↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) is computationally expensive. Existing parameter-efficient methods primarily focus on modifying model weights, which may not be optimal. This research introduces Representation Finetuning (ReFT), a family of methods that learn task-specific interventions on hidden representations within a frozen LLM. This approach offers a potentially more effective way to adapt LLMs to specific tasks.
The study presents LoReFT (Low-rank Linear Subspace ReFT), a highly efficient ReFT method and its ablation DiReFT. Evaluated across several reasoning and instruction-following tasks, LoReFT consistently outperforms other parameter-efficient techniques. LoReFT achieves state-of-the-art results while using 15-65x fewer parameters than comparable methods. This demonstrates the effectiveness and efficiency of ReFT, offering a promising new direction for LLM adaptation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel and efficient approach to fine-tuning large language models, addressing the high computational cost of traditional methods. Its findings challenge existing parameter-efficient techniques and open new avenues for research in model interpretability and control. The proposed method offers a strong alternative, particularly relevant in resource-constrained settings, making it highly impactful for researchers and practitioners.
Visual Insights#
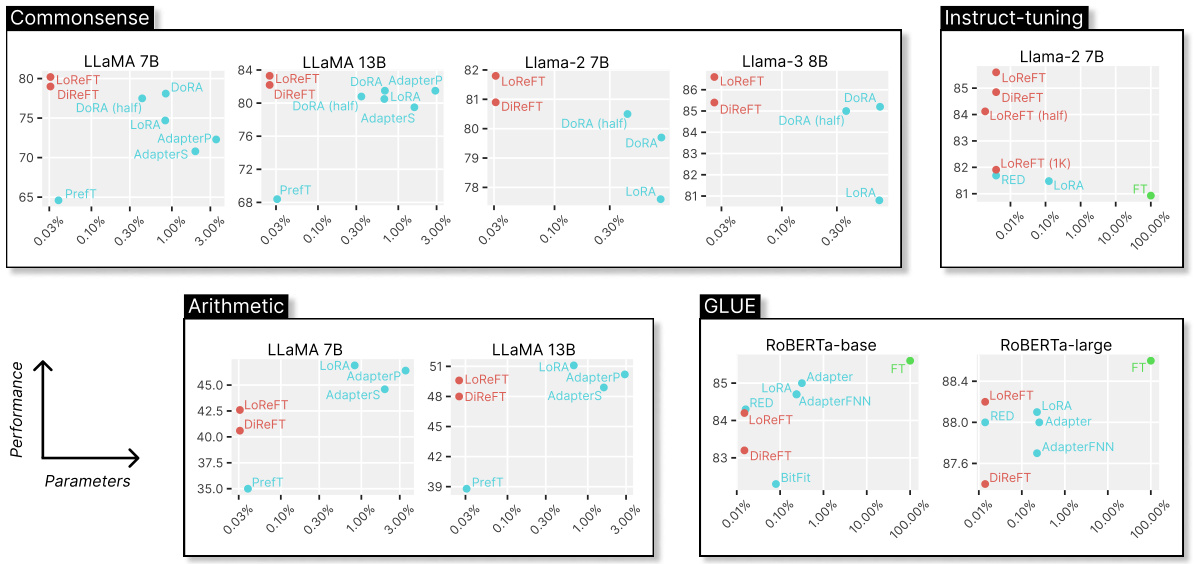
This figure compares the performance and parameter efficiency of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four benchmarks: commonsense reasoning, arithmetic reasoning, instruction tuning, and GLUE. It shows that LoReFT achieves competitive performance while using significantly fewer parameters than other PEFTs, especially for larger language models. The performance is measured on the y-axis while the number of trainable parameters relative to the base model’s total number of parameters is shown on the x-axis. ‘FT’ represents full finetuning (not a PEFT or ReFT method).
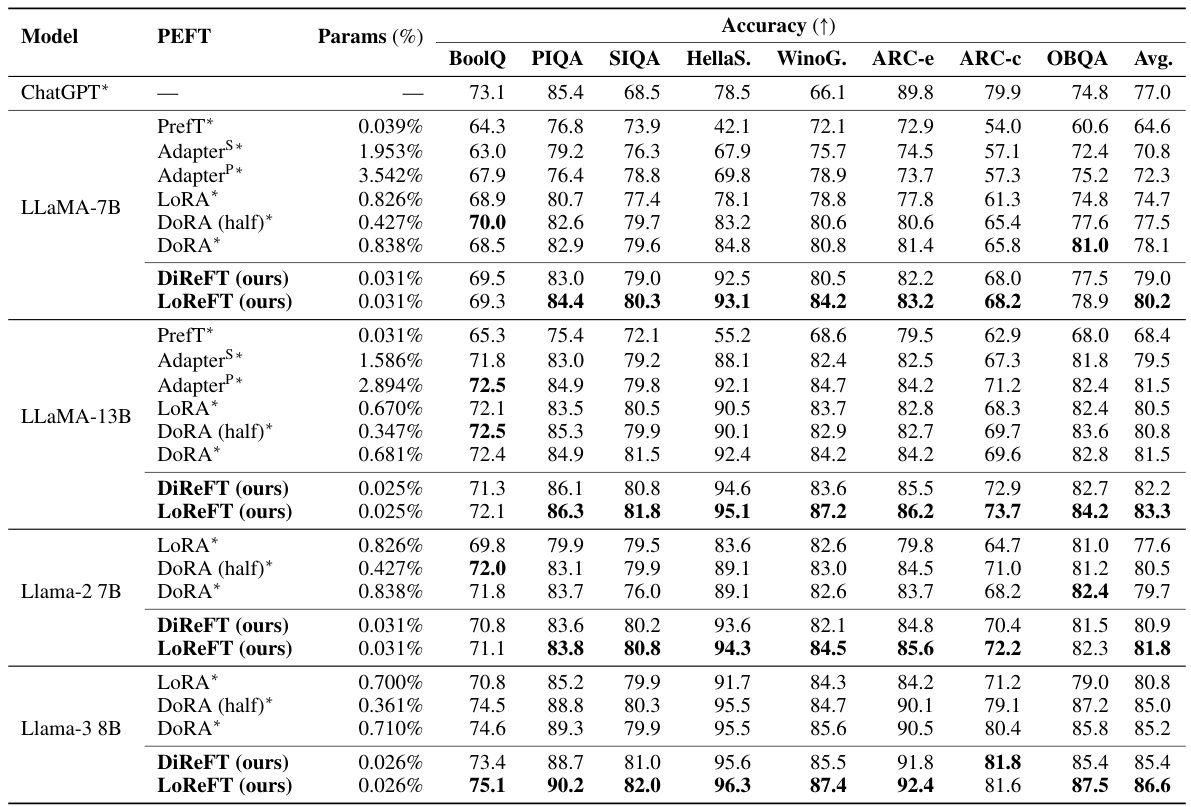
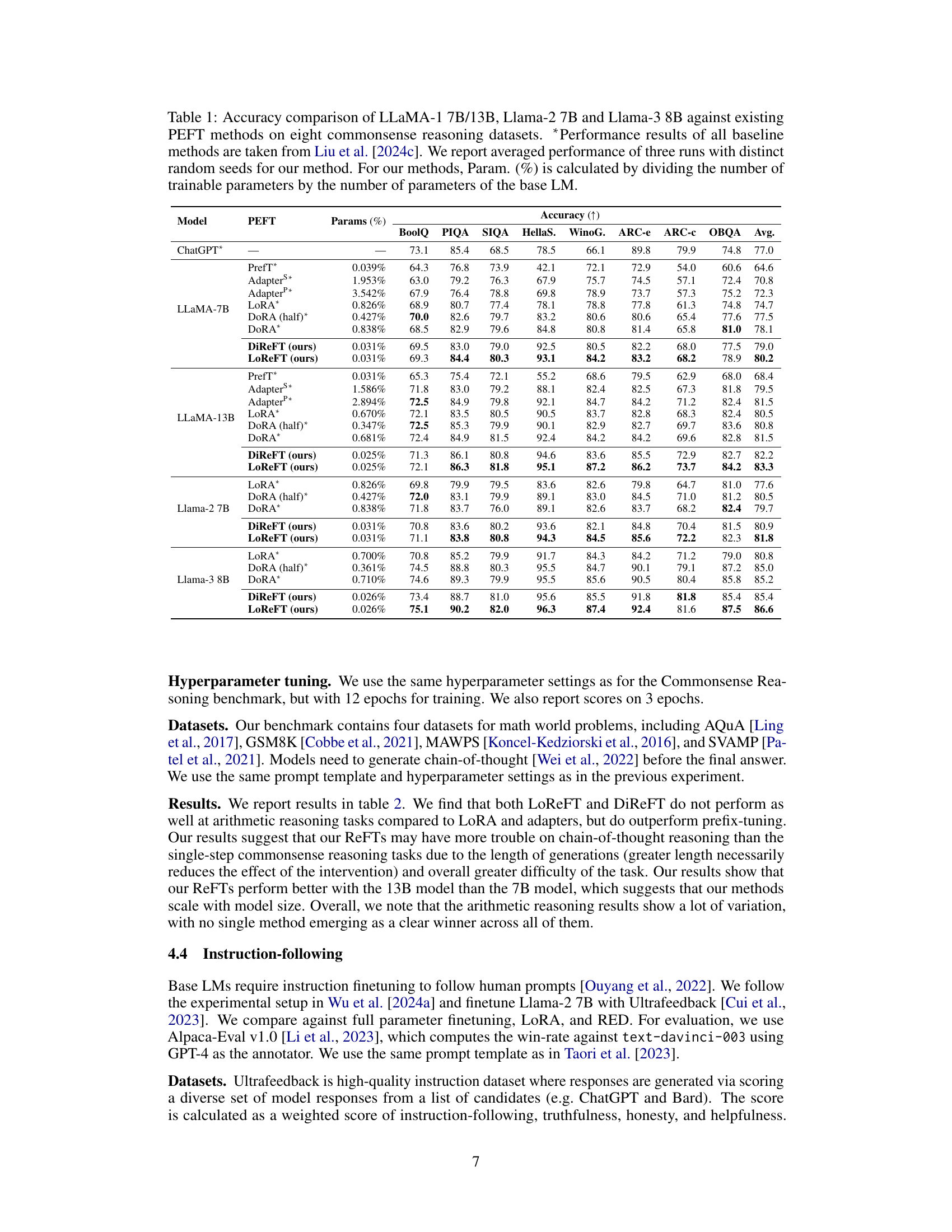
This table compares the performance of Low-rank Linear Subspace ReFT (LoReFT) and its ablation (DiReFT) against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets. It shows the accuracy achieved by each method, along with the percentage of parameters trained relative to the base language model. The results demonstrate LoReFT’s superior performance and efficiency compared to existing PEFTs.
In-depth insights#
ReFT: Overview#
