↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current few-shot 3D point cloud segmentation methods struggle with low prototype quality due to limited semantic information and class bias. This paper introduces Generated and Pseudo Content guided Prototype Refinement (GPCPR), a novel framework that uses Large Language Models (LLMs) to generate richer semantic descriptions, improving prototype quality and reducing class information bias. Furthermore, a dual-distillation technique further enhances the refinement process.
GPCPR addresses the issues by incorporating LLM-generated content to enrich prototypes with comprehensive semantic knowledge. It also leverages pseudo-query contexts to mitigate class information bias. Experiments show that GPCPR outperforms existing methods by a significant margin on standard benchmarks (S3DIS and ScanNet), achieving up to 12.1% and 13.75% mIoU improvement, respectively. This demonstrates the effectiveness of the proposed method in improving the accuracy and reliability of few-shot 3D point cloud segmentation.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances few-shot 3D point cloud segmentation, a crucial task in various applications. By leveraging LLMs and pseudo-query context, it surpasses state-of-the-art methods, opening new avenues for research in this active field. The enhanced prototype refinement technique can inspire related research in other few-shot learning domains. The introduction of dual-distillation regularization offers a novel refinement technique which can improve other meta-learning tasks. Its superior performance and innovative approach make it highly relevant to researchers working on improving the efficiency and accuracy of 3D data analysis.
Visual Insights#

This figure provides a comprehensive overview of the proposed GPCPR framework for few-shot 3D point cloud segmentation. It illustrates the data flow, highlighting the three main stages: Prototype Generation, Generated Content-guided Prototype Refinement (GCPR), and Pseudo Query Context-guided Prototype Refinement (PCPR). The diagram visually explains how the support set and query set are processed, with particular emphasis on the integration of LLM-generated content and the dual-distillation mechanism for refining prototypes and improving prediction accuracy. The support and query flows are clearly distinguished.

