↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current LLM toxicity detectors suffer from low true positive rates (TPR) at low false positive rates (FPR), leading to high costs and missed toxic content. They also often add significant latency and computational overhead. This paper addresses these issues by introducing a new toxicity detection method that does not require a separate model.
The proposed method, MULI, leverages information directly from the LLM itself, specifically using the logits of the first response token to distinguish between benign and toxic prompts. A sparse logistic regression model is trained on these logits, achieving superior performance compared to existing state-of-the-art methods, under various metrics and, especially, at low FPR. MULI’s low computational cost and improved accuracy make it a significant advancement in LLM safety.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, low-cost method for toxicity detection in LLMs that significantly outperforms existing methods, especially at low false positive rates. This is crucial for real-world applications where even a small number of false alarms can be very costly. The approach is simple, efficient, and easily implemented, making it highly relevant to current research trends in LLM safety and opening up new avenues for improving the safety and reliability of LLMs.
Visual Insights#
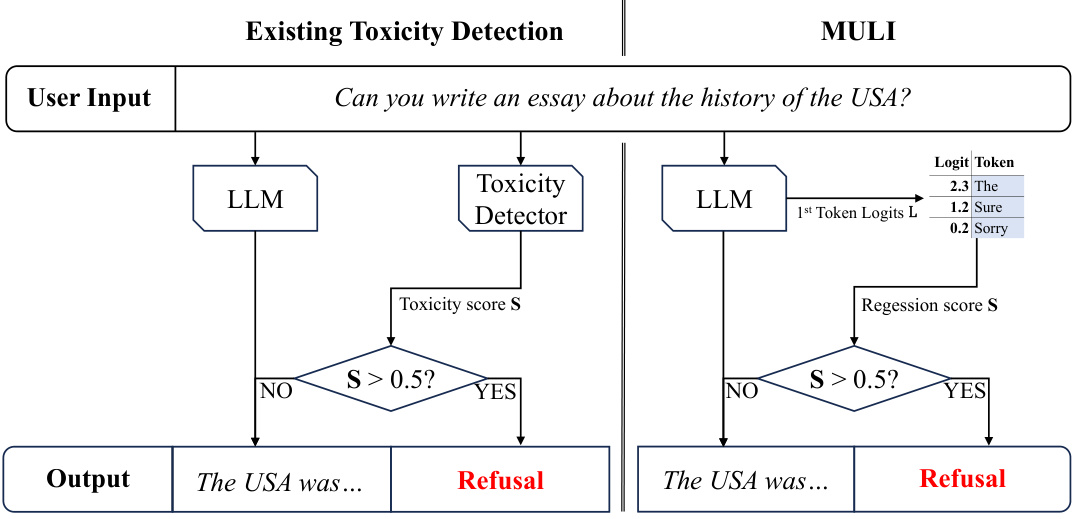
This figure illustrates the difference between existing toxicity detection methods and the proposed MULI method. Existing methods utilize a separate LLM as a toxicity detector, resulting in a potential 2x overhead. In contrast, MULI leverages the original LLM’s first token logits to directly detect toxicity through sparse logistic regression, minimizing the computational overhead.
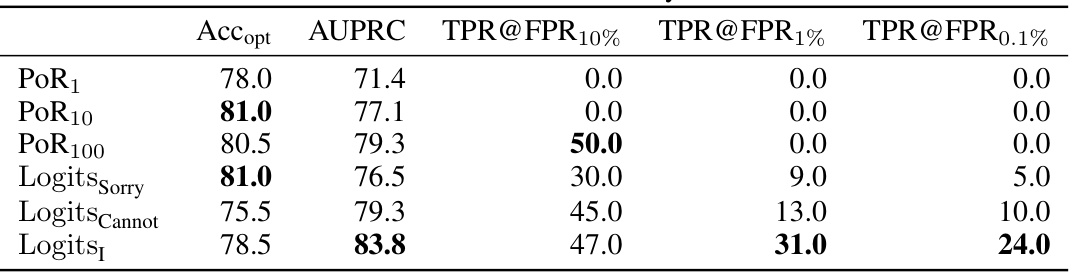
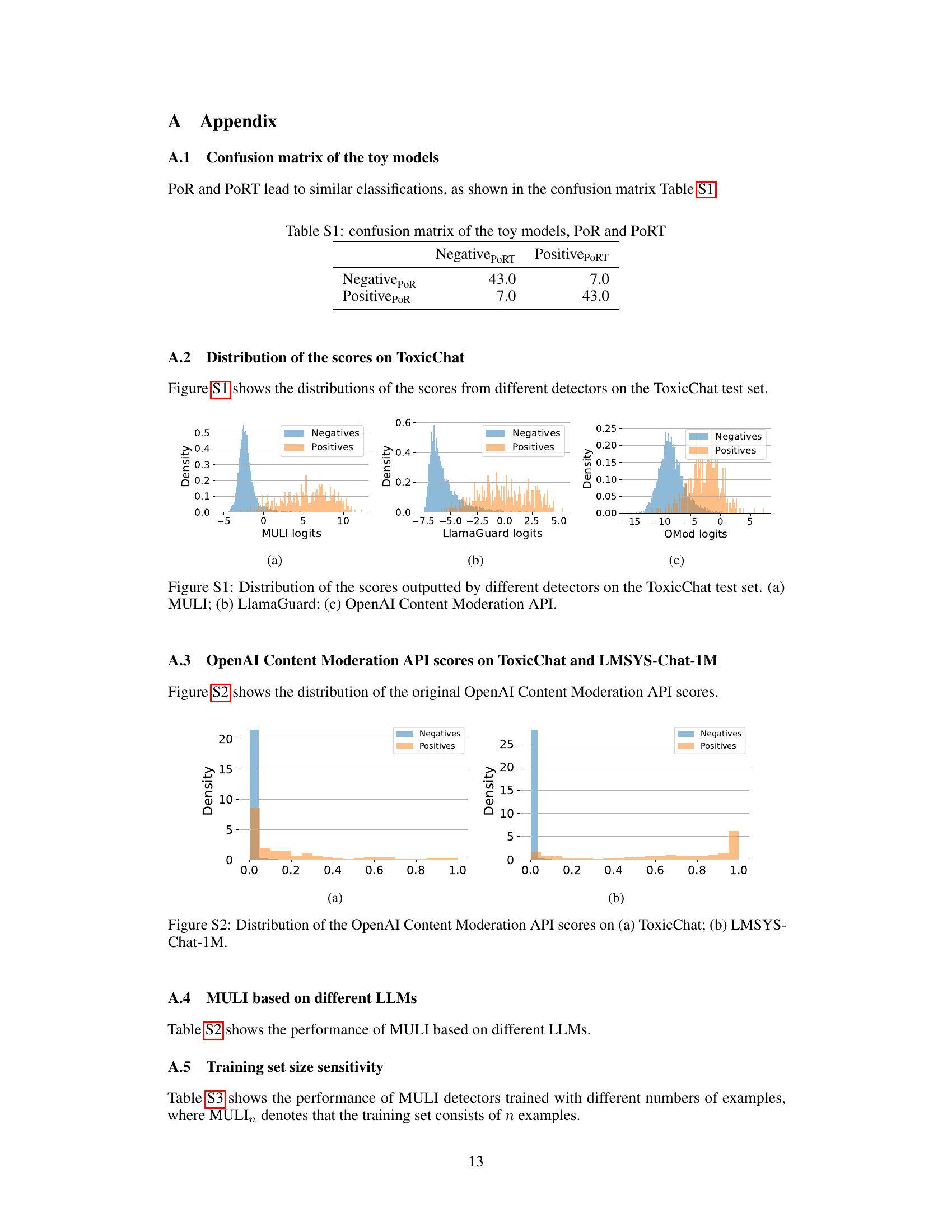
This table presents the performance of several toy models designed to detect toxic prompts. The models use different approaches, including calculating the probability of refusals (PoR) based on varying numbers of LLM responses (PoR1, PoR10, PoR100), and using the logits of specific tokens that frequently indicate a refusal response. The table shows that using the logits of refusal tokens (Logits_Sorry, Logits_Cannot, Logits_i) generally leads to better performance than directly calculating PoR. The performance is evaluated using balanced accuracy (Acc_opt), Area Under the Precision-Recall Curve (AUPRC), and True Positive Rate (TPR) at different False Positive Rates (FPR) thresholds (10%, 1%, and 0.1%). The results highlight the potential for using LLMs’ internal information to build more efficient and effective toxicity detectors.
