↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Vision-language models (VLMs) have shown impressive capabilities but often exhibit biases, skewing outputs towards societal stereotypes. Existing debiasing methods are often task-specific or require extensive retraining. This is problematic because it limits the widespread adoption of bias mitigation techniques.
This paper introduces Selective Feature Imputation for Debiasing (SFID), a novel method addressing these limitations. SFID integrates feature pruning and low-confidence imputation to effectively reduce bias. The approach is versatile and cost-effective, maintaining output integrity while eliminating the need for retraining. Experiments across various VLM tasks demonstrate SFID’s effectiveness in significantly reducing gender bias without performance compromise, highlighting its potential to improve the fairness and efficiency of VLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on fairness and bias in AI, particularly in vision-language models. It offers a novel, efficient debiasing method applicable across diverse tasks, addressing a critical limitation of current approaches. The findings promote the development of fairer and more reliable AI systems.
Visual Insights#

This figure shows examples of gender bias in vision-language models (VLMs) for image captioning and image generation tasks. In the image captioning example, CLIP-CAP captions an image of a woman surfing as ‘A woman in a wetsuit surfing on a wave.’ However, when the same model is used with the SFID debiasing method, the caption becomes more gender-neutral (‘A person on a surfboard in the water.’). The image generation example shows similar bias where the model generates images of a particular gender even if a neutral prompt is provided. SFID helps mitigate this bias, as seen in the changes to both the captions and the generated images.
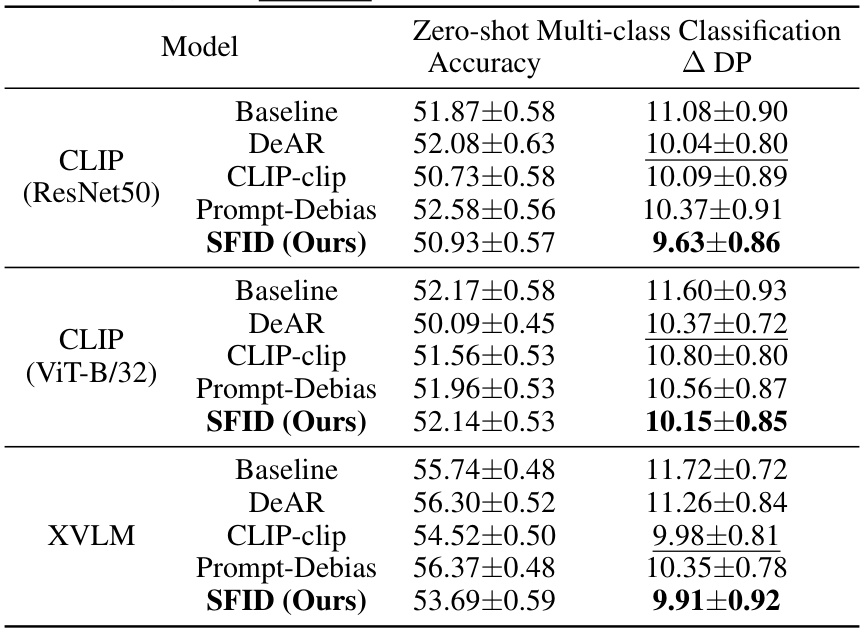
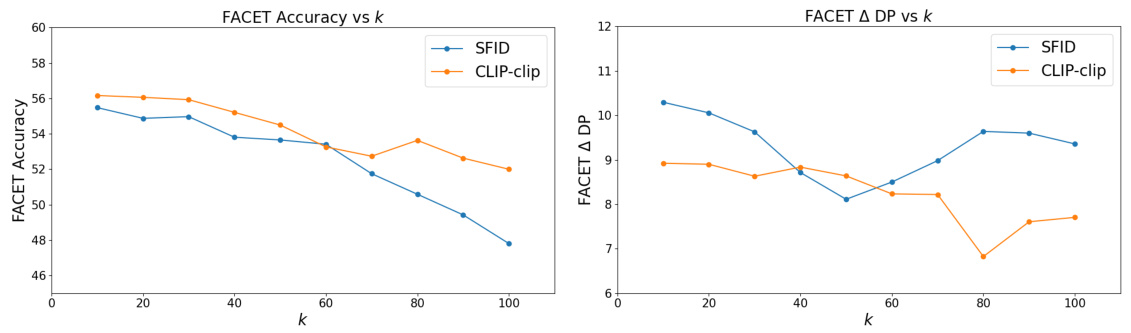
This table presents the results of zero-shot multi-class classification experiments conducted on the FACET dataset. The table compares the performance of several models: a baseline, DeAR, CLIP-clip, Prompt-Debias, and the proposed SFID method. Performance is evaluated using two metrics: Accuracy and ΔDP (Demographic Parity). The bold values represent the best accuracy for each model type (CLIP ResNet50, CLIP ViT-B/32, and XVLM), while underlined values indicate the second-best results. The ΔDP metric quantifies the fairness of the model’s predictions. Lower values indicate better fairness.
