↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current prompt optimization methods for large language models (LLMs) mainly focus on finding the global optimum, which can be inefficient and costly, especially when dealing with black-box LLMs that only accept discrete text prompts. This paper challenges this assumption, demonstrating that high-performing local optima are usually prevalent and much more worthwhile for efficient prompt optimization. This insight is crucial since finding the global optimum often requires extensive computations and many queries to the LLM, incurring substantial costs.
To address this, the researchers propose a novel algorithm, Localized Zeroth-Order Prompt Optimization (ZOPO). ZOPO leverages a Neural Tangent Kernel-based Gaussian process within a standard zeroth-order optimization framework to efficiently search for high-performing local optima. Through extensive experiments, they show that ZOPO outperforms existing baselines in terms of both optimization performance and query efficiency. This suggests a paradigm shift in prompt optimization away from solely focusing on the global optimum.
Key Takeaways#
Why does it matter?#
This paper is important because it challenges the common practice of global optimization in prompt engineering, showing that focusing on high-performing local optima is often more efficient. This is particularly relevant to researchers working with large language models (LLMs) where query costs are significant. The proposed Localized Zeroth-Order Prompt Optimization (ZOPO) algorithm provides a novel approach to improve efficiency and performance in prompt optimization tasks. The empirical study and results open new avenues for exploring efficient LLM optimization strategies.
Visual Insights#

This figure shows the distribution of validation accuracies for prompts generated by two different large language models, Vicuna-13B and ChatGPT. It demonstrates that ChatGPT tends to generate prompts with higher accuracy and a larger mean accuracy than Vicuna-13B. The x-axis represents validation accuracy, and the y-axis represents the probability density. The vertical dotted lines represent the mean accuracy for each model.

