↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Serving large language models (LLMs) quickly and efficiently is crucial for widespread adoption, but the inherent I/O bottleneck in LLM inference creates a significant challenge. Existing speculative decoding methods, while promising, struggle with scalability and robustness across different hyperparameters.
SEQUOIA tackles these issues by introducing a dynamic programming algorithm for constructing optimal token trees, and a novel sampling and verification method. This results in significant speed improvements across various LLMs and hardware, achieving up to 4.04x speedup on an A100 GPU for Llama2-7B and a remarkable 9.5x speedup on an L40 GPU for Llama3-70B-Instruct via offloading. The improved scalability and robustness of SEQUOIA mark a substantial advancement in accelerating LLM inference.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SEQUOIA, a novel and effective algorithm that significantly accelerates large language model (LLM) inference. This is crucial for deploying LLMs in real-world applications, where speed is a major constraint. The research opens up new avenues for investigating efficient tree-based speculative decoding methods and hardware-aware optimization techniques that can improve the efficiency of AI systems.
Visual Insights#
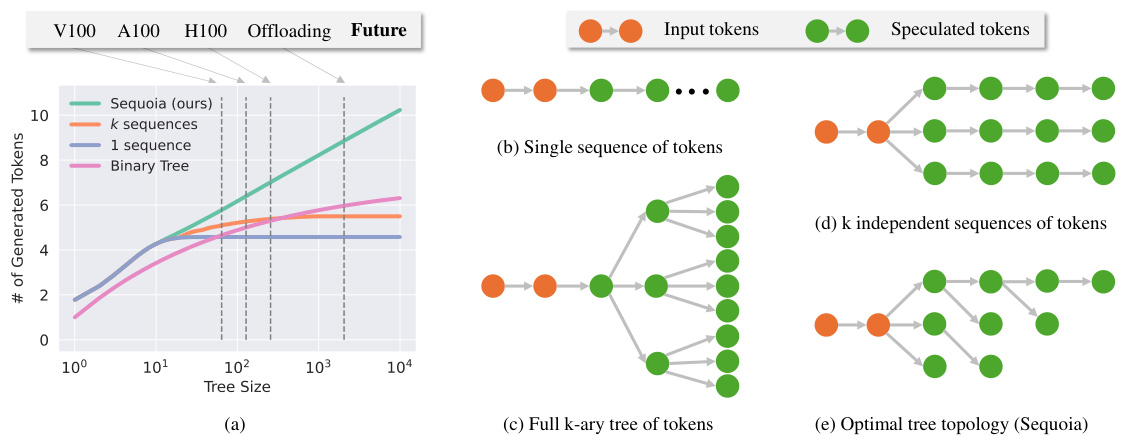
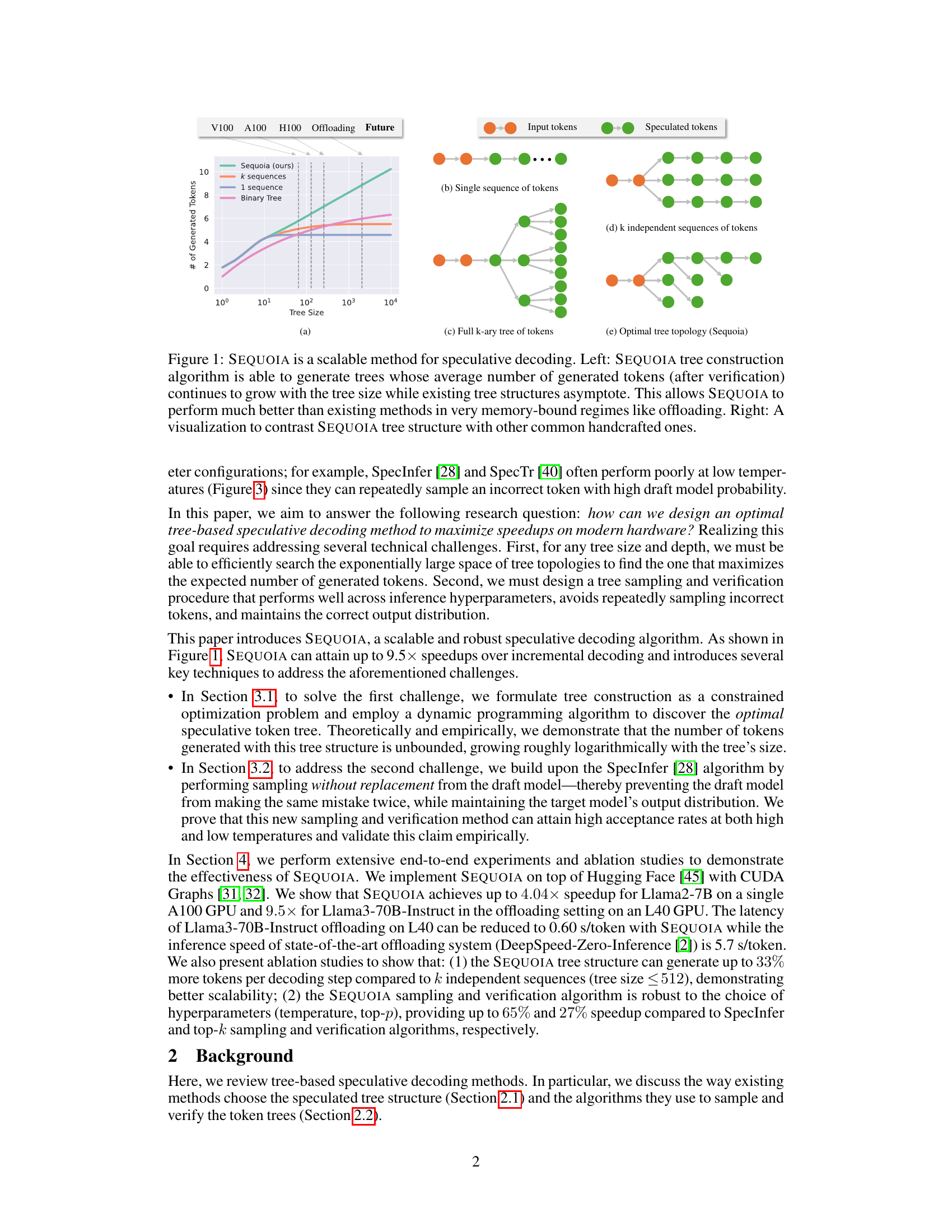
The figure demonstrates the scalability of the SEQUOIA speculative decoding algorithm. The left panel shows that the average number of generated tokens after verification in SEQUOIA trees continues to grow with the tree size, unlike existing methods which asymptote. This improved scalability is particularly beneficial in memory-constrained environments like offloading. The right panel provides a visual comparison of the SEQUOIA tree structure with other common handcrafted structures, highlighting SEQUOIA’s ability to generate significantly larger and more efficient trees.