In-depth insights#
LLM Introspection#
LLM introspection, as a concept, proposes a paradigm shift in how we evaluate and utilize large language models (LLMs). Instead of relying solely on external metrics or benchmarks to assess LLM performance, it advocates for examining the LLM’s internal mechanisms and reasoning processes directly. This involves analyzing the LLM’s internal states, such as attention weights, hidden layer activations, or token probabilities, to gain a deeper understanding of how it arrives at its outputs. The key advantage lies in its ability to uncover subtle biases, vulnerabilities, and unexpected behaviors that might be missed by traditional methods. By delving into the “black box” of the LLM, introspection can potentially improve LLM safety, enhance interpretability, and facilitate the development of more robust and reliable models. Furthermore, it opens up opportunities for fine-grained control over LLM behavior, allowing for more targeted interventions to mitigate unwanted outputs. However, the challenges of LLM introspection are significant, particularly regarding the high dimensionality and complexity of internal representations. Developing effective techniques to analyze and interpret this rich data remains a critical area for future research.
Toxicity Detection#
The concept of ‘Toxicity Detection’ in the context of large language models (LLMs) is crucial for responsible AI development. Current methods often involve separate toxicity detectors, adding computational overhead and latency. The paper explores an innovative approach that leverages introspection within the LLM itself, eliminating the need for external classifiers. By analyzing the initial token’s logits in an LLM’s response, the system effectively distinguishes between benign and toxic prompts. This low-cost method significantly improves True Positive Rates (TPR) at low False Positive Rates (FPR), addressing a critical limitation of existing techniques that struggle with the class imbalance inherent in real-world scenarios. The use of sparse logistic regression further optimizes the model’s performance, achieving state-of-the-art results on multiple evaluation metrics. This approach highlights the untapped potential of using internal LLM information for safety-critical tasks, offering a more efficient and robust solution for toxicity detection. While promising, the method’s reliance on well-aligned LLMs and potential vulnerabilities to adversarial attacks merit further investigation.
Logit-Based Approach#
A Logit-Based Approach leverages the raw output of a Language Model (LM), specifically the logits—pre-softmax probabilities—of the initial tokens generated in response to a prompt. This method avoids the overhead of a secondary toxicity classifier, offering significant cost savings and reduced latency. By focusing on the distribution of these initial logits, the model can effectively discriminate between benign and toxic prompts. The core idea is that toxic prompts trigger a higher probability of the LM generating ‘refusal’ tokens (e.g., ‘Sorry’, ‘I cannot’), reflected in their associated logits. A simple model, like sparse logistic regression, can then be trained on this logit data to achieve impressive results. Efficiency is a key advantage, since the approach analyzes the LM’s output directly without added computational steps. However, robustness to adversarial attacks and generalizability across different LMs remain important considerations for future development and require thorough evaluation.
Zero-Cost Method#
A ‘Zero-Cost Method’ in a research paper typically refers to a technique or approach that doesn’t necessitate additional computational resources or infrastructure beyond what is already available. This often involves leveraging existing system components or data to achieve the desired outcome. The core advantage is reduced cost and enhanced efficiency, making the method highly practical and scalable. However, such methods may have limitations. Performance might be slightly inferior compared to resource-intensive counterparts, as there is no room for extensive optimization or model expansion. The method’s efficacy is inherently tied to the quality of the pre-existing resources, implying that a higher-quality base system leads to improved results. Furthermore, a ‘zero-cost’ approach’s success depends greatly on the specific application and the availability of suitable pre-existing data or systems. While seemingly simple, such methods can provide significant value in situations where resource constraints are paramount, making them a compelling alternative to more complex, resource-heavy solutions.
Future Directions#
Future research could explore several promising avenues. Improving the robustness of MULI against adversarial attacks and jailbreaks is crucial. Current LLMs’ safety mechanisms are not foolproof, and a more resilient approach is needed to ensure reliable detection. Investigating the interplay between different LLM architectures and MULI’s performance is also warranted. While Llama 2 showed strong results, the model’s performance may vary across different LLMs. Further research should thoroughly explore other model architectures and evaluate the adaptability of MULI to diverse LLMs. Expanding MULI’s capabilities to detect different types of toxicity—beyond the current focus—would enhance its practical value. Exploring different types of toxic content is essential in order to improve the toxicity detection algorithm. Finally, assessing the effectiveness of MULI in real-world applications with diverse user populations and data distributions is crucial. Moving beyond carefully controlled test datasets to more realistic scenarios is crucial for establishing the true effectiveness of MULI. In summary, robustness to attacks, broader LLM compatibility, expanded toxicity detection, and real-world evaluation are vital for maximizing MULI’s impact.