In-depth insights#
Bias in VLMs#
Vision-Language Models (VLMs) are powerful tools, but their potential is hampered by inherent biases. These biases, often reflecting societal stereotypes, skew model outputs towards certain demographics in various tasks such as image captioning, text-to-image generation, and zero-shot classification. Bias in VLMs is a critical issue because it leads to unfair or discriminatory outcomes, perpetuating and amplifying existing societal prejudices. The biases are not limited to specific modalities but can manifest across text and image data. Addressing bias requires more than simple post-hoc fixes; it demands careful consideration of model architecture, training data, and evaluation metrics. While existing methods focus on specific modalities or tasks, a more unified debiasing approach is needed to ensure fairness across applications and tasks without sacrificing efficiency. The development of robust and effective debiasing techniques is essential for the responsible and ethical deployment of VLMs.
SFID Debiasing#
The proposed SFID debiasing method offers a unified approach to mitigate bias in vision-language models (VLMs). Its core innovation lies in integrating feature pruning with low-confidence imputation (LCI). This combined strategy effectively reduces biases across various VLM tasks without extensive retraining, a significant advantage over existing methods. By identifying bias-related features using RandomForest and replacing them with values from ambiguous samples, SFID preserves semantic integrity and avoids the distortion sometimes caused by simply dropping features or introducing noise. The method’s versatility and efficiency make it a promising technique for enhancing fairness in VLMs. The experimental results, showing improvements across zero-shot classification, image captioning, and image retrieval, strongly support its effectiveness and broad applicability.
Multimodal Fairness#
Multimodal fairness, in the context of artificial intelligence, presents a significant challenge. It necessitates the development of algorithms that avoid perpetuating or amplifying societal biases present in both visual and textual data. Achieving fairness requires careful consideration of how biases inherent in training data interact with model architectures and learning processes. Methods for evaluating and mitigating bias must be tailored to the specific modalities involved, as biases may manifest differently in images and text. A crucial aspect is the need for comprehensive and nuanced evaluation metrics that go beyond simple accuracy and capture the subtle ways biases can affect model outputs. This includes evaluating fairness across different demographic groups and considering the potential for intersectional biases. Furthermore, effective debiasing strategies must balance fairness with model utility, ensuring that efforts to correct biases do not significantly compromise the overall performance or usability of multimodal systems. Future research should focus on the development of robust and adaptable debiasing techniques, as well as standardized evaluation procedures to facilitate better understanding and improvement in multimodal fairness.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a vision-language model (VLM) debiasing paper, an ablation study would likely investigate the impact of different debiasing techniques or model components. Key aspects assessed might include the effectiveness of feature imputation versus simply removing biased features, the effect of different feature selection methods (like RandomForest), and the influence of the threshold used for selecting low-confidence samples. The results would demonstrate which components are essential for debiasing and whether removing specific elements severely impacts performance. Analyzing the ablation study’s results helps determine which aspects of the proposed method are crucial for fairness, offering crucial insights into the model’s overall architecture and improving the debiasing strategy. A well-conducted study would reveal the trade-offs between debiasing effectiveness and overall model performance, providing valuable information on how to optimize and refine the proposed approach. By systematically evaluating various design choices, the ablation study strengthens the paper’s claims regarding the method’s efficacy and sheds light on the interplay between different aspects of the debiasing process.
Future Works#
Future work in debiasing vision-language models (VLMs) could explore several promising avenues. Extending SFID to address other forms of bias beyond gender, such as race, religion, or socioeconomic status, is crucial for broader fairness. Investigating the impact of different feature selection methods and imputation strategies on the effectiveness of SFID would refine the approach. A key area for advancement lies in developing more robust evaluation metrics that go beyond simple accuracy, considering nuanced societal implications and various downstream tasks. Benchmarking SFID against a wider range of VLMs and datasets is necessary to validate its generalizability and performance. Finally, researching the interplay between bias mitigation and VLM efficiency to minimize computational overhead is essential for practical applications. Addressing these points would significantly advance the field of fair and responsible VLM development.
More visual insights#
More on figures

This figure shows examples of gender bias in vision-language models (VLMs) and how the proposed Selective Feature Imputation for Debiasing (SFID) method mitigates this bias. The top row demonstrates how CLIP-CAP (a VLM) tends to associate specific genders with certain activities (surfing and skiing) in image captioning. The bottom row illustrates the same bias in text-to-image generation with CoDi, where a prompt mentioning ‘man’ preferentially generates images of men as nurses. SFID’s application improves fairness, resulting in more gender-balanced outputs in both tasks.
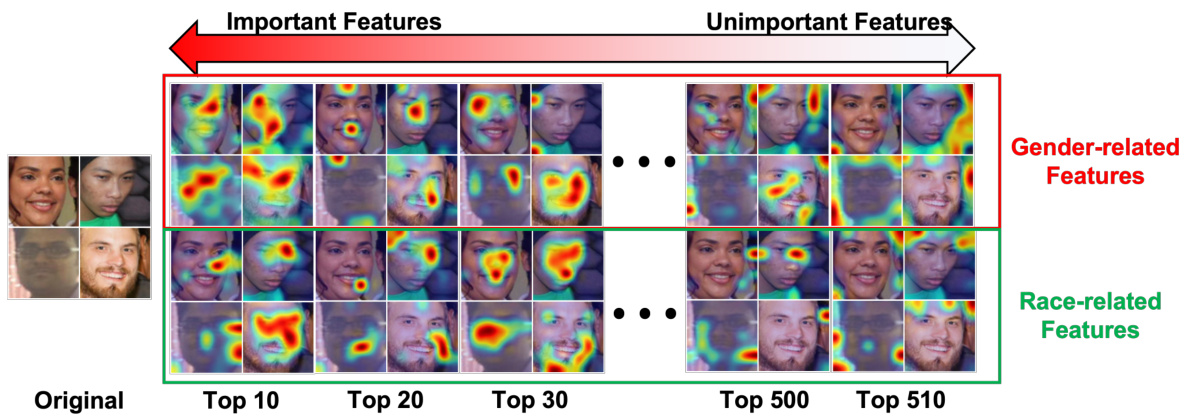
This figure shows GradCAM visualizations to demonstrate how important features are correlated to gender and race biases. The left side displays the top 30 most important features identified by RandomForest, which highlight facial attributes related to gender and race. The right side shows the least important 10 features, focusing on the background. SFID uses this information to identify and replace biased features with ambiguous values from low-confidence samples.