ReFT, or Representation Finetuning, offers a novel approach to parameter-efficient fine-tuning of large language models (LLMs). Unlike traditional methods that modify model weights, ReFT directly manipulates hidden representations, learning task-specific interventions on these representations while leaving the base model frozen. This approach leverages the rich semantic information encoded within representations, potentially leading to more effective and interpretable adaptation. A key instance of ReFT is LoReFT (Low-rank Linear Subspace ReFT), which achieves high efficiency by operating within a low-rank subspace of the representation. LoReFT’s parameter efficiency surpasses existing methods like LoRA by a significant margin. The flexibility of ReFT allows it to be applied to various downstream tasks such as commonsense and arithmetic reasoning, instruction-tuning, and natural language understanding, consistently demonstrating strong performance in experimental evaluations. The simplicity and versatility of ReFT make it a promising alternative to weight-based PEFT methods for adapting LLMs to new tasks while preserving computational resources.
LoReFT Method#
The LoReFT (Low-rank Linear Subspace ReFT) method is a novel parameter-efficient finetuning technique for large language models. Instead of modifying model weights directly, LoReFT learns task-specific interventions on hidden representations within a low-rank linear subspace. This approach is significantly more parameter-efficient than existing methods like LoRA, requiring 15-65 times fewer parameters while achieving comparable or even superior performance. LoReFT leverages insights from interpretability research showing that representations encode rich semantic information, making targeted representation editing a powerful alternative to weight modification. The core of LoReFT involves learning a low-rank projection matrix (R) and a linear transformation (W and b) to manipulate the representations within the subspace. This design allows LoReFT to make efficient, targeted adjustments to the model’s behavior without altering the base model weights, maintaining the efficiency and simplicity of the original model at inference time. A key advantage of LoReFT is its compatibility with existing PEFTs; it functions as a drop-in replacement, making adoption straightforward. The efficiency and strong performance demonstrated by LoReFT highlight the potential of representation finetuning as a highly promising direction for efficient and powerful LLM adaptation.
Empirical Results#
The empirical results section of a research paper is crucial for demonstrating the validity and effectiveness of the proposed methods. A strong empirical results section will present clear and concise findings, often with supporting visualizations like graphs or tables. It should compare the new approach against relevant baselines, highlighting improvements in performance metrics while also acknowledging any limitations. The discussion should be balanced, addressing not only the successes but also potential reasons for any shortcomings, perhaps due to dataset limitations or methodological choices. Statistical significance should be rigorously addressed, ensuring that reported improvements are not merely due to chance. The overall presentation should be tailored to the target audience, emphasizing the practical implications of the results and their contribution to the broader field.
