↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) have shown promise in reasoning, but their performance is often limited by either relying on simple, single-query prompts or complex, computationally expensive multi-query approaches. Existing methods lack universality and generalization, often requiring task-specific designs and neglecting to leverage informative guidelines or thoughts from previous tasks. These limitations hinder the efficiency, accuracy and robustness of LLMs in complex reasoning scenarios.
The paper introduces Buffer of Thoughts (BoT), a novel framework that uses a “meta-buffer” to store high-level thoughts distilled from diverse problem-solving processes. For each problem, BoT retrieves a relevant thought-template, instantiates it with specific reasoning structures, and conducts efficient reasoning. A buffer-manager dynamically updates the meta-buffer, enhancing its capacity over time. Experiments on various challenging reasoning tasks demonstrated BoT’s significant performance improvements, achieving substantial gains in accuracy and efficiency compared to state-of-the-art methods, while only requiring a fraction of the computational cost. This efficiency and improved performance suggests BoT could be a major step towards more robust and effective LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient thought-augmented reasoning framework (BoT) that significantly improves the accuracy, efficiency, and robustness of large language models (LLMs) across various reasoning-intensive tasks. BoT’s use of shared high-level thoughts and adaptive instantiation offers significant advantages over existing methods, opening avenues for enhanced LLM performance and scalability in complex reasoning tasks.
Visual Insights#

