↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Training large language models (LLMs) is computationally expensive, hindering research progress. Current model growth methods lack comprehensive evaluations, tested scalability, and clear guidelines for efficient LLM pre-training, creating obstacles for wider adoption. This limits the potential of accelerating LLM development and deployment.
The study introduces four atomic growth operators and evaluates them in a standardized LLM pre-training setting. It finds that a depth-wise stacking operator, Gstack, significantly accelerates training, reducing loss and improving performance on NLP benchmarks. The research shows Gstack’s scalability through experiments with up to 7 billion parameter LLMs and 750 billion training tokens, providing empirical guidelines on growth timing and factor to ensure practical application. This work overcomes critical obstacles hindering the adoption of model growth in LLM pre-training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient large language model (LLM) pre-training. It directly addresses the high computational cost of training LLMs by introducing a novel model growth technique, systematically evaluating its effectiveness, and providing practical guidelines for its application. This work has the potential to significantly reduce the resources needed to train LLMs, accelerating research progress and making LLMs more accessible to a wider range of researchers.
Visual Insights#
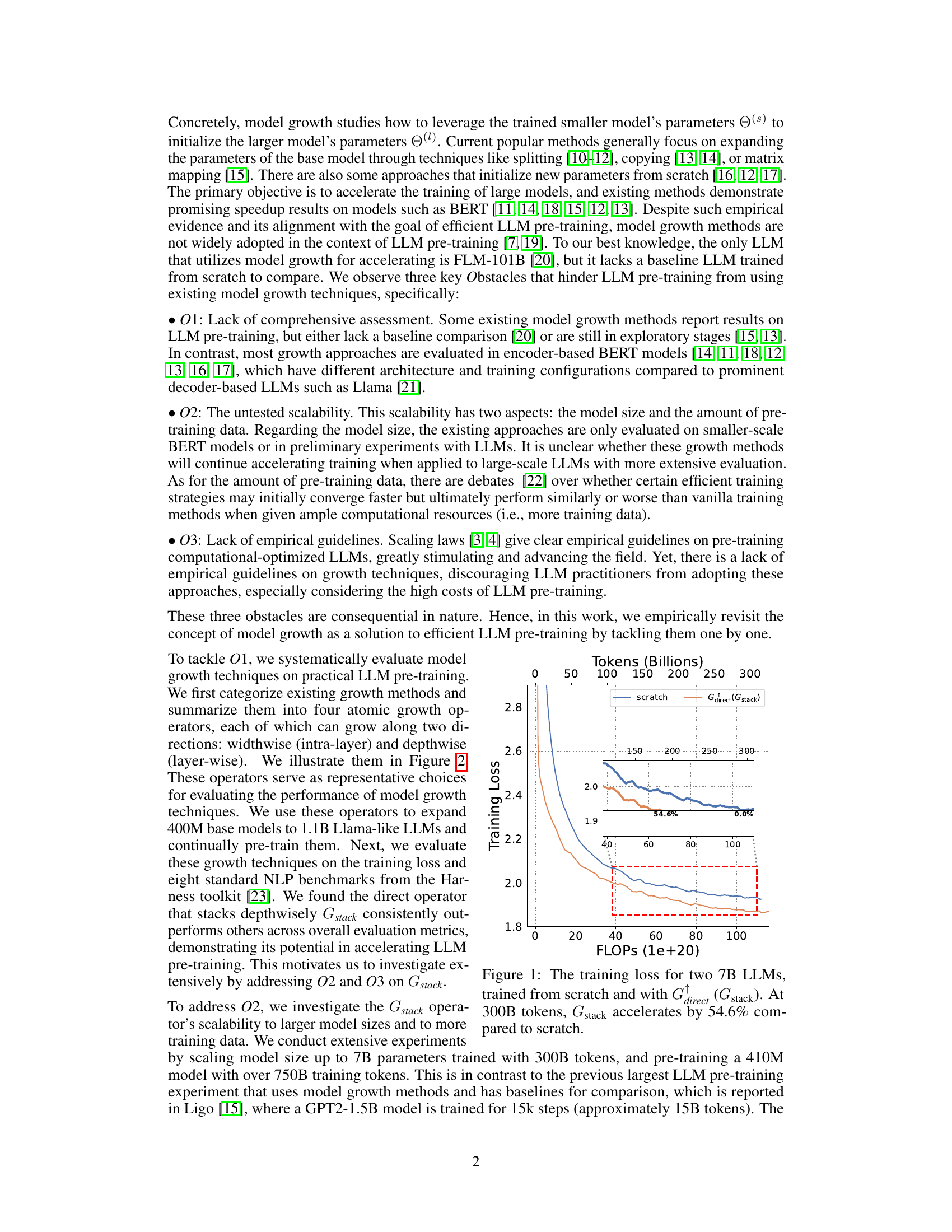
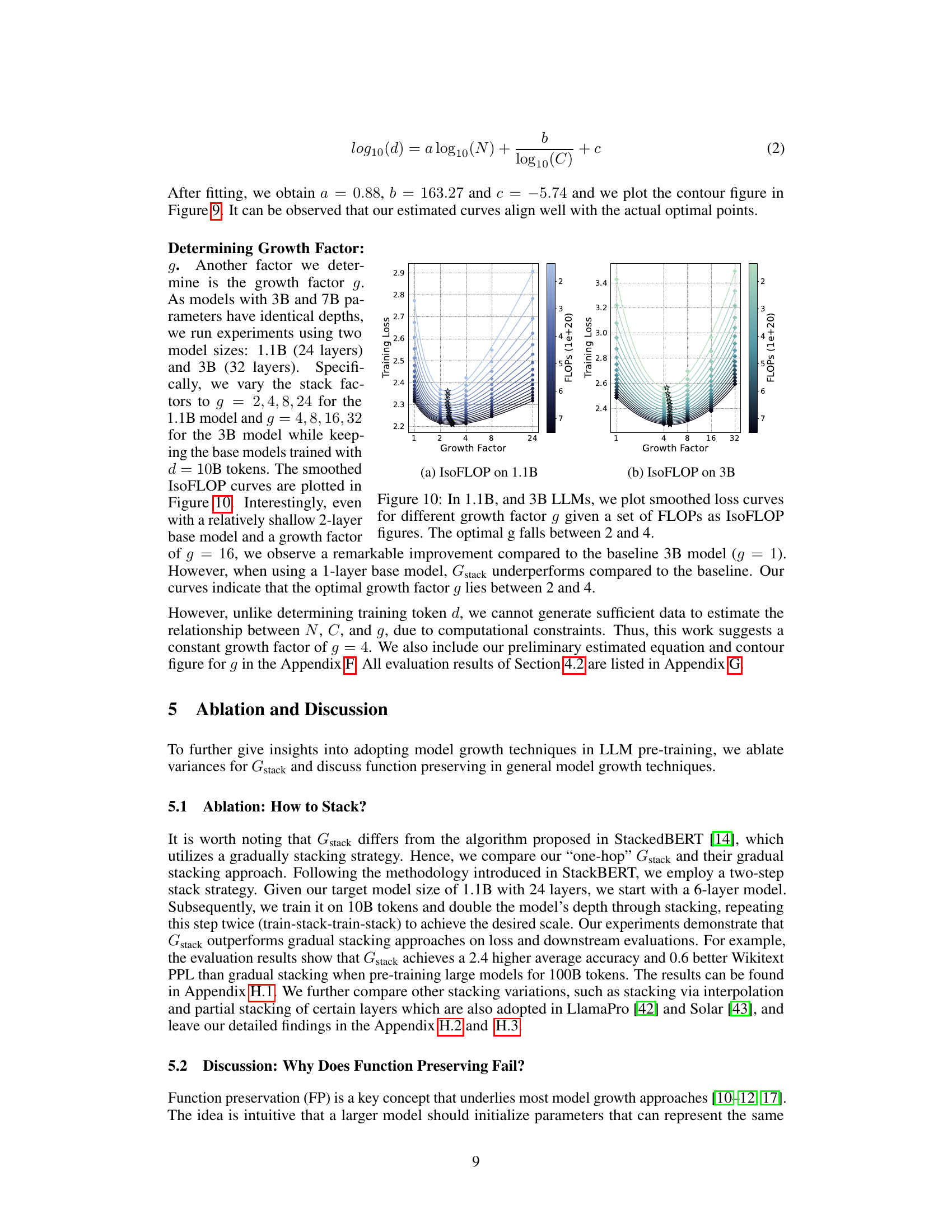
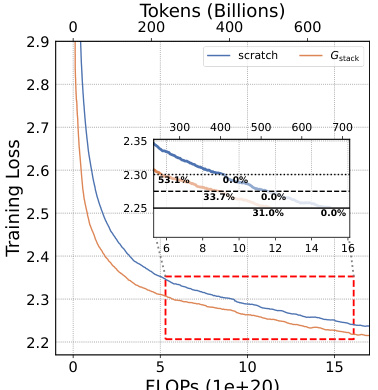
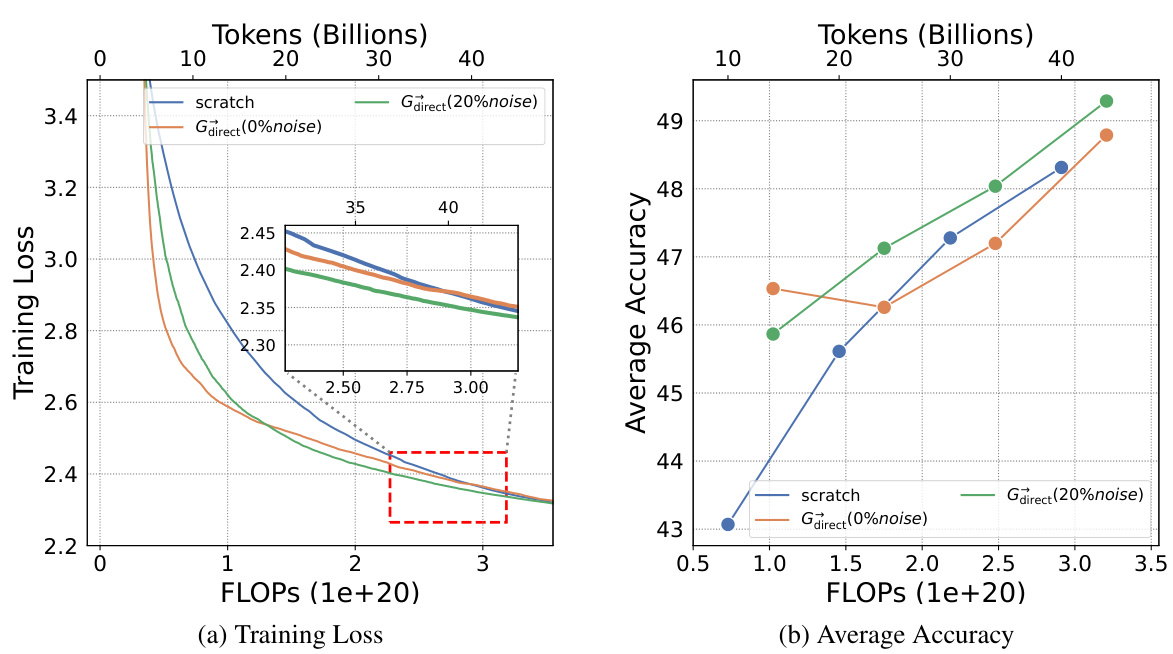
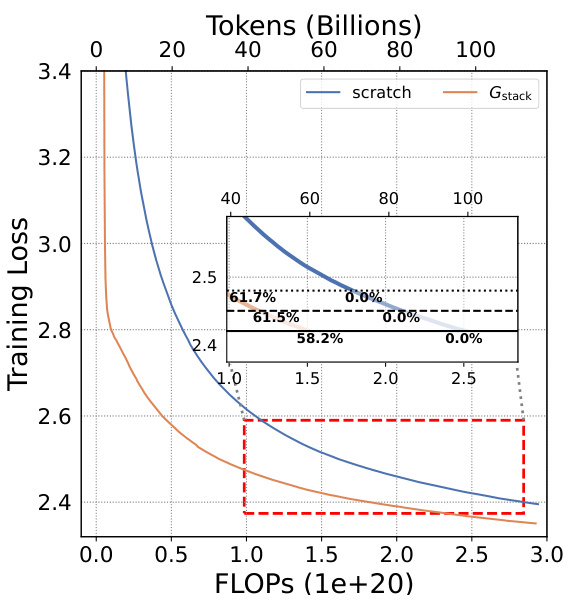
This figure compares the training loss curves of two 7B LLMs. One model was trained from scratch, while the other utilized the Gdirect (Gstack) method, a depthwise stacking operator. The x-axis represents the training FLOPS (floating-point operations), and the y-axis shows the training loss. The inset shows a zoomed-in view of the region where the models converge. The key observation is that Gstack achieves the same loss as the conventionally trained model (trained from scratch), but it uses significantly fewer FLOPs. Specifically, at 300 billion tokens, Gstack is 54.6% faster than the conventionally trained model. This highlights the efficiency gains of the Gstack method in accelerating LLM pre-training.