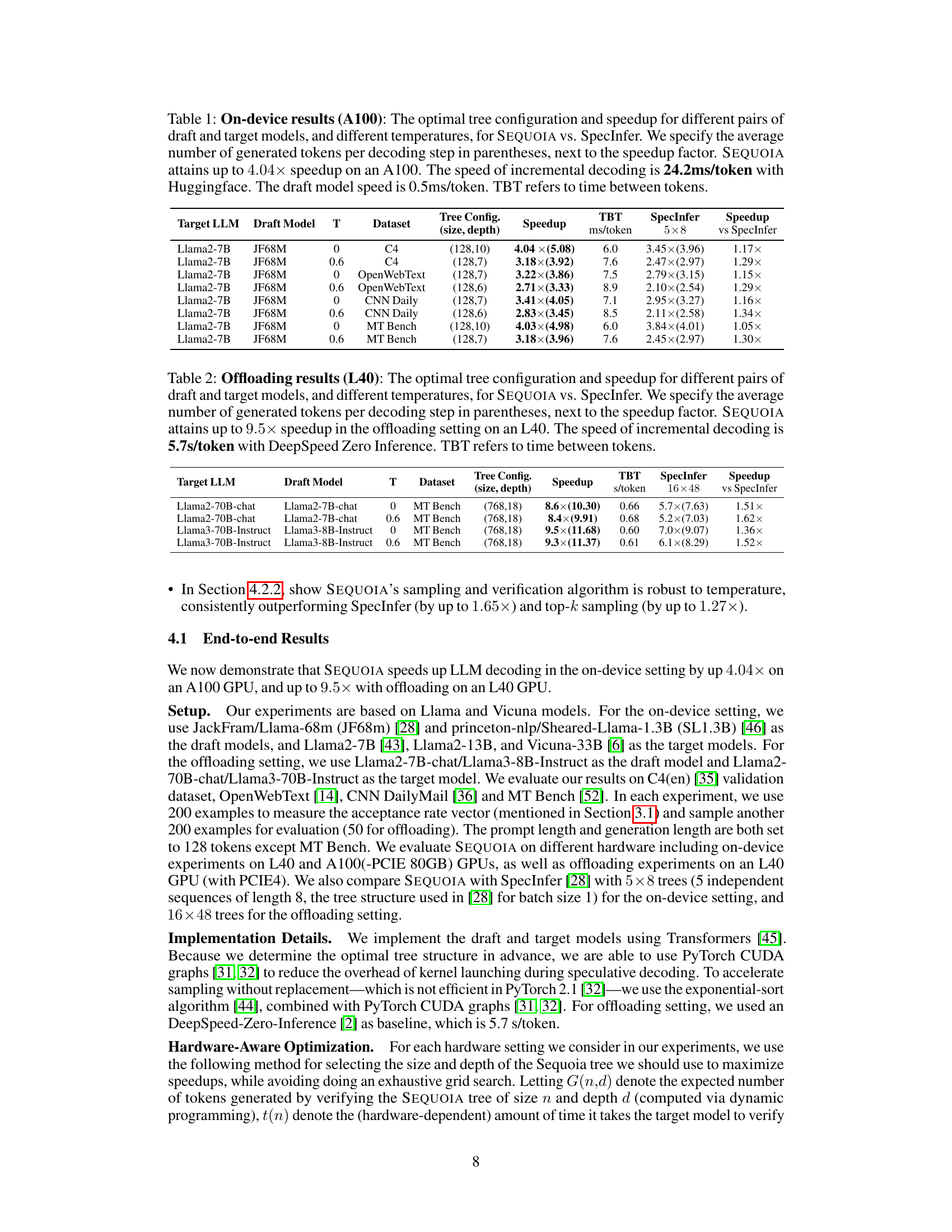
This table presents the experimental results of SEQUOIA and SpecInfer on an A100 GPU. It shows the optimal tree configuration (size and depth), speedup achieved by SEQUOIA compared to SpecInfer, time between tokens (TBT), and the average number of generated tokens per decoding step for various combinations of draft and target language models and different temperatures. The baseline speed of incremental decoding using HuggingFace is also provided, along with the draft model’s speed.
