↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Generative Language Models (GLMs) often produce inaccurate or ‘hallucinated’ information, hindering their use in critical applications. Current risk mitigation methods, like selective prediction, struggle with GLMs due to the lack of an appropriate correctness metric for evaluating generated text. This is because multiple valid answers exist for many questions, making simple metrics like exact match unreliable.
The paper tackles this issue by proposing two selective generation algorithms (SGensup and SGenSemi). These algorithms use textual entailment to evaluate answer correctness and control the false discovery rate. SGenSup uses supervised learning with entailment-labeled data, while SGenSemi leverages unlabeled data through pseudo-labeling and conformal prediction. SGenSemi further introduces ’neuro-selection functions’, allowing for a more general class of selection functions and improved efficiency. The authors demonstrate the efficacy of their approach on various GLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on controllable language models and trustworthy AI. It introduces a novel semi-supervised approach to selective generation, improving efficiency and offering theoretical guarantees on controlling the false discovery rate. This work opens new avenues for mitigating the hallucination problem in large language models and advances the field of certified risk control methods.
Visual Insights#
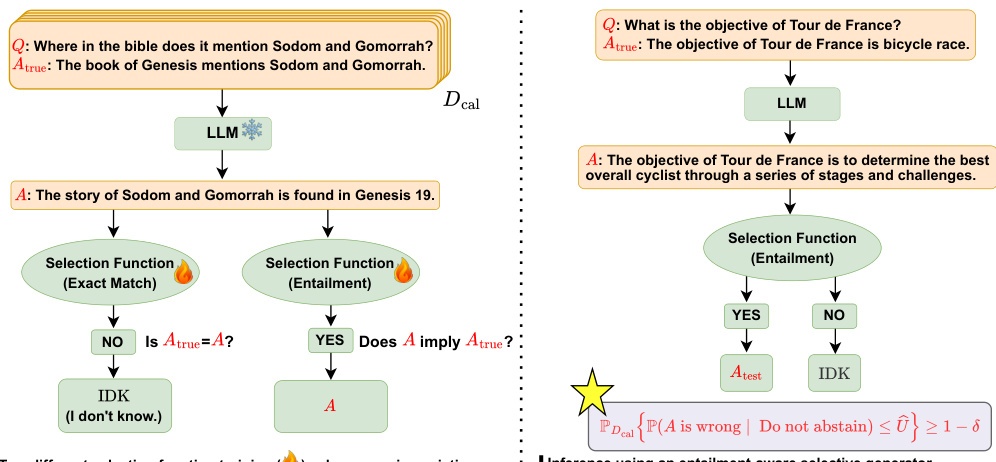
This figure provides a high-level overview of the proposed method for selective generation in language models. It illustrates two example question-answer scenarios, highlighting the difference between using exact match and entailment-based selection functions. The left side shows a case where an exact match is used for evaluation, while the right side uses textual entailment. The key concept is that the model can abstain from answering if it is uncertain about the correctness of its response. This uncertainty is evaluated through textual entailment to ensure a controlled false discovery rate, offering a probabilistic guarantee of accuracy.
