↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
In-context learning (ICL) in large language models (LLMs) has been limited by context window size, restricting research to few-shot ICL. This paper explores many-shot ICL, using hundreds or thousands of examples. However, this approach is limited by the availability of human-generated data.
To address the data limitation, the researchers propose two approaches: Reinforced ICL, which replaces human-written rationales with model-generated ones; and Unsupervised ICL, which removes rationales altogether. They find that both approaches are effective, particularly for complex reasoning tasks. The study demonstrates that many-shot ICL overcomes pre-training biases and performs comparably to fine-tuning, significantly advancing the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates the significant performance gains achievable through many-shot in-context learning (ICL), particularly in complex reasoning tasks. It also introduces novel ICL techniques (reinforced and unsupervised ICL) to mitigate the reliance on human-generated data, a major bottleneck in many-shot ICL. The findings challenge existing assumptions about ICL limitations and open up new avenues for research and development in large language models.
Visual Insights#

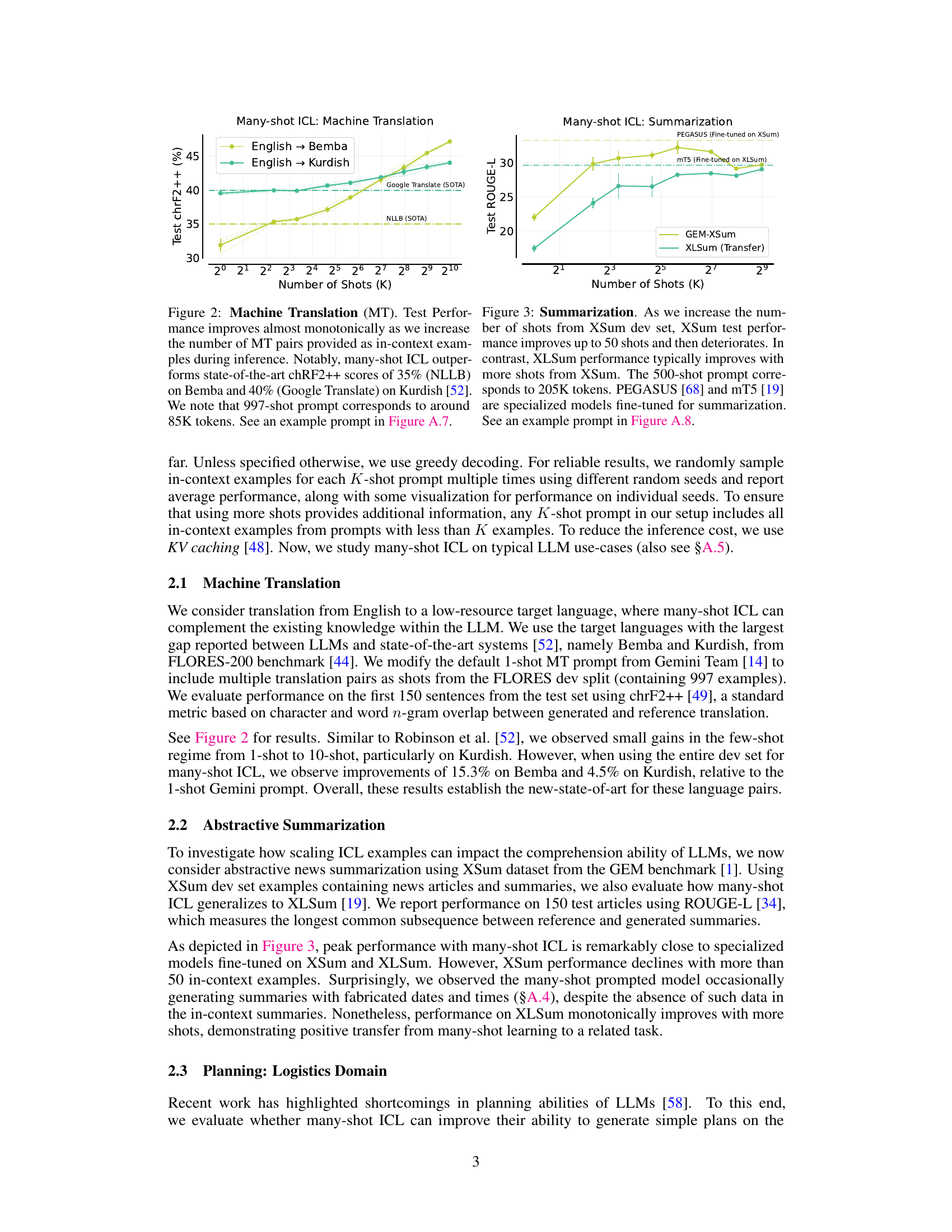
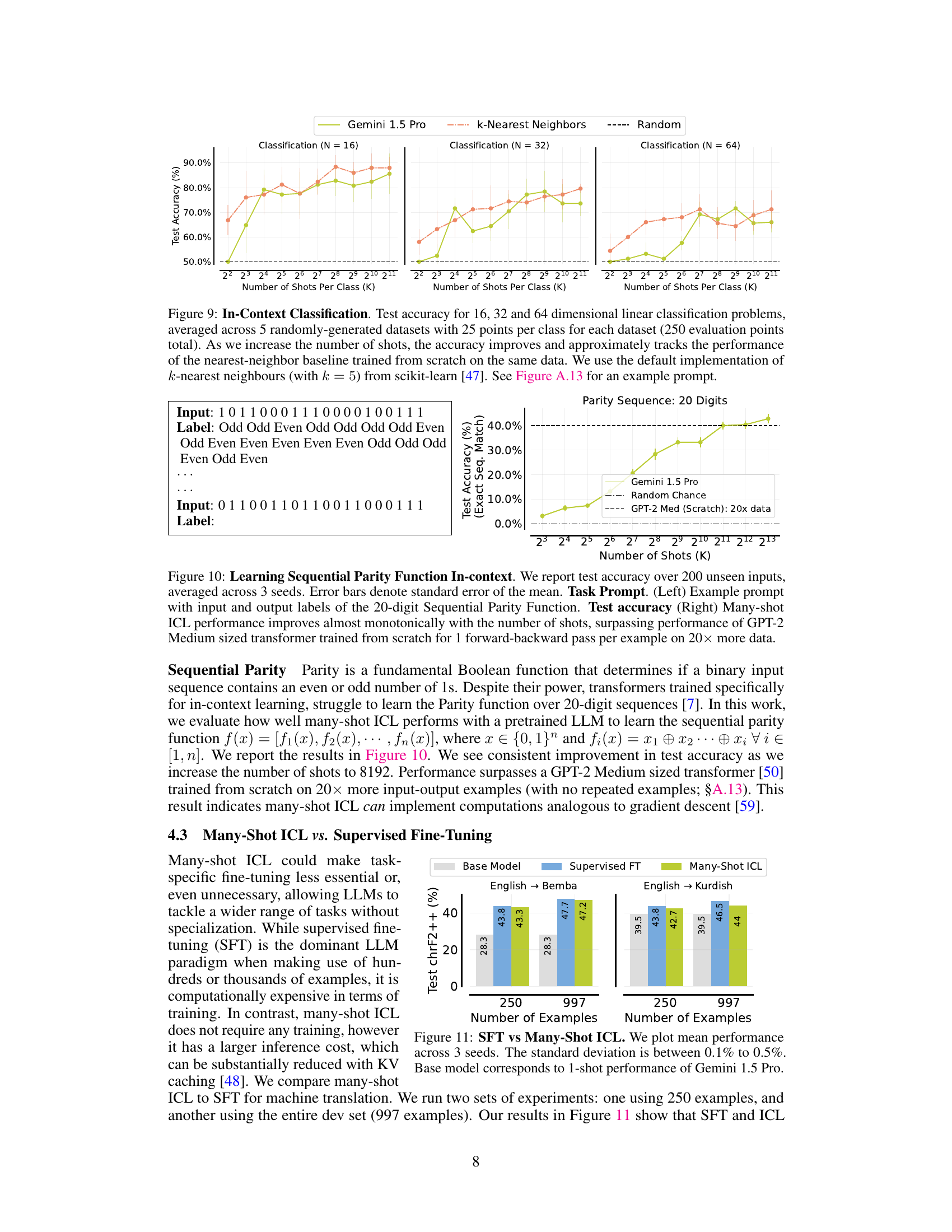
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks not involving natural language. The optimal number of shots for each task in the many-shot regime is indicated. The figure also notes the types of prompts (e.g., chain-of-thought) used for different tasks and benchmarks.

