↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Large language models (LLMs) excel at various tasks but struggle with learning and effectively utilizing new factual information. Existing LLMs often rely on simple word relationships (co-occurrence) rather than true understanding of facts, limiting their ability to reason and generalize beyond simple question answering. This shortcoming hinders their real-world applicability where complex reasoning and novel information processing is required.
This research investigates this problem, showing that LLMs encode co-occurrence statistics in the middle layers and true factual associations in the lower layers of their architecture. The researchers propose two novel methods: using training data where facts are implicitly conveyed, and actively “forgetting” co-occurrence statistics during training. These strategies are shown to improve LLMs’ ability to generalize newly learned factual knowledge to more complex reasoning tasks, such as indirect and multi-hop question answering, demonstrating considerable advancement in factual knowledge learning for LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a critical limitation of current language models: over-reliance on superficial word co-occurrence instead of genuine factual understanding. This finding opens avenues for improving knowledge acquisition in language models, impacting various downstream applications. The proposed strategies for enhanced factual learning are directly applicable to current research, promoting more robust and reliable models.
Visual Insights#

This figure shows the comparison and negation ratios for three different language models (LLaMA 3 8B, LLaMA 3 70B, and Gemma 7B) after they were fine-tuned on synthetic datasets. The comparison ratio measures how much more likely the model is to predict the correct factual association versus an incorrect one, while the negation ratio measures how likely the model is to predict the correct association even when the statement is negated. The results indicate that models trained on text with explicit co-occurrence statistics perform well on the comparison ratio but poorly on the negation ratio, while models trained on text with implicit associations perform well on both. This suggests that the former learn co-occurrence statistics whereas the latter learn true factual associations. The x-axis shows the type of training data used (Narrative or Referencing). The y-axis represents the log likelihood ratio (comparison or negation).
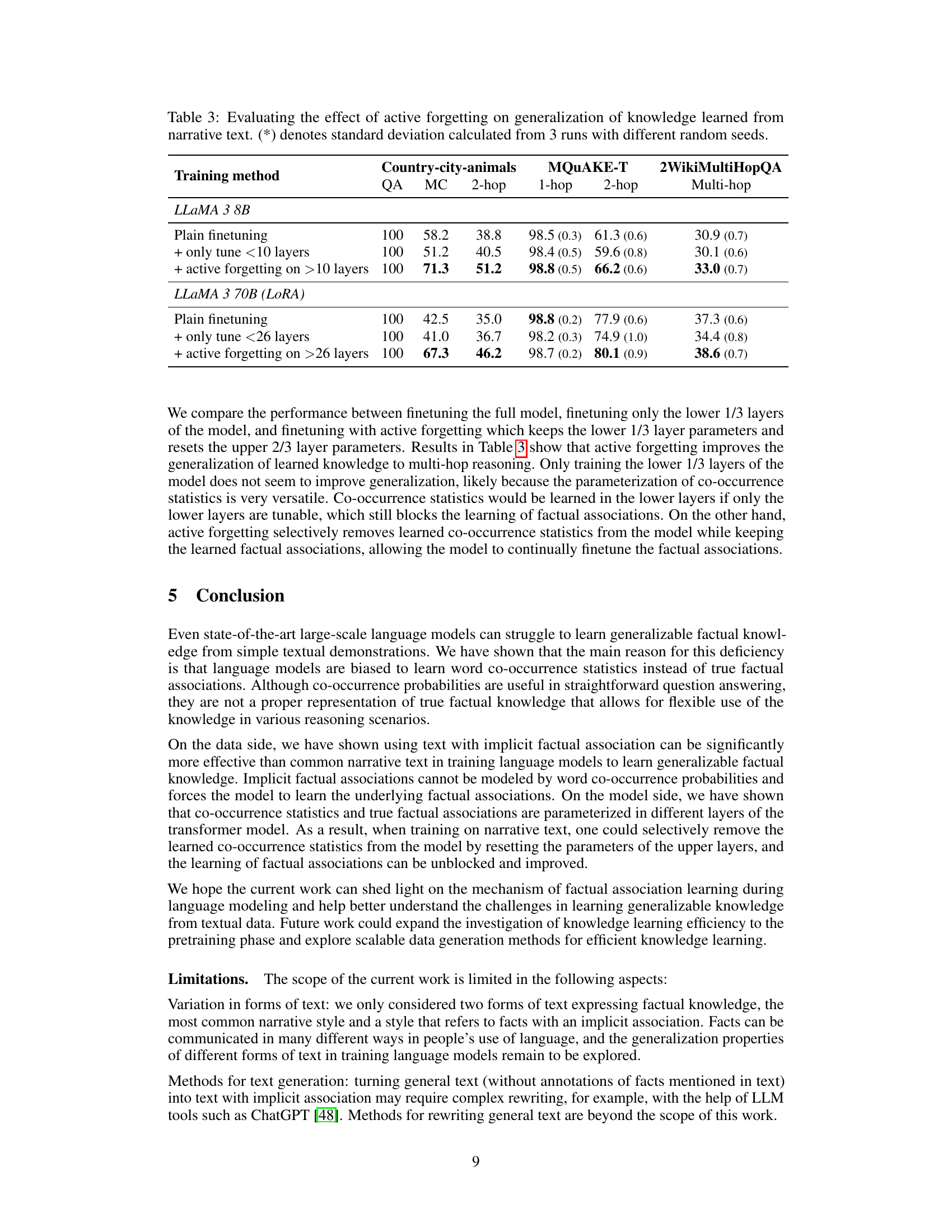
This table presents the results of evaluating the generalization of knowledge learned by language models finetuned on synthetic corpora. The models were tested on various question-answering and reasoning tasks, including simple question answering (QA), multiple-choice questions, reverse QA, indirect reasoning, and 2-hop reasoning. The results show that models trained on text with implicit factual associations (Referencing) generalize significantly better to complex reasoning tasks compared to those trained on text with explicit co-occurrence statistics (Narrative). The 5-shot accuracy reflects performance after only five examples for the models to learn the new knowledge.