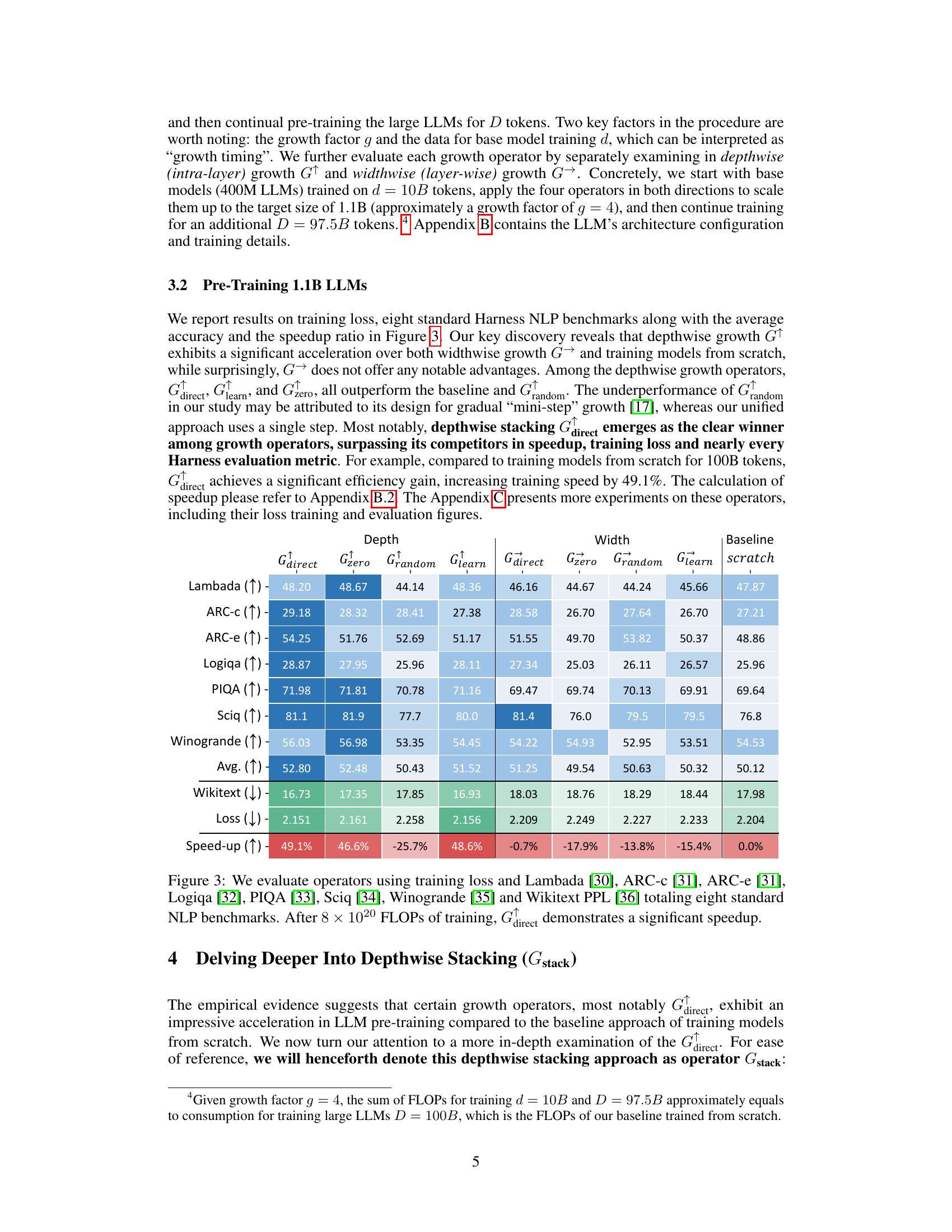
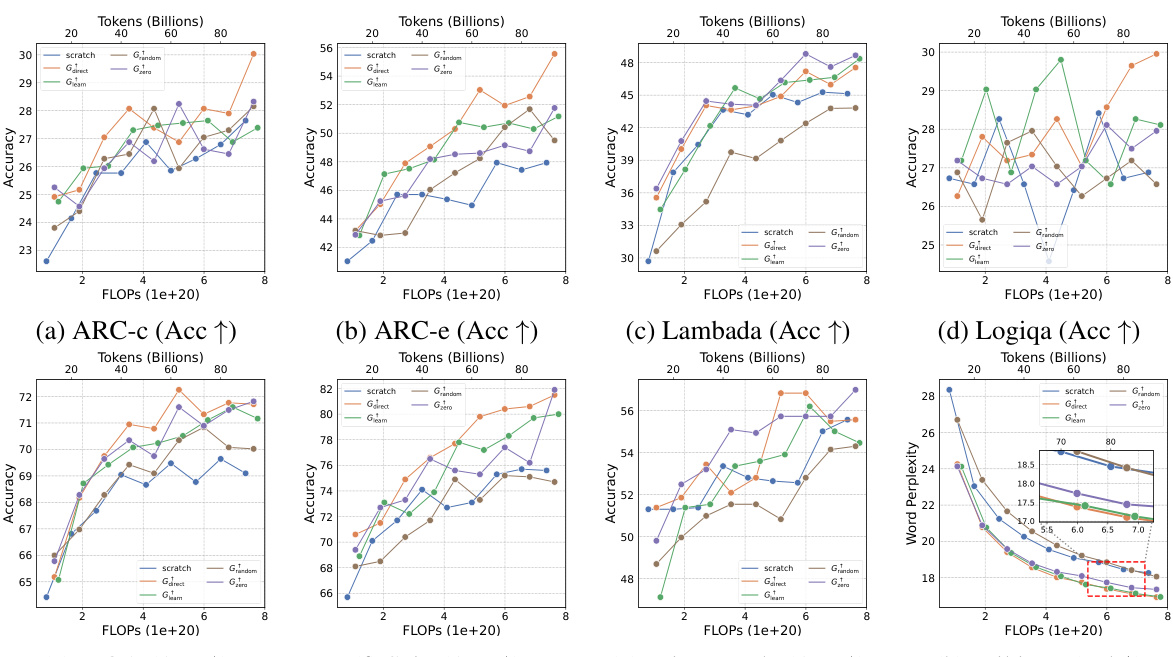
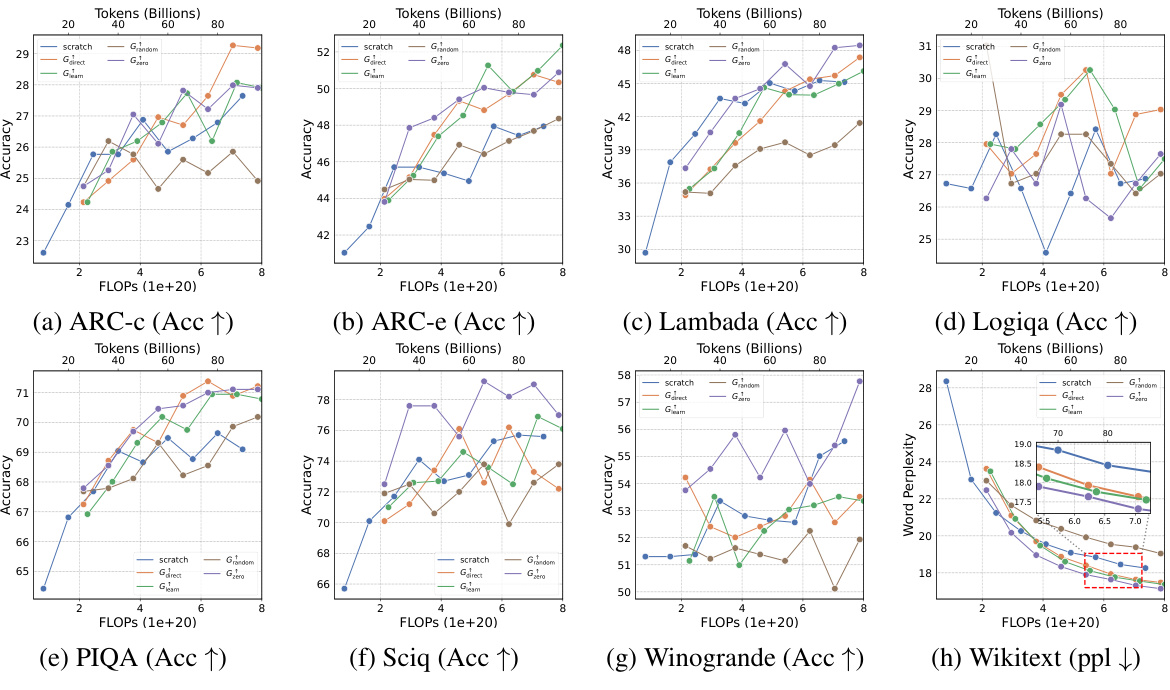
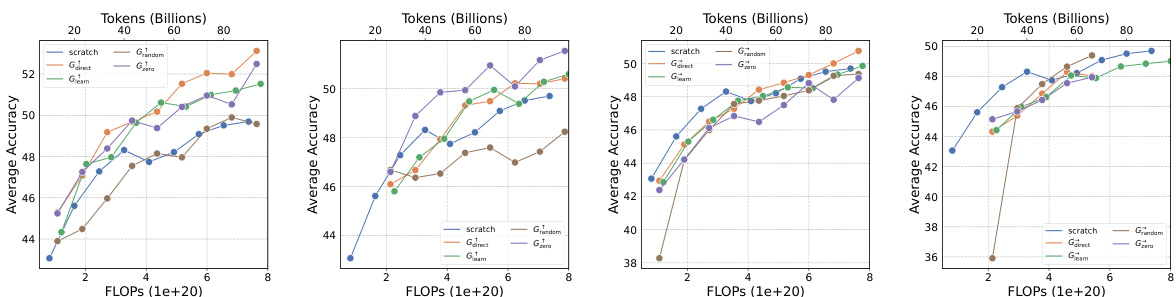
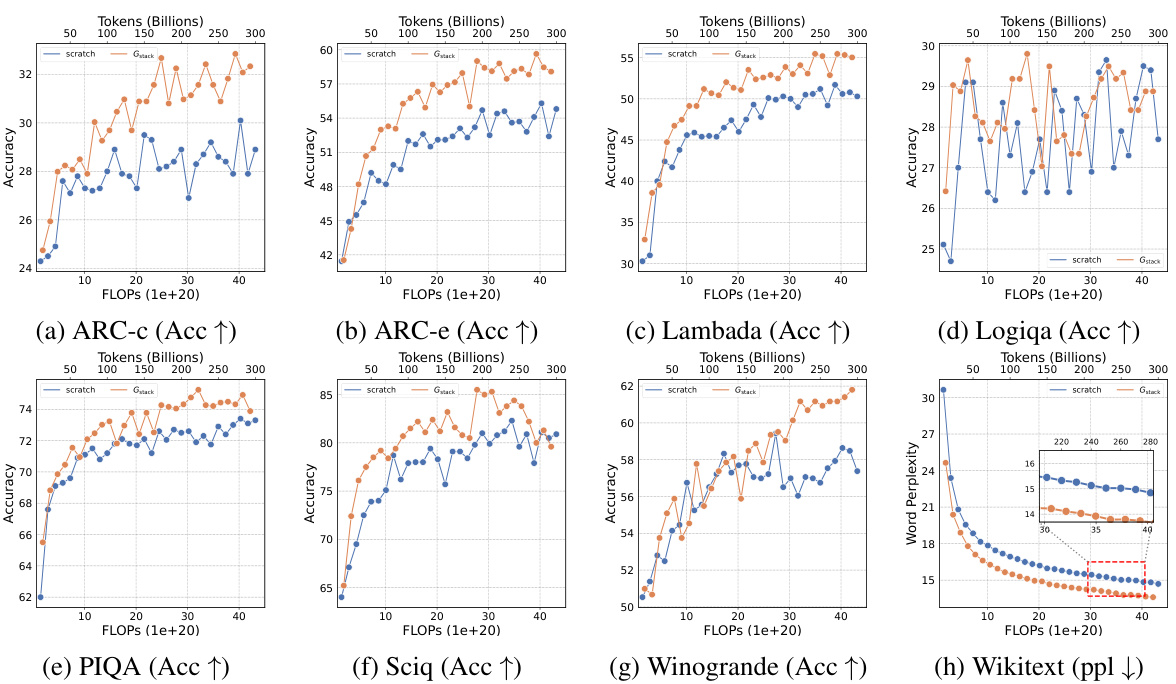
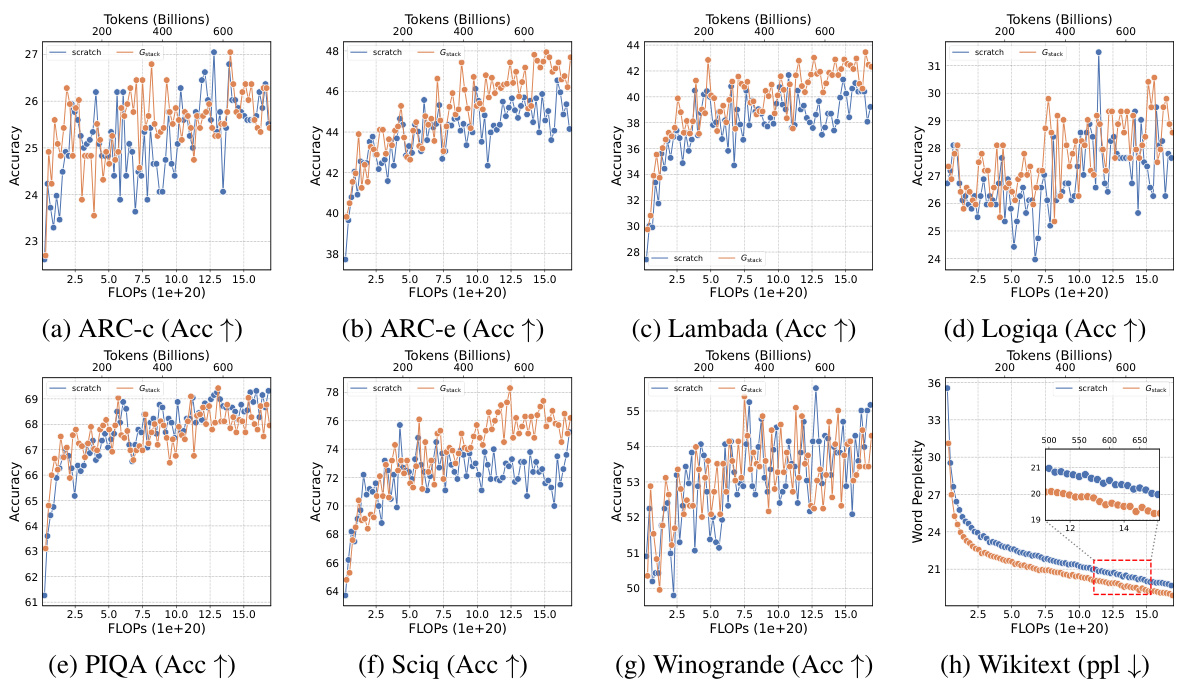
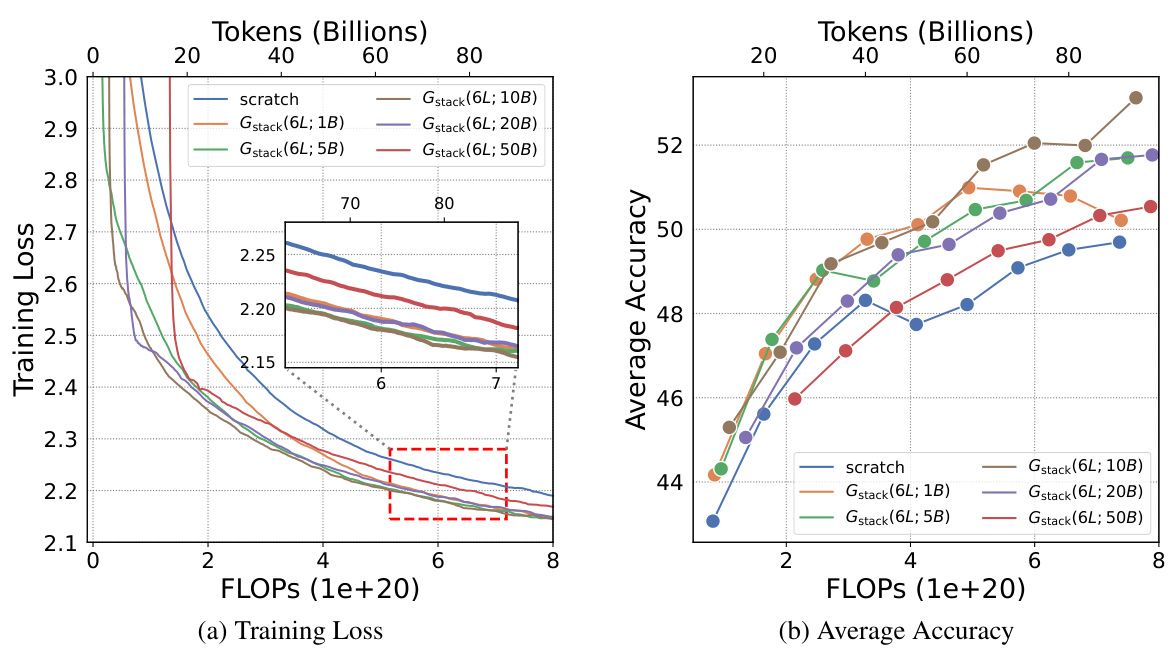
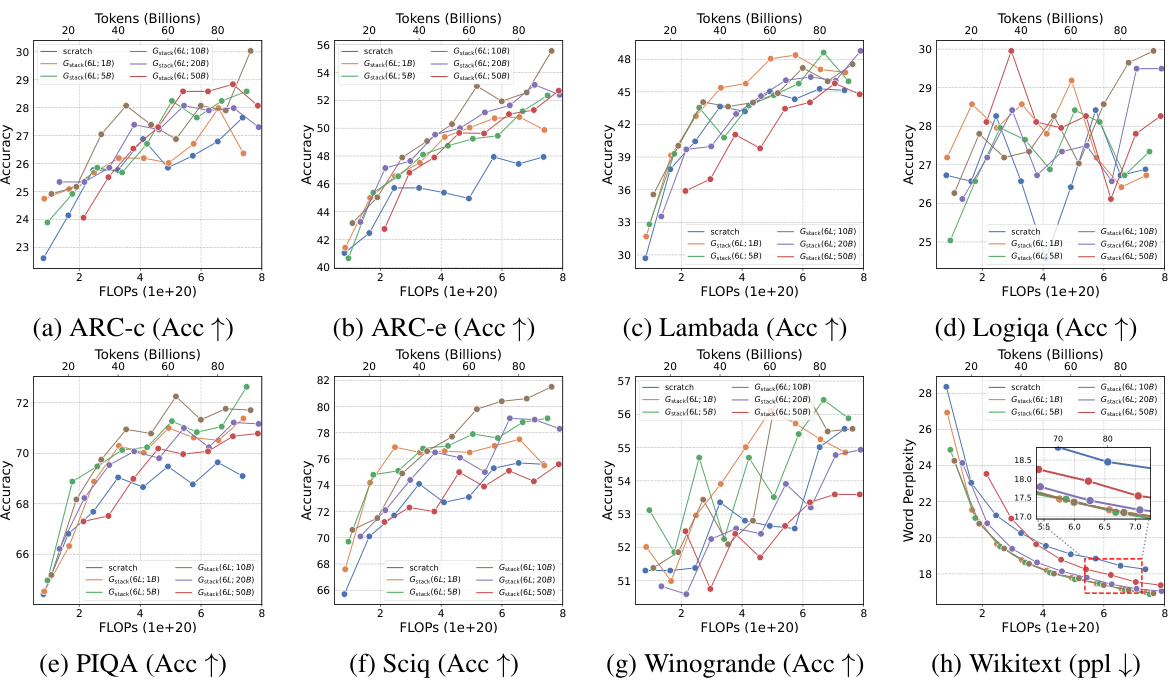
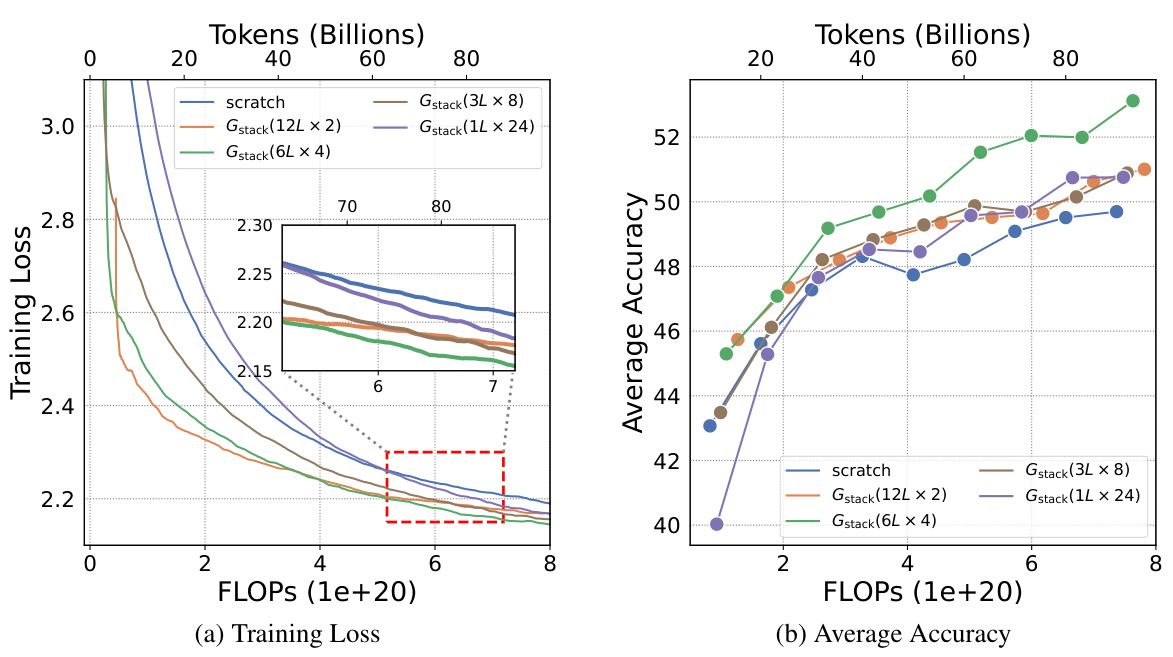
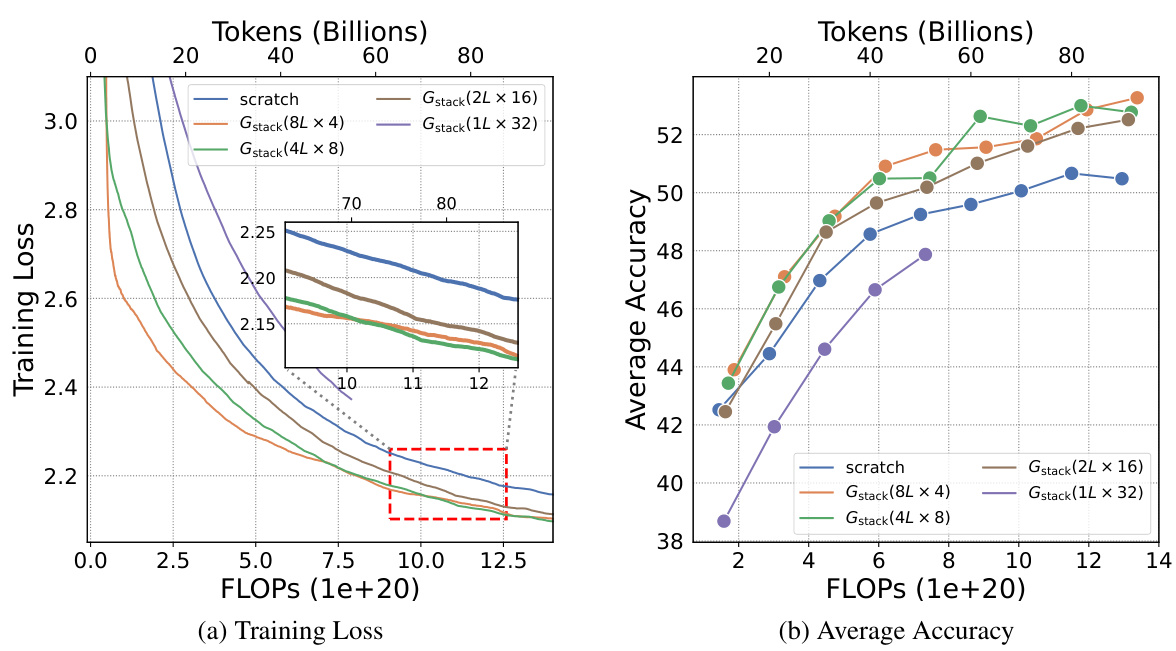
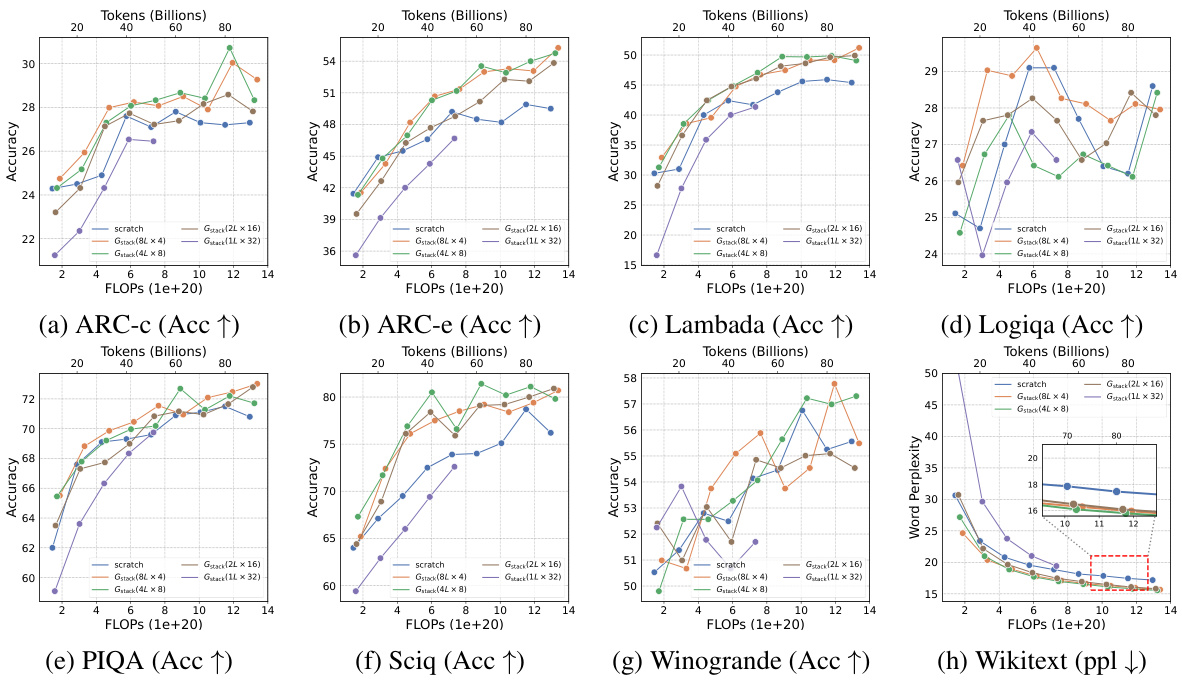
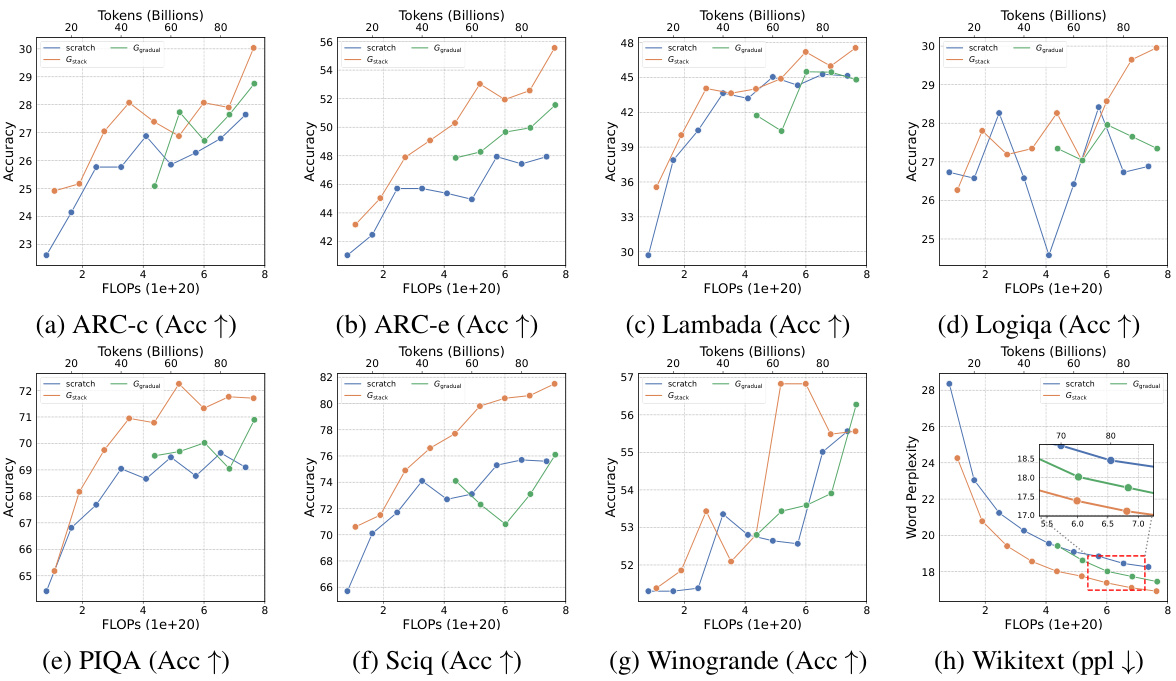
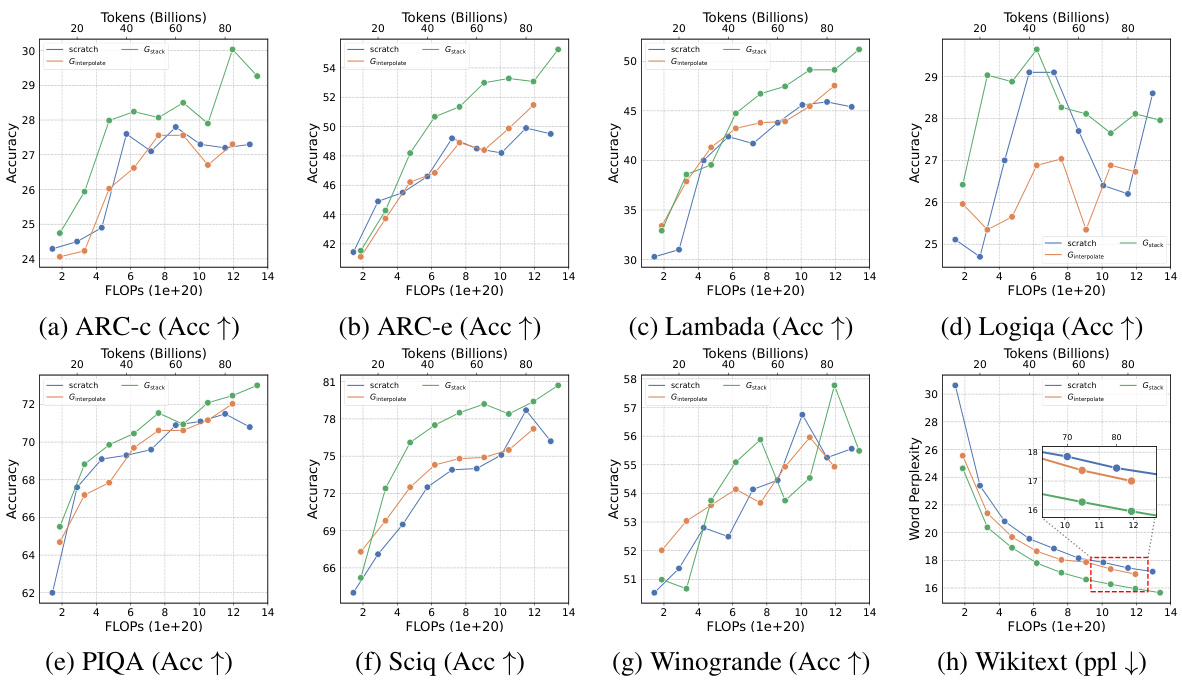
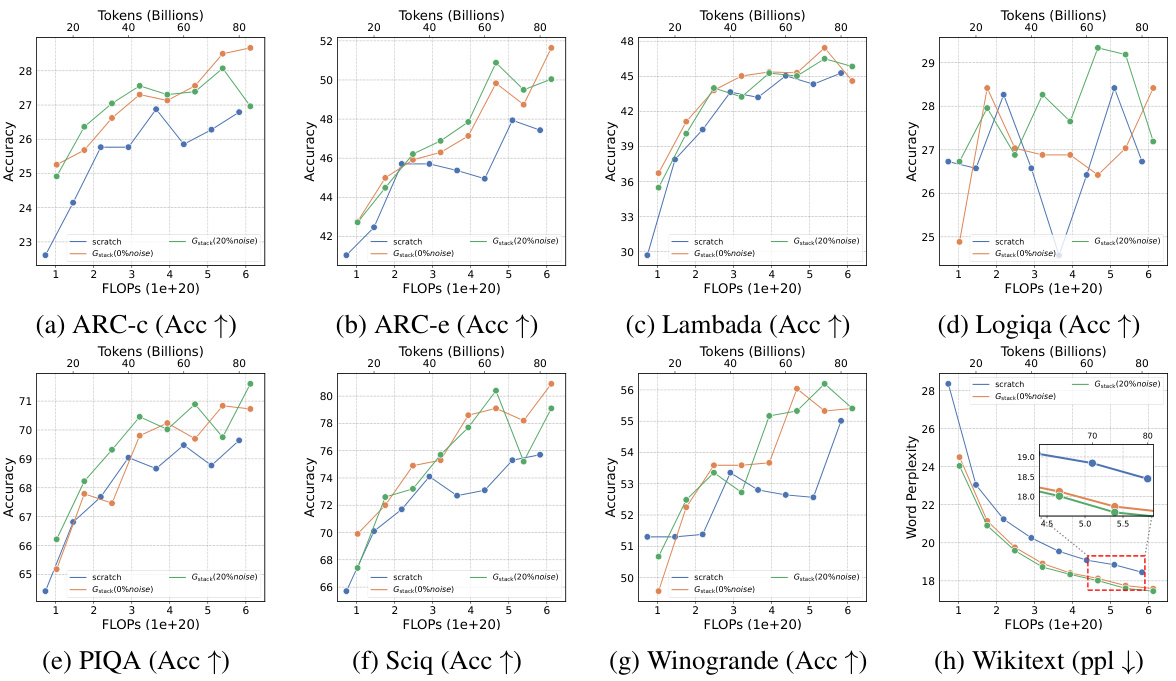
This table presents the results of an experiment evaluating four growth operators in both depthwise and widthwise directions on a 1.1B Llama-like LLM pre-training setting. The table compares the training loss, and performance on eight standard NLP benchmarks (Lambada, ARC-C, ARC-e, Logiqa, PIQA, Sciq, Winogrande, and Wikitext) for each growth operator and a baseline trained from scratch. The Gdirect operator, in particular, demonstrates significant speed improvements.
In-depth insights#
Efficient LLM Pretraining#
Efficient LLM pre-training is a critical area of research due to the high computational costs associated with training large language models. This paper explores model growth as a promising approach, systematically evaluating different growth operators and identifying depth-wise stacking (Gstack) as a particularly effective method. Gstack demonstrates significant speedups compared to training from scratch, even scaling to larger models and datasets. The authors also provide empirical guidelines for optimizing Gstack, addressing obstacles in model growth adoption such as a lack of comprehensive evaluation and standardized guidelines. This work is significant for making LLM pre-training more accessible and environmentally friendly by substantially reducing the computational burden.
Model Growth Operators#
The concept of “Model Growth Operators” in the context of large language model (LLM) pre-training presents a novel approach to accelerate the training process. The core idea revolves around systematically expanding smaller, pre-trained models into larger ones, thereby leveraging the knowledge gained during the initial training phase. This method contrasts with training LLMs from scratch, which is computationally expensive. The paper categorizes different model growth strategies into four atomic operators: each with its strengths and weaknesses concerning training speed and performance. A crucial aspect is the evaluation of these operators across various benchmarks and model scales to identify the most effective techniques for practical applications. Depth-wise stacking (Gstack) emerged as a particularly promising operator, exhibiting considerable speed improvements and performance gains compared to other methods and baselines. The research further explores practical guidelines, including optimization strategies for growth timing and scaling, to maximize the efficiency and scalability of these operators in LLM pre-training.
