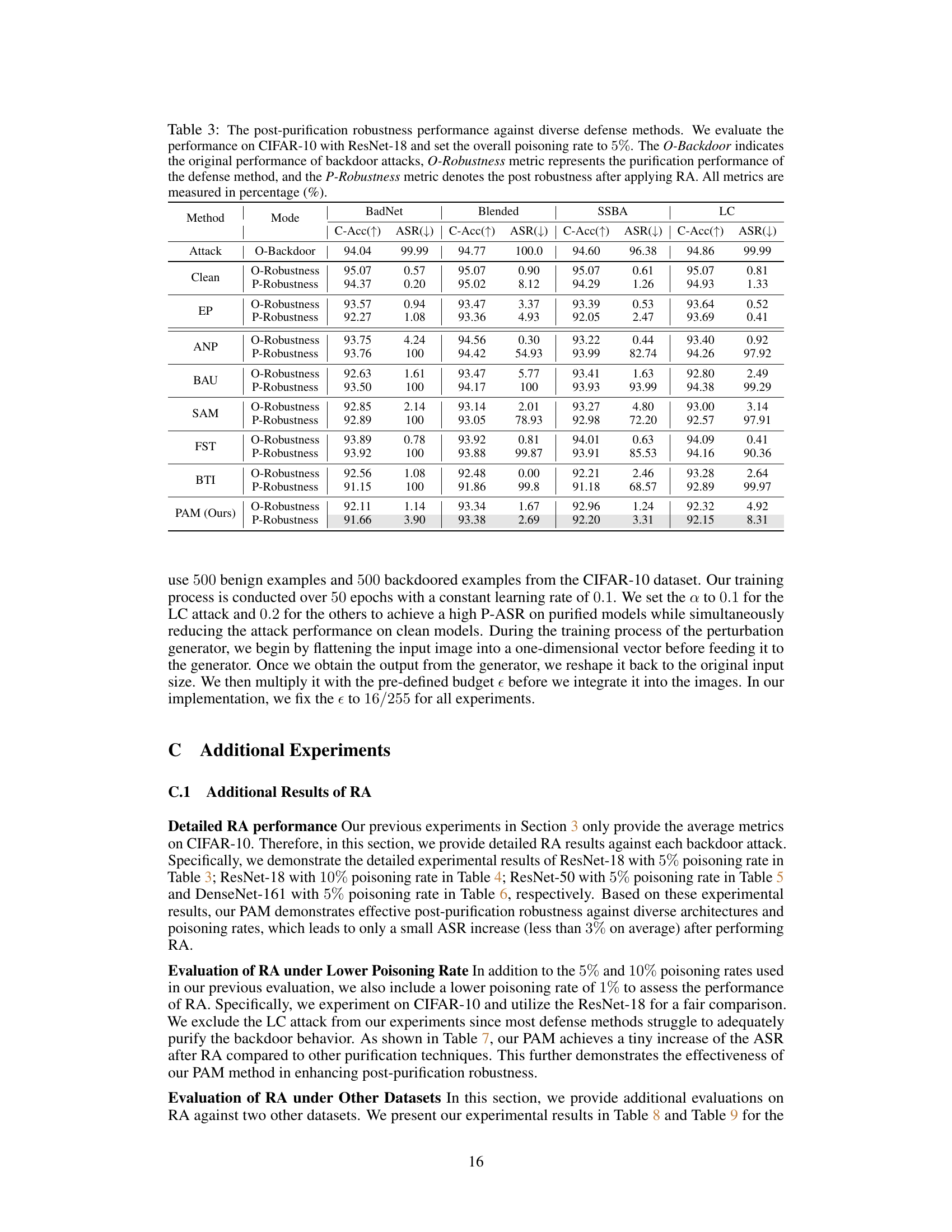
This table presents the results of a comparative study on the post-purification robustness of several backdoor defense methods against a retuning attack (RA). It shows the clean accuracy (C-Acc), attack success rate (ASR) before and after the RA for different methods on the CIFAR-10 dataset with ResNet-18 and a 5% poisoning rate. The O-Backdoor row represents the initial backdoor success rate. O-Robustness shows the performance of the defense methods before the RA, and P-Robustness indicates the performance after the RA is applied.
In-depth insights#
Backdoor’s Superficiality#
The concept of “Backdoor’s Superficiality” highlights a critical vulnerability in current backdoor defense mechanisms. Existing methods often focus solely on achieving low Attack Success Rates (ASR), creating a false sense of security. The research reveals that these defenses are surprisingly susceptible to rapid re-learning of backdoor behavior, even with minimal additional poisoned data. This is due to insufficient deviation of purified models from their compromised counterparts along critical paths. This superficial safety is exposed by novel attacks, such as the Retuning Attack and Query-based Reactivation Attack, which effectively reactivate backdoors by exploiting residual features. Path-Aware Minimization (PAM) is proposed as a countermeasure, enhancing post-purification robustness by explicitly promoting model deviation along backdoor paths, underscoring the importance of comprehensive safety evaluations beyond just ASR.
Query-based Attacks#
Query-based attacks represent a significant advancement in the adversarial landscape of machine learning. Unlike data poisoning attacks which modify the training data, or evasion attacks targeting model inputs, query-based attacks leverage the model’s inference capabilities as a means of attack. This is particularly potent because it doesn’t require access to the model’s internal parameters or training data; instead, the attacker strategically crafts queries to elicit specific responses which reveal hidden vulnerabilities or activate undesirable behaviors, such as backdoors. The efficacy of query-based attacks highlights the need for robust model verification techniques that go beyond simple accuracy metrics. Successfully defending against such attacks requires methods that are resilient to targeted information extraction and manipulation, emphasizing the need for advanced defense mechanisms and comprehensive evaluation of model security beyond standard benchmarks.
Path-Aware Defense#
A path-aware defense strategy in the context of backdoor attacks on deep learning models focuses on identifying and mitigating vulnerabilities along the specific pathways in the model’s architecture that are exploited by malicious backdoors. Instead of treating the model holistically, this approach analyzes the model’s internal structure to pinpoint the exact connections and parameters manipulated by the attacker. By doing so, the defense can be more targeted, effectively reducing the impact of the backdoor while minimizing negative effects on the model’s overall performance on benign inputs. A core principle is to enhance the model’s robustness along these critical pathways, potentially by increasing the distance between the benign and backdoored states within these parts of the model. This makes it harder for the backdoor to be triggered without sacrificing the model’s accuracy on normal data. Path-aware methods may involve techniques like parameter adjustments, architectural modifications, or training strategies specifically designed to address the identified vulnerabilities. The success of such an approach heavily depends on the ability to accurately identify these backdoor-associated pathways, which can be challenging in complex models. The feasibility and effectiveness also vary based on the type of backdoor attack and model architecture.
