↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current video understanding methods struggle with the complexity of videos and noisy web video-text data, requiring extensive pre-training on large-scale video data. This is computationally expensive and limits accessibility for researchers. This paper introduces a novel approach, TOPA, which tackles these challenges.
TOPA uses Large Language Models (LLMs) to automatically generate “textual videos” with corresponding annotations, simulating real video-text pairs. It then uses these simulated pairs for pre-alignment with the video modality via CLIP model. This method successfully extends LLMs to video understanding without pre-training on real video data and achieves state-of-the-art results on challenging video benchmarks like EgoSchema.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to video understanding that avoids the computationally expensive and data-hungry process of traditional video-text pre-training. By using large language models and a text-only pre-alignment technique, researchers can achieve promising results on challenging video understanding benchmarks without the need for extensive video data. This opens up new possibilities for efficient video understanding research, especially for those with limited computational resources or access to large video datasets. The approach also tackles the issues with inconsistent web-collected video-text data. The proposed method addresses current limitations in the field, paving the way for further advancements in video-language research.
Visual Insights#
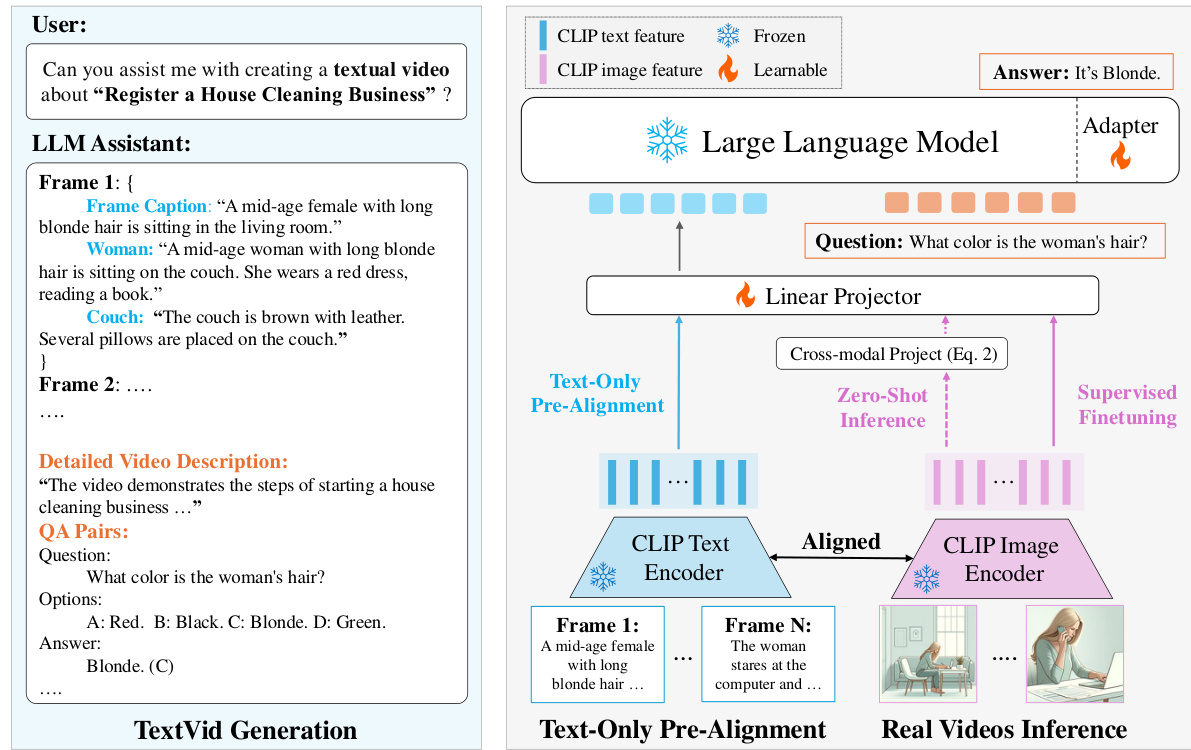
This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and aligning the large language model (LLM) with video modality (right). The left side depicts how an LLM generates textual videos with annotations to simulate real video-text pairs. The right side shows how TOPA uses these textual videos to pre-align the LLM with the video modality using CLIP, bridging the gap between textual and real videos for zero-shot and supervised fine-tuning.