Parameter Efficiency#
Parameter efficiency in large language models (LLMs) is crucial due to the substantial computational resources required for training and inference. This paper investigates representation finetuning (ReFT) as a parameter-efficient alternative to existing methods. Unlike weight-based approaches, ReFT modifies hidden representations directly, potentially offering a more powerful and interpretable way to adapt LLMs. The core idea is to learn task-specific interventions that manipulate a small subset of model representations, keeping the base model frozen. Low-rank Linear Subspace ReFT (LoReFT) is presented as a strong instance of this family, demonstrating a superior balance of efficiency and performance compared to other state-of-the-art methods across multiple benchmarks. The paper highlights that the interventions are significantly more parameter-efficient (15-65 times fewer parameters compared to LoRA), while achieving competitive or surpassing state-of-the-art results. This makes ReFT a promising direction for future research in adapting large LLMs for various tasks with improved efficiency and interpretability.
Future Work#
The paper’s ‘Future Work’ section would ideally expand on several key areas. Exploring ReFT’s effectiveness across a wider range of model architectures beyond the LLaMA family is crucial. A thorough investigation into automating the hyperparameter search process is also necessary, as this is currently a significant limitation. Further research could delve into understanding the mechanisms underlying ReFT’s success, potentially through theoretical analysis or more in-depth empirical studies. Addressing the scalability challenges associated with ReFT’s application to larger models is important for practical deployment. Finally, investigating how ReFT interacts with other parameter-efficient methods and its potential for personalization would provide valuable insights into its flexibility and broader applicability. The study of compositional interventions with ReFT, allowing multiple, coordinated interventions, deserves further exploration.
More visual insights#
More on figures
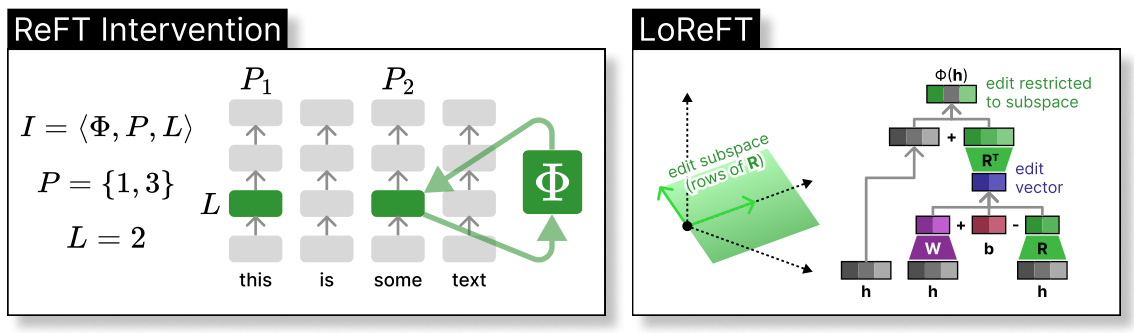
This figure illustrates the ReFT intervention and LoReFT methods. The left panel shows a general ReFT intervention where an intervention function is applied to hidden representations at specific positions in a layer. The right panel illustrates the LoReFT method, a specific instance of ReFT, which uses a low-rank projection matrix to modify hidden representations within a linear subspace. It shows how a rank-2 LoReFT modifies 3-dimensional hidden representations by applying an edit vector to the subspace.