This figure compares three different approaches to reasoning with large language models (LLMs): single-query, multi-query, and the proposed Buffer of Thoughts (BoT) method. Single-query methods rely on a single LLM query with a carefully crafted prompt to elicit a correct response, but this often requires significant task-specific engineering and struggles with complex problems. Multi-query methods break down complex tasks into multiple sub-problems solved with iterative LLM queries, potentially improving accuracy but at the cost of increased computational expense. The BoT method leverages a ‘meta-buffer’ storing reusable high-level ’thought-templates’ distilled from previously solved tasks, allowing efficient and accurate reasoning even for complex problems by retrieving relevant templates and instantiating them with task-specific details. The figure visually represents the flow of information and processing steps in each method, highlighting the key differences in approach and their respective strengths and weaknesses in terms of accuracy and efficiency.
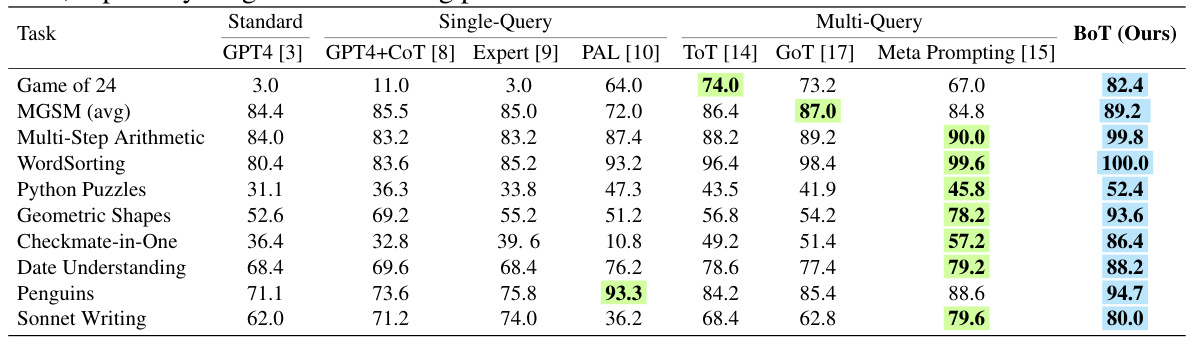
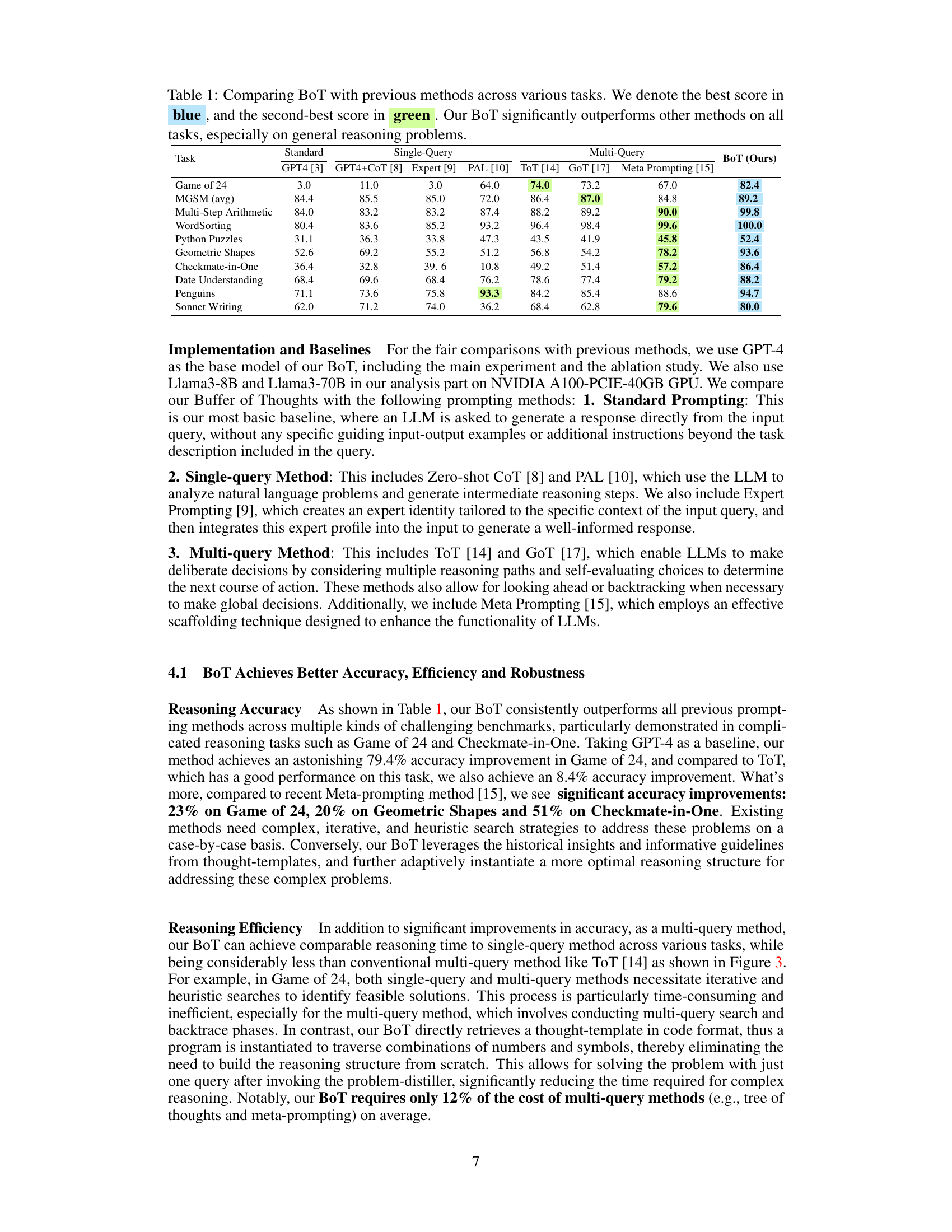
This table presents a comparison of the Buffer of Thoughts (BoT) method with several other state-of-the-art methods across ten diverse reasoning tasks. The tasks cover areas such as arithmetic, geometric reasoning, code generation, and more. For each task, the table shows the accuracy or success rate achieved by various single-query, multi-query, and prompting methods, as well as the BoT method. The best and second-best performing methods for each task are highlighted in blue and green, respectively. The results demonstrate that BoT achieves significantly higher performance than other methods on most tasks, particularly for complex reasoning problems.
