↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive. Existing LLM pruning methods often rely on hand-crafted criteria to identify and remove less important parameters, which can be inaccurate and limit transferability. This leads to suboptimal pruning results and hinders the deployment of LLMs in resource-constrained settings.
MaskLLM addresses these issues by explicitly modeling the sparsity patterns as a learnable distribution using Gumbel Softmax sampling. This enables end-to-end training on large datasets, producing accurate sparsity masks and improving the transferability of sparsity across domains. The method demonstrates significant improvements over existing approaches on various LLMs and downstream tasks, showcasing lossless compression with substantial speedup and reduced memory footprint.
Key Takeaways#
Why does it matter?#
This paper is highly important because it presents MaskLLM, a novel and effective method for efficiently reducing the computational cost of large language models (LLMs) without significant loss in performance. It addresses a critical challenge in deploying LLMs by introducing learnable semi-structured sparsity, opening new avenues for research on efficient LLM deployment and transfer learning across domains.
Visual Insights#
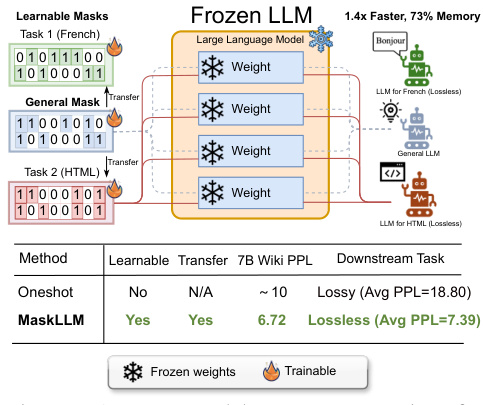
This figure illustrates the concept of learnable N:M sparsity for Large Language Models (LLMs) introduced by MaskLLM. It shows how MaskLLM learns task-specific and general masks that can be transferred to different downstream tasks, leading to lossless compression in LLMs. The left side depicts the learnable mask generation process. The middle depicts the frozen LLM weights and learnable mask application. The right depicts the speed and memory improvements obtained. The table at the bottom summarizes the performance comparison between oneshot and MaskLLM methods.
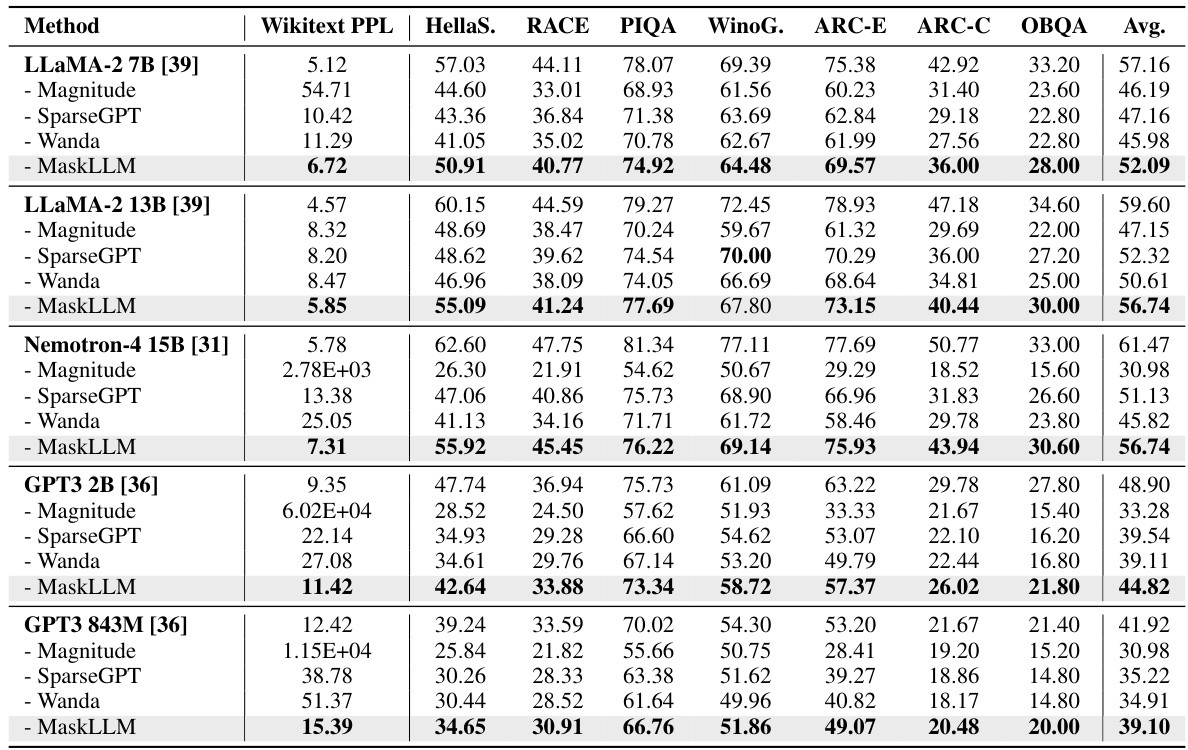
This table compares the performance of MaskLLM against several baseline methods for achieving 2:4 sparsity in various LLMs. The metrics used are perplexity on the Wikitext-2 dataset and accuracy scores across various downstream tasks (HellaSwag, RACE, PIQA, Winograd, ARC-E, ARC-C, OBQA). The table demonstrates that MaskLLM achieves better performance than other state-of-the-art methods (SparseGPT and Wanda) while only learning the masks and not updating the model weights. Additional results for Llama-3 and other baselines can be found in the appendix.
In-depth insights#
Learnable Sparsity#
