↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly capable of handling longer contexts, but the quadratic complexity of attention mechanisms creates a significant computational bottleneck, especially during the initial prompt processing stage (pre-filling). This slow pre-filling severely impacts the user experience and limits the practicality of deploying LLMs for long-context tasks. Existing methods for improving pre-filling speed often compromise accuracy or are not easily adaptable to various LLMs.
To address these challenges, the authors introduce MInference, a novel method that utilizes dynamic sparse attention. MInference identifies three common patterns in attention matrices and uses them to build sparse attention indexes dynamically during inference. Using optimized GPU kernels, MInference significantly reduces the pre-filling time of several LLMs, achieving up to a 10x speedup on a single A100 GPU without any accuracy loss. The method is designed to be readily adaptable to existing models, thus improving the efficiency of long-context LLM applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and long-context processing. It directly addresses the significant computational bottleneck of the pre-filling stage in LLMs, offering a practical and effective solution. The proposed method, MInference, is readily applicable to existing LLMs without needing retraining or fine-tuning, opening exciting avenues for enhancing the efficiency and scalability of long-context LLM applications. Its focus on dynamic sparse attention patterns also provides valuable insights for future research on optimized attention mechanisms.
Visual Insights#

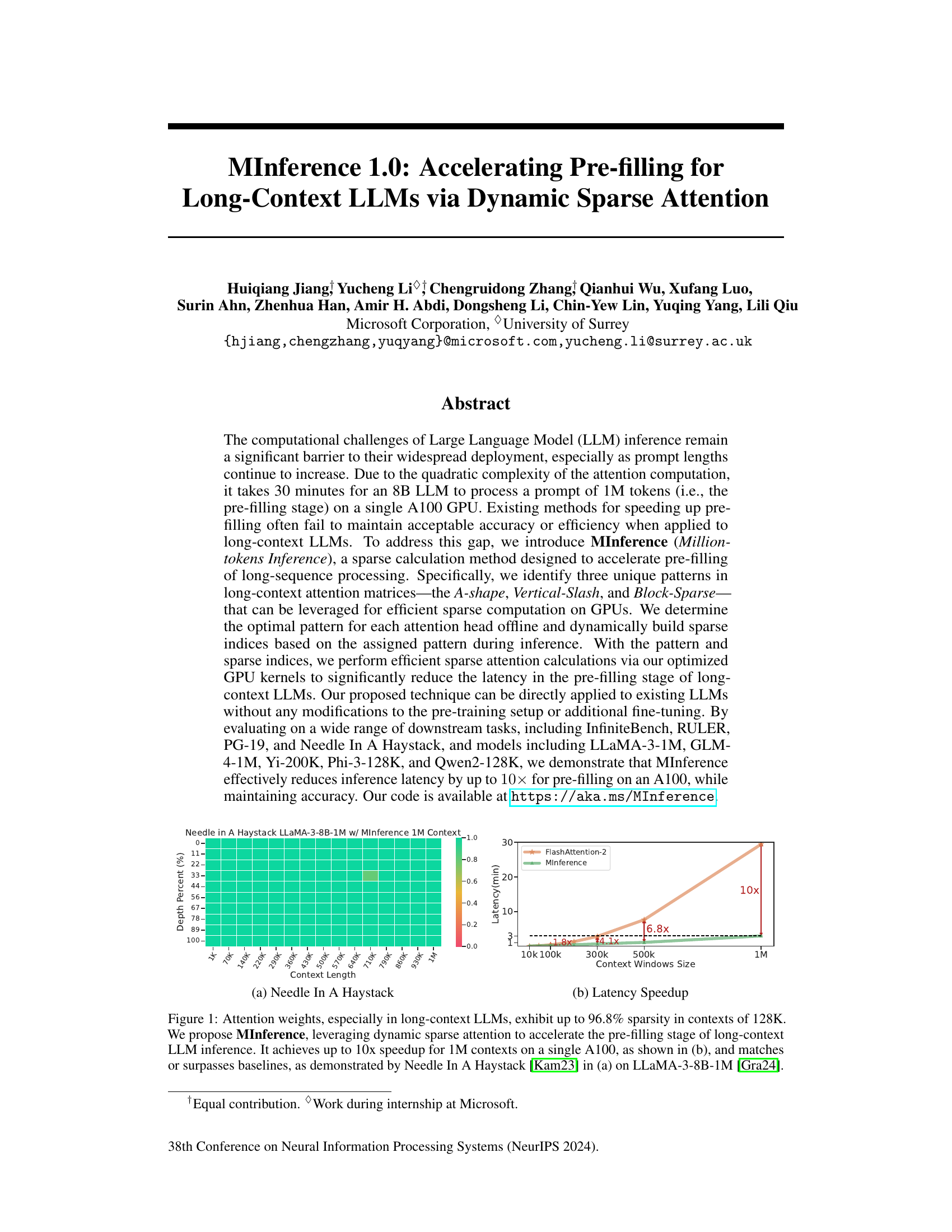
This figure shows two plots. Plot (a) is a bar chart comparing the latency of MInference and FlashAttention-2 on the Needle in a Haystack benchmark using the LLaMA-3-8B-1M model. It demonstrates that MInference achieves comparable accuracy with significantly lower latency. Plot (b) shows a line chart illustrating the speedup achieved by MInference across various context window sizes, highlighting a 10x speedup for 1M context.