In-depth insights#
Scalable Speculative Decoding#
Scalable speculative decoding tackles the challenge of efficiently serving large language models (LLMs) by predicting multiple token sequences in parallel, rather than generating tokens sequentially. This approach significantly reduces latency, but existing methods struggle with scaling to larger speculation budgets and adapting to diverse hyperparameters. A key innovation is to dynamically construct an optimal tree structure to represent the speculated tokens using dynamic programming, optimizing the balance between exploration and exploitation. This contrasts with earlier methods that often use less efficient, predetermined tree structures. A robust verification method is also developed, employing sampling without replacement to enhance the accuracy of token selection across various decoding temperatures, preventing repeated sampling of incorrect tokens. This approach exhibits superior scalability and robustness, delivering substantial speed improvements for several LLMs and different hardware platforms. Overall, the improved scalability and robustness of speculative decoding make it a much more practical approach for significantly accelerating LLM inference in real-world applications.
Dynamic Programming#
Dynamic programming, in the context of a research paper, likely refers to an algorithmic technique used to solve complex problems by breaking them down into smaller, overlapping subproblems. The core idea is to avoid redundant computations by storing and reusing solutions to the subproblems. This is particularly valuable when dealing with problems exhibiting optimal substructure, meaning an optimal solution to the overall problem can be constructed from optimal solutions to its subproblems. A key aspect is the creation of a recursive relationship or recurrence relation that defines how subproblem solutions combine to form the overall solution. This relation is central to the algorithm’s efficiency. The algorithm then proceeds by solving these subproblems systematically, usually in a bottom-up fashion, starting with the smallest and working its way to larger subproblems, while storing solutions in a table or memoization structure. This approach dramatically reduces computation time compared to naive recursive solutions, which can lead to exponential growth due to repeated calculations. The effectiveness of dynamic programming relies on the efficient identification and organization of subproblems and the accurate definition of the recurrence relation. The space complexity is often affected by the size of the solution table.
Robust Sampling#
Robust sampling in the context of large language model (LLM) decoding focuses on reliable and efficient token selection from a probability distribution, particularly in the face of varying hyperparameters or model behaviors. A robust sampling method should be insensitive to temperature adjustments, maintaining the intended output distribution even at low temperatures. It should also exhibit high acceptance rates, minimizing the rejection of correctly speculated tokens and maximizing throughput. Addressing potential biases in the draft model’s predictions is crucial, preventing the repeated sampling of incorrect tokens and thus enhancing the overall efficiency and accuracy of speculative decoding. The methods’ effectiveness is often evaluated by comparing acceptance rates across different temperature settings and considering the final token selection quality and decoding speed. Theoretical guarantees on the properties of the method, such as maintaining the output distribution and bounds on rejection rates, can offer significant insights into robustness and reliability, ultimately improving the efficiency and speed of LLM inference. Finally, a robust sampling technique will ideally be scalable to larger model sizes and increased speculation budgets, adapting efficiently to resource constraints and maintaining high performance.
Empirical Validation#
An Empirical Validation section in a research paper would typically present evidence supporting the claims made earlier. In the context of a paper on speculative decoding for LLMs, this section might involve experiments comparing the performance of the proposed method (SEQUOIA) against existing techniques. Key aspects of the validation would include measuring the average number of generated tokens per decoding step, evaluating speedups achieved compared to baselines (e.g., incremental decoding and other speculative decoding methods), and assessing robustness across various inference hyperparameters (temperature, top-p). The experiments would likely be conducted on multiple LLMs of varying sizes and across different datasets, allowing for a robust assessment of scalability and generalization capabilities. Visualizations such as graphs showing the logarithmic growth of generated tokens for SEQUOIA compared to the asymptotic behavior of others would be expected, reinforcing the scalability claim. Quantitative results demonstrating consistent speedups, perhaps broken down by LLM size or hyperparameter, would solidify the claims. Statistical significance should also be considered, ensuring that observed improvements are not merely due to chance. Overall, a robust empirical validation would demonstrate SEQUOIA’s effectiveness, scalability, and robustness, making a strong case for its adoption.
Future Directions#
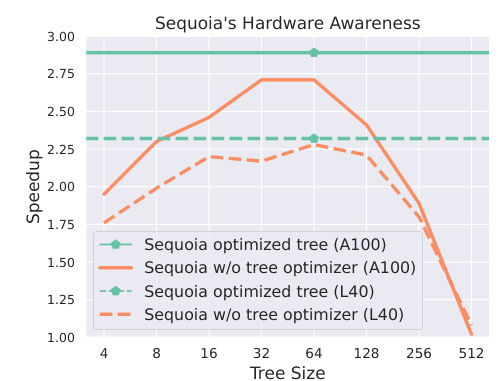
Future research could explore several avenues. Improving the scalability of SEQUOIA to even larger LLMs and more complex hardware architectures is crucial. Addressing the computational cost of finding optimal tree structures for various model-hardware combinations is important. Investigating different draft model strategies could enhance the performance and robustness of the speculative decoding approach. Exploring alternate sampling and verification methods beyond the current dynamic programming and sampling-without-replacement could lead to further speed improvements or better robustness. Analyzing the theoretical limits of speculative decoding and identifying fundamental bottlenecks is also key. Combining speculative decoding with other LLM optimization techniques (quantization, pruning, etc.) could yield significant synergistic gains. Finally, developing hardware-specific implementations of SEQUOIA could further accelerate inference and unlock new possibilities.