Learnable sparsity presents a revolutionary approach to model optimization, moving beyond static pruning techniques. Instead of pre-determining which weights to remove based on heuristics, learnable sparsity allows the model itself to learn the optimal sparsity pattern during training. This dynamic process can lead to higher accuracy and efficiency compared to traditional methods. A key advantage is the potential for transfer learning, where sparsity patterns learned in one domain or task can be effectively transferred to others. Differentiable sampling techniques are crucial, enabling the use of backpropagation to optimize the sparsity pattern directly. However, challenges remain, particularly the computational cost of training learnable masks and the need for robust techniques to prevent gradient vanishing during the learning process. Despite these challenges, the potential for improved efficiency and performance makes learnable sparsity a significant area of active research and development within the field of machine learning.
N:M Mask Sampling#
N:M mask sampling, a crucial aspect of semi-structured pruning in large language models, addresses the challenge of efficiently identifying and selecting a subset of model parameters for removal without significant performance degradation. Learnable mask sampling methods, as opposed to heuristic approaches, offer superior performance by directly optimizing mask selection during the training process. The core idea is to frame mask selection probabilistically, using techniques such as Gumbel-Softmax to make the process differentiable and amenable to gradient-based optimization. This probabilistic approach allows the model to learn effective mask distributions, enabling the selection of high-quality masks tailored to specific tasks or domains. One key advantage is the improved scalability to large datasets, which enhances the generalizability of the pruned models. Transfer learning is also facilitated as learned mask distributions can be easily transferred across tasks. Overall, N:M mask sampling represents a significant advancement in model compression techniques for LLMs, addressing the limitations of existing heuristic methods.
Transfer Learning#
Transfer learning, in the context of large language models (LLMs) and sparsity, presents a powerful technique to accelerate the learning of effective sparsity masks. Instead of learning masks from scratch for every task or domain, pre-trained masks (obtained through methods like magnitude pruning or other one-shot techniques) can be used as a starting point. This prior knowledge significantly reduces training time and potentially improves the quality of the resulting sparse model. MaskLLM leverages this concept by incorporating pre-trained masks as priors, thus initializing the learnable mask distribution with a head-start. The learnable nature of MaskLLM then allows the model to refine these masks further through end-to-end training, adapting them to the specific requirements of the target task while capitalizing on the knowledge already embedded in the prior masks. This approach enhances efficiency and demonstrates that transferring sparsity patterns effectively facilitates lossless compression across various downstream applications.