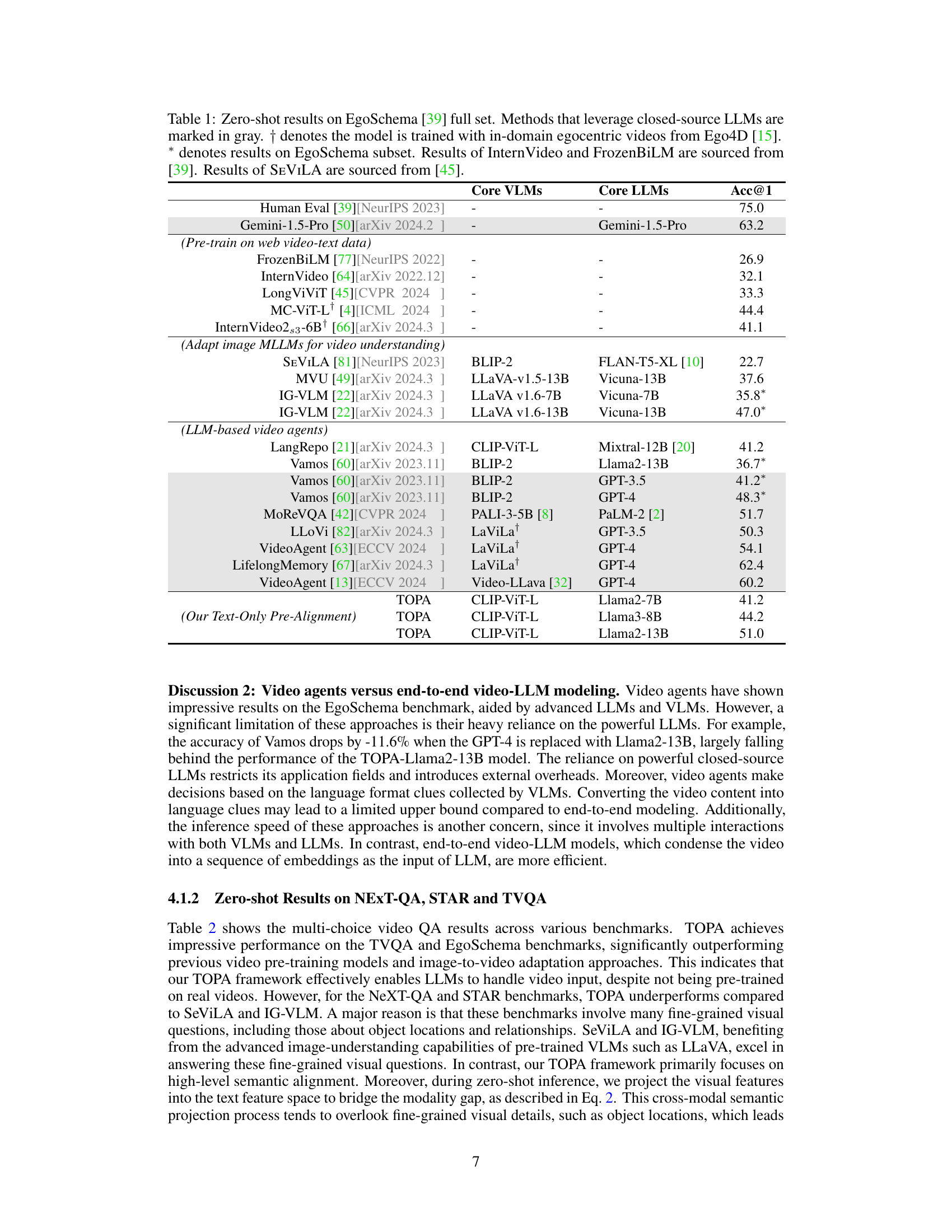
This table presents the zero-shot accuracy results on the EgoSchema benchmark, comparing various video understanding approaches. It highlights the performance of TOPA against existing methods that use pre-trained models on web video-text data or adapt image-based Multimodal Large Language Models (MLLMs) to videos. The table shows the Top-1 accuracy for each method, categorized by whether they use pre-trained web video data, adapt image MLLMs, utilize LLM-based video agents, or employ TOPA’s novel text-only pre-alignment method. Closed-source LLMs are indicated, as are models trained on in-domain egocentric videos.
In-depth insights#
TOPA: LLM Video Alignment#
The concept of “TOPA: LLM Video Alignment” presents a novel approach to bridging the gap between large language models (LLMs) and video understanding. Instead of relying on traditional video-text pre-training with real video data, TOPA leverages an LLM to generate synthetic “Textual Videos,” sequences of textual descriptions mimicking real video frames. This allows for efficient pre-alignment of the LLM to video modalities without the need for extensive video data. A key strength is the use of CLIP for feature extraction, aligning textual and visual representations. The effectiveness of TOPA is demonstrated through impressive zero-shot and fine-tuning results on challenging video understanding benchmarks, highlighting its potential as a cost-effective and efficient method for video-LLM alignment. However, limitations exist, including the modality gap between textual and visual CLIP features and challenges in capturing fine-grained visual details. Future work could explore methods to mitigate these limitations, such as incorporating video instruction tuning.
Textual Video Dataset#
A textual video dataset is a novel approach to video understanding that sidesteps the complexities of directly using real video data. Instead of relying on video frames, it leverages large language models (LLMs) to generate sequences of textual descriptions, simulating the temporal dynamics of a video. This approach bypasses challenges associated with visual-textual misalignment and inefficient language supervision in web-collected video-text datasets. The dataset’s effectiveness hinges on the LLM’s ability to create rich and accurate textual representations, effectively capturing video content. High-quality annotations, including dense descriptions and question-answer pairs, are crucial for successful pre-alignment of LLMs with the video modality. The dataset provides a scalable and cost-effective alternative to traditional video-text datasets, potentially addressing data scarcity limitations inherent in current video understanding research. The generation process itself is also significant, highlighting the capabilities of LLMs in creating synthetic yet realistic multimodal data. The quality of this synthetic data will directly influence the effectiveness of any downstream task.
Zero-Shot Video Tasks#
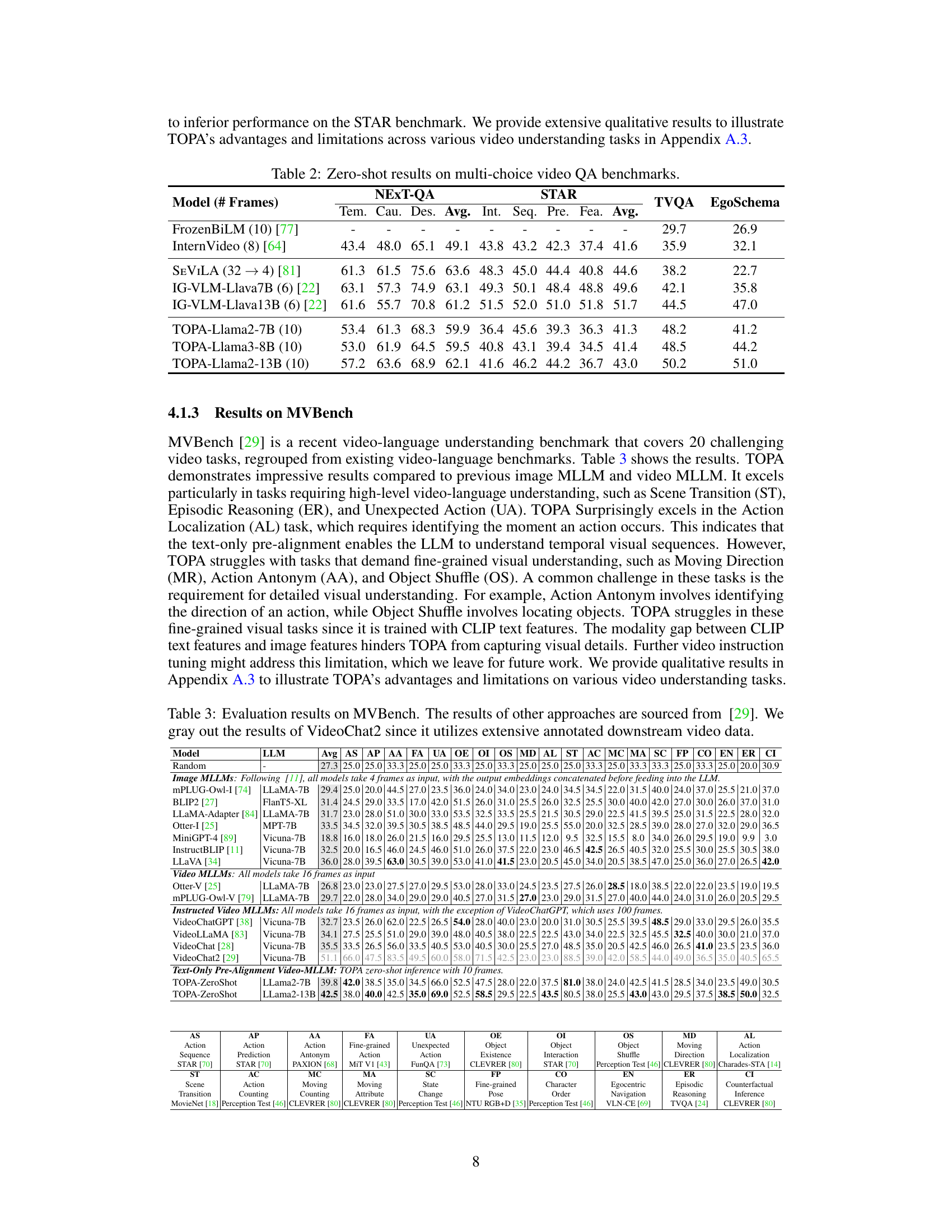
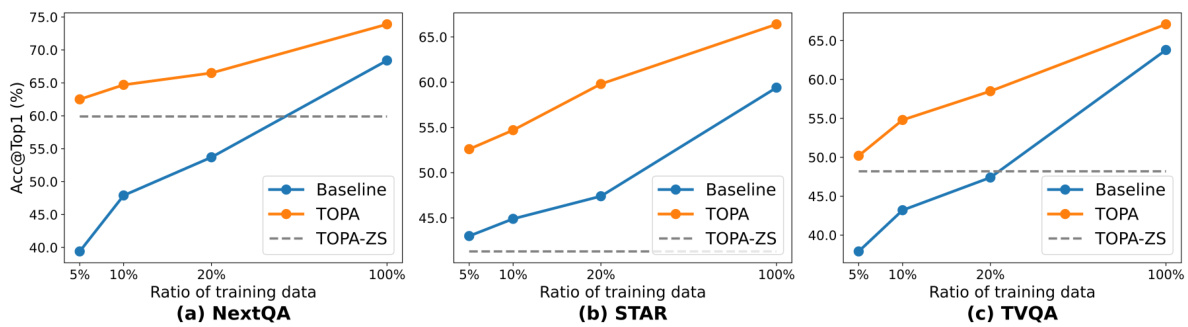
Zero-shot video task evaluation is crucial for assessing the generalization capabilities of video understanding models. It reveals how well a model can perform on unseen video categories or tasks without any prior training data for those specific categories. Strong zero-shot performance demonstrates a model’s robust learning of underlying visual and semantic concepts, transferring knowledge effectively across different domains. However, the inherent complexity and variability of videos pose significant challenges for zero-shot learning. Success often relies on the model’s ability to leverage pre-training on large, diverse video-text datasets. Furthermore, the design of appropriate zero-shot evaluation metrics that accurately capture model understanding is critical. Careful consideration of dataset bias and the definition of task success are needed to ensure meaningful and fair evaluation. Future research directions include improving the robustness of zero-shot methods against domain shift and noise, developing more comprehensive benchmarks that capture varied aspects of visual understanding, and investigating novel training strategies that specifically target zero-shot generalization.
TOPA Limitations#
The TOPA framework, while demonstrating promising results in video-language understanding, is not without limitations. A crucial limitation stems from the inherent modality gap between CLIP’s image and text encoders. TOPA’s reliance on CLIP for feature extraction introduces a discrepancy between training (textual videos) and inference (real videos), hindering performance. The reliance on textual video representations also means TOPA may struggle with tasks needing fine-grained temporal understanding or fine-grained visual details that textual descriptions often miss. The inability to capture the nuanced visual dynamics of real videos is another key limitation, impacting performance on tasks requiring precise visual analysis. While TOPA mitigates the modality gap through a projection technique, this approach inherently limits its capability to handle highly detailed or subtle visual aspects. Therefore, while a significant advancement, TOPA’s performance is dependent on the quality of the textual video representation and may not fully capture the complexity of real-world video understanding.
Future Research#
Future research directions stemming from this TOPA framework could explore several promising avenues. Firstly, enhancing the model’s ability to handle fine-grained visual details is crucial, perhaps through integrating more advanced visual feature extractors or incorporating mechanisms for explicit temporal modeling. Secondly, investigating different LLMs beyond Llama 2 could reveal the extent of TOPA’s generalizability and potential for even greater performance gains. Thirdly, expanding the TextVid dataset to encompass a wider range of video styles and complexities will further enhance the robustness of the pre-alignment process. Finally, combining TOPA with video instruction tuning could unlock the next level of video understanding, bridging the gap between textual and visual representations in a more powerful way. This fusion of techniques holds significant potential for advancing video-language capabilities.
More visual insights#
More on figures