Gstack Scalability#
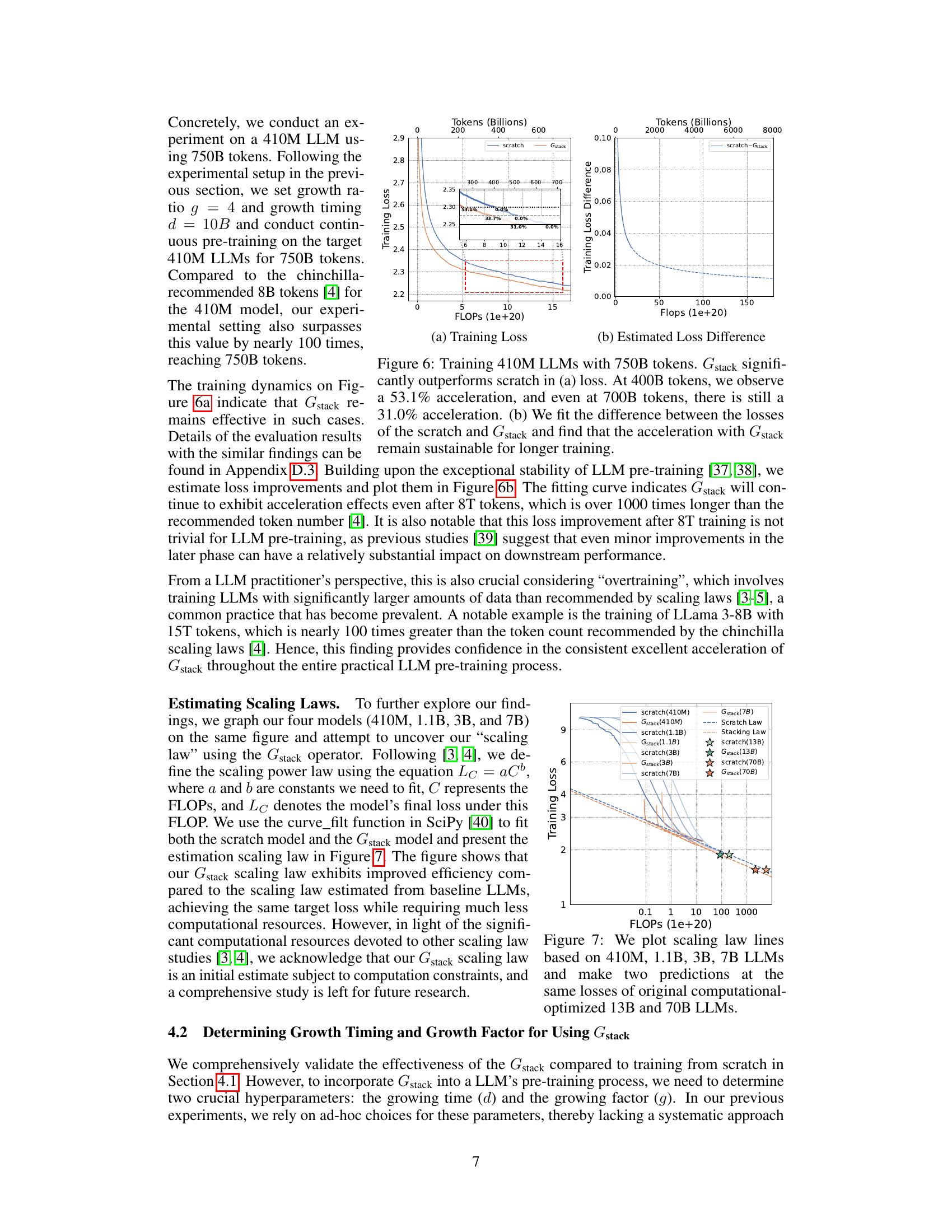
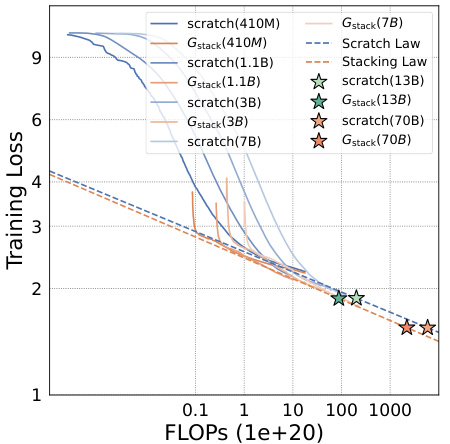
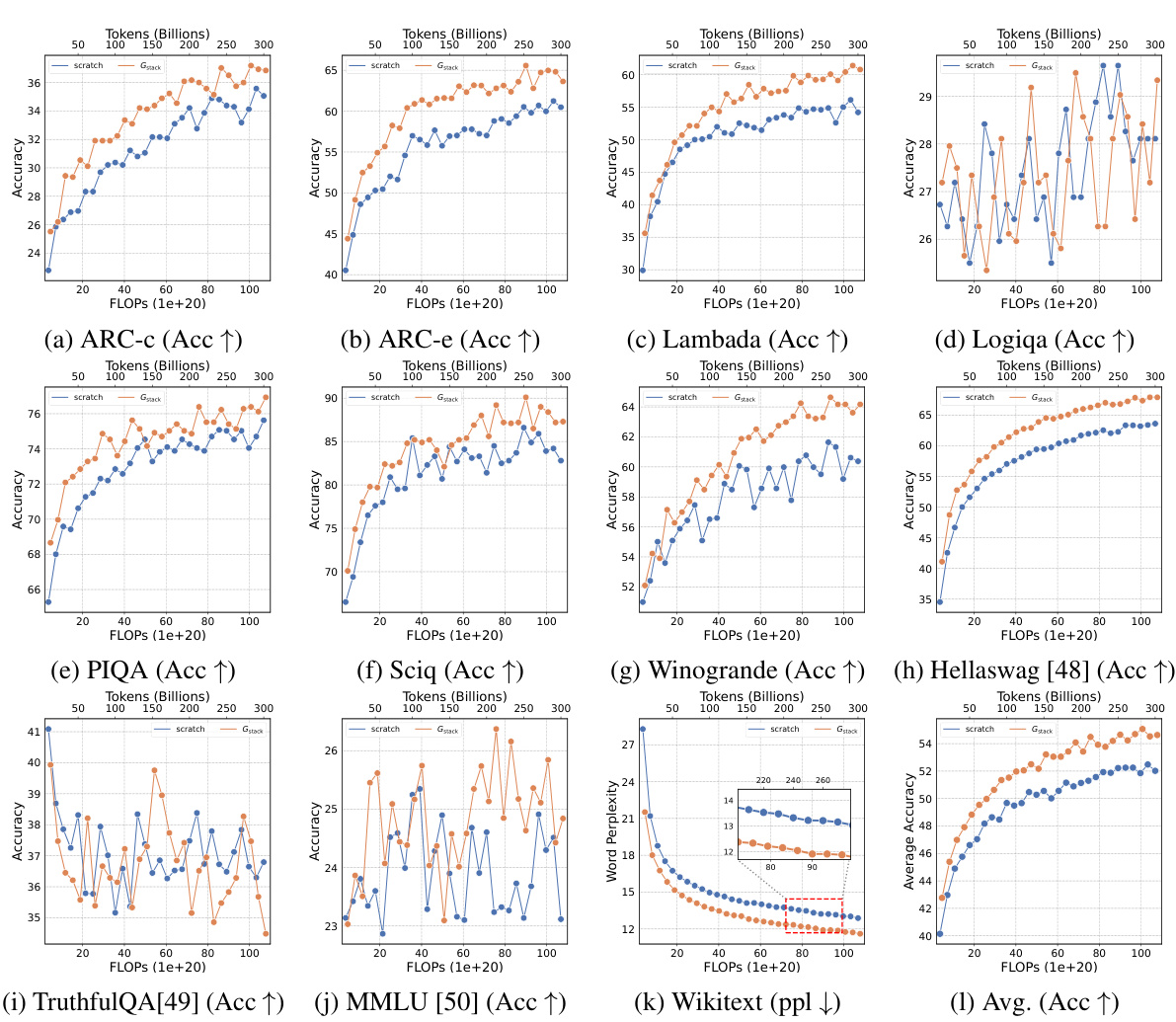
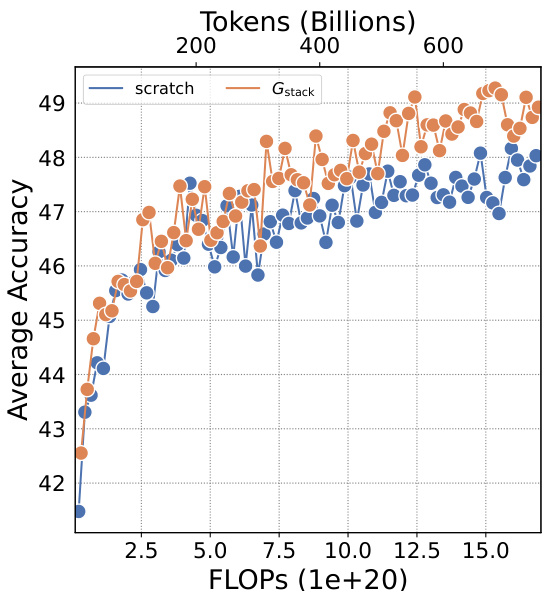
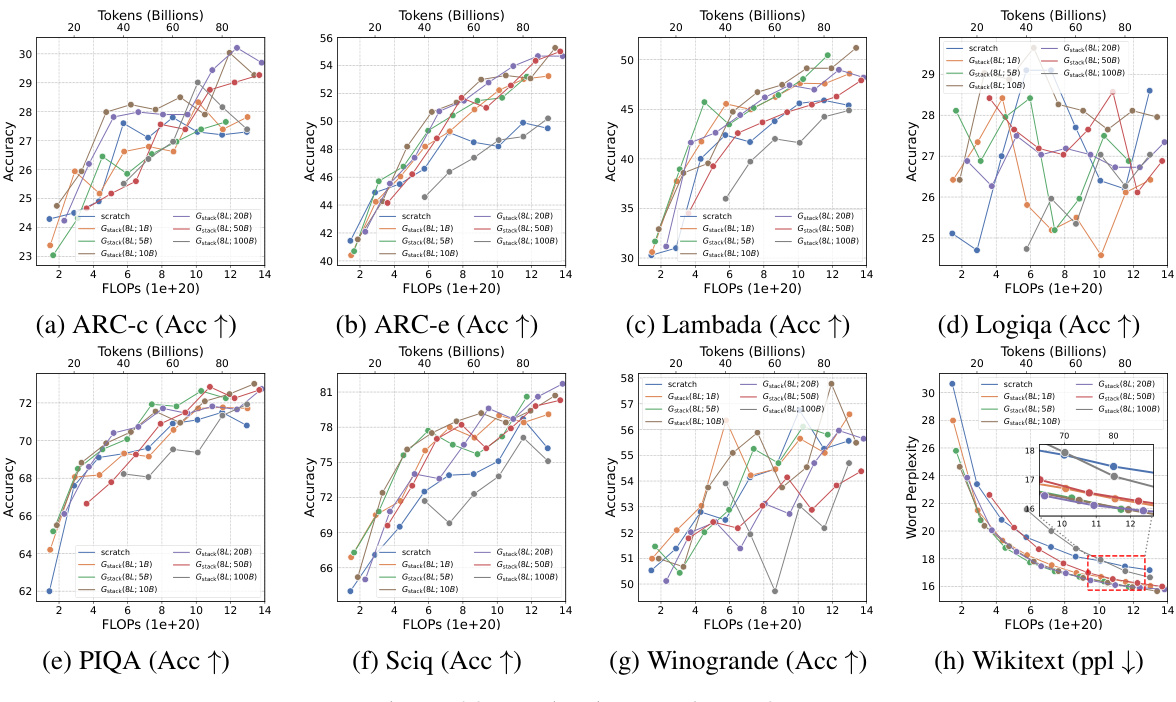
The scalability of GStack, a depth-wise stacking operator for efficient Large Language Model (LLM) pre-training, is a crucial aspect of its potential impact. The authors demonstrate consistent performance improvements across different model sizes (up to 7B parameters), indicating that the method is not limited to smaller LLMs. Furthermore, scalability with respect to training data is explored, showing GStack’s effectiveness even with up to 750B tokens, exceeding previous LLM growth studies. This demonstrated scalability addresses concerns about the limitations of model growth techniques in scaling to the extremely large datasets typically required for effective LLM training. The results strongly suggest GStack’s suitability for efficiently pre-training massive LLMs, thereby potentially reducing computational costs and carbon emissions associated with LLM development. The logarithmic scaling behavior further indicates the robustness of GStack for substantial future scaling.
Growth Guidelines#
The section on “Growth Guidelines” in this research paper is crucial for practical application of the proposed model growth technique. It translates theoretical findings into actionable steps, providing empirical guidance on key hyperparameters. This is especially valuable given the computational cost of large language model (LLM) pre-training, as it helps optimize the process. The authors likely present formalized equations or rules for determining optimal growth timing and growth factor. This allows researchers to tailor the growth strategy to their specific resource constraints and desired outcomes. A comprehensive analysis of these guidelines, including ablation studies and discussions of their limitations, is essential for demonstrating their practical utility and robustness. Furthermore, the paper likely explores the interaction effects between these two parameters and potential relationships with other LLM characteristics. Successfully establishing these guidelines is key to making model growth a widely adopted technique in LLM pre-training, bridging the gap between theoretical advancements and real-world applications.
Limitations and Future#
This research makes significant contributions to efficient large language model (LLM) pre-training by introducing the Gstack method. However, limitations exist. The study primarily focuses on specific model architectures and datasets, limiting generalizability. The computational cost of experiments, especially with larger LLMs, poses challenges for exhaustive exploration of hyperparameters and scalability. The empirical guidelines offered for Gstack could benefit from theoretical underpinnings. Future work should address these limitations by exploring diverse model architectures, conducting more extensive experiments across a broader range of datasets and scales, and developing a more robust theoretical framework to support the empirical observations. Exploring the interaction between Gstack and other training techniques, such as different optimizers and learning rate schedules, is also crucial. Finally, investigations into the potential societal impact of this efficient pre-training approach would enhance its overall value.
More visual insights#
More on figures
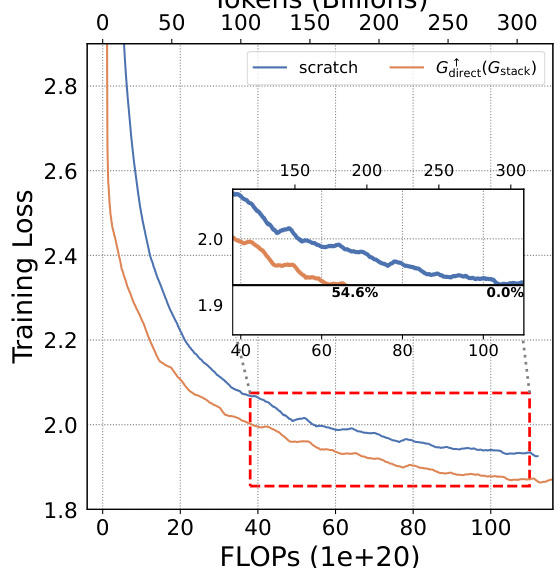
This figure illustrates four different methods for expanding the parameters of a neural network model. Each method involves different ways of generating new parameters (or neurons) based on existing parameters. * Gdirect: Directly duplicates or stacks existing layers (depthwise) or splits existing neurons (widthwise). * Glearn: Uses a learned hypernetwork to generate new parameters based on existing ones. * Gzero: Initializes new parameters to zero. * Grandom: Initializes new parameters randomly. The figure visually shows how each method modifies the existing network structure, either by adding layers (depthwise growth) or adding neurons within a layer (widthwise growth).
