↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current large language models (LLMs) struggle with knowledge graph (KG) reasoning due to their susceptibility to generating factually incorrect outputs, and existing methods for integrating LLMs with KGs are often inefficient and limited in scope. This paper tackles these limitations by introducing a novel three-word language called KGL for knowledge graph representation. The key challenge is adapting LLMs to understand and work with KGL, which lacks familiarity to LLMs’ existing vocabulary.
The paper introduces MKGL, a method which addresses these issues. MKGL leverages a tailored dictionary to bridge the gap between LLM vocabulary and KGL. Real-time KG context retrieval and KGL token embedding augmentation improve context understanding. Experiments demonstrate that LLMs can master KGL with significantly reduced error rates compared to traditional KG embedding methods. MKGL showcases exceptional competence in generating accurate three-word sentences and in interpreting new, unseen terms within KGs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel approach to integrate LLMs with KGs, a critical need in current AI research. MKGL’s efficiency and ability to handle unseen KG entities are significant advancements, opening new avenues for KG completion and other downstream tasks. Its unique KGL language and LoRA-based context/score retrievers offer a highly efficient solution compared to existing methods. This work is of significant importance to researchers working on knowledge graph reasoning, natural language processing, and large language model adaptation.
Visual Insights#

This figure illustrates the workflow of the proposed MKGL method. It starts from the bottom and goes upward. The input is an instruction to the LLM that includes a dictionary defining entity and relation tokens in the KGL language. The goal is to generate new KG sentences starting with an entity and relation. The process involves tokenization, embedding aggregation (using a retriever for textual and relational information, including LoRA-based scaling), and score retrieval to produce a probability distribution of candidate entities for completing the three-word sentence.

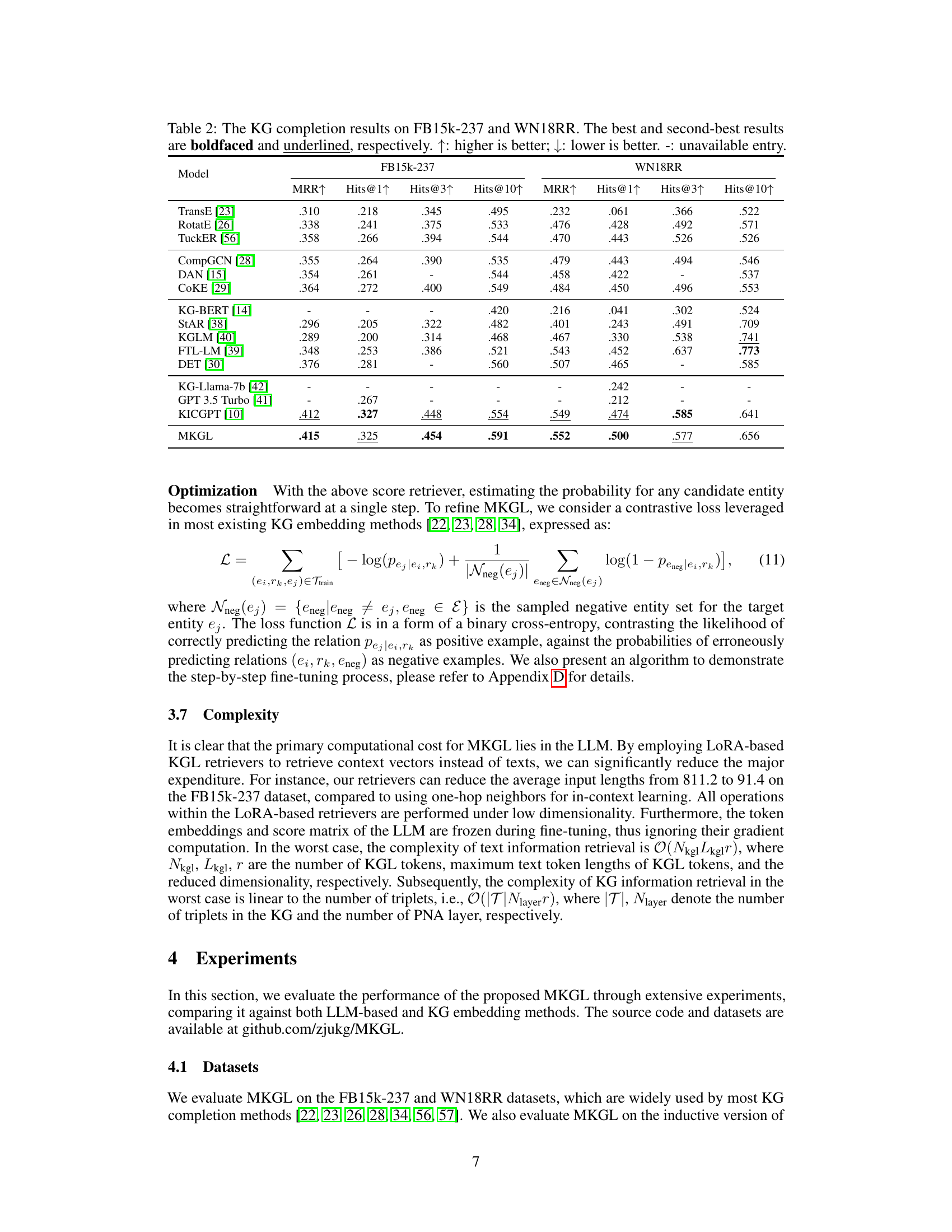
This table presents the performance comparison of MKGL against various baseline methods on two benchmark knowledge graph completion datasets: FB15k-237 and WN18RR. The metrics used are Mean Reciprocal Rank (MRR), and Hits@k (percentage of correctly ranked entities in top k). Higher MRR and Hits@k values indicate better performance. The table highlights the best and second-best performing methods for each metric on each dataset.
In-depth insights#
Three-Word Language#