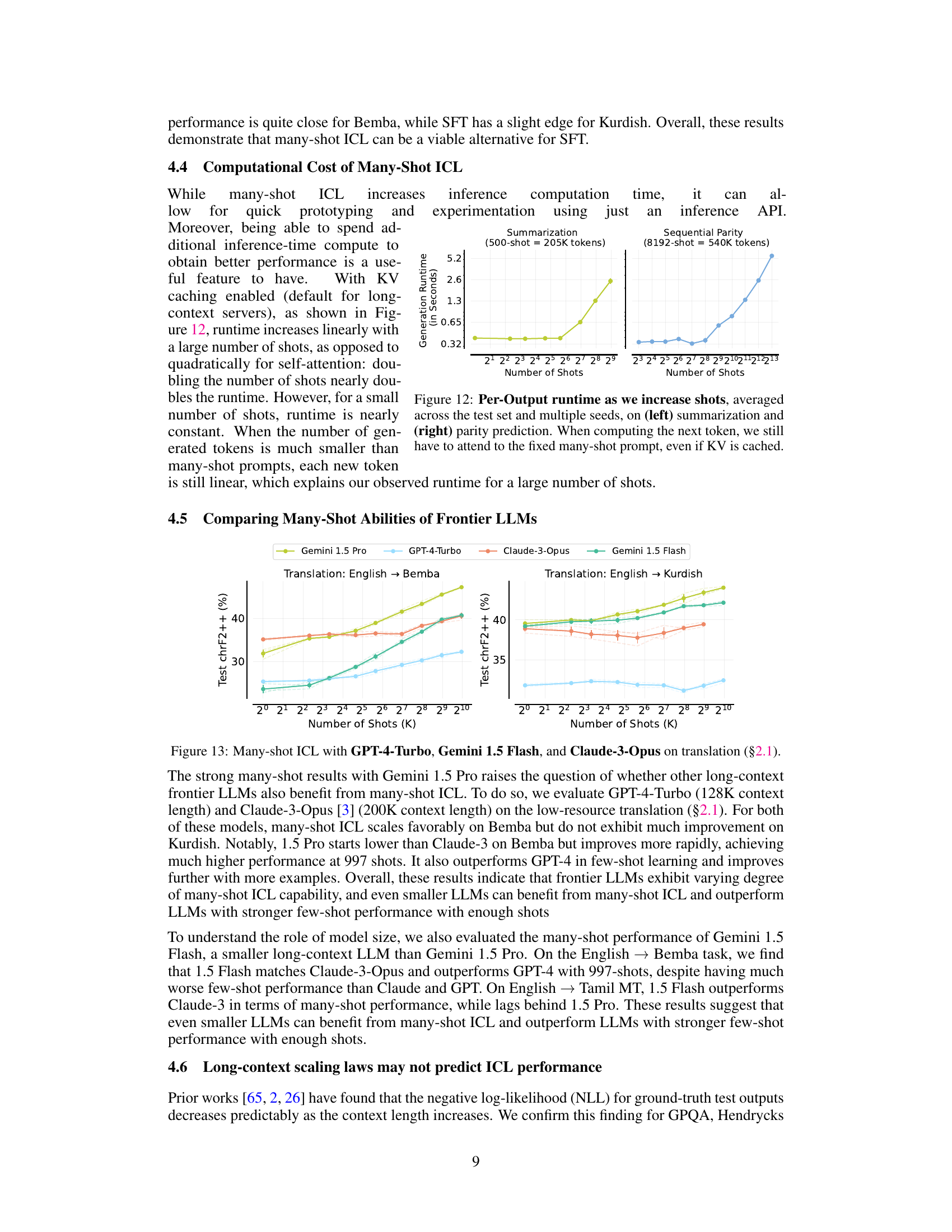
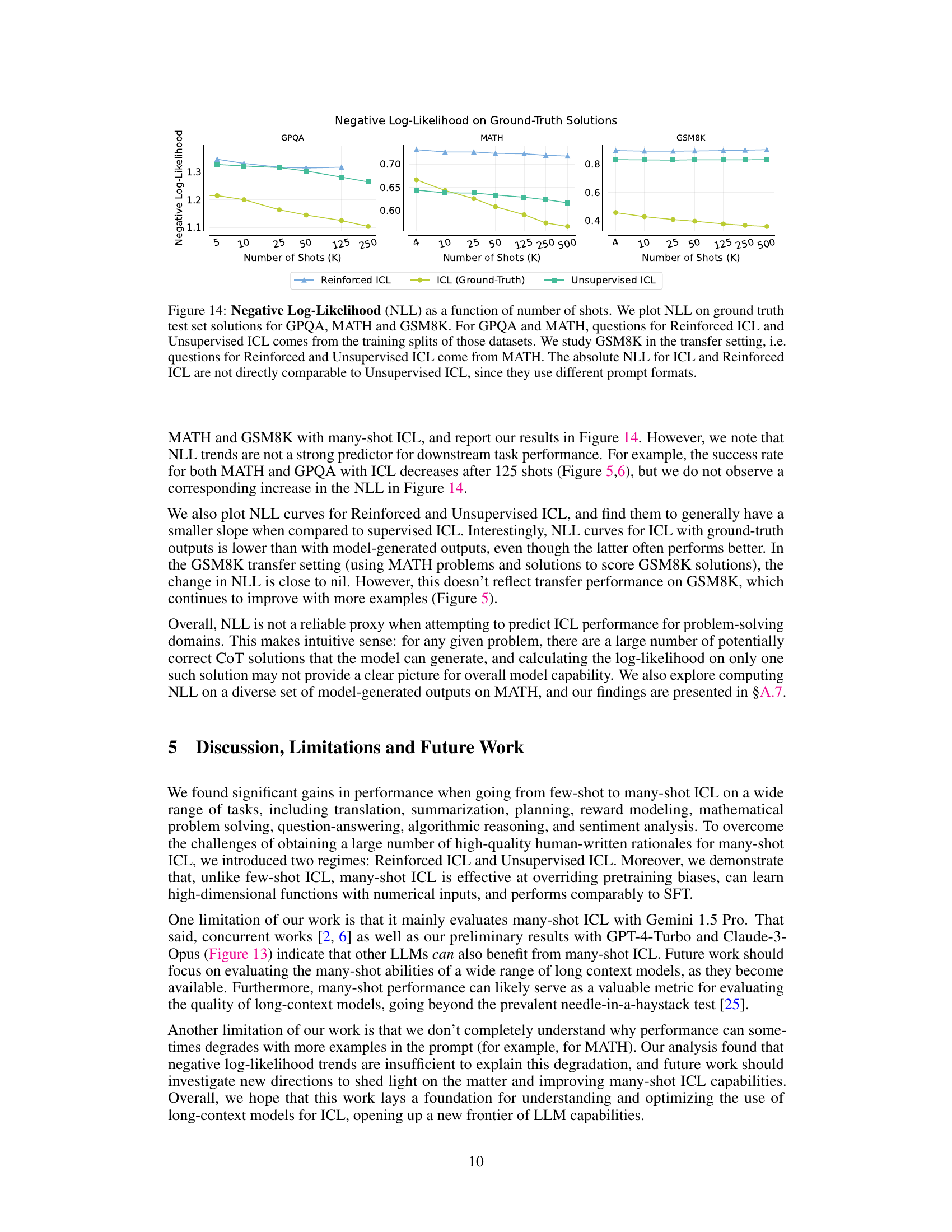
This figure compares the best-performing number of shots and the maximum number of shots tested in many-shot in-context learning (ICL) experiments across various tasks. It highlights the context length limitations of previous few-shot ICL approaches (using GPT-3’s 2048-token limit as a reference) and shows how many-shot ICL allows for significantly larger numbers of shots, which greatly impact performance. In some cases, performance even plateaus or slightly decreases after an optimal number of shots is reached.