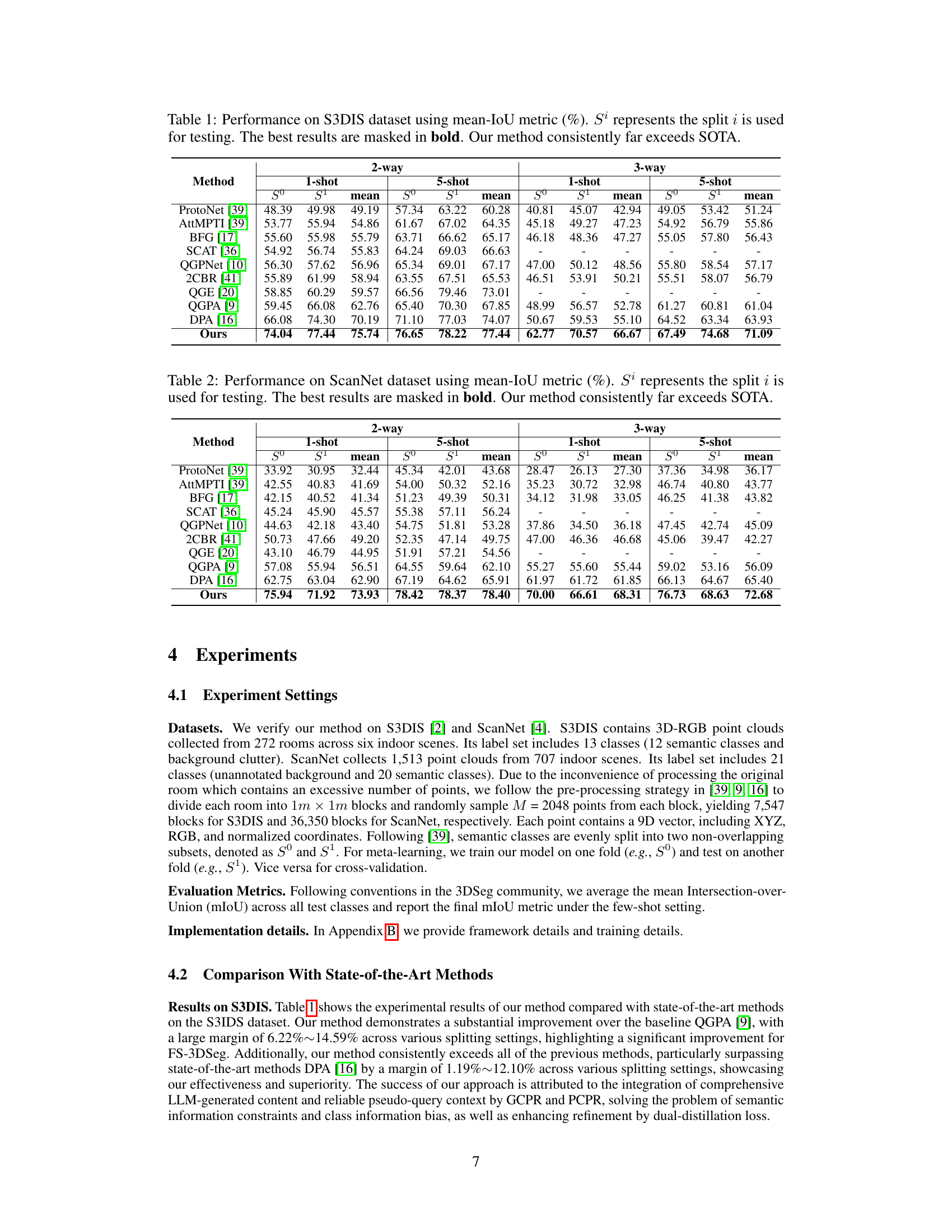
This table presents the performance comparison of different few-shot 3D point cloud segmentation methods on the S3DIS dataset. The mean Intersection over Union (mIoU) is used as the evaluation metric. Results are shown for 2-way and 3-way classification tasks, with both 1-shot and 5-shot learning settings. The table highlights the superiority of the proposed GPCPR method over state-of-the-art (SOTA) approaches.
In-depth insights#
Proto Refinement#
The core concept of ‘Proto Refinement’ revolves around enhancing the quality and effectiveness of prototypes utilized in few-shot learning, particularly within the context of 3D point cloud segmentation. Low-quality prototypes, often stemming from limited training data or class imbalances, hinder accurate segmentation. The proposed refinement methods leverage large language models (LLMs) to generate richer semantic descriptions of classes, thereby enriching the prototypes with more comprehensive knowledge. This addresses the semantic information constraints inherent in limited support sets. Furthermore, a pseudo-query context mechanism is introduced, leveraging reliable information from the query set to mitigate class information bias. This dual approach, coupled with a dual-distillation regularization, effectively refines prototypes, enabling more accurate segmentation of query point clouds even with limited labeled data. The overall strategy is designed to achieve better generalization and more robust performance in few-shot scenarios.
LLM-driven GCPR#
The heading “LLM-driven GCPR” suggests a method that leverages Large Language Models (LLMs) to refine prototypes within a Generative Content guided Prototype Refinement (GCPR) framework. This likely involves using LLMs to generate richer, more nuanced descriptions of different classes, going beyond simple feature vectors. The LLM-generated content could offer semantic understanding, providing contextual information to enhance the discriminative power of the prototypes. This approach addresses the limitations of traditional prototype-based methods, which often struggle with limited data and noisy features. By incorporating the knowledge and reasoning capabilities of LLMs, the method aims to improve the quality and generalizability of prototypes, leading to improved performance in downstream tasks such as segmentation. This innovative fusion of LLMs and GCPR highlights the potential of integrating natural language processing with computer vision, offering a promising direction for improving few-shot learning in complex domains.
PCPR:Pseudo Context#
