↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-video generation often struggles with animating customized subjects, lacking precise control over object and camera movements. Existing methods either generate low-quality videos or require extensive fine-tuning for each specific motion. This limits their applicability and efficiency.
MotionBooth tackles these issues by introducing a novel framework that efficiently fine-tunes a text-to-video model to accurately capture the subject’s shape and attributes. It uses a subject region loss and video preservation loss to improve the subject learning, along with a subject token cross-attention loss to integrate the customized subject with motion control. It features training-free techniques to easily manage subject and camera motions during inference. This ensures high-quality video generation and precise motion control while maintaining training efficiency. The results demonstrate the superiority of the proposed method.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for motion-aware customized video generation, a significant advancement in the field of AI-driven video content creation. The training-free motion injection method and the ability to precisely control both object and camera movements are valuable contributions that open up several avenues for future research, particularly in areas such as personalized video experiences, film production, and motion capture.
Visual Insights#

This figure shows several examples of videos generated by the MotionBooth model. Each row represents a different scenario: a dog jumping down stairs, a monster toy walking across Times Square, a cat jumping over a wall, and a cartoon character running in a painted forest. The figure highlights the model’s ability to generate videos with specific subject motions and camera movements, demonstrating the method’s motion-aware capabilities.
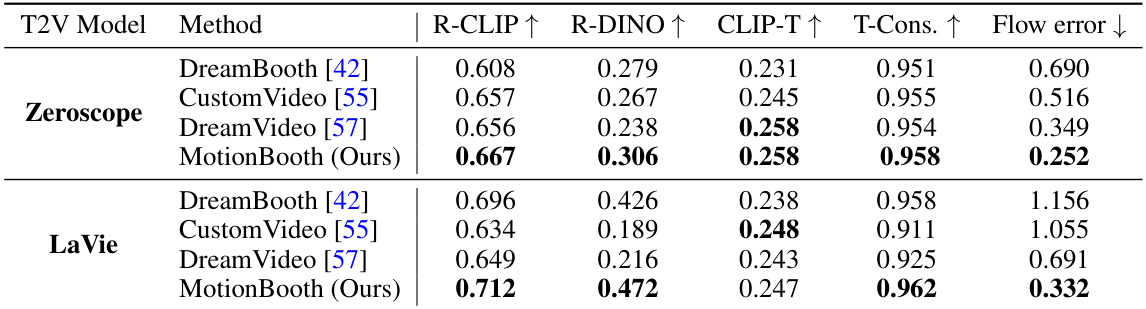
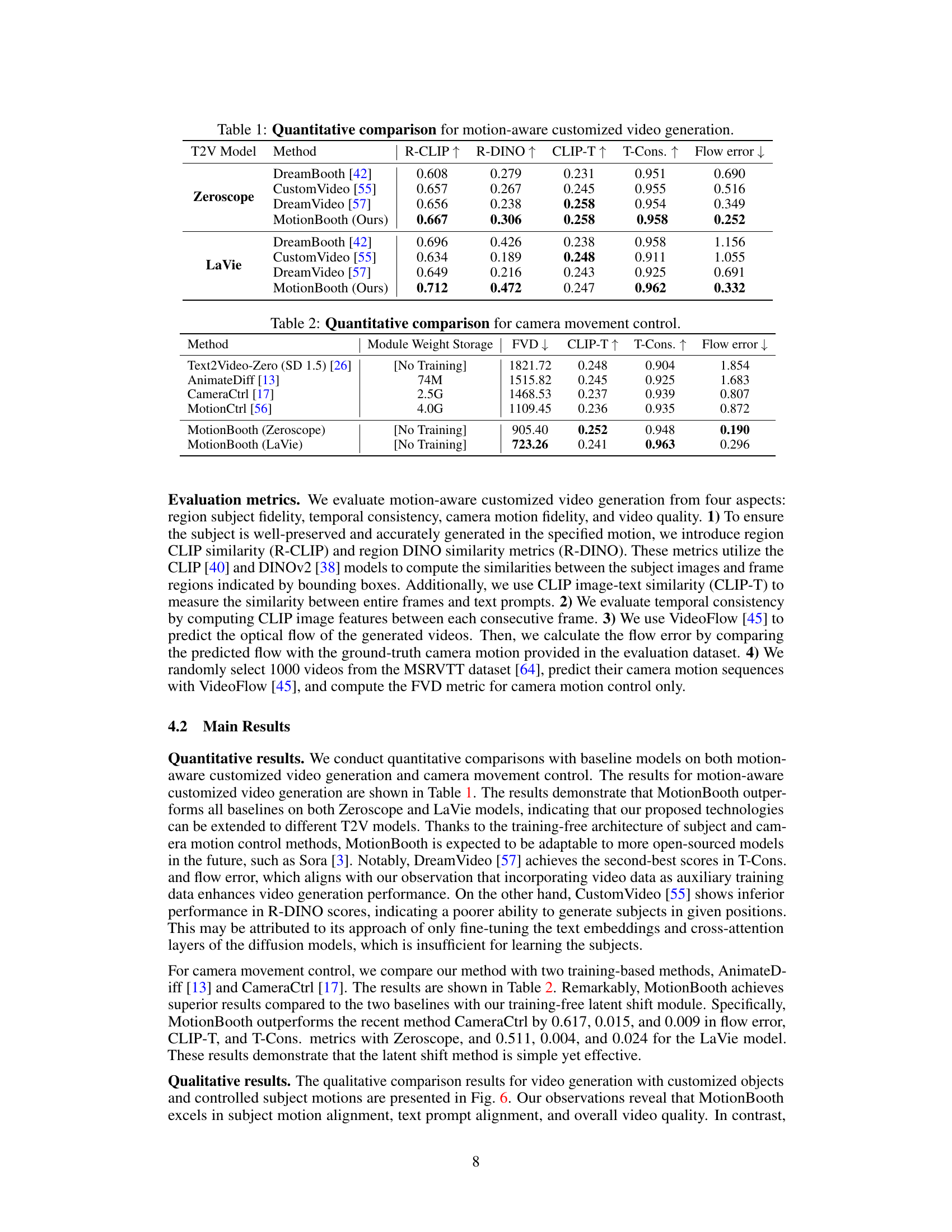
This table presents a quantitative comparison of MotionBooth against other state-of-the-art methods for motion-aware customized video generation. The comparison uses two different text-to-video models, Zeroscope and LaVie, and evaluates the performance across several metrics. These metrics assess the quality of the generated videos by considering subject fidelity (using R-CLIP and R-DINO scores, which measure the similarity between the generated subject and the input subject), text-to-video alignment (using CLIP-T score), temporal consistency (T-Cons), and flow error. The results illustrate the performance improvement achieved by MotionBooth in generating high-quality, motion-consistent videos with customized subjects, outperforming the comparative models on most metrics.