Downstream Tasks#
The concept of “Downstream Tasks” in the context of large language models (LLMs) refers to the various applications and functionalities LLMs are employed for after their initial pre-training. These tasks often leverage the knowledge and patterns learned during pre-training but require adaptation or fine-tuning to perform effectively. The MaskLLM paper particularly emphasizes the transferability of learned sparsity patterns. This means the optimized sparse models, created by MaskLLM for general use, can be directly applied to diverse downstream tasks without needing extensive retraining, potentially saving significant computational resources. This transferability underscores MaskLLM’s efficiency and adaptability. The success of this approach hinges on the quality of the initially learned sparsity masks and highlights the potential for creating efficient and versatile LLMs tailored for various applications. However, the lossless nature of this application to downstream tasks remains dependent on task specificity and suitable initial mask choices. Future research could investigate the limits of this transferability and explore ways to further improve its effectiveness across more diverse and challenging tasks.
Limitations#
A thoughtful analysis of the limitations section in a research paper would delve into several key aspects. First, it would critically examine the scope of the study, assessing whether the findings can be generalized beyond the specific context or datasets employed. Methodological limitations should be addressed, such as potential biases in data collection, limitations in sample size, and the reliance on specific algorithms or techniques. The discussion should also acknowledge the interpretive limitations of the results, including potential alternative explanations for the findings, and the impact of any assumptions made. Furthermore, a comprehensive limitations section would discuss the practical limitations of applying the research findings, such as scalability issues, resource constraints, or the feasibility of implementation. Finally, future research directions are often suggested to address these identified limitations and enhance the overall robustness of the research.
More visual insights#
More on figures
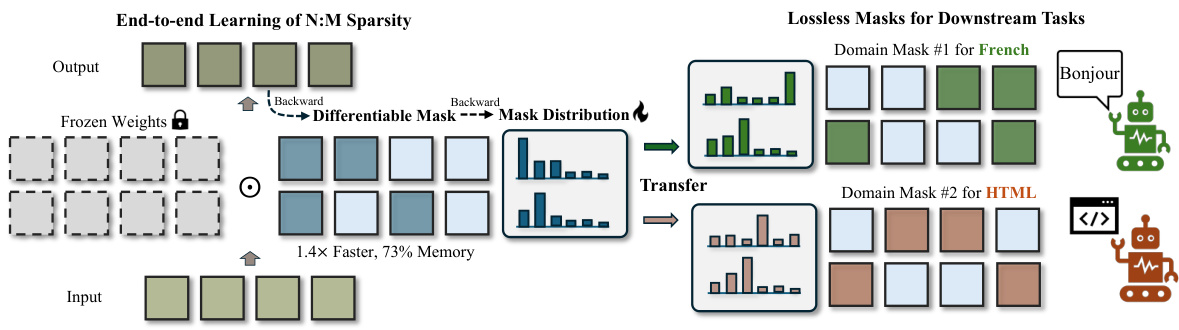
The figure illustrates the MaskLLM framework. The left side shows the end-to-end training process where a differentiable mask is learned from a mask distribution. The right side shows how this learned mask can be transferred to different downstream tasks (e.g., French and HTML processing), resulting in lossless compression.

This figure illustrates the process of sampling a mask from a learnable distribution using Gumbel Softmax. It shows how learnable logits are transformed into a probability distribution over candidate masks. Gumbel noise is added for differentiable sampling, resulting in a soft mask for training. A hard mask is then derived for inference by selecting the mask with the highest probability. The entire process, from logits to final mask, is differentiable, enabling end-to-end training.
