↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current vision-language models heavily rely on English-centric datasets like ImageNet, potentially overlooking valuable information from other languages and cultures. This research questions the current data curation practices that often prioritize English data over other languages. The study reveals that this practice might lead to a biased model with limited generalization capability and cultural sensitivity.
To address this, the researchers systematically studied the impact of adding non-English image-text pairs. They translated multilingual data into English for consistent analysis and incorporated them into the training process. Results show that pre-training models on this enriched dataset significantly outperforms using only English data on various benchmark tasks, including those with geographic diversity. This research highlights the importance of intentionally incorporating diverse linguistic and cultural perspectives in vision-language model training to improve performance and mitigate biases.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in vision-language modeling and computer vision. It challenges the current dominance of English-centric datasets, demonstrating the significant performance gains achievable by incorporating multilingual data. This finding opens new avenues for research, particularly in creating more inclusive and robust models. Its findings directly impact dataset creation and model training practices, leading to more generalizable and culturally sensitive models.
Visual Insights#

This figure demonstrates how multilingual data enriches datasets by showcasing culturally specific concepts absent in English-centric datasets (a). It also highlights the visual differences in representing even common objects like ‘stoves’ across different languages (b), illustrating the inherent value of multilingual data in enriching multimodal models.
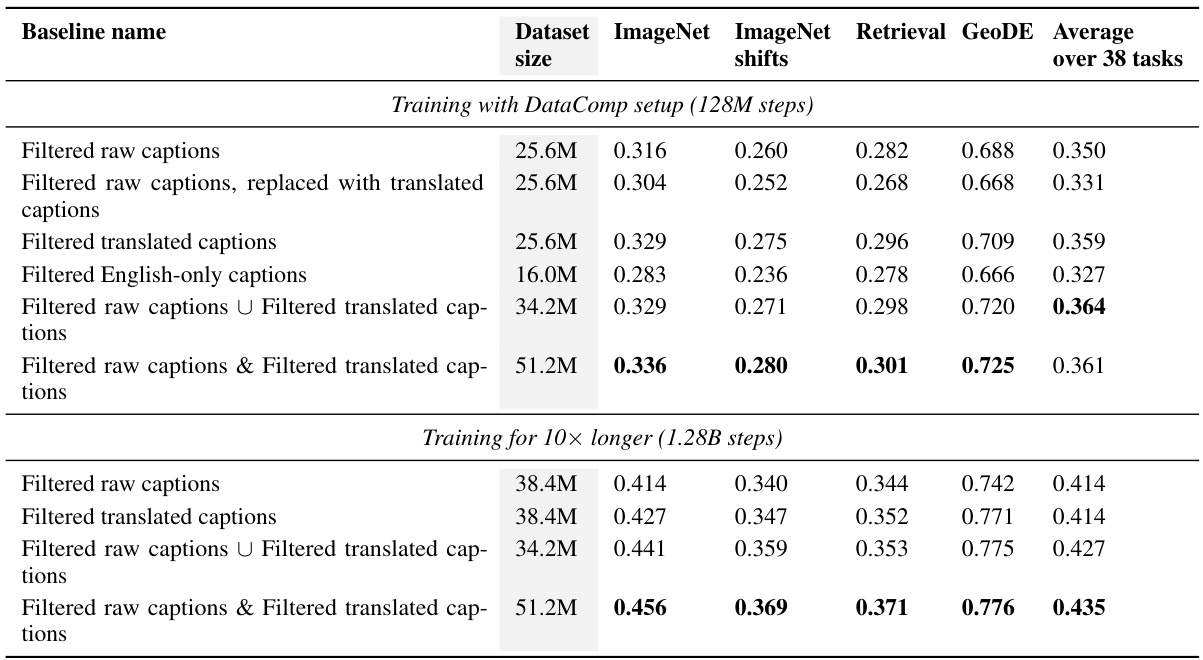
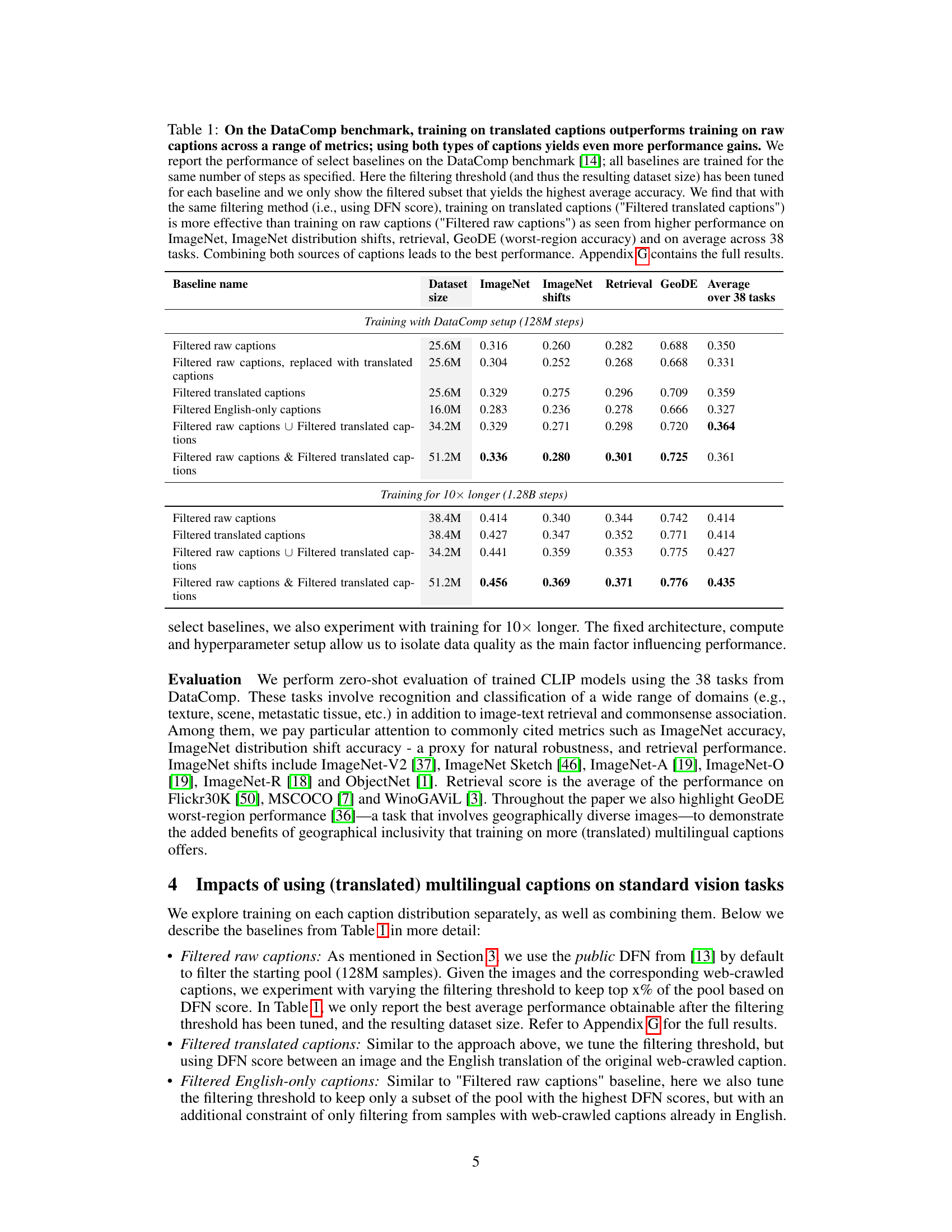
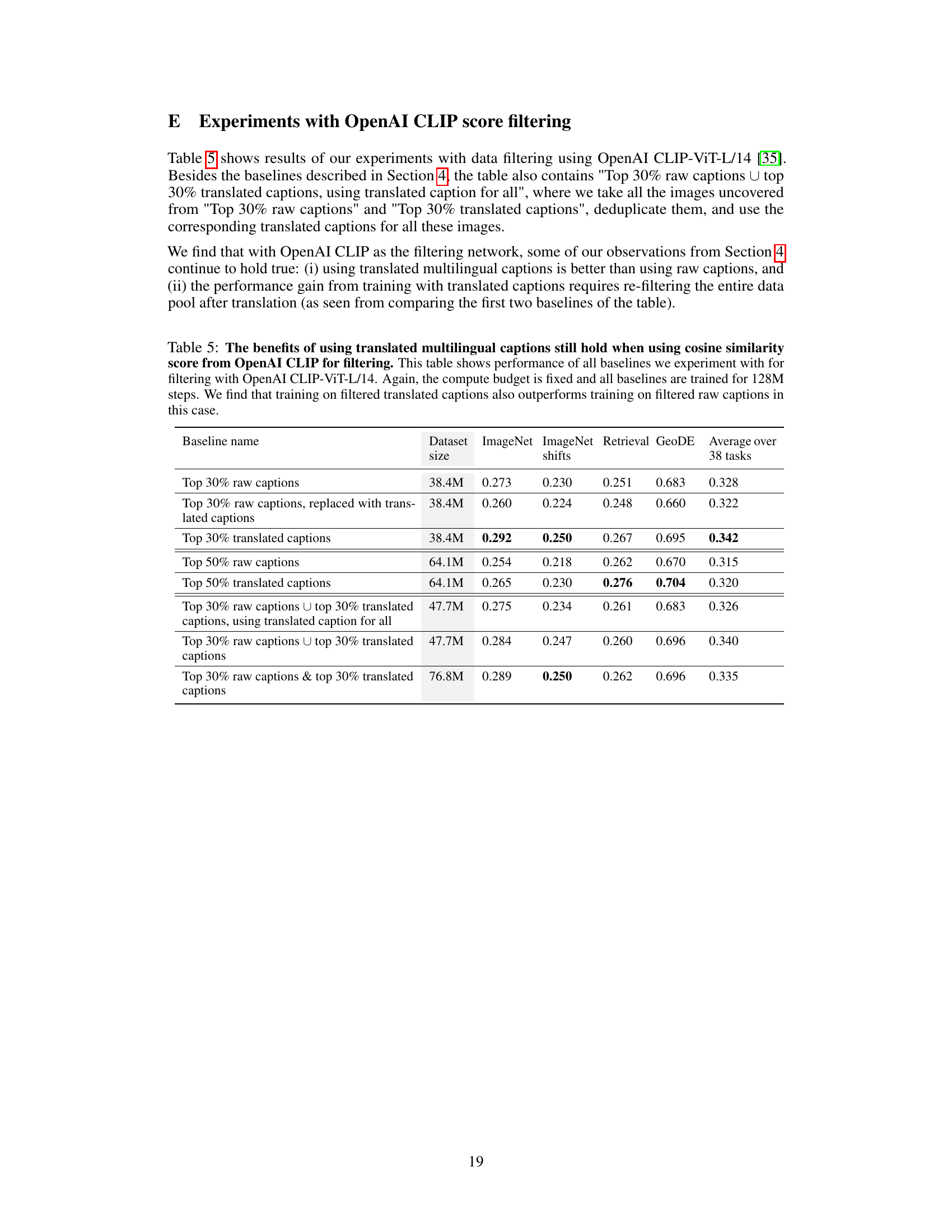
This table presents the results of experiments comparing different training methods on the DataComp benchmark. The methods involve training with filtered raw captions, filtered translated captions, and combinations of both. The table shows that using translated captions leads to improved performance across multiple metrics, including ImageNet accuracy, ImageNet distribution shift accuracy, and retrieval performance. Combining both raw and translated captions yields the best results overall, indicating the benefits of incorporating multilingual data into the training process.
In-depth insights#
Multilingual Vision#
Multilingual vision is a significant advancement in computer vision, moving beyond the limitations of English-centric datasets and models. It leverages the wealth of information available in multiple languages to create more robust and inclusive systems. This approach addresses biases inherent in current models by incorporating diverse linguistic and cultural perspectives. By translating and incorporating non-English data, multilingual vision improves model performance on various tasks and reduces the disparity in accuracy across different language groups. The inclusion of multilingual data introduces new perspectives on object representation, leading to richer feature sets and a deeper understanding of visual concepts across cultures. However, challenges remain in dealing with noisy translation, ensuring data quality, and mitigating potential biases introduced during data preprocessing. Future work should focus on developing robust methods for data cleaning and filtering, incorporating diverse translation approaches, and further investigating the impact of multilingual data on model generalization and fairness.
Translation Effects#