In-depth insights#
Many-Shot ICL Gains#
The concept of “Many-Shot ICL Gains” in the context of large language models (LLMs) refers to the significant performance improvements observed when scaling up the number of input-output examples (shots) provided during in-context learning. Unlike few-shot learning, which utilizes only a handful of examples, many-shot learning leverages hundreds or even thousands. This increase in data allows the LLM to better understand the task’s nuances and generalize effectively. The gains are particularly noticeable on complex tasks requiring intricate reasoning or those where the model has inherent pre-training biases. Many-shot ICL demonstrates the ability to overcome such biases and even allows for learning high-dimensional functions previously inaccessible to few-shot methods. However, the success of many-shot ICL depends on factors such as the quality of examples, and the availability of sufficient human-annotated data which poses a limitation. Novel techniques such as Reinforced ICL (using model-generated rationales) and Unsupervised ICL (removing rationales altogether) offer promising solutions for mitigating the need for extensive human input. Overall, many-shot ICL represents a significant advancement, promising more versatile and powerful LLMs but needs further exploration to overcome its data dependency.
Reinforced ICL#
The concept of “Reinforced ICL” presented in the research paper introduces a novel approach to address the limitations of many-shot in-context learning (ICL) by leveraging model-generated rationales. Instead of relying solely on human-generated rationales, which can be expensive and time-consuming to obtain, this method utilizes model-generated chain-of-thought rationales, filtered based on their accuracy. This addresses a key bottleneck in many-shot ICL, the scarcity of high-quality human-generated data. Reinforced ICL demonstrates that model-generated rationales can be effective in achieving many-shot ICL performance, especially on complex reasoning tasks, showing comparable or even superior results to approaches relying on human-generated rationales. The method showcases the potential for using model-generated data to enhance ICL, particularly where access to human expertise is limited. The effectiveness of Reinforced ICL highlights the potential of self-supervised learning techniques within the context of LLMs and its impact on improving the capabilities and efficiency of ICL.
ICL Scaling Laws#
In exploring in-context learning (ICL), the concept of scaling laws becomes crucial. Scaling laws aim to understand how ICL performance changes as key factors like the number of examples or the context window size increase. While simple scaling might be observed in some cases, non-linear relationships frequently emerge, indicating that performance gains are not always directly proportional to increased resources. The investigation of ICL scaling laws seeks to identify optimal resource allocation for maximum performance. It also aims to predict performance improvements before running expensive experiments. Studying these laws is essential for building cost-effective and efficient ICL systems. Understanding them helps in designing models and deploying them in practical applications and developing more accurate cost models to predict performance, improve resource management, and guide future ICL research.
Bias Mitigation#
Bias mitigation in large language models (LLMs) is a critical area of research. Addressing biases present in training data is crucial, as these biases can significantly impact the model’s output, potentially leading to unfair or discriminatory outcomes. Various techniques are employed to mitigate bias, such as data preprocessing, where biased samples are identified and either removed or reweighted. Another approach is algorithm modification, which involves modifying the model’s architecture or training process to reduce its sensitivity to biased features. However, the effectiveness of these methods is often dataset-specific and context-dependent. Furthermore, achieving complete bias removal is generally impossible, as biases may be deeply ingrained in the model’s underlying architecture and knowledge representation. Consequently, ongoing research and development are needed to refine existing techniques and explore new approaches for effective bias mitigation in LLMs. The focus needs to shift towards comprehensive evaluation metrics that capture diverse aspects of bias and consider the broader social implications of the model’s deployment.
Future of ICL#
The future of in-context learning (ICL) holds immense potential, particularly given the recent advancements in large language models (LLMs). Scaling ICL to even larger context windows is crucial, enabling LLMs to handle more complex tasks and potentially replace the need for extensive fine-tuning. Addressing the limitations of human-generated data is key; reinforced and unsupervised ICL methods, utilizing model-generated data and chain-of-thought rationales, offer promising solutions for overcoming data scarcity. Further research into overcoming pre-training biases within ICL is necessary, as shown by the ability of many-shot ICL to overcome such biases. Finally, exploring alternative evaluation metrics, beyond next-token prediction loss, which better reflect actual ICL performance on reasoning and complex tasks, is needed. Investigating the interplay between model architecture and ICL capabilities can also provide valuable insights. Ultimately, the future of ICL depends on collaborative efforts to address these challenges, paving the way for LLMs to achieve unprecedented levels of adaptability and versatility.
More visual insights#
More on figures
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. The bar chart shows that many-shot ICL significantly outperforms few-shot ICL, especially on complex tasks that are not based on natural language. Optimal numbers of shots for each task in the many-shot setting are indicated on the bars. The figure also notes the methodology for determining the number of shots used in the few-shot ICL experiments and specifies the types of rationales used for different tasks.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex, non-natural language tasks. The optimal number of shots for each task in the many-shot setting is indicated. The figure also highlights the use of chain-of-thought rationales in some tasks and points to additional sections of the paper for more details.