The concept of a ‘Three-Word Language’ within the context of a research paper focusing on knowledge graphs and large language models (LLMs) is a fascinating and potentially impactful innovation. It suggests a radical simplification of the interaction between LLMs and structured knowledge, reducing complex natural language sentences to their essential components: entity-relation-entity. This approach directly addresses the challenges of hallucination in LLMs by grounding them in verifiable facts from a knowledge graph. The constrained vocabulary of this simplified language, while seemingly limiting, might actually facilitate LLM training and performance by focusing learning on core relational structures. A crucial aspect will be how effectively the LLM can generalize from this constrained format to handle more complex language tasks, and how this approach scales to larger and more diverse knowledge graphs. Furthermore, efficient encoding of the three-word sentences is vital to scalability, requiring careful consideration of the embedding techniques used. The success of this ‘Three-Word Language’ approach rests on demonstrating significant improvements over existing methods in KG completion and related tasks, while maintaining practical applicability.
LLM-KG Integration#
LLM-KG integration represents a powerful paradigm shift in artificial intelligence, aiming to leverage the strengths of both Large Language Models (LLMs) and Knowledge Graphs (KGs). LLMs excel at natural language processing, while KGs offer structured, factual knowledge. Effective integration necessitates overcoming challenges like bridging the semantic gap between the symbolic nature of KGs and the probabilistic nature of LLMs. This involves sophisticated methods for knowledge representation and retrieval, often employing techniques such as embedding models or prompt engineering. A critical aspect is managing the inherent limitations of LLMs, such as hallucination and factual inconsistency, by using KGs as a source of ground truth and for validation. Successful integration promises improved accuracy, explainability, and broader applications in tasks such as question answering, knowledge base completion, and generating factual narratives. However, careful consideration must be given to computational cost and scalability issues, particularly as both LLMs and KGs continue to grow in size and complexity. Furthermore, research should address ethical concerns related to potential biases in KGs and the responsible use of powerful LLMs integrated with such knowledge bases.
LoRA-based Retrieval#
LoRA-based retrieval, in the context of LLMs and knowledge graphs, offers a compelling approach to efficiently integrate contextual information. By employing low-rank adaptation (LoRA), it drastically reduces computational costs associated with traditional methods. LoRA’s efficiency stems from its ability to adjust the LLM’s weights without requiring full fine-tuning, thus enabling faster training and deployment. This is particularly crucial when dealing with large knowledge graphs where integrating all contextual information directly into the model would be computationally prohibitive. The method leverages pre-trained token embeddings as a foundation and augments them with information retrieved from the knowledge graph. This approach is particularly effective for handling unseen entities in the knowledge graph, a significant challenge for many other methods. The combination of LoRA and efficient knowledge graph retrieval mechanisms is key to the effectiveness of this approach, making it a promising technique for a variety of knowledge graph related tasks.