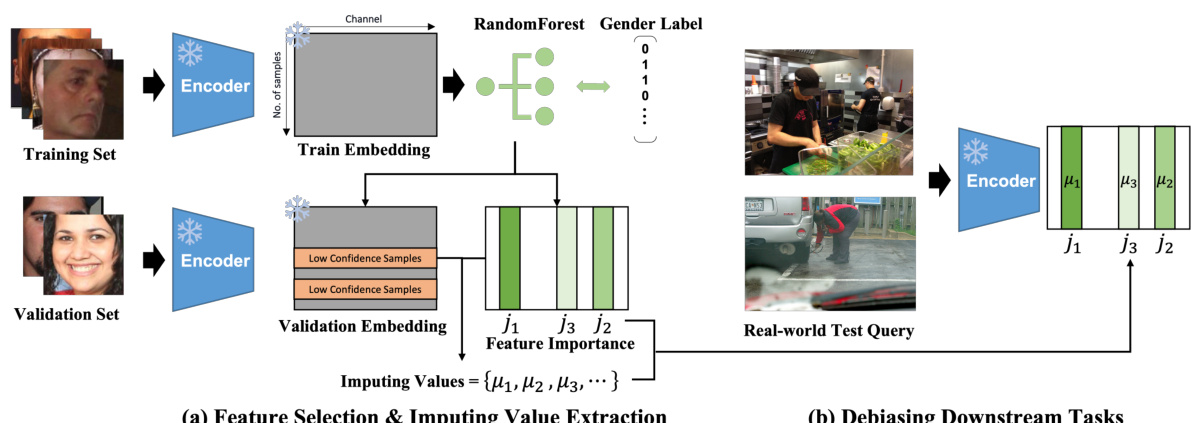
This figure illustrates the SFID (Selective Feature Imputation for Debiasing) process. It shows how RandomForest is used to identify important features correlated with gender bias in a training set of images. These features are then replaced with values from low-confidence samples (samples that are ambiguous and less likely to exhibit bias) found in a validation set. The process is applied during inference, where important features from the input embedding are replaced with these imputed values before the embedding is used in a downstream task, effectively reducing gender bias.
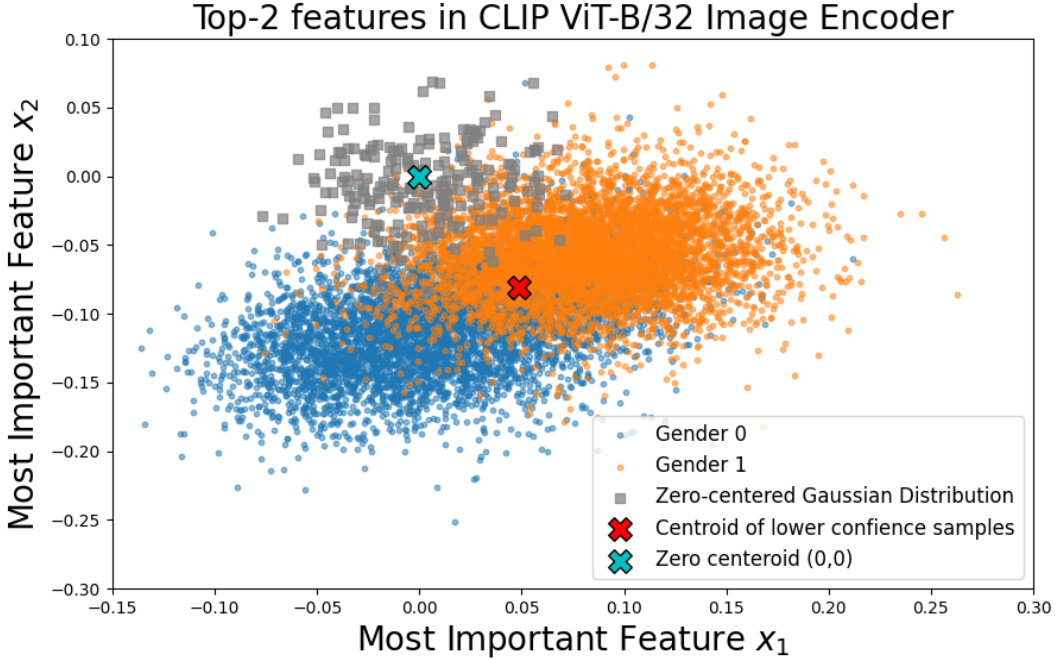
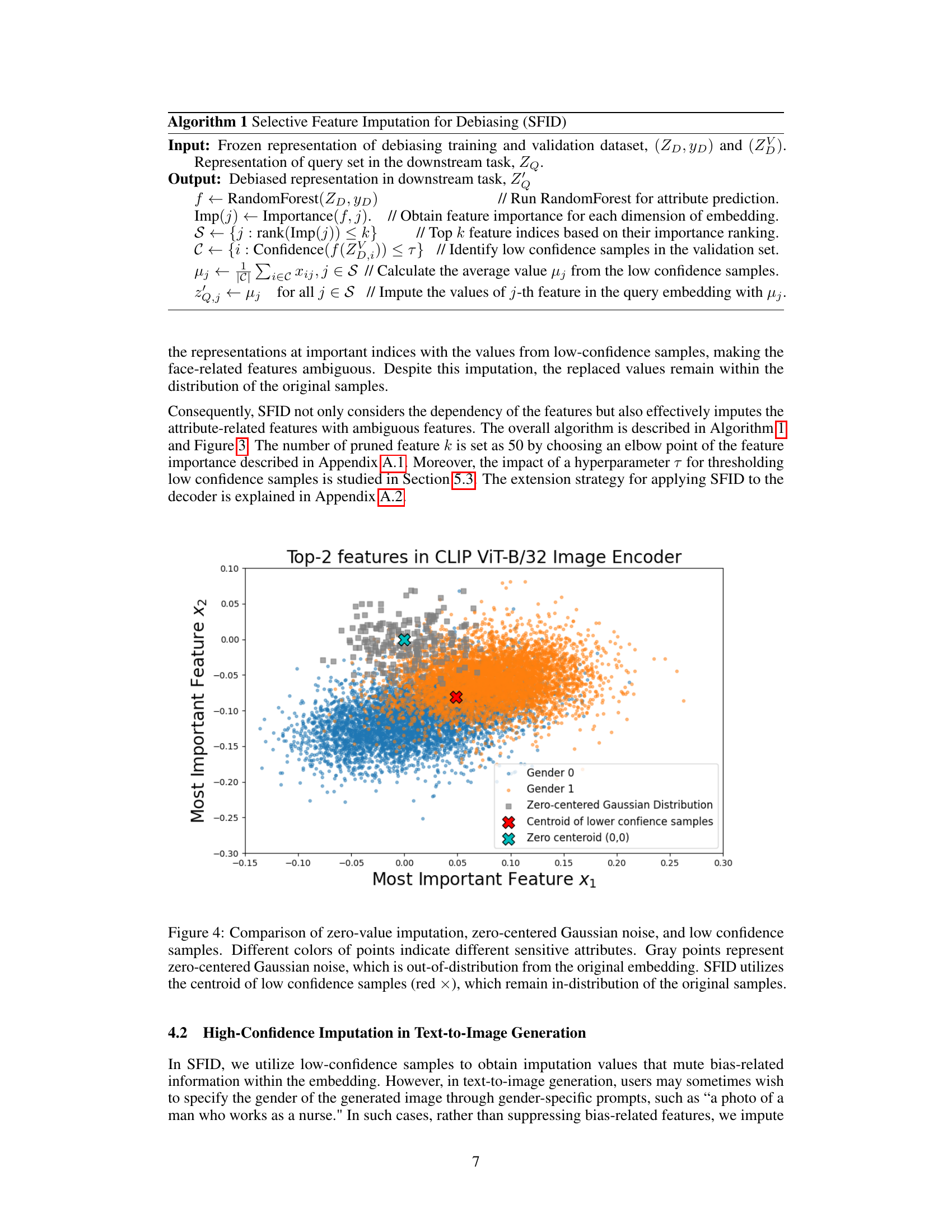
This figure compares three different imputation methods: zero-value imputation, zero-centered Gaussian noise, and low-confidence sample imputation. It shows how these methods affect the distribution of