In-depth insights#
Motion-Aware T2V#
Motion-Aware T2V (Text-to-Video) represents a significant advancement in video generation, moving beyond static image synthesis towards dynamic and controllable video creation. A key challenge lies in integrating precise control over subject and camera motion while maintaining high-fidelity video generation. This requires innovative approaches to encode and decode motion information effectively, often involving novel loss functions that balance subject preservation with motion realism. Successful methods leverage advanced deep learning architectures, such as Transformers, and incorporate techniques like cross-attention mechanisms to intricately connect text descriptions with the spatial and temporal aspects of video frames. Training-free motion control methods are particularly appealing due to the computational efficiency they offer over traditional fine-tuning approaches, enabling versatile video generation without extensive retraining. The ability to inject various camera movements and complex subject actions into the generation process opens avenues for personalized and immersive video creation, but also presents risks related to the generation of deepfakes and disinformation. Future work should focus on mitigating ethical concerns while enhancing motion control precision and developing more efficient training methods.
Subject Learning#
Subject learning in the context of text-to-video generation focuses on efficiently training a model to accurately represent a specific subject using limited data. Overfitting is a major challenge, as models tend to learn the background and other irrelevant details along with the target subject. To address this, techniques such as subject region loss are employed, focusing the model’s attention exclusively on the subject within each frame. Video preservation loss is another important component, aiming to prevent the fine-tuning process from harming the model’s ability to generate realistic videos. This is achieved by training alongside video data, ensuring the model retains its video generation capabilities. Additionally, a subject token cross-attention loss helps integrate the subject information with motion control signals, thus enabling more precise motion control during video generation. The goal is to learn the subject’s appearance and attributes while preserving the quality and diversity of the underlying video generation model.