More visual insights#
More on figures
The figure on the left shows the average number of generated tokens after verification for different tree construction methods. SEQUOIA’s performance continues to grow with the tree size, while other methods such as the use of k independent sequences or binary trees reach a plateau. This demonstrates SEQUOIA’s scalability, particularly beneficial in memory-constrained settings like offloading. The figure on the right provides a visual comparison of SEQUOIA’s tree structure with other common structures, highlighting its unique topology.
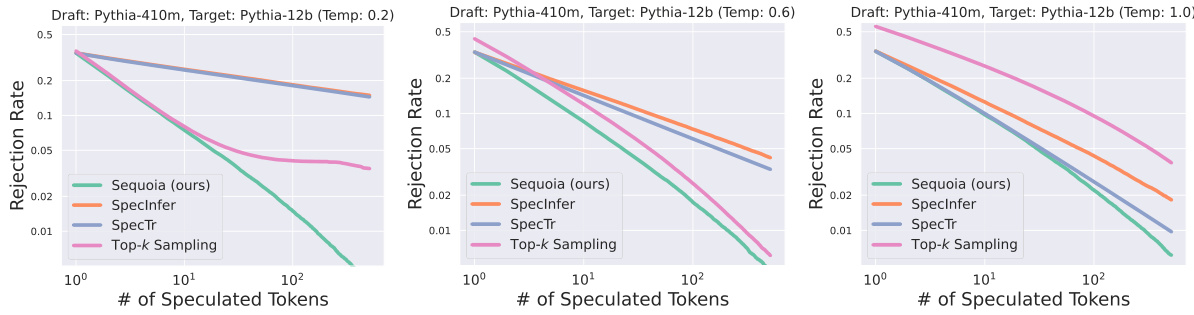
This figure compares the rejection rates of four different verification algorithms (SEQUOIA, SpecInfer, SpecTr, and Top-k Sampling) across three different temperature settings (0.2, 0.6, and 1.0). The x-axis represents the number of speculated tokens, and the y-axis represents the average rejection rate. The figure shows that SEQUOIA consistently achieves the lowest rejection rates across all temperature settings and exhibits a power-law acceptance rate. This indicates that SEQUOIA’s sampling and verification strategy is robust and effective at various temperatures.