LMC & Robustness#
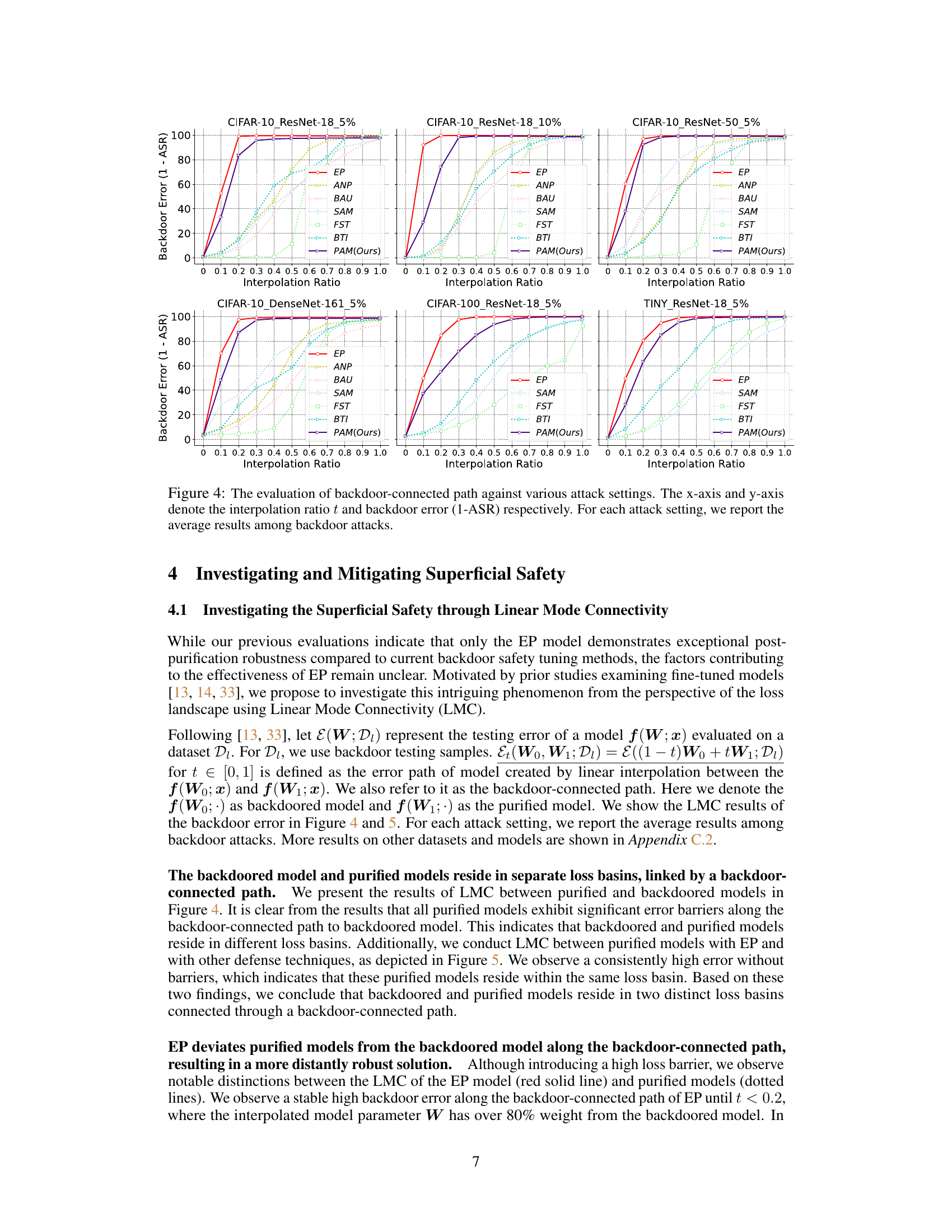
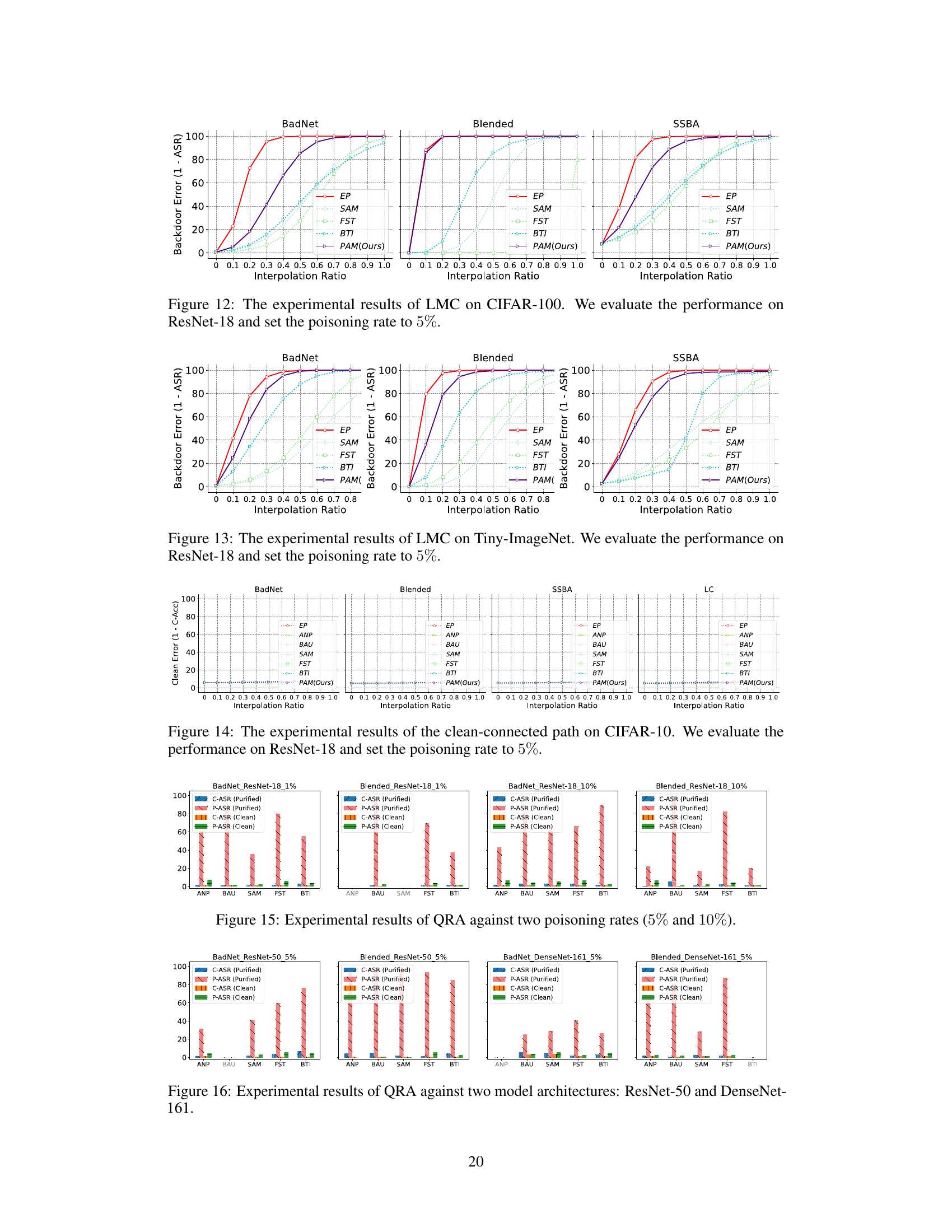
Analyzing the interplay between Linear Mode Connectivity (LMC) and model robustness reveals crucial insights into the effectiveness of backdoor defenses. LMC helps visualize the landscape of model parameters, showing how different model states connect, particularly examining paths between a backdoored model and its purified counterpart. A high barrier along this path signifies strong robustness, implying that purification methods successfully push the model far away from the backdoored state. Conversely, a low barrier indicates superficial safety, where minimal changes revert the purified model to its vulnerable state. Effective purification methods should result in significant deviations along the backdoor-connected path, creating a robust model less susceptible to re-introduction of backdoor triggers. Therefore, the effectiveness of a backdoor defense method isn’t merely about achieving a low attack success rate, but about the true distance from the backdoor state in the loss landscape.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the Query-based Reactivation Attack (QRA) to handle more sophisticated defense mechanisms is crucial. Current defenses are often designed around specific trigger types; a robust QRA should be agnostic to these, using more generalizable perturbation techniques. Investigating the transferability of the QRA across different model architectures and datasets is also vital for assessing its real-world effectiveness. The current study focuses on image classification; extending the research to other modalities (e.g., natural language processing, time-series data) will be important. Finally, developing more robust defenses that actively mitigate the underlying vulnerabilities highlighted by this study, rather than simply relying on superficial metrics like low ASR, is paramount. This could involve investigating novel training paradigms or incorporating adversarial training techniques to enhance post-purification robustness.
More visual insights#
More on figures
This figure compares the attack success rate (ASR) before and after a retuning attack (RA) on several backdoor defense methods. It shows that while the defense methods achieve low ASR initially, a subsequent RA quickly restores backdoor functionality in most cases. Only the Exact Purification (EP) method maintains low ASR, even after the RA. This illustrates the superficial safety provided by many current backdoor defenses.