In-depth insights#
Thought-Augmented LLMs#
Thought-augmented LLMs represent a significant advancement in leveraging the capabilities of large language models (LLMs). By incorporating explicit reasoning steps and incorporating external knowledge, these models move beyond simple pattern matching. The key innovation lies in the integration of structured thought processes, enabling LLMs to tackle complex, multi-step reasoning tasks more effectively. This augmentation can be achieved through various techniques such as chain-of-thought prompting, tree/graph-of-thought methods, and the novel meta-buffer approach. The meta-buffer approach is particularly promising as it allows for the efficient reuse of knowledge gained from solving previous tasks, thus improving both accuracy and efficiency. However, challenges remain in balancing the complexity of the thought augmentation with the computational cost and ensuring the generalizability and robustness of the learned thought structures across diverse tasks. Future research should focus on developing more sophisticated techniques for knowledge representation and retrieval, more scalable and efficient training methods, and exploring the potential of integrating thought-augmented LLMs into broader applications involving human-computer interaction and decision support systems.
Meta-buffer Efficiency#
Meta-buffer efficiency is crucial for the success of the Buffer of Thoughts framework. A well-designed meta-buffer, containing distilled high-level thoughts (thought-templates), enables efficient retrieval and instantiation of relevant reasoning structures for each problem. Efficient retrieval relies on effective indexing and similarity measures to quickly match the current problem with the appropriate thought-template. Adaptive instantiation is key, allowing for dynamic modification of the template to fit the specific problem context. Efficient updating of the meta-buffer via the buffer-manager is essential for maintaining relevance and scalability. A poorly designed meta-buffer could lead to slow retrieval times, inaccurate instantiation, or even an inability to find relevant templates. Thus, focusing on efficient storage, retrieval, and dynamic update mechanisms is paramount for ensuring the overall effectiveness and scalability of the BoT framework.
BoT Reasoning#
BoT Reasoning, as presented in the research paper, introduces a novel approach to enhance large language model (LLM) reasoning capabilities. It leverages a meta-buffer storing high-level “thought-templates” distilled from various problem-solving processes. For a given problem, BoT retrieves a relevant thought-template, instantiates it with specific reasoning structures, and performs efficient, thought-augmented reasoning. This approach offers improvements in accuracy, efficiency, and robustness. The dynamic update mechanism of the meta-buffer ensures scalability and adaptability as more tasks are encountered and solved. The core innovation lies in the ability to learn and share generalized reasoning strategies across tasks, moving beyond task-specific prompting techniques. The effectiveness is demonstrated through significant performance gains across several challenging reasoning benchmarks, showing strong generalization capabilities and cost efficiency compared to multi-query prompting methods.
Future Directions#
Future research should focus on enhancing the scalability and robustness of the Buffer of Thoughts framework. Investigating techniques to automatically refine and update the meta-buffer is crucial for continuous improvement. Exploring the integration of external knowledge sources and other reasoning methods with BoT to improve problem-solving capabilities in complex real-world scenarios is a key area. Developing robust methods for handling noisy or incomplete input data is needed for broader applicability. Furthermore, rigorous theoretical analysis and empirical evaluation on a wider range of tasks and benchmarks will strengthen the framework’s foundation. Comparative studies against alternative thought augmentation techniques are also important for assessing the unique contributions of BoT. Finally, exploring ethical implications and designing safeguards to mitigate potential biases or misuse of the technology is essential for responsible development and deployment.
BoT Limitations#
The Buffer of Thoughts (BoT) framework, while demonstrating significant improvements in accuracy and efficiency for large language model reasoning, has inherent limitations. Scalability is a concern; the meta-buffer’s size and the computational cost of updating it could become substantial with a massive increase in tasks and data. The quality of distilled thought-templates greatly impacts BoT’s performance; inaccurate or incomplete templates hinder the accuracy of instantiated reasoning. The generalization ability of the method, while promising, needs further evaluation across diverse tasks and benchmarks beyond those presented. Furthermore, the reliance on problem distiller introduces a potential bottleneck, and performance depends on its ability to correctly extract critical information. The framework’s current success relies on LLMs with advanced capabilities; its performance with less powerful LLMs remains unclear. Lastly, the robustness needs more extensive tests to ascertain consistency under different conditions and error scenarios. Addressing these limitations would greatly enhance BoT’s practical applicability and overall reliability.