Inductive KG Comp.#
Inductive knowledge graph completion (KG completion) tackles a crucial challenge in knowledge representation: predicting relationships between entities where some or all of the entities are previously unseen. This differs from transductive KG completion, which operates on known entities within a graph. The inductive setting requires a model to generalize beyond its training data, demonstrating true understanding of relational patterns rather than simple memorization. This task is significantly harder because the model lacks the prior context of seen entities, necessitating a stronger capacity for generalization. Successful inductive KG completion methods typically involve learning rich entity and relation representations that capture semantic meaning and relational structures effectively. Approaches often combine embedding methods with techniques that leverage textual descriptions or incorporate external knowledge. The performance is evaluated on metrics such as Mean Reciprocal Rank (MRR) and Hits@k, reflecting the ability to rank correct predictions among numerous possibilities. The ability to accurately complete knowledge graphs inductively is a significant step towards creating more robust and adaptable AI systems, capable of handling real-world scenarios with constantly evolving information.
Future Directions#
The ‘Future Directions’ section of this research paper would ideally expand on several key areas. Firstly, refining the KGL (Knowledge Graph Language) itself is crucial. Exploring alternative three-word sentence structures, or even incorporating more complex phrases, could significantly enhance the model’s expressiveness and ability to handle nuanced knowledge. Secondly, the ethical implications deserve thorough investigation. The potential for misuse, particularly in generating misleading information, necessitates a careful discussion of safeguards and responsible deployment strategies. This includes exploring techniques to mitigate biases and ensure