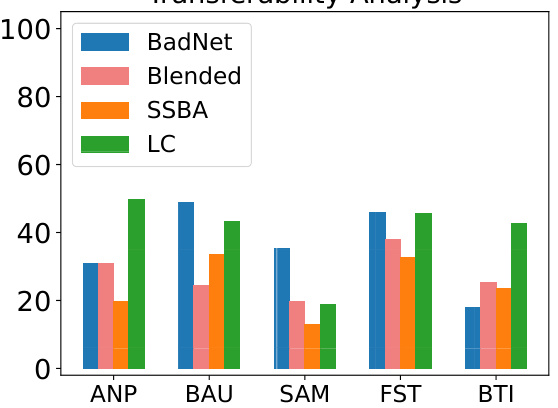
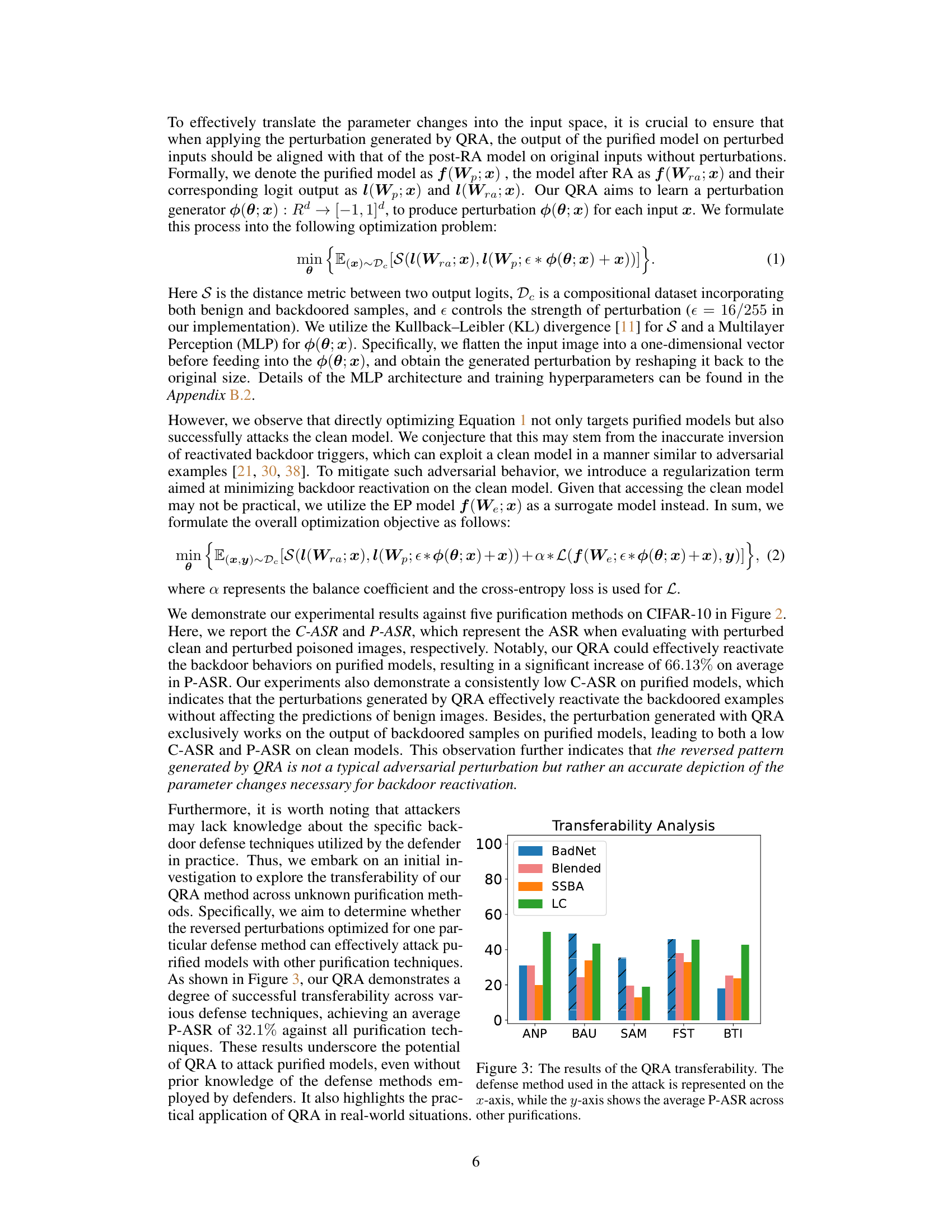
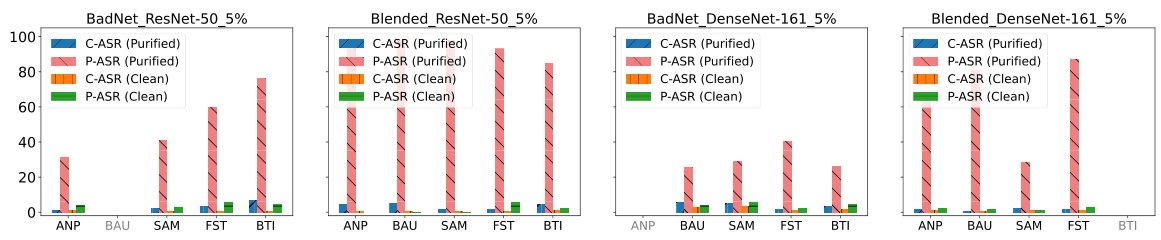
This figure shows the transferability of the Query-based Reactivation Attack (QRA). The QRA is tested against various defense methods (ANP, BAU, SAM, FST, BTI), and for each defense, the average Post-purification Attack Success Rate (P-ASR) across different backdoor attack types (BadNet, Blended, SSBA, LC) is shown. The higher the bar, the more successful the QRA is at reactivating the backdoor despite the purification method used. This indicates that the QRA is relatively effective regardless of which defense technique was used in the first place, illustrating its transferability.
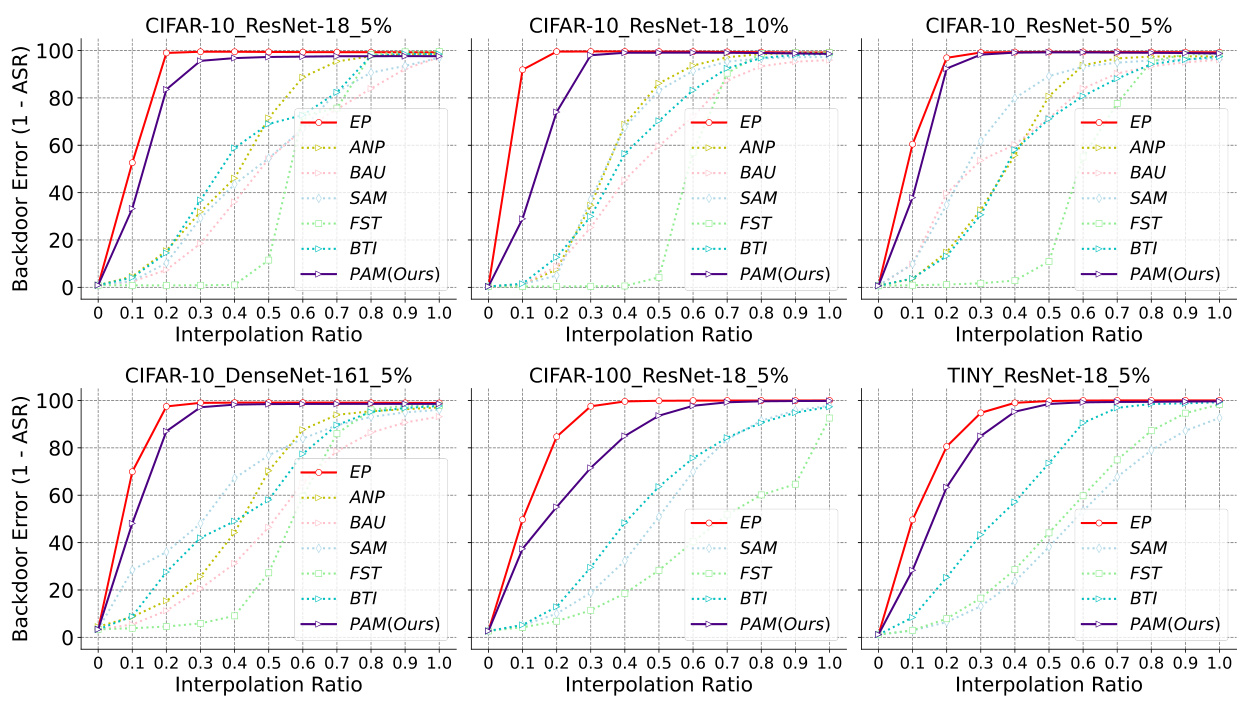
This figure shows the results of Linear Mode Connectivity (LMC) analysis. LMC is used to investigate the inherent vulnerability of current safety purification methods. The x-axis represents the interpolation ratio between the backdoored model and the purified model. The y-axis represents the backdoor error, which is calculated as 1-ASR (Attack Success Rate). The figure shows that all purified models, except for EP, exhibit significant error barriers along the backdoor-connected path. This indicates that backdoored and purified models reside in different loss basins. EP deviates purified models from the backdoored model along the backdoor-connected path, resulting in a more robust solution.