This figure compares the performance of three different in-context learning (ICL) methods on two mathematical problem-solving datasets: MATH500 and GSM8K. The left panel shows results for MATH500, while the right shows transfer performance to GSM8K using prompts from MATH. The three methods are: ICL with ground-truth solutions, unsupervised ICL (using only problem statements), and reinforced ICL (using model-generated rationales). The figure demonstrates that reinforced and unsupervised ICL, especially with many shots, significantly outperform standard ICL on both datasets. The results highlight the effectiveness of model-generated rationales in many-shot ICL and its ability to generalize across datasets.
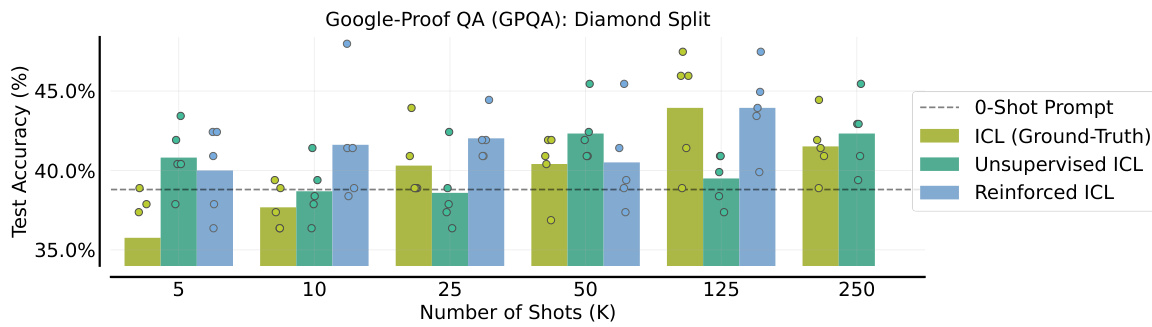
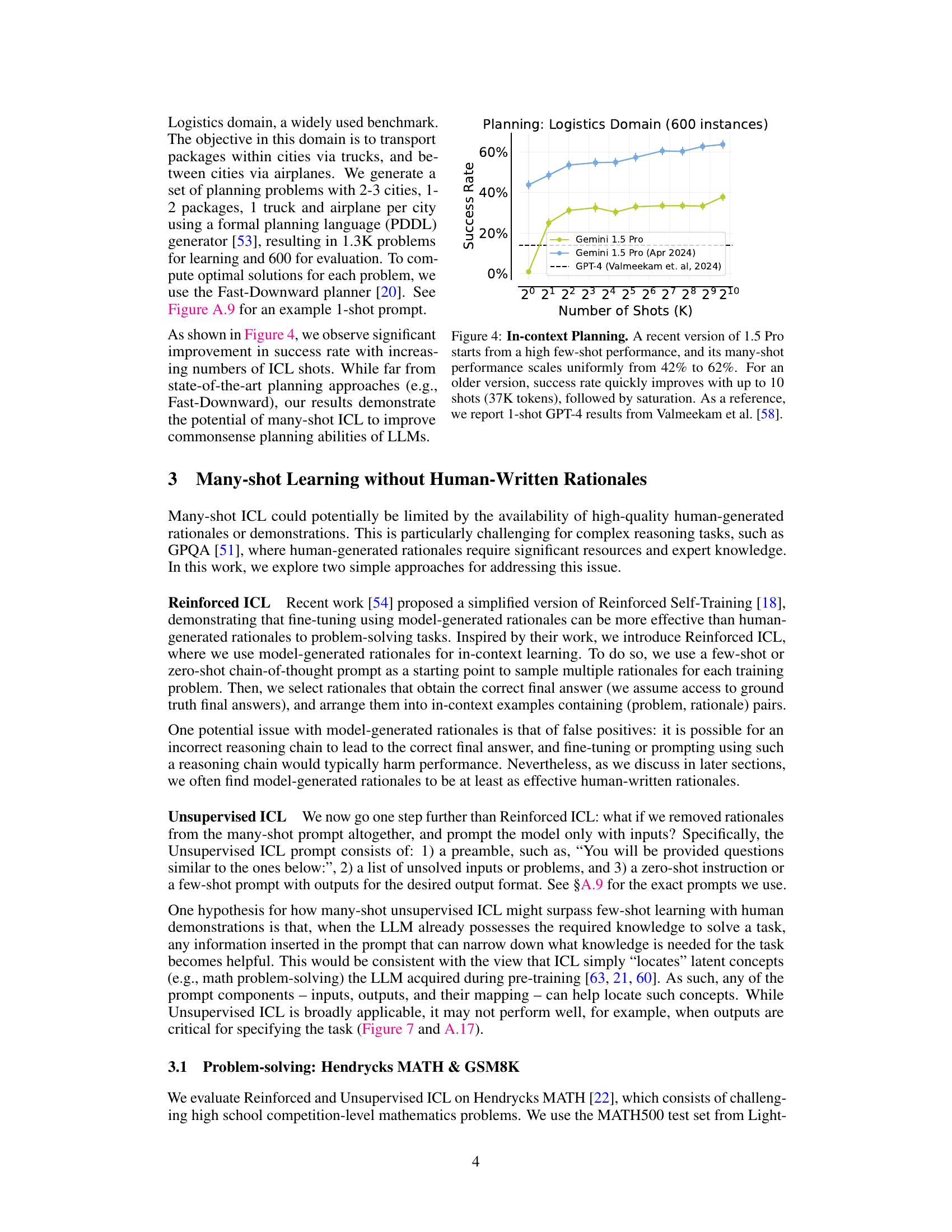
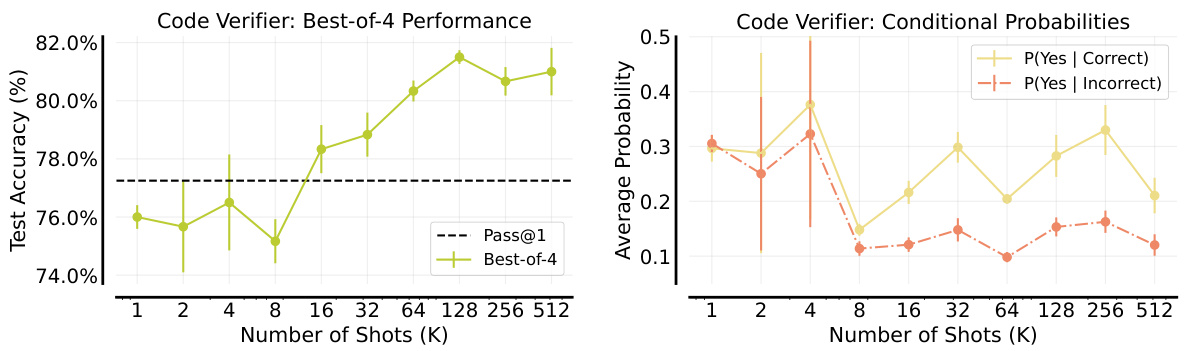
This figure shows the performance comparison of three different methods for Google-Proof QA (GPQA) task across different numbers of shots (in-context examples). The three methods are: 1) ICL (Ground-Truth) using human-written rationales, 2) Unsupervised ICL prompting the model only with questions, and 3) Reinforced ICL using model-generated rationales. The results indicate that Reinforced ICL consistently outperforms both Unsupervised ICL and the baseline zero-shot prompt, especially with 125 shots, almost matching the state-of-the-art performance of Claude-3 Sonnet. Unsupervised ICL shows mixed results, sometimes matching or surpassing the zero-shot baseline but generally underperforming Reinforced ICL.