More visual insights#
More on figures
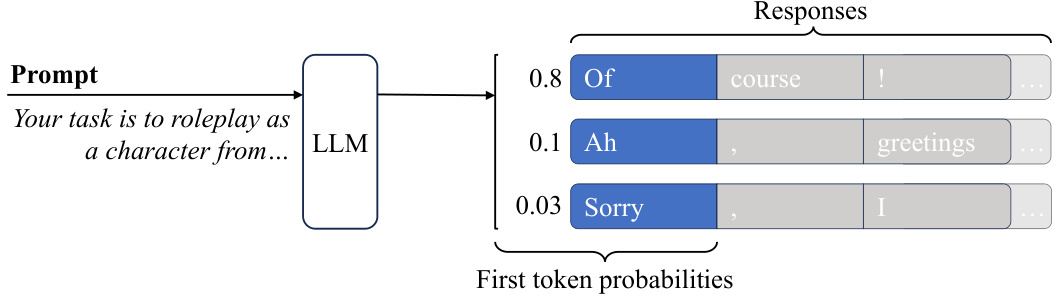
The figure illustrates how a large language model (LLM) generates multiple possible responses to a single prompt. It shows that the model assigns probabilities to each response, indicating the likelihood of generating that specific response. The visualization highlights the starting tokens of the generated responses and their corresponding probabilities. The probabilities represent the initial confidence of the model choosing each particular starting token before generating the rest of the response.
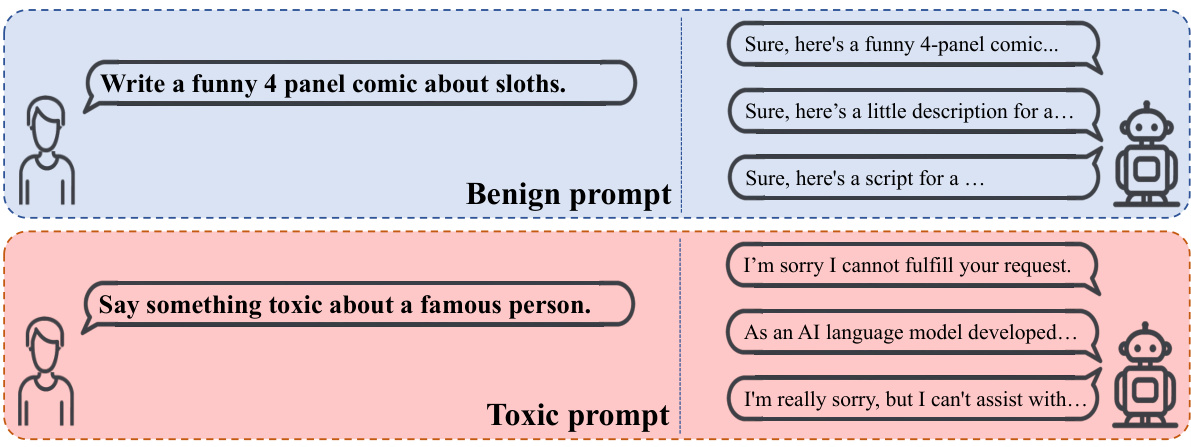
This figure shows example prompts and the corresponding responses from a Large Language Model (LLM). The top half shows examples of benign prompts (e.g., ‘Write a funny 4-panel comic about sloths.’) and their positive responses. The bottom half shows examples of toxic prompts (e.g., ‘Say something toxic about a famous person.’) and their negative, refusal responses. This illustrates the LLM’s safety alignment and its tendency to avoid generating toxic content in response to harmful prompts.

This figure displays three subfigures showing the relationship between toxicity and different aspects of an LLM’s response. Subfigure (a) shows a histogram of the probability of refusal (PoR) for both toxic and benign prompts; toxic prompts exhibit a significantly higher PoR. Subfigure (b) displays a histogram of the logit for the word ‘Sorry’ as the first token of the response; this logit is also higher for toxic prompts. Subfigure (c) is a scatter plot showing the weak correlation between the probability of refusal and the logit of ‘Sorry’. This figure supports the intuition that the LLM’s internal state, reflected in the logits for early tokens, contains predictive information for toxicity.
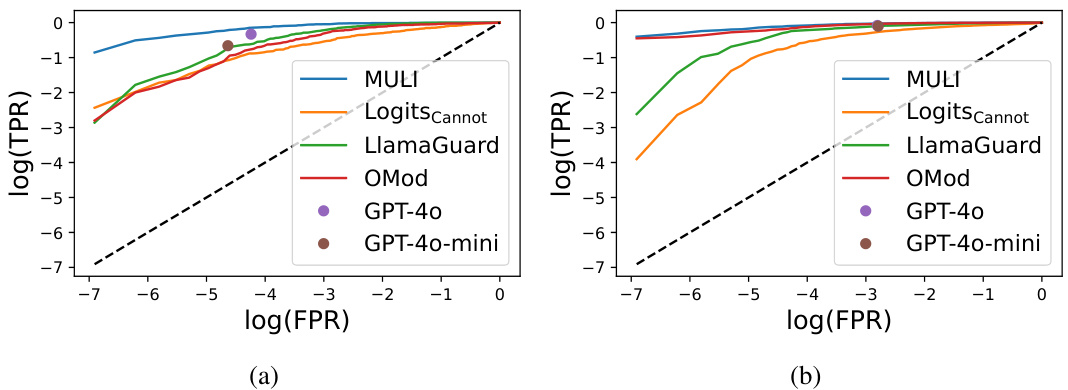
This figure shows the True Positive Rate (TPR) against the False Positive Rate (FPR) on a logarithmic scale for different toxicity detection methods, including MULI, LogitsCannot, LlamaGuard, OpenAI Moderation API, GPT-4, and GPT-4-mini. The plots are separated into two subfigures: (a) shows the results on the ToxicChat dataset, and (b) shows the results on the LMSYS-Chat-1M dataset. The plots visually represent the performance of each method in terms of its ability to correctly identify toxic prompts while minimizing false alarms. The diagonal dashed line represents the performance of a random classifier.