This figure compares the performance of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four NLP benchmarks using different language models (LLaMA, Llama-2, Llama-3, and RoBERTa). It shows that LoReFT achieves comparable or superior performance while using significantly fewer parameters than other PEFTs, particularly when used with larger language models.

This figure compares the performance and the number of parameters of LoReFT against other PEFT methods (Parameter-Efficient Fine-Tuning) on four different NLP benchmarks using various language models like LLaMA, Llama-2, Llama-3, and RoBERTa. It shows that LoReFT achieves comparable or superior performance while using significantly fewer parameters, especially with larger language models. Full finetuning (FT) is included as a baseline for comparison but is not a PEFT method.

This figure compares the performance of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four different benchmarks (Commonsense, Arithmetic, Instruction-tuning, and GLUE). The x-axis represents the number of parameters used (as a percentage of the base model’s parameters), while the y-axis represents the performance achieved. The figure demonstrates that LoReFT achieves competitive or superior performance while using significantly fewer parameters than other PEFT methods, particularly on larger models.

This figure compares the performance and parameter count of LoReFT against other PEFT methods across four different NLP benchmarks using various language models. It shows that LoReFT achieves competitive or better performance while using significantly fewer parameters, especially when applied to large models.

This figure compares the performance and parameter count of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four different benchmarks and model sizes (LLaMA, Llama-2, Llama-3, and RoBERTa). It shows that LoReFT achieves state-of-the-art or competitive performance while using significantly fewer parameters than other PEFTs, particularly on the larger language models.

The figure compares the performance and the number of parameters used by LoReFT and other parameter-efficient fine-tuning (PEFT) methods across four benchmarks using different language models (LLaMA, Llama-2, Llama-3, and RoBERTa). LoReFT consistently achieves competitive or better performance while using significantly fewer parameters than other PEFTs, especially for larger language models.

This figure compares the parameter efficiency and performance of LoReFT against other PEFT methods across four different benchmarks using various language models. It showcases LoReFT’s ability to achieve competitive or even state-of-the-art results while using significantly fewer parameters than existing methods, especially when applied to larger models. The benchmarks include commonsense reasoning, arithmetic reasoning, instruction tuning, and GLUE.

The figure compares the performance and parameter count of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four NLP benchmarks using different language models (LLaMA, Llama-2, Llama-3, and RoBERTa). LoReFT consistently achieves state-of-the-art performance while using significantly fewer parameters than existing PEFT methods, highlighting its efficiency and effectiveness, particularly with larger models.

This figure compares the parameter efficiency and performance of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four different NLP benchmarks (Commonsense, Arithmetic, Instruction-tuning, and GLUE) and using four different language models (LLaMA, Llama-2, Llama-3, and RoBERTa). The results show that LoReFT achieves competitive or better results than other PEFTs while using significantly fewer parameters, especially for larger language models. The y-axis represents performance, and the x-axis represents the number of parameters used (as a percentage of the total parameters in the base model).
This figure compares the parameter efficiency and performance of LoReFT against other PEFT methods (Parameter-Efficient Fine-Tuning) on four different NLP benchmarks using various language models (LLaMA, Llama-2, Llama-3, and RoBERTa). The x-axis represents the percentage of parameters trained relative to the full model, showing LoReFT’s significant parameter efficiency. The y-axis shows the performance on each benchmark. The results demonstrate that despite using drastically fewer parameters, LoReFT achieves performance comparable to, or even better than, existing PEFT methods, particularly with larger language models.

This figure compares the performance and parameter efficiency of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four different benchmarks and model sizes. LoReFT consistently achieves competitive results despite using significantly fewer parameters, demonstrating its efficiency, especially with larger models.

This figure compares the performance and the number of parameters used by LoReFT and other PEFT methods across four different NLP benchmarks and model sizes. It demonstrates that LoReFT achieves performance comparable to other PEFT methods while using significantly fewer parameters, with the difference particularly pronounced for larger models. The figure highlights LoReFT’s parameter efficiency.

This figure compares the performance and parameter efficiency of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four different benchmarks (Commonsense, Arithmetic, Instruction-tuning, and GLUE) and various language models (LLaMA, Llama-2, Llama-3, and RoBERTa). It demonstrates that LoReFT achieves competitive or superior performance while using significantly fewer parameters than other PEFT methods, especially when applied to larger language models. The y-axis represents performance, and the x-axis shows the number of parameters used (as a percentage of the total model parameters).

This figure compares the parameter efficiency and performance of LoReFT against other parameter-efficient fine-tuning (PEFT) methods across four NLP benchmarks. The results show LoReFT achieves competitive or superior performance while using significantly fewer parameters, particularly beneficial for larger language models.