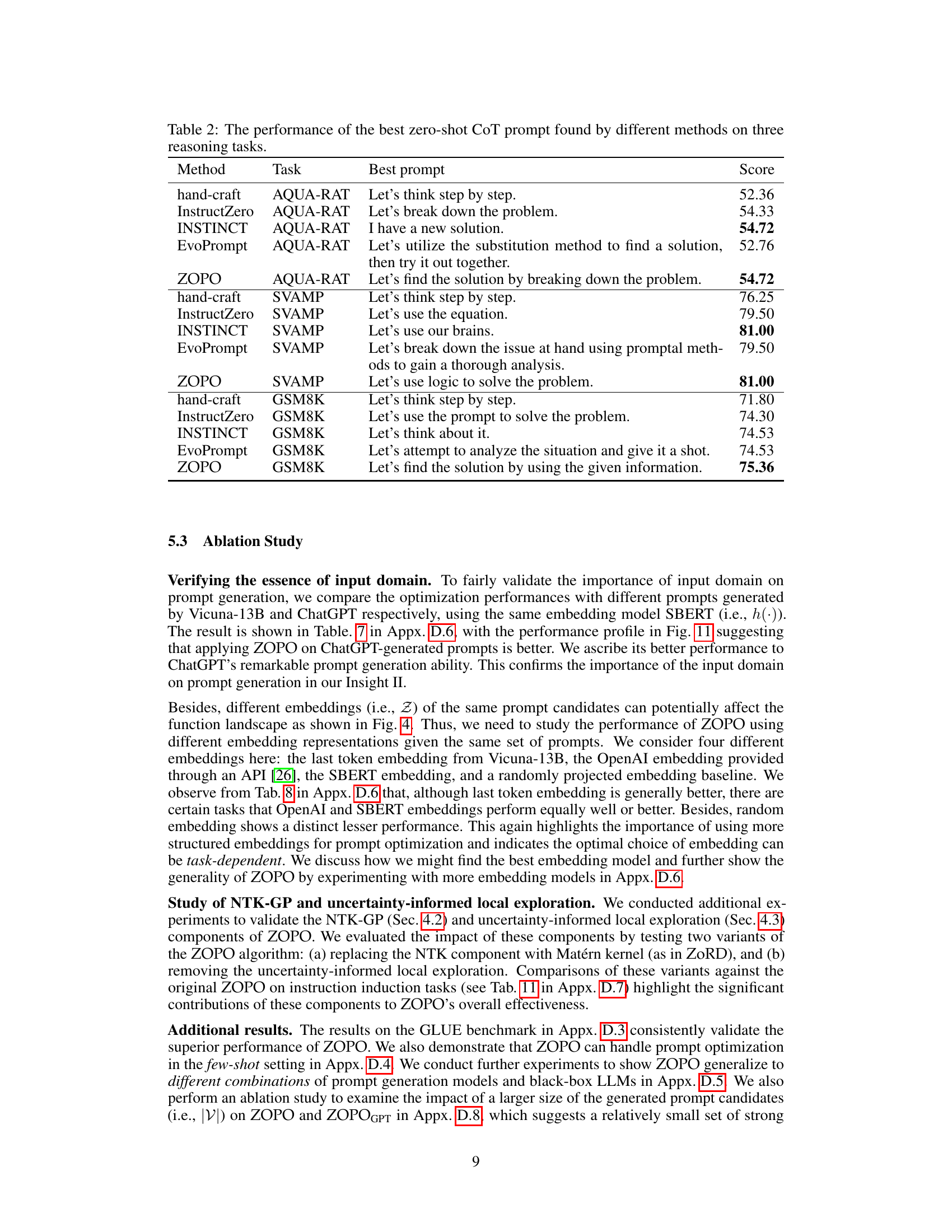
This table presents the average test accuracy, along with standard errors, achieved by various prompt optimization methods on 20 instruction induction tasks. The highest accuracy for each task is highlighted, differentiating between comparisons of ZOPO against baselines and ZOPOGPT against baselines.
In-depth insights#
Localized Prompt Opt#
Localized prompt optimization is a novel approach to enhance the efficiency and effectiveness of prompt-based methods for large language models (LLMs). Traditional global optimization strategies often prove computationally expensive and may not be necessary for achieving satisfactory performance. Localized optimization, in contrast, focuses on identifying high-performing local optima within a defined region of the prompt space. This strategy is particularly beneficial when operating under budget constraints. The core idea involves leveraging insights into the distribution of both global and local optima within the prompt space, and intelligently using this knowledge to design efficient search algorithms. The choice of input domain, particularly in the representation of prompts, plays a significant role in determining the success of this approach. Incorporating techniques like Neural Tangent Kernel (NTK)-based Gaussian processes can further improve the gradient estimation and optimize the search of well-performing local optima. The effectiveness of localized prompt optimization is clearly demonstrated through empirical studies showing superior performance and query efficiency compared to existing baselines. Overall, this approach offers a valuable and practical technique to improve prompt-based LLM utilization.
NTK-GP Optimization#
NTK-GP optimization represents a novel approach to efficiently tackle the challenges of prompt optimization in large language models. By leveraging the Neural Tangent Kernel (NTK), it addresses the limitations of traditional zeroth-order optimization methods, which often suffer from high query complexity. The NTK-based Gaussian process provides a more accurate estimate of the gradient, guiding the search process towards high-performing local optima. This strategy is particularly valuable considering the empirical observation that local optima are abundant and effectively performant within prompt optimization tasks, thus reducing computational costs and enhancing optimization efficiency. A key advantage lies in the localized nature of the optimization, focusing on regions of the search space showing promising results. This targeted approach helps the system avoid getting stuck in suboptimal solutions or wasting resources exploring unproductive areas. Moreover, this method complements a more general input domain transformation framework that allows prompt generation using various LLMs and representations using a variety of existing embedding models. Thus, NTK-GP optimization emerges as a sophisticated solution that synergistically combines a strong theoretical foundation with efficient practical implementation for prompt optimization, marking a significant improvement in the efficiency and efficacy of harnessing the power of large language models.
Empirical Insights#
An empirical study in prompt optimization reveals two key insights. First, local optima are prevalent and perform comparably to global optima, challenging the conventional wisdom of prioritizing global optimization. This finding is particularly relevant for scenarios with limited query budgets, as finding a high-performing local optimum is more efficient than a computationally expensive global search. Second, the choice of the input domain, encompassing prompt generation and representation methods, significantly influences the identification of well-performing local optima. This underscores the importance of careful consideration in selecting appropriate LLMs and embedding models for effective prompt optimization, as different combinations can yield drastically varying results, highlighting the interaction between these components in achieving optimal performance.
Input Domain Essence#
The essence of input domain in prompt optimization is a crucial, yet often overlooked, factor determining the effectiveness of the approach. The choice of how prompts are generated and represented significantly impacts the performance. Using various embedding models, the research highlights that different domains lead to varied landscapes of local and global optima. High-performing local optima are prevalent in some domains, rendering a global search inefficient and wasteful of resources. The quality of prompt generation is directly linked to the ability to discover these beneficial local optima. Thus, instead of solely focusing on global optimization, a strategy that considers the input domain and the distribution of well-performing local optima within that domain could be more effective in terms of both query efficiency and optimization performance. This understanding shifts the focus towards a more targeted search for beneficial prompts and guides the selection of effective prompt generation and embedding strategies, ultimately enhancing the overall efficiency and performance of prompt optimization.
Future Research#
Future research directions stemming from this localized zeroth-order prompt optimization (ZOPO) method could explore several promising avenues. Extending ZOPO to handle more complex prompt optimization tasks, such as those involving multi-modal inputs or intricate reasoning processes, would significantly broaden its applicability. Investigating the impact of different prompt generation models and embedding techniques on ZOPO’s performance across diverse NLP tasks is crucial for enhancing its robustness and efficiency. A deeper understanding of the optimal balance between exploration and exploitation within the ZOPO framework, especially in scenarios with limited query budgets, could improve its convergence speed and overall effectiveness. Furthermore, developing theoretical guarantees for ZOPO’s convergence and generalization ability would strengthen its foundational underpinnings. Lastly, exploring the integration of ZOPO with other prompt engineering techniques, such as chain-of-thought prompting, could potentially unlock even more advanced capabilities for interacting with large language models.
More visual insights#
More on figures

