↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Deep learning models are increasingly used for tabular data in various critical applications, yet their robustness against adversarial attacks remains largely unexplored. Existing attacks often fail to account for the unique properties of tabular data such as categorical features, immutability, and complex relationships among features. This lack of effective evaluation methods hinders the development of robust and secure models.
This paper introduces two novel attacks: CAPGD, an adaptive gradient-based attack that effectively handles feature constraints and CAA, an efficient evasion attack combining CAPGD and the state-of-the-art search-based attack MOEVA. Experiments demonstrate that CAA outperforms existing attacks, achieving significantly higher accuracy drops across various architectures and use cases, setting a new benchmark for evaluating adversarial robustness in tabular deep learning. The findings underscore the urgent need for robust model architectures and effective defense mechanisms against such attacks in real-world tabular data applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for robust deep learning models in tabular data, a widely used data format in many sensitive applications. The proposed attacks (CAPGD and CAA) set a new benchmark for evaluating adversarial robustness, pushing the field to develop more secure models and prompting new research directions in defense mechanisms. This work significantly advances the understanding and improvement of adversarial robustness in tabular machine learning.
Visual Insights#
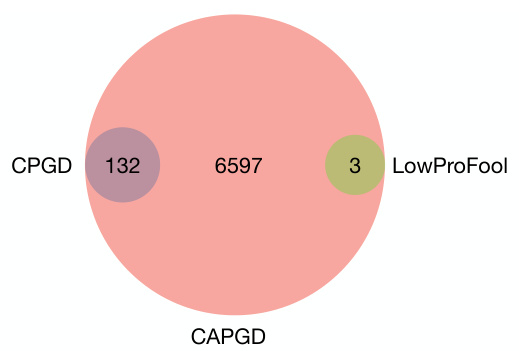
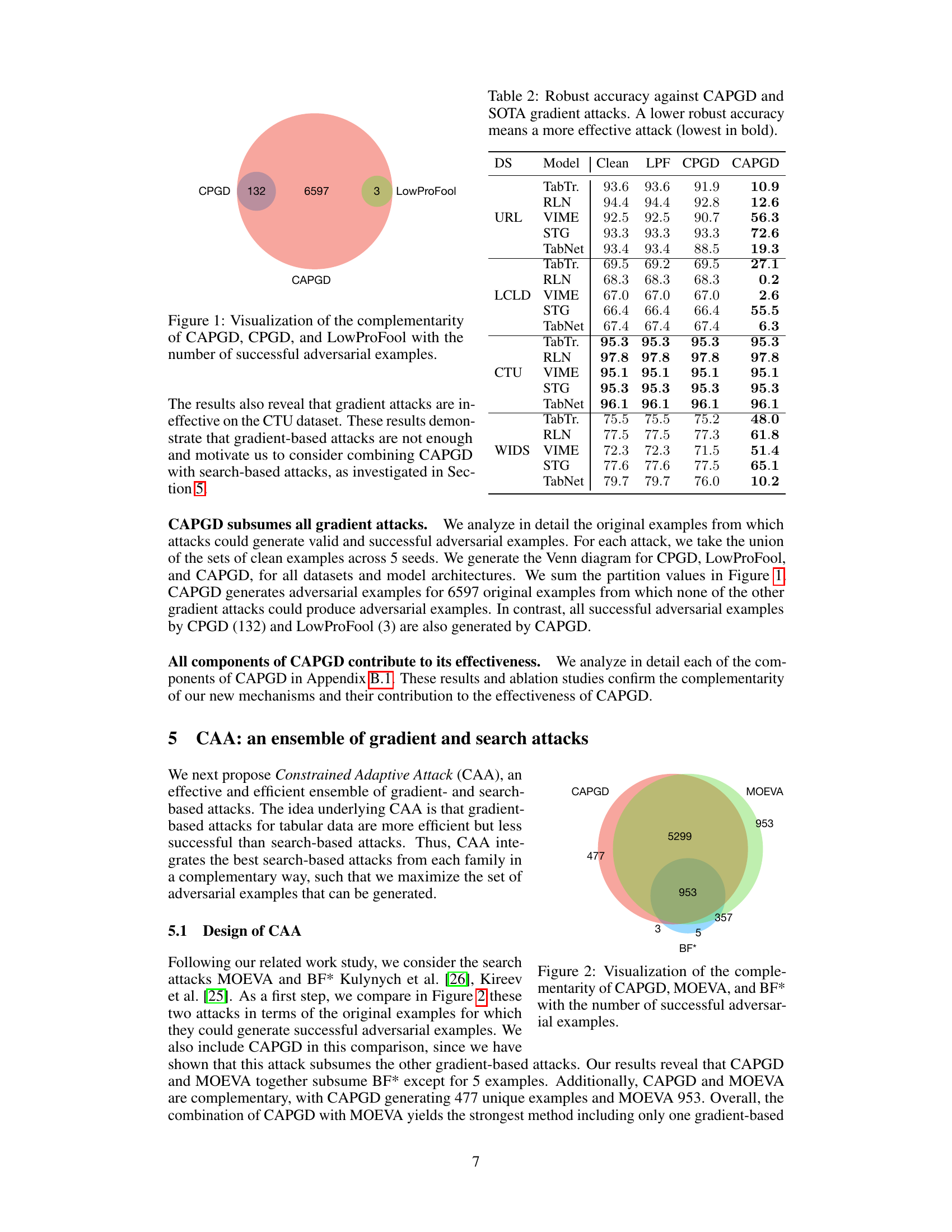
This figure shows a Venn diagram illustrating the number of successful adversarial examples generated by three different gradient-based attacks: CAPGD, CPGD, and LowProFool. The largest circle represents CAPGD, indicating it produced the most successful adversarial examples. The smaller circles for CPGD and LowProFool are mostly contained within the CAPGD circle, showing that CAPGD generated all the successful examples produced by the other two methods and a substantial number of additional, unique successful attacks. This visually demonstrates the superior performance of CAPGD compared to its predecessors.