the imputed features in the context of mitigating biases related to sensitive attributes. The low-confidence sample imputation method, used by SFID, is highlighted as it keeps the imputed features within the original data distribution, unlike the other two methods.
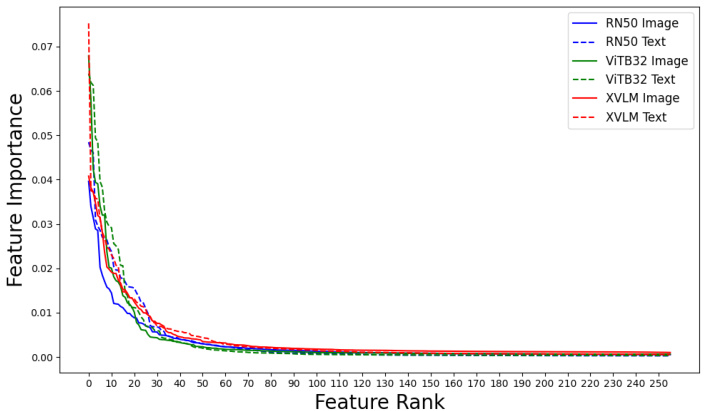
The figure shows feature importances for gender prediction by RandomForest for each frozen representation. The x-axis represents the feature rank, sorted from most to least important. The y-axis represents the feature importance, which indicates how strongly each feature contributes to the prediction of gender. Separate lines are shown for different models and components, including RN50 Image, RN50 Text, ViT-B/32 Image, ViT-B/32 Text, XVLM Image and XVLM Text. The plot shows that the top few features are significantly more important than the others, stabilizing around the top 100 for all components.