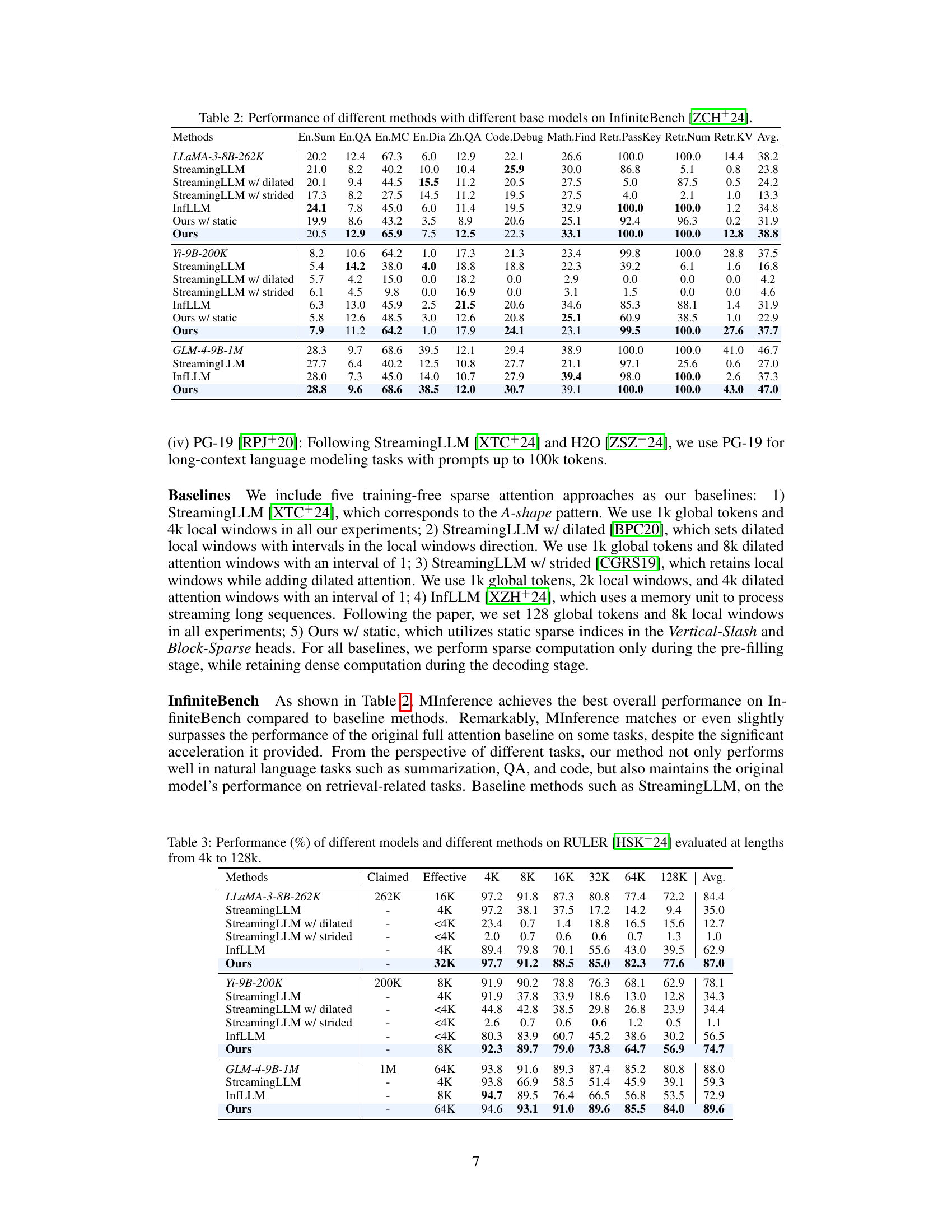
This table compares four different sparse attention patterns: A-shape, Vertical-Slash, Block-Sparse, and Top-K. It contrasts them based on their spatial distribution (how the sparse elements are arranged in the attention matrix), latency on GPU (how long it takes to compute attention using these patterns), and the time required to build the index for sparse computation. The table highlights that A-shape has low latency and zero index build time, while Vertical-Slash has medium latency and small index build time. Block-Sparse is similar to Vertical-Slash, and Top-K exhibits high latency and index build time. This illustrates the trade-offs involved when choosing a sparse attention pattern for long-context LLMs.
In-depth insights#
Dynamic Sparse Attention#
Dynamic sparse attention is a crucial technique for optimizing large language model (LLM) inference, particularly when dealing with long sequences. The core idea is to selectively compute only the most relevant parts of the attention mechanism, thereby reducing computational costs and improving efficiency. Unlike static sparse attention methods, which use fixed sparsity patterns, dynamic approaches adapt to the input sequence, identifying and focusing on the most important attention weights. This adaptability is critical because the importance of different tokens varies significantly based on the context. The approach, therefore, involves identifying unique patterns within the attention matrices (like A-shape, Vertical Slash, Block-Sparse) and then dynamically building sparse indices during inference to enable efficient computation of only the necessary attention weights. This strategy is particularly beneficial for long-context LLMs where quadratic complexity of attention becomes a significant bottleneck. By carefully crafting the sparsity patterns and corresponding optimized GPU kernels, dynamic sparse attention can achieve significant speedups while maintaining accuracy. This represents a notable advancement over previous methods as it directly addresses the limitations of static approaches in handling the dynamic nature of attention weight distributions in long sequences.
MInference Algorithm#
The core of the research paper revolves around the proposed MInference algorithm, a novel approach to accelerate the pre-filling stage of long-context LLMs. MInference leverages the inherent sparsity of attention matrices in LLMs, identifying three distinct patterns (A-shape, Vertical-Slash, and Block-Sparse) to optimize computation. By dynamically identifying the optimal pattern for each attention head and building sparse indices accordingly, MInference significantly reduces computational cost. Key to its efficiency is the use of optimized GPU kernels, tailored to each identified sparse pattern, enabling extremely fast sparse attention calculations. The algorithm’s effectiveness is demonstrated across various downstream tasks and LLMs, achieving up to a 10x speedup while maintaining accuracy. A key advantage of MInference is its plug-and-play nature, requiring no modifications to the pre-trained model or additional fine-tuning, making it a readily applicable solution for enhancing the performance of existing LLMs. Furthermore, the algorithm demonstrates robustness across different model architectures and context lengths.** The research highlights the importance of online, dynamic sparsity prediction in contrast to static sparse methods, offering a significant advancement in accelerating long-context LLM inference.**
Long-Context LLM Speedup#
The research explores accelerating long-context LLMs, focusing on the computationally expensive pre-filling stage. MInference 1.0, the proposed method, leverages the inherent sparsity in long-context attention matrices. By identifying unique patterns (A-shape, Vertical-Slash, Block-Sparse) and dynamically building sparse indices, MInference reduces FLOPs significantly. This results in substantial speedups (up to 10x) on various benchmarks, including InfiniteBench, RULER, and Needle In A Haystack, across different LLMs. The approach is directly applicable to existing models without requiring pre-training or fine-tuning. Maintaining accuracy while achieving such speed improvements is a critical finding, making MInference a strong contender for enhancing long-context LLM inference.