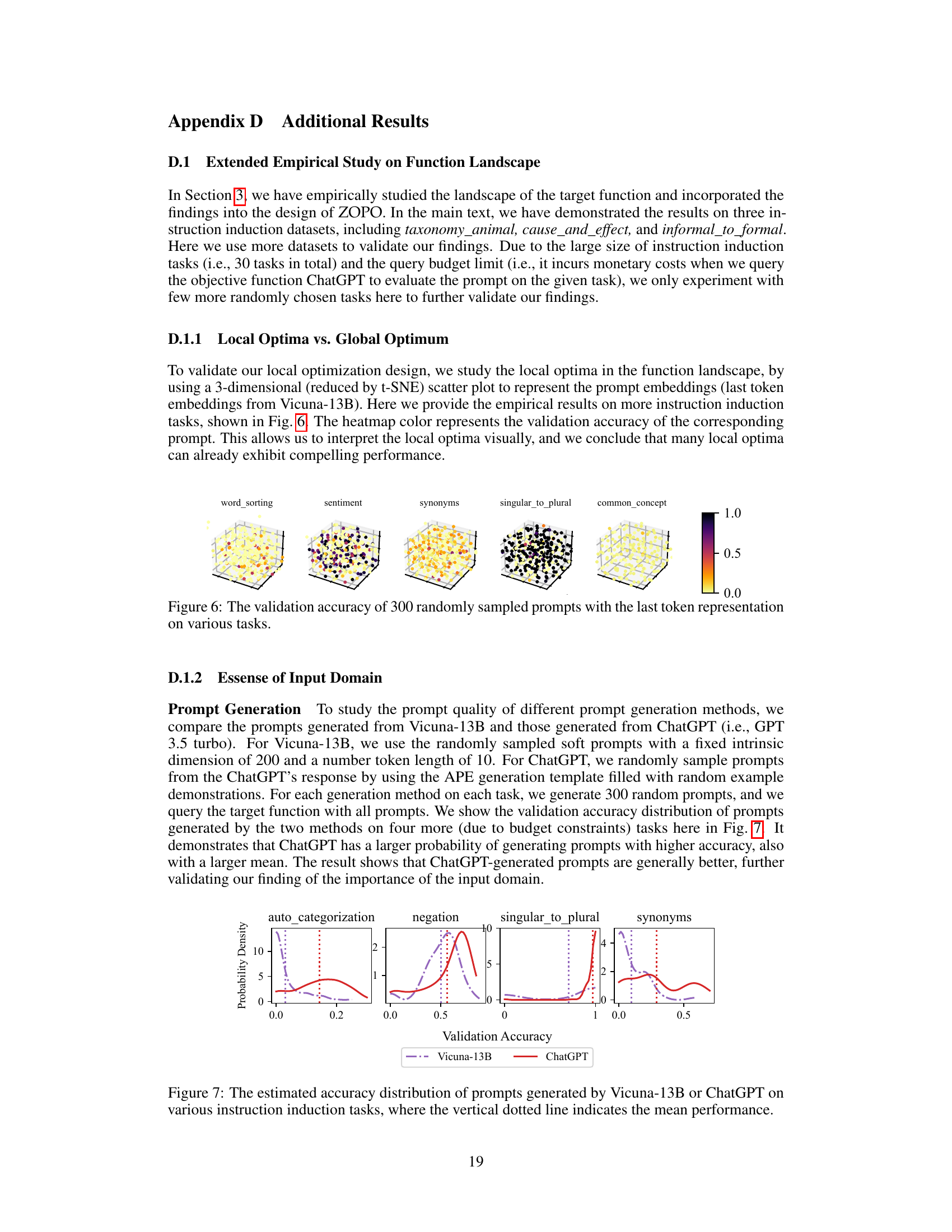
This figure visualizes the accuracy landscape (function surface) for prompt optimization using two different embedding methods: the last token embedding from the Vicuna-13B model and the SBERT embedding. The visualizations aim to illustrate how the choice of embedding impacts the distribution of well-performing local optima in the prompt optimization process. Different embeddings lead to varying numbers of well-performing local optima, highlighting the importance of input domain selection in efficient prompt optimization.
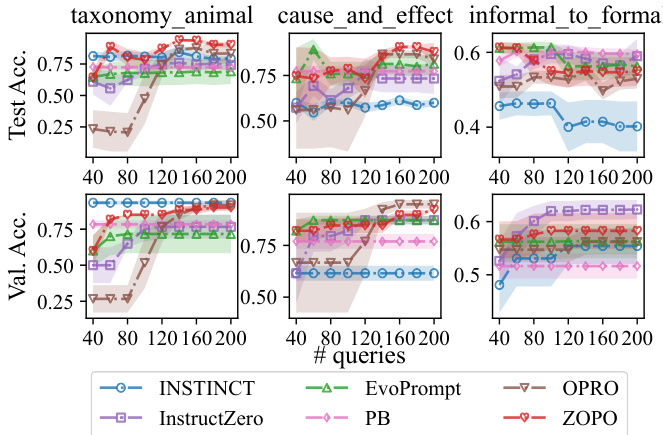
This figure compares the query efficiency of ZOPO against several baseline methods (APE, InstructZero, INSTINCT, EvoPrompt, PB, and OPRO) across three different tasks (taxonomy_animal, cause_and_effect, and informal_to_formal). The top row shows test accuracy, while the bottom row shows validation accuracy. The x-axis represents the number of queries, and the y-axis represents accuracy. The figure demonstrates that ZOPO generally achieves better performance with the same number of queries compared with other baseline methods and yields superior performance upon convergence. The plot also reveals that ZOPO achieves lower validation accuracy but higher test accuracy on the taxonomy_animal task compared to INSTINCT, suggesting better generalization for ZOPO.
This figure shows the performance profile of several prompt optimization methods on 20 different instruction induction tasks. The performance profile is a plot showing the cumulative distribution function (CDF) of the performance of each method. The x-axis represents the performance level (τ) and the y-axis shows the proportion of tasks for which the method achieves at least that performance level (p(τ)). A method that is consistently better than other methods will have a curve that is higher and further to the right. The figure indicates that ZOPO outperforms other methods across a range of performance levels.