This figure compares SEQUOIA’s tree construction algorithm with existing methods for speculative decoding. The left side shows that SEQUOIA generates trees with an average number of verified tokens that increases with tree size, unlike existing methods which plateau. This scalability is particularly advantageous in memory-constrained environments like offloading. The right side visually contrasts SEQUOIA’s tree structure with simpler structures used by other methods, highlighting the key difference in topology that leads to SEQUOIA’s improved performance.
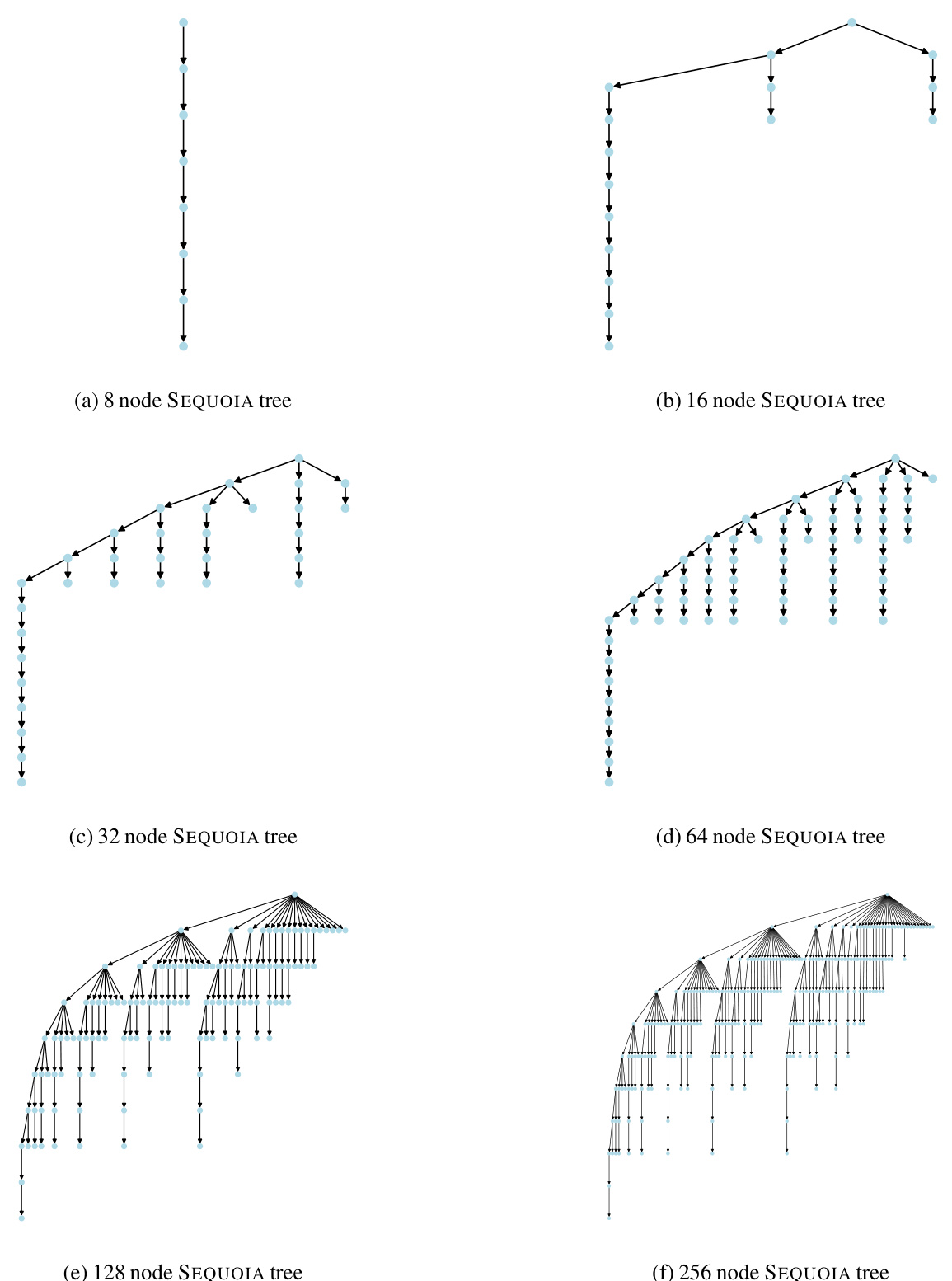
The figure demonstrates the scalability of the SEQUOIA algorithm for speculative decoding. The left panel shows that the average number of generated tokens after verification in SEQUOIA trees continues to increase with the size of the tree, unlike existing methods. This scalability is particularly beneficial in memory-constrained environments such as offloading. The right panel visually compares the SEQUOIA tree structure with other common tree structures.
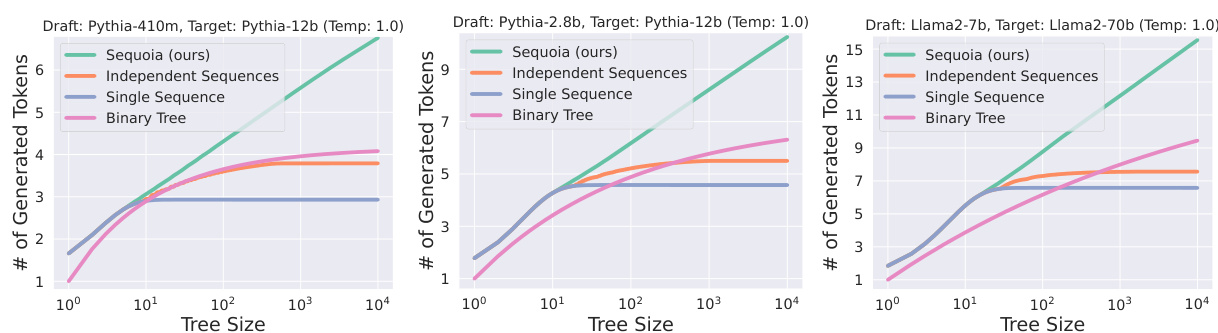
The figure shows that SEQUOIA’s tree construction algorithm outperforms other methods by generating trees whose average number of verified tokens grows with the tree size, unlike existing methods that asymptote. This scalability advantage is particularly beneficial in memory-constrained environments such as offloading. The right side visually compares SEQUOIA’s tree structure to other common structures, highlighting its unique ability to grow unboundedly with tree size.