factual accuracy. Thirdly, the integration of MKGL with other LLMs and KG embedding methods warrants further exploration. Investigating the interplay between different LLMs and comparing MKGL’s performance against other state-of-the-art KG completion techniques would provide valuable insights. Finally, the research could delve deeper into the scalability and efficiency of MKGL. Addressing limitations related to computational resources and exploring techniques for efficient model training and deployment on larger datasets is important for broader adoption and real-world applicability.
More visual insights#
More on figures
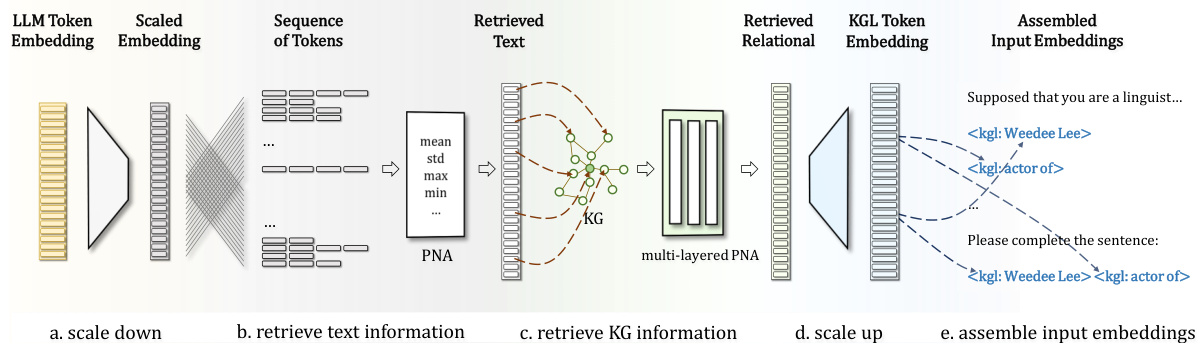
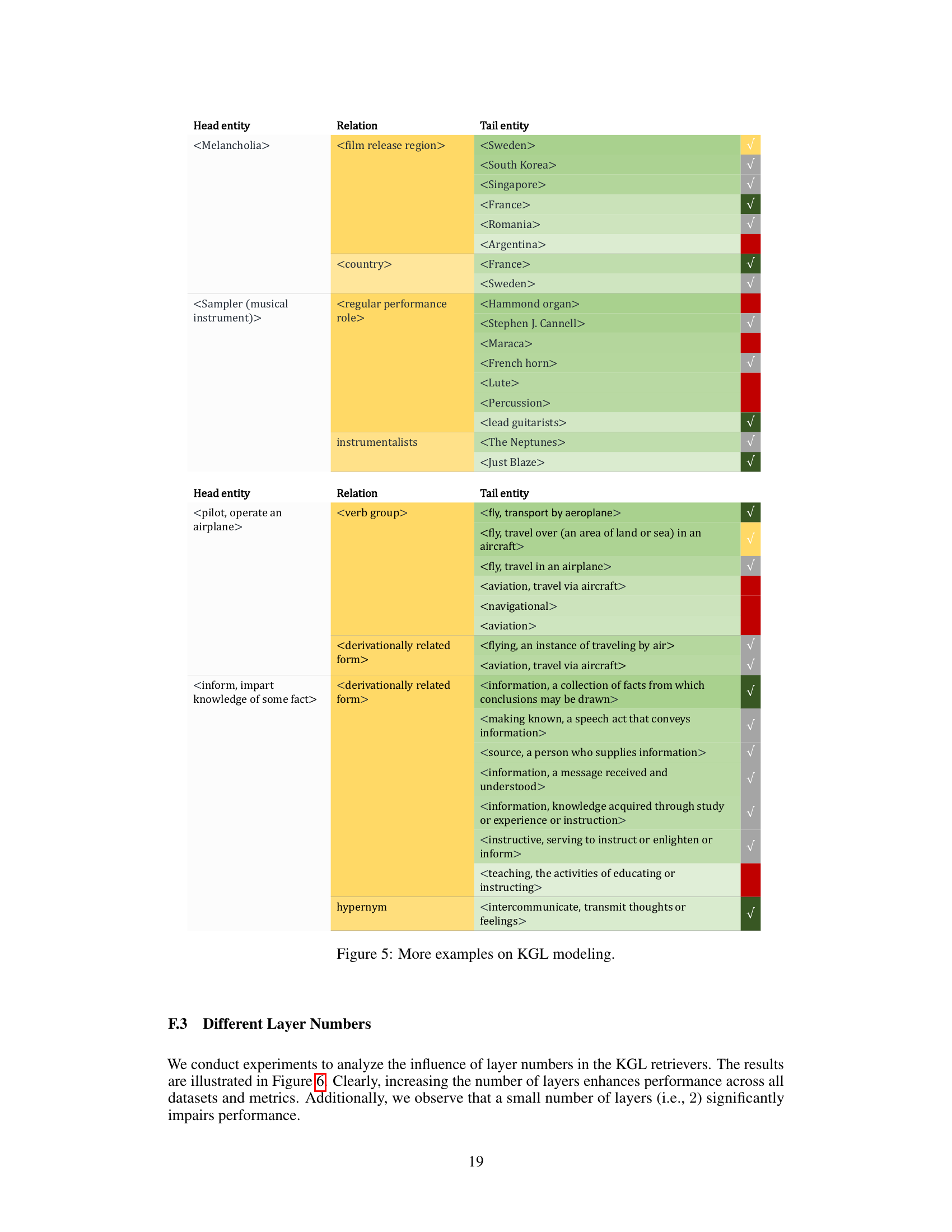
This figure illustrates the LoRA-based KGL Context Retriever, a crucial component of the MKGL model. It shows a step-by-step process of how textual and relational information from a Knowledge Graph (KG) is incorporated into the KGL token embeddings. First, the dimensionality of the LLM token embeddings is reduced using a down-scaling operation. Then, for each KGL token, its constituent textual embeddings are aggregated using a PNA (Principal Neighbourhood Aggregation) encoder. Next, a multi-layered PNA encoder aggregates the KG’s relational information and the previously generated embedding to improve the embedding’s contextual understanding. Finally, the resulting embedding is assigned to the KGL token. This process efficiently leverages information from the KG to enhance the LLM’s understanding of KGL tokens.

This figure illustrates the workflow of the proposed MKGL model. It shows how the model takes an initial entity and relation as input, uses a tokenizer and retriever to generate KGL token embeddings, and then uses a score retriever to produce a probability distribution over candidate entities to complete the three-word sentence. The process includes steps for collecting text tokens, retrieving context vectors, assigning KGL token embeddings, and retrieving score estimations.