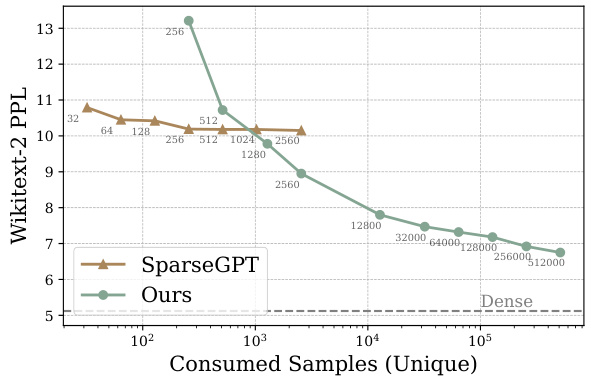
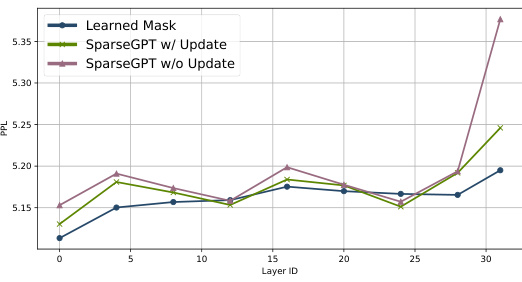
This figure shows the relationship between the number of consumed samples during training and the resulting perplexity (PPL) on the Wikitext-2 benchmark for the LLaMA-2 7B model using two methods: SparseGPT and MaskLLM. The x-axis represents the number of unique samples used for training, while the y-axis represents the PPL achieved. The plot demonstrates that MaskLLM outperforms SparseGPT, especially when a larger number of samples are used. Notably, MaskLLM only requires 128 samples to surpass SparseGPT’s performance.
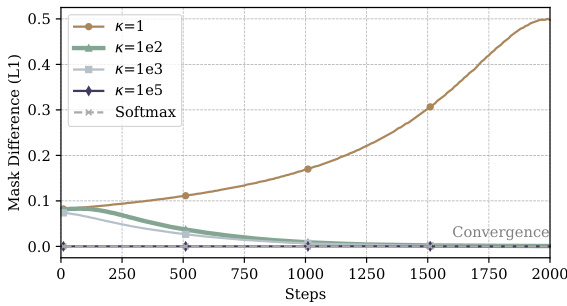
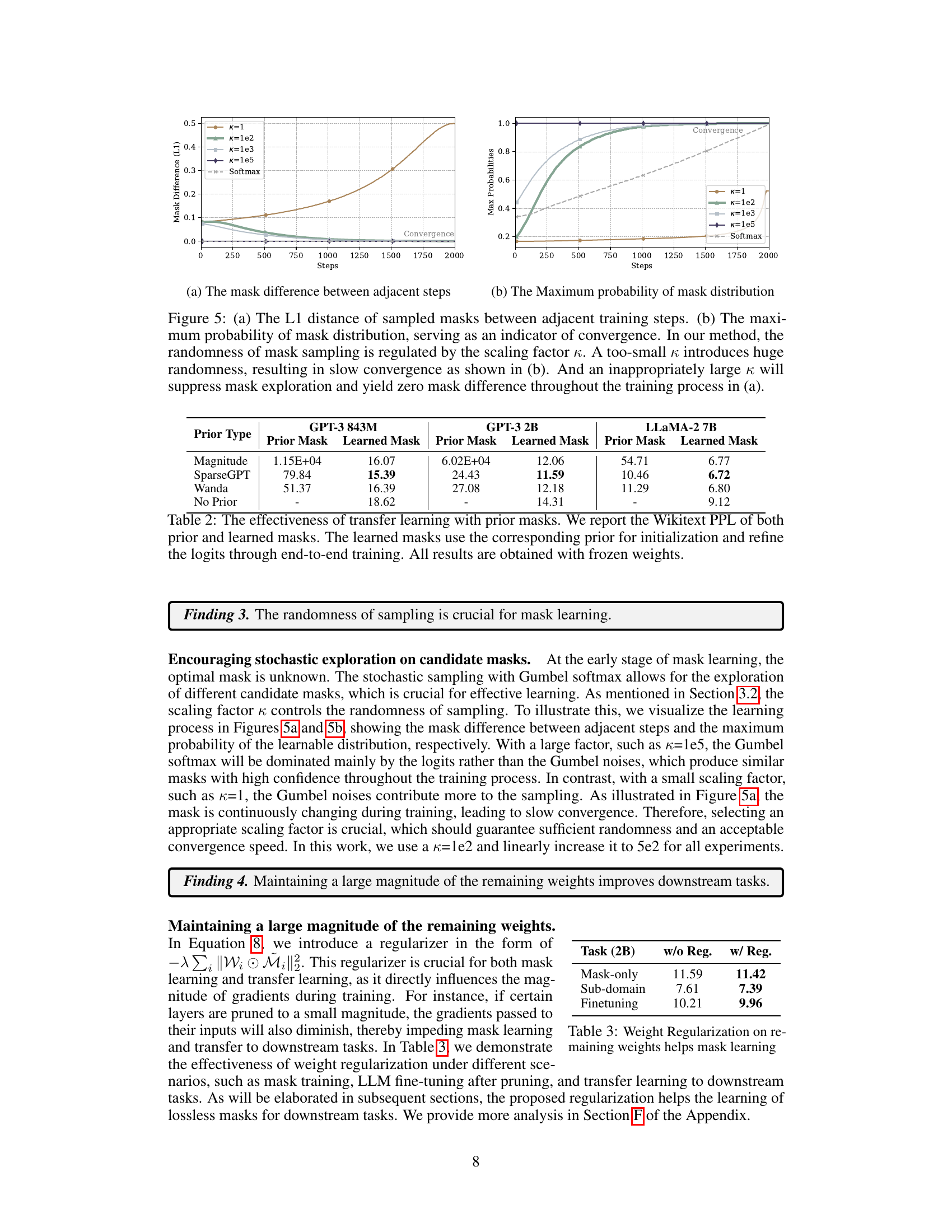
This figure shows two graphs that illustrate the effect of the scaling factor (κ) on the convergence of the mask sampling process. The first graph shows the L1 distance between sampled masks in consecutive training steps, while the second graph shows the maximum probability of the mask distribution. The results indicate that an appropriately chosen scaling factor is crucial for balancing exploration and exploitation during the mask learning process, ensuring efficient convergence without sacrificing diversity.