This figure shows the performance profile curves for various prompt optimization methods on 20 different tasks. The performance profile, denoted as p(τ), indicates the probability that a given method achieves a performance within a factor of τ of the best observed performance across all methods tested on the task. A higher p(τ) value at any given τ signifies better performance. The curve for ZOPO (the proposed method) dominates others, indicating better performance overall. Section 5 provides further details on the methodology and the results.

This figure shows the performance profile of different prompt optimization methods across 20 tasks. The performance profile is a cumulative distribution function (CDF) that plots the proportion of tasks for which a given method achieves a performance within a certain distance (τ) from the best-performing method for each task. A higher p(τ) indicates superior performance across more tasks. Section 5 provides further details.

This figure visualizes the performance of 300 randomly selected prompts on various tasks. Each prompt’s embedding (using the last token representation) is reduced to two dimensions using t-SNE for better visualization. The color of each point represents its validation accuracy, demonstrating the prevalence of well-performing local optima in the prompt optimization landscape, supporting Insight I in the paper.

This figure displays the distribution of validation accuracies achieved by prompts generated using two different large language models: Vicuna-13B and ChatGPT. The x-axis represents the validation accuracy, while the y-axis shows the probability density. Each subplot corresponds to a different instruction induction task. The vertical dotted lines in each subplot indicate the mean validation accuracy for that task. This visualization helps to understand the variability in performance across different prompts generated by each model and across different tasks. The comparison between Vicuna-13B and ChatGPT highlights differences in their ability to generate high-performing prompts.

This figure visualizes the accuracy landscape (function surface) for different prompt optimization tasks. The x and y axes represent the two dimensions of the reduced prompt embedding (Vicuna-13B last token embedding reduced to 2D using t-SNE), and the color intensity represents the validation accuracy. The contour plots at the bottom provide additional visualization of the accuracy landscape. This figure illustrates that the complexity of the target function varies among tasks, with some having many good local optima and others having fewer. The existence of numerous good local optima supports the paper’s focus on localized zeroth-order optimization.
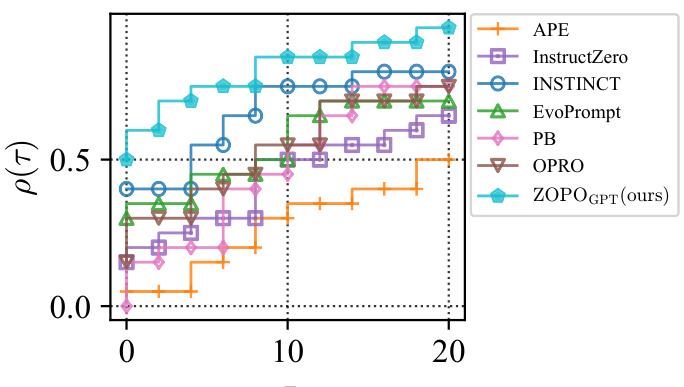
This figure shows the performance profile of different prompt optimization methods on 20 instruction induction tasks. The performance profile plots the cumulative distribution function (CDF) of the performance of each method relative to the best performing method across all tasks. A higher p(τ) indicates better performance, meaning that the method achieves a higher accuracy within a given distance (τ) from the optimal accuracy. The figure highlights the superior performance of the proposed ZOPOGPT method compared to several baselines (APE, InstructZero, INSTINCT, EvoPrompt, PB, OPRO).