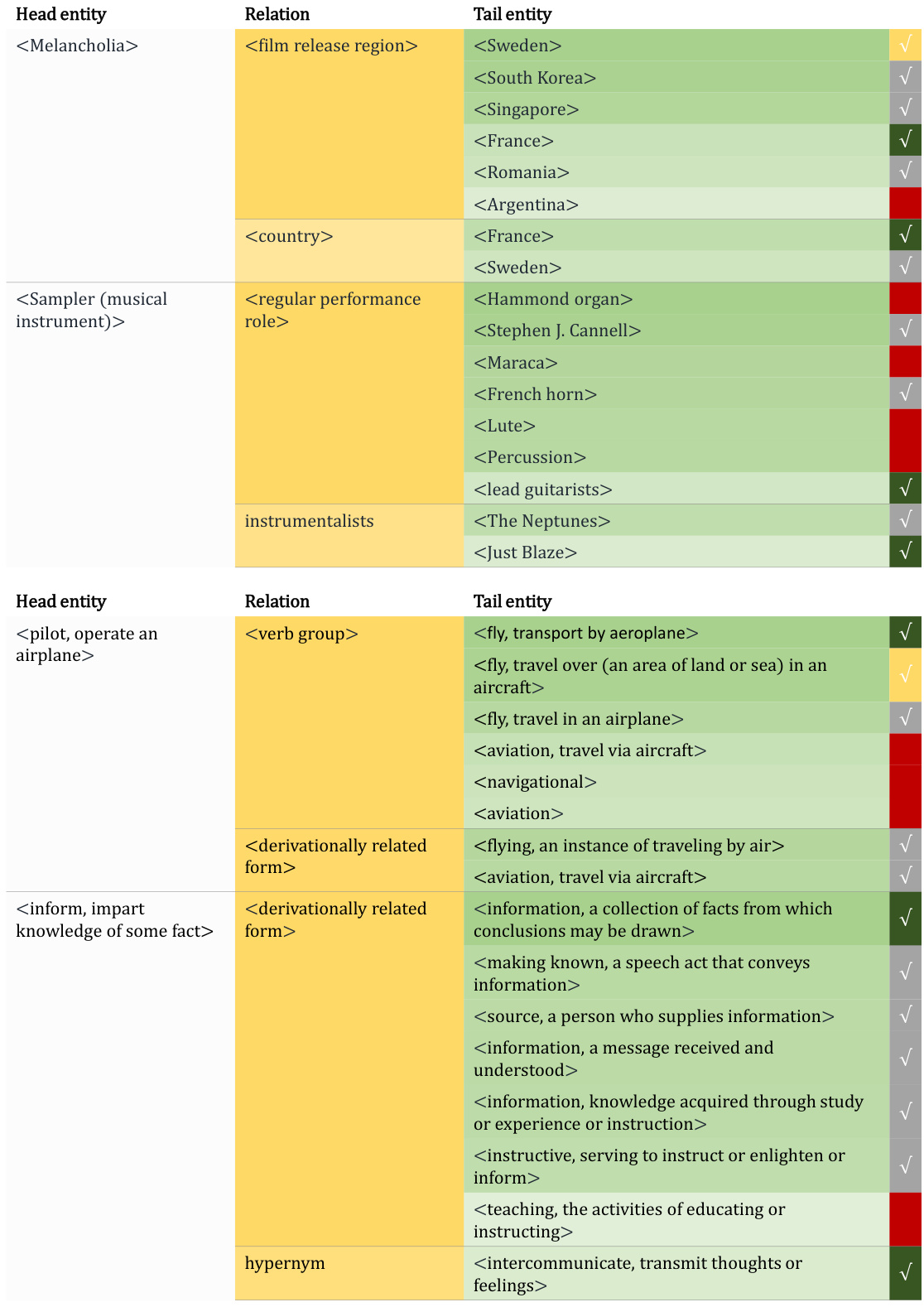
This figure illustrates the LoRA-based KGL Context Retriever, which aggregates textual and KG information into KGL token embeddings. It involves four steps: (a) scaling down token embeddings, (b) aggregating textual embeddings using a PNA encoder, (c) further aggregation of output embeddings using multi-layered PNA encoders for retrieving KG information, and (e) assigning final embeddings to KGL tokens.

This figure shows the performance of the proposed MKGL model on two benchmark datasets, FB15k-237 and WN18RR, when varying the number of layers in the KGL retrievers. The x-axis represents the number of layers, while the y-axis shows the performance metrics: MRR, Hits@1, and Hits@10. The results indicate how the model’s performance changes with different depths of the retrieval modules. The plot helps in understanding the optimal number of layers for balancing performance and computational cost.

This figure compares the performance of the MKGL model using three different encoders (GAT, Mean, and PNA) in its retrievers on two benchmark knowledge graph completion datasets: FB15k-237 and WN18RR. The results are shown for three evaluation metrics: MRR (Mean Reciprocal Rank), Hits@1 (percentage of correctly ranked top-1 entities), and Hits@10 (percentage of correctly ranked top-10 entities). The figure illustrates the relative effectiveness of each encoder in aggregating textual and relational information for the KGL token embeddings within the MKGL framework.