The proposed PCPR (Pseudo Query Context-guided Prototype Refinement) module cleverly addresses the challenge of class information bias in few-shot point cloud segmentation. Standard prototype-based methods often struggle because the features of support and query sets aren’t perfectly aligned. PCPR ingeniously leverages pseudo masks generated from early prototype predictions to extract class-specific context from the query point cloud. This contextual information acts as a filter, removing noise and focusing on relevant features for prototype refinement. By integrating this refined context, PCPR generates more accurate, query-specific prototypes, leading to improved segmentation performance. The method’s strength lies in its ability to create more robust and adaptable prototypes capable of handling variations within and between classes. This approach is particularly significant in few-shot settings where limited annotated data makes reliable prototype generation challenging.
Dual-Distillation#
The concept of ‘Dual-Distillation’ in the context of few-shot 3D point cloud segmentation is a clever regularization technique. It leverages the idea of knowledge transfer between different stages of the prototype refinement process. By distilling knowledge from early-stage, less refined prototypes (or predictions) to their more refined counterparts (teacher prototypes), the network learns to better integrate disparate sources of semantic information. This bidirectional flow of information, encompassing both prototype and prediction distillation, is key to enhancing the overall refinement process. Prototype distillation ensures consistency and knowledge transfer between early and late-stage representations of point cloud features and prototypes. Prediction distillation, focusing on pseudo-masks, refines the pseudo predictions by aligning early predictions with the more accurate final predictions, further improving the quality of class-specific query context. This dual-distillation approach elegantly addresses the challenge of limited semantic information and class information bias often encountered in few-shot learning, leading to superior segmentation performance.
Future Works#
The authors acknowledge limitations, primarily concerning the computational cost of using LLMs and the potential for biased or inaccurate LLM-generated content to negatively affect model performance. Future work should focus on mitigating these limitations. This could involve exploring more efficient LLM prompting strategies or incorporating techniques to enhance the reliability and diversity of LLM outputs. Investigating alternative methods for generating class descriptions, potentially leveraging other large language models or knowledge bases, would also be valuable. Furthermore, analyzing the impact of different hyperparameter settings on model performance is necessary, optimizing the balance between computational cost and accuracy. Addressing the scalability of the proposed method to handle larger datasets and a higher number of classes is crucial for practical applications. Finally, exploring the potential of applying similar techniques to other few-shot learning tasks and different data modalities would expand the impact and generalizability of the research.
More visual insights#
More on figures