This figure compares LoReFT’s performance against other parameter-efficient fine-tuning (PEFT) methods across four benchmarks using different language models (LLaMA, Llama-2, Llama-3, and RoBERTa). It shows that LoReFT, despite using significantly fewer parameters, achieves comparable or superior performance to other PEFTs, especially when using larger language models.
More on tables
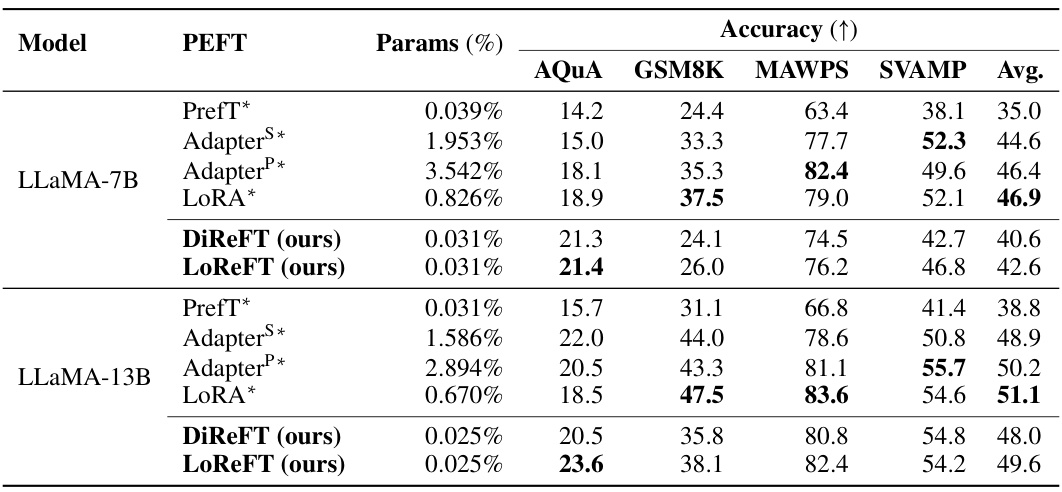
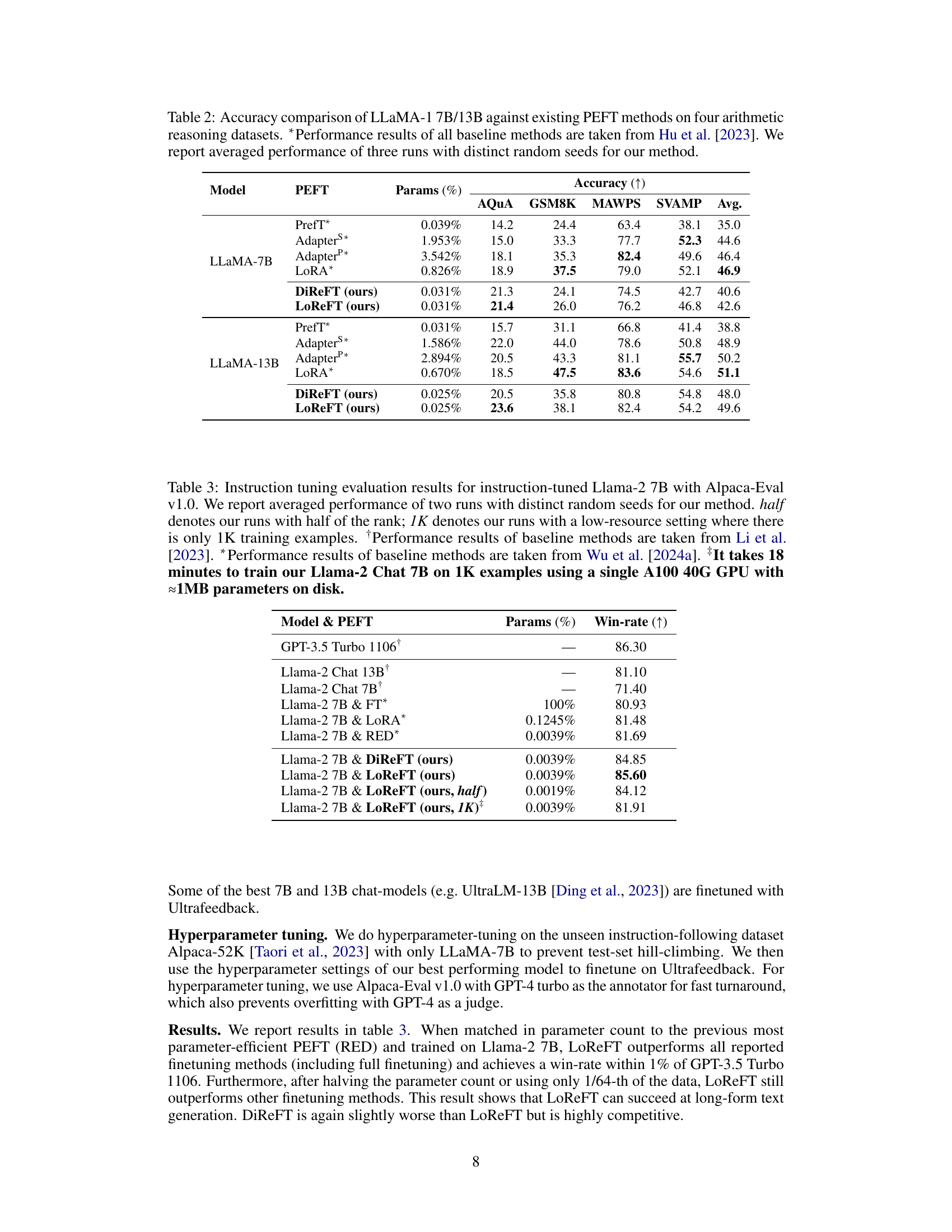
This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods, including LoReFT and DiReFT (the methods introduced in the paper), against existing PEFTs on four arithmetic reasoning datasets using LLaMA-1 7B and 13B models. The results show accuracy and the percentage of parameters trained for each method. The performance is averaged over three runs with different random seeds, highlighting the consistency and reliability of LoReFT and DiReFT. The baseline results are taken from a previous study by Hu et al. (2023).