This figure compares the query efficiency of ZOPO against several other baseline methods across different query budget scales. The top row shows the test accuracy, while the bottom row displays the validation accuracy. It illustrates that ZOPO generally achieves better performance with the same number of queries compared to other methods, and it shows superior performance upon convergence. Noteworthy is that ZOPO achieves lower validation accuracy but higher test accuracy on the \texttt{taxonomy_animal} task than INSTINCT, suggesting potentially better generalization.

The figure shows the performance profile of different prompt optimization methods across 20 tasks, comparing their efficiency in achieving high accuracy within a given query budget. The x-axis (τ) represents the performance gap from the best-performing method, and the y-axis (ρ(τ)) indicates the proportion of tasks for which a method achieves a performance within τ of the optimum. A higher curve shows better performance. Section 5 provides more detailed analysis of these results.
More on tables

This table presents the average test accuracy and standard error for various prompt optimization methods across 20 instruction induction tasks. The results compare ZOPO and ZOPOGPT against several baselines (APE, InstructZero, INSTINCT, EvoPrompt, PB, OPRO). The highest accuracy for each task is highlighted, with the best results for ZOPO and ZOPOGPT indicated using bold and green highlighting, respectively. The table showcases the superior performance of ZOPO and ZOPOGPT compared to the other baselines on a majority of tasks.
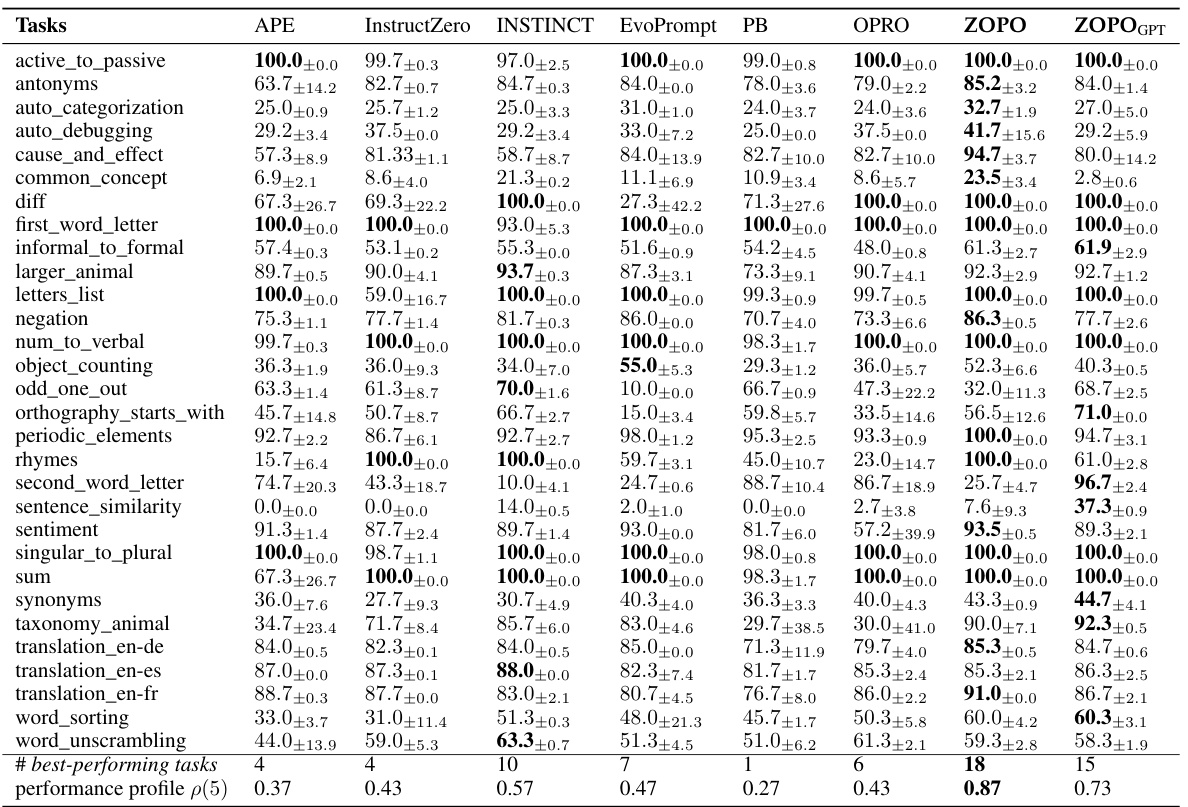
This table presents a comparison of the average test accuracy achieved by various prompt optimization methods on 20 instruction induction tasks. The results are reported with standard error across three runs. The table highlights the highest accuracy achieved by ZOPO compared to the baselines for each task, and also highlights the best performance of ZOPOGPT against baselines using green cells. The results showcase the superior performance of ZOPO and ZOPOGPT compared to the other methods.