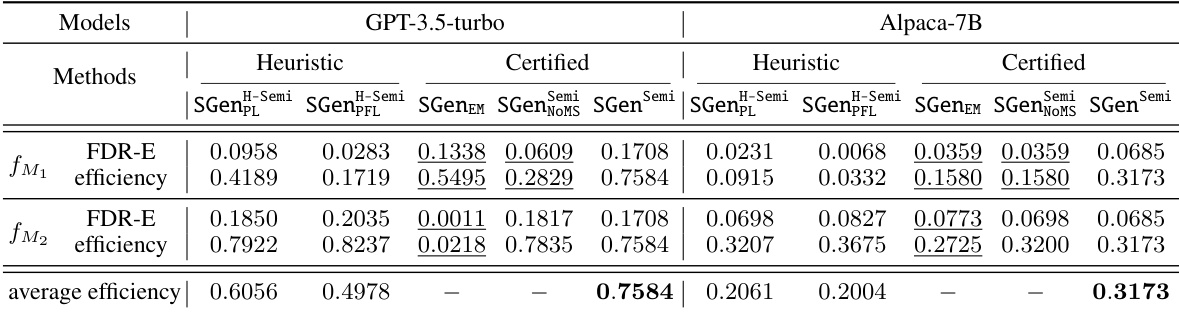
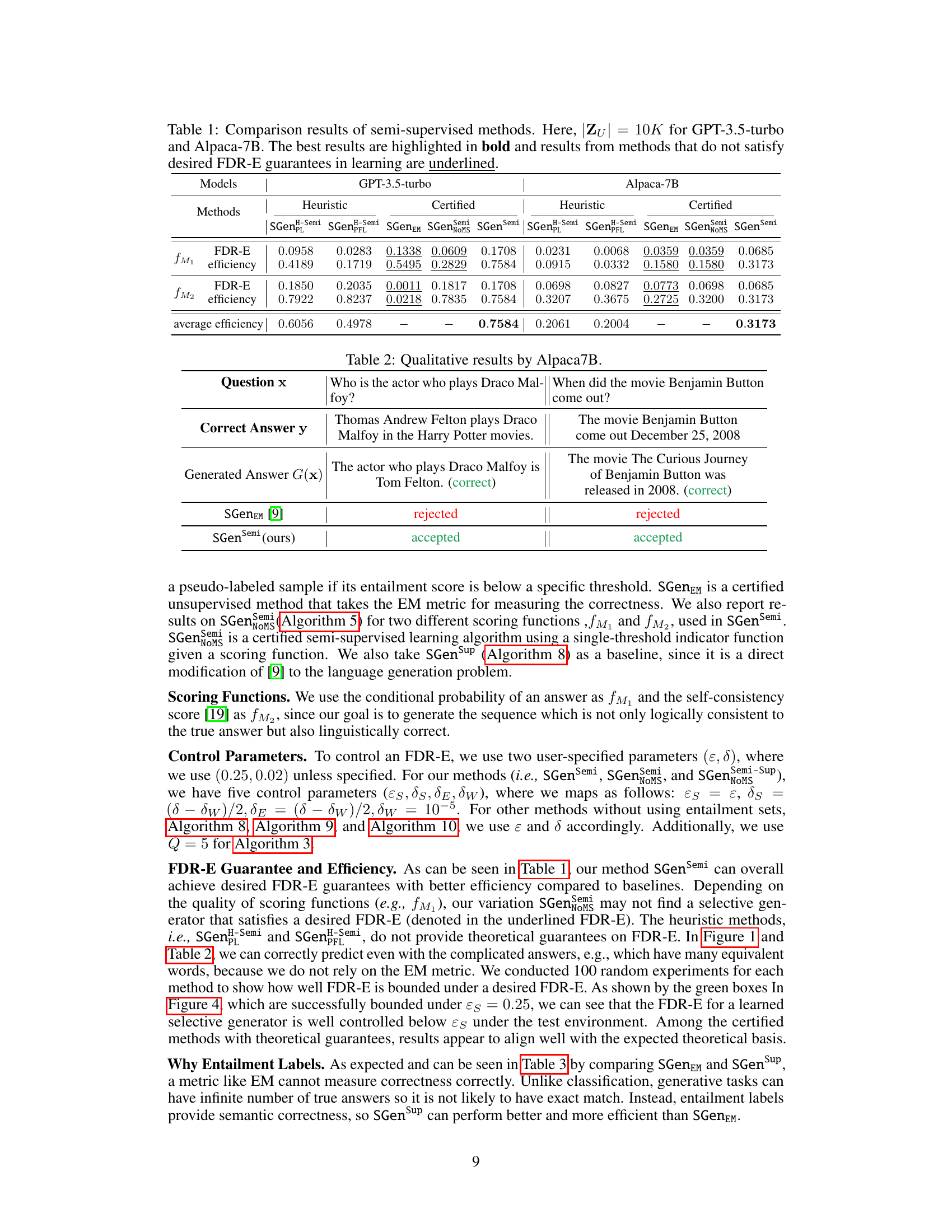
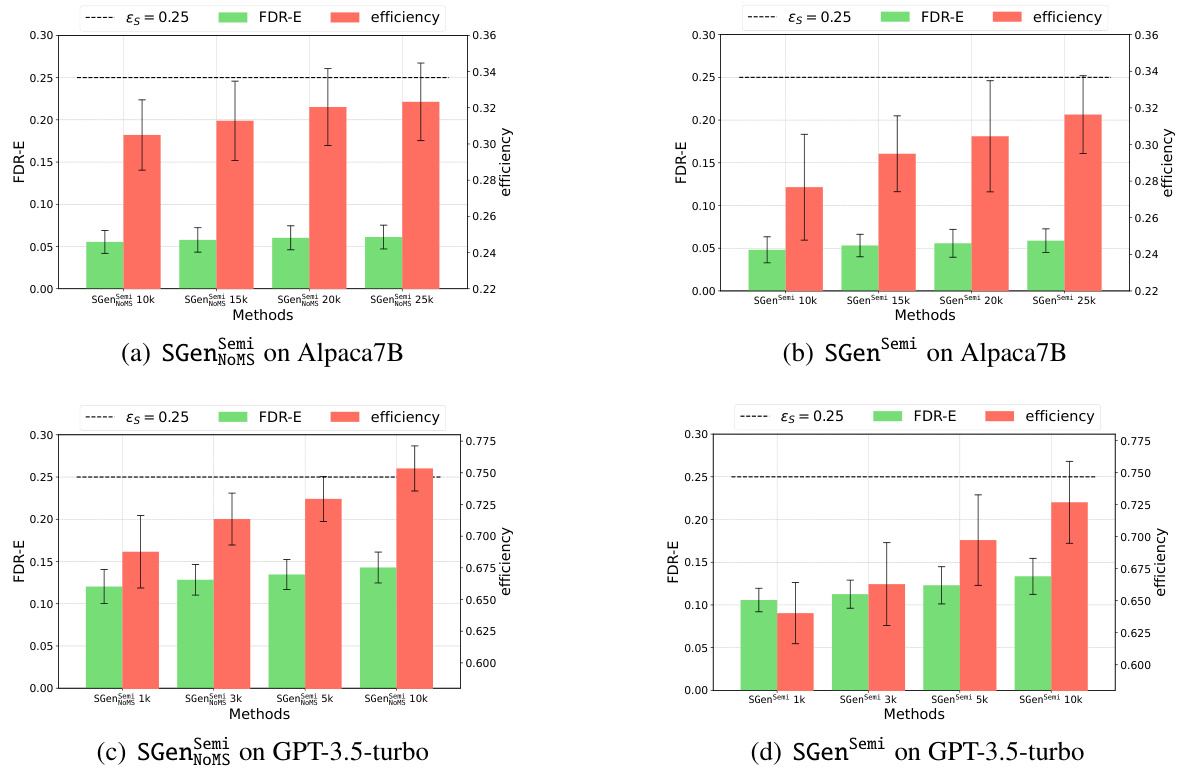
This table compares the performance of several semi-supervised methods for selective generation on two language models, GPT-3.5-turbo and Alpaca-7B. The methods are evaluated based on their false discovery rate with respect to textual entailment (FDR-E) and their selection efficiency. The table highlights the best-performing methods and indicates which methods failed to meet the desired FDR-E guarantee.