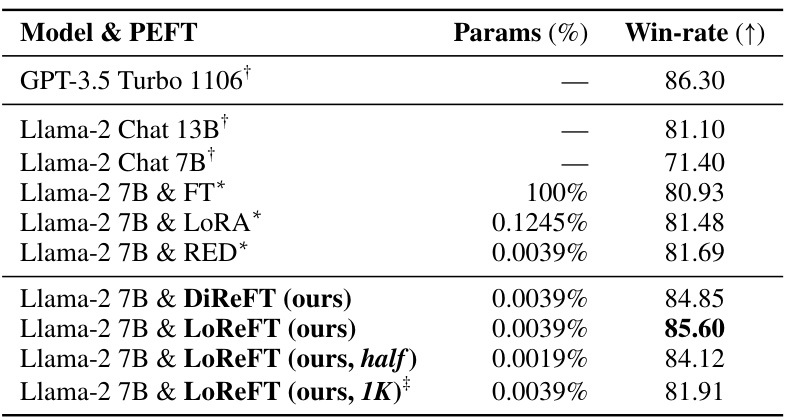
This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods and full finetuning (FT) on an instruction-following task using the Llama-2 7B language model. The win-rate is measured using Alpaca-Eval v1.0, comparing against text-davinci-003 using GPT-4 as the annotator. The table also shows the number of parameters used for each method. Ablation studies are included with LoReFT using half the rank and only 1K training examples.
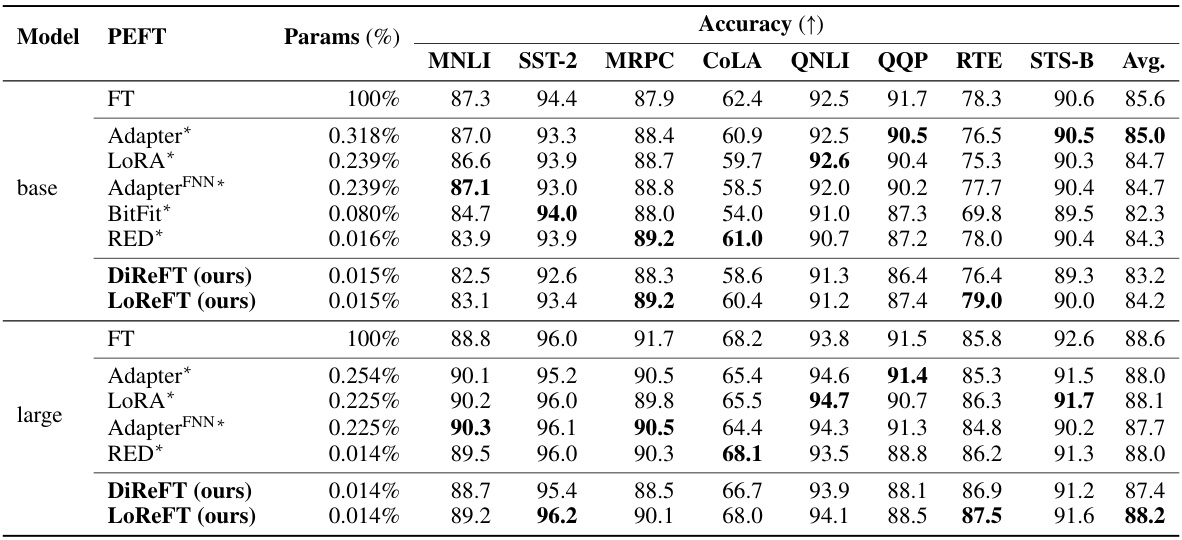
This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (LLaMA-1 7B/13B, Llama-2 7B, and Llama-3 8B). It shows the accuracy achieved by each method, along with the percentage of parameters trained relative to the base model size. The results highlight LoReFT’s ability to achieve competitive or superior performance while using significantly fewer parameters than other PEFTs.