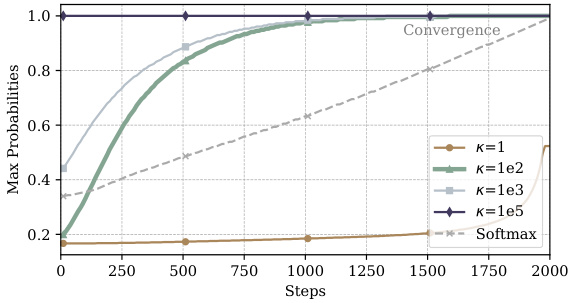
This figure shows two graphs, (a) and (b), that illustrate the impact of the scaling factor (κ) on the learning process of MaskLLM. Graph (a) plots the L1 distance between consecutively sampled masks against the number of training steps. It demonstrates that a small κ leads to high randomness and slow convergence, while a large κ suppresses exploration, resulting in no change in masks. Graph (b) displays the maximum probability of mask distribution over training steps, also showing the impact of κ on convergence speed. The figure highlights the importance of selecting an appropriate κ value to balance exploration and convergence in MaskLLM’s learning process.
This figure illustrates the MaskLLM approach for achieving learnable N:M sparsity in LLMs. It shows how learnable masks are generated and transferred to downstream tasks, resulting in improved speed and memory efficiency. The diagram depicts the process of using a general mask to achieve lossless compression for different downstream tasks (e.g., French, HTML), demonstrating the transferability and efficiency gains of the MaskLLM method compared to existing approaches.