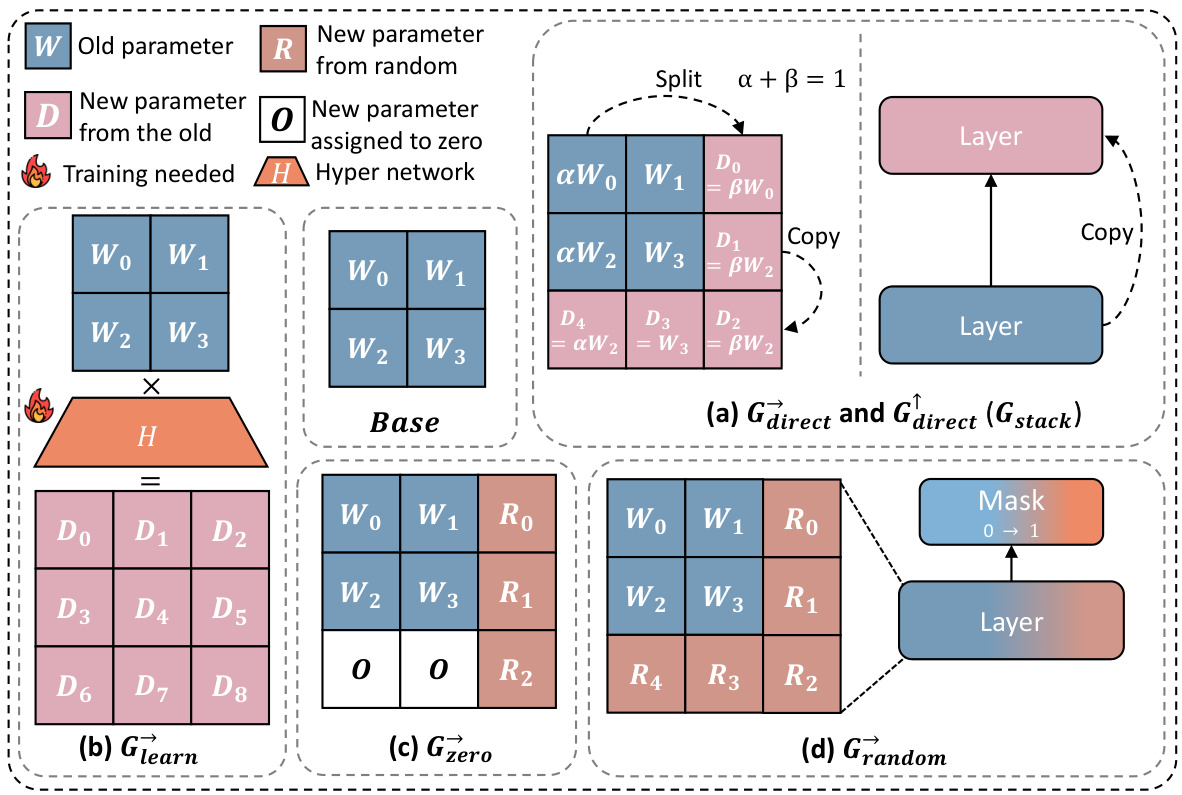
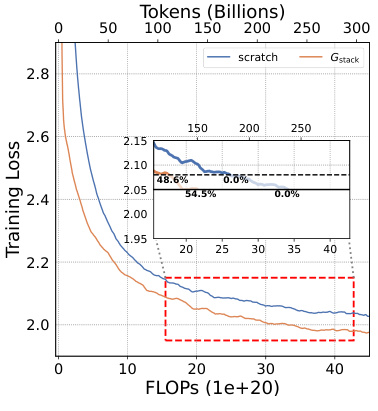
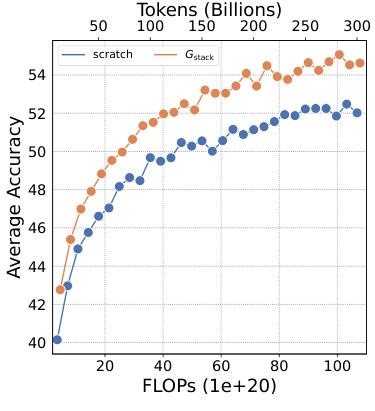
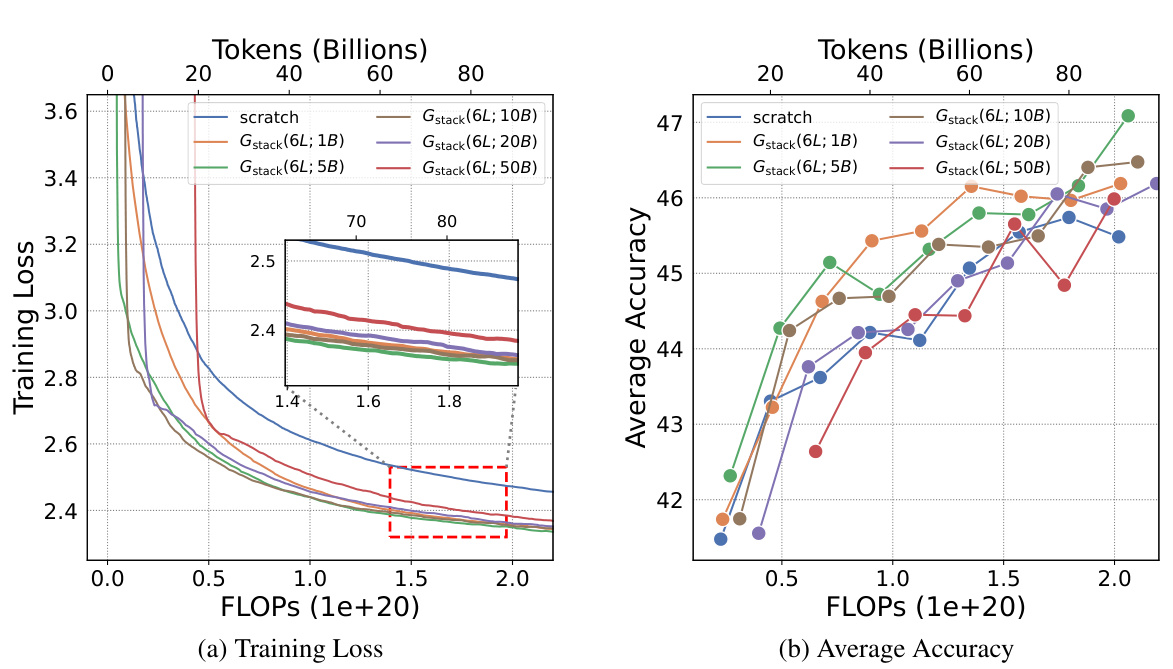
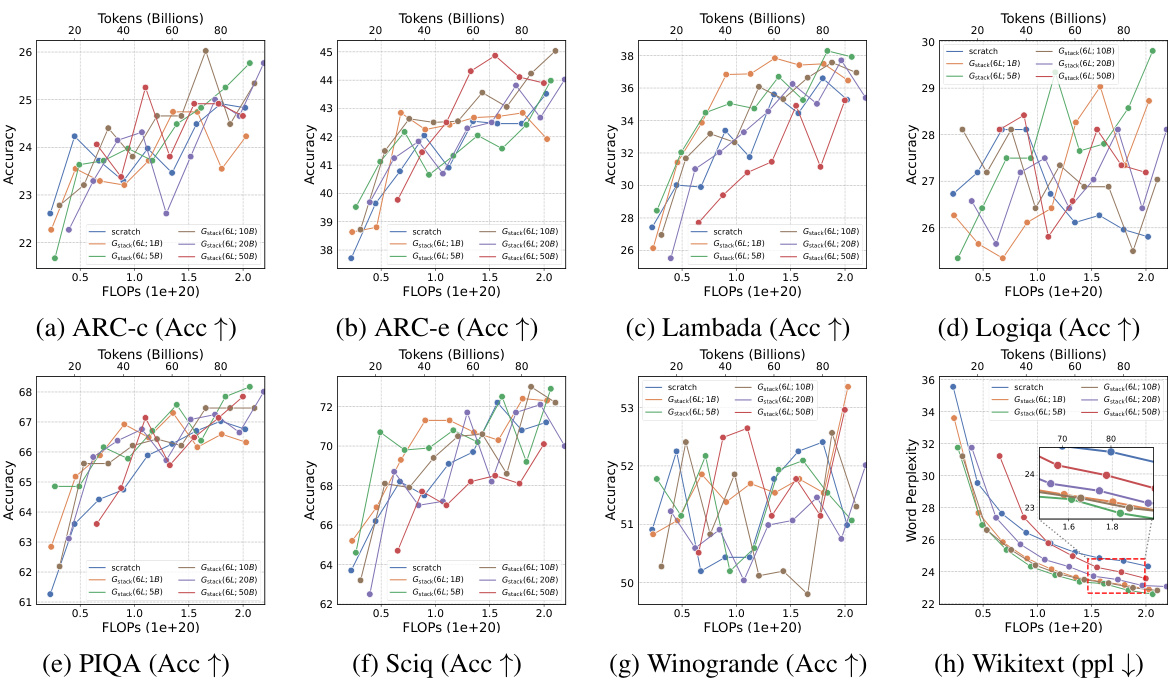
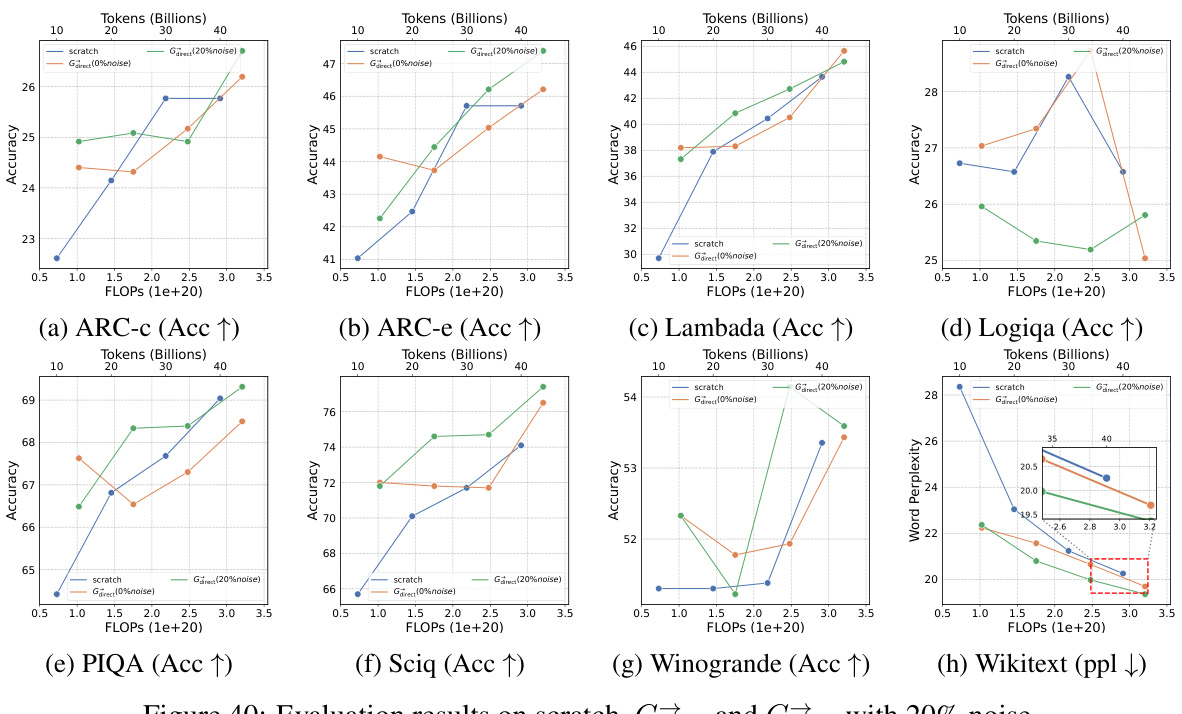
This figure shows the training loss and average accuracy across multiple NLP benchmarks for two 3B LLMs: one trained from scratch and another using the Gstack method. The Gstack model demonstrates significantly lower training loss and higher average accuracy compared to the model trained from scratch, achieving speedups of 48.6% at 180B tokens and 54.5% at 240B tokens. This highlights the effectiveness of the Gstack approach in accelerating the training of large language models.
This figure compares the training loss curves of two 7-billion parameter LLMs. One model was trained from scratch, while the other used the Gstack method, a depthwise stacking operator. The x-axis represents the FLOPs (floating-point operations) in units of 1e+20, and the y-axis shows the training loss. The inset graph zooms in on the region where the two curves diverge, highlighting that Gstack achieves a 54.6% speedup at 300 billion tokens compared to the conventional training method.
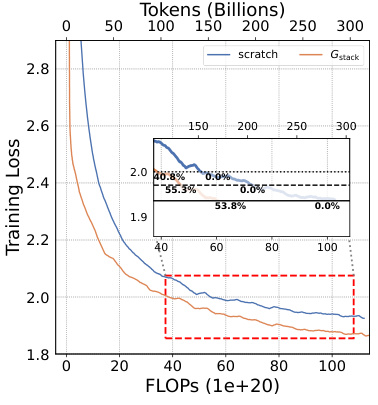
This figure compares the training loss curves of two 7B Large Language Models (LLMs). One LLM was trained conventionally from scratch, while the other used the Gstack method, a model growth technique. The x-axis represents the FLOPs (floating point operations) during training, and the y-axis represents the training loss. The Gstack model achieves the same level of training loss as the conventionally trained model but uses significantly fewer FLOPs (54.6% fewer in this case), indicating a substantial speedup in training time. The red dashed box highlights the point where Gstack achieves its 54.6% speedup.
This figure shows the training loss and average accuracy of 3B LLMs trained with 300B tokens using two different methods: conventional training from scratch and the proposed Gstack method. The Gstack method consistently shows lower training loss and higher average accuracy across eight standard NLP benchmarks, demonstrating a significant speedup in training. The speedup is more pronounced at higher token counts (180B and 240B tokens).
This figure shows the training loss curves for two 7B Large Language Models (LLMs). One LLM was trained from scratch, while the other utilized the Gstack method. The x-axis represents the number of training tokens (in billions), and the y-axis represents the training loss. The Gstack method demonstrates a significant speedup, converging to a similar loss as the model trained from scratch with fewer tokens (300B tokens for Gstack vs. more for the from-scratch model). The figure highlights that at 300 billion tokens, Gstack achieves a 54.6% speedup compared to training the model from scratch.
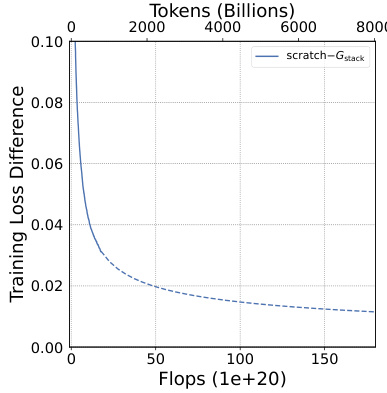
This figure shows a comparison of the training loss curves for two 7B Large Language Models (LLMs). One LLM was trained from scratch, while the other used the Gstack method, a depth-wise stacking operator. The x-axis represents the number of tokens (in billions) used for pre-training, and the y-axis represents the training loss. The Gstack model achieves the same training loss as the conventionally trained model, but with significantly fewer tokens (194B tokens versus 300B tokens), representing a 54.6% reduction in training time.
This figure shows the training loss and average accuracy of 3B LLMs trained with 300B tokens using both conventional training (scratch) and the proposed Gstack method. The results demonstrate that Gstack significantly reduces training loss and improves average accuracy across multiple NLP benchmarks. Specifically, at 180B and 240B tokens, Gstack achieves a 48.6% and 54.5% speedup, respectively, compared to the scratch model.