More visual insights#
More on figures

This figure illustrates the Buffer of Thoughts (BoT) reasoning process, comparing it to traditional Chain-of-Thought and Plan-and-Solve methods. It highlights the key steps: problem distillation (extracting relevant information), thought retrieval (selecting an appropriate thought template from the meta-buffer), and instantiated reasoning (adapting the template to solve the specific problem). The use of a meta-buffer to store reusable high-level thought-templates is emphasized, showcasing how BoT improves efficiency and accuracy by leveraging previously learned problem-solving strategies. The figure uses color-coding (orange for thought templates, blue for instantiated thoughts) to visually distinguish the different stages of the process. An example problem is shown to demonstrate the workflow.

This figure compares the inference time of different prompting methods across three benchmark tasks: Game of 24, MGSM, and Checkmate-in-One. The methods compared are: Buffer of Thoughts (Ours), GPT-4, GPT-4+CoT, Expert Prompting, PAL, and ToT. The y-axis represents the logarithmic inference time in seconds, and the x-axis represents the benchmark task. The figure shows that Buffer of Thoughts has comparable inference times to single-query methods (Expert Prompting and PAL) and significantly faster times than multi-query methods (ToT).

This figure compares the robustness of different prompting methods, including the proposed Buffer of Thoughts (BoT), across various reasoning benchmarks. Robustness is measured as the average success rate over multiple runs. The BoT demonstrates superior robustness, consistently outperforming other methods across all benchmarks. This highlights the method’s ability to handle variations and uncertainties in problem solving.