Training-Free Control#
The concept of ‘Training-Free Control’ in the context of a research paper on text-to-video generation is a significant advancement. It implies the ability to manipulate video generation parameters, such as object motion and camera movement, without requiring additional training of the underlying model. This is crucial because retraining large video generation models is computationally expensive and time-consuming. A training-free approach makes the system more flexible and adaptable, allowing for real-time or near real-time control of the generated videos with diverse combinations of user inputs (e.g., text, bounding boxes). This often involves clever manipulation of intermediate model representations, like attention maps or latent vectors, to achieve control during the inference stage. The success of such a method depends on effectively leveraging the inherent capabilities of the pre-trained model, which is critical for generating high-quality, coherent videos. The paper likely highlights the efficiency and scalability improvements offered by this training-free approach, contrasting it with methods requiring retraining, and showcasing its superior performance in various aspects like speed and control precision. Key challenges likely addressed are avoiding overfitting to specific training examples and ensuring the control mechanism doesn’t degrade the video quality or introduce artifacts. The method’s performance will ultimately be evaluated in comparison to training-based methods, possibly focusing on metrics such as speed, control precision, and overall video quality.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a model or system. In a text-to-video generation context, this might involve removing or modifying modules responsible for subject learning, motion control (either subject or camera), or the loss functions guiding the training process. The goal is to understand the impact of each component’s absence on the overall performance metrics, such as video quality, fidelity to the text prompt, and smoothness of motion. By selectively removing components, researchers gain valuable insights into the relative importance and interplay of different design choices. For instance, removing the subject region loss might lead to background overfitting, while disabling the camera control module could result in static or unnatural camera movement. Careful analysis of these results enables informed design choices and helps to optimize the architecture for improved performance. Furthermore, ablation studies provide a form of model interpretability, shedding light on the underlying mechanisms and justifying the inclusion of specific components.
Future Directions#
Future research directions for motion-aware customized video generation could explore several promising avenues. Improving the handling of multiple objects within a scene is crucial; current methods struggle with object separation and accurate motion control when multiple subjects are present. Developing more robust training-free methods for controlling both subject and camera motion, potentially incorporating advanced techniques like inverse kinematics or physics simulation, would enhance the system’s flexibility and realism. The integration of more sophisticated semantic understanding of text prompts to guide both subject behaviors and camera actions could further improve the generated video quality and coherence. Finally, investigating the ethical implications of generating highly realistic customized videos, including strategies to mitigate potential misuse like deepfakes, is paramount. These directions would move the field toward more versatile, controllable, and ethically responsible AI-driven video generation.
More visual insights#
More on figures

This figure illustrates the training and inference stages of the MotionBooth model. During training, the model is fine-tuned on a specific subject using three loss functions: subject region loss, video preservation loss, and subject token cross-attention loss. The inference stage involves using a latent shift module to control camera movement and manipulating cross-attention maps to control subject motion. The figure visually represents the data flow and key components at each stage.

This figure shows a case study on subject learning. The left column shows the results of a pre-trained text-to-video model. The middle column shows the subject images used for training. The right column shows the results of fine-tuning the model with different loss functions. The top row shows the results of fine-tuning with only the region loss, which results in overfitting to the background. The bottom row shows the results of fine-tuning with both region and video preservation loss, which results in better preservation of the video generation capabilities. indicates subject region loss. “Video” indicates video preservation loss. The images are extracted from generated videos.
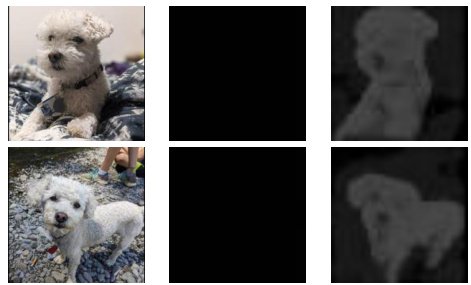
This figure shows a case study on subject learning. It compares the results of pre-trained text-to-video model, subject only learning, region and video loss combined, and region and video loss. The results show that adding subject region loss and video preservation loss leads to better results than using only subject learning.
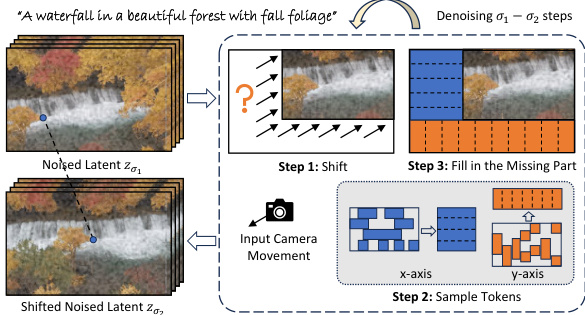
This figure illustrates the process of controlling camera movement in MotionBooth’s video generation. It involves shifting the noised latent (representing the video’s visual information) based on user-specified camera movement ratios (horizontal and vertical). The process is broken down into three steps: 1. Shift: The latent is shifted according to the input camera movement, creating missing regions in the latent space. 2. Sample Tokens: Tokens are sampled from the original latent space to fill these missing regions using context information (semantically similar regions in the latent). 3. Fill in the Missing Part: The sampled tokens are used to replace the missing parts. The overall approach is training-free, enabling efficient and versatile camera movement control.