In-depth insights#
Factual vs. Co-occurrence#
The core of this research lies in differentiating factual knowledge from mere co-occurrence statistics within language models. The authors highlight that while models excel at capturing co-occurrence (words frequently appearing together), this is not equivalent to genuine factual understanding. This distinction is crucial because co-occurrence, a superficial statistical pattern, doesn’t translate well to complex reasoning tasks, unlike true factual knowledge. The study proposes that models, particularly when finetuned on limited data, often take the shortcut of learning co-occurrence instead of delving into the deeper, more meaningful factual associations. This leads to poor generalization—the model fails to apply learned facts in novel contexts. Therefore, the paper’s central argument is that successful factual learning requires moving beyond simply identifying word co-occurrences and focusing instead on genuine semantic relationships and contextual understanding. This distinction has important implications for improving the learning efficiency and reasoning abilities of language models.
Implicit Fact Learning#
Implicit fact learning, a crucial aspect of language model development, focuses on enabling models to acquire factual knowledge without explicit training examples. Instead of directly providing facts like “Paris is the capital of France,” implicit methods leverage contextual clues and implicit relationships within text. This approach is particularly important for improving model generalization and handling novel scenarios, because explicitly listing every fact is impractical. Successful implicit learning leads to more robust models that can infer facts, make connections between seemingly disparate pieces of information, and reason effectively in contexts unseen during training. The challenge, however, lies in designing effective training paradigms that can guide the model to learn factual associations rather than superficial statistical correlations (such as word co-occurrence). Strategies for improving implicit fact learning might include crafting training datasets with implicit relational structures, using specific architectures or training objectives, or employing techniques like active forgetting to suppress the learning of spurious correlations and enhance the acquisition of true factual knowledge. Ultimately, the goal is to build language models that exhibit a deeper understanding of the world, move beyond rote memorization, and exhibit human-like reasoning abilities.