This figure illustrates how the Buffer of Thoughts (BoT) method works. It shows a comparison of different reasoning processes, highlighting how BoT leverages a ’thought-augmented reasoning’ approach. The process begins with an input problem, which is distilled to extract key information. A relevant ’thought-template’ (highlighted in orange) is then retrieved from the meta-buffer, a library of high-level thoughts. This template is instantiated with task-specific reasoning structures (blue), leading to a solution. The figure emphasizes the key components of BoT: the problem distiller, thought retrieval, instantiated reasoning, and the meta-buffer itself, showing how they work together to solve complex reasoning problems.

This figure shows the accuracy of Llama-3-8B and Llama-3-70B language models, both with and without the Buffer of Thoughts (BoT) method, on three challenging reasoning tasks: Game of 24, Word list sorting, and Checkmate-in-One. The results demonstrate that BoT significantly improves the accuracy of the smaller Llama-3-8B model, even surpassing the performance of the larger Llama-3-70B model in some cases. This highlights BoT’s ability to improve the efficiency of language models by leveraging shared knowledge across tasks, thus reducing the need for extremely large models.

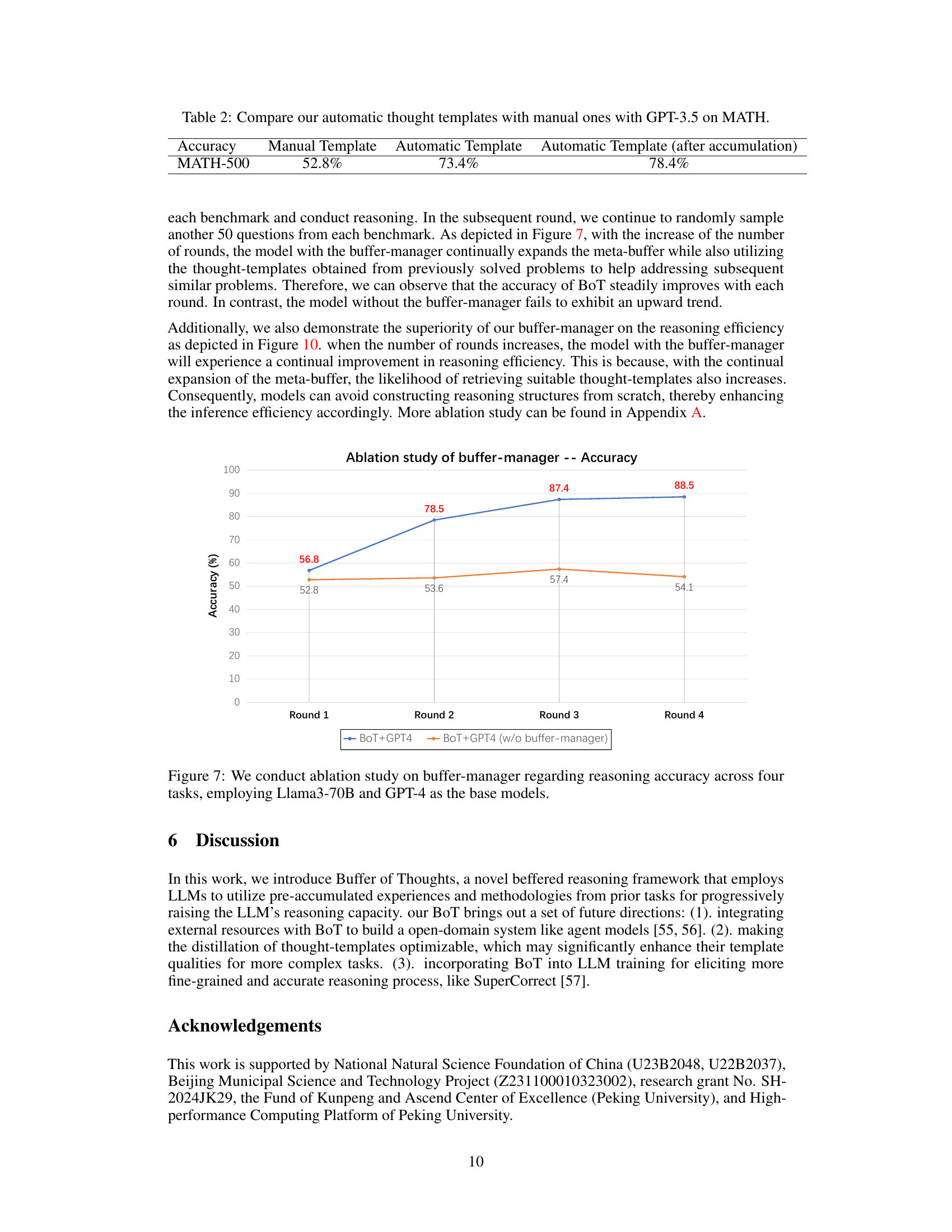
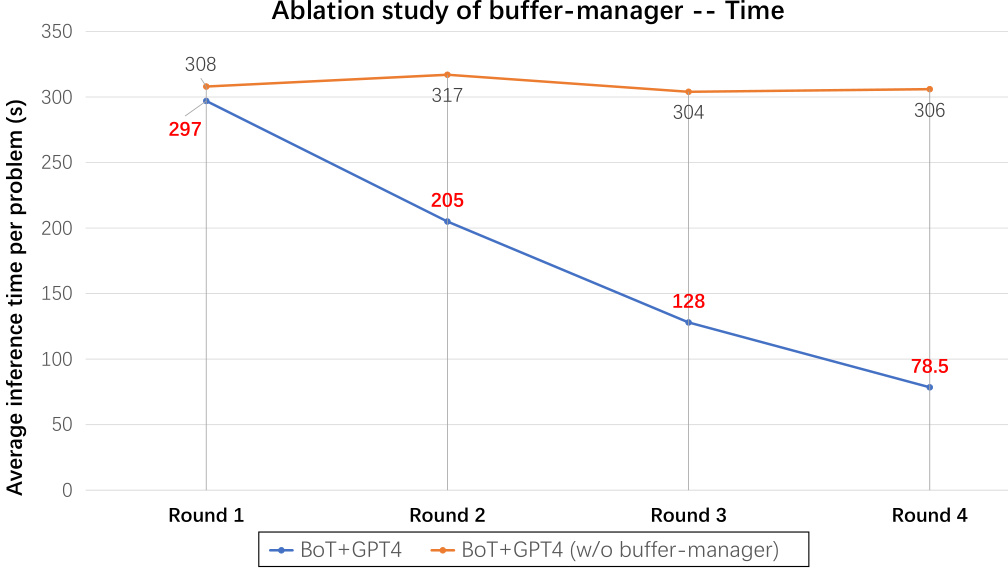
This figure shows the results of an ablation study on the impact of the buffer-manager component of the Buffer of Thoughts (BoT) model. The study compares the accuracy of the BoT model with and without the buffer-manager across four different reasoning tasks, using two large language models (LLMs), Llama3-70B and GPT-4, as base models. The x-axis represents the four rounds of the experiment, and the y-axis represents the accuracy achieved in each round. The lines represent the accuracy of BoT+GPT4 with the buffer-manager and BoT+GPT4 without the buffer-manager. The results demonstrate that the buffer-manager significantly improves the accuracy of the BoT model, especially in later rounds.