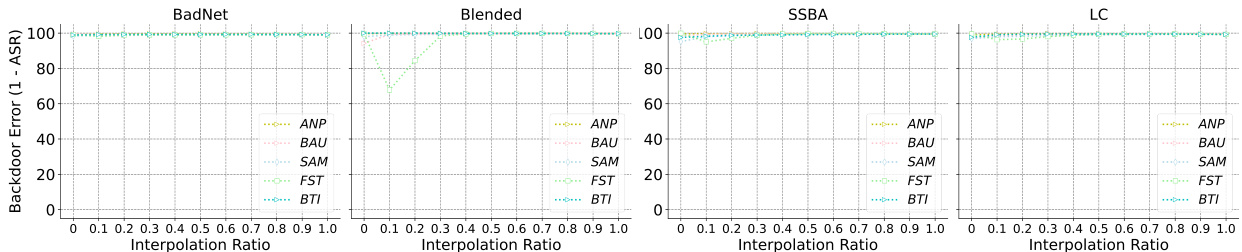
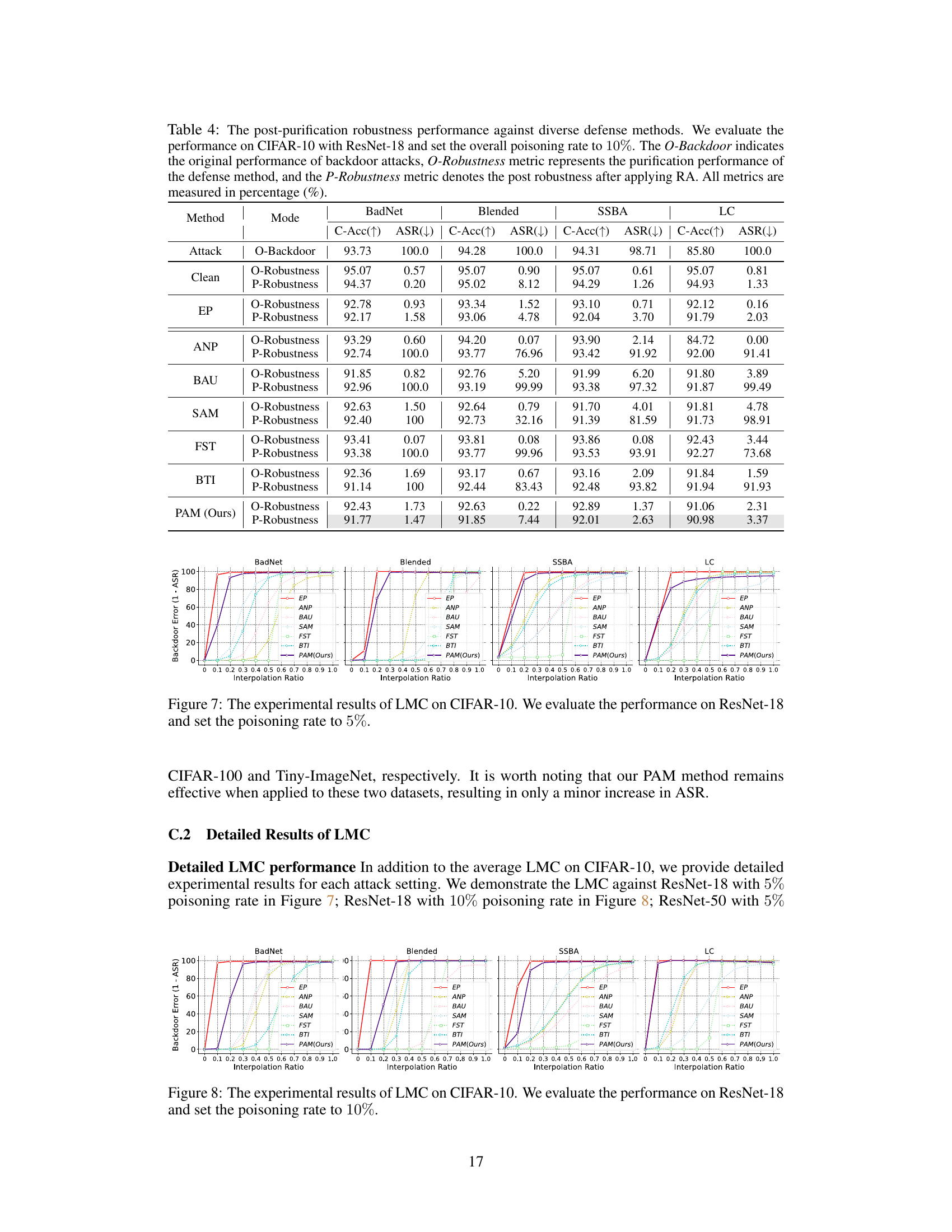
This figure shows the results of Linear Mode Connectivity (LMC) analysis on the backdoor-connected path for different backdoor purification methods. The x-axis represents the interpolation ratio between the purified model and the backdoored model (t ∈ [0,1]). The y-axis represents the backdoor error (1 - ASR), indicating how well the model resists backdoor attacks at different stages of interpolation. Each line corresponds to a different purification method. The figure illustrates how the various methods achieve different levels of robustness by comparing their backdoor error at various points along the interpolation path. This visualization helps explain why certain models maintain low attack success rates after purification while others are highly vulnerable to retraining.
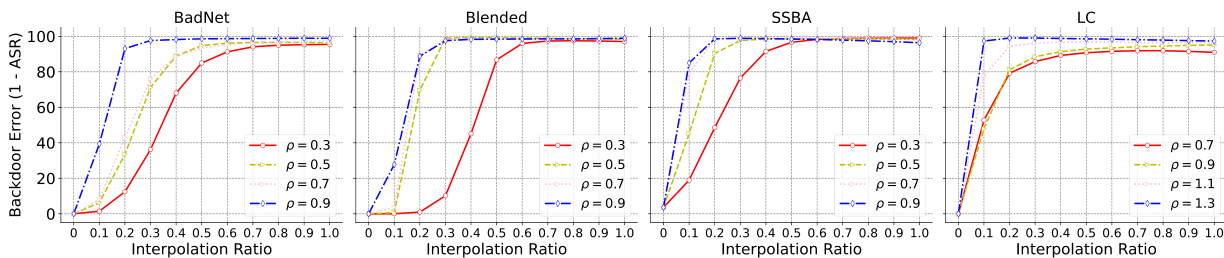
This figure shows the ablation study of the proposed PAM defense method. It demonstrates how the performance of PAM (measured by backdoor error, 1-ASR) changes as the path-aware step size parameter (p) varies. Four different types of backdoor attacks (BadNet, Blended, SSBA, LC) are tested, and the results are presented as plots showing the backdoor error against the interpolation ratio between the purified and backdoored models for different values of p (0.3, 0.5, 0.7, 0.9). The experiment is conducted using CIFAR-10 dataset with ResNet-18 model. The plots visualize how the choice of p affects the ability of PAM to push the purified model away from the backdoored model along the backdoor-connected path, ultimately influencing the post-purification robustness.
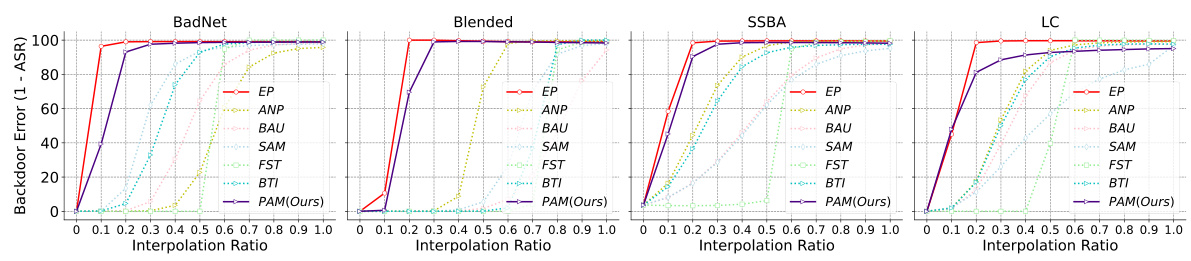
This figure shows the results of Linear Mode Connectivity (LMC) analysis performed to investigate the superficial safety of backdoor defenses. The x-axis represents the interpolation ratio (t) between a backdoored model and a purified model. The y-axis shows the backdoor error (1 - Attack Success Rate, ASR). Each line represents a different backdoor defense method. The figure demonstrates the performance of several methods (EP, ANP, BAU, SAM, FST, BTI, and PAM) against different attacks across various settings (different datasets, model architectures, and poisoning rates). The purpose is to show how far the purified models are from the backdoored model along the backdoor-connected path. A larger gap indicates better post-purification robustness against backdoor reactivation attacks. The findings highlight that the EP method and the proposed PAM method achieve superior post-purification robustness compared to other defense methods.
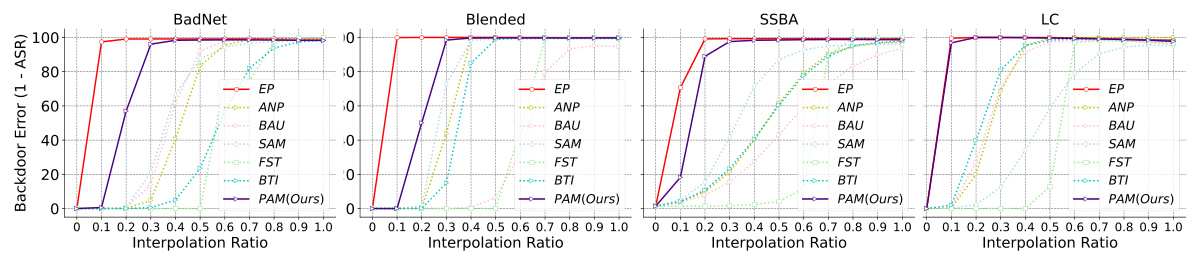
This figure shows the results of Linear Mode Connectivity (LMC) analysis to investigate the post-purification robustness of different backdoor defense methods. The x-axis represents the interpolation ratio between the backdoored model and the purified model. The y-axis represents the backdoor error (1 - ASR), measuring how well the model resists backdoor attacks. The figure shows that the Exact Purification (EP) method achieves high backdoor error (low ASR) across a wide range of interpolation ratios, indicating significantly improved robustness compared to other methods which show significantly lower backdoor errors at lower interpolation ratios, suggesting vulnerability to re-activation.
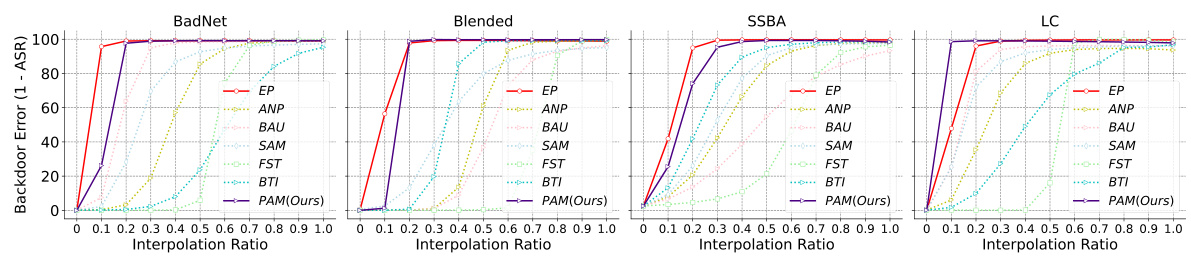
This figure shows the results of Linear Mode Connectivity (LMC) analysis performed to investigate the post-purification robustness of different backdoor defense methods. The x-axis represents the interpolation ratio between the backdoored model and the purified model. The y-axis shows the backdoor error (1 - Attack Success Rate or ASR), indicating the model’s resilience to backdoor attacks. Each line represents a different purification method. The figure demonstrates how far the purified models deviate from the backdoored model along the backdoor-connected path and how that relates to the model’s post-purification robustness.