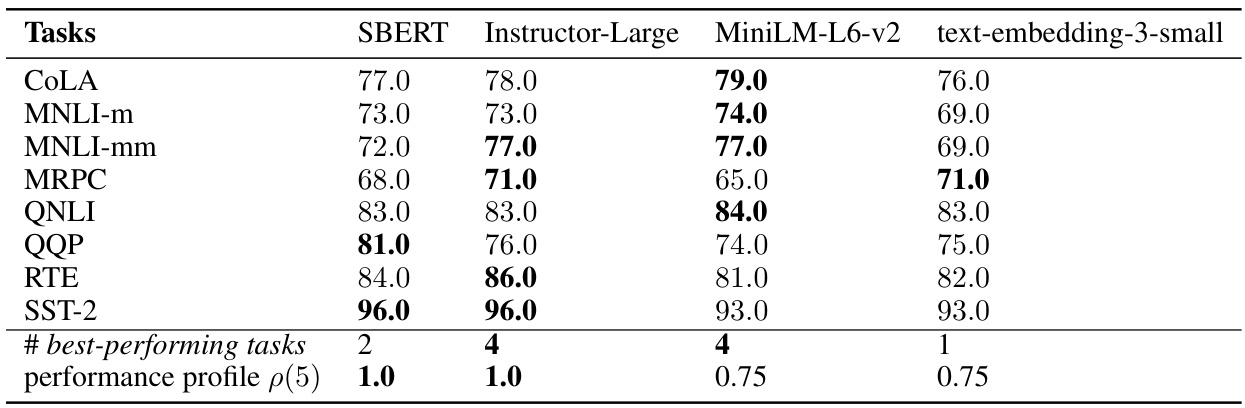
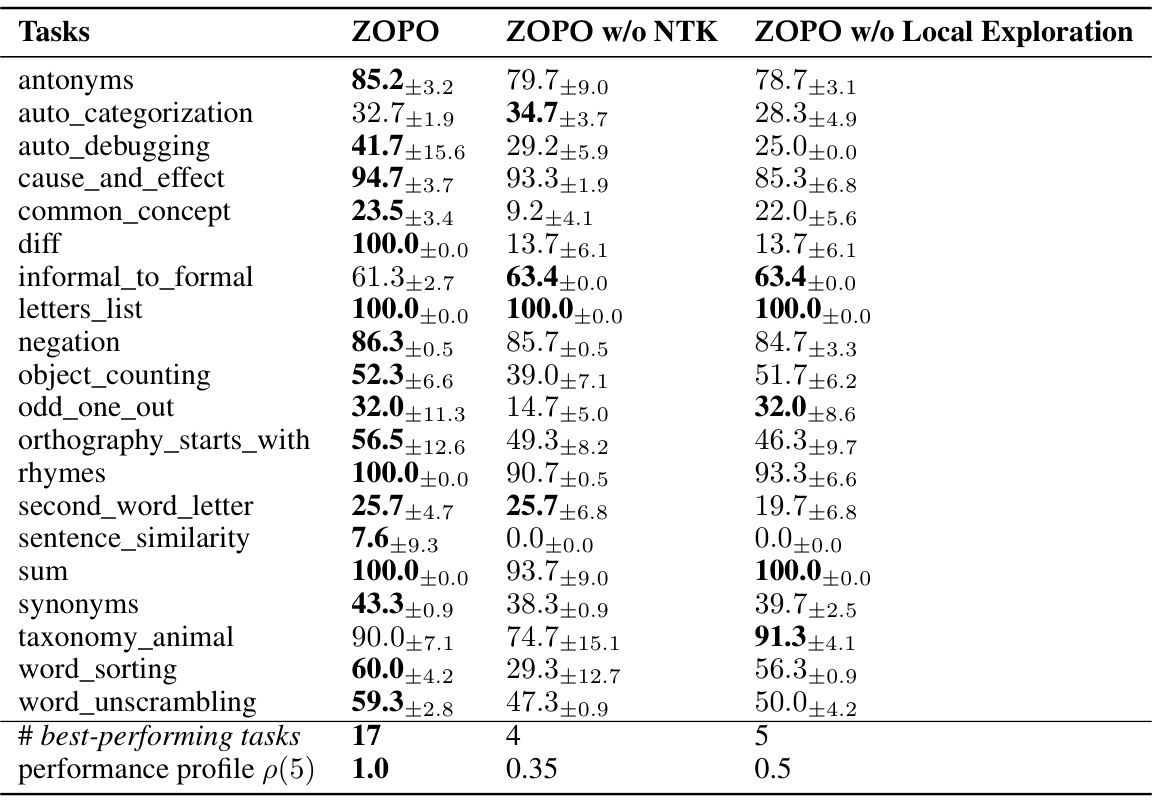
This table presents the performance of various prompt optimization methods on the GLUE benchmark. The GLUE benchmark consists of several natural language understanding tasks. The table shows the test accuracy achieved by each method on each task, highlighting the relative performance of ZOPO compared to established baselines. The ‘#best-performing tasks’ and ‘performance profile p(5)’ rows provide a summary of the overall comparative performance.