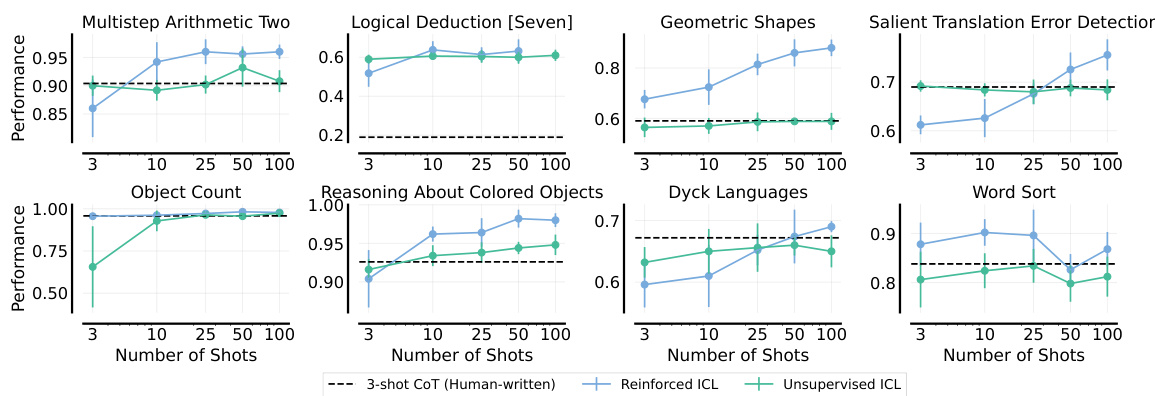
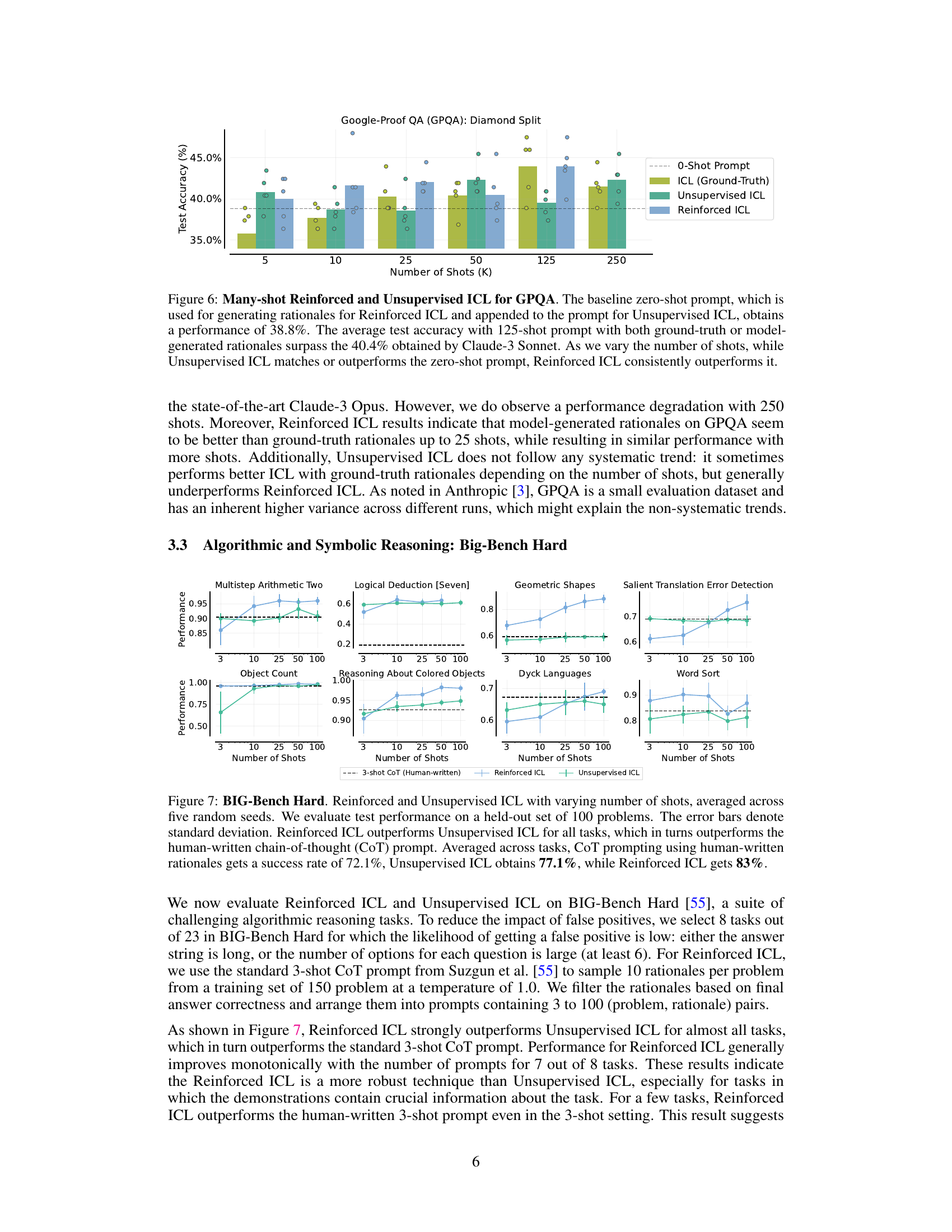
This figure shows the performance comparison of different in-context learning methods on the BIG-Bench Hard benchmark. Reinforced ICL consistently outperforms Unsupervised ICL and the baseline human-written chain-of-thought prompting across eight algorithmic and symbolic reasoning tasks. The results demonstrate the effectiveness of model-generated rationales in improving many-shot in-context learning performance.