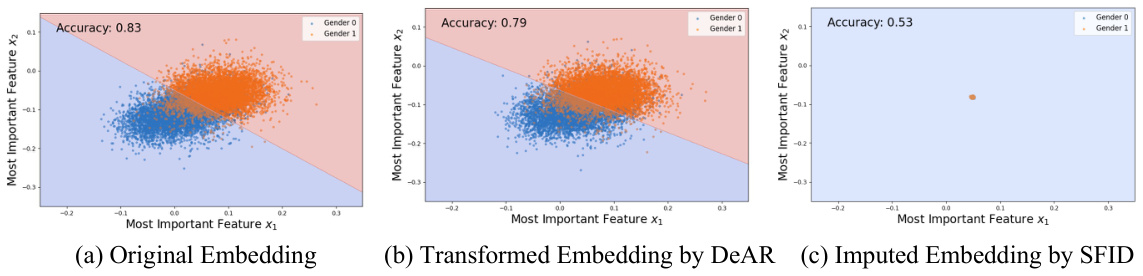
This figure compares the performance of three different debiasing methods on a binary classification task using only the two most important features. (a) shows that a linear classifier can easily distinguish between two classes in the original embedding. (b) shows that DeAR fails to effectively debias the embedding. (c) shows that SFID successfully removes bias-related information and the classifier cannot distinguish between the two classes.
This figure shows the feature importances for gender prediction using RandomForest on different frozen representations from various vision-language models (VLMs). The x-axis represents the feature rank, ordered from most important to least important. The y-axis shows the feature importance score. Each line represents a different VLM’s representation (RN50 Image, RN50 Text, ViT-B/32 Image, ViT-B/32 Text, XVLM Image, XVLM Text). The plot helps visualize the relative importance of each feature in predicting gender and informs the selection of the top k features to prune during the SFID debiasing process. The stabilization around the top 100 features is a key observation that motivated choosing k=50 in the SFID algorithm.