More on tables
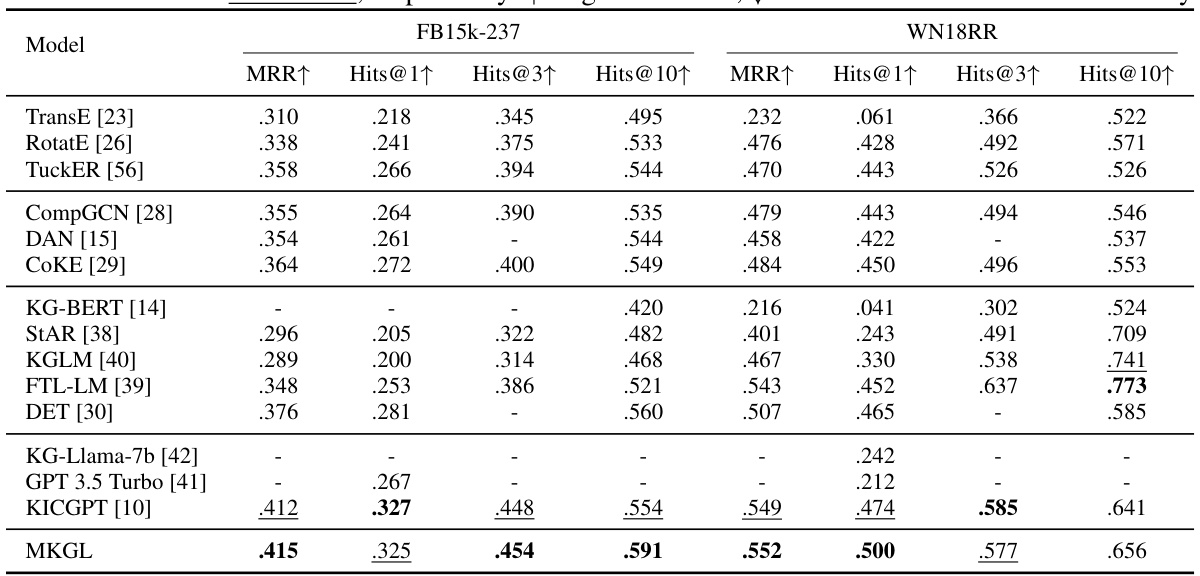
This table presents the results of knowledge graph completion experiments on two benchmark datasets, FB15k-237 and WN18RR. It compares the performance of MKGL against various other methods, including TransE, RotatE, TuckER, CompGCN, DAN, COKE, KG-BERT, StAR, KGLM, FTL-LM, DET, KG-Llama-7b, GPT 3.5 Turbo, and KICGPT. The metrics used for comparison are Mean Reciprocal Rank (MRR), Hits@1, Hits@3, and Hits@10. Higher values for MRR and Hits@k indicate better performance. The best and second-best results for each metric are highlighted.
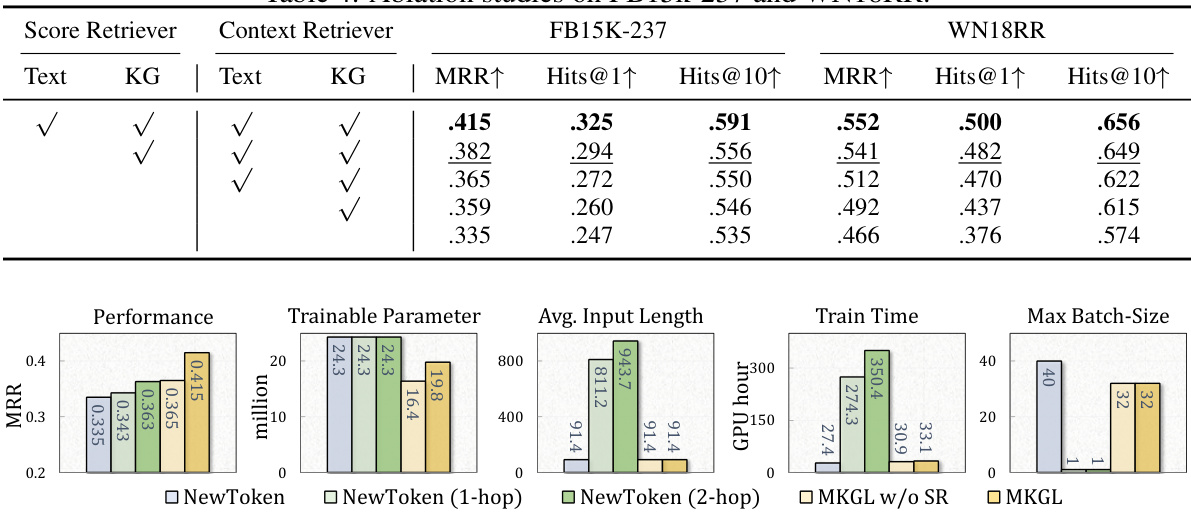
This table presents the results of Knowledge Graph Completion (KGC) experiments on two benchmark datasets, FB15k-237 and WN18RR. It compares the performance of MKGL against various other state-of-the-art KGC methods. The metrics used are Mean Reciprocal Rank (MRR) and Hits@k (percentage of correctly ranked entities within the top k). Higher values for MRR and Hits@k indicate better performance.