In-depth insights#
Certified Control#
In the realm of machine learning, particularly within the context of generative language models (GLMs), certified control mechanisms are paramount. These methods guarantee a certain level of accuracy and reliability, mitigating the risk of errors and untrustworthy predictions. The core idea revolves around providing probabilistic guarantees, quantifying the uncertainty associated with predictions. Selective prediction and conformal prediction emerge as prominent techniques. The former carefully selects predictions based on a confidence metric, rejecting those below a certain threshold to control the false discovery rate. Conformal prediction, on the other hand, produces prediction sets that probabilistically guarantee the inclusion of the correct outcome. However, a key challenge lies in establishing appropriate correctness metrics for tasks involving sequence generation, where multiple valid outputs exist. The paper appears to address this by proposing novel approaches that leverage textual entailment, thereby enabling the application of certified control methods to generative language models, bolstering their trustworthiness for high-stakes applications.
Semi-Supervised SG#
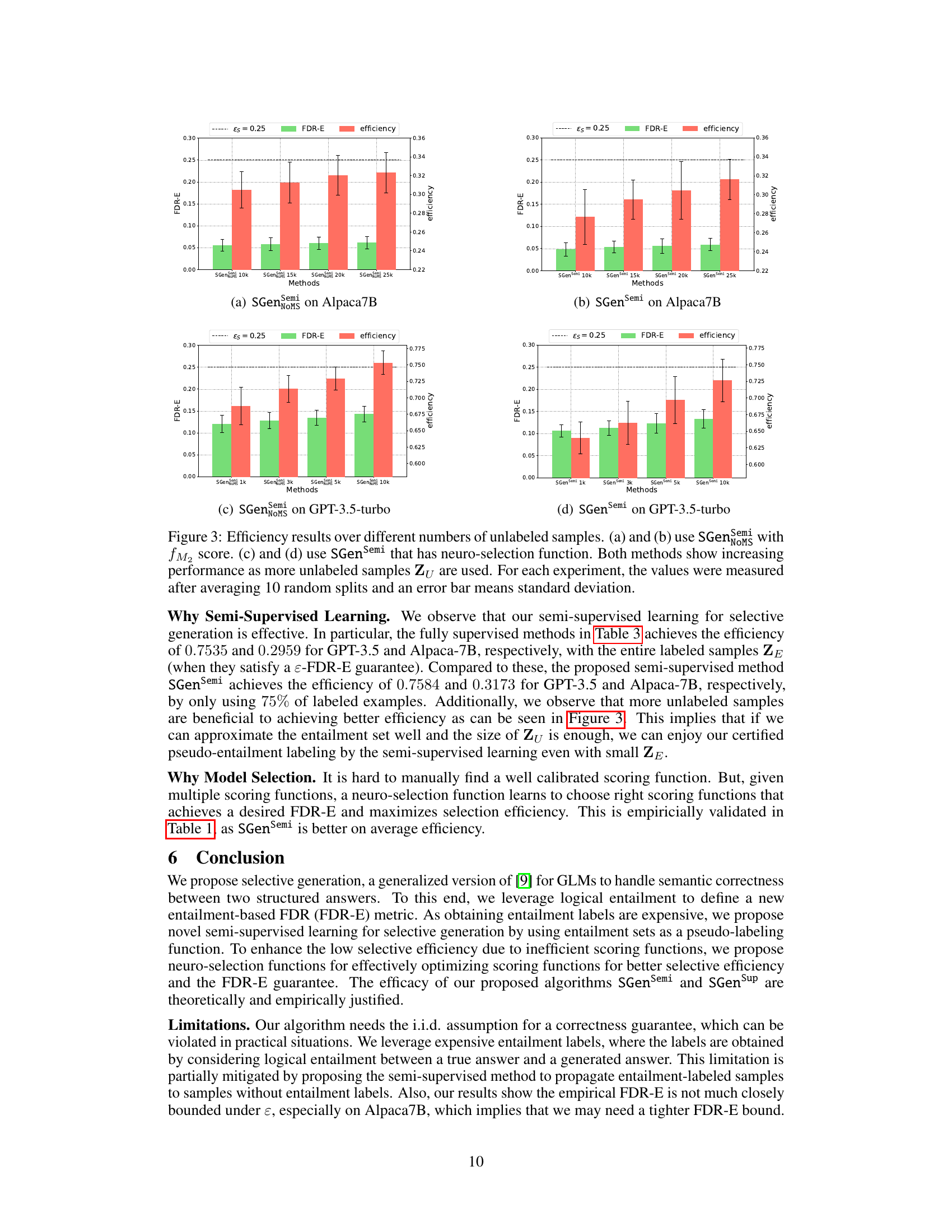
Semi-supervised selective generation (SG) leverages unlabeled data to improve the efficiency and effectiveness of the model. By utilizing both labeled and unlabeled data, the model can learn more robust representations and generalize better to unseen data, thereby potentially improving performance on downstream tasks. A key challenge in this approach lies in effectively incorporating the unlabeled data without introducing bias or noise. Techniques like pseudo-labeling, where the model’s predictions on unlabeled data are used as pseudo-labels for further training, are commonly employed. However, careful consideration must be given to handling potential errors in pseudo-labels, as inaccurate labels can negatively impact model performance. Effective strategies to handle this noise often involve confidence-based filtering or uncertainty estimation. Furthermore, the choice of algorithm and selection functions in semi-supervised SG can significantly influence its efficacy. The theoretical guarantees of the algorithm, particularly in relation to controlling the false discovery rate (FDR) when selecting outputs, is a crucial aspect. Empirical evaluation of the FDR across various datasets and language models is needed to validate the claims of improved performance and reliability.
Neuro-selection Funcs#