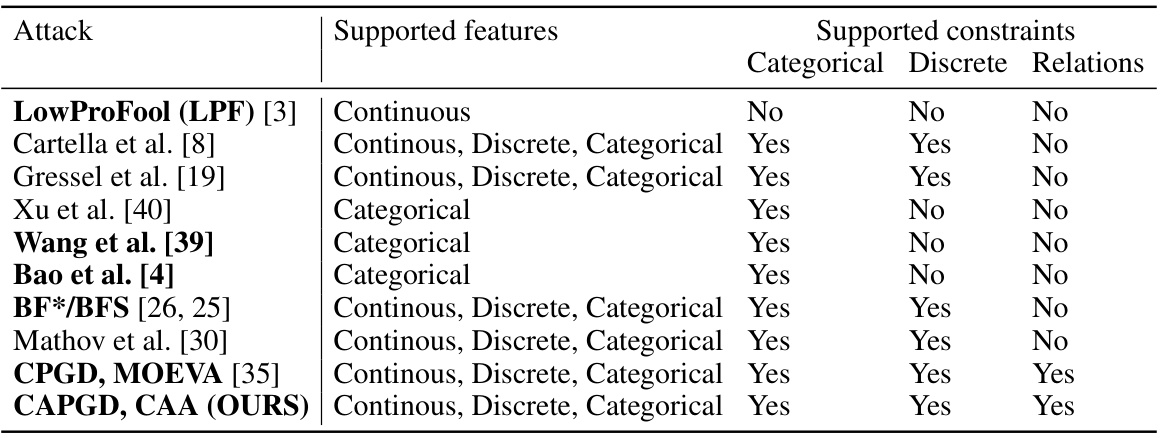
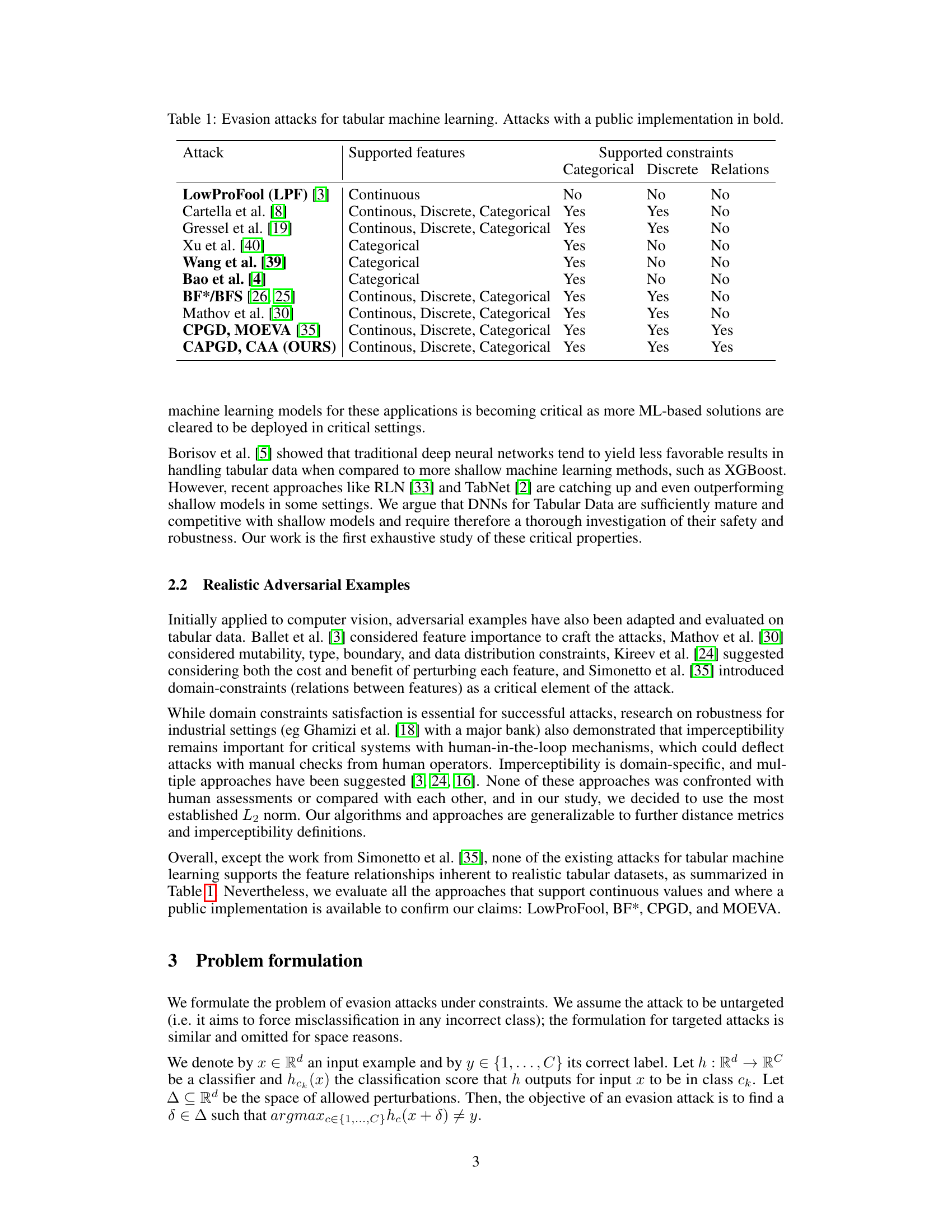
This table compares existing evasion attacks for tabular data. For each attack, it shows the types of features supported (continuous, discrete, categorical), and whether it supports various types of constraints (categorical, discrete, relational). Attacks with publicly available implementations are highlighted in bold. This table helps contextualize the authors’ work by showing how their proposed attacks, CAPGD and CAA, compare to existing methods in terms of feature and constraint support.
In-depth insights#
Adaptive Attack#
The concept of an ‘Adaptive Attack’ in the context of adversarial machine learning signifies a significant advancement over traditional attacks. Adaptive attacks dynamically adjust their strategies based on the model’s response, unlike static attacks which utilize a pre-defined approach. This adaptive nature makes them significantly more potent and challenging to defend against. The core of such an adaptive system likely involves a feedback loop where the attacker observes the model’s reaction to a perturbation and uses this information to refine the subsequent attack. This could involve techniques such as gradient-based optimization, evolutionary algorithms, or reinforcement learning. The effectiveness of an adaptive attack would be highly dependent on the sophistication of the adaptation mechanism as well as its ability to circumvent existing defenses. A well-designed adaptive attack represents a substantial threat to the robustness of machine learning systems, pushing the need for more resilient and adaptive defense strategies.
Tabular Robustness#
The robustness of tabular deep learning models is a relatively unexplored area compared to computer vision or NLP. This is largely due to the unique characteristics of tabular data, such as the presence of categorical features, feature relationships, and immutability constraints. Existing gradient-based attacks often fail to generate valid adversarial examples because they don’t effectively handle these constraints. Search-based attacks, while more successful, are computationally expensive. This paper highlights the critical need for effective and efficient adversarial attacks specifically designed for tabular data, showcasing a significant gap in current research. The authors propose CAPGD and CAA to overcome existing limitations and demonstrate their effectiveness and efficiency across diverse datasets and model architectures. The work underscores that deeper investigation into the adversarial robustness of tabular deep learning models is crucial for deploying reliable and secure ML systems in real-world applications.
CAA Efficiency#
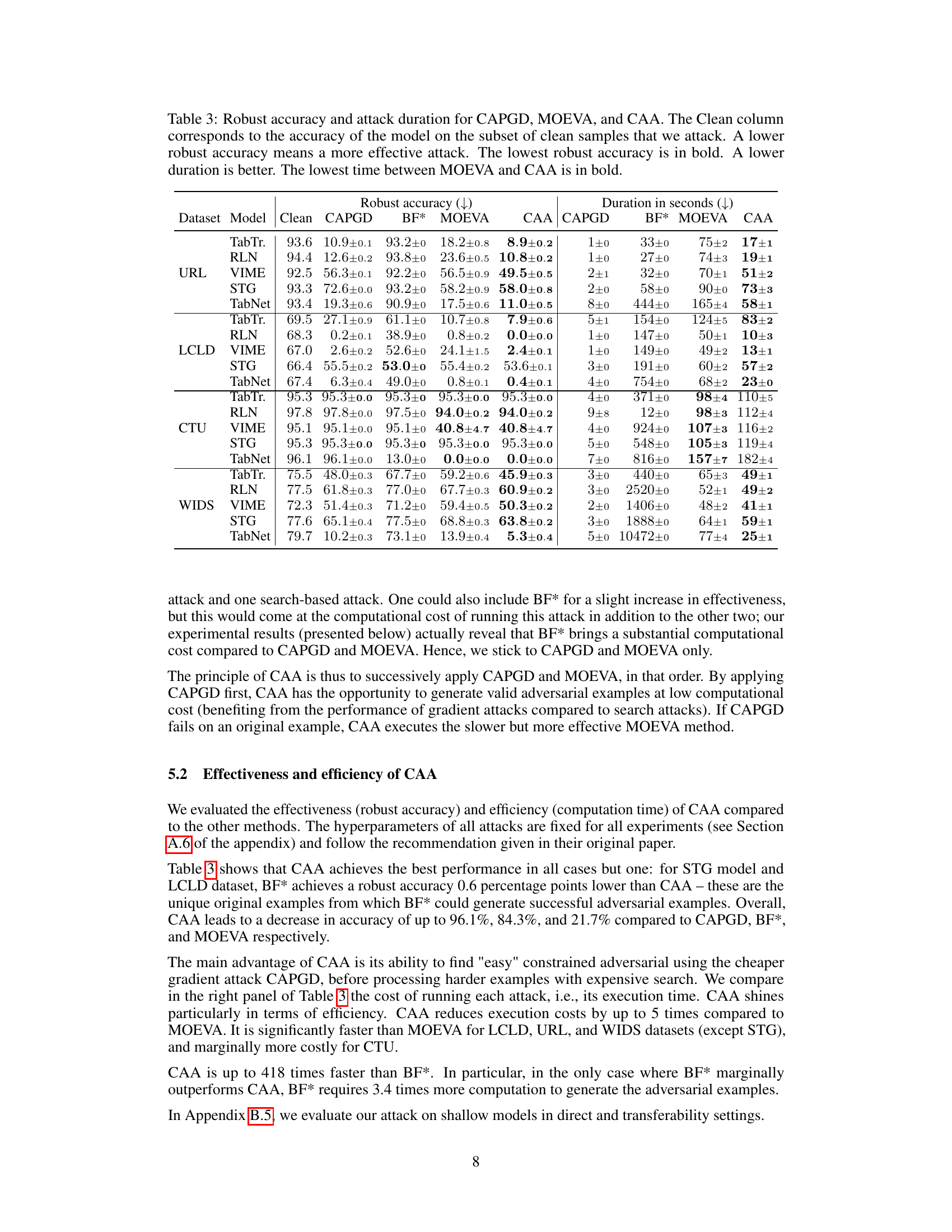
The efficiency of the Constrained Adaptive Attack (CAA) is a crucial aspect of its practicality. CAA cleverly combines the speed of gradient-based attacks with the higher success rate of search-based methods. This hybrid approach leads to significant computational savings, particularly when compared to solely using search-based attacks like MOEVA. The paper highlights that CAA is up to five times faster than MOEVA while achieving comparable or even superior results in many cases. This enhanced efficiency is primarily due to CAPGD, the novel gradient-based component of CAA, which efficiently generates many valid adversarial examples before resorting to the more computationally expensive search method. The parameter-free nature of CAPGD further contributes to the overall efficiency, eliminating the need for extensive hyperparameter tuning. The effectiveness of CAA despite its efficiency showcases a powerful balance between speed and attack success, making it a significant advancement in adversarial attacks against tabular data.