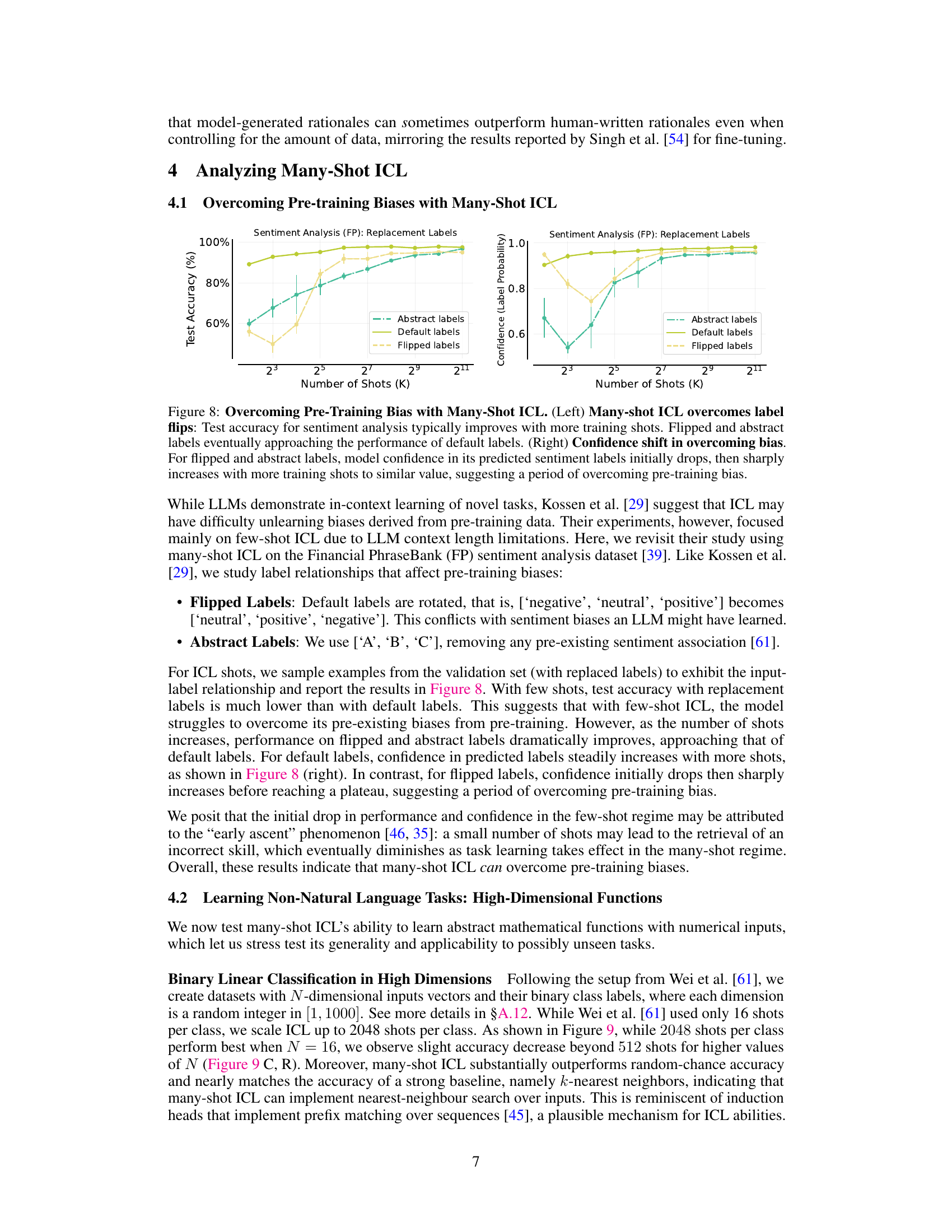
This figure shows the results of an experiment designed to evaluate the ability of many-shot in-context learning (ICL) to overcome pre-training biases. Two sets of experiments were performed on the Financial PhraseBank (FP) sentiment analysis dataset using three types of labels: default labels, flipped labels (where the order of sentiment categories is reversed), and abstract labels (where non-descriptive labels ‘A’, ‘B’, ‘C’ are used). The left panel displays the test accuracy for each label type as a function of the number of shots (in-context examples). The right panel shows the change in confidence (label probability) for the same label types, demonstrating the learning process of overcoming the bias. The results indicate that many-shot ICL successfully overcomes pre-training biases as the number of shots increases, demonstrating a significant improvement in accuracy compared to a few-shot setting and eventually achieving similar performance to the default label setting.
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It shows that many-shot ICL significantly outperforms few-shot ICL, especially on complex tasks not involving natural language. The optimal number of shots for each task in the many-shot setting is indicated. The figure also notes the type of prompts and datasets used for each task.

The figure compares the performance of few-shot and many-shot in-context learning across various tasks. It shows that many-shot ICL significantly improves performance compared to few-shot ICL, especially on challenging non-language tasks. The optimal number of shots varies across tasks. Reasoning tasks utilize chain-of-thought prompting.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It shows that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks not involving natural language. The optimal number of shots for each task in the many-shot setting is indicated. Different task types (problem-solving, summarization, translation, etc.) are included, and details about prompting techniques used (like chain-of-thought rationales) are noted.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks, demonstrating the significant performance gains achieved with many-shot ICL, especially on complex, non-natural language tasks. It highlights the optimal number of shots for each task in the many-shot setting and notes the methodology used for few-shot ICL. Specific details on the types of prompts and datasets used for each task are provided.
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. The bar chart shows that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks not involving natural language. The optimal number of shots for each task in the many-shot setting is indicated within each bar. The few-shot results use either standard benchmarks’ shot numbers (e.g., 4 shots for MATH) or the maximum number of shots possible while remaining within GPT-3’s context window. Tasks requiring reasoning (MATH, GSM8K, BBH, GPQA) utilize chain-of-thought rationales. Translation results are specifically for English to Bemba, summarization uses XLSum, MATH results show the MATH500 test set, and sentiment analysis utilizes semantically unrelated labels.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It shows that many-shot ICL significantly outperforms few-shot ICL, especially on complex tasks that are not based on natural language. The optimal number of shots is indicated for each task in the many-shot setting. Different types of prompts and datasets are used for different tasks.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently achieves higher accuracy than few-shot ICL, especially for tasks involving complex reasoning. The optimal number of shots for each task is also shown, ranging from just a few to several hundreds, suggesting the substantial increase in context window size significantly affects the performance. The figure highlights the benefits of using many-shot ICL by showcasing substantial performance gains across different tasks such as problem solving, question answering, machine translation and summarization.