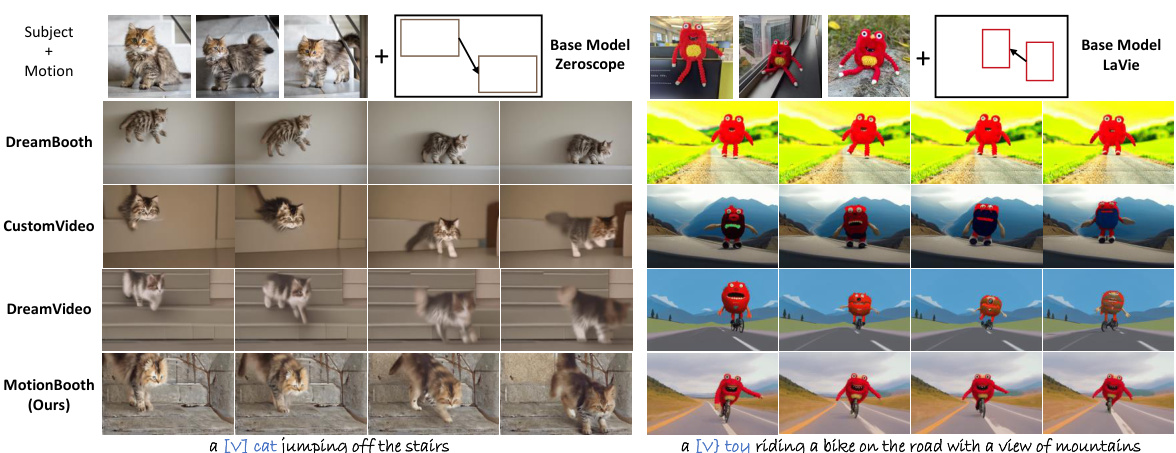
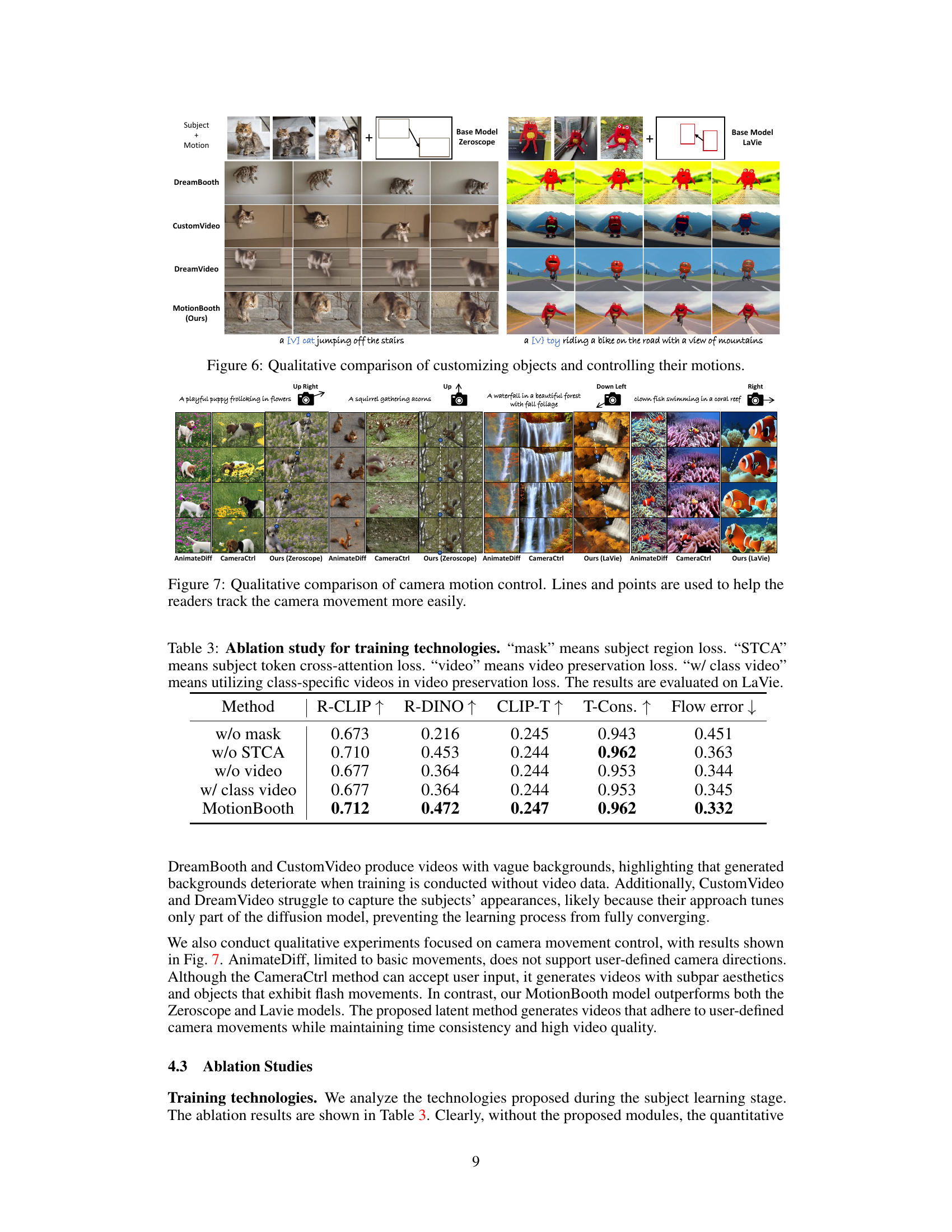
This figure shows a qualitative comparison of different methods for customizing objects and controlling their motions in video generation. The top row shows the input subject and motion. The subsequent rows show the results obtained using various methods, including DreamBooth, CustomVideo, DreamVideo, and the proposed MotionBooth method. For each method, the generated videos are shown for two different prompts: one involving a cat jumping off stairs, and the other involving a toy riding a bike on a road. The comparison demonstrates the superiority of MotionBooth in terms of subject fidelity, motion accuracy, and overall video quality.
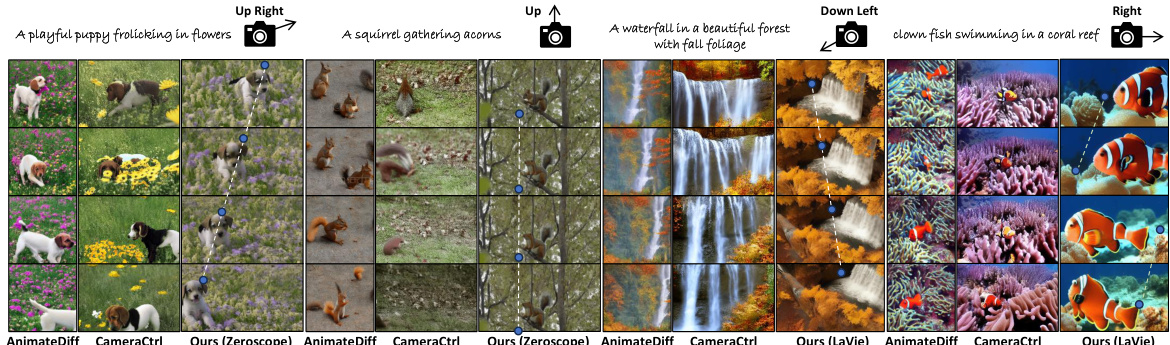
This figure compares the results of camera movement control using different methods: AnimateDiff, CameraCtrl, and MotionBooth (with Zeroscope and LaVie models). The results show generated videos with different levels of control over camera movement, demonstrating MotionBooth’s superior ability to achieve smooth and precise camera control as indicated by the lines and points guiding the viewer’s eyes.
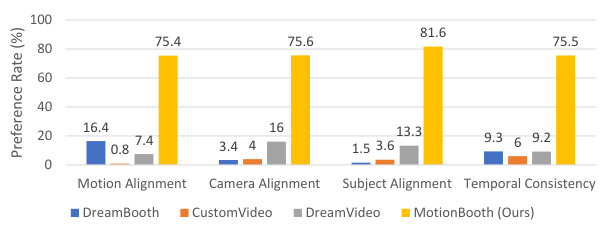
This figure shows the results of a human preference study comparing MotionBooth with three baseline methods (DreamBooth, CustomVideo, and DreamVideo) across four evaluation aspects: motion alignment, camera alignment, subject alignment, and temporal consistency. The bar chart displays the percentage of times each method was selected as the best for each aspect. MotionBooth consistently outperforms the other methods, achieving the highest preference rate in all four aspects, indicating its superiority in generating high-quality videos that are well-aligned with user input and expectations.