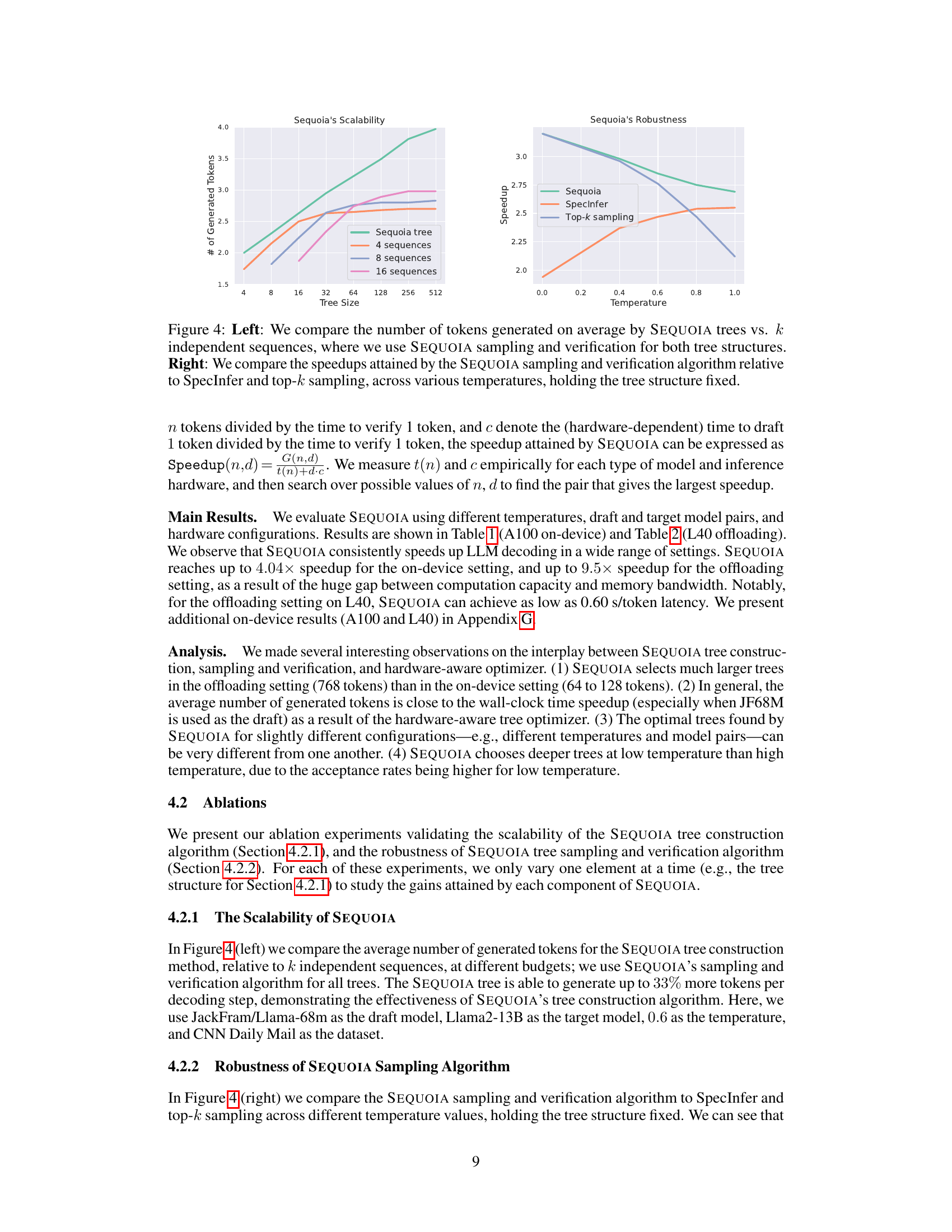
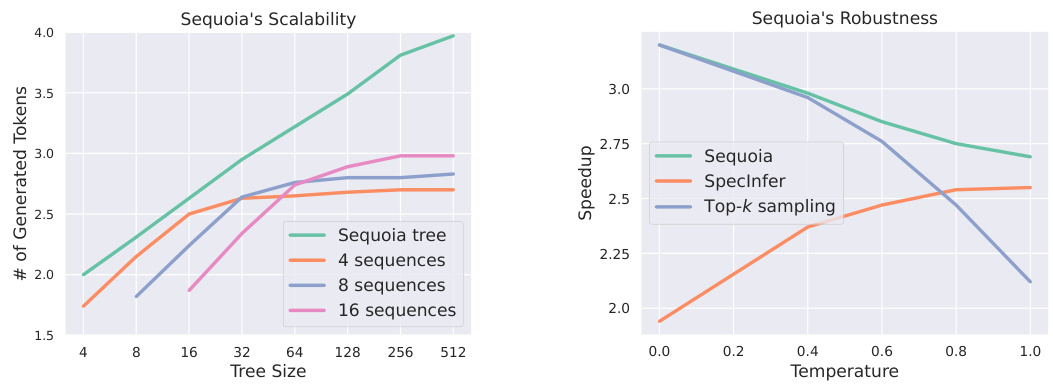
This figure demonstrates two key aspects of the SEQUOIA algorithm. The left panel shows the scalability of SEQUOIA’s tree construction method by comparing the average number of generated tokens for SEQUOIA trees versus k independent sequences of tokens (with the same sampling and verification methods). It highlights that SEQUOIA trees generate more tokens as their size increases, unlike other methods that reach a plateau. The right panel showcases the robustness of the SEQUOIA sampling and verification algorithm across different temperature settings, comparing its performance against SpecInfer and top-k sampling methods. It indicates that SEQUOIA consistently achieves higher speedups across various temperatures.
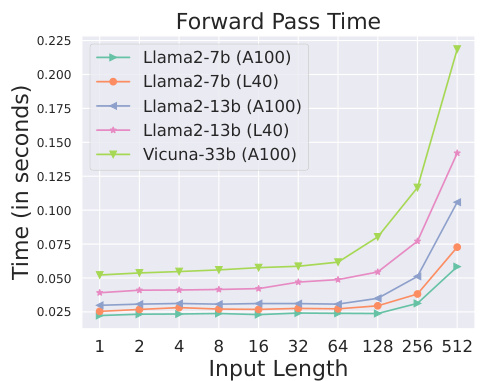
This figure shows the forward pass time (in seconds) for different large language models (LLMs) and hardware configurations (A100 and L40 GPUs) as a function of the input length (number of tokens). The plot helps in determining the optimal tree size for SEQUOIA’s speculative decoding algorithm by considering the tradeoff between the time spent on the draft model and the time for verification on the target model. It highlights the importance of hardware-aware optimization. As the input length increases, the forward pass time increases, particularly significantly for larger models and less memory-bound hardware. This is because the I/O cost of processing tokens becomes more significant with larger input lengths. The lines show that the growth rate is hardware dependent.