Benchmark Results#
The benchmark results section of a research paper is crucial for validating the claims and demonstrating the effectiveness of a proposed method. A thoughtful analysis should go beyond simply presenting the numbers and delve into the nuances of the experimental setup and the selection of benchmarks. The choice of benchmarks is paramount, as they should represent a diverse range of tasks and difficulties that are relevant to the problem being addressed. A comprehensive analysis would also include a discussion of the limitations of the benchmarks themselves and any potential biases they might introduce. Statistical significance and error bars are also essential for conveying the reliability and robustness of the experimental results. Moreover, a comparative analysis of the proposed method against state-of-the-art techniques is critical to showcase its novelty and potential impact. In summary, a compelling benchmark results section not only validates the method but also provides valuable insights into its strengths, weaknesses, and potential for future applications. Presenting the results clearly and concisely with appropriate visualizations is crucial for effective communication, making it easily accessible to a wide range of readers, including those without extensive technical expertise.
Future Research#
Future research directions stemming from this work on MInference could explore several promising avenues. Extending MInference to support various model architectures beyond the transformer-based LLMs currently tested would broaden its applicability and impact. Investigating the optimal methods for dynamically determining the sparse attention patterns, perhaps through more sophisticated machine learning models or by incorporating contextual information beyond the current approach, could further enhance efficiency. A key area for future work is improving the scalability of MInference to even larger context windows and larger language models, possibly by combining this technique with model parallelism or other advanced optimization strategies. Finally, a rigorous theoretical analysis of the identified sparse attention patterns and their relationship to the underlying mechanisms of LLMs would provide deeper insights and may lead to the development of new, more efficient attention mechanisms. These advancements could significantly improve long-context LLM inference speed and accessibility.
More visual insights#
More on figures
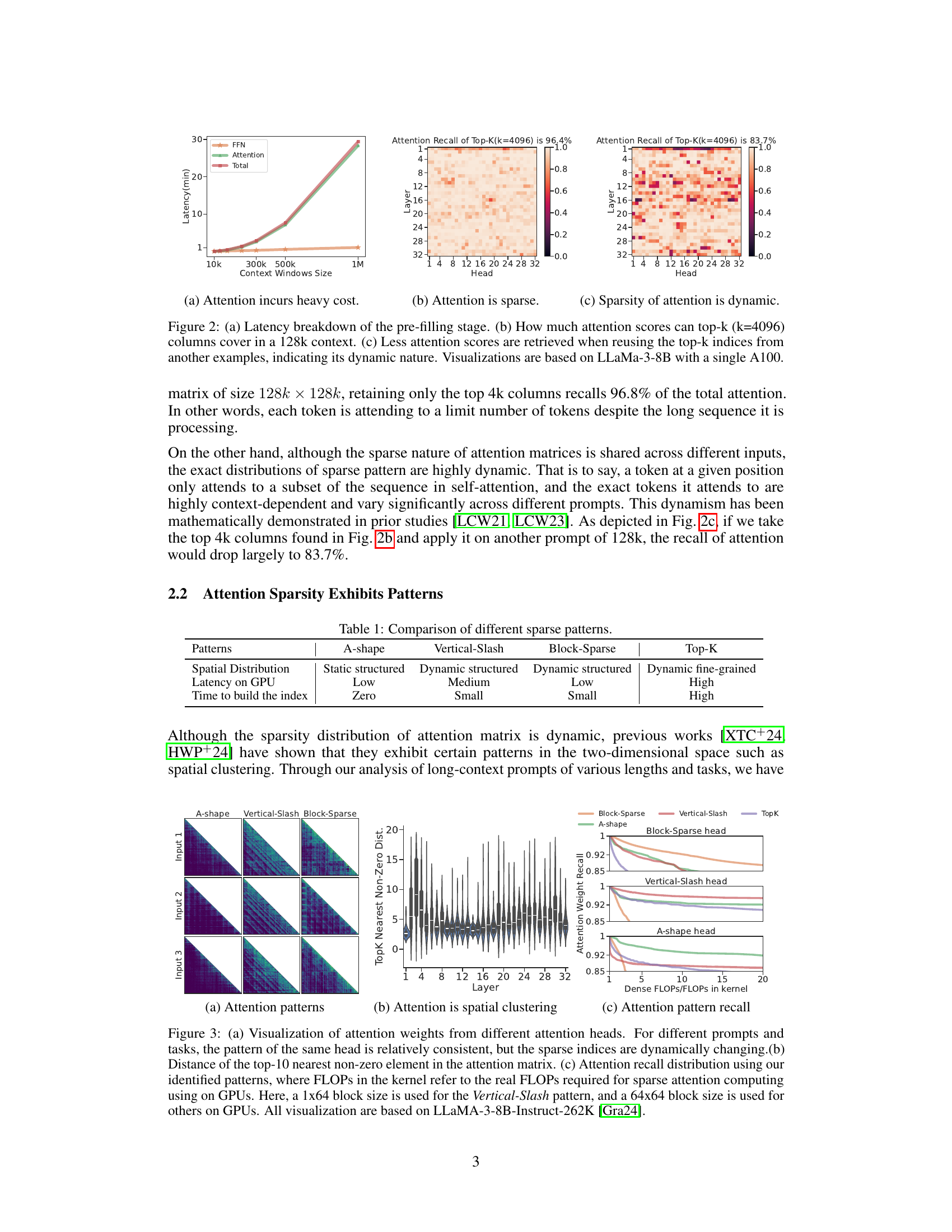
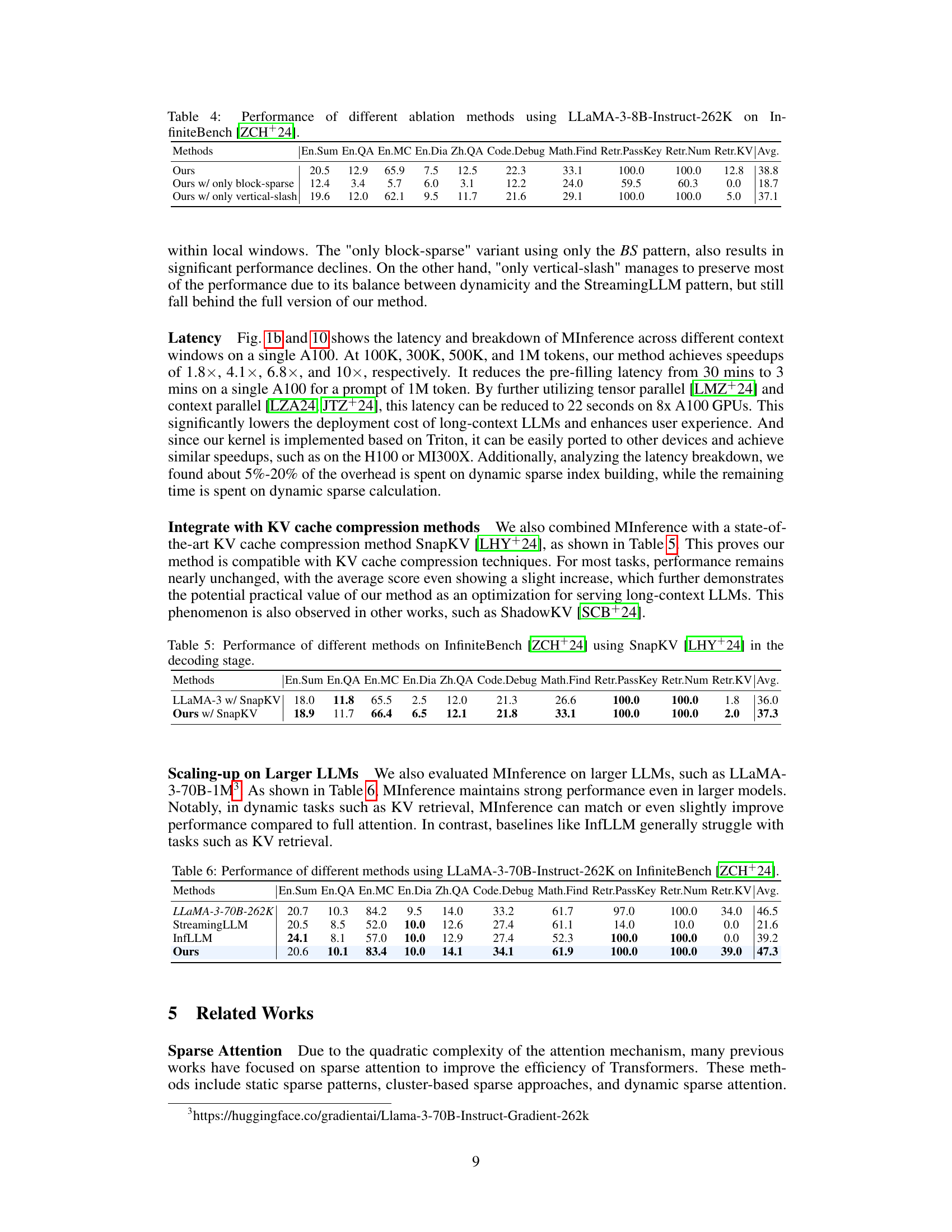
This figure shows the breakdown of latency during the pre-filling stage of a long-context LLM. It highlights the significant cost of attention computation (a). It then demonstrates the sparsity of attention weights, showing that a small subset of attention scores captures most of the information (b). Finally, it illustrates the dynamic nature of attention sparsity, showing that patterns observed in one example do not generalize well to others (c). The visualizations are based on the LLaMA-3-8B model using a single A100 GPU.
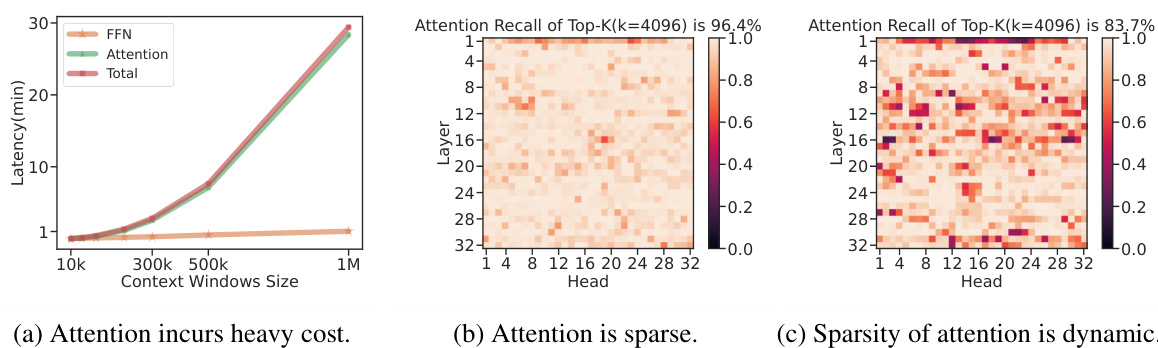
This figure visualizes the three sparse attention patterns identified in the paper: A-shape, Vertical-Slash, and Block-Sparse. Panel (a) shows example attention weight matrices for each pattern, highlighting their distinct structures. Panel (b) illustrates the spatial clustering of non-zero attention weights across different layers, supporting the existence of these patterns. Panel (c) compares the recall (percentage of attention scores captured) of these patterns against the computational cost (dense FLOPs/FLOPs in kernel), demonstrating their efficiency compared to a dense approach.