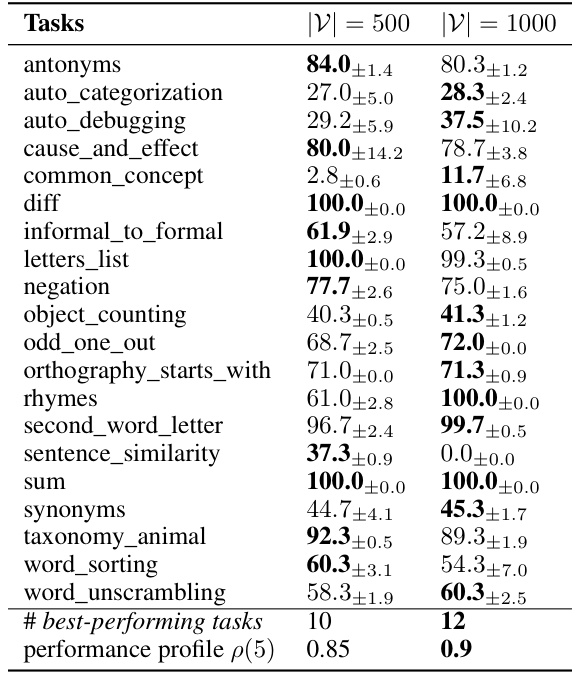
This table compares the performance of ZOPO under zero-shot and few-shot (5 examples) settings on various instruction induction tasks. It demonstrates the impact of providing a small number of examples to guide the LLM (few-shot learning) on the final accuracy. The table allows one to see whether providing in-context examples improves performance.
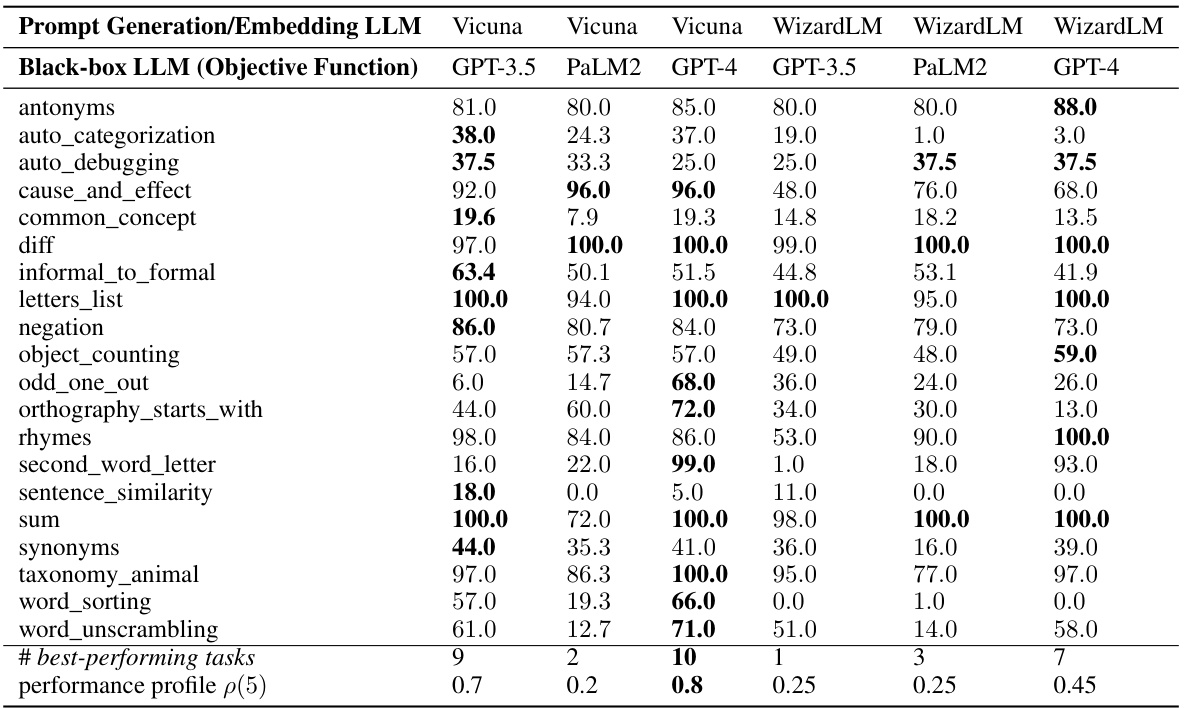
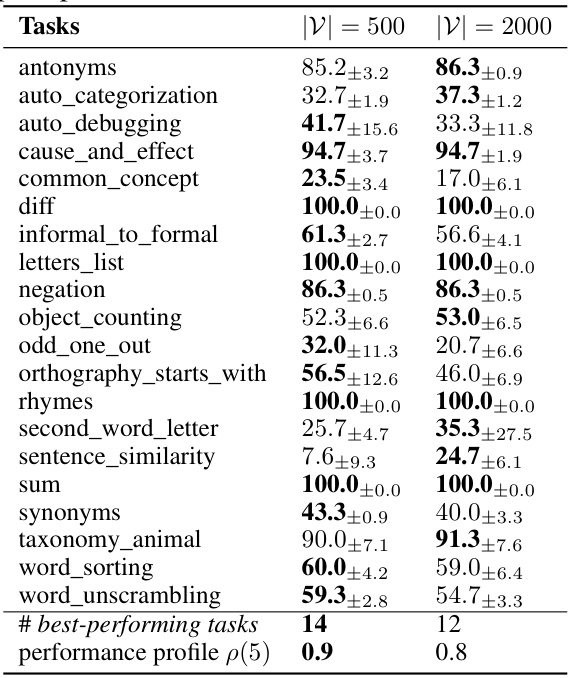
This table shows the test accuracy results for different combinations of prompt generation models (Vicuna-13B and WizardLM-13B) and black-box LLMs used for prompt evaluation (GPT-3.5, PaLM2, and GPT-4) on instruction induction tasks. It demonstrates the generalizability of ZOPO across various LLMs and shows that Vicuna generally performs better than WizardLM for prompt generation and representation in this context. The best-performing LLM for each task is highlighted. The performance profile (p(5)) is also included to provide a summary of the overall performance.