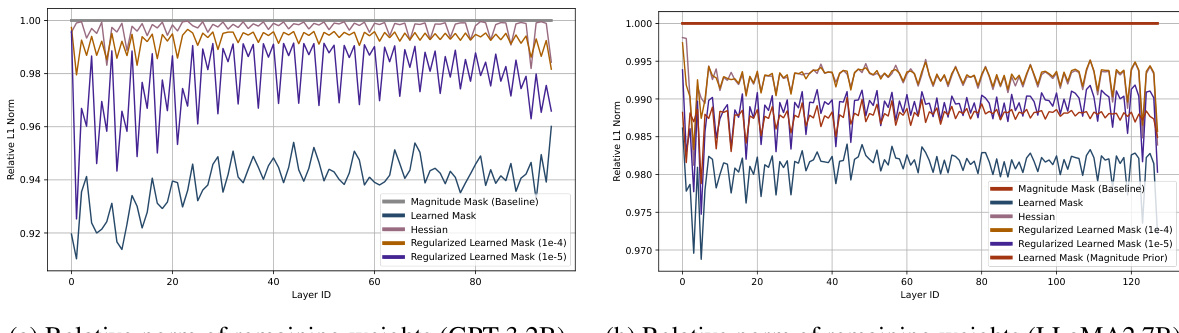
This figure shows the relative L1 norm of pruned weights compared to the magnitude pruning baseline. The subfigures (a) and (b) present the results for GPT-3 2B and LLaMA-2 7B, respectively. The plots compare the L1 norm of weights after different pruning methods: magnitude pruning, learned mask (MaskLLM), Hessian-based pruning, and regularized learned masks with different regularization strengths (1e-4 and 1e-5). The learned mask with a magnitude prior is also included for comparison. The results illustrate that the learned mask method often achieves a lower L1 norm than magnitude pruning, and that weight regularization helps maintain larger magnitudes in the remaining weights.
This figure shows the relationship between the number of training samples used and the resulting perplexity (PPL) on the Wikitext benchmark for the pruned LLaMA-2 7B model. It compares the performance of MaskLLM to SparseGPT. The results demonstrate that MaskLLM is more data-efficient, achieving good performance with fewer samples than SparseGPT. While SparseGPT shows improvement with more samples, the gains diminish beyond a certain point. MaskLLM, on the other hand, continues to improve its performance even with a larger number of samples.

This figure illustrates the concept of learnable N:M sparsity in Large Language Models (LLMs). It shows how MaskLLM learns customized sparsity masks for different tasks (e.g., French, HTML). The general mask, learned from a large dataset, can be transferred to new tasks, enabling efficient sparsity transfer learning. The figure also highlights the speed and memory improvements achieved by using MaskLLM for lossless compression.
More on tables

This table demonstrates the effectiveness of transfer learning when using pre-computed masks as priors for initializing the learnable masks in MaskLLM. It shows the Wikitext-2 Perplexity (PPL) for several large language models (LLMs) using different prior masks (Magnitude, SparseGPT, Wanda) and without a prior. The PPL values for the learned masks illustrate how initializing with a prior can improve the model’s performance and how the end-to-end training refines these initial masks.
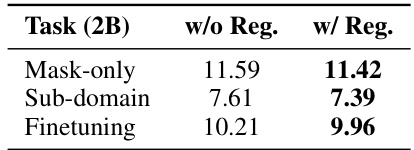
This table shows the impact of sparse weight regularization on the performance of the MaskLLM model across three different scenarios: mask-only evaluation, sub-domain evaluation, and fine-tuning. The ‘w/o Reg.’ column shows results without regularization, while the ‘w/ Reg.’ column presents results with the addition of a regularization term designed to maintain the magnitude of the remaining weights after pruning. The results demonstrate that regularization is beneficial to improving downstream task performance.
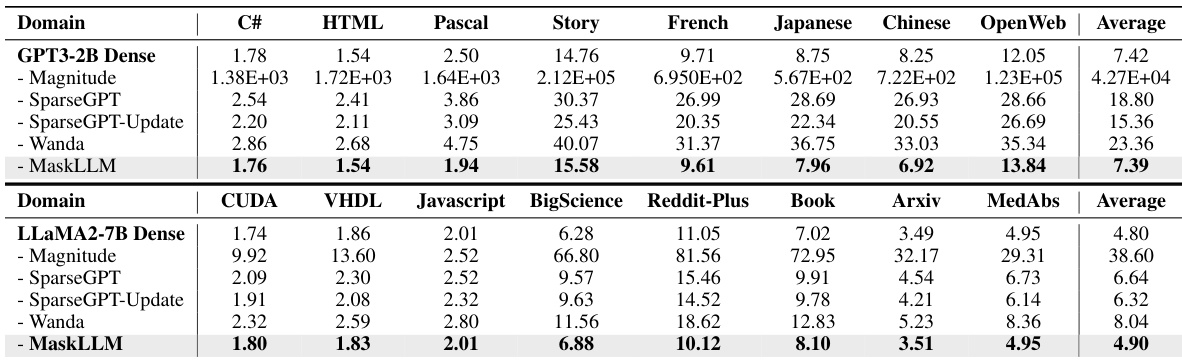
This table presents the results of applying MaskLLM to various downstream tasks with frozen weights. It shows the average task perplexity (PPL) achieved by different methods, including MaskLLM, on several downstream domains (e.g., C#, HTML, Pascal, Story, French, Japanese, Chinese, Open Web, CUDA, VHDL, Javascript, BigScience, Reddit-Plus, Book, Arxiv, MedAbs). The results demonstrate MaskLLM’s ability to learn domain-specific masks and achieve high-quality results even without updating the base model’s weights.