This figure shows the three sparse methods used in MInference: A-shape, vertical-slash, and block-sparse. Each method shows how a subset of the attention matrix is computed to reduce the computational cost. The A-shape focuses on the top-left corner, the vertical-slash on diagonal and vertical lines, and the block-sparse on selected blocks. The figure highlights the different ways MInference approximates the full attention matrix to achieve efficiency while maintaining accuracy.
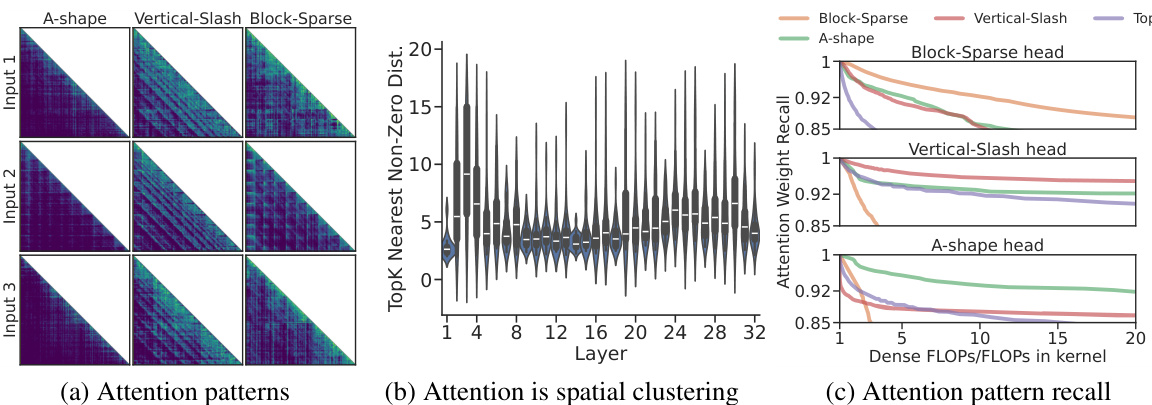
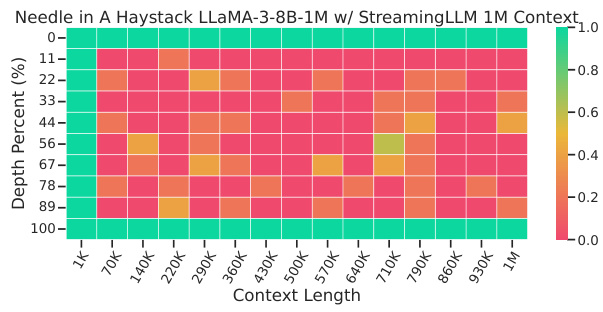
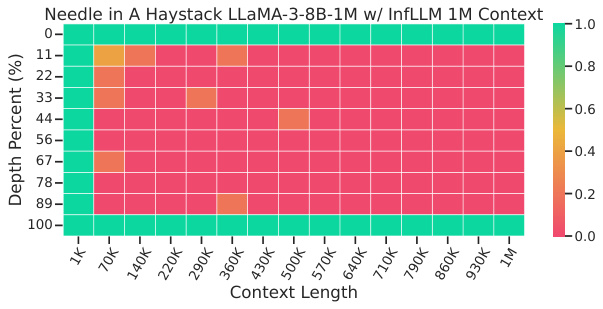
The figure shows the perplexity results on the PG-19 language modeling task for different context window sizes using several models (LLaMA-3-8B-Instruct-262K and Yi-9B-200K). It compares the performance of MInference against several baseline methods including StreamingLLM, StreamingLLM with dilated and strided attention, InfLLM, and FlashAttention-2. The graph demonstrates MInference’s superior performance in maintaining low perplexity even with large context window sizes while significantly outperforming baselines.
This figure shows two graphs. Graph (a) compares the performance of MInference and FlashAttention-2 on the Needle in a Haystack benchmark using the LLaMA-3-8B-1M model with a 1M context. The results demonstrate that MInference matches or surpasses the baseline. Graph (b) illustrates the latency speedup achieved by MInference across various context window sizes, showcasing a significant improvement in efficiency.