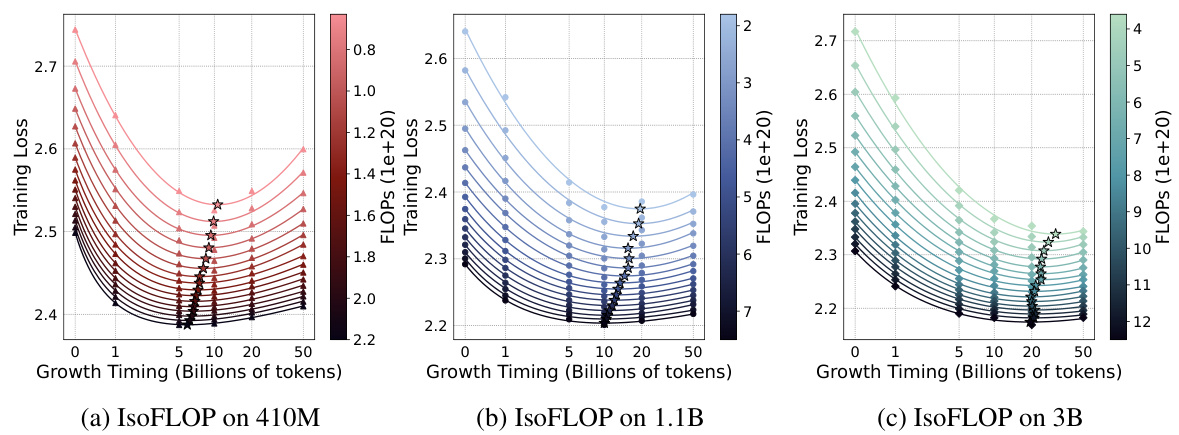
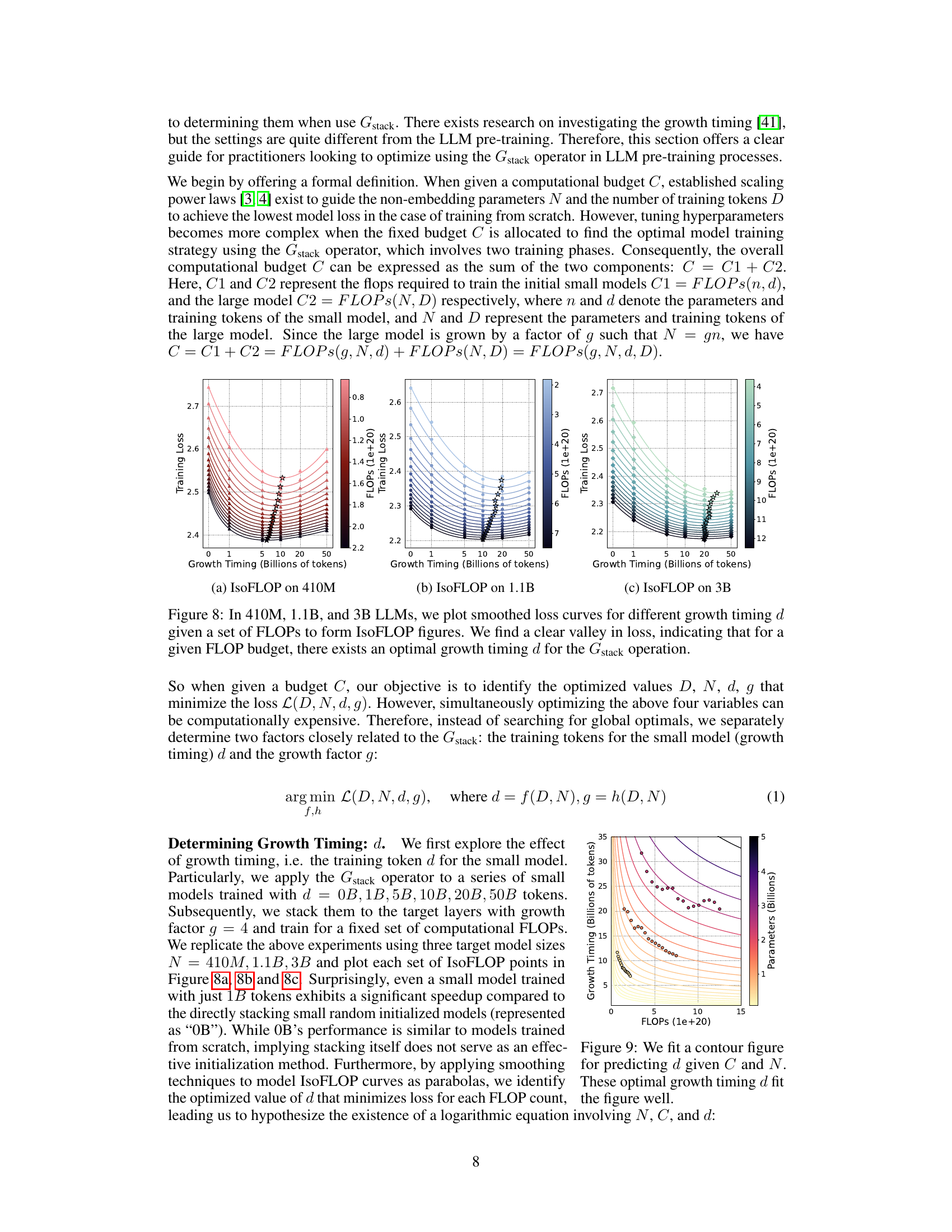
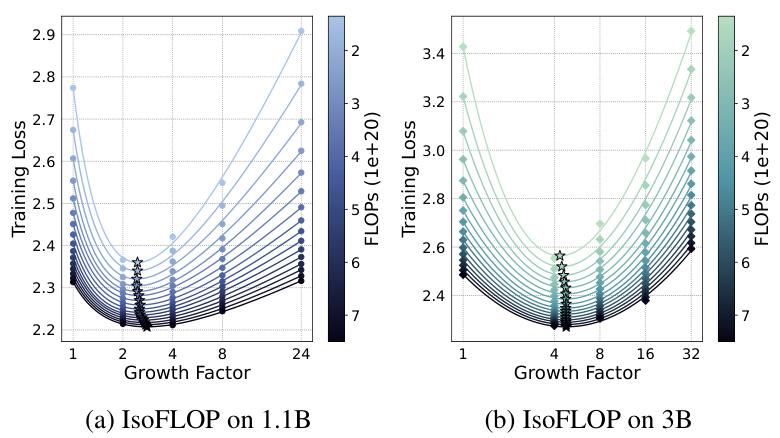
This figure shows the relationship between training loss, FLOPs, and growth timing (d) for three different sizes of LLMs (410M, 1.1B, and 3B parameters). Each subplot displays multiple curves representing different FLOPs. The curves show that for each FLOP value, there’s a minimal loss associated with an optimal growth timing (d). This suggests a way to determine the best time to initiate the growth operation given a particular computational budget.
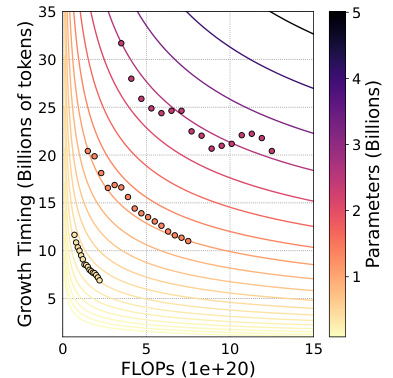
This figure visualizes the relationship between the optimal growth timing (d), computational budget (C), and number of parameters (N) for the Gstack operator in LLM pre-training. It shows a contour plot where lines of constant FLOPs are plotted against growth timing. Each line represents a particular computational budget, and the valley along each line indicates the optimal growth timing (d) for a given computational budget (C) and target model size (N). The plot demonstrates the existence of a logarithmic equation linking these three variables.
This figure displays the training loss and average accuracy of 3B LLMs trained with 300B tokens, comparing the performance of Gstack against training from scratch. Gstack demonstrates significant improvements in both loss and accuracy across various NLP benchmarks, resulting in notable speedups (48.6% and 54.5% at 180B and 240B tokens, respectively).
This figure shows the training loss curves for two 7-billion parameter large language models (LLMs). One LLM was trained conventionally from scratch, while the other utilized the Gstack method. The x-axis represents the cumulative floating-point operations (FLOPs), a measure of computational cost, and the y-axis displays the training loss. The figure demonstrates that Gstack achieves a 54.6% speedup in training compared to the conventional approach, reaching the same loss with significantly fewer FLOPs.

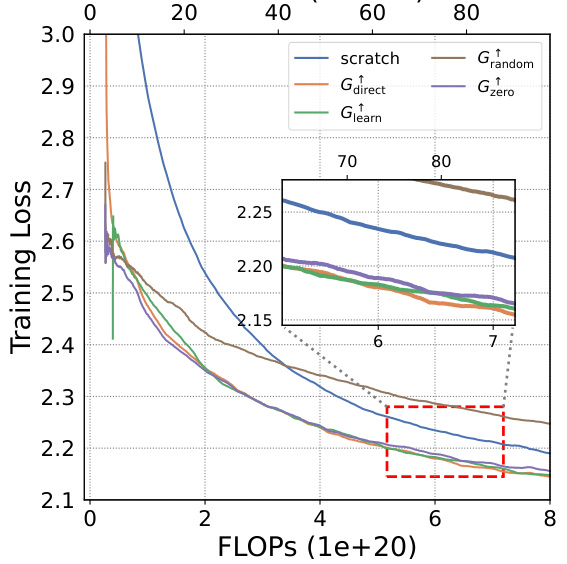
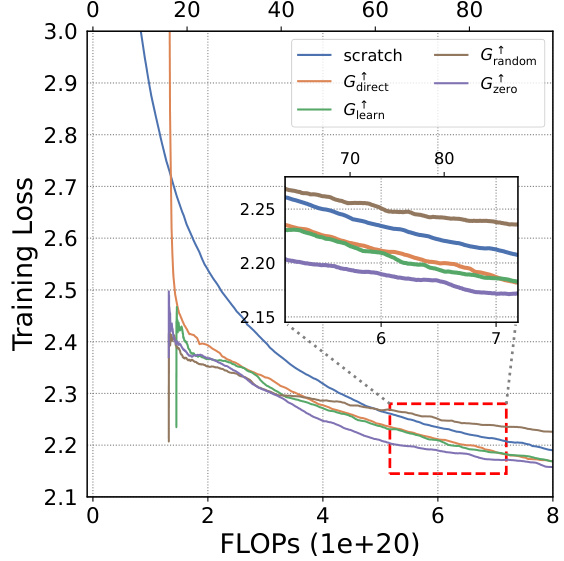
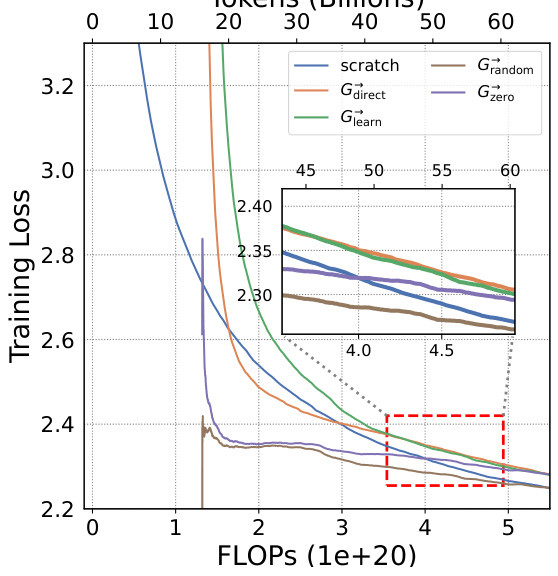
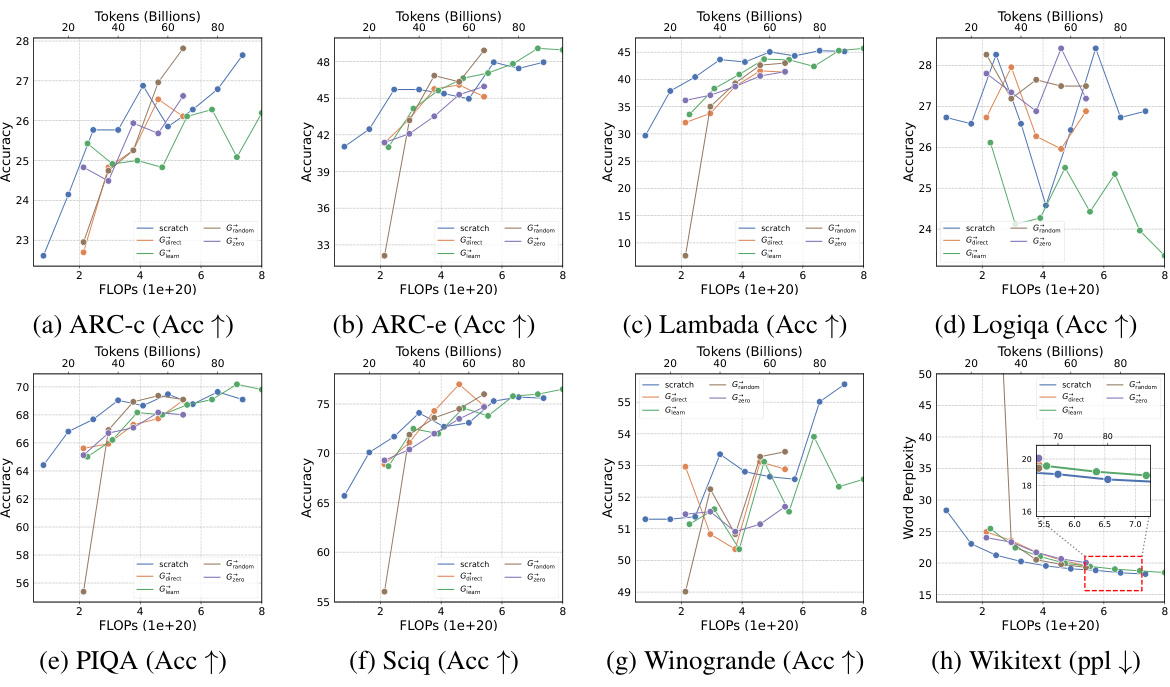
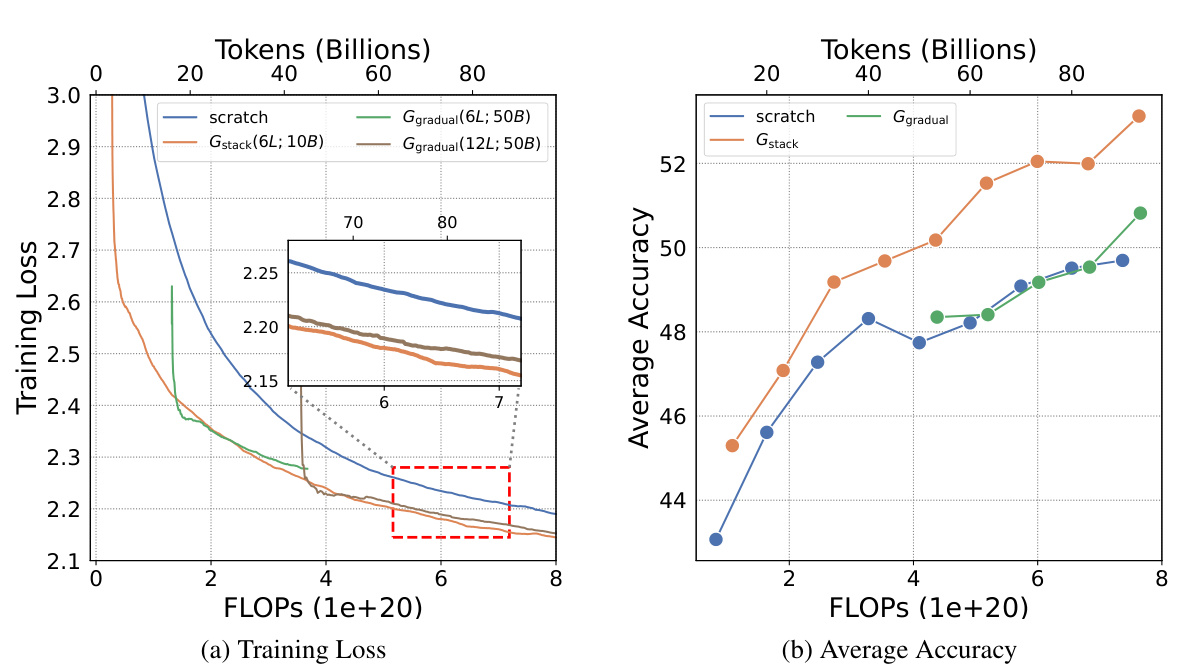
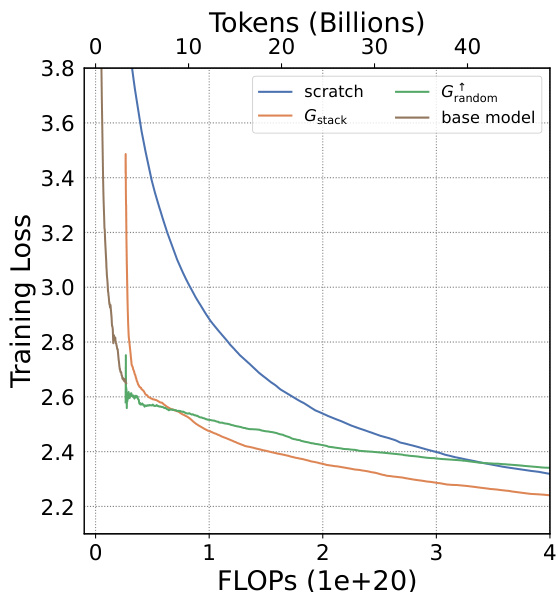
This figure shows the training loss curves for four different growth operators (Gdirect, Glearn, Gzero, Grandom) and training from scratch on the Slimpajama dataset. The top two sub-figures show the depth-wise growth from small models trained on 10B and 50B tokens respectively, while the bottom two sub-figures depict the width-wise growth from the same small models. Each sub-figure compares the training loss of the different methods in terms of FLOPs. This visualization helps to assess the efficiency of each growth operator in accelerating LLM pre-training, showing how quickly they achieve lower training loss compared to starting from scratch.
This figure shows a comparison of the training loss curves for two 7B LLMs. One model was trained from scratch, while the other utilized the Gdirect (Gstack) method. The graph demonstrates that the Gstack model achieves a significant speedup of 54.6% at 300 billion tokens compared to the conventionally trained model. This highlights the efficiency gains of the Gstack approach in LLM pre-training.