This figure shows a qualitative comparison of the proposed method’s performance against the QGPA method and ground truth (GT) on the S3DIS and ScanNet datasets. The results are for a 2-way 1-shot Sº segmentation task, meaning only one example from each of two classes is used in the support set for the segmentation of the query point clouds. The figure visually demonstrates the superior segmentation accuracy of the proposed method compared to the baseline QGPA method.

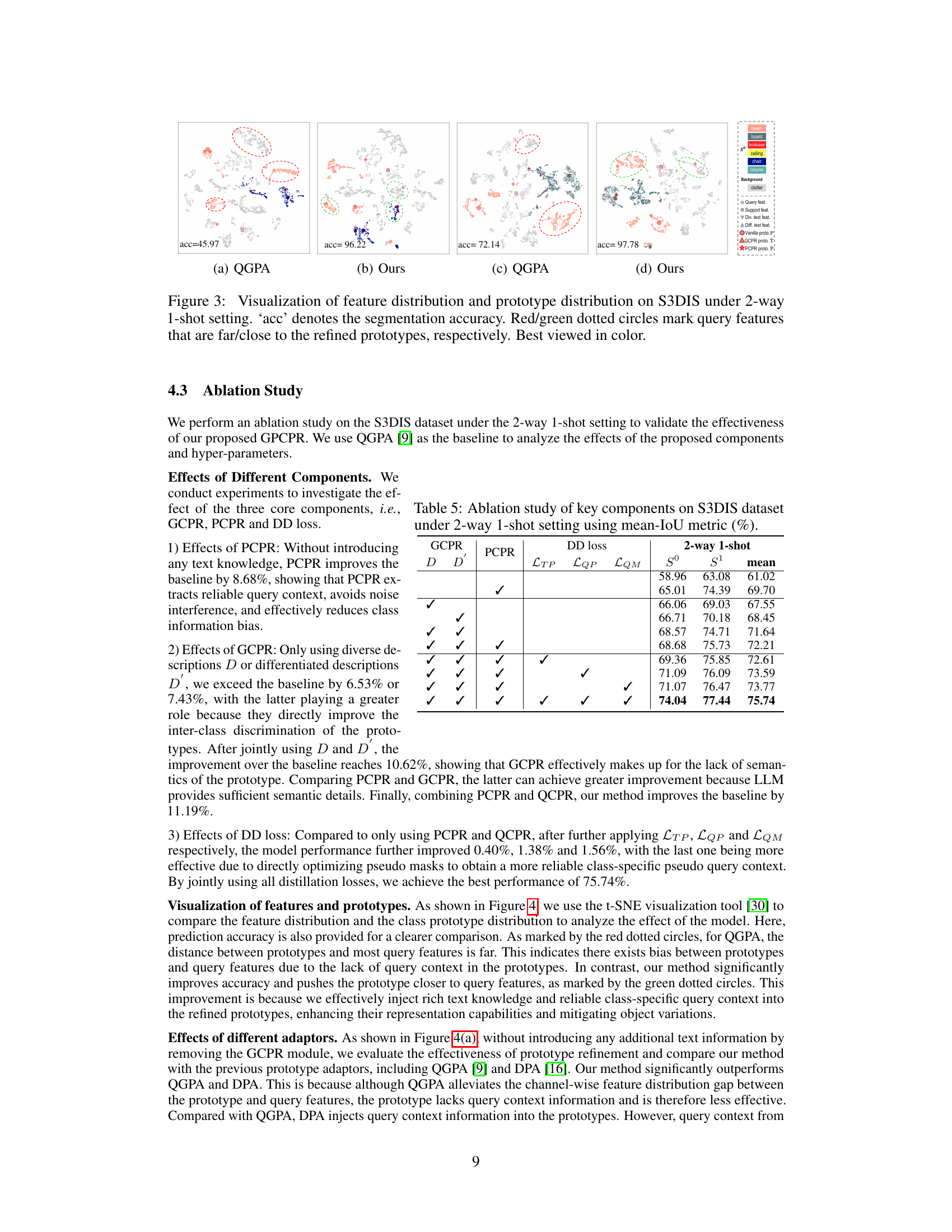
This figure visualizes the feature and prototype distributions using t-SNE for both the baseline method (QGPA) and the proposed method (Ours) on the S3DIS dataset under a 2-way 1-shot setting. The accuracy of each method is indicated. Red dotted circles highlight query features distant from the prototypes, while green circles indicate query features close to the prototypes. The visualization demonstrates how the proposed method effectively improves prototype quality, leading to better alignment between prototypes and query features.
This figure visualizes the feature and prototype distributions on the S3DIS dataset for a 2-way 1-shot setting. It compares the baseline method (QGPA) with the proposed method (Ours). The visualization uses t-SNE to reduce dimensionality. Red circles highlight query features far from refined prototypes, while green circles indicate features close to them. The accuracy (‘acc’) of each method is shown, demonstrating improved accuracy with the proposed method due to more effectively incorporating text knowledge and reliable query context into prototypes, thus reducing the distribution gap between prototypes and query features.

This figure presents a detailed overview of the proposed framework, GPCPR, which is composed of two main parts: the support flow and the query flow. The support flow involves prototype generation, GCPR, and PCPR for refining prototypes by incorporating LLM-generated text descriptions and pseudo query contexts. The query flow uses the refined prototypes to predict segmentation results. Dual-distillation regularization is used to further enhance the refinement process.

This figure illustrates the architecture of the proposed framework GPCPR. It shows the data flow from the support set and query set through various modules, including a point encoder, prototype generation, LLM-driven content refinement (GCPR), pseudo-query context refinement (PCPR), and a dual-distillation process. The support set is processed to generate prototypes which are then refined using both LLM-generated content and pseudo-query information to improve quality. Finally, query features are compared with the refined prototypes using cosine similarity to predict the segmentation mask.
More on tables

This table presents the results of the proposed method and other state-of-the-art methods on the ScanNet dataset. The mean Intersection over Union (mIoU) metric is used to evaluate the performance of different semantic segmentation methods. The results are shown for both 2-way and 3-way few-shot settings, with 1-shot and 5-shot scenarios for each way. The table highlights the consistent superiority of the proposed method over existing methods, showcasing its significant improvement in accuracy.