This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (7B, 13B, and 8B). It shows accuracy scores for each method, along with the percentage of parameters trained relative to the total number of parameters in the base model. The results from Liu et al. (2024c) are included for comparison.

This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods, including the proposed Low-rank Linear Subspace ReFT (LoReFT) and its ablation DiReFT, on eight commonsense reasoning datasets using three different LLaMA models (7B, 13B, and 8B). It shows the accuracy achieved by each PEFT method relative to the number of parameters used (as a percentage of the total model parameters). The results highlight LoReFT’s superior performance and efficiency compared to existing PEFTs.
This table compares the performance of the proposed LoReFT and DiReFT methods against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using different LLaMA models. The table shows accuracy, the percentage of parameters trained, and highlights that LoReFT and DiReFT achieve state-of-the-art performance with significantly fewer parameters compared to existing PEFTs. The results from Liu et al. (2024c) are used as baselines for other PEFT methods.

This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using various LLaMA models. It shows the accuracy achieved by each method, along with the percentage of parameters trained relative to the base model size. The results from Liu et al. (2024c) are included for comparison. The table highlights LoReFT’s performance gains and parameter efficiency.
This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using different LLaMA models. It shows accuracy scores for each dataset, along with the percentage of trainable parameters relative to the total number of parameters in the base LLaMA models. The results from Liu et al. (2024c) are included for comparison.
This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using different LLaMA models. It shows accuracy results for each dataset, along with the percentage of parameters trained for each method. The results highlight LoReFT’s performance compared to existing PEFTs such as Prefix-tuning, Adapters, LoRA, and DoRA.
This table compares the performance of the proposed Low-rank Linear Subspace ReFT (LoReFT) method and its variant, DiReFT, against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models. It shows the accuracy achieved by each method, along with the percentage of parameters trained relative to the full model size. The results highlight LoReFT’s effectiveness with fewer parameters.
This table compares the accuracy of LLaMA-1 7B/13B, Llama-2 7B, and Llama-3 8B language models when fine-tuned using LoReFT against existing parameter-efficient fine-tuning (PEFT) methods across eight commonsense reasoning datasets. It shows the accuracy achieved by each method, along with the percentage of parameters trained relative to the total number of parameters in the base language model. The results from existing PEFT methods are taken from a previous study by Liu et al. (2024c). The table highlights LoReFT’s performance in comparison to other PEFTs, showing it achieves competitive results while using significantly fewer parameters.
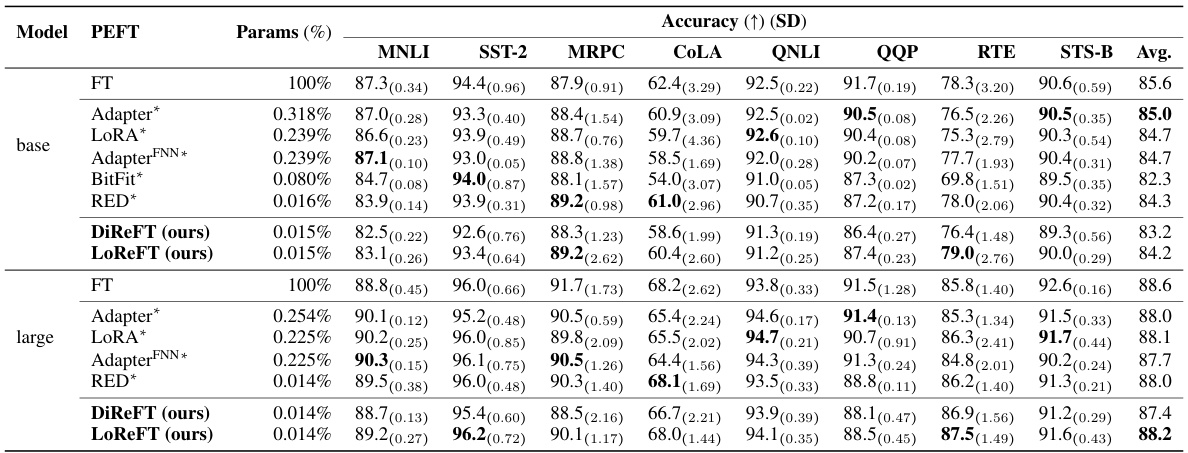
This table compares the performance of LoReFT and DiReFT against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using LLaMA 1 7B/13B, Llama-2 7B and Llama-3 8B language models. It shows accuracy scores and the percentage of parameters trained for each method. The results highlight LoReFT’s superior performance and efficiency compared to existing PEFTs.