This figure illustrates the TOPA framework, showing the pipeline for generating the TextVid dataset (left) and the video-LLM alignment process (right). The TextVid dataset generation involves using an LLM to create textual videos mimicking real videos. The video-LLM alignment uses CLIP to extract features from both textual and real videos and aligns the LLM to the video modality through text-only pre-alignment. The framework also allows for zero-shot inference and supervised fine-tuning on downstream datasets.
This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos with annotations. The right side shows how the LLM is aligned with the video modality using continuous CLIP text features (during training) and then adapts to real video data using projected CLIP visual features (during inference). The framework also supports fine-tuning with real video data to further enhance performance.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos (sequences of textual frames mimicking real videos) and their corresponding annotations (dense descriptions and QA pairs). The right side details the video-LLM alignment process. TOPA pre-aligns the LLM with video modality using only text data from TextVids, leveraging CLIP for feature extraction to bridge the gap between text and image. Zero-shot inference and supervised fine-tuning are also shown as options for adapting the aligned model to real video understanding tasks.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how TextVid is created using an LLM to generate textual videos and corresponding annotations. The right side shows how TOPA aligns LLMs with video modality using only text data. During text-only pre-alignment, the LLM processes continuous CLIP text features, which are analogous to continuous CLIP image features from real videos. Zero-shot inference uses projected CLIP visual features, and fine-tuning can be done on downstream datasets.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is generated using an LLM to create textual videos and their corresponding annotations. The right side illustrates the video-LLM alignment process. During text-only pre-alignment, the LLM processes continuous CLIP text features of textual videos, effectively aligning itself with the video modality. In zero-shot inference, CLIP image features from real videos are projected into the LLM’s space, allowing for video understanding without training on real video data. Finally, supervised fine-tuning is supported to enhance performance further.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how TextVids are created using an LLM to generate textual frames and annotations. The right side details how the TextVids are used for text-only pre-alignment of the LLM with video modality via CLIP features, enabling zero-shot inference and supervised fine-tuning on downstream video datasets.

This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and the video-LLM alignment process (right). The TextVid dataset is created by using an LLM to generate textual videos that simulate real videos. These textual videos are then used to pre-align the LLM with the video modality. During inference, CLIP is used to extract features from real videos, which are then projected into the LLM feature space. The LLM can then be fine-tuned on downstream video datasets to further improve performance.

This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and how the video-LLM alignment is performed (right). The TextVid dataset is created using an LLM to generate textual videos mimicking real video content. The right side shows how TOPA aligns LLMs with video modality by using continuous CLIP text features for pre-alignment and projected CLIP visual features for zero-shot inference. Supervised fine-tuning on downstream datasets is also supported to further enhance performance.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and annotations. The right side depicts the video-LLM alignment process, where a pre-trained LLM is aligned with video modality using textual video representations. The alignment allows for both zero-shot inference (using projected CLIP visual features) and supervised fine-tuning on downstream video datasets.

This figure shows the overall architecture of the TOPA framework, which is divided into two main parts: TextVid dataset generation and video-LLM alignment. The left side illustrates the process of generating the TextVid dataset using an LLM to create textual videos and corresponding annotations. The right side shows how TOPA aligns the LLM with the video modality using CLIP features. During text-only pre-alignment, the LLM processes continuous text features, and then transitions to processing continuous image features for real video inference using a projection layer. Zero-shot inference is also supported, as is supervised finetuning on downstream video datasets to further improve performance.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows the process of generating the TextVid dataset using an LLM to create textual videos and their annotations. The right side shows how TOPA aligns LLMs with video modality using CLIP features and a pre-alignment step, enabling zero-shot inference and supervised fine-tuning.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and annotations. The right side details the video-LLM alignment process, demonstrating how TOPA pre-aligns LLMs with video modality using only text data and then adapts to real video understanding through zero-shot inference and supervised fine-tuning.

This figure shows the overall architecture of the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side illustrates the process of generating the TextVid dataset using an LLM to create textual videos and their corresponding annotations. The right side shows the video-LLM alignment process, which involves pre-aligning the LLM with the video modality using the generated TextVid data and then using CLIP to align the text and image features. The framework supports both zero-shot inference and supervised fine-tuning on downstream video datasets.

This figure shows a schematic overview of the TOPA framework. The left side illustrates the process of generating the TextVid dataset, which involves using a large language model (LLM) to create textual videos and their corresponding annotations. The right side shows the process of aligning a large language model (LLM) with the video modality. This alignment is performed using Text-Only Pre-Alignment (TOPA), which leverages continuous textual frames (analogous to continuous CLIP image features) to pre-align the LLM with the video modality. The figure also highlights the zero-shot inference and supervised fine-tuning capabilities of the TOPA framework.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how textual videos are generated using an LLM, mimicking real video dynamics. The right side shows how these textual videos are used to pre-align LLMs with video modality using CLIP features, allowing for zero-shot and finetuned video understanding. The framework highlights the process of generating textual video data, aligning the LLM with the video modality using textual frames and CLIP, performing zero-shot inference using projected CLIP visual features, and the option for supervised finetuning on downstream datasets.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how textual videos (Tideos) are generated using an LLM, mimicking real videos with continuous textual frames and annotations. The right side depicts the video-LLM alignment process, where a pre-trained LLM is aligned with the video modality using the generated Tideos. The process includes text-only pre-alignment, zero-shot inference (using projected CLIP visual features), and optional supervised fine-tuning on downstream video datasets.