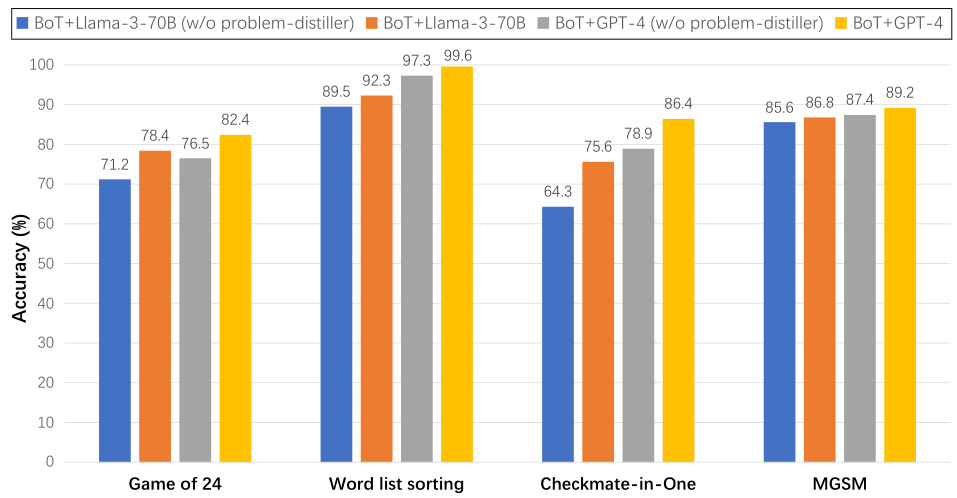
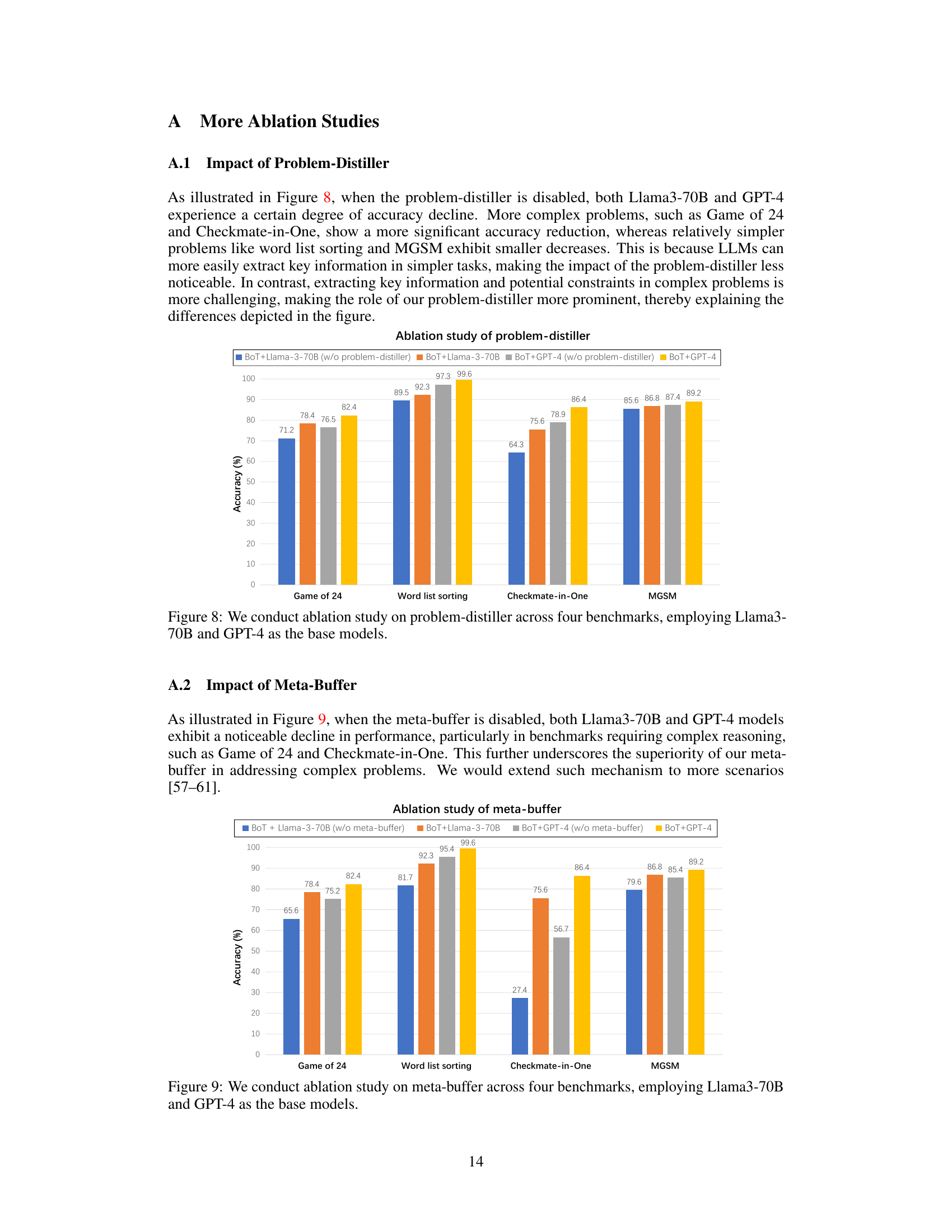
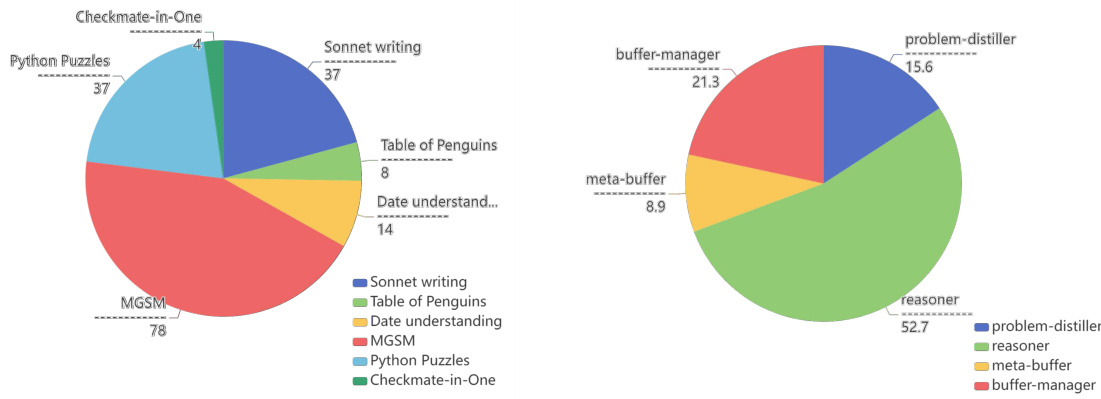
This figure shows the results of an ablation study where the problem-distiller component of the Buffer of Thoughts (BoT) model was removed. The experiment was conducted on four benchmark tasks (Game of 24, Word list sorting, Checkmate-in-One, and MGSM) using two different base language models: Llama3-70B and GPT-4. The bar chart displays the accuracy achieved by the BoT model with and without the problem-distiller for each benchmark and language model. The results demonstrate the impact of the problem-distiller on model performance, particularly for more complex reasoning tasks.