This figure illustrates the Selective Feature Imputation for Debiasing (SFID) method. It shows how RandomForest is used to identify important features associated with bias, and how low-confidence samples are used to replace those features, maintaining dimensionality while reducing bias in downstream tasks.
More on tables
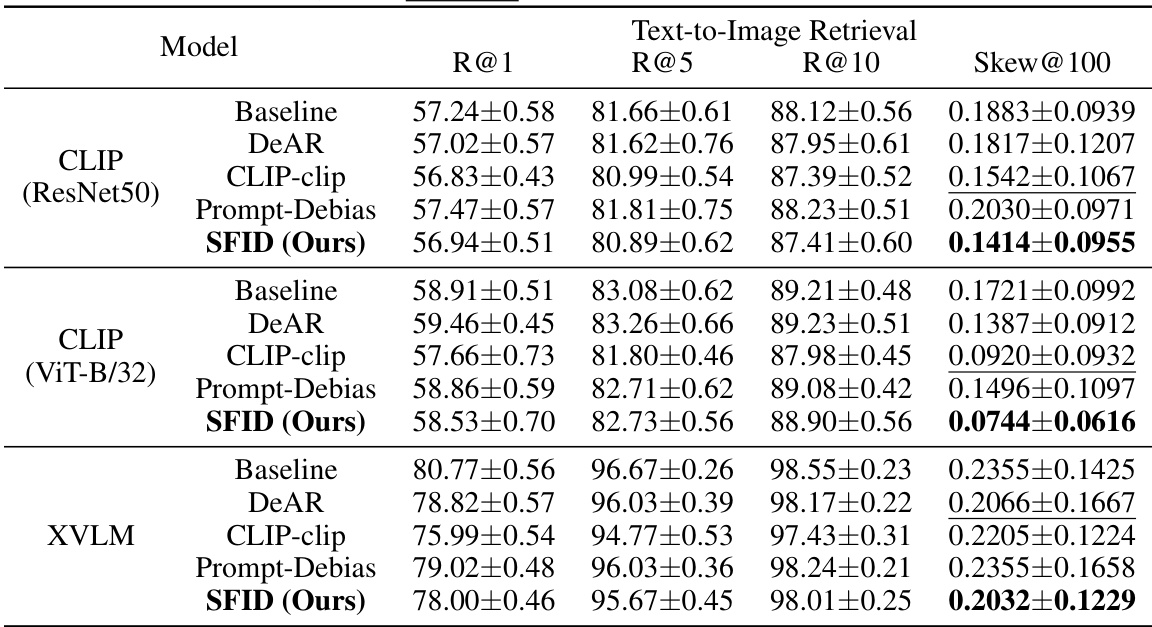
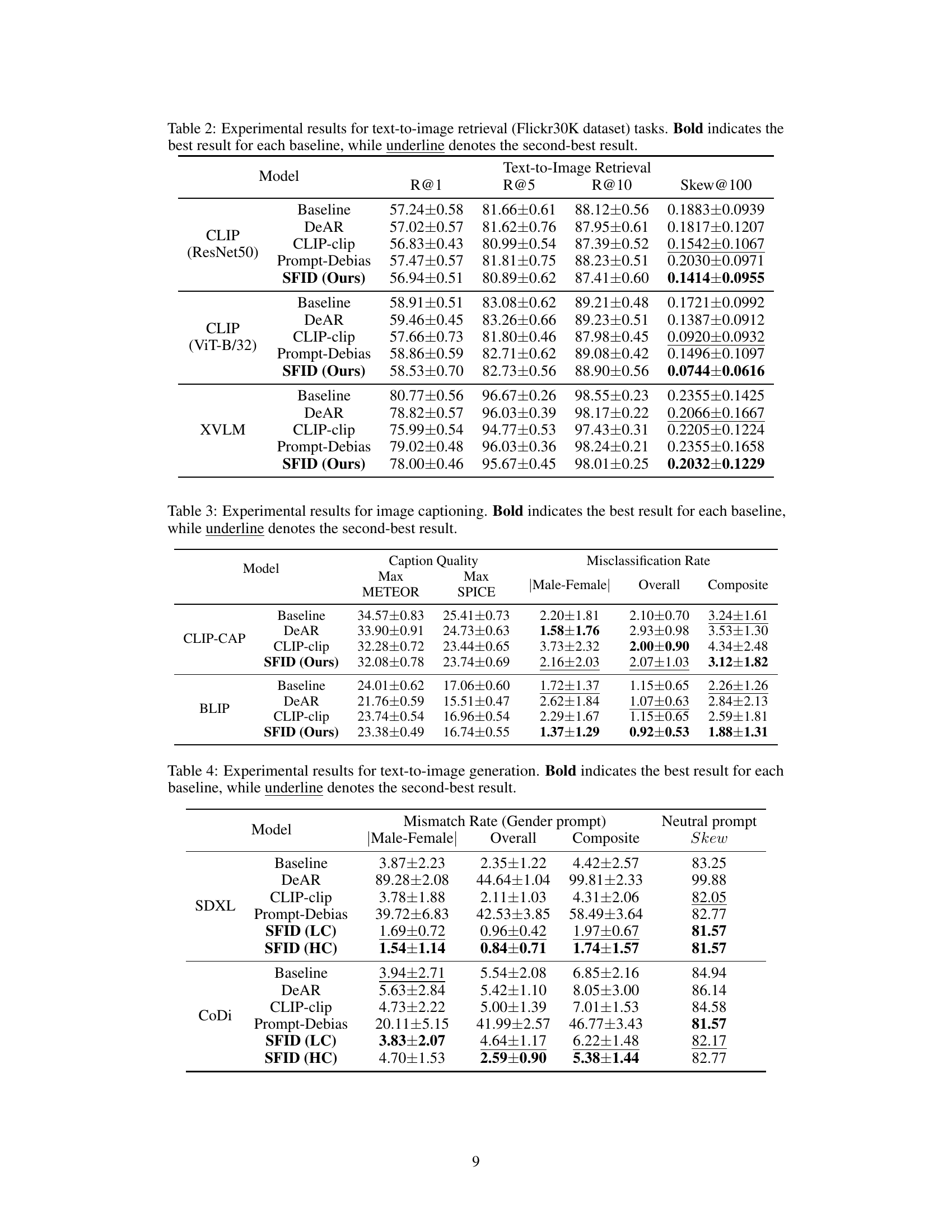
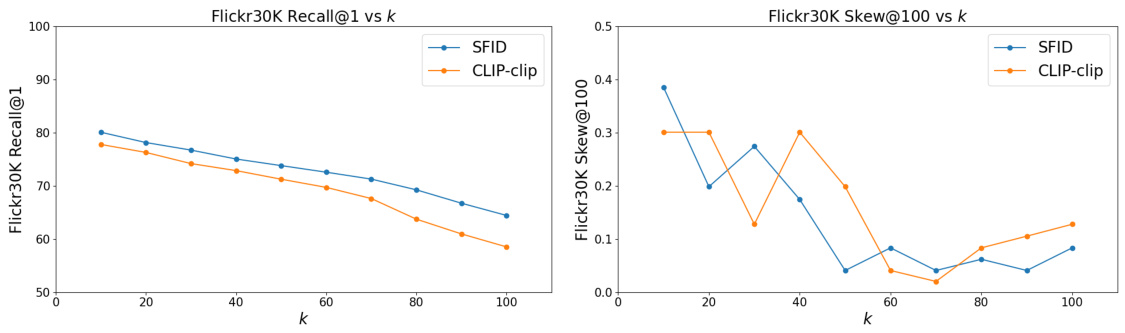
This table presents the results of text-to-image retrieval experiments using three different vision-language models (CLIP with ResNet-50, CLIP with ViT-B/32, and XVLM). For each model, it shows the recall at ranks 1, 5, and 10, as well as the gender bias (Skew@100) using the Flickr30K dataset. The results are shown for a baseline model and four debiasing methods (DeAR, CLIP-clip, Prompt-Debias, and SFID). The bold values indicate the best performance for each model and baseline, while underlined values indicate the second-best performance.
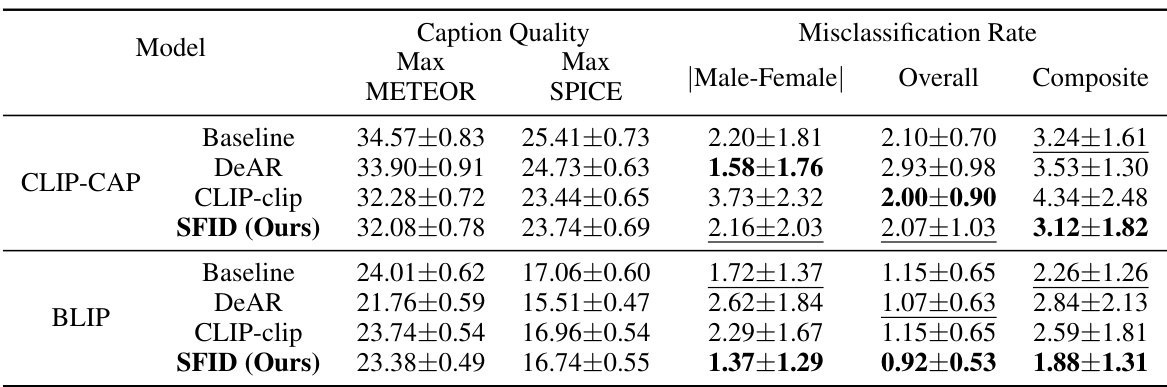
This table presents the experimental results for image captioning task using different models. Metrics include caption quality (Max METEOR and Max SPICE scores) and misclassification rates (Male-Female, Overall, and Composite). The table compares the performance of a baseline model against several debiasing methods, highlighting the best-performing method for each metric and model.