Attack Limits#
The heading ‘Attack Limits’ suggests an exploration of the boundaries and constraints affecting adversarial attacks against deep learning models for tabular data. A thoughtful analysis would delve into factors limiting attack effectiveness, such as the inherent characteristics of tabular data (categorical features, relationships between features), constraints on data manipulation, and computational costs. The discussion might cover limitations of gradient-based attacks, which are often hampered by the non-convexity of the loss landscape and the difficulty in maintaining data integrity while generating adversarial examples. Furthermore, it could explore limitations of search-based approaches regarding their computational expense, scalability and ability to guarantee valid adversarial samples within feasible bounds. The analysis should also consider the impact of defense mechanisms, such as adversarial training or data augmentation techniques, on attack effectiveness. By exploring the limitations and examining specific attack scenarios, the analysis can provide insights into the robustness of tabular deep learning models and guide future research towards developing more resilient systems and potentially more effective attack methods.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency of the CAA attack is crucial, particularly for larger datasets. Investigating adaptive mechanisms beyond those currently implemented in CAPGD could further enhance evasion success rates. Extending the research to other types of tabular data with unique constraints and relationships is vital to establish the generalizability of the findings. Developing robust defenses against these adaptive attacks presents a key challenge, requiring new approaches that account for the constraints inherent in tabular data. A deeper analysis of the relationship between model architecture and attack effectiveness would improve our understanding of vulnerabilities and guide the design of more robust models. Furthermore, research on transferability of these attacks across different models and datasets warrants further investigation to develop more generalizable defense strategies. Ultimately, exploring the impact of these attacks on real-world applications is crucial to understanding the implications of adversarial robustness and guide the development of trustworthy and secure machine learning systems.