The heading ‘Neuro-selection Funcs’ suggests a novel approach to function selection within a machine learning model, likely in the context of selective generation. It implies moving beyond simpler, single-threshold selection methods towards a more sophisticated, neural network-based approach. This neural network would learn to weigh and combine multiple selection functions, instead of relying on a pre-defined threshold. The flexibility of a neural network allows the system to adapt to complex patterns in the data, leading to potentially improved selection efficiency and reduced false discovery rates. This approach would be particularly beneficial for tasks like language generation, where multiple valid answers exist and accurate uncertainty estimation is crucial for making informed decisions about what to output. The use of the term “neuro” highlights the deep learning aspect of this approach and the potential of adapting the selection functions dynamically during training or even inference.
Empirical Efficacy#
An empirical efficacy analysis of a research paper would delve into the experimental results section to evaluate the practical effectiveness of proposed methods. It would involve a critical examination of the methodologies, data analysis, and interpretation of results. Key aspects to consider include the choice of metrics: are they appropriate and comprehensive? How do the results compare to existing baselines? The analysis should also discuss the generalizability of the findings: do the results hold across different datasets, settings, or models? Another critical point is statistical significance: are the observed improvements statistically sound and not merely due to chance? Finally, a discussion of limitations and potential confounding factors in the experimental design adds to a complete empirical analysis. Overall, a strong empirical efficacy section provides compelling evidence of a method’s real-world utility and addresses possible concerns.
Future Work#
The paper’s ‘Future Work’ section would benefit from exploring several key directions. First, investigating the generalizability of the proposed methods to diverse language generation tasks beyond question-answering is crucial. This includes examining their performance on tasks requiring creative writing, summarization, or translation, where the notion of ‘correctness’ might need refinement. Second, a deeper exploration into the selection efficiency of different neuro-selection functions is warranted. The current experiments only touched upon a few options; a systematic comparison of a wider variety of architectures and training strategies for these functions is needed. Third, developing advanced techniques for handling the inevitable error in pseudo-labeling in the semi-supervised setting is critical. Analyzing the trade-offs between model accuracy and efficiency under varying levels of labeling noise could inform more robust strategies for semi-supervised training. Finally, investigating the impact of using more complex entailment relations beyond simple textual entailment could significantly enhance the model’s ability to capture nuanced semantic relationships and improve the overall trustworthiness of generated text.