This table presents the performance of MKGL and various baseline methods on two benchmark knowledge graph completion datasets, FB15k-237 and WN18RR. The results are compared using standard metrics: MRR (Mean Reciprocal Rank) and Hits@k (percentage of correctly predicted entities within the top k ranks). Higher values for MRR and Hits@k indicate better performance. The table highlights the best and second-best performing methods for each metric.
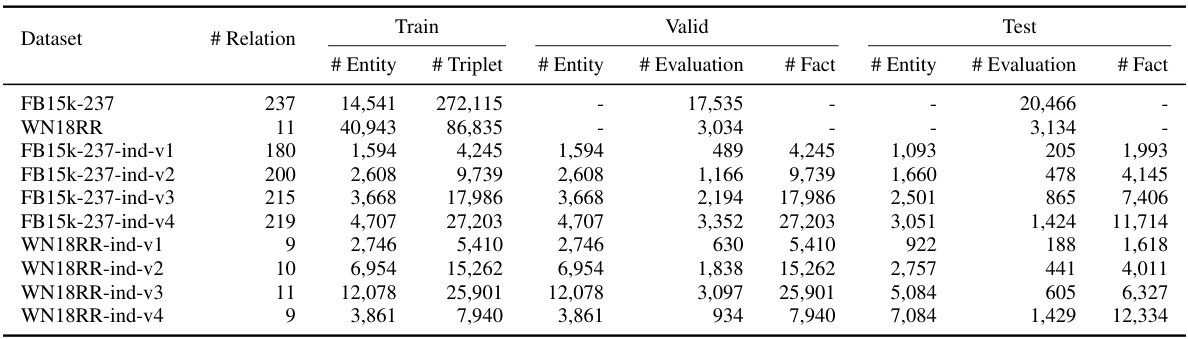
This table presents the results of Knowledge Graph Completion experiments on two benchmark datasets: FB15k-237 and WN18RR. It compares the performance of MKGL against several other state-of-the-art KG completion methods, using metrics like MRR (Mean Reciprocal Rank) and Hits@k (percentage of correctly ranked entities within the top k results). The best and second-best results for each method are highlighted.
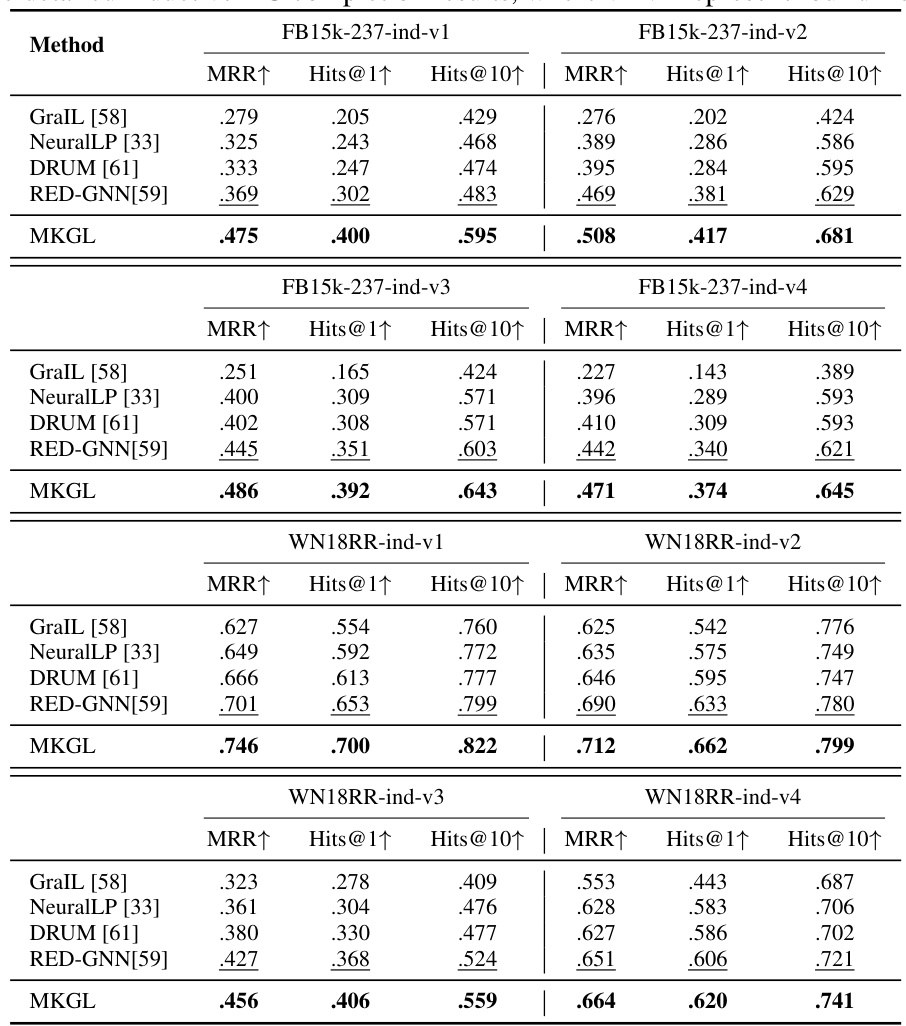