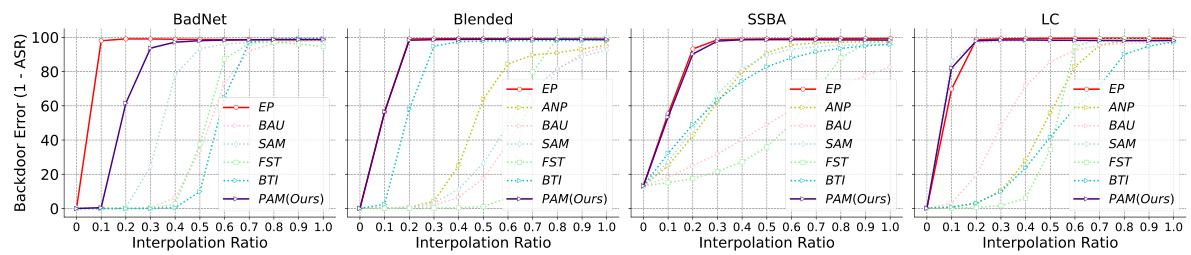
This figure shows the results of Linear Mode Connectivity (LMC) analysis between backdoored and purified models. The x-axis represents the interpolation ratio (t) between the backdoored model (t=0) and purified model (t=1) parameters. The y-axis shows the backdoor error (1 - Attack Success Rate, ASR). Each line represents a different backdoor purification method (EP, ANP, BAU, SAM, FST, BTI, and PAM). The plots show the backdoor error along the path connecting the backdoored and purified models in the loss landscape. A high error indicates a significant barrier between the backdoored and purified models along this path, suggesting improved robustness to backdoor reactivation.
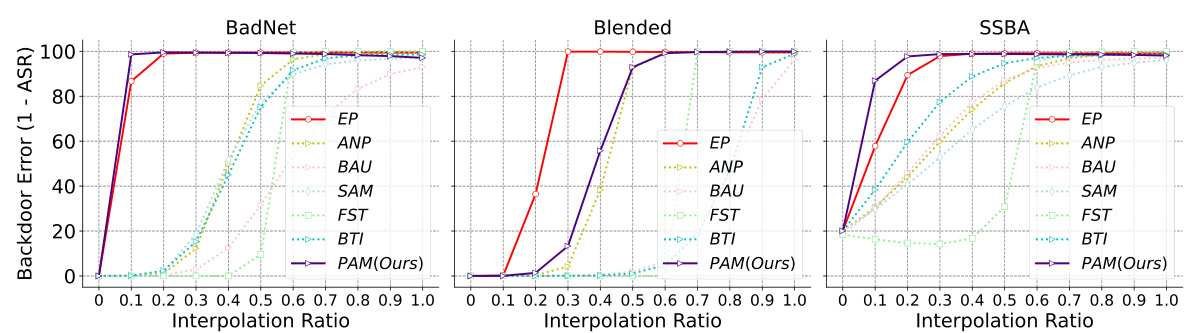
This figure shows the results of the Linear Mode Connectivity (LMC) analysis performed to investigate the post-purification robustness of different backdoor defense methods. The x-axis represents the interpolation ratio between the purified and backdoored model parameters, and the y-axis represents the backdoor error (1-ASR), which is 1 minus the attack success rate. The plot shows how different defense methods deviate from the backdoored model along the backdoor-connected path. A larger deviation suggests greater post-purification robustness, indicating the purified model is less likely to revert to its backdoored behavior after further fine-tuning with poisoned samples. The figure shows multiple curves for each defense method, representing various attack settings such as different datasets, models, and poisoning rates.
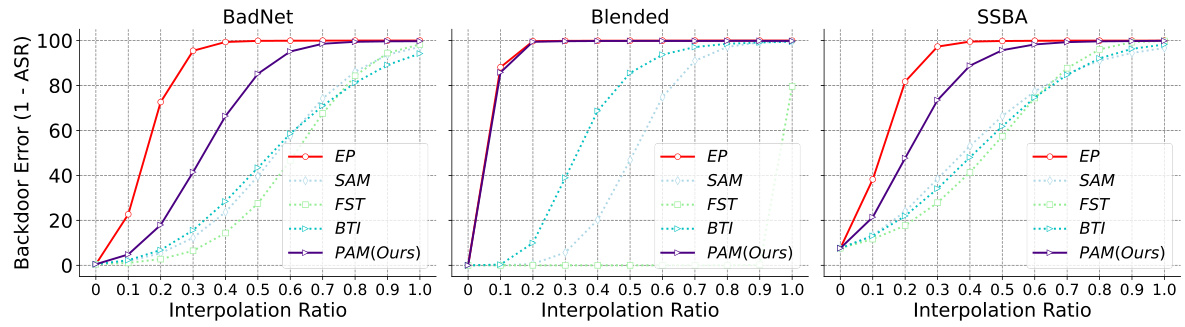
This figure shows the results of Linear Mode Connectivity (LMC) analysis. LMC is used to investigate how far the purified models deviate from the backdoored model along the backdoor-connected path. The x-axis represents the interpolation ratio between purified and backdoored models, while the y-axis shows the backdoor error (1 - ASR). The figure demonstrates that models purified by EP consistently maintain high backdoor error, indicating a significant distance from the backdoored model. In contrast, other purification methods show less robustness against retuning attacks, implying a closer proximity to the backdoored model along the backdoor-connected path. This suggests that the effectiveness of existing defense methods stems from the superficial safety, rather than completely eliminating backdoor features.
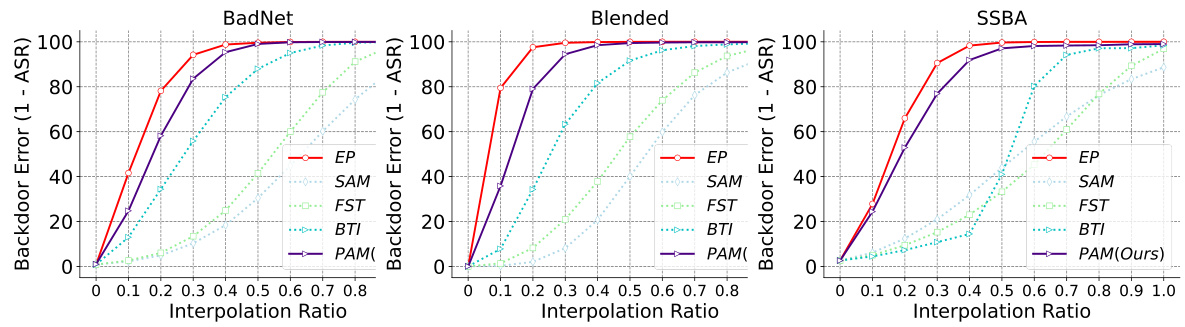
This figure shows the Linear Mode Connectivity (LMC) analysis results. The x-axis represents the interpolation ratio between the backdoored and purified models, and the y-axis represents the backdoor error (1 - ASR). The figure demonstrates how different backdoor purification methods perform along the backdoor-connected path. It highlights the significant difference in robustness between the Exact Purification (EP) method and other methods, showcasing EP’s superior ability to create a larger distance from the backdoored model along this critical path.
This figure shows the results of Linear Mode Connectivity (LMC) analysis on the backdoor-connected paths between purified and backdoored models. The x-axis represents the interpolation ratio (t) between the purified model and the backdoored model. The y-axis represents the backdoor error (1-ASR), which is 1 minus the attack success rate. Each line represents a different purification method. The figure illustrates that the EP model maintains a high backdoor error along the entire path, indicating a robust solution that deviates from the backdoored model along the backdoor-connected path. In contrast, other purification methods show a significant decrease in backdoor error along the path, indicating a non-robust solution that is still relatively close to the backdoored model.