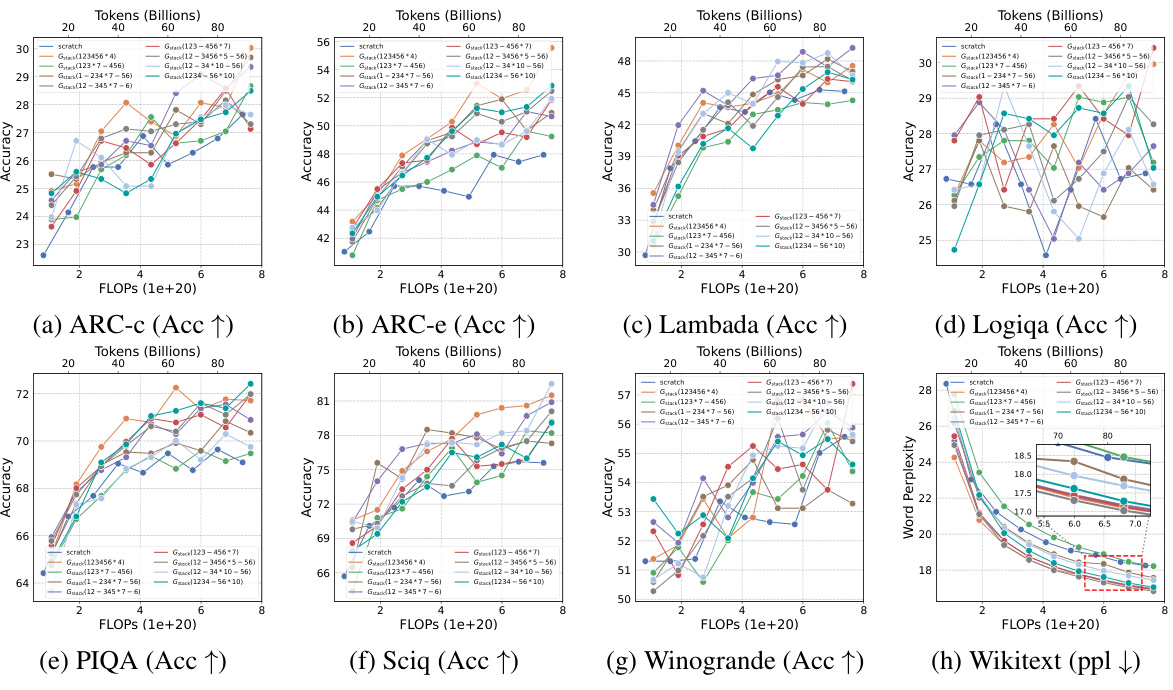
This figure shows the results of training loss and eight NLP benchmark evaluation metrics on four growth operators (Gdirect, Glearn, Gzero, Grandom) in both depthwise and widthwise directions. The depthwise stacking operator (Gdirect) consistently outperforms other operators in accelerating LLM pre-training. The results demonstrate the effectiveness of Gdirect and its significant speedup compared to training from scratch, as evidenced by the substantial reduction in training loss and improvement in various NLP benchmark scores.
This figure compares the training loss curves for two 7 Billion parameter Language Models (LLMs). One LLM was trained conventionally from scratch, while the other used the Gstack method, a model growth technique. The y-axis represents the training loss, and the x-axis represents the number of training tokens (in billions). The figure shows that the Gstack model achieves the same loss as the conventionally trained model but with significantly fewer tokens (194B vs 300B), resulting in a 54.6% speedup.
This figure compares the training loss curves of two 7-billion parameter LLMs. One model was trained conventionally from scratch, while the other utilized the Gstack method, a depth-wise stacking operator. The plot shows that at 300 billion tokens, the Gstack model converges to the same loss as the scratch model but with a significant reduction in the number of training tokens, resulting in a 54.6% speedup.

This figure shows a comparison of the training loss curves for two 7B LLMs. One model was trained from scratch, while the other used the Gdirect (Gstack) method, which leverages smaller pre-trained models to accelerate training. The graph clearly demonstrates that Gstack achieves significantly faster convergence, reaching the same loss level as the model trained from scratch with 105.4 billion fewer tokens (a 54.6% reduction in tokens needed). This highlights the efficiency gains offered by the Gstack model growth technique.
This figure shows a comparison of the training loss curves for two 7B LLMs. One model was trained conventionally from scratch, while the other was trained using the Gstack method (a depth-wise stacking operator). The results demonstrate that Gstack achieves a 54.6% speedup in training compared to the conventional training method when reaching the same loss level at 300B tokens. The graph visually represents the substantial training time reduction that Gstack provides.
This figure shows the results of comparing four different growth operators for LLMs on eight standard NLP benchmarks. The operators are evaluated on their training loss and accuracy. The results show that the depthwise growth operator Gdirect (Gstack) significantly outperforms the other operators and a model trained from scratch in terms of speed and performance.
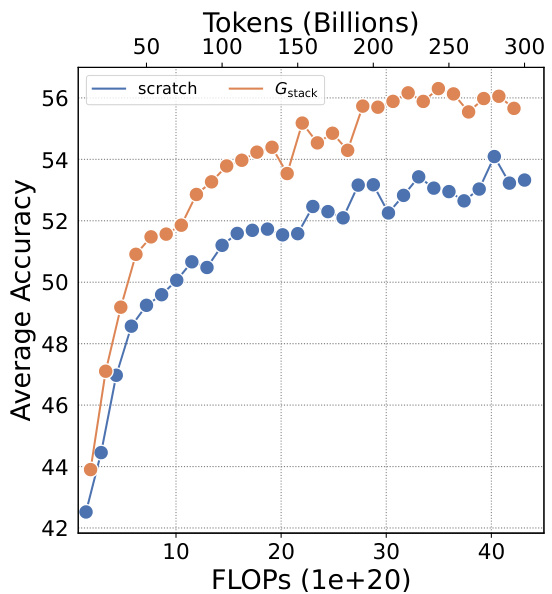
This figure shows the training loss and average accuracy of two 3B LLMs, one trained from scratch and the other using the Gstack method. The Gstack model converges faster, reaching the same loss with fewer tokens, demonstrating a significant speedup in training. The average accuracy across eight NLP benchmarks further supports the superior performance of the Gstack method.
This figure shows the training loss curves for two 7B LLMs: one trained from scratch and another trained using the Gdirect (Gstack) method. The plot demonstrates that Gstack achieves a significantly faster convergence rate than training from scratch. Specifically, at 300 billion tokens, Gstack shows a 54.6% speedup compared to the conventionally trained model, indicating substantial improvements in training efficiency.
This figure shows a comparison of the training loss curves for two 7-billion parameter LLMs. One model was trained from scratch, while the other utilized the Gdirect (Gstack) method, a depth-wise stacking operator that leverages pre-trained smaller models to accelerate training. The graph demonstrates that, at the 300 billion token mark, the Gstack model achieves a 54.6% speedup compared to the conventionally trained model, indicating that Gstack significantly accelerates training for large language models.
This figure shows the results of training 3B parameter LLMs using 300B tokens. It compares the training loss and average accuracy across several NLP benchmarks for two approaches: training from scratch and using the Gstack method. The results demonstrate that Gstack significantly outperforms training from scratch, achieving substantial speedups (48.6% and 54.5% at 180B and 240B tokens respectively).
This figure compares the training loss curves of two 7-billion parameter LLMs. One model was trained from scratch, while the other utilized the Gstack method, a depthwise stacking operator. The plot shows that Gstack achieves a 54.6% speedup in training time compared to the model trained from scratch, reaching the same loss level with significantly fewer training tokens.
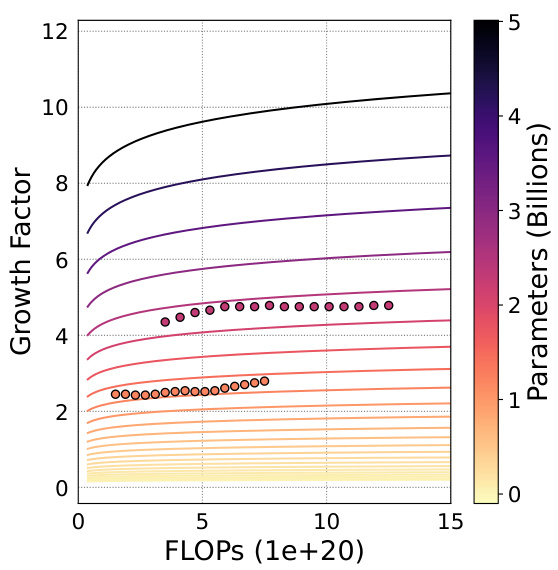
This figure visualizes the relationship between three key hyperparameters in the Gstack model growth technique: growth timing (d), computational budget (C), and number of parameters in the target model (N). It shows a contour plot where each curve represents a constant value of training loss (IsoFLOP). The lowest loss (optimal d) is indicated by the valley along each IsoFLOP curve. The plot suggests a logarithmic relationship between these hyperparameters, which is formalized in equation (2) in the paper.
This figure compares the training loss curves of two 7B LLMs. One model was trained from scratch, while the other used the Gstack method (a depth-wise stacking operator). The x-axis represents the number of tokens processed during training (in billions), and the y-axis represents the training loss. The figure shows that the Gstack model reaches the same training loss as the from-scratch model but with significantly fewer tokens (194B vs 300B), resulting in a 54.6% speedup. This demonstrates the efficiency gains achieved by Gstack during LLM pre-training.
This figure compares the training loss curves of two 7B Large Language Models (LLMs). One LLM was trained conventionally from scratch, while the other utilized the Gstack method, a depthwise stacking operator. The x-axis represents the number of training tokens (in billions), and the y-axis shows the training loss. The graph demonstrates that the Gstack model achieves the same training loss as the conventionally trained model but using significantly fewer tokens (194B vs 300B), resulting in a 54.6% reduction in training time.
This figure shows a comparison of the training loss curves for two 7B Large Language Models (LLMs). One LLM was trained from scratch, while the other used the Gstack method. The x-axis represents the number of tokens (in billions) used during training, and the y-axis represents the training loss. The Gstack method, a depthwise stacking operator, achieved a 54.6% speedup compared to training from scratch when reaching the same loss level at 300B tokens. This demonstrates the efficiency gains of the Gstack method in LLM pre-training.
This figure compares the training loss curves of two 7-billion parameter LLMs. One model was trained conventionally from scratch, while the other utilized the Gstack method, a depthwise stacking operator. The graph demonstrates that Gstack achieves a 54.6% speedup by converging to the same loss level with fewer training tokens (194B vs. 300B) than the model trained from scratch. This highlights Gstack’s efficiency in accelerating LLM pre-training.
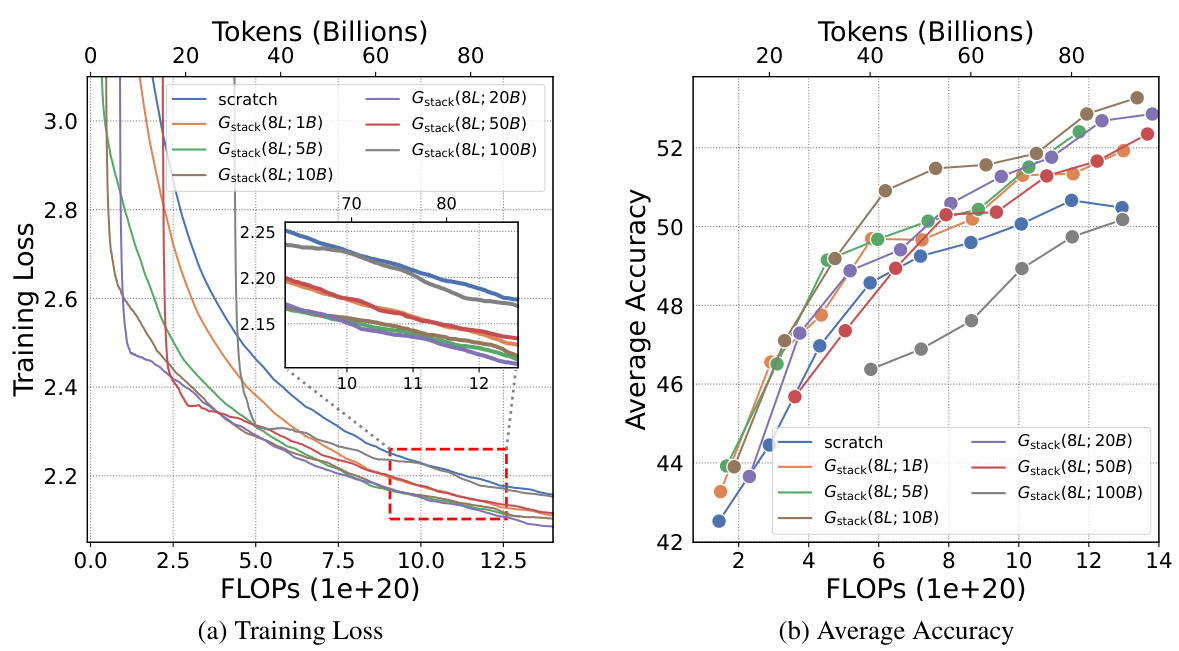
This figure shows the training loss and average accuracy across various NLP benchmarks for two 3B LLMs: one trained from scratch and the other using the Gstack method. The Gstack model demonstrates significantly lower training loss and higher accuracy than the model trained from scratch, indicating a substantial speedup in training time. Specific speedup percentages are shown for token counts of 180B and 240B, highlighting the significant performance improvement achieved using Gstack.
This figure demonstrates the training loss curves for two 7B LLMs. One model was trained conventionally from scratch, while the other used the Gstack method, a depthwise stacking operator. The Gstack model achieved a 54.6% speedup in training compared to the scratch model when both reached 300 billion tokens, indicating significant efficiency gains. The figure also shows the training FLOPS (floating point operations per second) for each model.
This figure shows the training loss and average accuracy on NLP benchmarks for two 7B LLMs: one trained from scratch and the other using the Gstack method. The Gstack model achieves the same loss with fewer tokens (194B vs 300B), resulting in a 54.6% speedup. The figure also shows the average accuracy on eight standard NLP benchmarks, demonstrating Gstack’s consistent superior performance.

This figure compares the training loss curves of two 7-billion parameter large language models (LLMs). One LLM was trained from scratch, while the other utilized the Gstack method, a depth-wise stacking operator. The plot shows that Gstack achieves the same loss with significantly fewer training tokens (194B instead of 300B), resulting in a 54.6% reduction in training time. This demonstrates the effectiveness of Gstack in accelerating LLM pre-training.
This figure shows the training loss and average accuracy of 3B LLMs trained with and without Gstack, across eight standard NLP benchmarks. The results demonstrate that using Gstack significantly improves training speed and model performance compared to training from scratch. Specifically, at 180B and 240B tokens, Gstack achieves a 48.6% and 54.5% speedup, respectively, while also improving average accuracy.
This figure compares the training loss curves of two 7-billion parameter language models (LLMs). One model was trained from scratch, while the other used the Gstack method, a technique that leverages smaller pre-trained models to accelerate the training of larger ones. The graph shows that, at the 300 billion token mark, the Gstack model achieves a 54.6% speedup compared to the model trained from scratch, indicating improved efficiency in LLM pre-training.
This figure presents the results of training 1.1B LLMs using four different growth operators: Gdirect, Glearn, Gzero, and Grandom. Both widthwise and depthwise growth are evaluated. The key finding is that depthwise stacking (Gdirect) significantly outperforms other methods and training from scratch across all eight NLP benchmarks (Lambada, ARC-c, ARC-e, Logiqa, PIQA, Sciq, Winogrande, Wikitext) and training loss. This highlights the effectiveness of depthwise stacking for accelerating LLM pre-training.
This figure compares the training loss curves of two 7-billion parameter large language models (LLMs). One LLM was trained from scratch, while the other utilized the Gstack method (a depthwise stacking operator). The x-axis represents the number of tokens processed during pre-training (in billions). The y-axis shows the training loss. The results show that the Gstack method achieves a significantly lower training loss than the conventional training method (54.6% faster at 300 billion tokens).