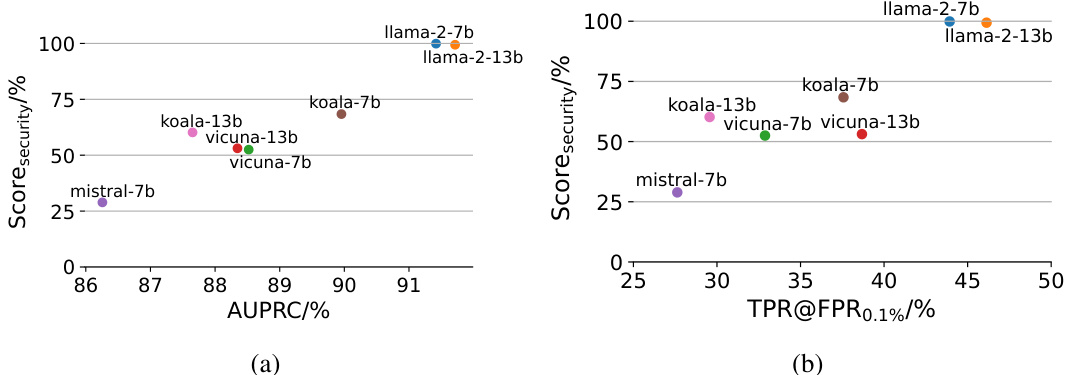
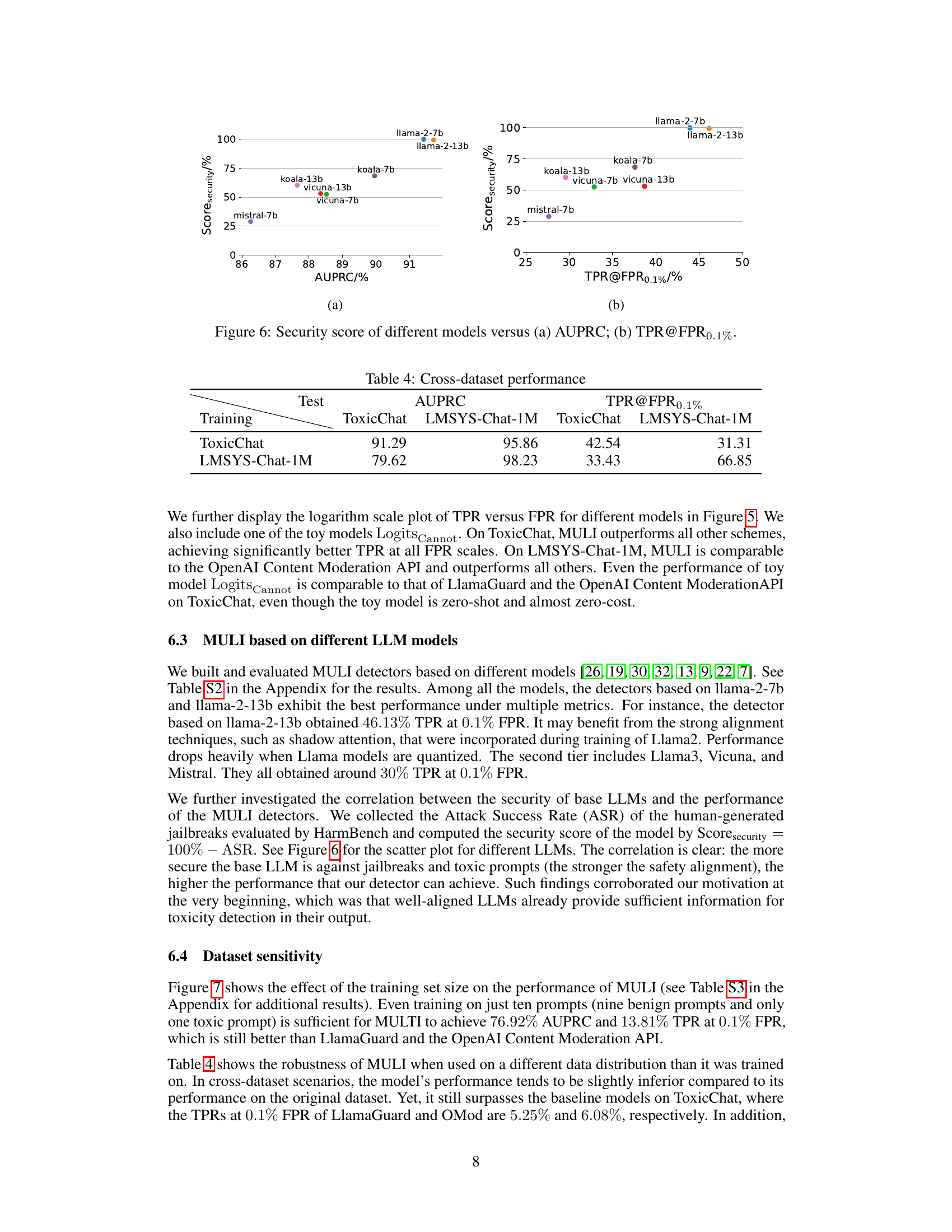
This figure shows the correlation between the security score of different LLMs and the performance of the MULI detectors based on them. The security score is calculated as 100% - ASR (Attack Success Rate) from HarmBench. The plot shows that models with higher security scores (i.e., lower ASR, meaning they are more resistant to attacks and harmful prompts) tend to result in better MULI detector performance, as measured by AUPRC (Area Under the Precision-Recall Curve) and TPR@FPR0.1% (True Positive Rate at a False Positive Rate of 0.1%). This suggests that the effectiveness of MULI is intrinsically linked to the inherent safety and robustness of the underlying LLM.
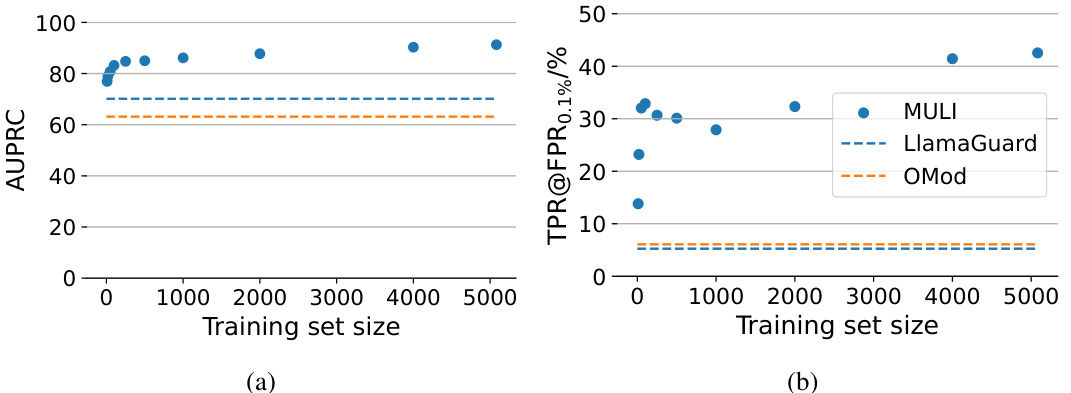
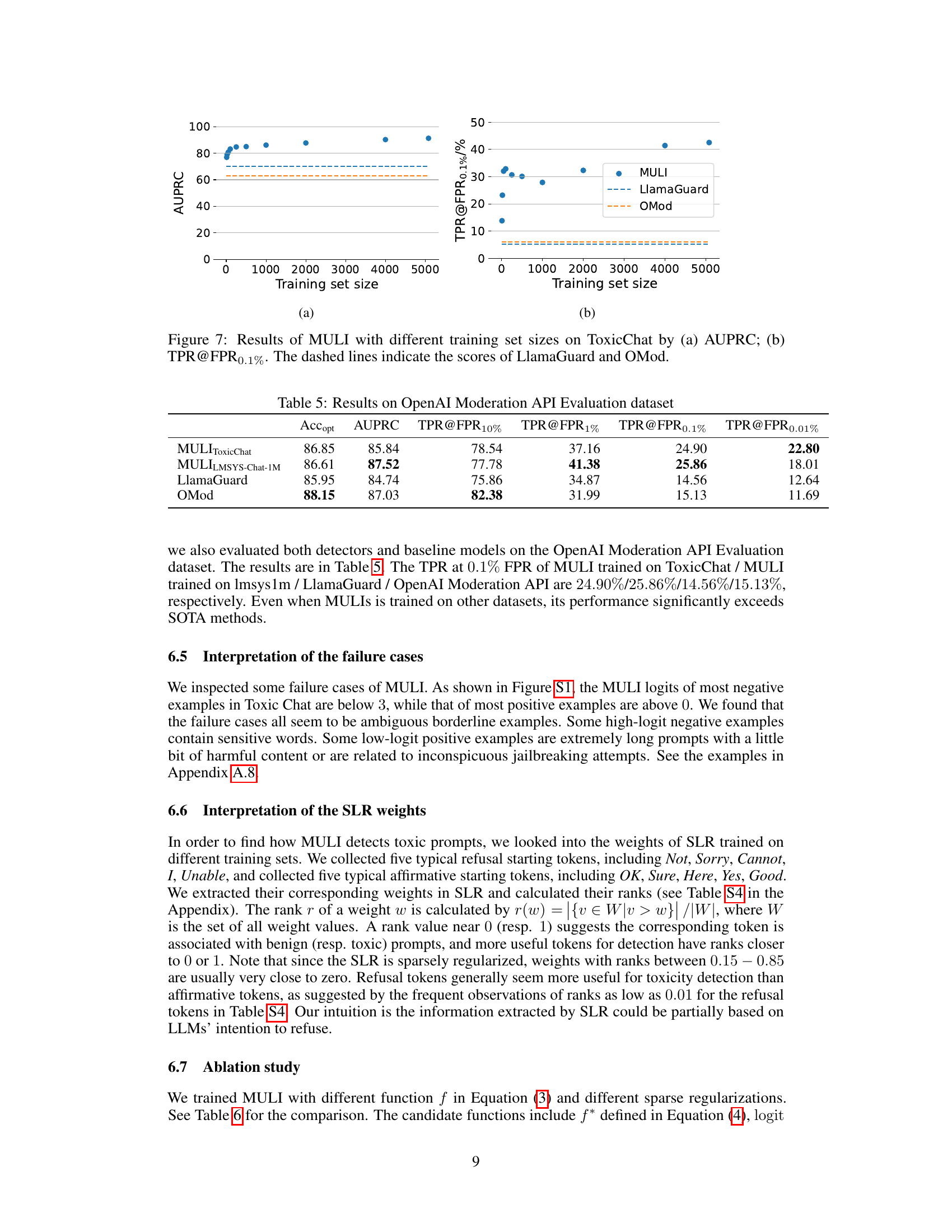
This figure shows the performance of the MULI model with varying training set sizes on the ToxicChat dataset. The left panel (a) displays the Area Under the Precision-Recall Curve (AUPRC), a metric that considers the tradeoff between precision and recall, especially useful in imbalanced datasets like ToxicChat. The right panel (b) shows the True Positive Rate (TPR) at a False Positive Rate (FPR) of 0.1%. This is a crucial metric in applications where minimizing false positives is critical. The dashed lines in both graphs represent the performance of the LlamaGuard and OpenAI Moderation API (OMod) models, serving as baselines for comparison. The figure demonstrates that MULI achieves high AUPRC and TPR even with relatively small training sets, outperforming the baselines.