This table presents the average task perplexity (PPL) for different mask types when applied to downstream tasks using a 2B parameter language model. It compares the performance of a dense model (no pruning) to three different approaches for learning sparsity masks: using a general mask learned on a large dataset, learning a separate (scratch) mask for each task, and transferring a pre-learned general mask to each downstream task. The results show that transferring a pre-trained general mask yields comparable performance to the dense model, highlighting the effectiveness of the transfer learning approach implemented in MaskLLM.

This table compares the storage requirements and inference speed of fine-tuning versus using learned 2:4 sparsity masks for downstream tasks using the Llama-2 7B model. Fine-tuning requires 16 bits per parameter and maintains 100% of the model size, resulting in 1.0x speed. In contrast, using learned 2:4 sparsity masks reduces storage to only 0.65 bits per parameter (a 25x reduction) and uses only 73% of the model size in memory. This results in a 1.4x speed improvement.

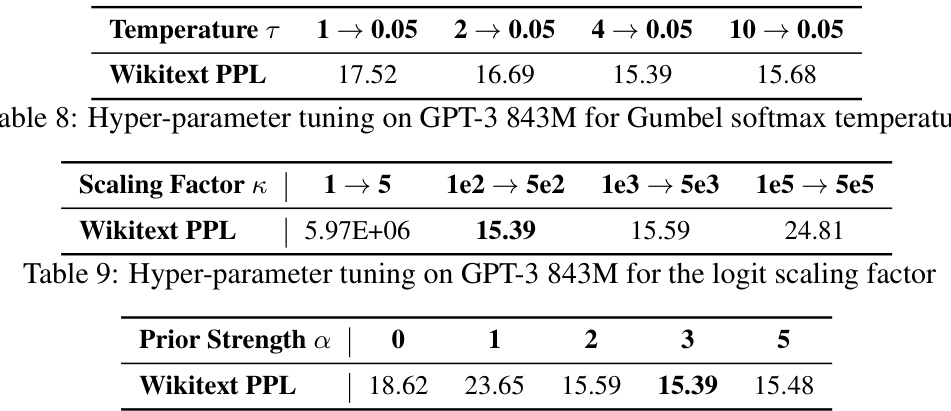
This table lists the training details and hyperparameters used for training the MaskLLM model on various large language models. It shows the optimizer used (AdamW), the number of training steps, the initialization of logits (drawn from a normal distribution), the scaling factor and range for the Gumbel softmax, the temperature range, and the prior strength and sparse regularization used. The parameters were tuned to achieve optimal results for learning high-quality sparsity masks.
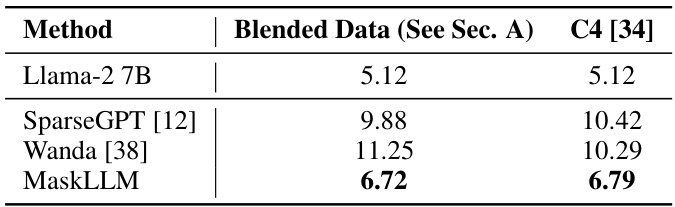
This table compares the performance of MaskLLM against several other methods for achieving 2:4 sparsity in several large language models. The evaluation metrics are perplexity and accuracy on the Wikitext-2 dataset. It highlights MaskLLM’s ability to achieve lower perplexity than other methods while only learning masks and keeping model weights frozen.