More visual insights#
More on figures
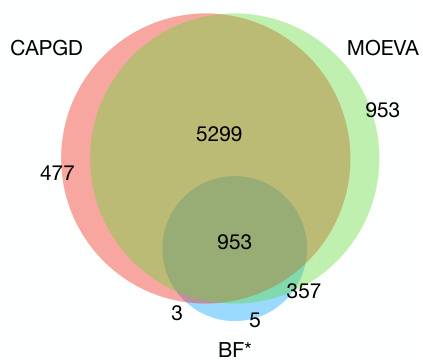
This figure is a Venn diagram showing the number of successful adversarial examples generated by three different attacks: CAPGD, MOEVA, and BF*. The overlapping areas show the number of examples successfully attacked by combinations of the attacks, illustrating their complementary strengths and the overall number of unique successful attacks achieved by combining CAPGD and MOEVA.
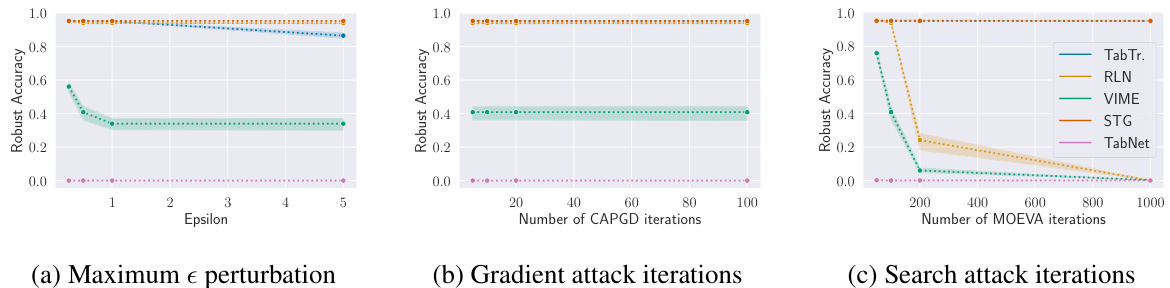
This figure shows how the robust accuracy of different models on the CTU dataset is affected by varying the budget allocated to the different components of the CAA attack. Specifically, it explores the impact of maximum epsilon perturbation, the number of CAPGD iterations (gradient attack), and the number of MOEVA iterations (search attack). The results illustrate how the effectiveness of CAA changes based on these different resource allocations.
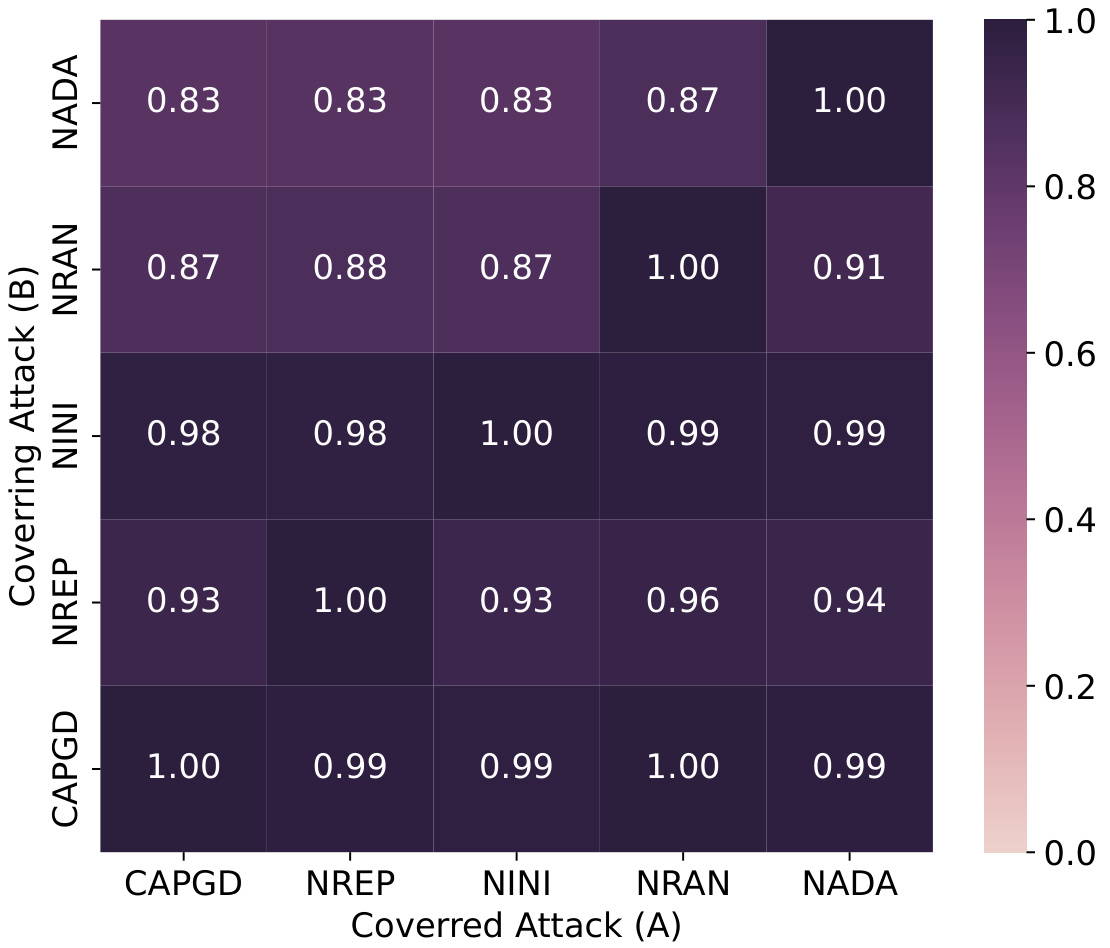
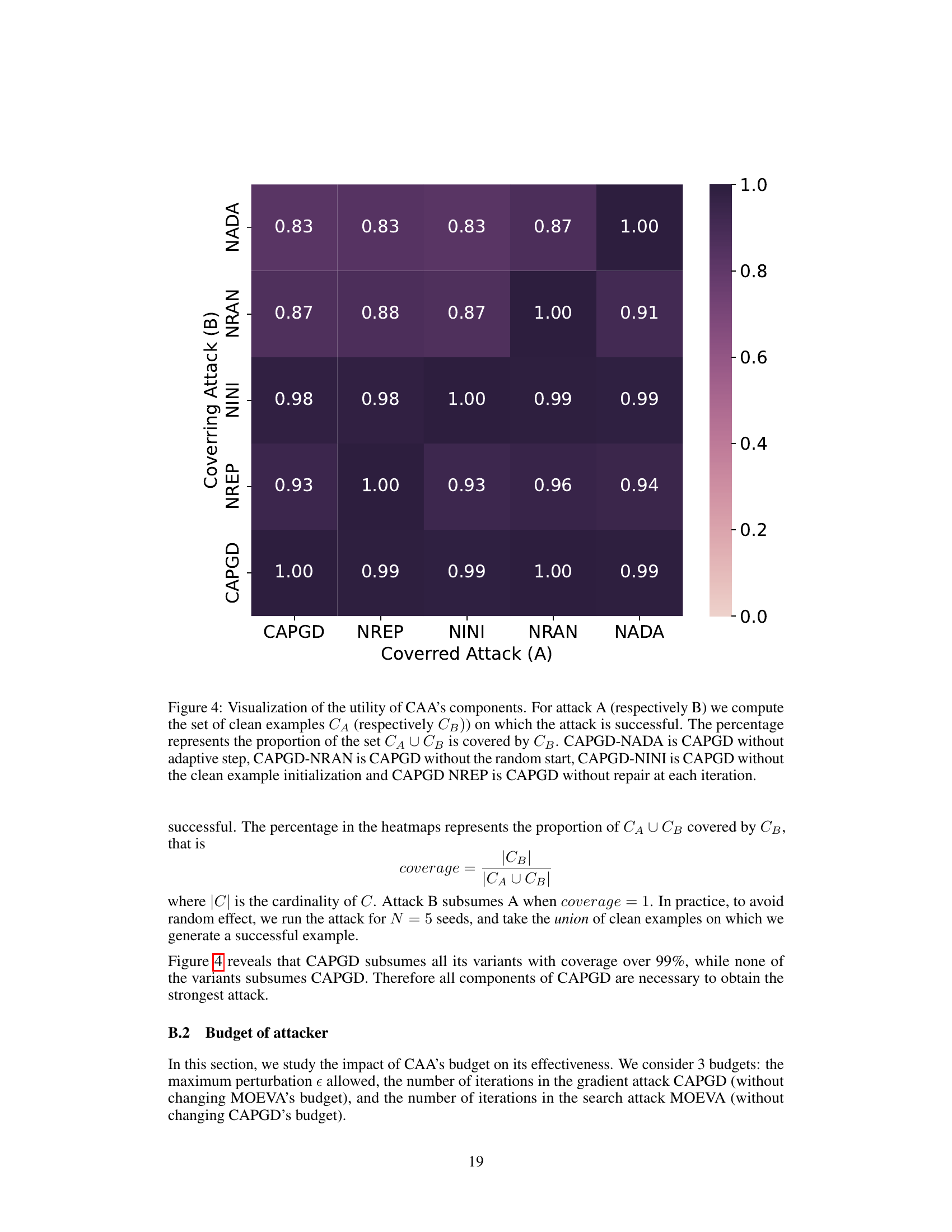
This figure shows a heatmap visualizing the complementarity of different components within the CAPGD attack. Each cell represents the percentage of successful adversarial examples generated by one CAPGD variant (covered attack, A) that are also generated by another variant (covering attack, B). The darker the cell, the higher the overlap and thus the stronger complementarity between the components. This analysis reveals that removing any single component diminishes the overall effectiveness of the CAPGD attack.
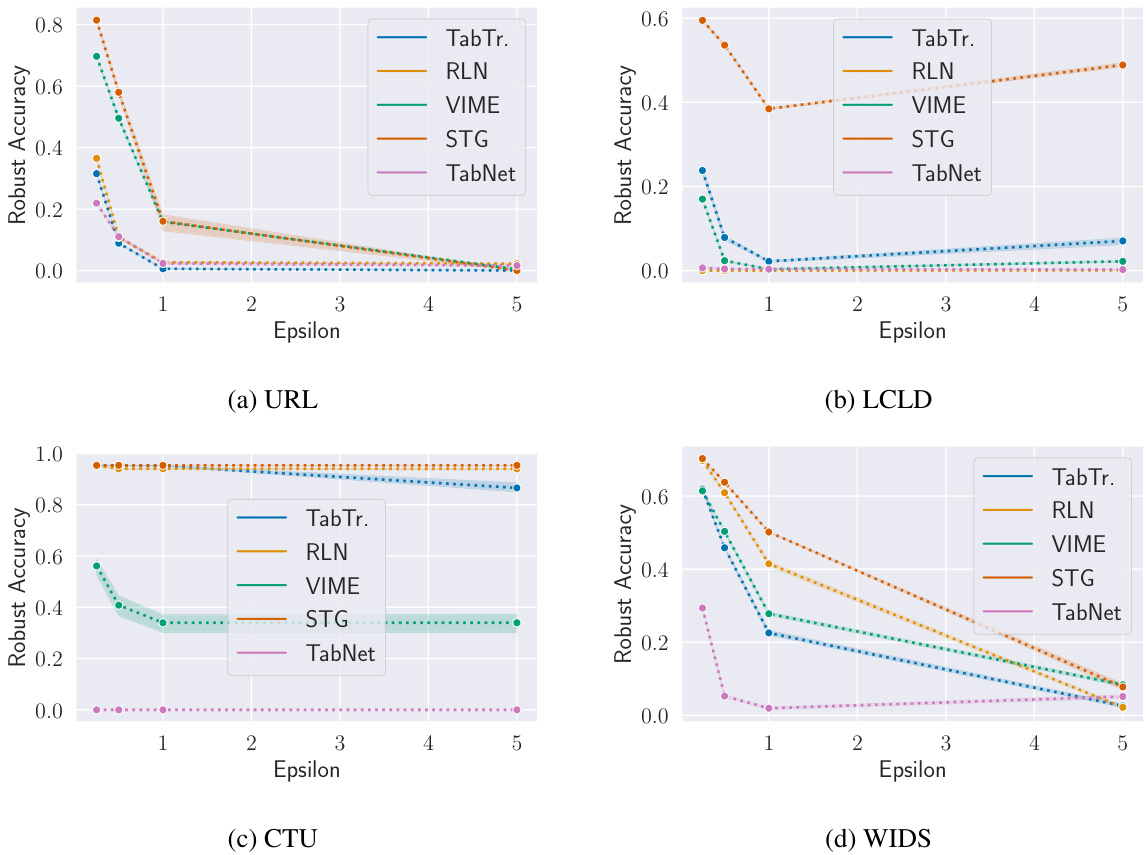
This figure displays the impact of varying the maximum perturbation (epsilon) on the robust accuracy of different models using the Constrained Adaptive Attack (CAA). Each subplot represents a different dataset (URL, LCLD, CTU, WIDS). The x-axis shows the epsilon values, and the y-axis shows the robust accuracy. Different colored lines represent different model architectures (TabTr, RLN, VIME, STG, TabNet). The figure demonstrates how changes in the maximum allowable perturbation affect the models’ robustness to adversarial attacks.