More visual insights#
More on figures
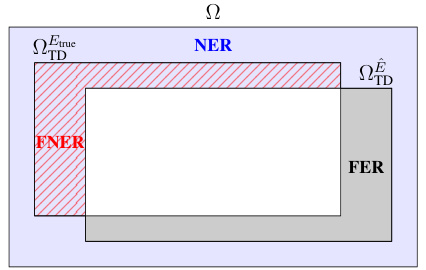
This figure shows the decomposition of the false discovery rate with respect to the true entailment set (FDR-E). It breaks down the FDR-E into four components to illustrate the different types of errors that can occur when estimating the entailment set: True Discovery (TD), False Negative Entailment Rate (FNER), False Entailment Rate (FER), and Non-Entailment Rate (NER). These components are used in the analysis and derivation of the FDR-E bounds for semi-supervised learning. The relationship between the estimated entailment set and the true entailment set illustrates the error rates.
This figure provides a high-level overview of the proposed method for selective generation, highlighting its key components and illustrating its qualitative performance. The core idea is to develop a selective generator capable of abstaining from making predictions when uncertain, thereby controlling the rate of hallucination (false discovery rate) in generated text sequences. The figure displays two examples illustrating different selection functions (exact match and entailment) applied to the language model’s generated answer in order to decide whether the answer is correct and should be accepted or incorrect and should be rejected. It shows that the proposed entailment-based approach provides a more robust method for evaluating answer correctness, particularly in handling scenarios with multiple valid answers.

This figure provides a high-level overview of the proposed method for selective generation, highlighting its key components and illustrating its application with qualitative examples. The core idea is to combine a language model (LLM) with a selection function to filter out unreliable predictions (hallucinations). The selection function leverages textual entailment, comparing generated answers to known correct answers to determine correctness. This approach ensures a controlled false discovery rate (FDR) on the generated text while offering a probabilistic guarantee on the quality of the remaining predictions.
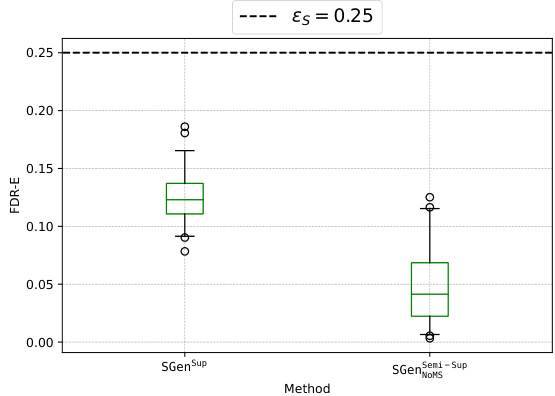
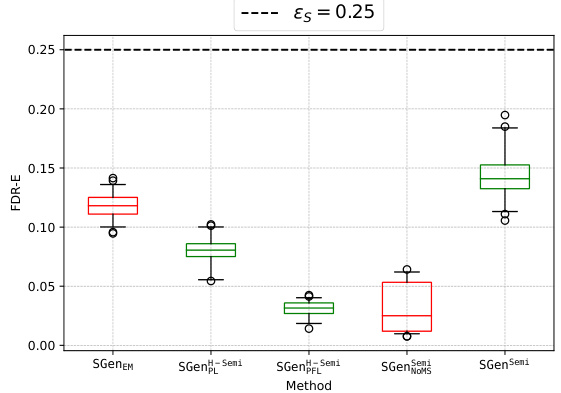
This figure shows box plots illustrating the False Discovery Rate with respect to textual entailment (FDR-E) for different methods on the GPT-3.5-turbo language model. The plots compare supervised and semi-supervised approaches, highlighting the effectiveness of the proposed methods in controlling FDR-E and satisfying the Probably Approximately Correct (PAC) guarantee. Red boxes indicate methods that failed to control FDR-E in at least one of 100 trials.
This figure provides a visual overview of the proposed method for selective generation, highlighting its key components and illustrating its performance. The main idea is to create a language model that can abstain from generating an answer when uncertain, thus controlling the rate of hallucination (incorrect answers). The left side shows a method using an exact match selection function while the right shows one using an entailment-based approach. The graphic demonstrates how the selection functions decide whether to accept or reject the LLM’s output by evaluating its correctness against a true answer. This ensures a controlled false discovery rate, providing a probabilistic guarantee for the correctness of the generated answers.