This table shows the time taken for two phases of the offline process: Description Generation using the GPT-3.5-turbo model and Text Feature Extraction using the CLIP rn50 model. The total time is also provided. The results are shown separately for the S3DIS and ScanNet datasets, indicating a substantially longer processing time for ScanNet compared to S3DIS.

This table presents a comparison of the online computational cost and experimental results for four different methods (AttMPTI, QGPA, DPA, and the proposed method) under a 2-way 1-shot setting. The metrics shown are the number of parameters (#Params), floating point operations (FLOPs), frames per second (FPS), inference time, and mean Intersection over Union (mIoU) on both the S3DIS and ScanNet datasets. It highlights the trade-off between computational cost and performance, showing that the proposed method achieves superior performance (highest mIoU) with a reasonable computational cost.
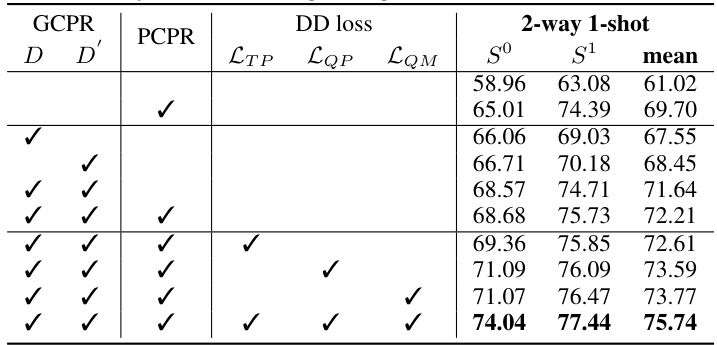
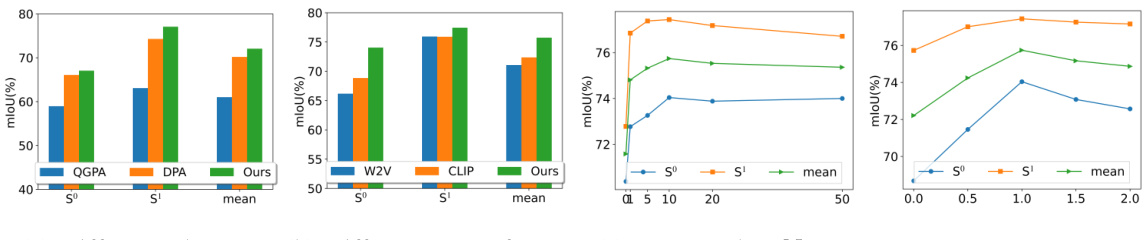
This table presents the results of an ablation study conducted on the Stanford Large-Scale 3D Indoor Spaces (S3DIS) dataset. The study investigates the impact of different components of the proposed method (Generated and Pseudo Content guided Prototype Refinement, or GPCPR) on the mean Intersection over Union (mIoU) metric for a 2-way 1-shot segmentation task. The components evaluated include the use of LLM-generated diverse descriptions (D), LLM-generated differentiated descriptions (D’), Pseudo Query Context-guided Prototype Refinement (PCPR), and the dual-distillation loss (DD loss) with its three components: prototype distillation (LTP), pseudo query distillation (LQP), and logit distillation (LQM). The table shows how the inclusion of each component affects the performance, measured by the mIoU, on both the S0 and S1 splits of the dataset.

This table shows the performance comparison of using different LLMs (gpt-3.5-turbo and gpt-40-mini) in the proposed GPCPR framework on the S3DIS dataset under the 2-way 1-shot setting. The results are presented in terms of mean IoU (%), and the comparison includes the state-of-the-art methods attMPTI, QGPA, and DPA. The table demonstrates the impact of different LLMs on the overall performance of the proposed method.
Full paper#