This figure shows a visualization of the dynamic sparse mask used in the Vertical-Slash pattern of the MInference method. The yellow regions highlight the non-zero elements (or computed parts) of the attention matrix, while the purple areas represent the zero elements (not computed). It demonstrates how the method identifies and utilizes specific patterns (vertical and slash lines) in the attention matrix to reduce computation during the inference stage. The different block sizes used for vertical and slash lines are also shown.
This figure demonstrates the sparsity of attention weights in long-context LLMs and the performance of MInference. (a) shows the attention weight sparsity in the Needle in A Haystack benchmark using LLaMA-3-8B-1M. It highlights that even with a million tokens, a significant portion of the attention weights are near zero. (b) illustrates the speedup achieved by MInference compared to FlashAttention-2 across varying context window sizes. MInference achieves a substantial speedup, especially with longer contexts. The figure supports the paper’s claim that MInference efficiently accelerates pre-filling for long-context LLMs by leveraging dynamic sparse attention.
This figure shows the sparsity of attention weights in long-context LLMs and the speedup achieved by MInference. (a) demonstrates the performance of MInference on the Needle In A Haystack benchmark compared to FlashAttention-2, showing that MInference matches or surpasses the baseline while maintaining high sparsity. (b) illustrates the latency speedup achieved by MInference for different context window sizes, showing up to a 10x speedup for 1M contexts on a single A100 GPU.