More on tables
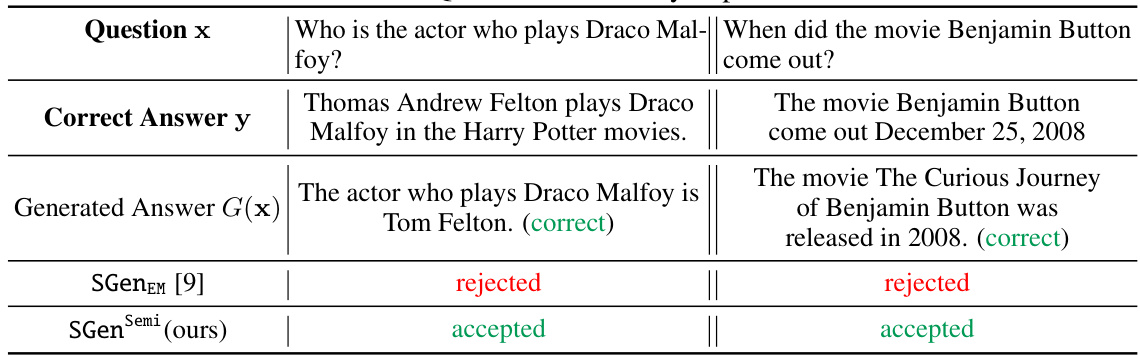
This table shows qualitative results of the Alpaca7B model in terms of whether the model’s generated answer is correct or not according to human judgment. It demonstrates the effectiveness of the proposed method (SGenSemi) in selecting correct answers while rejecting incorrect ones. Specifically, it compares the results of the proposed method with the baseline method (SGENEM) on two different question-answer pairs.

This table compares the performance of several semi-supervised methods for selective generation. The key metrics are the False Discovery Rate with respect to textual entailment (FDR-E) and the selection efficiency. The table shows results for two different language models (GPT-3.5-turbo and Alpaca-7B) and uses 10,000 unlabeled samples. The best performing methods for each model are highlighted in bold, while methods that failed to meet the desired FDR-E guarantee are underlined.
This table compares the performance of several semi-supervised methods for selective generation. The methods are evaluated based on their False Discovery Rate with respect to textual entailment (FDR-E) and their efficiency (the ratio of non-abstained generations). The experiment uses 10,000 unlabeled samples for both GPT-3.5-turbo and Alpaca-7B language models. The best-performing methods for each metric are highlighted in bold, and methods that failed to meet the desired FDR-E level are underlined.

This table compares the performance of several semi-supervised methods for selective generation in controlling the False Discovery Rate with respect to Textual Entailment (FDR-E). The methods are evaluated on two language models (GPT-3.5-turbo and Alpaca-7B) using 10,000 unlabeled data points. The table shows the achieved FDR-E and the selection efficiency for each method. The best performing methods (lowest FDR-E) are highlighted in bold. Methods that failed to meet the desired FDR-E guarantee are underlined.

This table compares the performance of several semi-supervised methods for controlling the false discovery rate via textual entailment (FDR-E). The methods are evaluated on two large language models (GPT-3.5-turbo and Alpaca-7B) using 10,000 unlabeled samples. The best results for FDR-E and efficiency are highlighted in bold. Underlined results indicate methods that failed to meet the desired FDR-E guarantee during training.