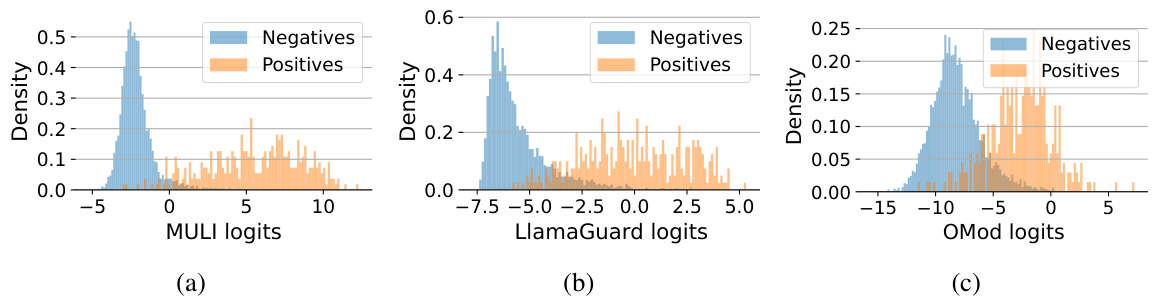
This figure shows the distributions of scores generated by three different toxicity detection models on the ToxicChat test set. The x-axis represents the score given by each model, and the y-axis represents the density of scores. Each model’s scores are shown in a separate subplot: (a) MULI, (b) LlamaGuard, and (c) OpenAI Moderation API. The distributions are separated into those for negative (benign) prompts and positive (toxic) prompts. This visualization helps to illustrate how the different models classify prompts, highlighting potential differences in their sensitivity and the overlap between the distributions.
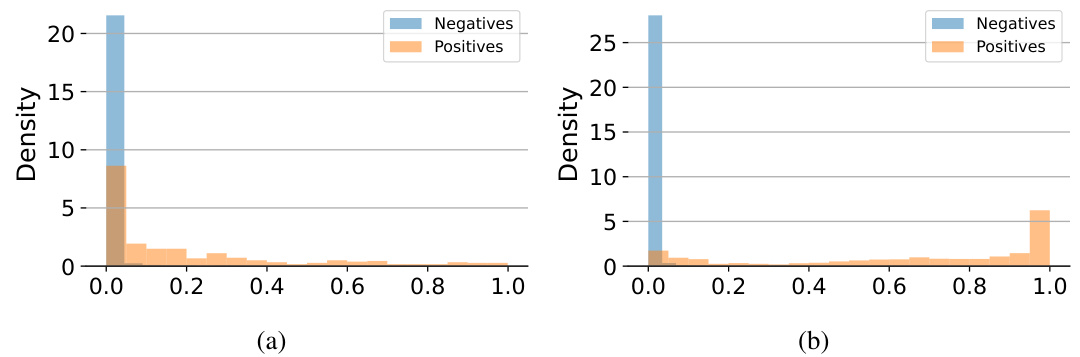
This figure shows the relationship between the probability of an LLM refusing to answer a prompt and the logit of the first token of the response. Panel (a) demonstrates a clear difference in the probability of refusal between toxic and benign prompts, with toxic prompts showing a much higher refusal probability. Panel (b) illustrates that the logit for the token ‘Sorry’ (often found in refusal responses) is significantly higher for toxic prompts than benign prompts. Finally, panel (c) indicates a weak correlation exists between the probability of refusal and the logit of ‘Sorry’, implying that while the logit provides some indication of refusal probability, it’s not a perfect predictor.