More on tables
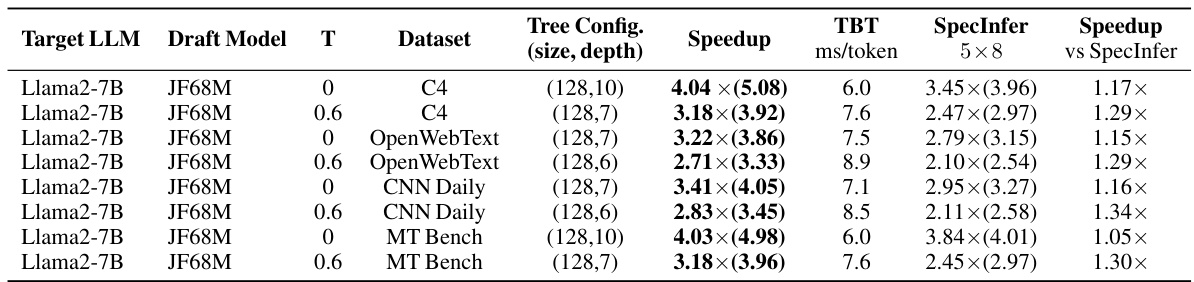
This table presents the results of on-device experiments conducted on an A100 GPU, comparing the performance of SEQUOIA and SpecInfer. The table shows the optimal tree configuration (size and depth) for each model and temperature combination, the speedup achieved by SEQUOIA compared to SpecInfer, the time between tokens (TBT), and the average number of tokens generated per decoding step. The results highlight SEQUOIA’s improved speed, showing speedups of up to 4.04x. Note that incremental decoding speed and draft model speed are provided for context.

This table shows the performance of SEQUOIA and SpecInfer on an L40 GPU in an offloading setting. It presents speedup factors for different LLMs (Llama2-70B-chat, Llama3-70B-Instruct) using various draft models at different temperatures. The speedup is relative to incremental decoding using DeepSpeed Zero Inference. The table also provides the optimal tree configuration (size and depth) used by SEQUOIA for each experiment, and the average number of tokens generated per decoding step.
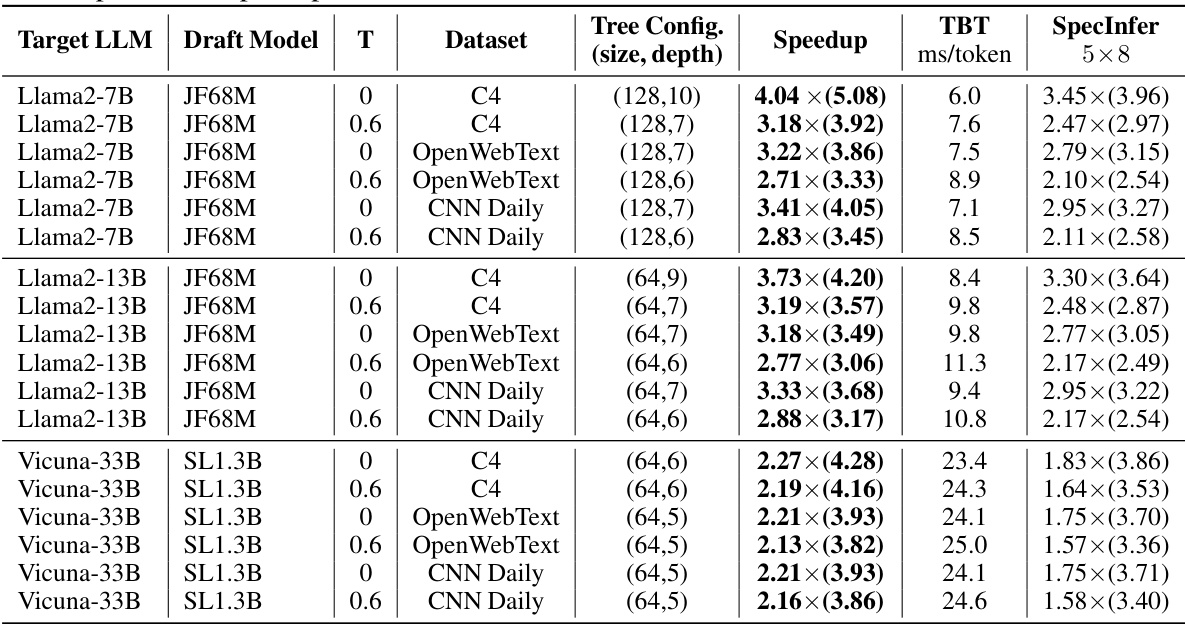
This table presents the results of on-device experiments conducted on an A100 GPU. It compares the performance of SEQUOIA and SpecInfer for various large language models (LLMs) at different temperatures. The table shows the optimal tree configuration (size and depth) used for SEQUOIA, the speedup achieved by SEQUOIA compared to SpecInfer, and the time between tokens (TBT) for both methods. The average number of generated tokens per decoding step is also provided for both SEQUOIA and SpecInfer.