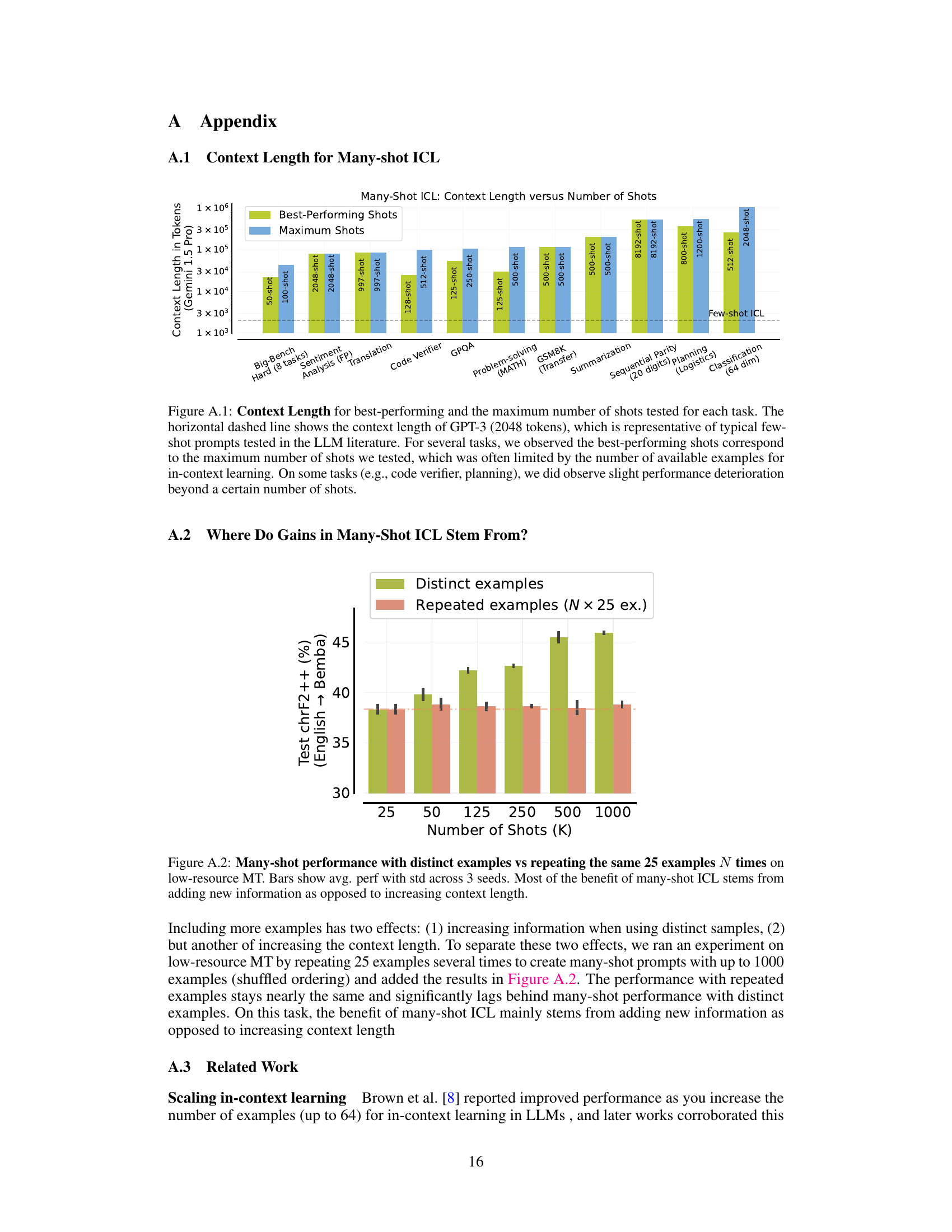
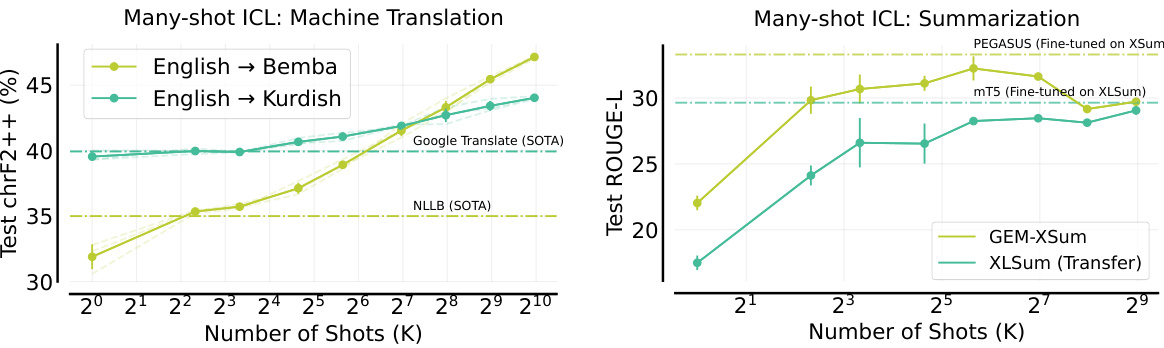
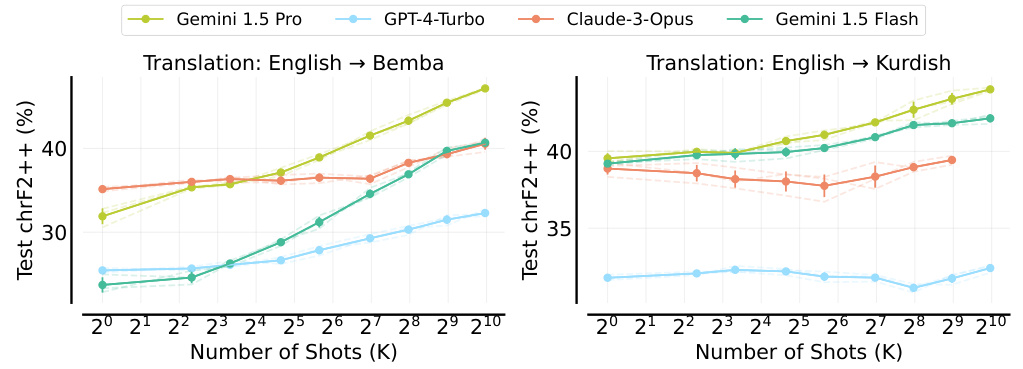
This figure compares the performance of many-shot in-context learning (ICL) using two different approaches: using distinct examples and repeating a small set of examples multiple times. The results show that using distinct examples yields significantly better performance in low-resource machine translation than simply increasing the context length by repeating the same examples. This indicates that the primary benefit of many-shot ICL comes from adding new information rather than simply increasing the context window size.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks that are not based on natural language. The optimal number of shots is indicated for each task in the many-shot setting. Few-shot ICL results are based on either the standard number of shots used in the task’s benchmark or the maximum prompt length tested (less than the 2048-token limit of GPT-3). Tasks involving reasoning use chain-of-thought rationales. Specific details for each task’s experimental setup are provided in the caption.
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL significantly improves performance compared to few-shot ICL, especially on complex tasks involving reasoning, indicating the benefits of scaling ICL to many examples. The chart displays percentage improvements, optimal shot numbers for many-shot ICL, and the type of prompts and datasets used for each specific task.

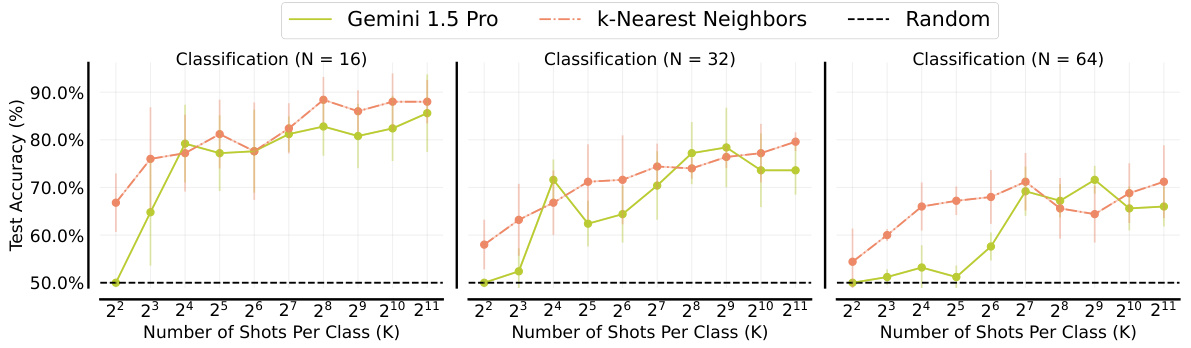
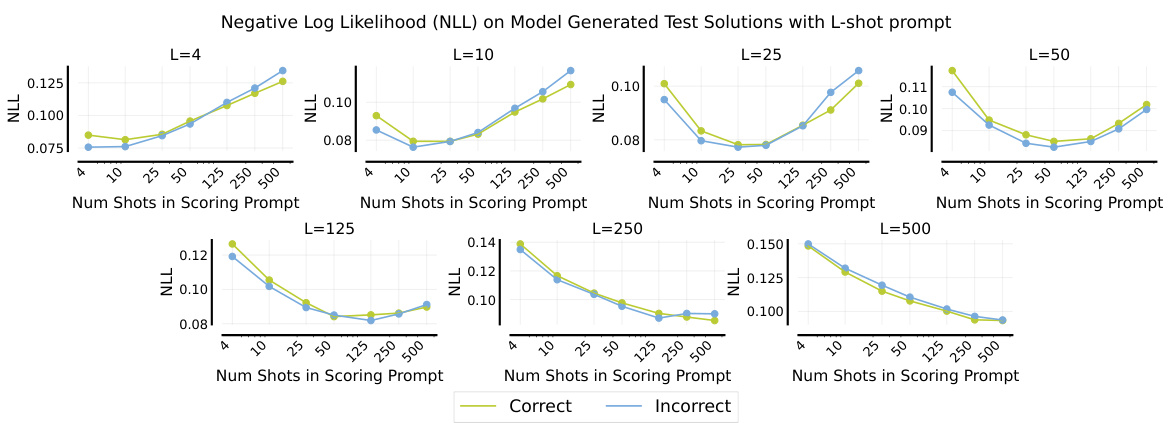
This figure shows the sensitivity of many-shot in-context learning (ICL) to the order of examples in the prompt. Ten different random orderings of 50 in-context examples from the MATH training split were used to evaluate performance on the MATH500 test set. The results demonstrate that performance varies significantly across different problem subcategories within MATH500. An ordering that performs well in one subcategory might perform poorly in another. However, the average performance across all subcategories shows less variation than individual subcategories.