This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and the video-LLM alignment process (right). The TextVid dataset generation uses an LLM to create textual videos simulating real videos. The alignment process uses CLIP to bridge textual and real video modalities, enabling the LLM to learn from textual videos and then adapt to real video data. Zero-shot inference and supervised fine-tuning options are also shown.

This figure illustrates the TOPA framework, showing the TextVid dataset generation pipeline on the left and the video-LLM alignment framework on the right. The left side depicts how an LLM is used to create textual videos (TextVids) mimicking real videos, complete with annotations for training. The right side details how TOPA aligns an LLM with video modality by using CLIP to bridge textual and real video features. TOPA supports both zero-shot inference (using projected CLIP visual features) and supervised fine-tuning on downstream video datasets.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and annotations. The right side details how TOPA aligns the LLM with video modality using continuous CLIP text and image features, enabling zero-shot inference and supervised fine-tuning.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how textual videos (Tideos) are created using an LLM. These Tideos mimic real videos with textual frames and annotations, creating simulated video-text pairs. The right side depicts the video-LLM alignment process, where the LLM is pre-aligned with video modality using the generated Tideos and CLIP features (both text and image). The framework supports both zero-shot inference (using projected CLIP visual features) and supervised fine-tuning on downstream video datasets.

This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and the video-LLM alignment (right). The left side depicts how an LLM generates textual videos and their annotations. The right side details how TOPA pre-aligns LLMs with video modality using textual video data and CLIP for feature extraction, enabling zero-shot inference and fine-tuning on real video data.
This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how TextVid is created using an LLM to generate textual videos with annotations. The right side demonstrates how TOPA aligns LLMs with video modality using TextVid, CLIP, and an adapter. The framework supports both zero-shot inference and supervised fine-tuning.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and annotations. The right side details the video-LLM alignment process. During text-only pre-alignment, the LLM processes textual video features (analogous to real video features), enabling zero-shot inference with real video data using projected CLIP visual features. The framework also supports supervised fine-tuning for improved performance.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and their annotations. The right side details the video-LLM alignment process, showing how TOPA uses text-only pre-alignment to align LLMs with the video modality. It also highlights the zero-shot inference and supervised finetuning capabilities of the framework.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows the process of generating the TextVid dataset using an LLM to create textual videos and their annotations. The right side illustrates the video-LLM alignment process, where the LLM is pre-aligned with video modality using textual videos and CLIP features. Zero-shot inference and supervised fine-tuning are also shown as ways to use the aligned LLM for video understanding tasks.

This figure illustrates the TOPA framework, showing the process of generating the TextVid dataset (left) and the video-LLM alignment process (right). The TextVid generation uses an LLM to create textual videos that mimic real videos. The alignment process involves pre-aligning an LLM with textual video representations using CLIP for feature extraction, enabling zero-shot inference and fine-tuning on real video datasets.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how TextVids are created using an LLM, generating textual frames analogous to real video frames, complete with descriptions and question-answer pairs. The right side depicts how TOPA pre-aligns LLMs with video data using only text, bridging the gap between textual and real video representations via the CLIP model. Zero-shot inference and supervised fine-tuning are also shown as options for using the aligned model.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how TextVid is created using an LLM to generate textual videos and their annotations. The right side details the video-LLM alignment process, including text-only pre-alignment using continuous CLIP text features and zero-shot inference using projected CLIP visual features. The framework also supports supervised fine-tuning for enhanced performance.
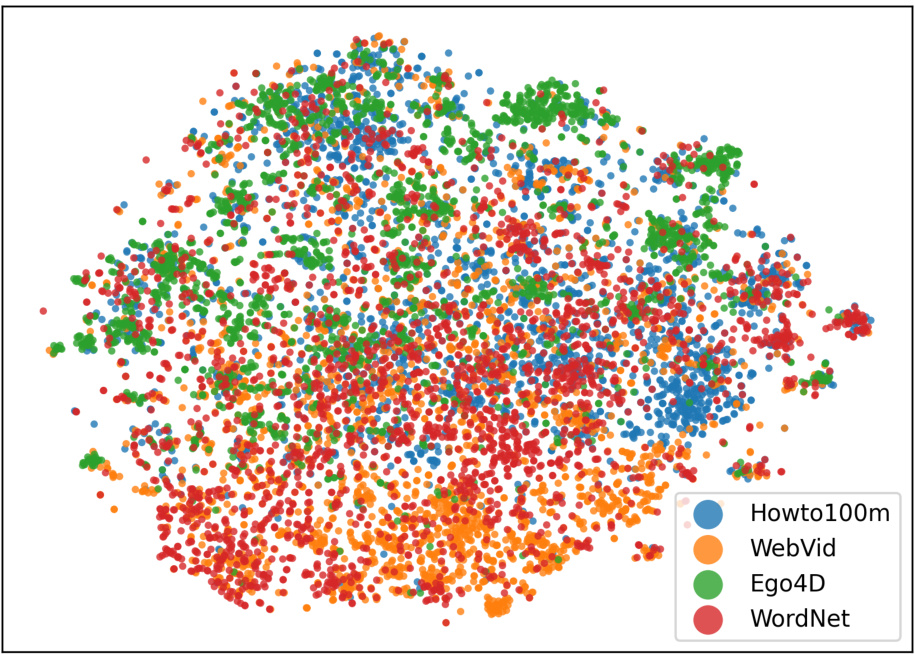
This figure visualizes the Tideo features generated from different types of prompts, namely Howto100m, WebVid, Ego4D, and WordNet. Each point represents a Tideo feature vector, and the color indicates the type of prompt used to generate it. The figure shows that the Tideo features generated from different types of prompts are clustered together in different regions of the feature space, indicating that the features capture different aspects of the video content. This visualization helps to understand the diversity of the Tideo dataset and how different types of prompts contribute to this diversity. The plot appears to use a dimensionality reduction technique (like t-SNE or UMAP) to project the high-dimensional feature vectors into a 2D space for visualization.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and their annotations. The right side details the video-LLM alignment process, including text-only pre-alignment using continuous CLIP text features, zero-shot inference using projected CLIP visual features, and optional supervised fine-tuning on downstream video datasets to enhance performance.

This figure illustrates the TOPA framework, which consists of two main stages: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos (Tideos) mimicking real videos. The right side details the video-LLM alignment process, which involves text-only pre-alignment using the Tideos and CLIP features, followed by zero-shot inference and optional supervised fine-tuning on real video datasets.

This figure illustrates the TOPA framework, showing the two main stages: TextVid dataset generation and video-LLM alignment. The left side depicts the process of creating the TextVid dataset using an LLM to generate textual videos and annotations. The right side details the alignment process, where a language model (LLM) is pre-aligned with video modality using textual videos, and how this alignment facilitates both zero-shot inference using CLIP visual features and supervised finetuning on real video datasets.

This figure illustrates the TOPA framework, which consists of two main parts: TextVid dataset generation and video-LLM alignment. The left side shows how the TextVid dataset is created using an LLM to generate textual videos and their annotations. The right side shows how the pre-trained LLM is aligned with video modality using the generated TextVid dataset and CLIP features. TOPA supports both zero-shot inference using projected CLIP visual features and supervised fine-tuning on downstream video datasets for improved performance.