This figure shows two plots. Plot (a) compares the performance of MInference and FlashAttention-2 on the Needle in a Haystack benchmark using the LLaMA-3-8B-1M model with 1M context. It demonstrates that MInference achieves similar performance to FlashAttention-2 while exhibiting significantly reduced latency. Plot (b) illustrates the speedup achieved by MInference in terms of latency reduction. For a context window of 1M tokens, it shows a speedup of approximately 10 times compared to other methods. The figure highlights the effectiveness of MInference in accelerating the pre-filling stage of long-context LLMs by leveraging the sparsity of attention weights.
This figure shows two graphs. Graph (a) presents the performance comparison of MInference and FlashAttention-2 on the Needle In A Haystack benchmark using the LLaMA-3-8B-1M model. It demonstrates that MInference maintains accuracy while achieving similar performance. Graph (b) illustrates the speedup in latency provided by MInference across various context window sizes, showcasing significant improvements.

The figure shows two plots. Plot (a) compares the performance of MInference and FlashAttention-2 on the Needle in A Haystack benchmark using the LLaMA-3-8B-1M model with a 1M context. The plot shows that MInference achieves comparable performance to FlashAttention-2 while significantly reducing latency. Plot (b) illustrates the speedup achieved by MInference compared to a baseline approach. The plot shows that MInference achieves up to a 10x speedup for 1M contexts on a single A100 GPU.
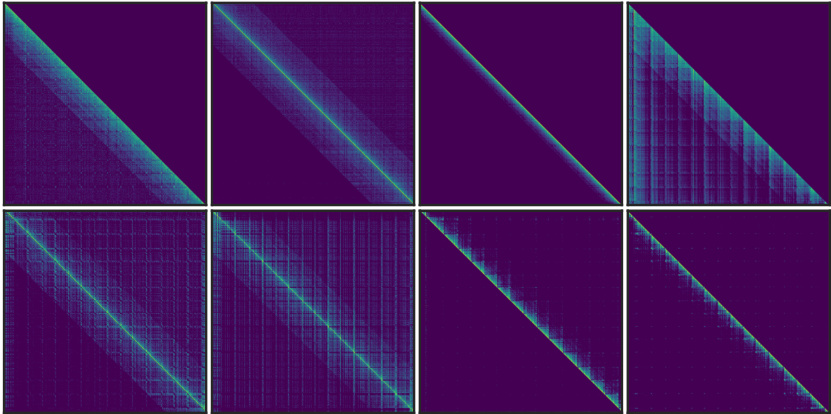
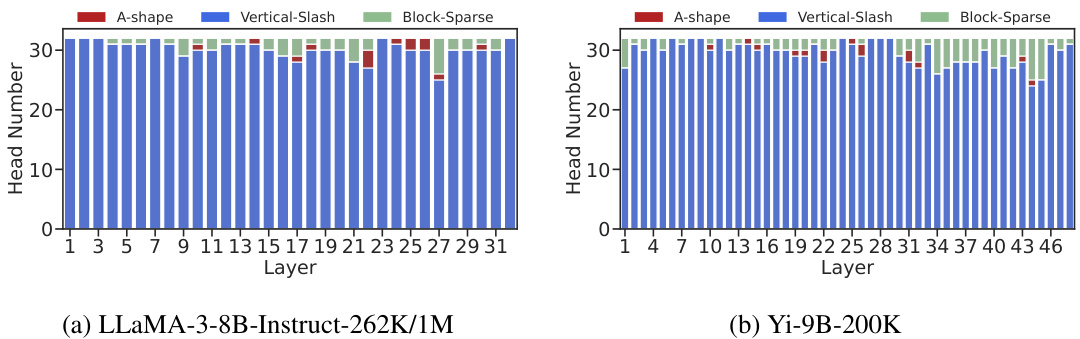
This figure visualizes three key aspects of the attention mechanism in long-context LLMs. (a) shows the distinct patterns (A-shape, Vertical-Slash, Block-Sparse) observed in attention weight matrices for different attention heads. These patterns remain consistent across various prompts and tasks, despite the dynamic nature of the sparse indices. (b) illustrates spatial clustering in the attention matrix by showing the distances between non-zero attention weights and their nearest non-zero neighbors. This demonstrates that attention weights are not randomly distributed but exhibit spatial patterns. Finally, (c) compares the recall and computational efficiency (FLOPs) of different sparse patterns, highlighting the superiority of the proposed method in retrieving important attention scores with minimal computational cost.
More on tables