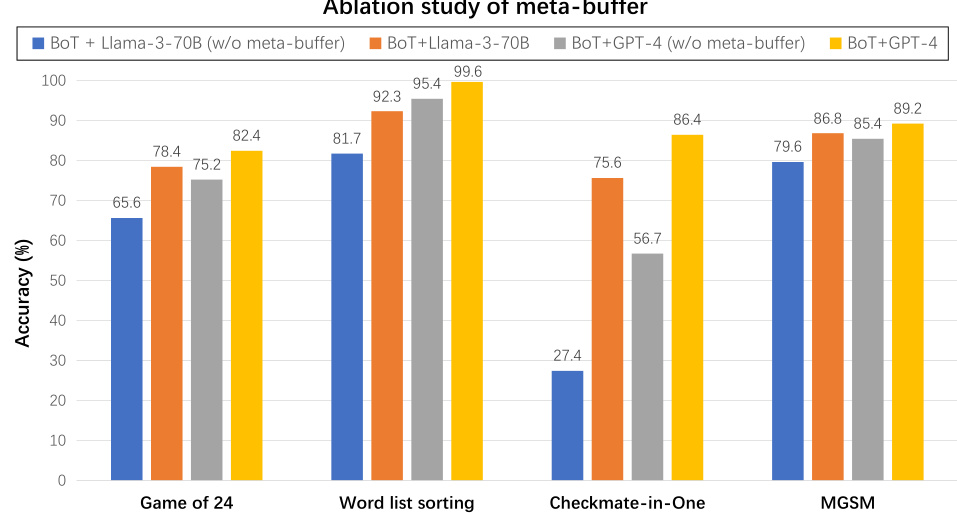
This ablation study investigates the impact of removing the meta-buffer component from the Buffer of Thoughts (BoT) model. The figure displays accuracy results across four different benchmarks (Game of 24, Word list sorting, Checkmate-in-One, MGSM) using two different base LLMs (Llama3-70B and GPT-4). The results demonstrate the significant improvement in accuracy provided by the meta-buffer across all benchmarks and both LLMs. The differences in accuracy between models with and without the meta-buffer highlight its crucial role in the BoT’s overall performance. The larger difference between the models in the Checkmate-in-One benchmark is especially noteworthy, indicating the meta-buffer’s increased importance for more complex reasoning tasks.
This figure compares the inference time of the Buffer of Thoughts method with several other baseline methods across various benchmarks. It shows that Buffer of Thoughts achieves a comparable inference time to single-query methods while significantly outperforming multi-query methods. The logarithmic scale is used to better visualize the differences in time across the different methods. The benchmarks listed allow for a cross-comparison of the model performance.

This figure illustrates the thought-augmented reasoning process of Buffer of Thoughts. It compares three different reasoning methods: Chain-of-Thought, Plan-and-Solve, and Buffer of Thoughts. The figure shows how Buffer of Thoughts uses a meta-buffer to store high-level thoughts and retrieves a relevant thought-template for each problem. The thought-template is then instantiated with specific reasoning structures to conduct efficient reasoning. The figure highlights that Buffer of Thoughts enables large language models to tackle complex reasoning tasks more effectively by leveraging informative historical reasoning structures and eliminating the need to build reasoning structures from scratch.

This figure compares three different reasoning methods used with large language models (LLMs): single-query, multi-query, and the authors’ proposed Buffer of Thoughts (BoT) method. Single-query methods rely on a single prompt to obtain an answer, while multi-query methods iteratively refine the answer through multiple prompts. The BoT method uses a meta-buffer to store high-level thoughts derived from previous problem-solving, allowing for more efficient and accurate reasoning on new problems.
Full paper#