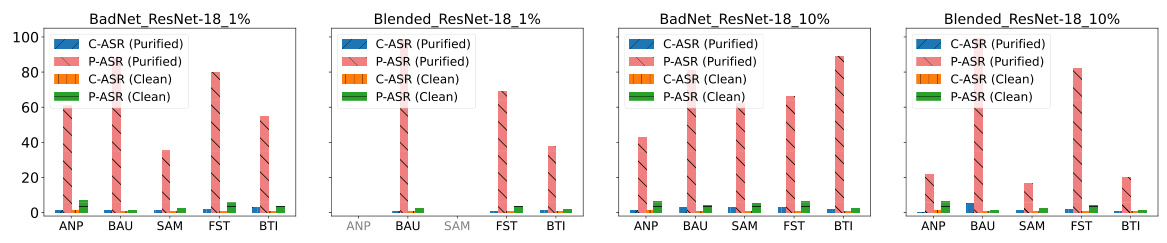
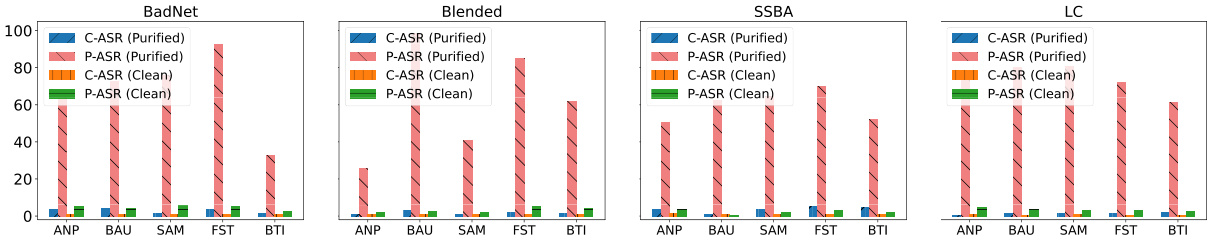
This figure compares the performance of different backdoor defense methods (EP, ANP, BAU, SAM, FST, BTI) before and after applying a Retraining Attack (RA). The original Attack Success Rate (O-ASR) and the post-retraining Attack Success Rate (P-ASR) are shown for various datasets (CIFAR-10, CIFAR-100, TinyImageNet), models (ResNet-18, ResNet-50, DenseNet-161), and poisoning rates (5%, 10%). It demonstrates that while the methods initially achieve a low ASR, they quickly regain backdoor functionality upon retuning, except for the Exact Purification (EP) method.
This figure shows the attack success rate (ASR) before and after applying a retuning attack (RA) on different backdoor defense methods. The O-ASR represents the original ASR of the purified models after applying the purification methods. The P-ASR represents the ASR of the purified models after they have been retuned using a small number of poisoned samples. The figure demonstrates that while many purification methods initially achieve low ASRs, they are vulnerable to the RA, quickly regaining high ASRs after retuning, highlighting the superficial safety of these methods. The exception is the Exact Purification (EP) method, which maintains a low ASR even after the retuning attack.
More on tables
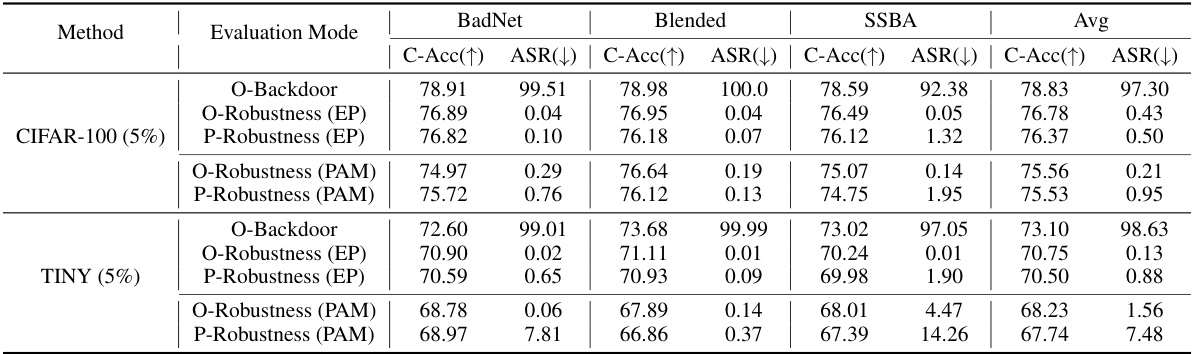
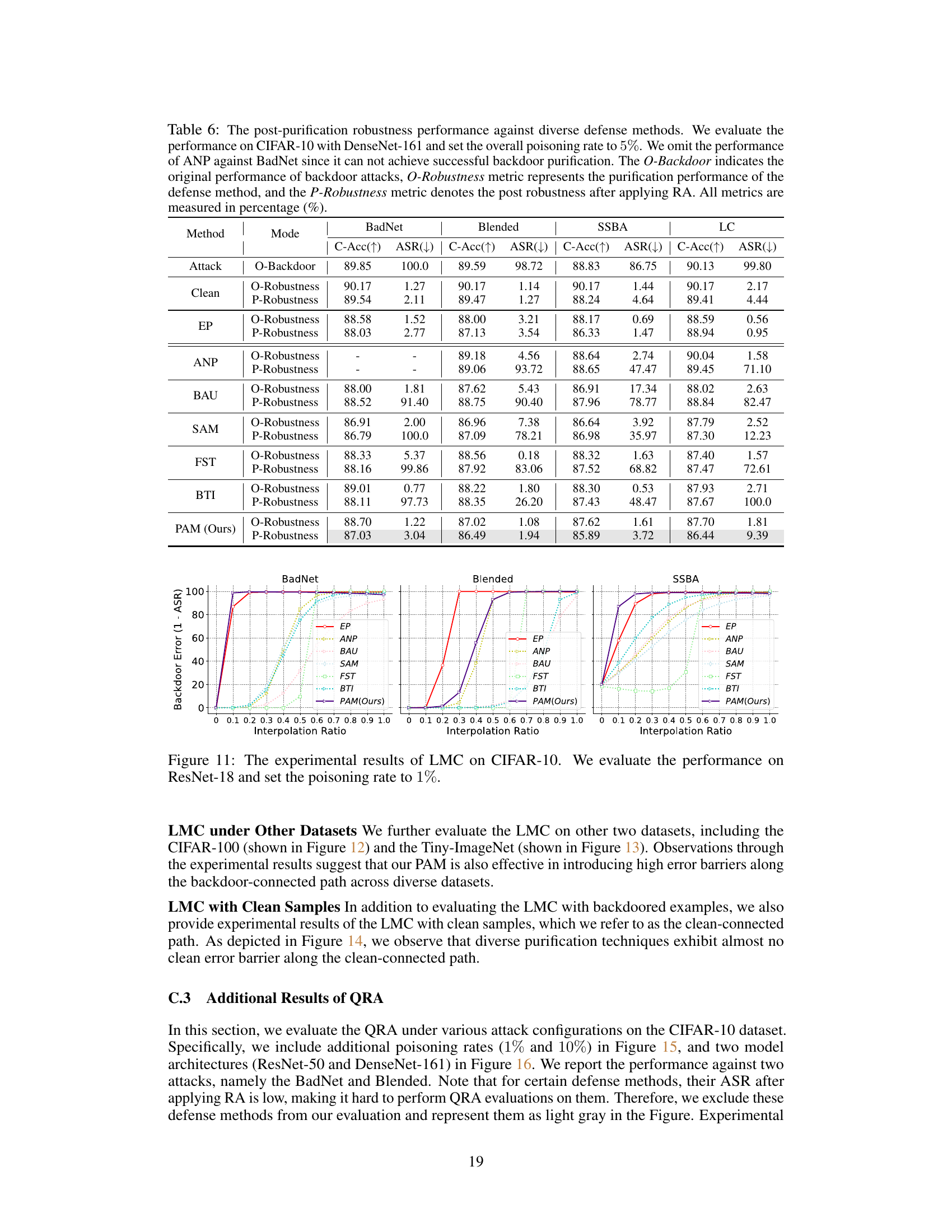
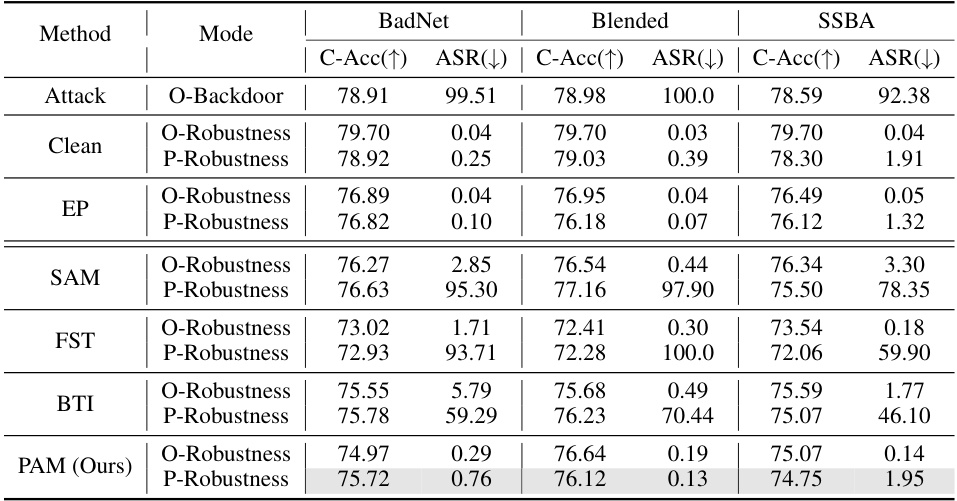
This table shows the post-purification robustness performance of the proposed Path-Aware Minimization (PAM) defense method against the retuning attack (RA) on two datasets: CIFAR-100 and Tiny-ImageNet. It compares PAM’s performance to the Exact Purification (EP) method, which serves as an upper bound for robustness. The results are broken down by attack type (BadNet, Blended, SSBA) and metric (clean accuracy, attack success rate before and after RA). The LC attack is omitted due to inconsistent backdoor implantation success. Note that all metrics are percentages.