This table compares the performance of ZOPO when using prompts generated by Vicuna-13B and ChatGPT, while keeping the embedding model (SBERT) consistent. It demonstrates how the choice of prompt generation model affects the optimization results, highlighting the impact of the input domain on the ZOPO’s performance. The results are presented for 20 instruction induction tasks, allowing for a comprehensive comparison of the two prompt generation methods.

This table presents the average test accuracy achieved by the ZOPO algorithm using four different embedding methods (Last Token, OpenAI, SBERT, and Random) on 20 instruction induction tasks. The standard error across 3 runs is also provided. The results show the impact of different embedding choices on the algorithm’s performance.

This table presents a comparison of the performance of the ZOPO algorithm across four different embedding methods (Last Token, OpenAI, SBERT, and Random) when applied to 20 instruction induction tasks. The goal is to investigate how the choice of embedding impacts the algorithm’s ability to find high-performing prompts. Each row represents a task, and the columns show the average test accuracy and standard error for each embedding method. The final two rows summarize the number of tasks where each embedding method achieved the highest accuracy and the performance profile (p(5)), a metric that assesses the algorithm’s overall performance.
This table presents the average test accuracy achieved by the ZOPO algorithm using four different embedding methods on 20 instruction induction tasks. The embeddings used are: Last Token embedding from Vicuna-13B, OpenAI embedding, SBERT embedding, and Random embedding. The table shows the average test accuracy and standard error (across 3 runs) for each embedding method on each of the 20 tasks, and also provides the number of times each method achieved the highest accuracy, and the performance profile p(5) which reflects the overall ranking of each method across the 20 tasks.
This table compares the performance of the proposed ZOPO method against several strong baseline methods on 20 instruction induction tasks. The average test accuracy and standard error are provided for each method and task. The best performing method for each task is highlighted. The table also highlights the highest accuracy achieved by ZOPO and ZOPOGPT (a variant using ChatGPT) compared to the baselines.
This table presents the average test accuracy of several prompt optimization methods on 20 instruction induction tasks. The results are averaged over three runs, with standard errors reported. The highest accuracy for each task is bolded when comparing ZOPO against the baselines. Additionally, the highest accuracy when comparing ZOPOGPT against baselines is highlighted in green. This table allows for a direct comparison of the performance of ZOPO and ZOPOGPT against existing approaches on various instruction induction tasks.
This table presents the average test accuracy, along with standard errors, achieved by different prompt optimization methods across 20 instruction induction tasks. The highest accuracy for each task is highlighted, differentiating between the ZOPO and ZOPOGPT models. ZOPO represents the Localized Zeroth-Order Prompt Optimization model, while ZOPOGPT uses ChatGPT to generate prompts. The table allows comparison of ZOPO’s performance against other established methods in the field of prompt optimization.

This table presents the average test accuracy achieved by different prompt optimization methods on 20 instruction induction tasks. The results are shown for several baselines (APE, InstructZero, INSTINCT, EvoPrompt, PB, OPRO) and the proposed methods (ZOPO, ZOPOGPT). The highest accuracy for each task is highlighted, allowing for a comparison of the relative performance of the different approaches. ZOPO and ZOPOGPT represent variations of the proposed method, indicating different implementations or modifications applied.
This table presents the average test accuracy achieved by different prompt optimization methods across 20 instruction induction tasks. The results are averaged across three runs and include standard errors. The table highlights the best performing method for each task by bolding the highest accuracy when comparing against traditional methods and using a green cell to highlight the best performance for ZOPOGPT (a variant of ZOPO). This allows for a direct comparison of ZOPO and ZOPOGPT against several state-of-the-art methods.
Full paper#