Layer-wise Knowledge#
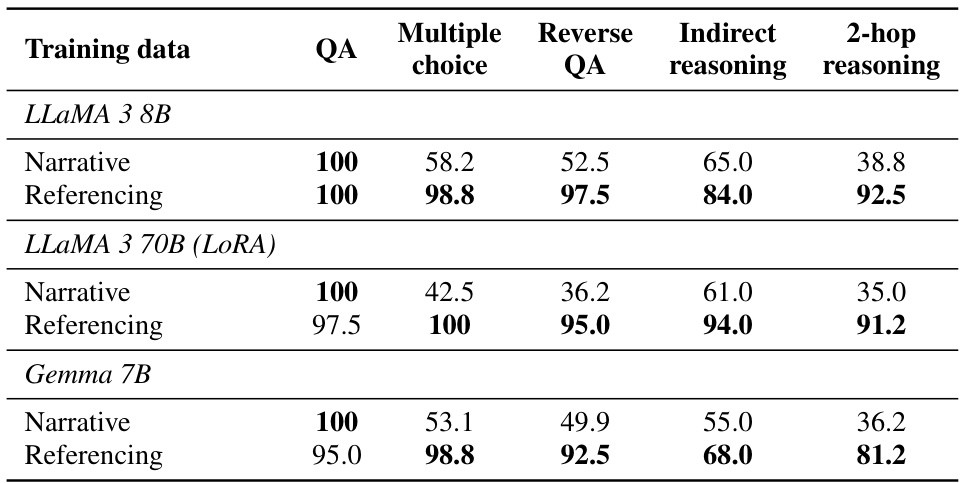
The concept of “Layer-wise Knowledge” in deep learning models, particularly transformer networks, is crucial for understanding how these models represent and utilize information. Different layers appear to encode different types of knowledge. Lower layers might focus on basic word embeddings and syntactic relationships. As you move up the layers, more complex semantic and factual associations emerge, with higher layers potentially incorporating more abstract reasoning and contextual understanding. The study’s findings reveal that co-occurrence statistics are predominantly encoded in the middle layers, showing a limited ability to generalize to complex reasoning tasks. Conversely, true factual associations are primarily found in the lower layers, showcasing a much stronger capacity for generalization across diverse reasoning scenarios. This suggests that focusing on training methods which emphasize the learning of factual associations within lower layers, rather than simply relying on co-occurrence statistics learned in higher layers, will significantly improve model performance in complex reasoning and knowledge-intensive tasks. Active forgetting of the middle layer’s co-occurrence information, followed by further training on plain narrative text, can unlock the learning of true factual associations and enhance model generalization.
Active Forgetting#
The concept of ‘Active Forgetting’ presents a novel approach to enhance factual knowledge learning in language models. It directly addresses the issue of shortcut learning, where models prioritize easily learned co-occurrence statistics over deeper factual associations. The method involves strategically resetting specific layers of the model’s parameters—those primarily encoding superficial co-occurrences—to disrupt this shortcut learning. By forcing the model to re-learn from a non-zero loss state, active forgetting unblocks the acquisition of more robust and generalizable factual knowledge. This is a significant contribution, offering a solution to a common limitation in language model training. The approach’s elegance lies in its simplicity and effectiveness in prompting the model to focus on meaningful factual relationships. The targeted forgetting mechanism ensures that only the less-important statistics are removed, leaving the genuine factual knowledge intact, leading to improved performance on complex reasoning tasks. The empirical results showcase the effectiveness of this method, with noticeable improvements on tasks requiring generalization beyond simple question answering.
Future of Fact Learning#
The future of fact learning in language models hinges on addressing the limitations of current approaches. While large language models (LLMs) demonstrate impressive abilities to encode and utilize knowledge, their reliance on co-occurrence statistics rather than true factual associations hinders generalization and reasoning capabilities. Future research should focus on enhancing the learning of factual associations by moving beyond the current causal language modeling objective. This might involve developing novel training methods that prioritize the learning of causal relationships between entities and relations, rather than simply memorizing co-occurrences. Furthermore, better ways to represent and parameterize factual knowledge within the model architecture are needed. This could involve exploration of different network architectures or training strategies that encourage the separation of surface-level statistical patterns from deeper semantic understanding. The development of more effective evaluation metrics that go beyond simple question-answering is also crucial. Ultimately, the goal is to build LLMs that can not only store vast quantities of facts but also reason effectively with them in complex scenarios, requiring a shift towards a more robust and nuanced understanding of fact representation and learning.