This figure illustrates the TOPA framework’s two main stages: TextVid dataset generation and video-LLM alignment. The left side shows how textual videos (Tideos) are created using an LLM, mimicking real videos with textual frames and annotations. The right side details the alignment process: during text-only pre-alignment, the LLM processes continuous CLIP text features from Tideos. For real video inference (zero-shot or fine-tuned), CLIP visual features are projected to align with the LLM’s text feature space. Fine-tuning on downstream video datasets can further enhance performance.
More on tables
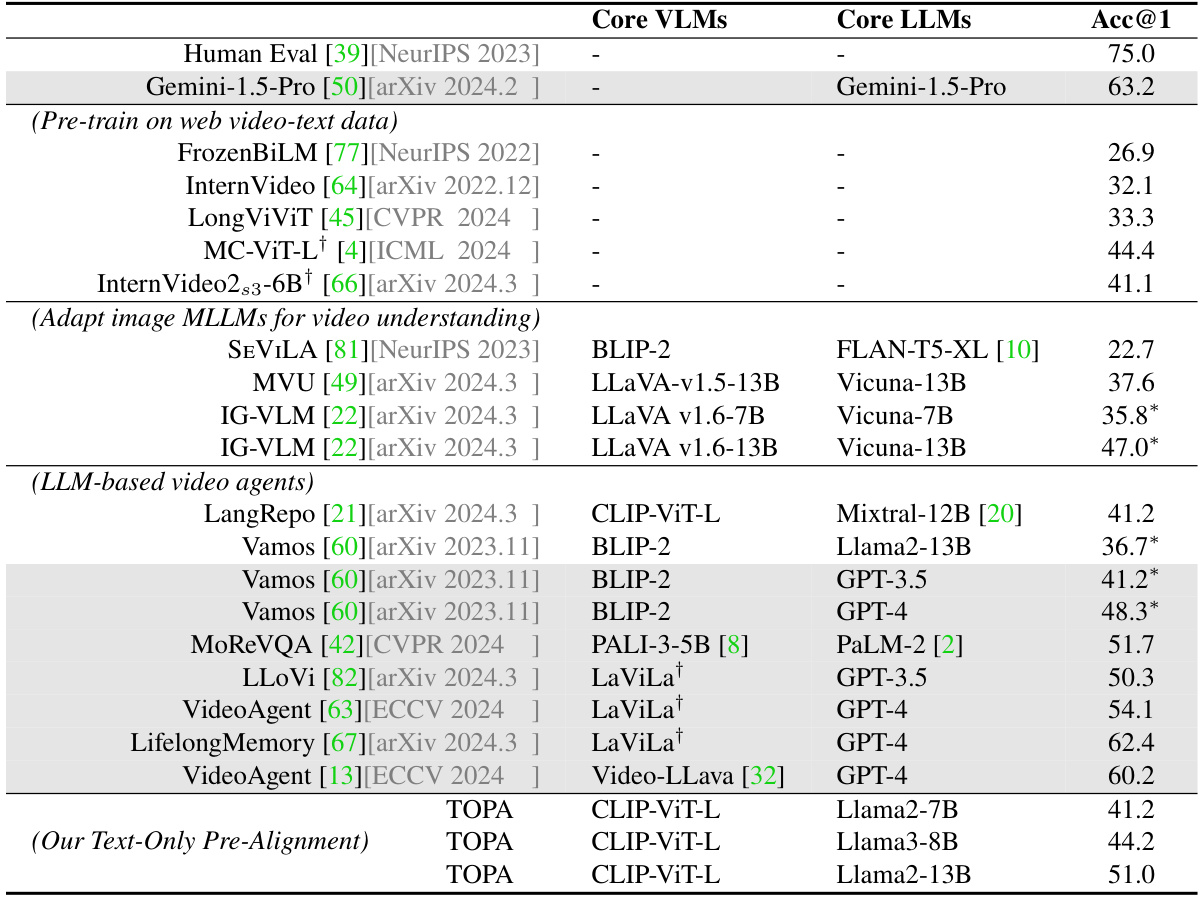
This table presents the zero-shot performance of various video understanding approaches on the EgoSchema benchmark’s full set. It compares different model types (pre-trained on web video-text data, adapting image MLLMs for video understanding, LLM-based video agents, and the proposed TOPA), highlighting their accuracy (Acc@1). Closed-source LLMs are indicated, along with notes on any in-domain training and subset results for clarity.
This table presents the results of a zero-shot evaluation on the EgoSchema benchmark. It compares the performance of various video understanding models, including those using closed-source LLMs (marked in gray), models trained with in-domain data (denoted by †), and models evaluated on a subset of EgoSchema (denoted by *). The table highlights the Top-1 accuracy achieved by each model, providing a comparison across different video understanding approaches.
This table presents the zero-shot results on the EgoSchema benchmark, comparing various video understanding approaches. It highlights the performance of different models, categorized by their underlying core visual language models (VLMs) and large language models (LLMs). The table distinguishes between models trained on web video-text data, those adapting image-based MLLMs for video, LLM-based video agents, and the proposed TOPA method. The results show TOPA’s competitive performance, especially considering its text-only pre-alignment approach and lack of training on real video data.