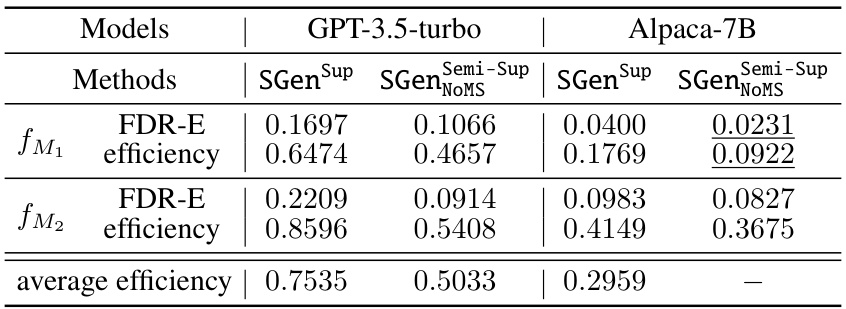
This table compares the performance of fully supervised selective generation methods on two language models, GPT-3.5-turbo and Alpaca-7B. The methods are evaluated based on their False Discovery Rate with respect to textual entailment (FDR-E) and selection efficiency. The best results (lowest FDR-E and highest efficiency) are highlighted, and those that did not meet the desired FDR-E guarantee are indicated. The table also notes that the best efficiency values for the fully supervised methods serve as a benchmark for comparing the semi-supervised methods.
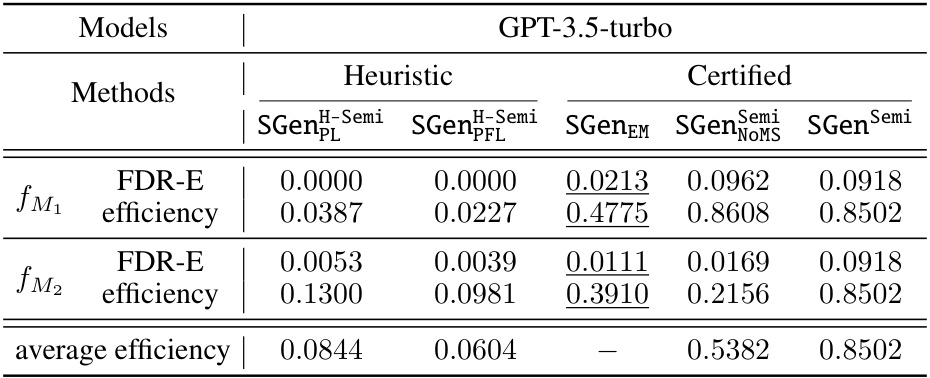
This table compares the performance of several semi-supervised methods for selective generation on two language models (GPT-3.5-turbo and Alpaca-7B). The key metrics are FDR-E (False Discovery Rate with respect to Entailment) and efficiency (percentage of instances where the model does not abstain). The table highlights the best performing methods and indicates which methods failed to meet the desired FDR-E guarantee (underlined values). The dataset used is the QA2D dataset, filtered to include only questions from the SQUAD subset, where human-labeled entailment information is available. A stricter FDR-E threshold (ε = 0.15) was used for this evaluation.
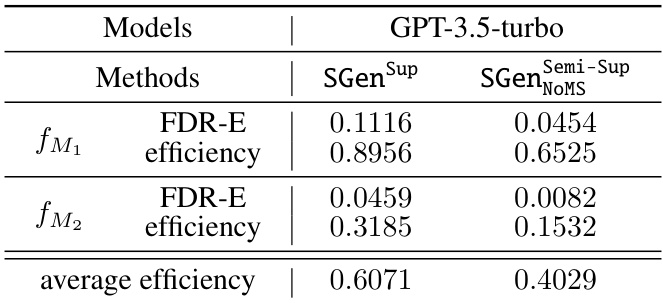
This table compares the performance of fully supervised methods for controlling the False Discovery Rate with respect to textual entailment (FDR-E). It shows the FDR-E and efficiency achieved by different methods using two different scoring functions (fM1 and fM2) on two language models (GPT-3.5-turbo and Alpaca-7B). The dataset used is the QA2D dataset filtered to include only the SQuAD subset with human-transformed questions and answers, and the desired FDR-E level (ε) is set to 0.15. Underlined results indicate that the method did not meet the FDR-E guarantee during training.
Full paper#