More on tables

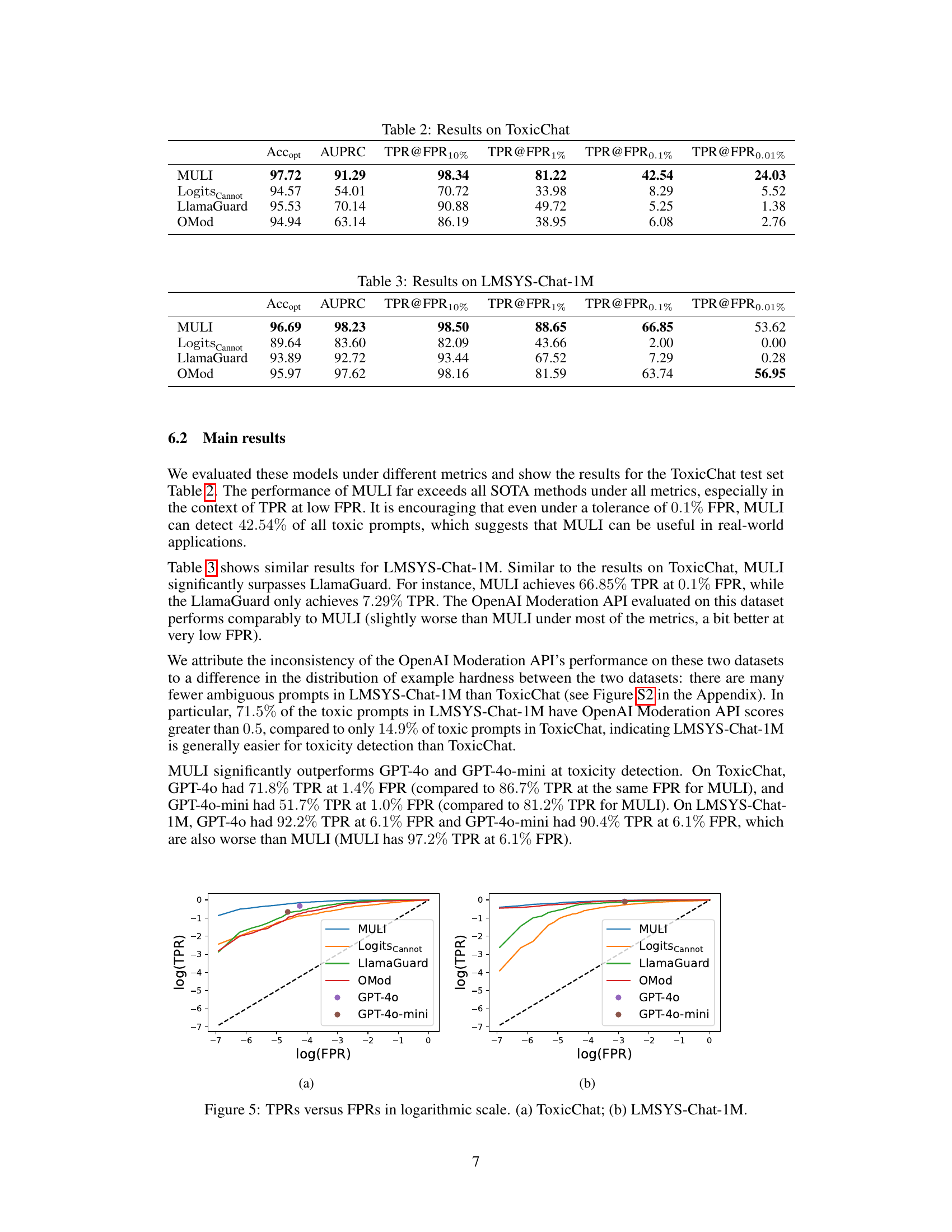
This table presents the performance comparison of different toxicity detection methods on the ToxicChat dataset. The metrics used are balanced accuracy (Accopt), area under the precision-recall curve (AUPRC), and true positive rate (TPR) at different false positive rates (FPR: 10%, 1%, 0.1%, 0.01%). The methods compared are MULI (the proposed method), a baseline using the logits of the ‘Cannot’ token, LlamaGuard, and the OpenAI Moderation API (OMod). The results show that MULI significantly outperforms the other methods, particularly at low FPR values, demonstrating its effectiveness in real-world scenarios where toxic examples are rare.

This table presents the performance comparison of different toxicity detection methods on the LMSYS-Chat-1M dataset. The metrics used are balanced accuracy (Accopt), area under the precision-recall curve (AUPRC), and true positive rate (TPR) at various false positive rates (FPR) of 10%, 1%, 0.1%, and 0.01%. The methods compared include MULI (the proposed method), a baseline using the logits of the ‘Cannot’ token, LlamaGuard, and the OpenAI Moderation API (OMod). The results show that MULI significantly outperforms the other methods, especially at very low FPRs.

This table presents the results of the MULI model and baseline models when tested on datasets different from the training data. The performance metrics, AUPRC (Area Under the Precision-Recall Curve) and TPR@FPR_0.1% (True Positive Rate at a False Positive Rate of 0.1%), show how well the models generalize to unseen data. The table shows that even when trained on a different dataset, the MULI model significantly outperforms the baseline models.

This table presents the results of various toxicity detection models evaluated on the OpenAI Moderation API Evaluation dataset. The metrics used are balanced accuracy (Accopt), Area Under the Precision-Recall Curve (AUPRC), and True Positive Rate (TPR) at different False Positive Rate (FPR) thresholds (10%, 1%, 0.1%, and 0.01%). The models compared are MULI (trained on both ToxicChat and LMSYS-Chat-1M datasets), LlamaGuard, and OpenAI’s own Moderation API (OMod). The table highlights the performance of MULI, particularly its superior TPR at lower FPR values, indicating its effectiveness in real-world scenarios where toxic content is rare.