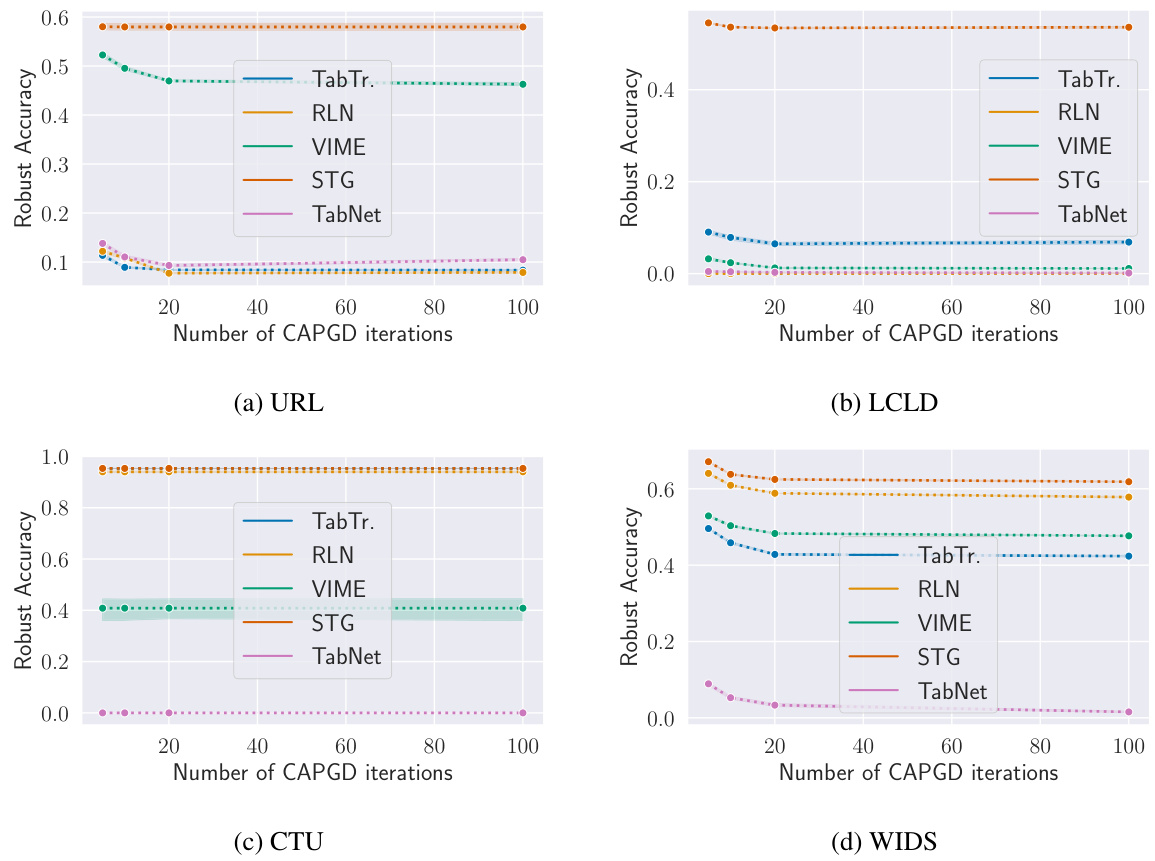
The figure analyzes how the robust accuracy of models on the CTU dataset changes when varying different aspects of the CAA attack budget. Three subplots show the effect of adjusting the maximum perturbation (epsilon) allowed for adversarial examples, the number of iterations for the CAPGD (gradient-based) attack component, and the number of iterations for the MOEVA (search-based) attack component. The results illustrate the tradeoffs between these different parameters in determining the effectiveness of the CAA attack.
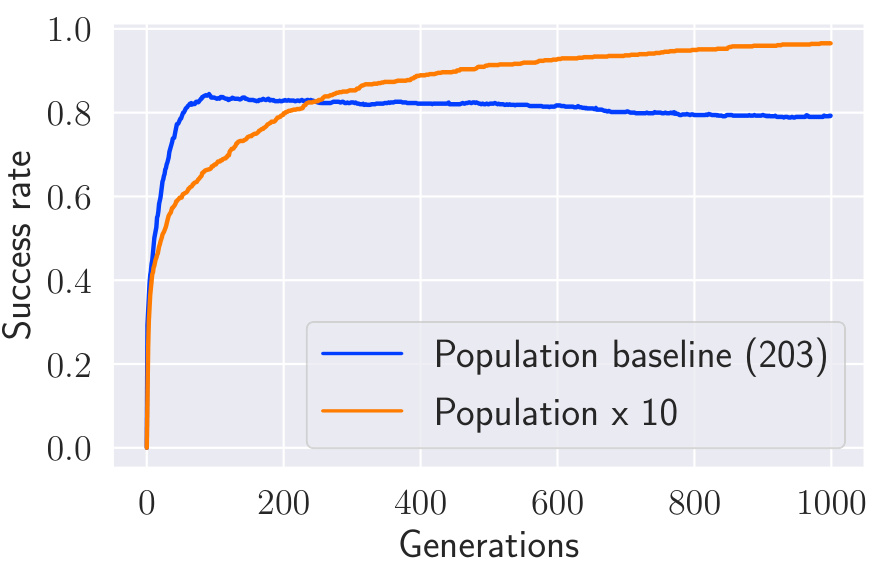
This figure shows the success rate of the MOEVA algorithm over generations for two different population sizes: the baseline population size (203) and a population size 10 times larger (2030). The plot demonstrates how increasing the population size affects the convergence speed and overall success rate of finding adversarial examples for the LCLD dataset using a TabTransformer model. The larger population converges more slowly but ultimately achieves a higher success rate.
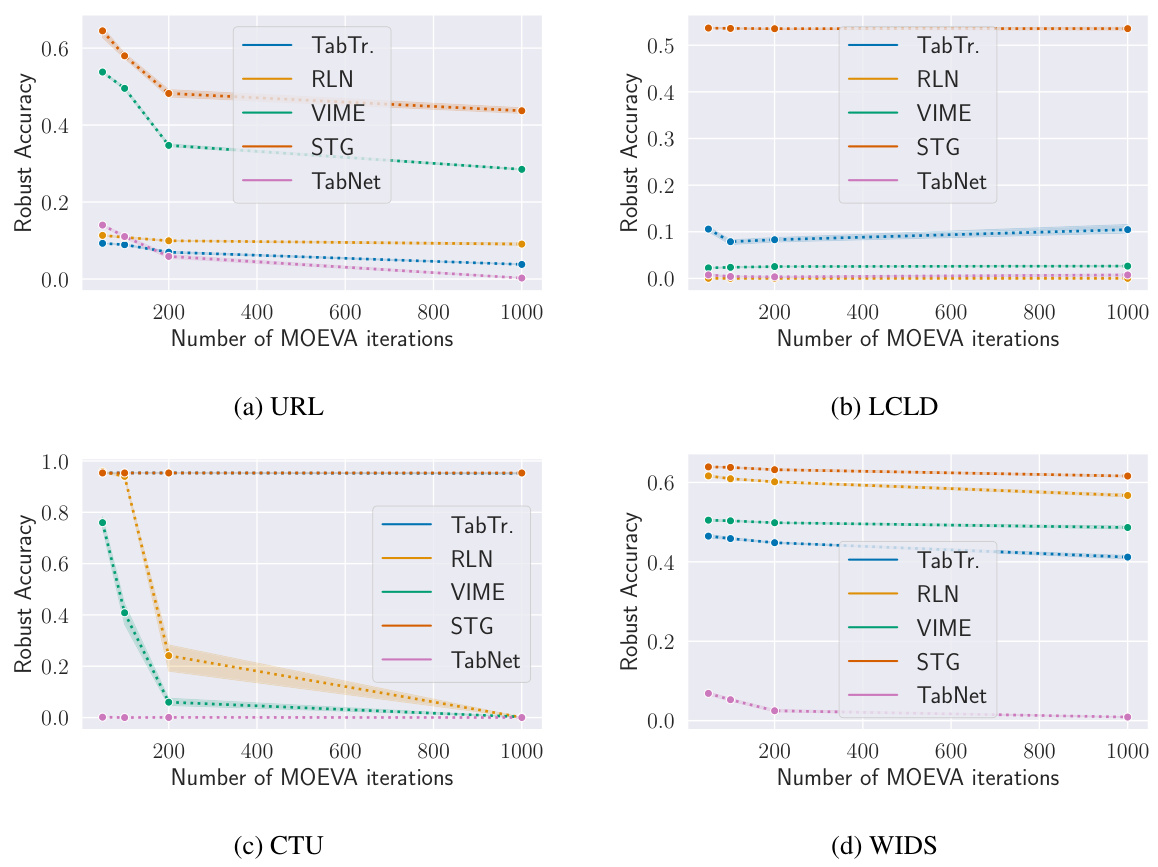
This figure shows the impact of different budget allocations on the robustness of the CAA attack against the CTU dataset. It consists of four sub-figures: (a) shows the effect of varying the maximum perturbation (epsilon); (b) shows the effect of varying the number of iterations for the gradient attack component (CAPGD); (c) shows the effect of varying the number of iterations for the search attack component (MOEVA); and (d) shows the number of iterations for both CAPGD and MOEVA.