This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It shows that many-shot ICL significantly outperforms few-shot ICL, especially on complex tasks that are not based on natural language. The optimal number of shots for each task in the many-shot setting is indicated. Different types of tasks are included, and the prompts used are described.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex, non-natural language tasks. The optimal number of shots for each task in the many-shot setting is indicated within each bar. The figure also notes the type of prompt used for each task and the specific datasets involved, offering context for interpreting the results. The significant performance improvements seen with many-shot ICL highlight its potential for enhancing LLM capabilities.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks that don’t involve natural language. The figure provides a bar chart showing the percentage improvement achieved by many-shot ICL for each task, along with the optimal number of shots used. The tasks include summarization, planning, problem solving, question answering, translation, and sentiment analysis.

This figure compares the performance of few-shot and many-shot in-context learning across various tasks. It shows that many-shot learning consistently outperforms few-shot learning, especially on complex tasks that are not based on natural language. The optimal number of shots for each task is also displayed. Note that different tasks may use different numbers of shots for few-shot learning.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It shows that many-shot ICL consistently outperforms few-shot ICL, especially on complex tasks that aren’t based on natural language. The optimal number of shots for each task in the many-shot setting is also provided. Different tasks (summarization, translation, problem solving, etc.) used different numbers of shots, and reasoning-based tasks used chain-of-thought prompting. The results demonstrate that scaling up the number of shots significantly improves ICL performance.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially on complex, non-natural language tasks. The optimal number of shots for each task in the many-shot setting is indicated. The figure also notes the methodology for determining the number of shots in the few-shot setting and the types of prompts used for different task categories.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL significantly improves performance compared to few-shot ICL, especially on challenging tasks that don’t involve natural language processing. The optimal number of shots for each task is shown. The figure highlights the impact of increased context window size on ICL performance.
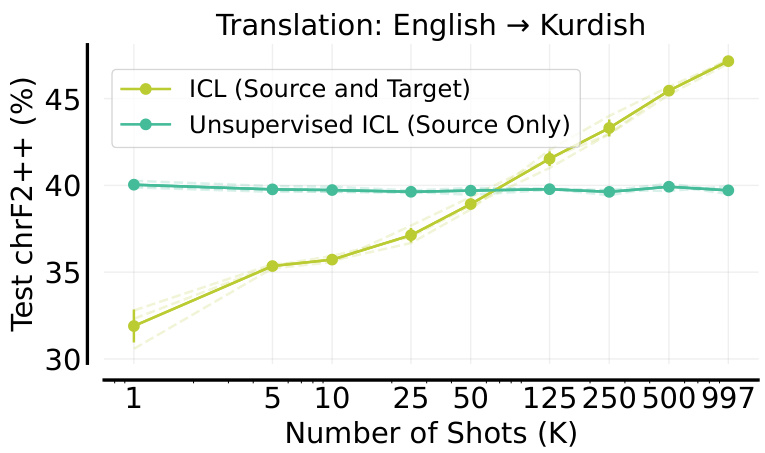
This figure shows the performance of unsupervised ICL on machine translation from English to Kurdish. The results demonstrate that providing only source sentences (without target translations) in the prompt does not improve performance. This is expected because the model needs both source and target examples to learn the translation task effectively. The figure is referenced in the appendix section. It complements Figure 2 in the main body of the paper, which shows that supervised many-shot ICL (with both source and target language pairs) does improve the performance of low-resource machine translation.
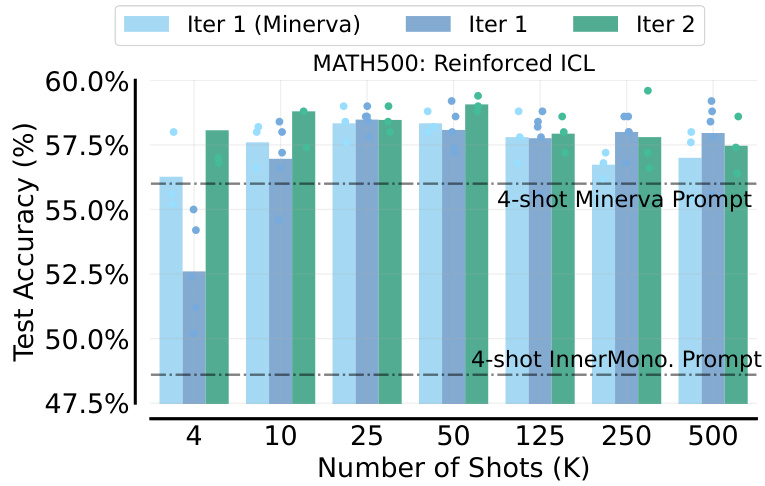
The figure shows the performance comparison of three different methods: ICL with ground truth, reinforced ICL, and unsupervised ICL on MATH500 and GSM8K datasets. The left panel shows that reinforced and unsupervised ICL outperform ICL with ground truth on MATH500. The right panel demonstrates the transferability of the learned knowledge from MATH to GSM8K, where reinforced ICL again shows superior performance. Overall, the results highlight the effectiveness of reinforced and unsupervised ICL in many-shot learning.

This figure compares the performance of few-shot and many-shot in-context learning (ICL) across various tasks. It demonstrates that many-shot ICL consistently outperforms few-shot ICL, especially for complex tasks that do not involve natural language. The optimal number of shots for each task in the many-shot regime is provided. The figure also highlights the use of chain-of-thought prompting for reasoning-intensive tasks.
Full paper#