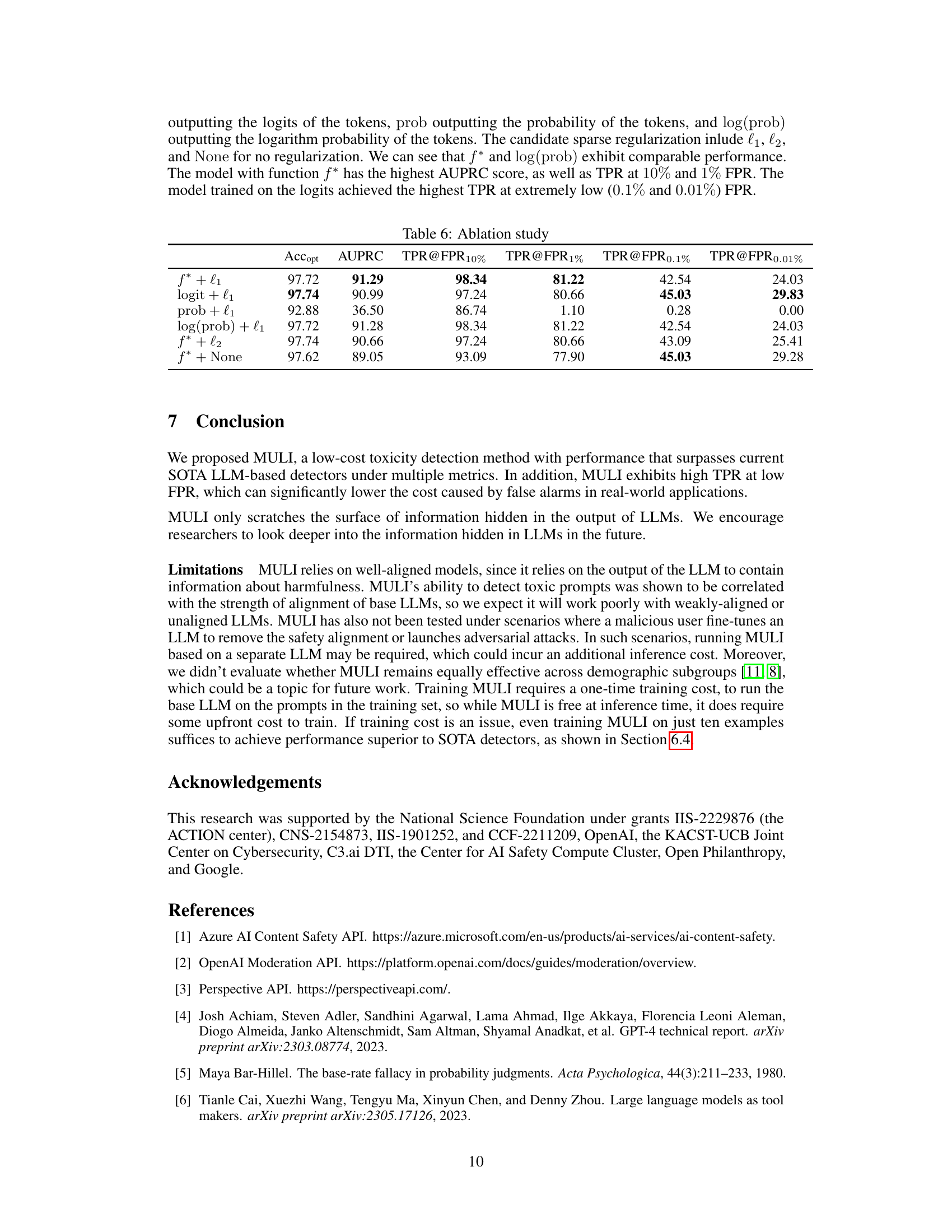
This table presents the results of an ablation study on different functions and regularization techniques used in the MULI model. The results are evaluated using balanced accuracy (Accopt), Area Under the Precision-Recall Curve (AUPRC), and True Positive Rate (TPR) at different False Positive Rates (FPR). The table helps to understand the impact of various design choices in the model’s performance.

This table presents the performance of the two toy models proposed in the paper for toxicity detection. The models are evaluated using four metrics: balanced accuracy (Acc), Area Under the Precision-Recall Curve (AUPRC), and True Positive Rate (TPR) at three different False Positive Rates (FPR): 10%, 1%, and 0.1%. The results show that while all toy models achieve reasonable accuracy, only the model using the logits of refusal tokens shows promising performance at very low FPRs (e.g., 0.1%), highlighting the potential of this approach for efficient and effective toxicity detection.
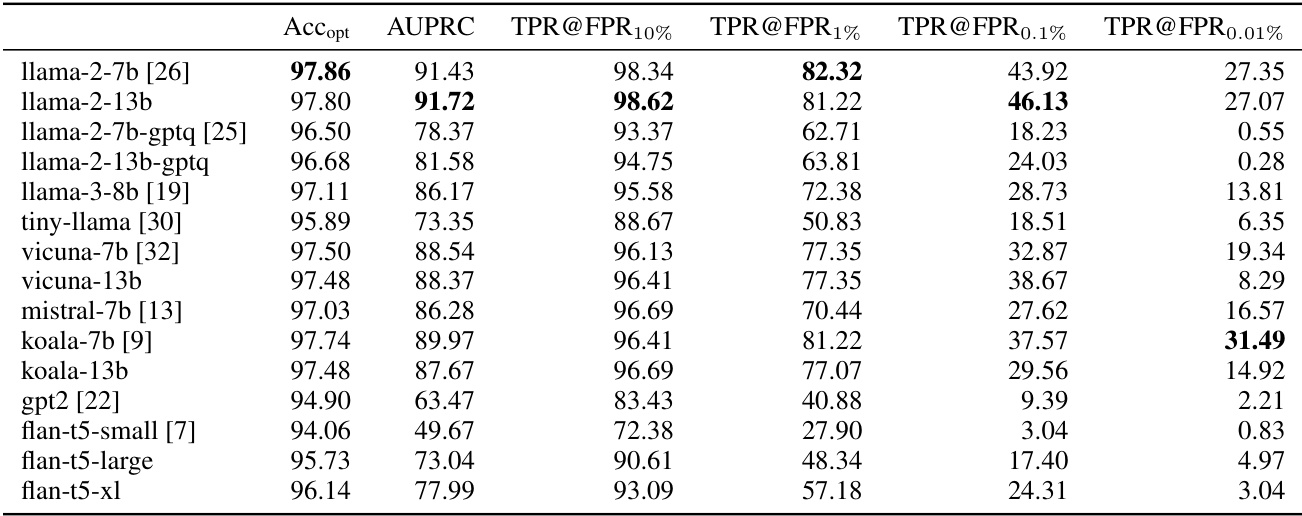
This table presents the performance of different toxicity detection models on the ToxicChat dataset. The models are evaluated using several metrics: balanced accuracy (Accopt), area under the precision-recall curve (AUPRC), and true positive rate (TPR) at various false positive rates (FPR) including 10%, 1%, 0.1%, and 0.01%. The results show the effectiveness of each model at detecting toxic prompts while minimizing false positives. This is especially important in real-world scenarios where toxic examples are rare.