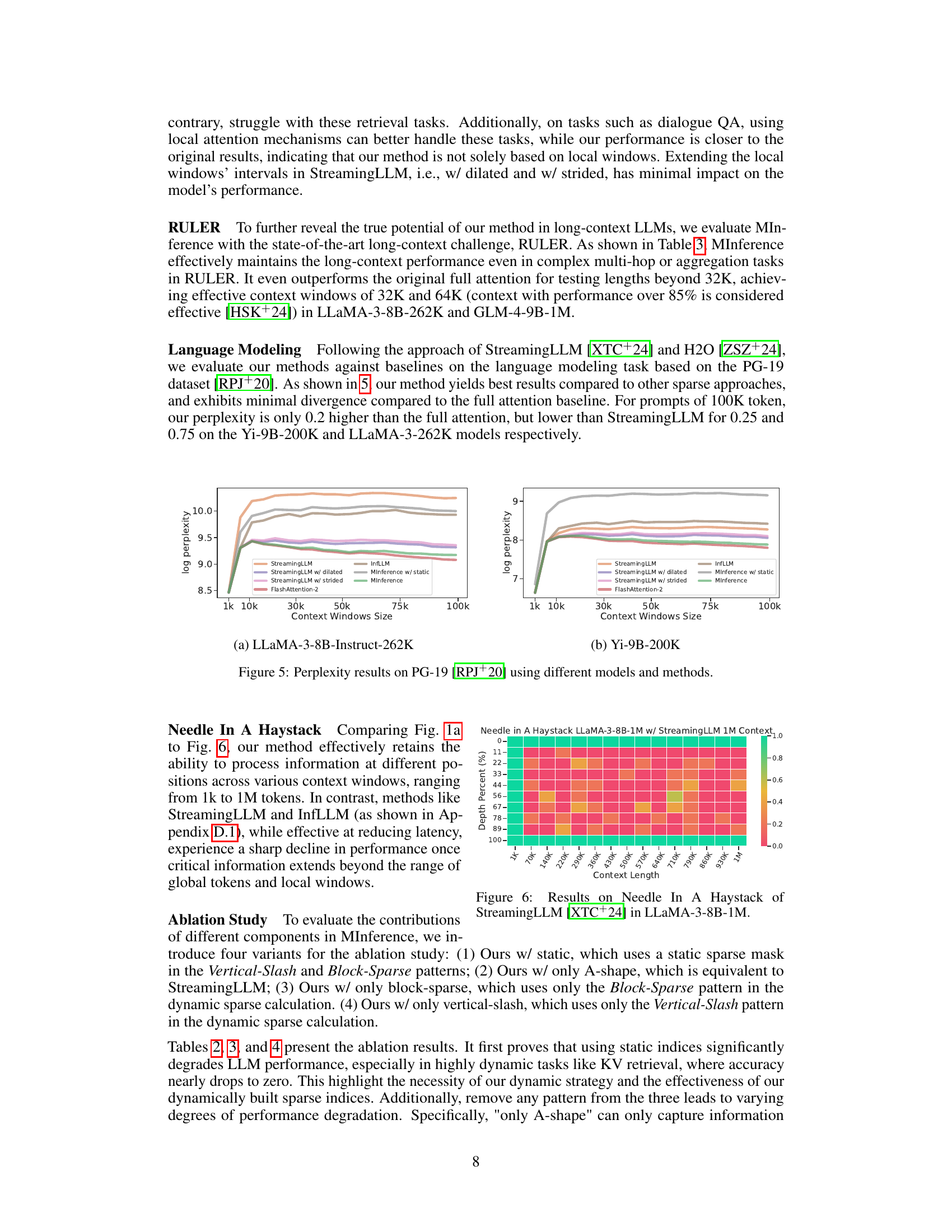
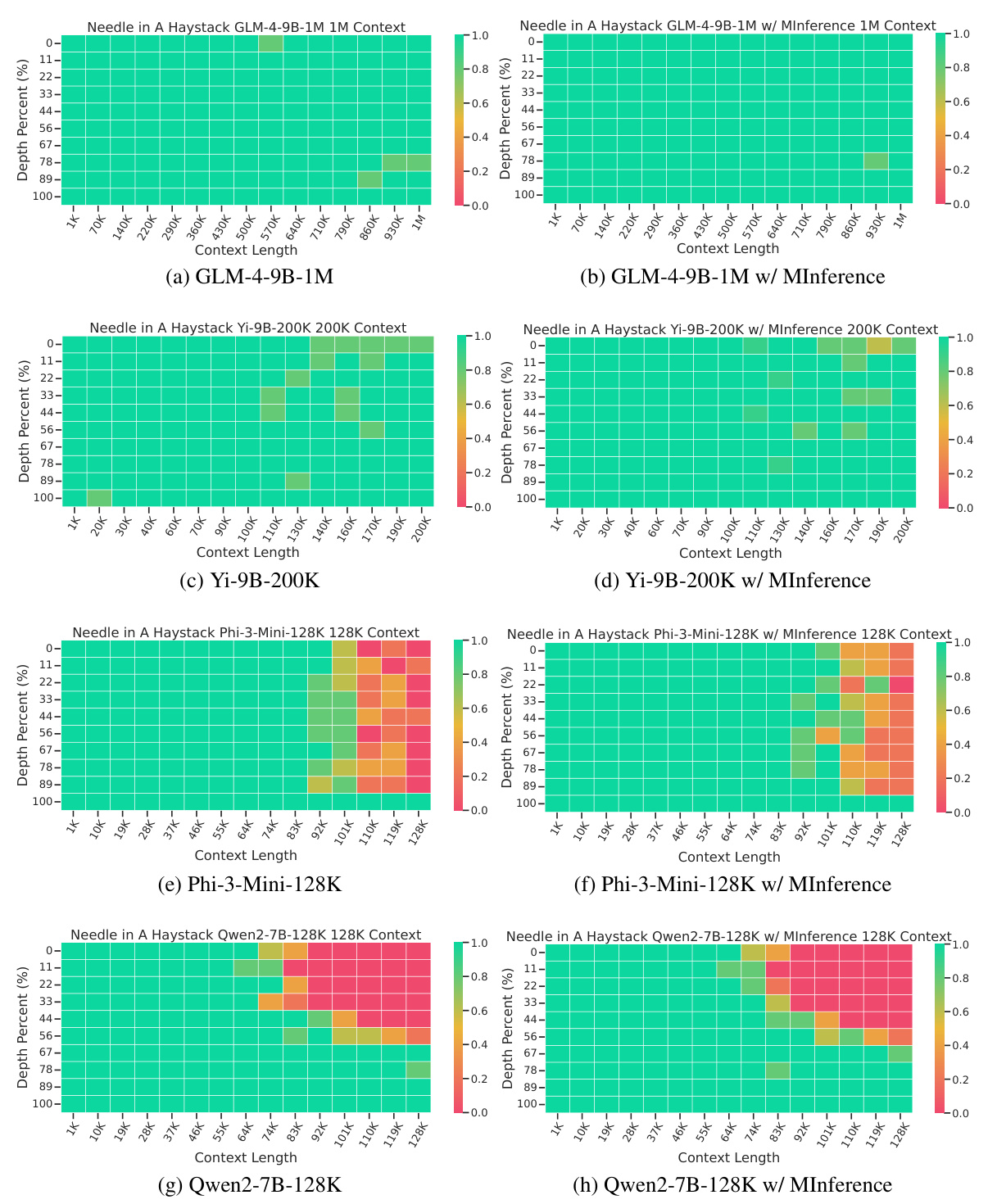
This table presents the performance comparison of various methods, including MInference and its variants, along with several baselines, on the InfiniteBench benchmark. The results are broken down by specific tasks within the benchmark (e.g., English summarization, English question answering, etc.) and show the average performance across all tasks. The table helps demonstrate the effectiveness of MInference in improving performance across a diverse set of long-context tasks while using different base LLMs.
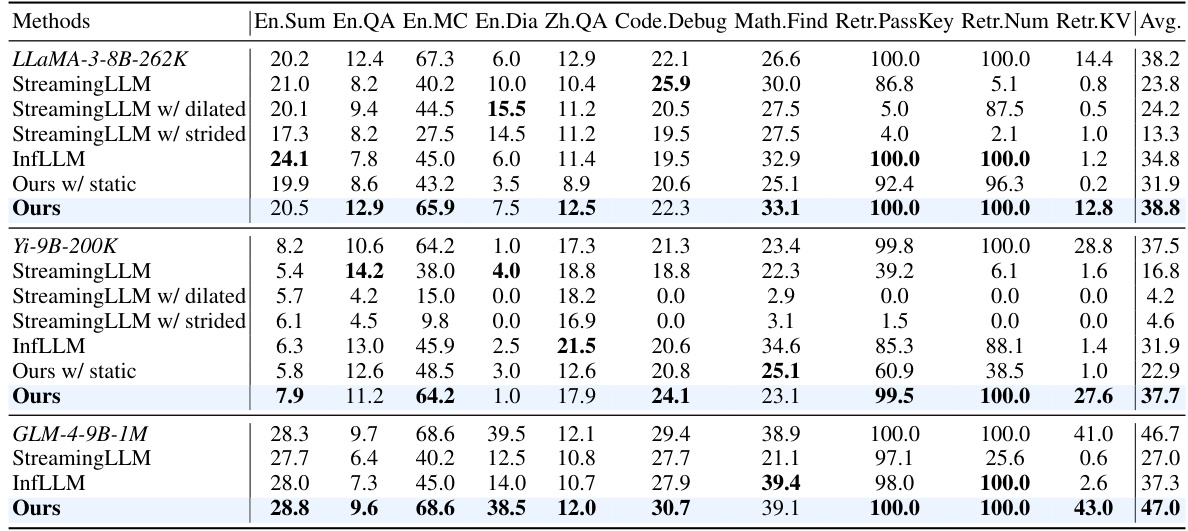
This table presents the performance comparison of different methods (StreamingLLM, StreamingLLM with dilated/strided windows, InfLLM, Ours with static masks, and Ours (MInference)) on the InfiniteBench benchmark. It shows the average performance across ten tasks, categorized into English summarization, English question answering, English multiple choice questions, English dialogue, Chinese question answering, code debugging, math finding, and retrieval tasks (Passkey, Number, and KV retrieval). The results are broken down by the three different base LLMs used: LLaMA-3-8B-262K, Yi-9B-200K, and GLM-4-9B-1M. It illustrates the impact of different sparse attention methods on the accuracy of various downstream tasks for long-context LLMs.