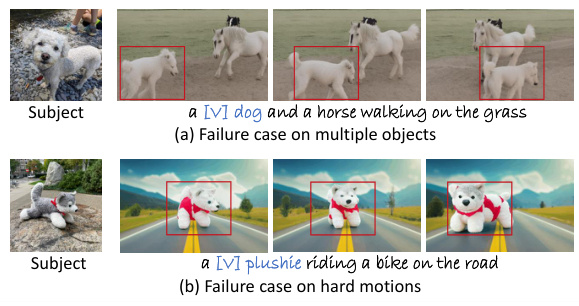
This figure presents two failure cases of the MotionBooth model. (a) shows a failure case involving multiple objects, where the subject’s appearance merges with another object in the scene. (b) shows a failure case with a challenging motion, where the subject performs an unrealistic action, highlighting limitations in subject separation and motion understanding capabilities.

This figure shows the 26 objects used in the evaluation dataset for MotionBooth. The images represent a diverse range of subjects, including pets (dogs, cats), plushies (panda, octopus), toys (robot, monster), cartoons, and vehicles. This diversity allows for a thorough assessment of the model’s performance across various object categories and visual characteristics.

This figure shows the results of MotionBooth, a novel framework for animating customized subjects. The figure demonstrates the ability of MotionBooth to generate videos with precise control over both object and camera movements, even when using only a few images of a specific object. The top row shows the input subject, the subject’s motion, and the camera motion. The bottom row shows the generated videos, which accurately reflect the specified inputs. This highlights MotionBooth’s ability to efficiently fine-tune a text-to-video model to capture the object’s shape and attributes while simultaneously controlling the motions in the generated videos.

This figure showcases the results of MotionBooth, a novel framework for motion-aware customized text-to-video generation. It highlights the ability of the model to animate a specific object—controlled by a few input images—with precise control over both object and camera movements. The examples displayed show diverse scenarios and subject motions, demonstrating the effectiveness of the approach in generating high-quality, customized videos.

This figure compares the results of camera motion control using three different methods: AnimateDiff, CameraCtrl, and MotionBooth (the proposed method). Two base T2V models, Zeroscope and LaVie are used. The top row shows results for videos depicting a playful puppy in flowers; the bottom row shows videos of a villa in a garden. The images illustrate how effectively each method controls camera movement based on user-specified camera trajectories. Lines and points guide the eye to illustrate the camera’s movement trajectory, making it easier to compare the differences in camera movement.