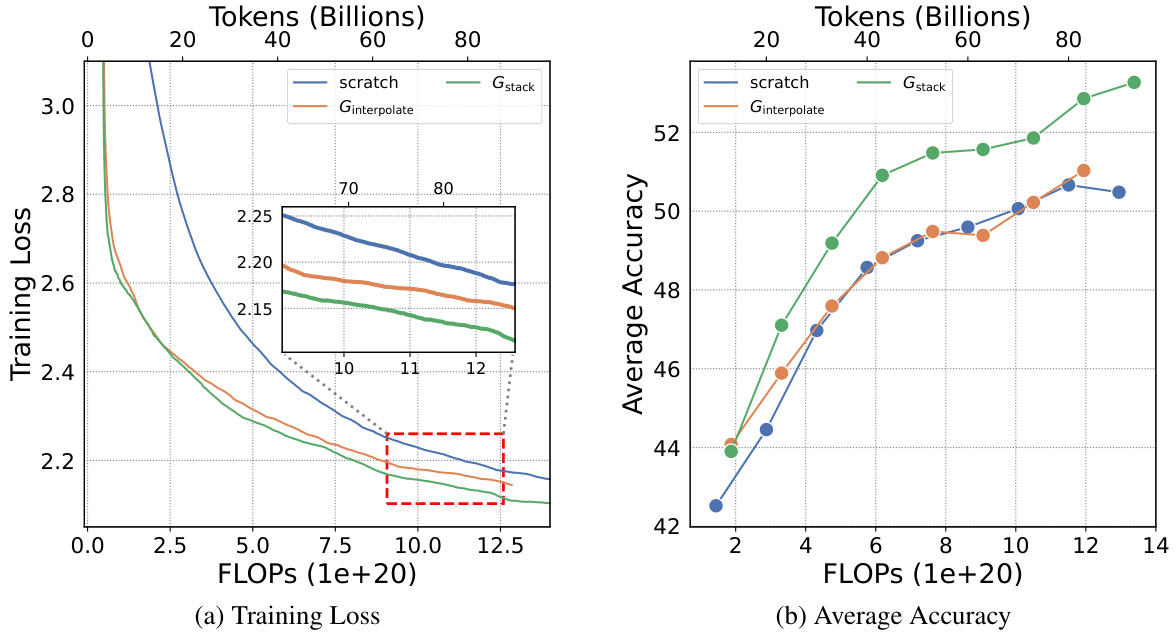
This figure compares the training loss curves for two 7B parameter LLMs. One model was trained from scratch, while the other used the Gstack method. The graph shows the training loss plotted against the number of tokens processed (in billions). The key takeaway is that Gstack achieves the same training loss as the scratch-trained model, but with significantly fewer tokens (194B tokens compared to 300B tokens), resulting in a 54.6% speedup in training time.
This figure shows the training loss curves for two 7B LLMs. One model was trained from scratch, while the other used the Gdirect (Gstack) method, which leverages smaller models to accelerate training. The graph demonstrates that the Gstack model converges to the same loss with fewer tokens (194B vs 300B), representing a 54.6% reduction in training time.
This figure presents the results of training 3B parameter LLMs using 300B tokens with and without Gstack. It shows that Gstack significantly improves both the training loss and average accuracy on various NLP benchmarks. Specifically, at 180B and 240B tokens, Gstack achieves a 48.6% and 54.5% speedup, respectively, compared to training from scratch.
This figure displays the training loss curves for two 7-billion parameter LLMs. One model was trained conventionally from scratch, while the other employed the Gstack method, a depthwise stacking operator for model growth. The graph demonstrates that the Gstack model reaches the same training loss as the conventionally trained model but using significantly fewer tokens (194B vs 300B). This translates to a 54.6% speedup in pre-training time, highlighting the efficiency gains of the Gstack method.
This figure shows a comparison of the training loss curves for two 7B Large Language Models (LLMs). One LLM was trained conventionally from scratch, while the other used the Gstack method, a depth-wise stacking operator. The x-axis represents the number of training tokens in billions, and the y-axis represents the training loss. The Gstack method significantly outperforms the conventional training method, achieving the same loss with fewer tokens (194B vs 300B). This translates to a 54.6% speedup in training time.
This figure compares the training loss curves for two 7-billion parameter large language models (LLMs) trained using different methods. One LLM was trained from scratch, while the other was trained using the Gstack method, which leverages smaller trained models to accelerate training. The figure shows that at the 300 billion token mark, the Gstack method achieves a 54.6% speedup in training compared to training from scratch.
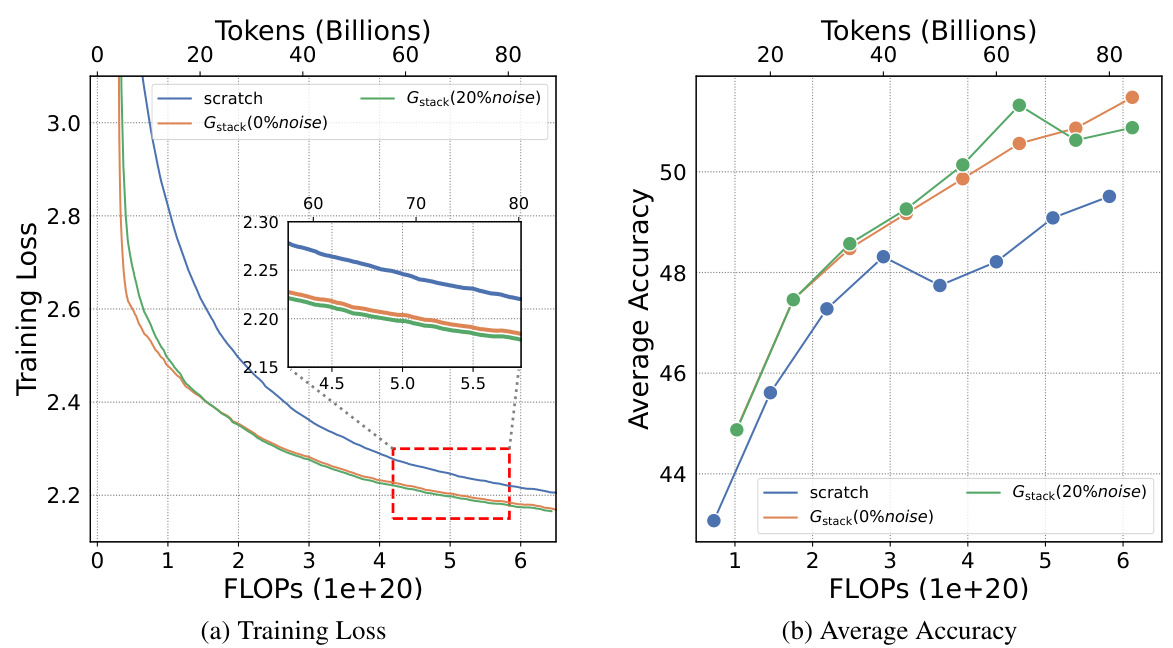
This figure compares the training loss curves for two 7-billion parameter large language models (LLMs). One LLM was trained from scratch, while the other utilized the Gstack method, a depthwise stacking growth operator. The x-axis represents the number of tokens (in billions) used for pre-training, and the y-axis shows the training loss. The figure demonstrates that Gstack achieves the same training loss as the model trained from scratch but using significantly fewer tokens (194B tokens instead of 300B), resulting in a 54.6% reduction in training time.
This figure shows a comparison of the training loss curves for two 7B LLMs: one trained from scratch and another trained using the Gstack method (a depthwise stacking operator). The Gstack model achieves a 54.6% speedup compared to the conventionally trained model at 300B tokens, demonstrating the efficiency gains provided by this model growth technique. The y-axis represents the training loss, and the x-axis represents the number of tokens used during training (in billions).
This figure compares the training loss curves of two 7B Large Language Models (LLMs). One LLM was trained conventionally from scratch, while the other used the Gstack method, a model growth technique. The graph shows that at 300 billion tokens, the Gstack model achieves the same loss as the scratch model but with significantly fewer training tokens (194B), representing a 54.6% speedup in training.
This figure compares the training loss curves of two 7B LLMs. One model was trained from scratch, while the other used the Gstack method (a depthwise stacking operator). The x-axis represents the number of tokens (in billions) used during pre-training, and the y-axis shows the training loss. The Gstack model achieves the same training loss as the scratch-trained model using significantly fewer tokens (194B vs 300B), demonstrating a 54.6% speedup in training.
More on tables

This table presents the results of instruction tuning on a 3B parameter model, comparing two methods: training from scratch with 400B tokens and using Gstack with 290B tokens. It evaluates the performance on several NLP benchmarks, including Lambada, ARC-c, ARC-e, Logiqa, PIQA, Sciq, Winogrande, and an average across these benchmarks. Higher scores indicate better performance. The results show that even with significantly fewer training tokens, the Gstack approach achieves comparable or better performance across various benchmarks.

This table shows the hyperparameters used for training different sized LLMs (410M, 1.1B, 3B, and 7B). The hyperparameters include the context length, batch size, maximum learning rate (max-LR), minimum learning rate (min-LR), warmup steps, and learning rate scheduler used in the training process. All models used a context length of 2048 and a batch size of 2M tokens. The learning rate scheduler used was cosine annealing for all models.

This table presents the results of instruction tuning experiments on a 3B parameter Language Model (LLM). It compares the performance of a model trained from scratch using 400B tokens with a model trained using the Gstack method with 290B tokens. The comparison is done with and without instruction tuning, across various NLP benchmarks including lambada, arc-c, arc-e, logiqa, piqa, sciq, winogrande and the average score of all benchmarks. Higher scores indicate better performance.
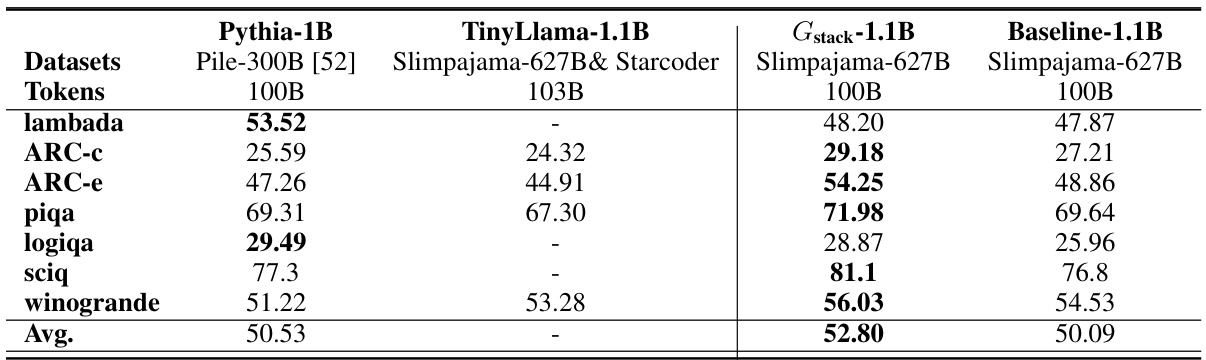
This table compares the performance of the Gstack-1.1B model with other open-source LLMs (Pythia-1B and TinyLlama-1.1B) and a baseline model trained from scratch. All models were trained on 100B tokens. The table shows the average accuracy scores achieved on eight standard NLP benchmarks. The results show that the Gstack model significantly outperforms the other models.
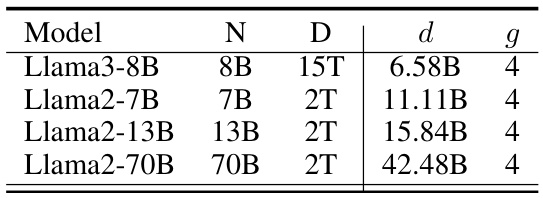
This table presents guidelines for using the Gstack model growth technique on different Llama models. It shows the recommended base model training token amount (d) and growth factor (g) for achieving optimal results. The growth factor remains constant at 4 across all models, while the optimal d increases with model size, reflecting the larger training data requirements for larger models.
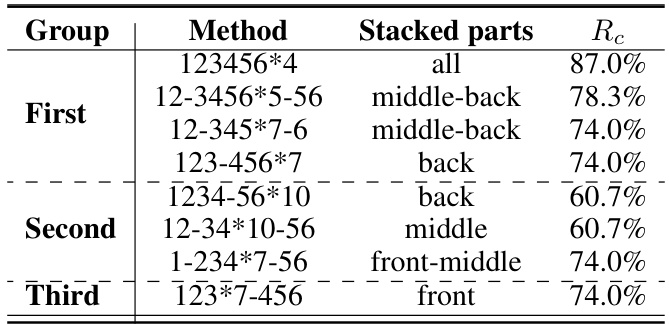
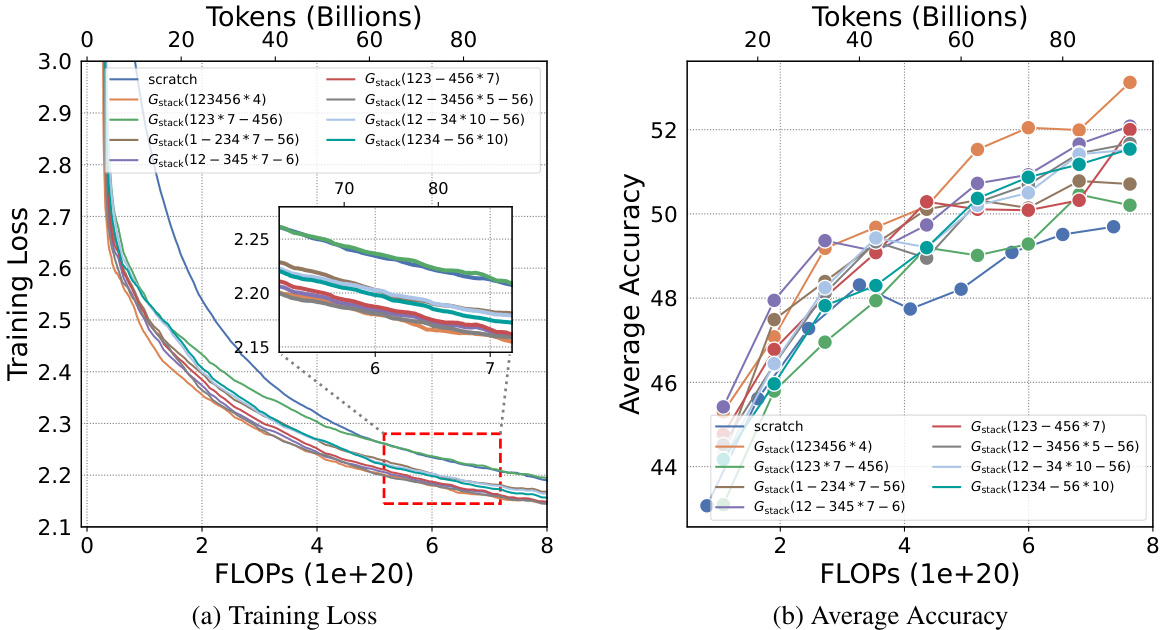
This table presents the results of an ablation study exploring different partial stacking strategies. It categorizes eight partial stacking methods into three groups based on their performance, indicating how much of the model’s inter-layer connections are retained (Rc). The groups highlight the impact of stacking on different parts of the model (all layers, middle-back layers, middle layers, back layers, front-middle layers, and front layers), showing a correlation between the connection retention rate (Rc) and performance.
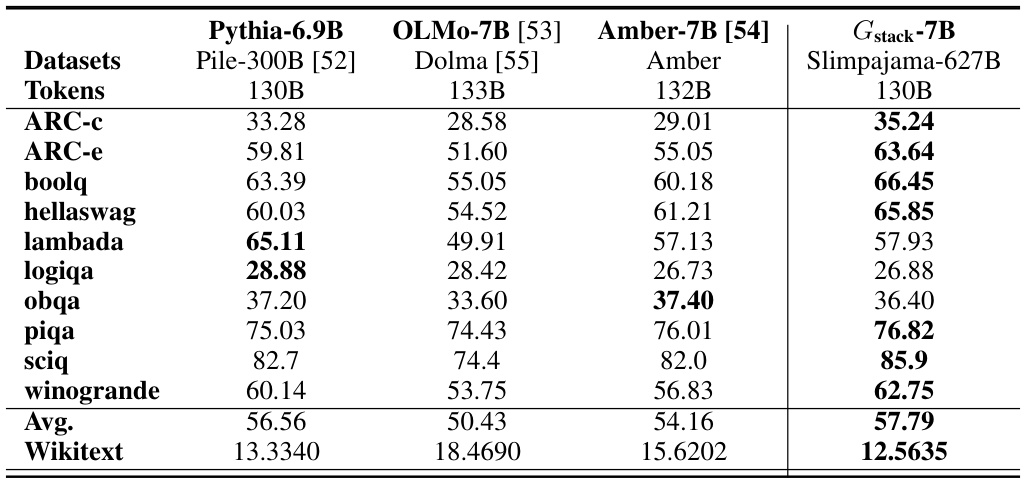
This table compares the performance of four different 7B parameter language models on eight standard NLP benchmarks using 130B tokens. The models compared are Pythia-6.9B, OLMo-7B, Amber-7B, and the Gstack-7B model introduced in this paper. The table shows the average accuracy scores for each model on each benchmark, allowing for a direct comparison of their performance. The Wikitext column presents perplexity scores, where lower values indicate better performance.

This table presents the evaluation results obtained using the Samba LLMs. It compares the performance of a model trained from scratch with 50B tokens against a model trained using the Gstack method with 47B tokens. The results are shown for various NLP benchmarks, including Lambada, ARC-c, ARC-e, Logiqa, PIQA, Sciq, and an average across all benchmarks. The table highlights the improved performance achieved using the Gstack method.
Full paper#