This table shows the results of applying different sparsity methods (Magnitude Pruning, SparseGPT, Wanda, and MaskLLM) to the LLaMA-3 8B model with 2:4 sparsity. The Wikitext-2 Perplexity (PPL) is used as a metric to evaluate the performance of the pruned models. The sequence length was 4096 for all experiments. Notably, the MaskLLM method used the SparseGPT mask as a prior. The experiments were conducted using the C4 dataset for both calibration and mask learning.

This table presents the results of evaluating different 2:4 sparsity methods on the Llama-2 7B and 13B, Nemotron-4 15B, and GPT-3 843M and 2B language models. The Wikitext-2 perplexity (PPL) and accuracy on several downstream tasks (HellaSwag, RACE, PIQA, Winogrande, ARC-E, ARC-C, OBQA) are reported for each method. The table compares the performance of MaskLLM against baselines like Magnitude Pruning, SparseGPT, and Wanda, highlighting MaskLLM’s improved performance with frozen weights. Additional results for Llama-3 and other state-of-the-art methods are referenced in the appendix.

This table shows the impact of different levels of sparse weight regularization on the average gradient norm during the first 500 training steps of the GPT-3 2B model. The results indicate that a regularization strength of 1e-5 provides a good balance between gradient stability and avoiding overly restrictive constraints on the search space during mask learning.
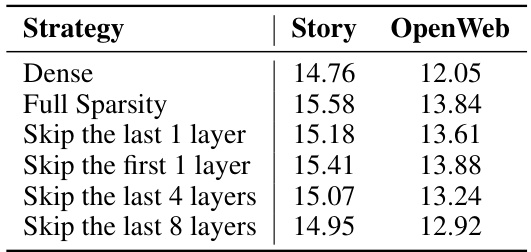
This table compares the proposed MaskLLM method with other state-of-the-art (SOTA) 2:4 pruning methods on the LLaMA-2 13B model. It shows the Wikitext-2 perplexity achieved by each method, indicating the performance of each pruning technique. The table also notes whether each method involves weight updates during the pruning process. MaskLLM demonstrates superior performance, even in comparison to methods that employ weight updates. The results highlight MaskLLM’s effectiveness in achieving high-quality, sparse models.
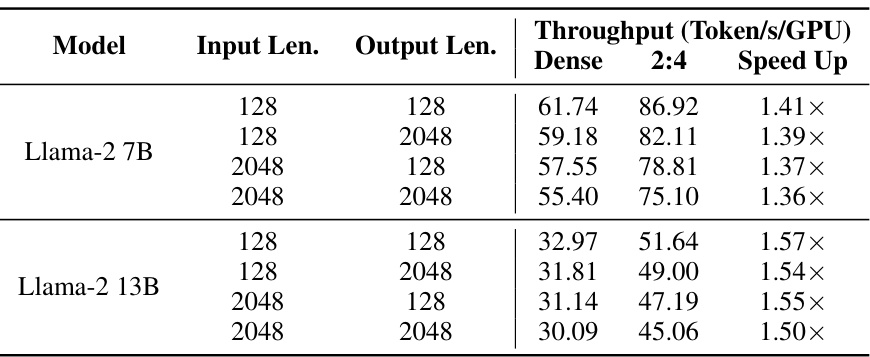
This table presents the benchmark results of LLaMA-2 7B and 13B models with 2:4 sparsity on an A6000 GPU using the TensorRT-LLM framework. It shows the throughput (tokens processed per second) for various input and output sequence lengths, comparing the dense model’s performance to that of the sparse model. The speedup factor is also calculated, demonstrating the performance improvement gained through sparsity.

This table presents the results of applying MaskLLM and several baseline methods for pruning a Vision Transformer (ViT-B/16) model. The top-1 accuracy on the ImageNet-1K dataset is reported for various sparsity patterns (dense, 2:4) and with or without weight updates during pruning. It demonstrates MaskLLM’s ability to achieve high accuracy with sparsity, even surpassing methods that utilize weight updates.
Full paper#