This table presents the results of a zero-shot evaluation on the EgoSchema benchmark, comparing various video understanding approaches. It highlights the performance (accuracy@1) of different models, categorized by their core visual language models (VLMs), core large language models (LLMs), or whether they employ image-based adaptation or video agents. The table also indicates if a model uses closed-source LLMs and trained with in-domain egocentric videos, providing a comprehensive comparison of approaches.
This table presents the zero-shot performance of various video understanding models on the EgoSchema benchmark. It compares different approaches, categorizing them by their underlying methodology (e.g., web video pre-training, adapting image MLLMs, LLM-based video agents, and the proposed TOPA method). The table highlights the Top-1 accuracy achieved by each model, showing how TOPA compares to existing state-of-the-art methods, even without training on real video data. The use of closed-source LLMs is indicated, as is the use of in-domain training data.
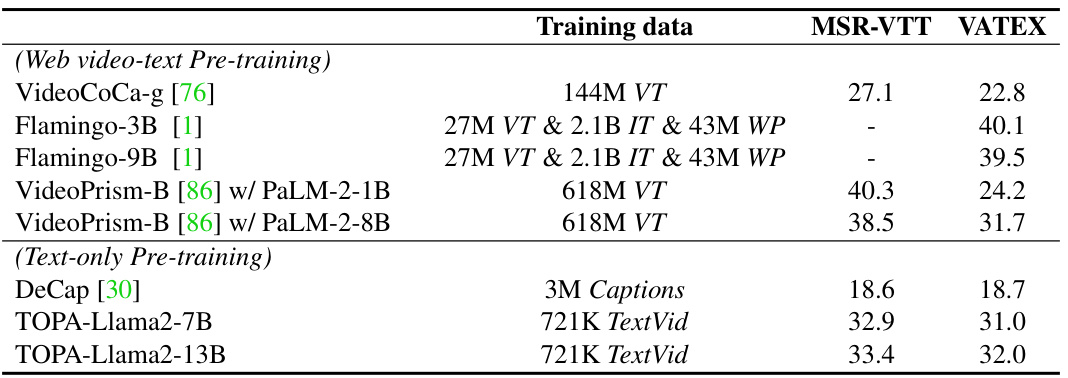
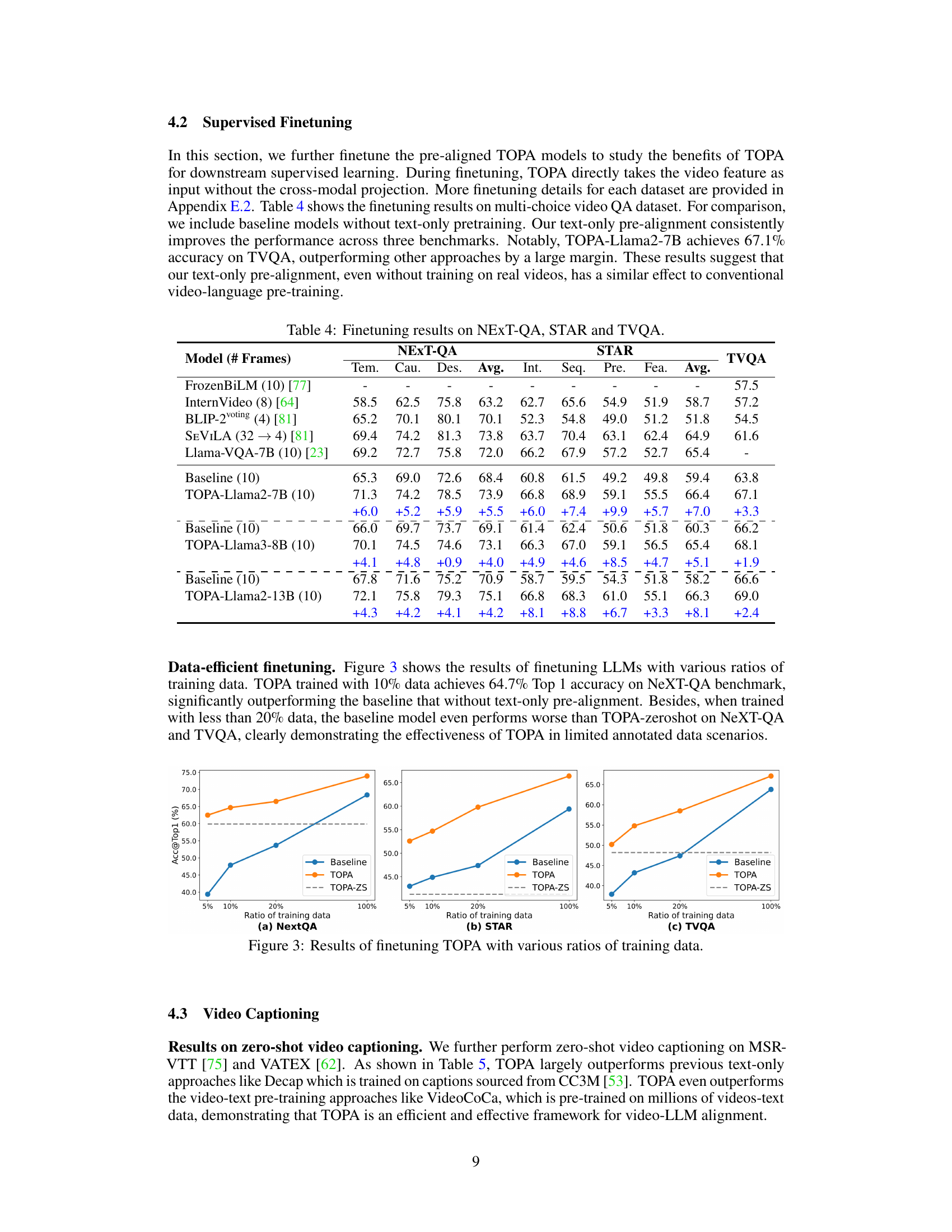
This table presents the zero-shot video captioning results on MSR-VTT and VATEX benchmarks, using CIDEr scores as the evaluation metric. It compares the performance of various models, categorized into those pre-trained on web video-text data and those using a text-only pre-training approach (TOPA). The table highlights the performance improvement achieved by TOPA compared to other text-only methods and even some video-text pre-training methods.
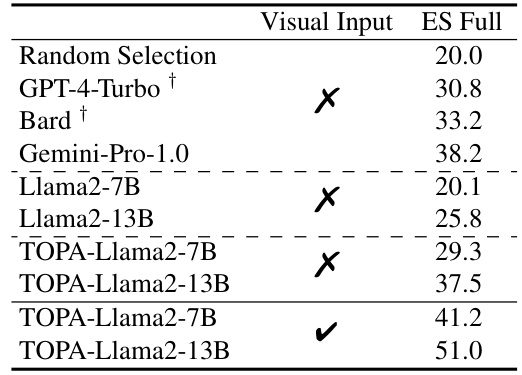
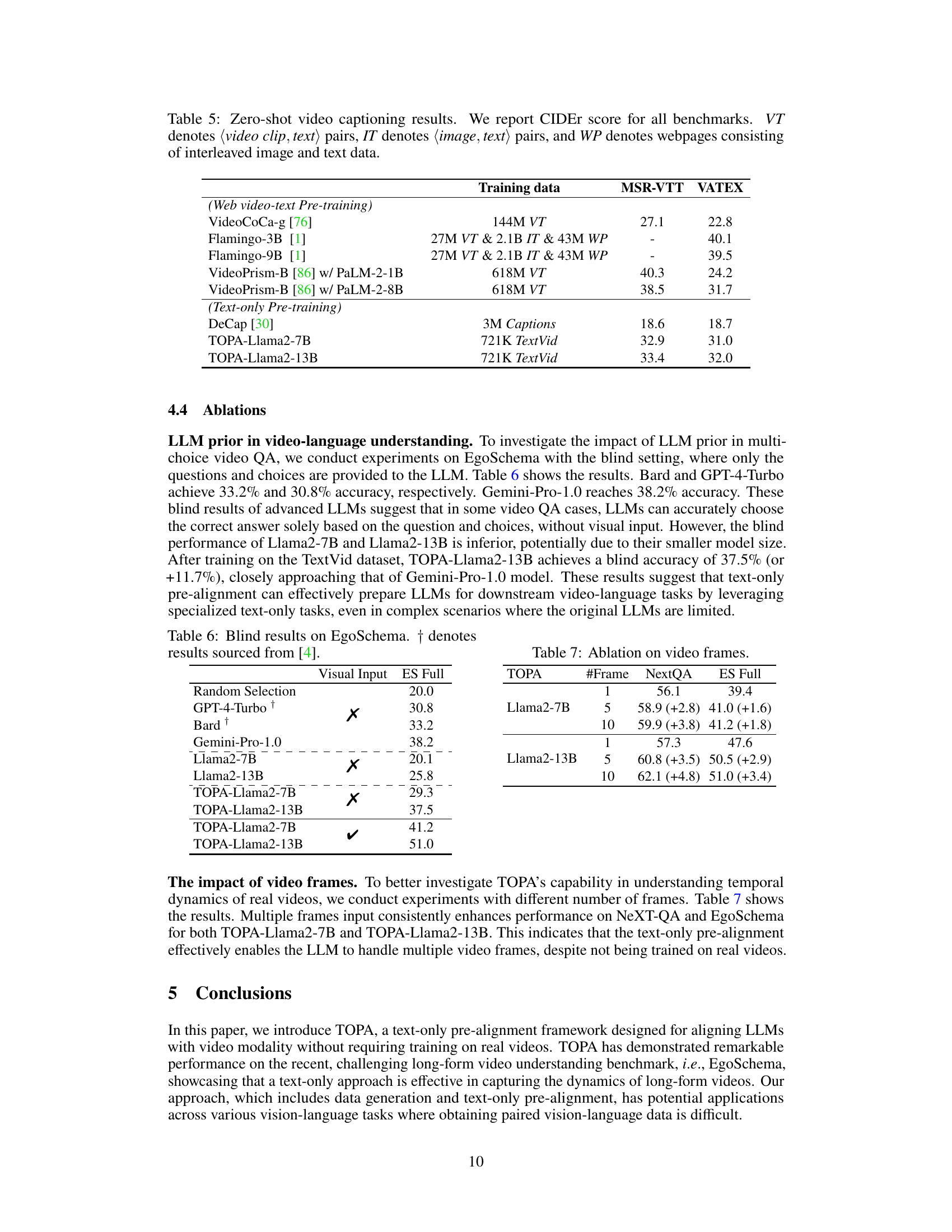
This table presents the results of a blind test conducted on the EgoSchema benchmark. The ‘Blind’ setting means that the model only received the questions and choices, but not the actual video. This tests the model’s ability to answer questions based solely on its pre-existing knowledge and linguistic understanding. The table compares the performance of several LLMs (Large Language Models) under this blind condition. The performance of TOPA models (TOPA-Llama2-7B and TOPA-Llama2-13B) is also shown, demonstrating their ability to perform well even without access to the video.
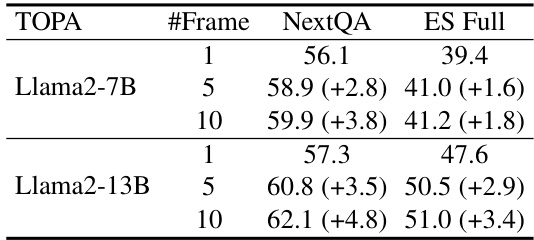
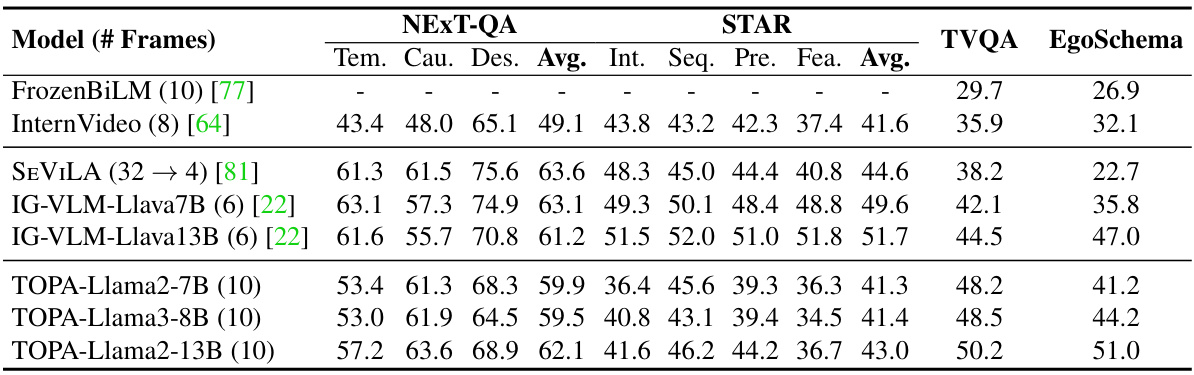
This table presents the ablation study on the number of video frames used as input to the TOPA model for the NeXT-QA and EgoSchema benchmarks. It shows the performance of Llama2-7B and Llama2-13B models with 1, 5, and 10 frames, demonstrating how the accuracy increases with the number of frames, indicating the model’s ability to capture temporal dynamics from more video information.
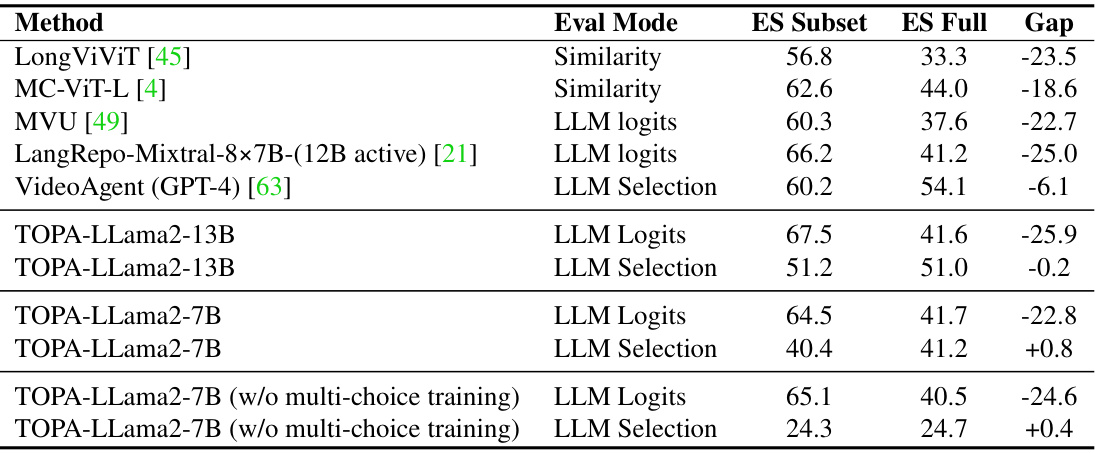
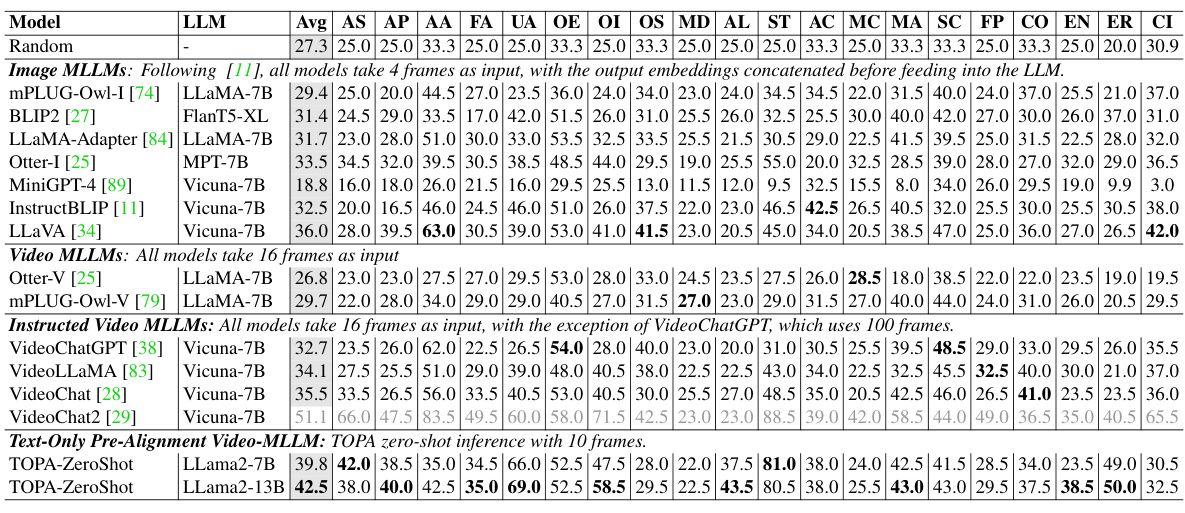
This table compares the performance of various methods on the EgoSchema benchmark’s subset and full set for multi-choice video QA. The ‘Gap’ column shows the difference in accuracy between the subset and full set, highlighting the challenge of generalizing to more complex and diverse video data. The methods include those using similarity-based approaches, LLM logits, and LLM selection. TOPA is shown with and without multi-choice training to demonstrate the impact of this type of training. This table demonstrates the impact of using different evaluation methods (LLM Logits vs LLM Selection) on the performance gap between the subset and full set of the EgoSchema dataset.