This table presents the performance of different methods (StreamingLLM variants, InfLLM, and the proposed MInference method) on the RULER benchmark, which evaluates long-context reasoning capabilities. The performance is evaluated at different context lengths (4K, 8K, 16K, 32K, 64K, and 128K tokens). The ‘Claimed Effective’ column indicates the claimed effective context window size reported by each model.

This table presents a comparison of the performance of different methods (StreamingLLM, StreamingLLM w/ dilated, StreamingLLM w/ strided, InfLLM, Ours w/ static, Ours) on the InfiniteBench benchmark across multiple tasks (En.Sum, En.QA, En.MC, En.Dia, Zh.QA, Code.Debug, Math.Find, Retr.PassKey, Retr.Num, Retr.KV). The results are shown for three different base LLMs: LLaMA-3-8B-262K, Yi-9B-200K, and GLM-4-9B-1M. The table allows readers to evaluate the effectiveness of MInference in comparison to other existing methods for long-context LLM inference, and across different model architectures. The average performance across all tasks is also provided for each method and model.

This table presents the performance comparison of different methods on the InfiniteBench benchmark when using SnapKV for KV cache compression in the decoding stage. It shows the average performance across various tasks (e.g., summarization, question answering, code debugging) using LLaMA-3 with and without MInference. The results demonstrate the compatibility and potential performance gains of combining MInference with KV cache compression techniques for efficient long-context LLM inference.

This table presents the performance comparison of different methods (StreamingLLM with variations, InfLLM, and the proposed method ‘Ours’ with and without static sparse indices) across various tasks within the InfiniteBench benchmark. The results are broken down by specific task (e.g., English summarization, English question answering, etc.) and model (LLaMA-3-8B-262K, Yi-9B-200K, GLM-4-9B-1M) showing performance scores for each method. The average performance across all tasks is provided for each model and method.

This table presents the performance comparison of different methods (StreamingLLM with variations, InfLLM, and the proposed method ‘Ours’ with and without static sparse attention) across various tasks within the InfiniteBench benchmark. The results are broken down by model (LLaMA-3-8B-262K, Yi-9B-200K, and GLM-4-9B-1M) and specific tasks (e.g., summarization, question answering, dialogue, code debugging, etc.). The average performance across all tasks is also provided. The table highlights how MInference performs compared to baselines in terms of accuracy on long-context tasks.

This table presents the results of an ablation study conducted on the InfiniteBench benchmark using the LLaMA-3-8B-Instruct-262K model. The study evaluates the effectiveness of different components of the proposed MInference method by removing or modifying specific parts of the algorithm. The table shows the average performance across various tasks within the InfiniteBench benchmark for the following models: the full MInference model (‘Ours’), MInference without Block-Sparse patterns (‘Ours w/ only vertical’), and MInference without Vertical-Slash patterns (‘Ours w/ only slash’). The results demonstrate the impact of each component on the overall performance, highlighting the importance of both Block-Sparse and Vertical-Slash patterns for achieving optimal accuracy.

This table presents a comprehensive comparison of various methods’ performance on the InfiniteBench benchmark, which consists of 10 diverse tasks. The results are broken down by specific tasks (e.g., English summarization, English question answering, Chinese question answering, etc.) and across three different base LLMs (LLaMA-3-8B-262K, Yi-9B-200K, and GLM-4-9B-1M). The table compares the performance of MInference against several baselines, including StreamingLLM with different windowing strategies, and InfLLM, providing a detailed analysis of the effectiveness and efficiency of the proposed approach across different models and tasks.

This table presents the performance comparison of various methods (StreamingLLM, StreamingLLM with dilated and strided attention, InfLLM, Ours w/ static, and Ours) on different base models (LLaMA-3-8B-262K, Yi-9B-200K, and GLM-4-9B-1M) across multiple tasks within the InfiniteBench benchmark. The tasks evaluate the models’ performance in various Natural Language Processing (NLP) and code-related tasks, showing the average performance across all tasks for each method. The results highlight how different methods handle different types of long-context scenarios.
Full paper#