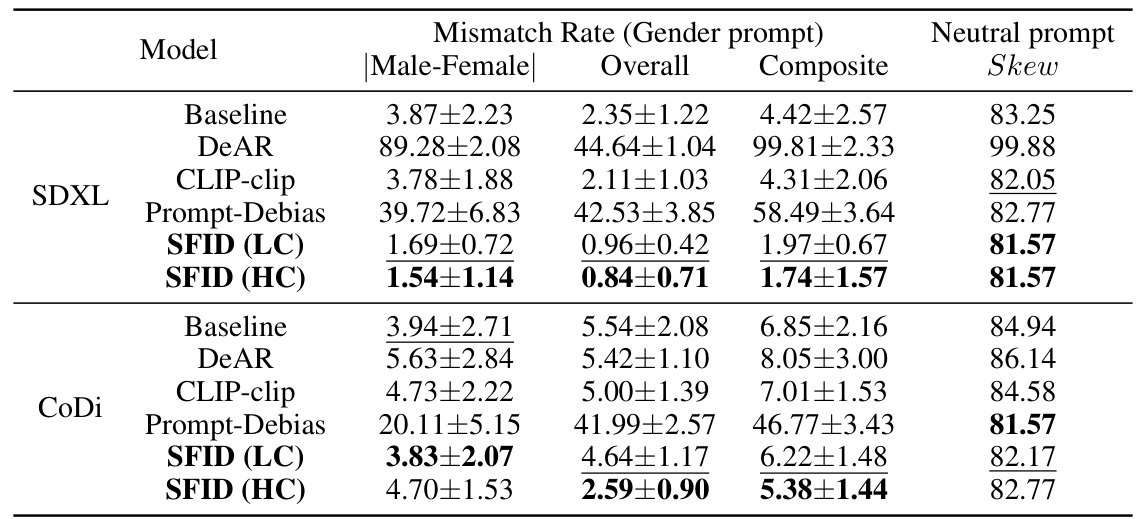
This table presents the performance of different debiasing methods on the text-to-image generation task, using two metrics: mismatch rate and skew. Mismatch rate evaluates the accuracy of gender prediction in generated images, considering both gender-specific and neutral prompts. Skew measures the fairness of gender distribution in images generated from neutral prompts. The results show the effectiveness of SFID (both LC and HC) in reducing bias without significantly sacrificing overall performance.
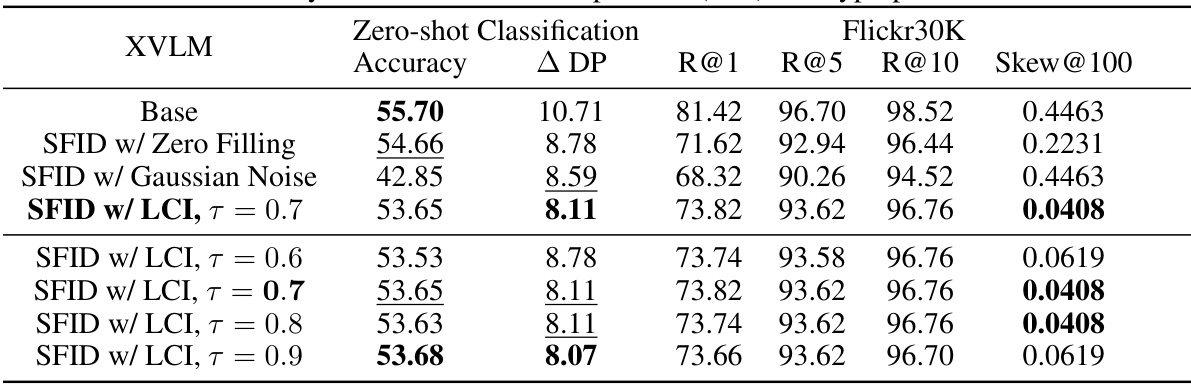
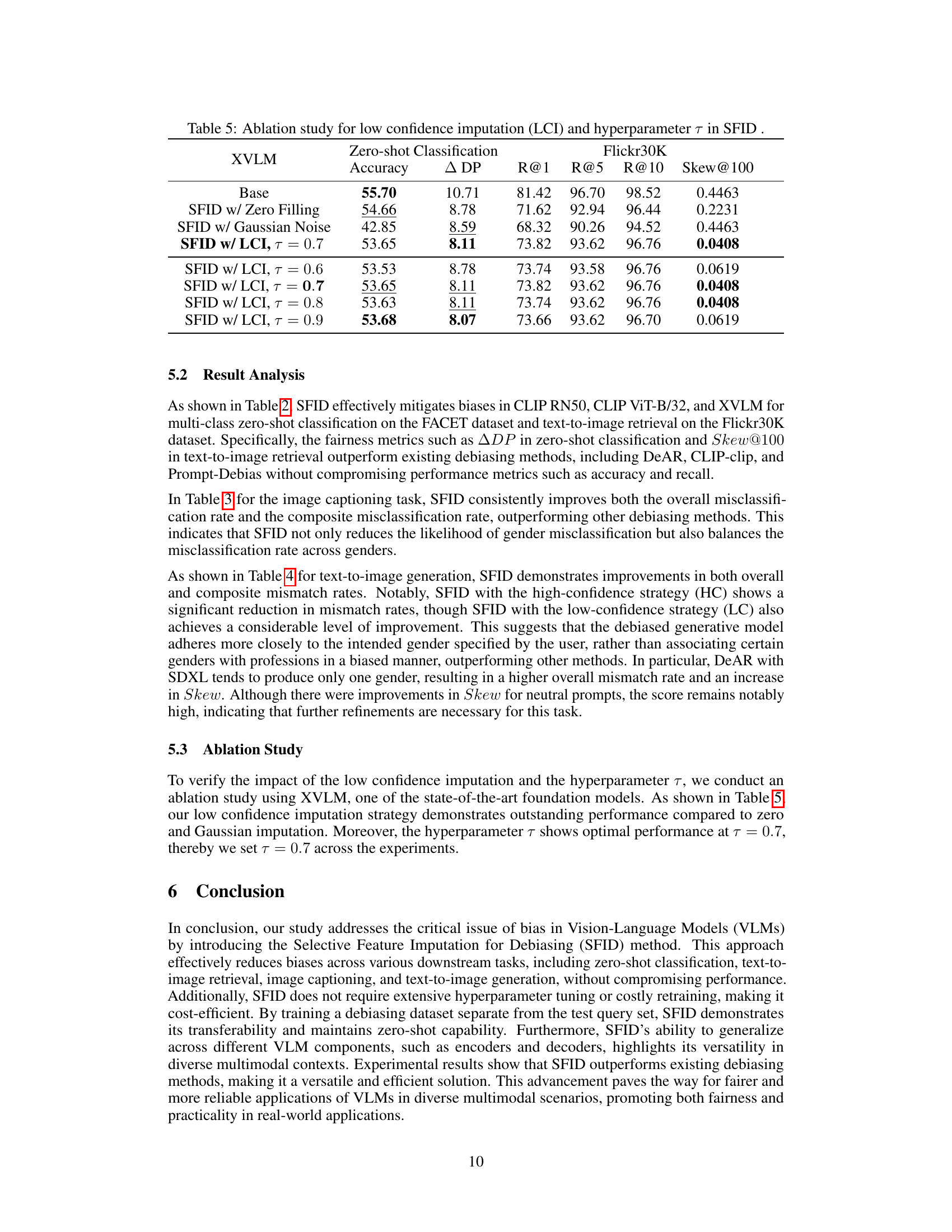
This table presents the results of an ablation study conducted to evaluate the impact of low-confidence imputation (LCI) and the hyperparameter τ on the performance of the Selective Feature Imputation for Debiasing (SFID) method. The study uses the XVLM model and assesses performance across zero-shot classification accuracy (Accuracy), demographic parity (Δ DP), and text-to-image retrieval metrics (R@1, R@5, R@10, Skew@100) using the FACET and Flickr30K datasets. Different variations of SFID are compared, including those with zero filling, Gaussian noise, and LCI with varying values of τ. The results demonstrate the effectiveness of LCI and the optimal value of τ for achieving a balance between bias mitigation and overall performance.