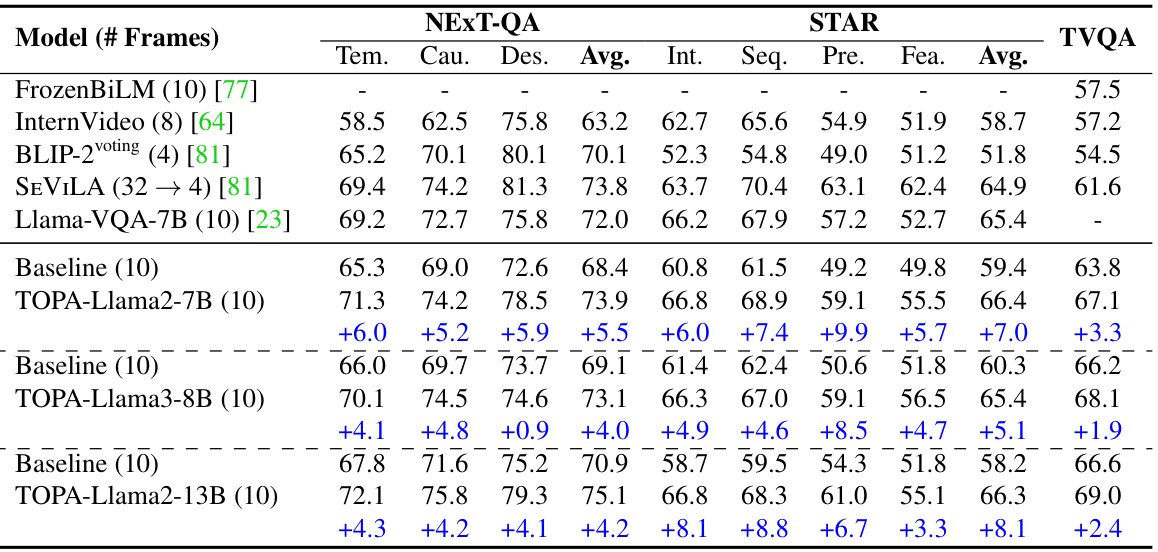
This table presents the ablation study of the modality projection (Equation 2) in the TOPA framework. It shows the results on the EgoSchema full set for two different models, TOPA-LLama2-7B and TOPA-LLama2-13B, with and without the modality projection. The modality projection aims to bridge the gap between CLIP text features used in pre-training and CLIP image features used in inference, improving the model’s performance.
This table presents the zero-shot results on the EgoSchema benchmark. It compares various video understanding approaches, categorized by their method (web video pre-training, adapting image MLLMs, LLM-based video agents, and the proposed TOPA method). The results are shown as accuracy at Top-1 (Acc@1), highlighting the performance of each method on the full EgoSchema dataset and, in some cases, a subset. The table also notes which methods use closed-source LLMs and those trained on in-domain egocentric videos.