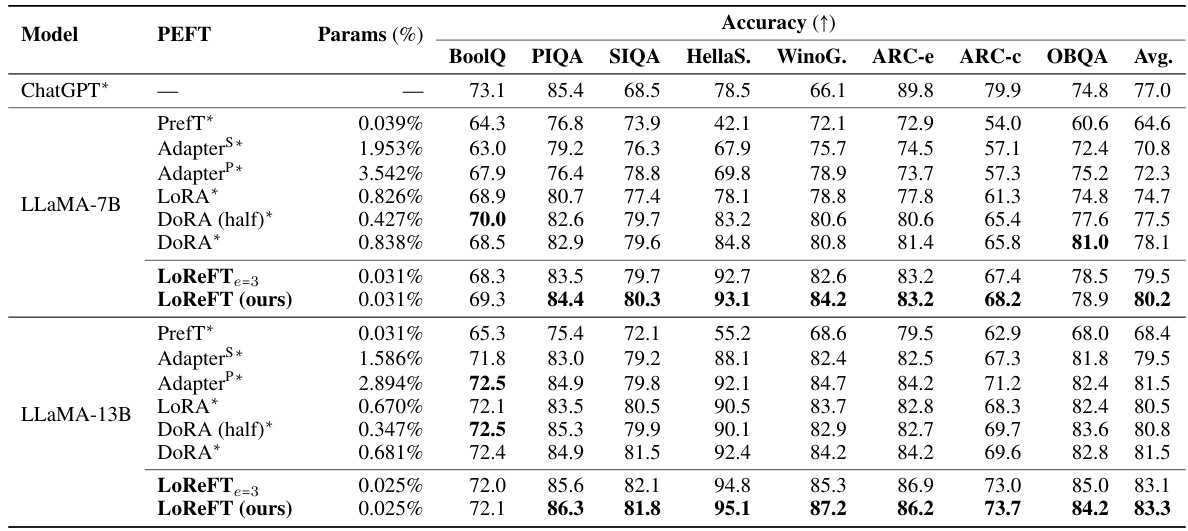
This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (7B, 13B, and 8B). It shows the accuracy achieved by each method and its relative parameter efficiency (percentage of parameters trained relative to the base model). The results highlight LoReFT’s superior performance and efficiency compared to other PEFTs. Note that the baseline results for other methods are taken from a different source, Liu et al. [2024c].
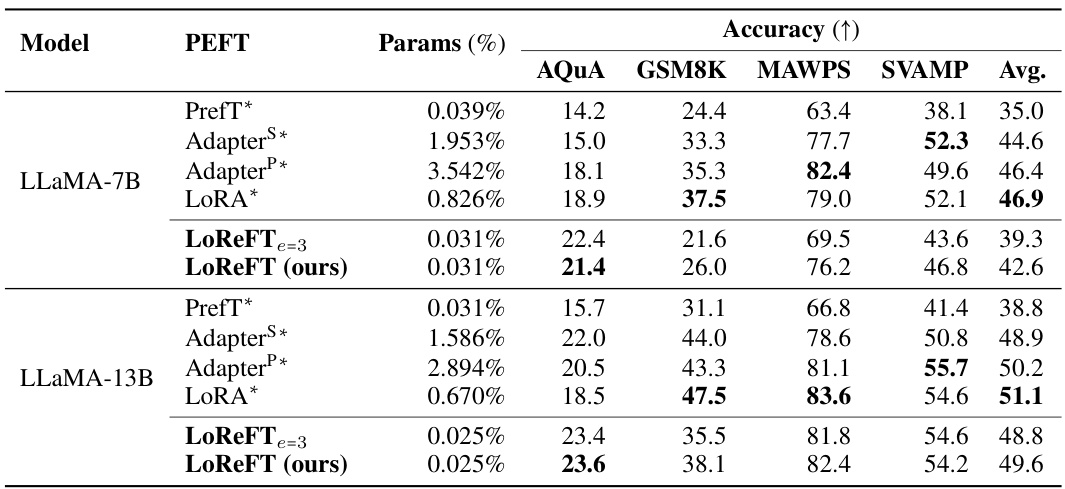
This table compares the performance of LoReFT and DiReFT against other Parameter-Efficient Fine-Tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (LLaMA-1 7B, LLaMA-1 13B, Llama-2 7B, and Llama-3 8B). It shows the accuracy achieved by each method and the percentage of parameters trained relative to the full model size. The results from other PEFT methods are cited from Liu et al. (2024c).
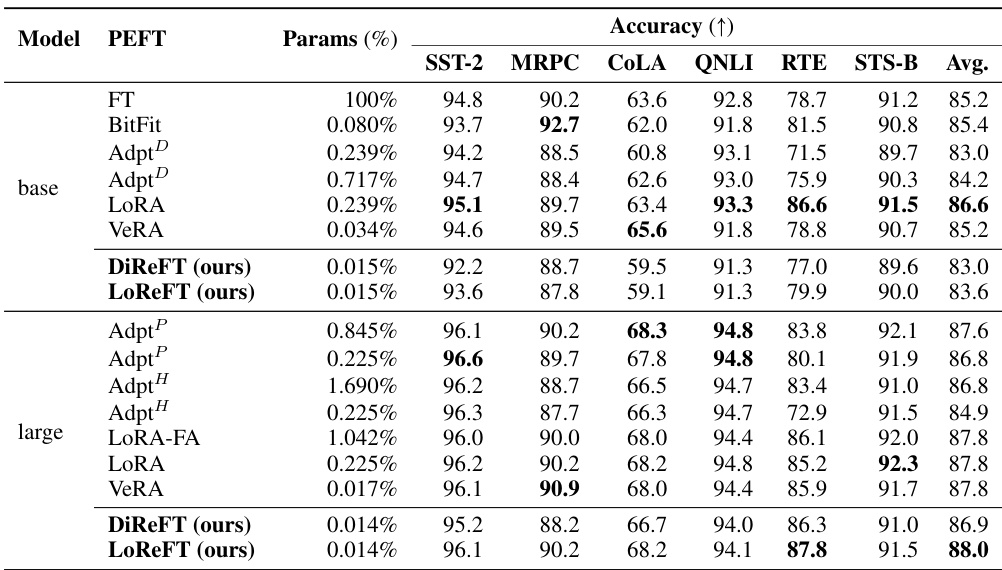
This table compares the performance of LoReFT and DiReFT against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (LLaMA-1 7B, LLaMA-1 13B, Llama-2 7B, and Llama-3 8B). It shows the accuracy achieved by each method and the percentage of parameters trained relative to the full model size. The results from other PEFT methods are taken from Liu et al. (2024c).
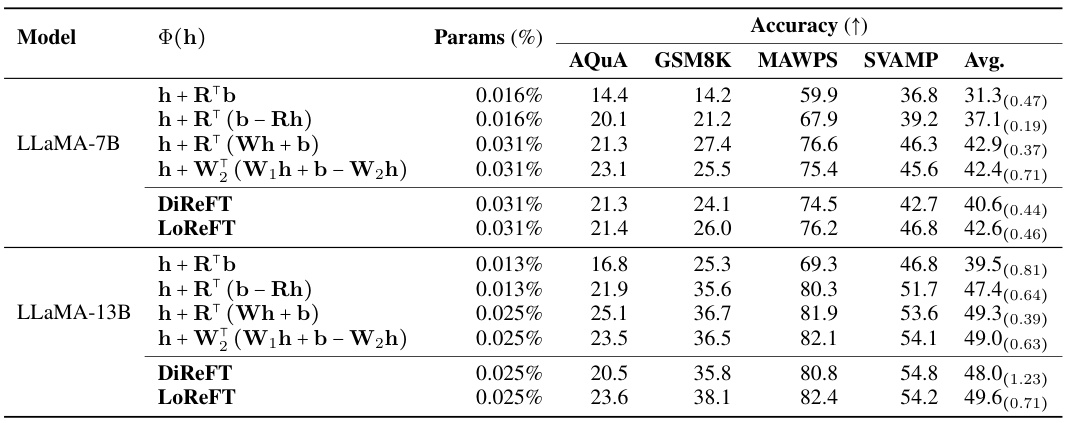
This table compares the performance of LLaMA 1 7B/13B, Llama-2 7B, and Llama-3 8B language models fine-tuned using LoReFT against other parameter-efficient finetuning (PEFT) methods on eight commonsense reasoning datasets. It shows accuracy results, along with the percentage of parameters trained for each method. The results from other PEFT methods are sourced from Liu et al., 2024c. The study used three different random seeds for LoReFT and reports the average performance.

This table compares the performance of different parameter-efficient fine-tuning (PEFT) methods and the proposed Representation Finetuning (ReFT) methods on eight commonsense reasoning datasets using LLaMA-1 7B/13B, Llama-2 7B and Llama-3 8B language models. It shows accuracy scores for each dataset and method, along with the percentage of trainable parameters relative to the base model size. The results highlight the efficiency and performance of the ReFT methods.

This table compares the performance of LoReFT and other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets using three different LLaMA models (LLaMA-1 7B, LLaMA-1 13B, Llama-2 7B, and Llama-3 8B). The table shows accuracy scores for each dataset and method, along with the percentage of trainable parameters relative to the base model’s total parameters. It highlights the performance and parameter efficiency of LoReFT compared to other PEFTs.

This table compares the performance of LLaMA-1 7B/13B, Llama-2 7B, and Llama-3 8B language models fine-tuned using LoReFT against other parameter-efficient fine-tuning (PEFT) methods on eight commonsense reasoning datasets. The table shows accuracy scores for each model and method, along with the percentage of parameters trained relative to the base model’s total parameters. Results from Liu et al. (2024c) are used as a baseline for comparison. LoReFT’s performance is averaged over three runs with different random seeds to ensure reliability.
Full paper#