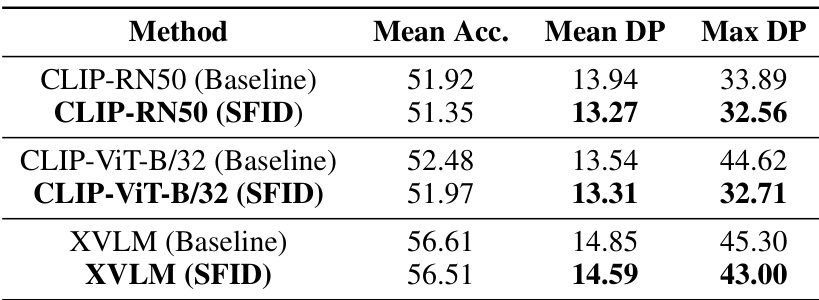
This table presents a comparison of the performance of different methods in terms of Mean Accuracy, Mean Demographic Parity (DP), and Max DP for multi-class zero-shot classification on the FACET dataset. It shows the results for three different Vision-Language Models (VLMs) and the improvements achieved by applying the Selective Feature Imputation for Debiasing (SFID) method.
This table presents the results of zero-shot multi-class classification experiments using three different vision-language models (CLIP with ResNet-50, CLIP with ViT-B/32, and XVLM) on the FACET dataset. The table shows the accuracy and average demographic parity (ADP) for each model, comparing the baseline performance to those of several debiasing methods (DeAR, CLIP-clip, Prompt-Debias). Bold values highlight the best performance for each model, and underlined values show the second-best performance. The table demonstrates the effectiveness of the proposed SFID method in improving model accuracy while simultaneously reducing bias.
Full paper#