More on tables
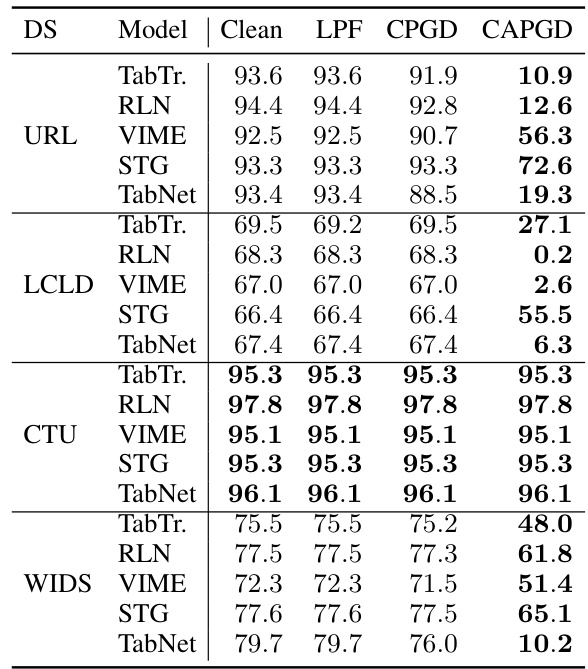
This table presents the robust accuracy achieved by various gradient-based attacks, including CAPGD, LowProFool, and CPGD, across different datasets (URL, LCLD, CTU, WIDS) and five different model architectures. A lower robust accuracy indicates that the corresponding attack is more effective at generating adversarial examples that fool the model. The table highlights that CAPGD outperforms the other gradient attacks in most cases.
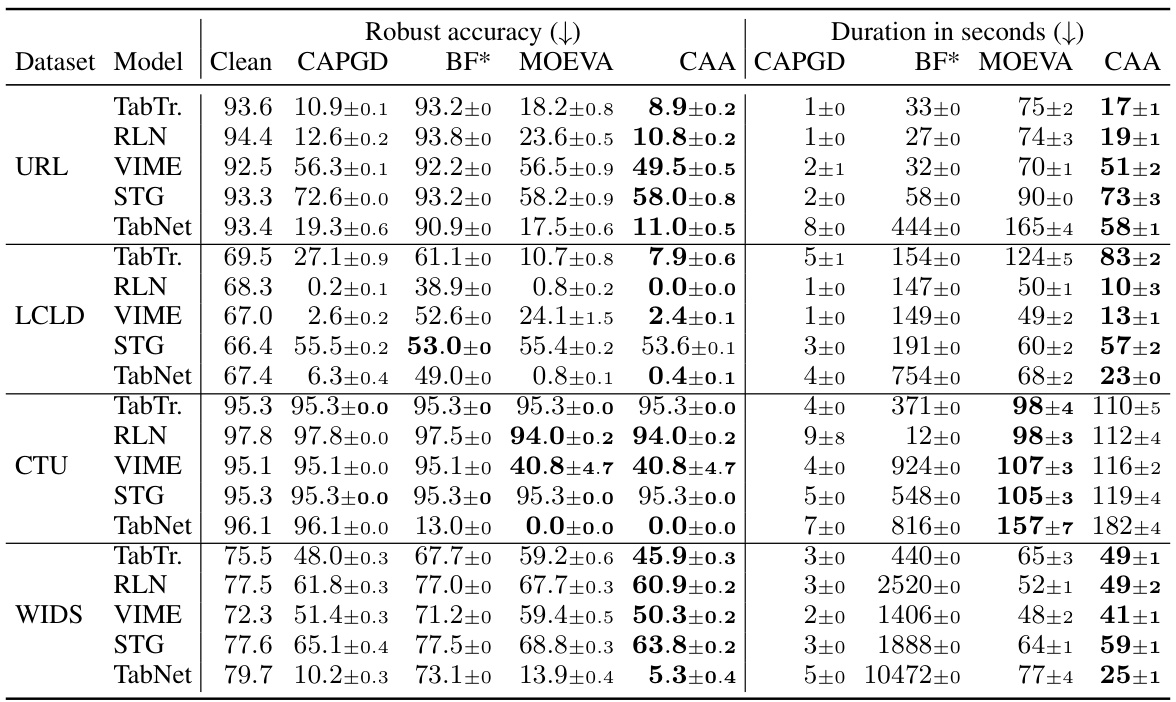
This table presents a comparison of the robustness and efficiency of three different adversarial attacks: CAPGD, MOEVA, and CAA. The ‘Clean’ column shows the model’s accuracy on unattacked samples. Lower robust accuracy values indicate a more effective attack. The table shows that CAA generally achieves the lowest robust accuracy (most effective attack), and in many cases, does so more efficiently (shorter duration) than MOEVA.
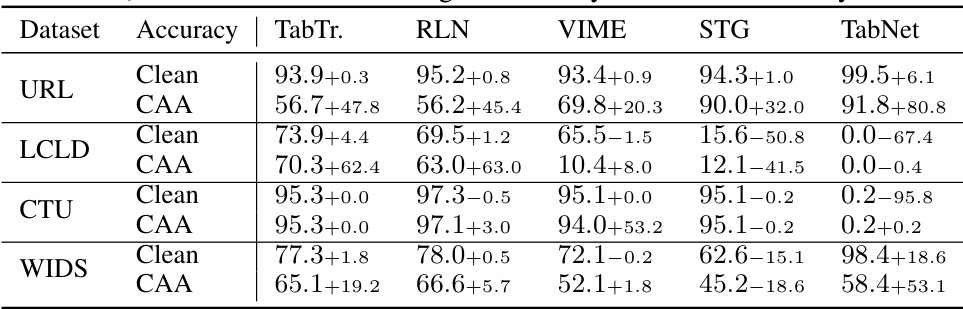
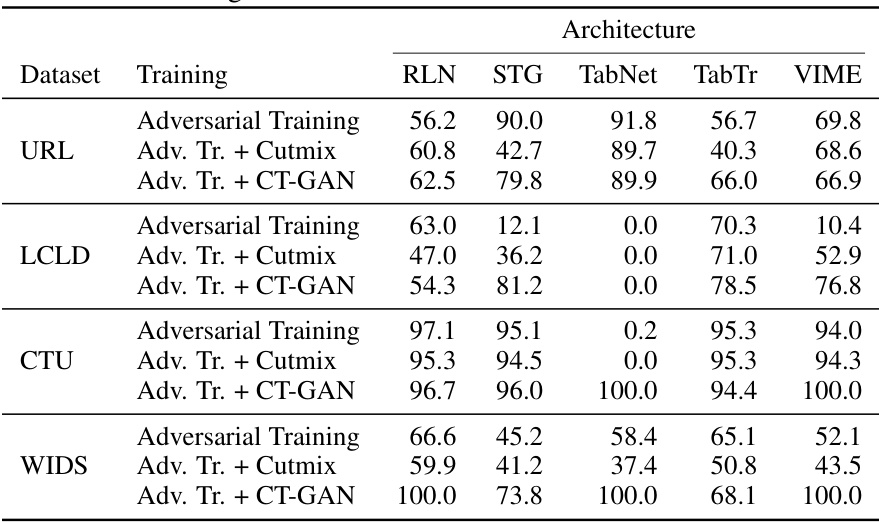
This table presents the performance of the proposed Constrained Adaptive Attack (CAA) against models trained using Madry’s adversarial training. It compares the clean accuracy and the robust accuracy (against CAA) of the adversarially trained models with those trained using standard training methods, highlighting the improvement or degradation in model performance resulting from the adversarial training.