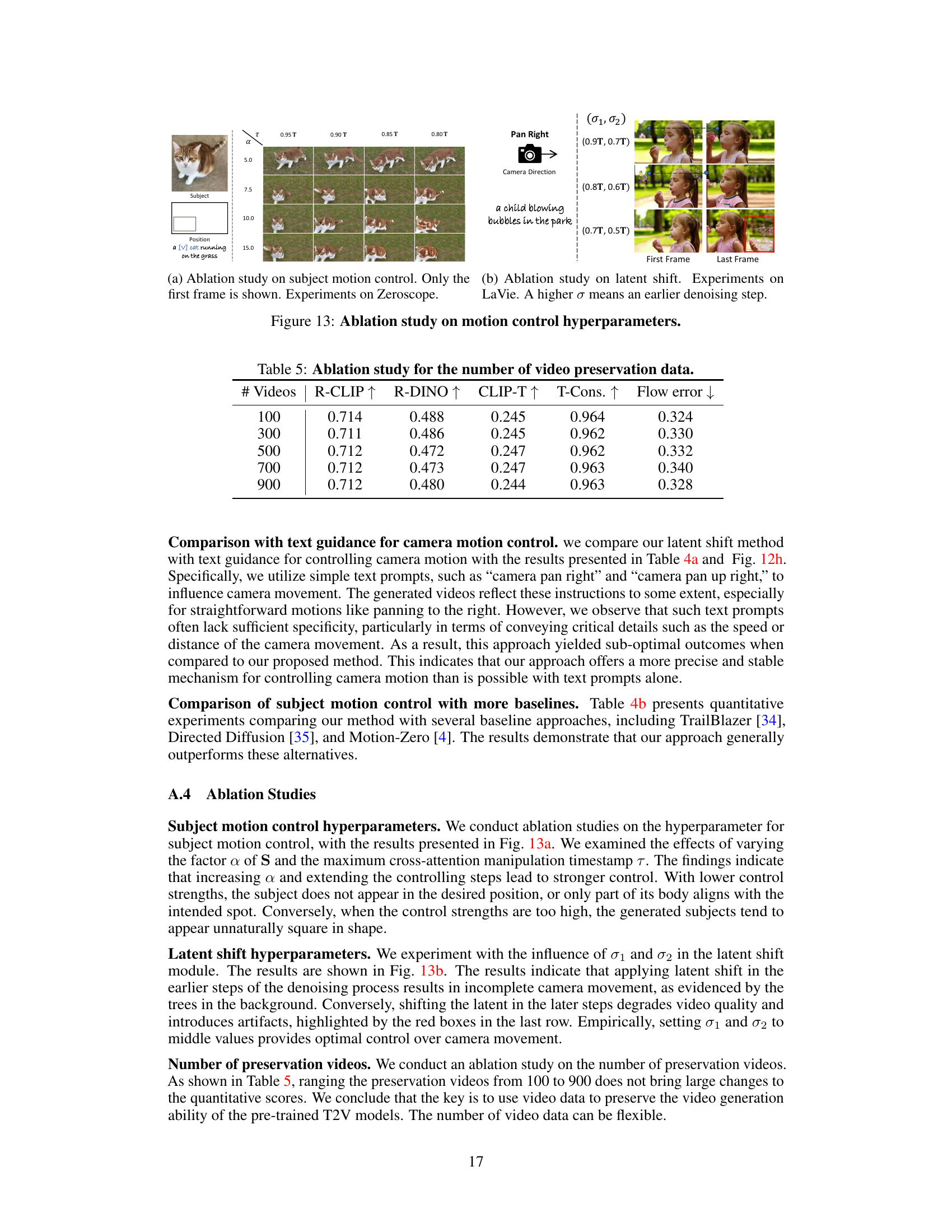
This figure presents ablation studies on the hyperparameters used for controlling motion in the MotionBooth model. Subfigure (a) shows the impact of varying the alpha (α) parameter and the temporal threshold (τ) on subject motion control, using Zeroscope as the base model. Only the first frame of the generated videos is shown for each configuration. Subfigure (b) investigates the effect of different latent shift start (σ₁) and end (σ₂) timesteps during inference, using LaVie as the base model, showing the effects of changing the range of timesteps when the latent shift module is applied. A higher σ value indicates an earlier denoising step. The results demonstrate how these hyperparameters influence the model’s ability to precisely control both subject and camera movements.

This figure showcases the results of the MotionBooth model. Several examples are shown demonstrating the ability to generate videos of customized objects (e.g., a specific dog, toy monster) with precise control over the object’s movement (e.g., jumping, walking) and camera movement (e.g., left, right). The figure visually demonstrates the model’s core capability: animating customized subjects while simultaneously controlling both subject and camera motions.
More on tables
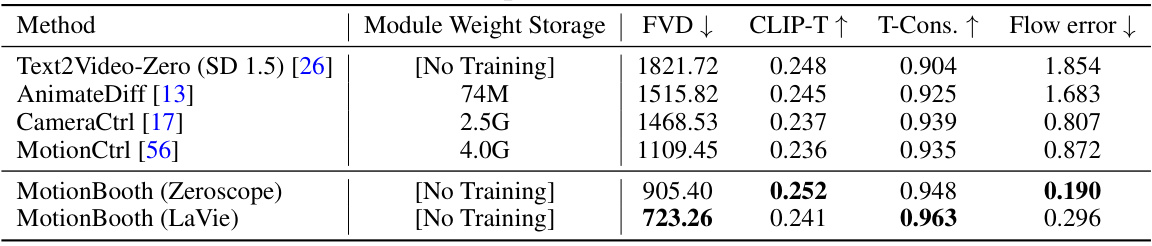
This table compares the performance of MotionBooth’s camera movement control method against several baselines. The metrics used are: FVD (Frechet Video Distance), CLIP-T (CLIP Text-Image similarity), T-Cons (Temporal consistency), and Flow Error. MotionBooth is shown to significantly outperform the baselines in flow error, and it shows comparable or better results in other metrics while having significantly less weight storage. The ‘No Training’ indicates that MotionBooth does not require additional training for camera control, unlike the baselines.