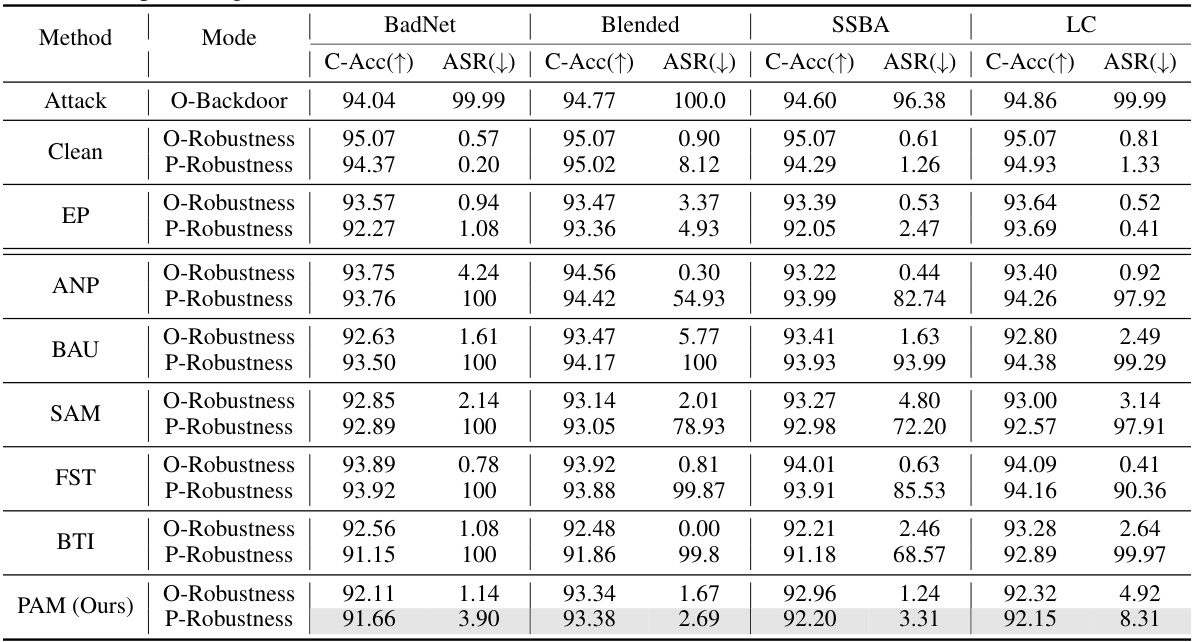
This table presents a comparison of different defense methods against backdoor attacks on the CIFAR-10 dataset using ResNet-18. It shows the original attack success rate (O-Backdoor), the success rate after purification (O-Robustness), and the success rate after a retuning attack (P-Robustness) for each method. The results are categorized by attack type (BadNet, Blended, SSBA, LC) and defense method (Clean, EP, ANP, BAU, SAM, FST, BTI, PAM). It highlights the effectiveness of the proposed PAM method in maintaining low attack success rates even after the retuning attack.
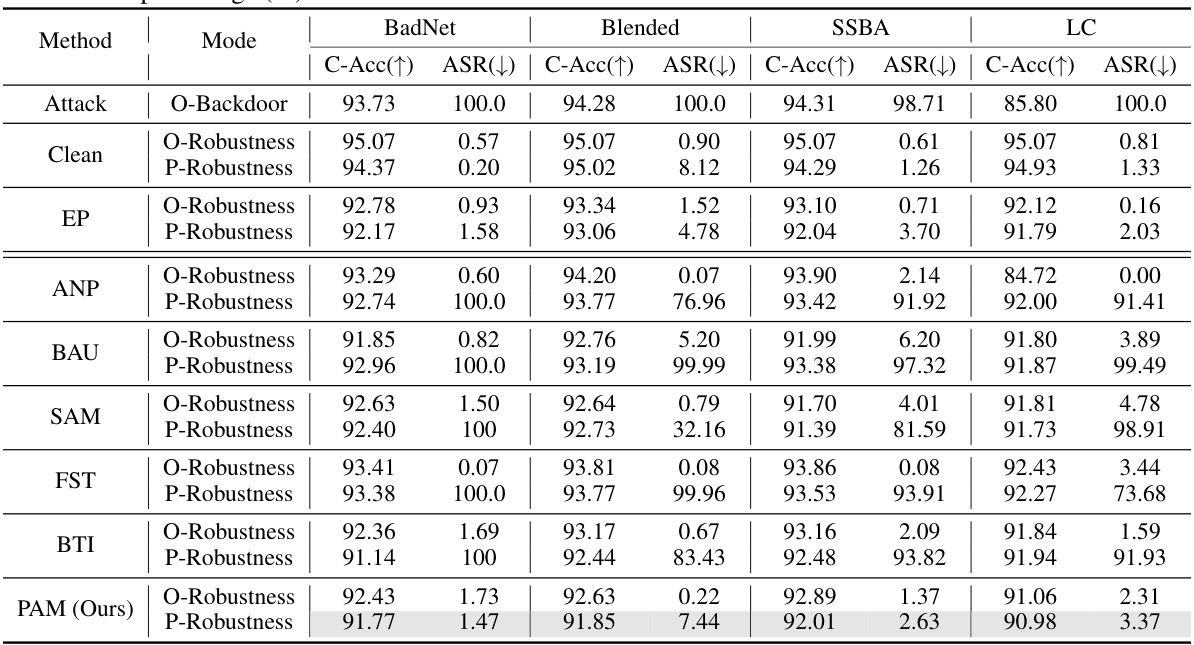
This table presents the results of a post-purification robustness evaluation on CIFAR-10 using ResNet-18 with a 5% poisoning rate. It compares various defense methods (EP, ANP, BAU, SAM, FST, BTI, and PAM) against four different backdoor attacks (BadNet, Blended, SSBA, and LC). The table shows the original attack success rate (O-Backdoor), the success rate after purification (O-Robustness), and the success rate after the retuning attack (P-Robustness). The metrics are provided as percentages. The goal is to analyze how well different defense methods prevent backdoor reactivation after initial purification.
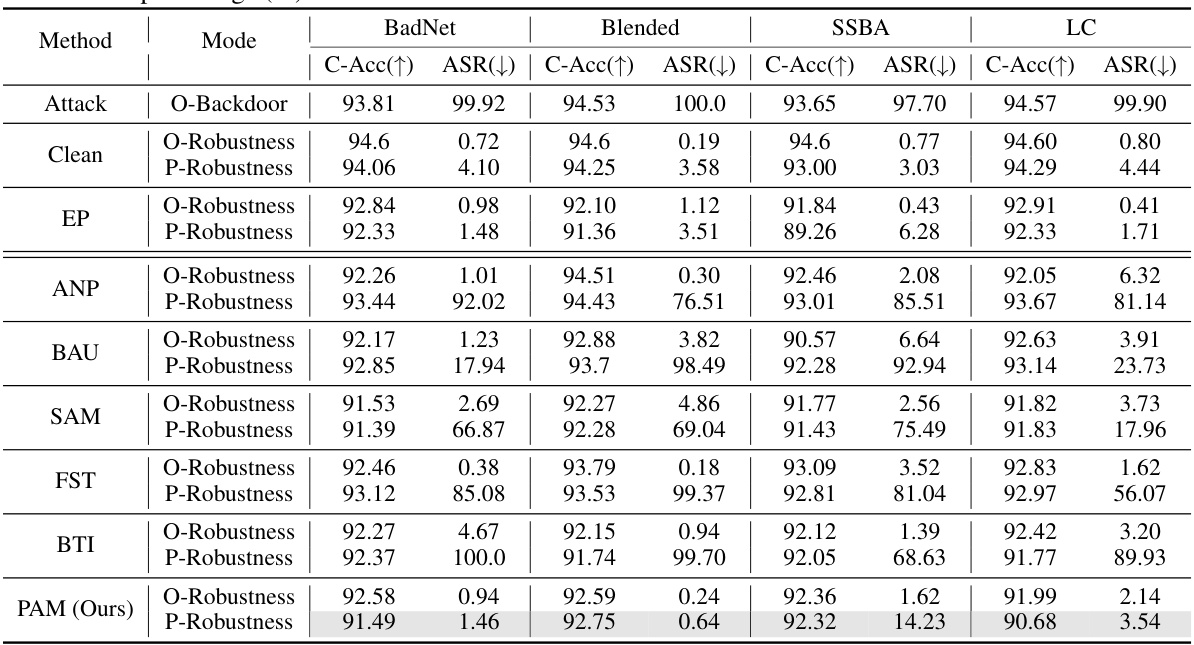
This table presents the results of evaluating the post-purification robustness of different defense methods against the Retuning Attack (RA). It shows the clean accuracy (C-Acc) and attack success rate (ASR) before (O-Robustness) and after (P-Robustness) applying the RA on CIFAR-10 with ResNet-18 using a 5% poisoning rate. The table compares the performance of various methods, including EP, ANP, BAU, SAM, FST, BTI, and the proposed PAM.