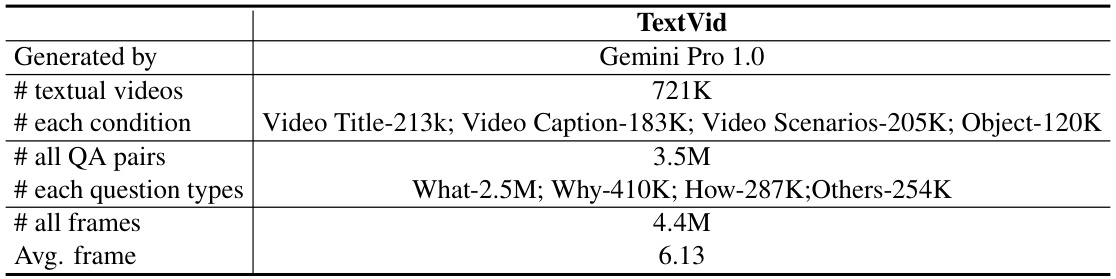
This table presents the vocabulary size of textual videos (Tideos) generated using different prompts. The prompts are based on four different datasets: Howto100m, Ego4D, WebVid, and WordNet. To ensure a fair comparison, a random sample of 20,000 global captions was selected from each dataset’s generated Tideos, and the resulting vocabulary size was then calculated and displayed in the table. This analysis helps to understand the diversity of the language used across different sources and their impact on the generated Tideos.
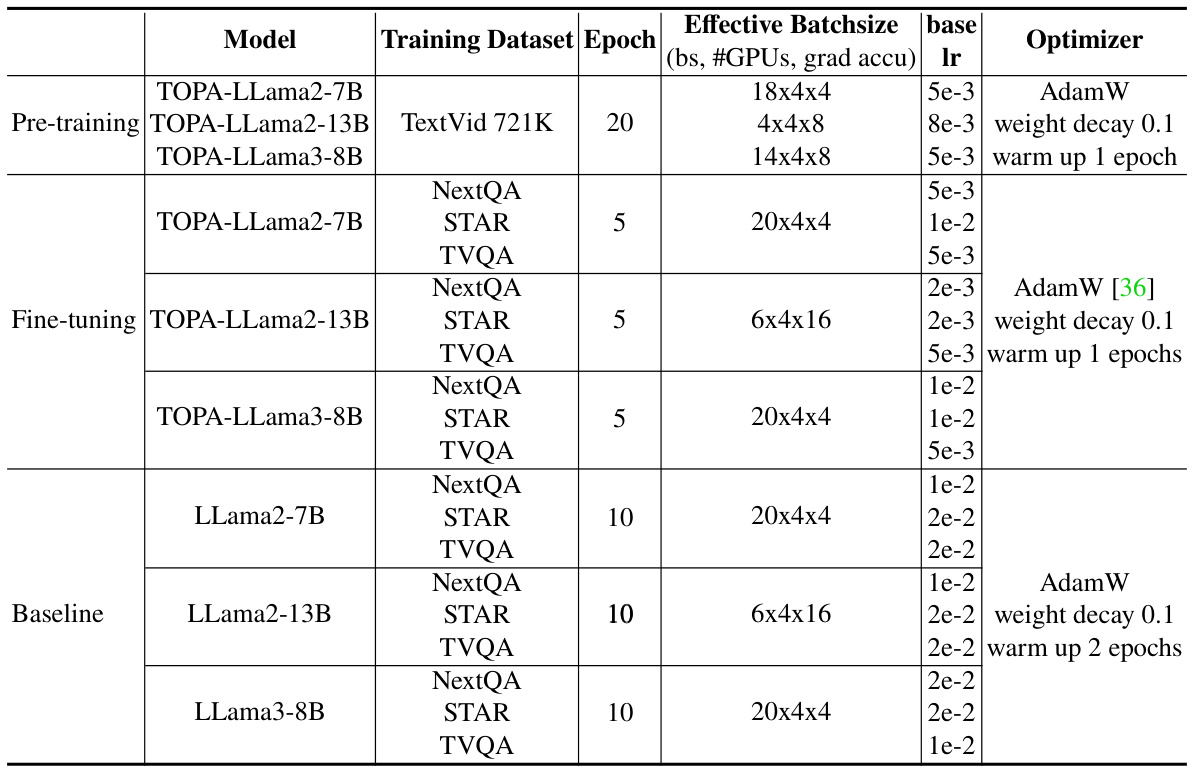
This table details the hyperparameters used for training the various models in the paper. It includes information about the model, training dataset, number of epochs, effective batch size, base learning rate, and the optimizer used. The table differentiates between the pre-training phase and the fine-tuning phase for the TOPA models, and also shows hyperparameters for the baseline models for comparison.
Full paper#