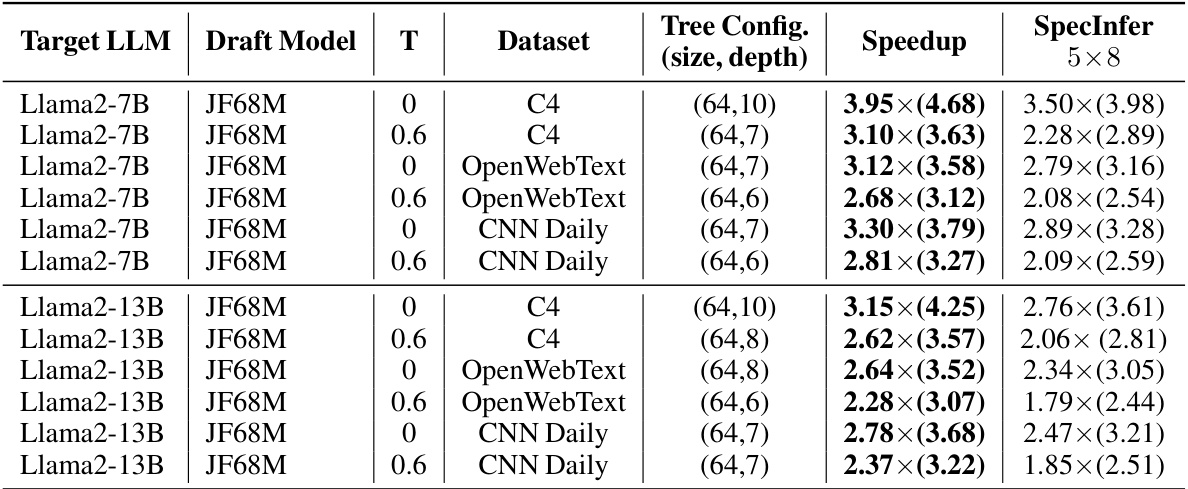
This table presents the results of on-device experiments conducted on an A100 GPU. It compares the performance of the SEQUOIA algorithm against SpecInfer for various Large Language Models (LLMs). The table shows the optimal tree configuration (size and depth) determined by SEQUOIA, the achieved speedup compared to SpecInfer, and the average number of generated tokens per decoding step for different models, temperatures, and datasets. The speedup values represent the improvement in decoding speed achieved by SEQUOIA compared to SpecInfer. The numbers in parentheses represent the average number of tokens generated per decoding step by SEQUOIA.
This table presents the on-device (A100 GPU) experimental results comparing SEQUOIA and SpecInfer. It shows the optimal tree configuration (size and depth), speedup achieved by SEQUOIA relative to SpecInfer, time between tokens (TBT), and the average number of generated tokens per step for various model pairs (Llama2-7B, Llama2-13B) and different temperatures. The baseline incremental decoding speed and draft model speed are also provided.
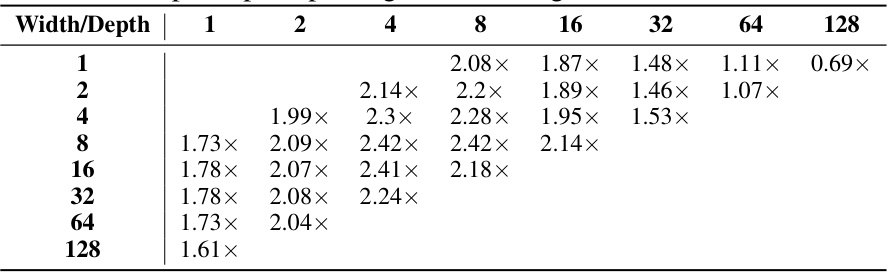
This table shows the speedups achieved by SpecInfer for various tree configurations in stochastic decoding using Llama2-7B as the target model and JF68M as the draft model on the C4 dataset. It highlights that SEQUOIA’s speedup of 3.18x surpasses all of SpecInfer’s configurations.

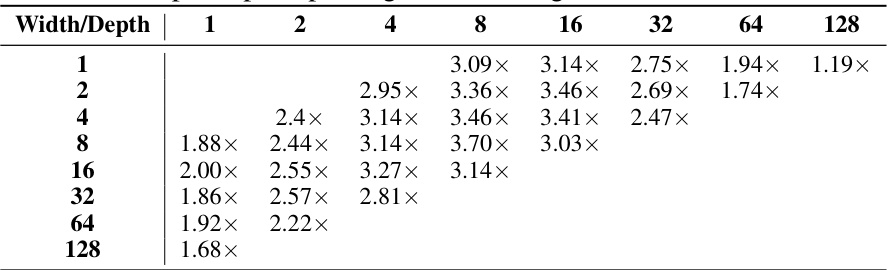
This table shows the speedup achieved by SpecInfer for various tree configurations in the L40 offloading setting using Llama2-7B-chat as the draft model and Llama2-70B-chat as the target model, evaluated on the MT-Bench dataset. It highlights the performance difference between SEQUOIA and SpecInfer across various tree structures (width and depth).

This table compares the robustness of three different sampling and verification algorithms (SEQUOIA, SpecInfer, and top-k sampling) to variations in the top-p hyperparameter. It reports the total speedup achieved by each algorithm on an A100 GPU, showing the average number of generated tokens in parentheses. The experiment kept the tree structure consistent across all three algorithms and used JF68M as the draft model and Llama2-7B as the target model.
Full paper#