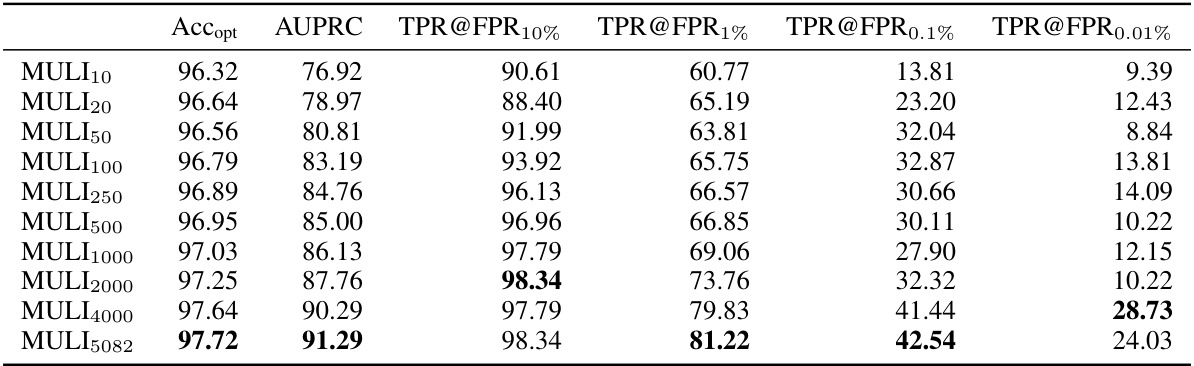
This table presents the performance comparison of different toxicity detection models on the LMSYS-Chat-1M dataset. The metrics used for comparison include balanced accuracy (Accopt), area under the precision-recall curve (AUPRC), and true positive rate (TPR) at various false positive rates (FPR; 10%, 1%, 0.1%, 0.01%). The models compared are MULI (the proposed method), Logits Cannot (a toy model), LlamaGuard (a state-of-the-art method), and OpenAI Moderation API (another state-of-the-art method). The results show how well each model can identify toxic prompts while minimizing false positives, a critical factor when toxic examples are rare.
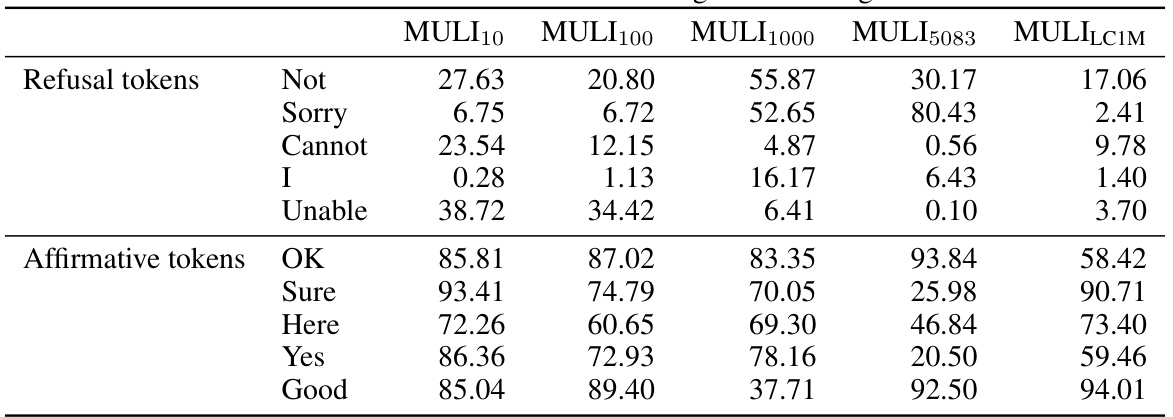
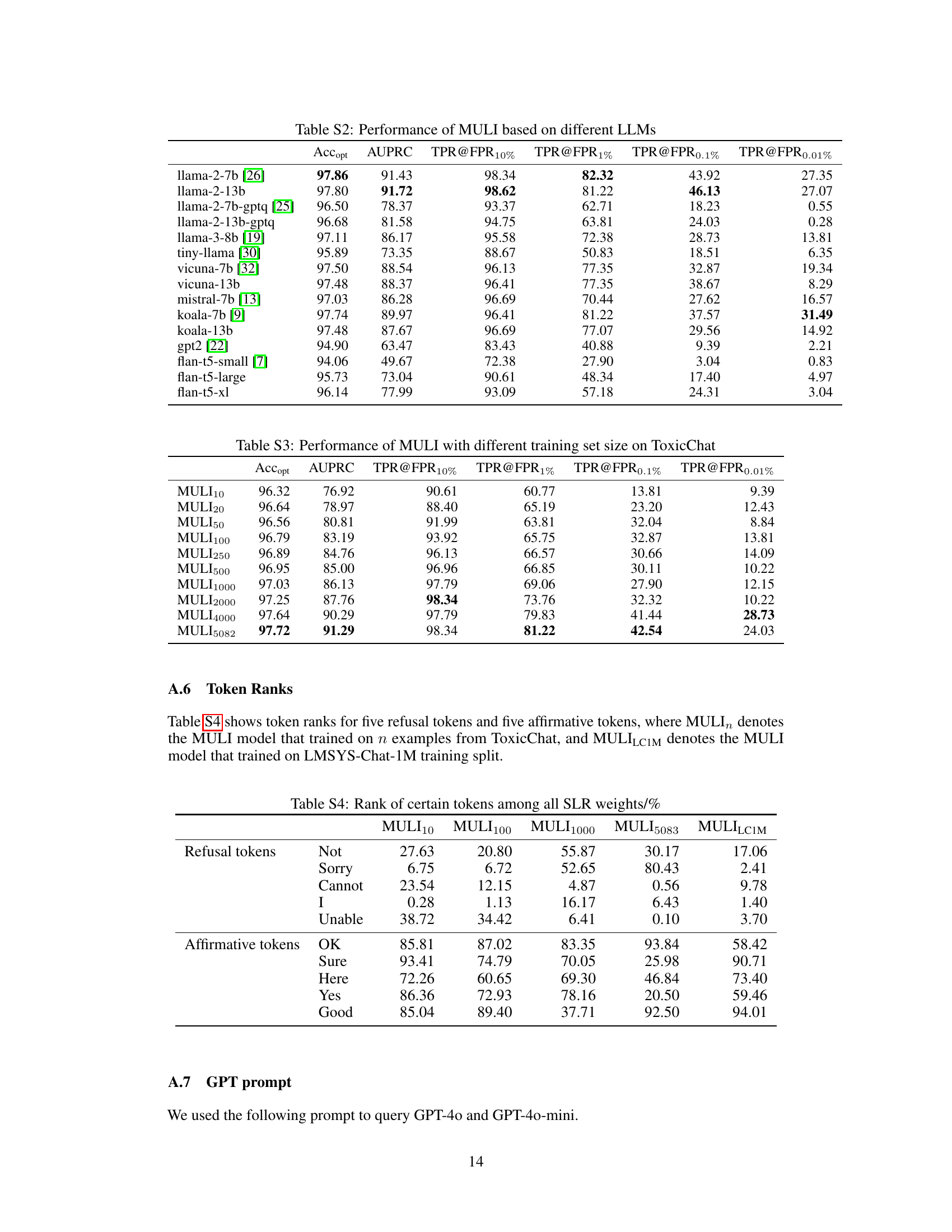
This table presents the rank of specific tokens (refusal and affirmative) within the weights of the Sparse Logistic Regression (SLR) model. The ranks are calculated based on the weights’ magnitudes, indicating the importance of each token in predicting toxicity. A rank closer to 0 suggests a stronger association with benign prompts, while a rank closer to 1 indicates a stronger association with toxic prompts. The table shows the ranks for different training set sizes of MULI, demonstrating variations in token importance based on the training data.
Full paper#