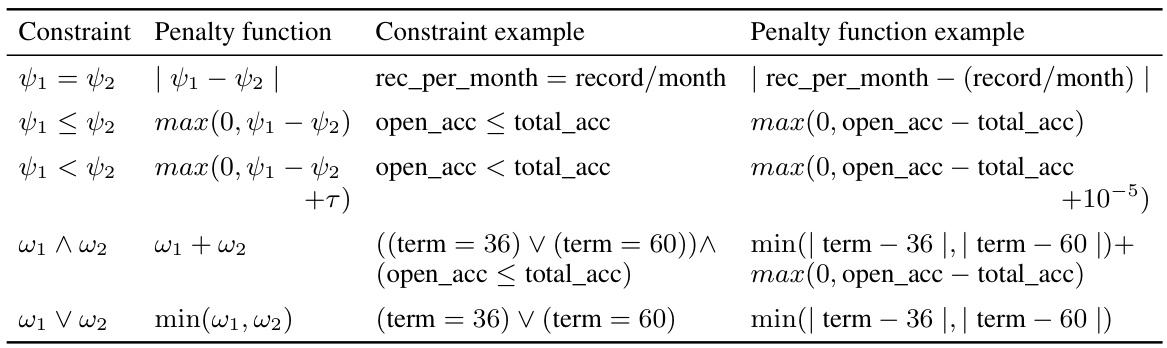
This table compares different evasion attacks designed for tabular data. It details which types of features (continuous, discrete, categorical) each attack supports and whether it accounts for categorical features, discrete features, or the relationships between features. Attacks with publicly available implementations are highlighted in bold. The table helps to illustrate the novelty of the proposed CAPGD and CAA attacks, which are the only ones that support all three feature types and feature relationships.

This table presents the characteristics of the four datasets used in the paper’s empirical study. For each dataset, it lists the task it is designed for, the number of data instances (size), the number of features, and the percentage of instances belonging to each class (class imbalance). The datasets represent diverse domains including credit scoring, botnet detection, phishing URL detection, and ICU patient survival.

This table presents the three model architectures used in the study: TabTransformer and TabNet (both transformer-based models), RLN (Regularization Learning Networks), STG (Stochastic Gates), and VIME (Value Imputation for Mask Estimation). It lists the family to which each model belongs and the hyperparameters tuned for each model during training.
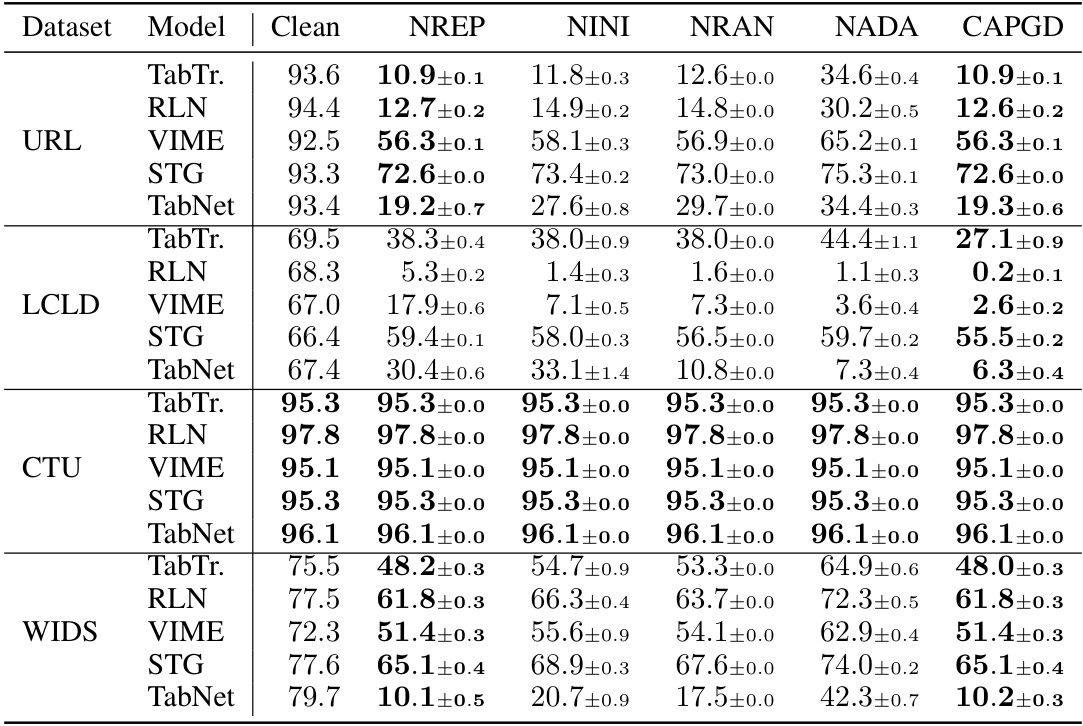
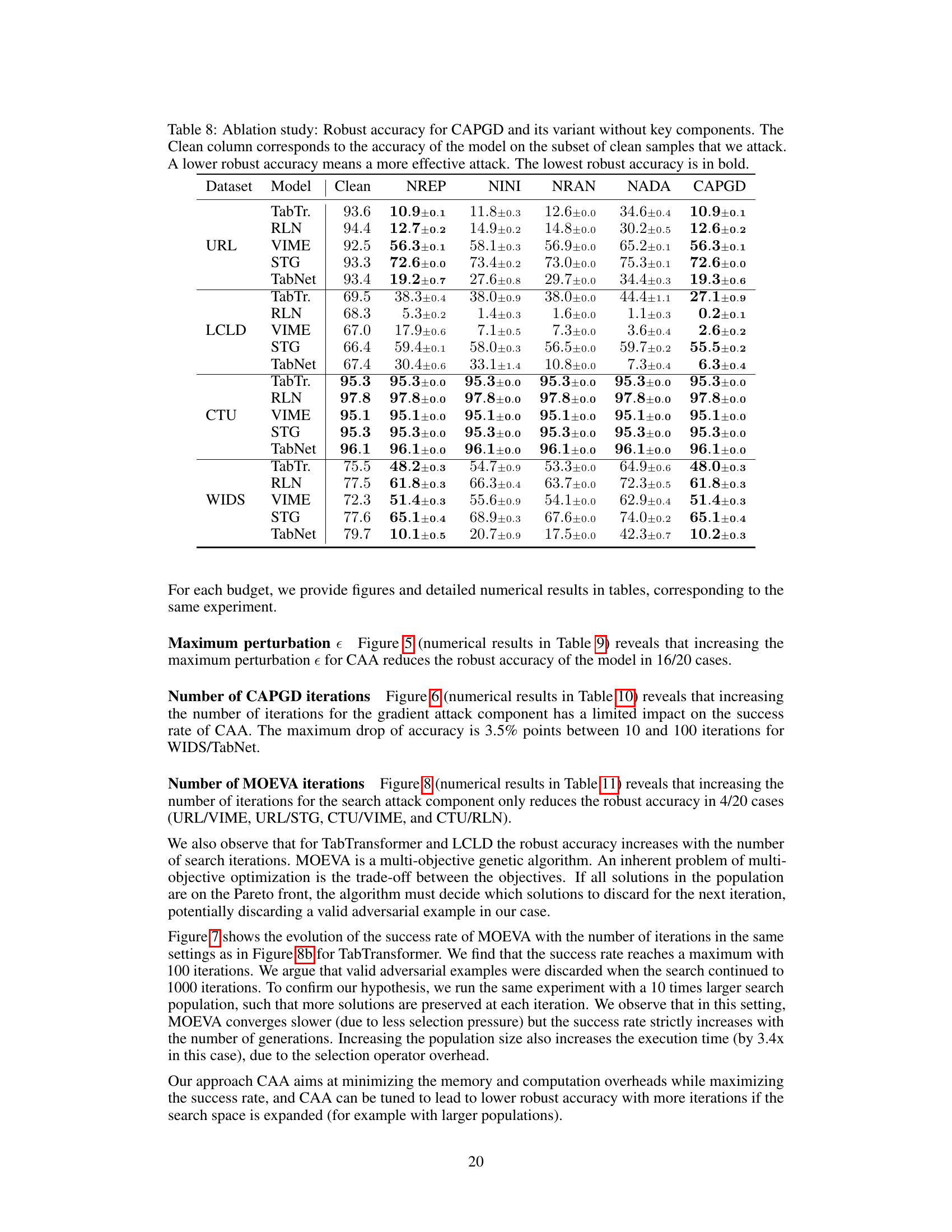
This table presents the results of an ablation study conducted to evaluate the impact of different components of the CAPGD attack on its effectiveness. The study removes one component at a time (repair operator, initialization with clean example, random initialization, and adaptive step size). The table shows the robust accuracy (i.e., accuracy against adversarial examples) for each variant of the attack, as well as the original CAPGD attack, across different datasets and models. A lower robust accuracy indicates a more effective attack.