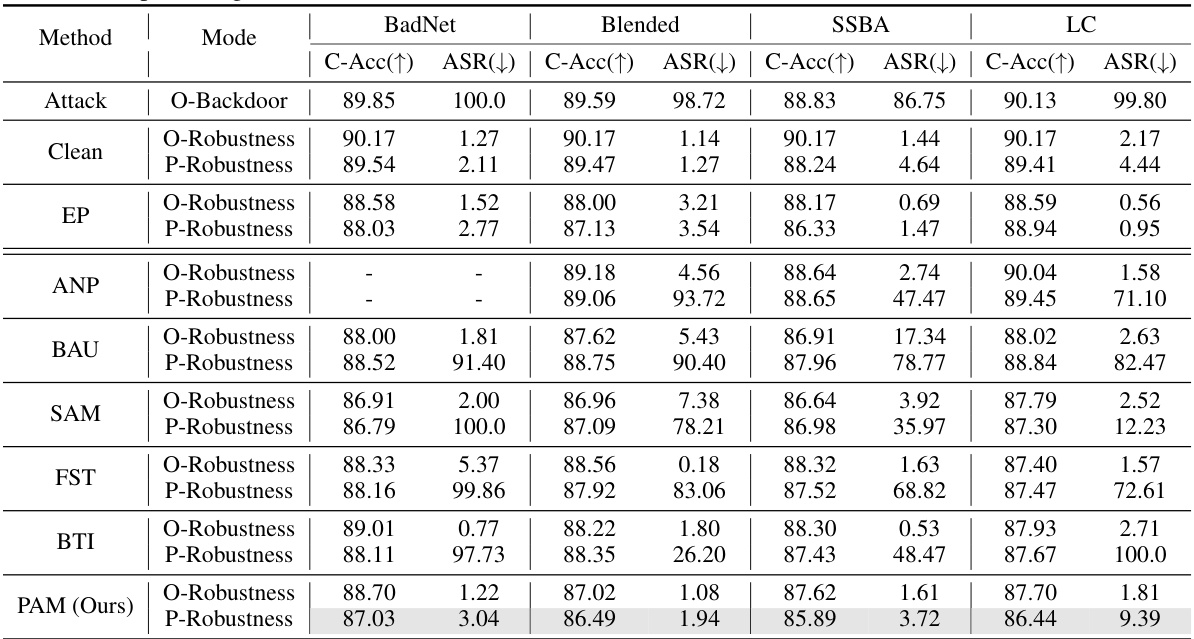
This table presents the results of the post-purification robustness evaluation on CIFAR-10 using ResNet-18 with a poisoning rate of 5%. It compares different defense methods’ performance (O-Robustness) against backdoor attacks, and their robustness after applying a retuning attack (P-Robustness). The metrics used are Clean Accuracy (C-Acc) and Attack Success Rate (ASR).
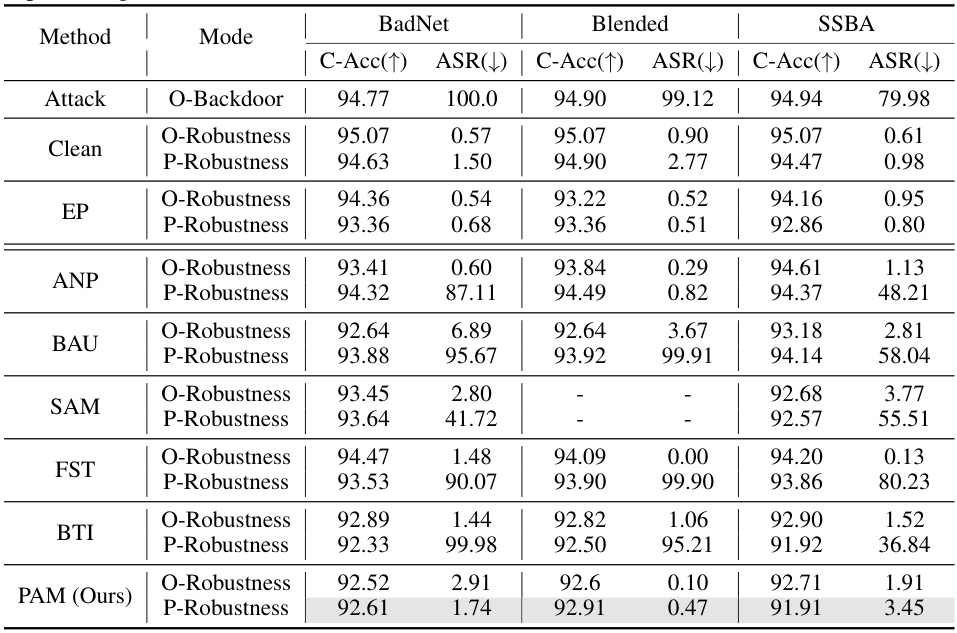
This table presents the results of evaluating the post-purification robustness of different backdoor defense methods against the Retuning Attack (RA). It shows the clean accuracy (C-Acc), attack success rate (ASR) before purification (O-Backdoor), after purification (O-Robustness), and after the RA is applied (P-Robustness). The results are shown for four different backdoor attacks (BadNet, Blended, SSBA, LC) and several defense methods (Clean, EP, ANP, BAU, SAM, FST, BTI, PAM). The table helps to understand how well the different defense methods eliminate backdoor features and resist reactivation of the backdoor after purification.
This table presents the results of a comparative analysis of different backdoor defense methods. It shows the original attack success rate (O-Backdoor), the success rate after purification (O-Robustness), and the success rate after a retuning attack (P-Robustness). The analysis is performed on the CIFAR-10 dataset using ResNet-18 architecture and a 5% poisoning rate. The methods compared include EP, ANP, BAU, SAM, FST, BTI, and the proposed PAM method.
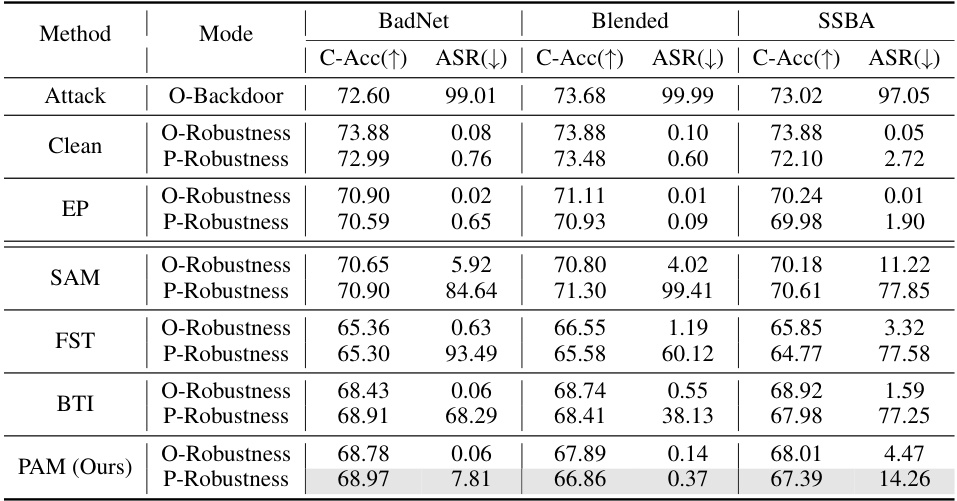
This table presents the results of evaluating the post-purification robustness of different backdoor defense methods against the Retuning Attack (RA). It shows the clean accuracy (C-Acc), attack success rate (ASR) before (O-Robustness) and after (P-Robustness) applying the RA for different methods: EP, ANP, BAU, SAM, FST, BTI and PAM. The comparison highlights the effectiveness of PAM in maintaining robustness after the RA.

This table presents the results of experiments evaluating the performance of the Path-Aware Minimization (PAM) defense method with different values of hyperparameter ‘p’ against the Blended backdoor attack. The O-Robustness column shows the attack success rate (ASR) after the initial purification with PAM, while the P-Robustness column shows the ASR after a retuning attack (RA). This demonstrates the impact of ‘p’ on the post-purification robustness of the model.
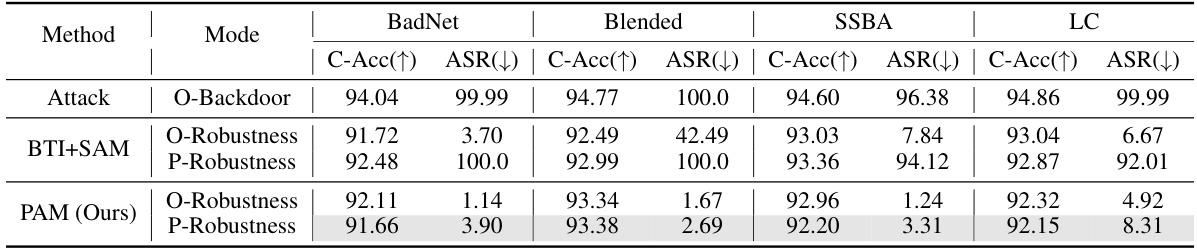
This table presents the results of the Path-Aware Minimization (PAM) defense method against the Retuning Attack (RA) on the CIFAR-10 dataset. It compares the original backdoor attack success rate (O-Backdoor), the purification performance of PAM (O-Robustness), and the post-purification robustness of PAM after RA (P-Robustness). The metrics used are Clean Accuracy (C-Acc) and Attack Success Rate (ASR), providing a comprehensive view of PAM’s effectiveness in mitigating superficial safety issues in backdoor defense.
Full paper#