More visual insights#
More on figures

This figure shows the results of ablating the learned parameters layer by layer to determine which layers are most responsible for the model’s performance on QA and multiple choice tasks. The results indicate that for the Narrative training data (explicit co-occurrence), the middle layers are more influential in simple QA, while the lower layers are crucial for multiple choice tasks. Conversely, for the Referencing training data (implicit association), the lower layers have more influence on both QA and multiple choice performance.
The figure illustrates the active forgetting method. The model is first fine-tuned normally. Then, parameters in the upper 2/3 layers of the transformer are reset to their pretrained values. This clears the co-occurrence statistics learned in the upper layers and allows the loss to become non-zero again. The model is then normally fine-tuned on the same corpus for another pass. With a non-zero loss, lower layers of the transformer undergo further training, leading to improved learning of factual knowledge after the second training pass.

This figure shows two graphs. The left graph displays the training loss curve of a language model during training with active forgetting on the Narrative text of the Country-city-animals dataset, using the LLaMA 3 8B model. The loss initially decreases rapidly, then plateaus near zero. At around step 130, the upper 2/3 layers of the model’s parameters are reset (active forgetting). This causes the loss to spike and then gradually decrease again. The horizontal dashed line represents the irreducible loss (entropy) of the training corpus. The right graph shows the multiple-choice accuracy on the same dataset and model over training steps. Similar to the loss curve, the accuracy initially increases rapidly and plateaus. The parameter reset at step 130 also results in a slight dip in accuracy before further improvement.

This figure shows the result of ablating the learned parameters (parameter delta) layer by layer, starting from the first layer and the last layer of the transformer model. It demonstrates that the model’s performance on question answering (QA) and multiple choice tasks are affected differently depending on which layers’ learned parameters are removed. Specifically, the QA task’s performance relies on middle layers when trained on narrative text, and lower layers when trained on referencing text. The multiple-choice task’s performance, however, consistently relies on lower layers regardless of the training data.
More on tables
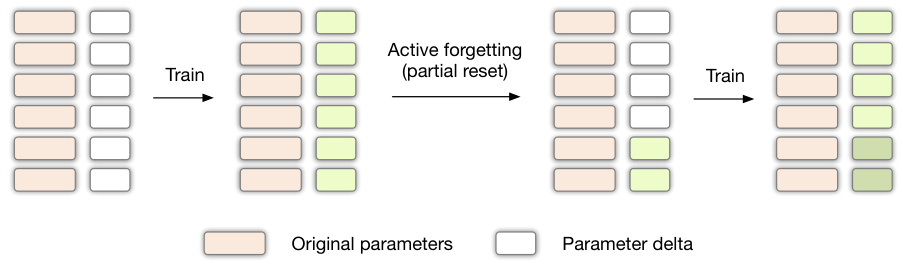
This table presents the results of evaluating the generalization of knowledge learned from the MQuAKE-T dataset using different training methods. It compares the performance of the models on single-hop and multi-hop question answering tasks. The ‘Original’ training data uses the narrative text provided in the original dataset, while the ‘Referencing’ data uses a modified version that introduces implicit associations between entities. The results demonstrate the impact of implicit textual associations on the model’s ability to generalize knowledge to more complex reasoning scenarios. The numbers represent 5-shot accuracies, and the numbers in parentheses are standard deviations across three separate runs with different random seeds.

This table presents the results of evaluating the generalization of knowledge learned by language models finetuned on two different types of synthetic corpora: Narrative and Referencing. It shows the 5-shot accuracy of several reasoning tasks (QA, Multiple Choice, Reverse QA, Indirect Reasoning, 2-hop Reasoning) for different language models (LLaMA 3 8B, LLaMA 3 70B, Gemma 7B). The results demonstrate that models trained on the Referencing corpus (implicit factual associations) generalize significantly better to complex reasoning tasks than those trained on the Narrative corpus (explicit co-occurrence statistics).
Full paper#