This table presents the results of knowledge graph completion experiments on two benchmark datasets, FB15k-237 and WN18RR. It compares the performance of the proposed MKGL method against various other state-of-the-art KG completion methods. The metrics used are Mean Reciprocal Rank (MRR), Hits@1, Hits@3, and Hits@10. Higher values indicate better performance. The table highlights the best and second-best performing models for each metric on each dataset.
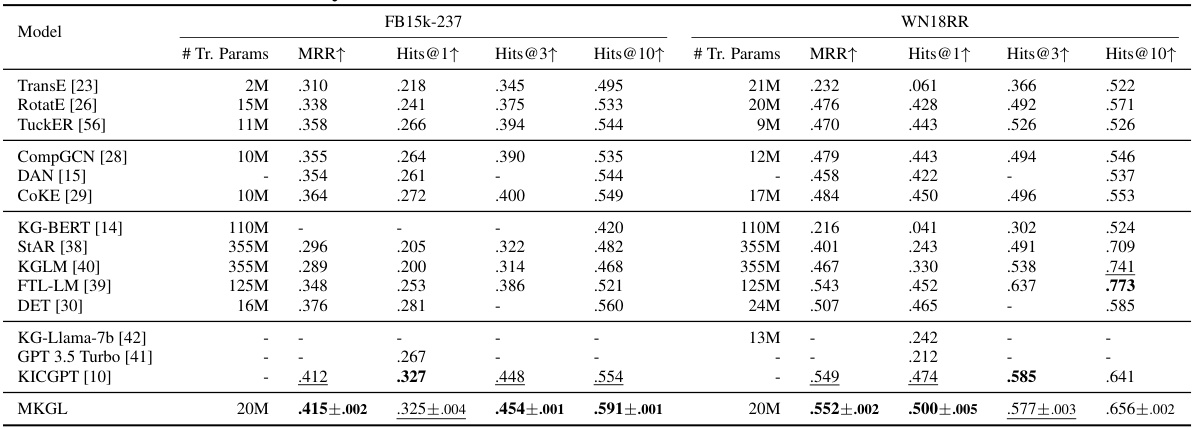
This table presents the results of knowledge graph completion experiments on two benchmark datasets, FB15k-237 and WN18RR. It compares the performance of the proposed MKGL method against various other state-of-the-art baselines, including TransE, RotatE, TuckER, CompGCN, DAN, CoKE, KG-BERT, StAR, KGLM, FTL-LM, DET, KG-Llama, GPT 3.5 Turbo, and KICGPT. The metrics used for comparison are Mean Reciprocal Rank (MRR), and Hits@1, Hits@3, and Hits@10 (the percentage of correctly predicted entities ranked within the top 1, 3, and 10 positions respectively). The table indicates the best and second-best performing methods in bold and underlines, respectively. Missing values are represented by a hyphen.
Full paper#