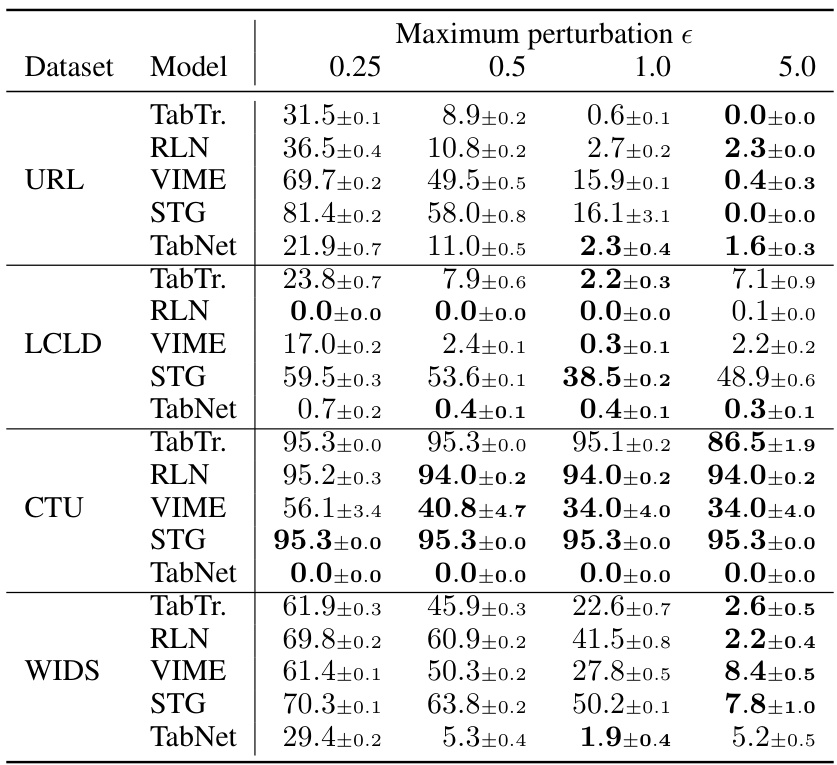
This table presents the robust accuracy results of the Constrained Adaptive Attack (CAA) against various models (TabTr, RLN, VIME, STG, TabNet) across four datasets (URL, LCLD, CTU, WIDS) with varying maximum perturbation thresholds (e). Lower robust accuracy values indicate a more effective attack. The results show how the attack’s success changes depending on the model and dataset used.

This table shows the results of an ablation study on the number of iterations used in the CAPGD attack component of the CAA framework. It presents the robust accuracy achieved against each model (TabTr., RLN, VIME, STG, TabNet) for four different datasets (URL, LCLD, CTU, WIDS) at various numbers of CAPGD iterations (5, 10, 20, 100). The lowest robust accuracy for each configuration is highlighted in bold, indicating the most effective attack.

This table presents a comparison of the effectiveness and efficiency of three different evasion attacks (CAPGD, MOEVA, and CAA) against five different architectures on four different datasets. Effectiveness is measured by robust accuracy (lower is better), indicating the ability of each attack to cause misclassification. Efficiency is measured by the time taken for the attack to complete (lower is better). The ‘Clean’ column shows the baseline accuracy of the model on the unperturbed data. The table highlights that CAA generally achieves the highest effectiveness and a better balance of effectiveness and efficiency compared to the other methods.
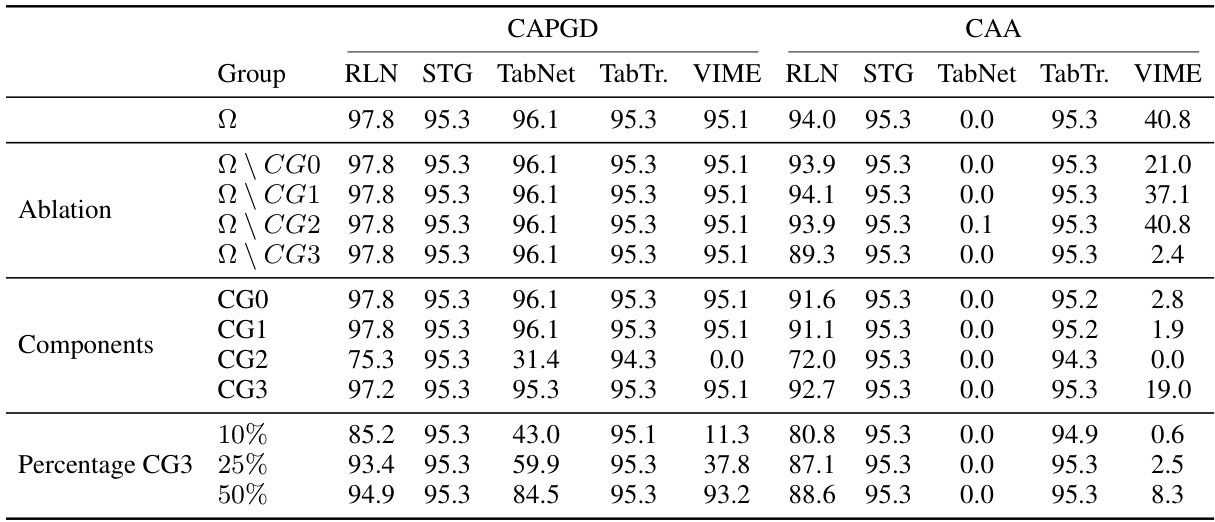
This table presents the robust accuracy results obtained using CAPGD and CAA with different subsets of constraints from the CTU dataset. The ‘Ω’ row represents the full set of constraints, while the subsequent rows show results after removing or only using specific groups (CG0, CG1, CG2, CG3) of constraints. For CG2 and CG3, various percentages (10%, 25%, 50%) of randomly selected constraints were also evaluated. The goal is to study how the number and complexity of constraints influence the effectiveness of the attacks.
This table presents the performance of three different adversarial attacks (CAPGD, MOEVA, and CAA) on various datasets and machine learning models. The ‘Clean’ column shows the accuracy of the model on the original, unperturbed data. The lower the robust accuracy, the more effective the attack is. The duration shows the time it takes for each attack to generate adversarial examples. The table highlights that CAA generally achieves the lowest robust accuracy (highest effectiveness) and is often significantly faster than MOEVA, especially when combining gradient-based attacks with search-based attacks.
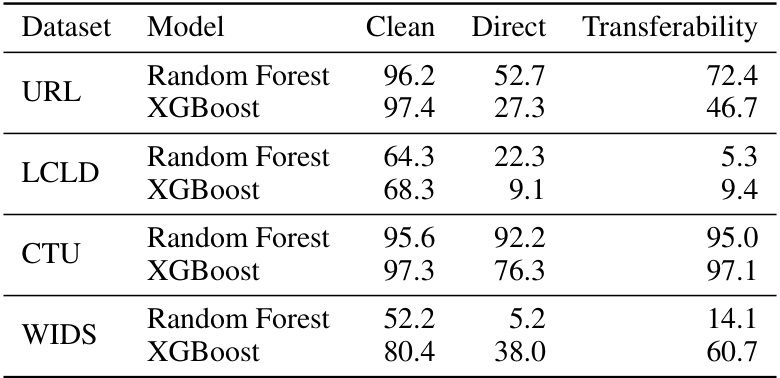
This table presents the clean accuracy, direct attack robust accuracy, and transferability robust accuracy for Random Forest and XGBoost models across four datasets (URL, LCLD, CTU, and WIDS). The transferability results show the robustness when adversarial examples generated against deep learning models are tested against the tree-based models. Lower accuracy indicates a more effective attack.
Full paper#