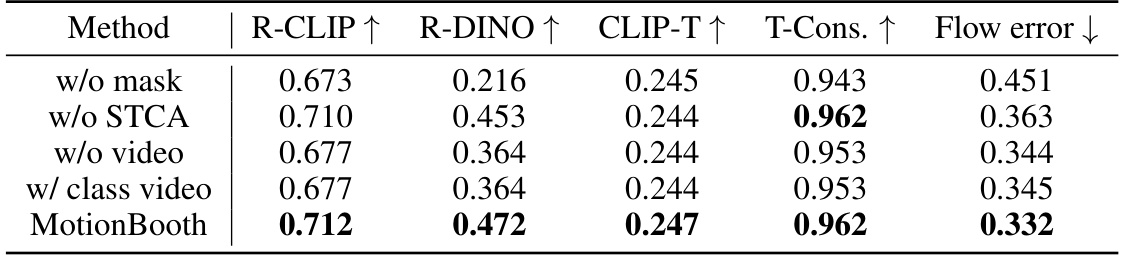
This table presents the results of an ablation study conducted to evaluate the impact of different training technologies on the performance of the MotionBooth model. The study specifically analyzes the contributions of subject region loss, subject token cross-attention loss, and video preservation loss, as well as the effect of using class-specific videos instead of general videos for video preservation loss. The results are reported in terms of several metrics, including R-CLIP, R-DINO, CLIP-T, T-Cons, and flow error, all evaluated using the LaVie model.

This table presents a quantitative comparison of different methods for camera movement control in video generation. It compares MotionBooth (with Zeroscope and LaVie models) against several baselines (Text2Video-Zero, AnimateDiff, CameraCtrl, and MotionCtrl). The metrics used are: FVD (Frechet Video Distance), a measure of video quality; CLIP-T (CLIP Image-Text Similarity), measuring the alignment between generated video frames and text prompts; T-Cons. (Temporal Consistency), evaluating the consistency of video frames; and Flow error, representing the difference between predicted and ground truth optical flow, showing the accuracy of camera motion generation. The table highlights that MotionBooth achieves superior performance in terms of Flow error compared to other methods, demonstrating its effectiveness in camera motion control.
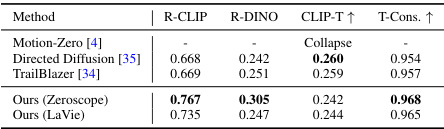
This table presents a quantitative comparison of the proposed MotionBooth method against several baseline methods for both camera and subject motion control. The results are presented in two parts: (a) compares the latent shift method with text guidance for camera motion control and (b) compares the subject motion control capabilities of MotionBooth with other methods, assessing region CLIP similarity (R-CLIP), region DINO similarity (R-DINO), CLIP image-text similarity (CLIP-T), temporal consistency (T-Cons), and flow error. The table highlights MotionBooth’s superior performance in both camera and subject motion control compared to the baselines.
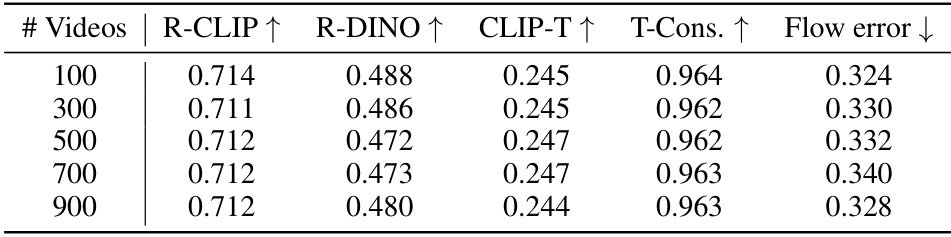
This table presents the results of an ablation study investigating the impact of varying the amount of video preservation data used during training on the performance of the MotionBooth model. The study assesses the effects on several key metrics including R-CLIP, R-DINO, CLIP-T, T-Cons., and Flow error, which capture different aspects of video generation quality. The results show that increasing the number of training videos from 100 to 900 does not significantly impact performance across these metrics.

This table presents a quantitative comparison of MotionBooth against several baseline methods for motion-aware customized video generation. The comparison is done using two different text-to-video models (Zeroscope and LaVie). Metrics include region CLIP similarity (R-CLIP), region DINO similarity (R-DINO), CLIP image-text similarity (CLIP-T), temporal consistency (T-Cons.), and flow error. Higher values are generally better for R-CLIP, R-DINO, CLIP-T, and T-Cons., while a lower value is better for flow error.
Full paper#