The study’s exploration of “Translation Effects” reveals crucial insights into the impact of multilingual data on vision-language models. Translation, while seemingly a simple preprocessing step, significantly alters the data distribution, enriching it with culturally diverse concepts and visual representations not found in English-centric datasets. The findings demonstrate that models trained on translated multilingual data outperform those trained on English-only data across various tasks, highlighting the value of incorporating multilingual data, even for English-focused tasks. This improvement is particularly notable on geographically diverse benchmarks, suggesting that translated data mitigates biases inherent in monolingual datasets. However, the study also acknowledges the limitations of translation, noting potential loss of nuance and the introduction of artifacts, thereby influencing future research directions to explore the optimization of this process for further improvements in model performance and mitigating biases.
Bias Mitigation#
Mitigating bias in vision-language models requires a multifaceted approach. Data bias is a primary concern, stemming from the skewed geographic and linguistic distributions in commonly used datasets. Addressing this necessitates strategies like diversifying data sources, actively including non-English and geographically diverse image-text pairs, and possibly employing techniques to rebalance class distributions within existing datasets. Furthermore, model bias can emerge during training, even with unbiased data. Methods for combating this include careful model architecture design, regularization techniques to reduce overfitting, and adversarial training to improve robustness. Finally, evaluation bias needs to be acknowledged, as standard benchmarks might be culturally or geographically skewed, leading to an inaccurate assessment of model performance. To counter this, researchers should incorporate a diverse array of metrics and benchmarks representing a more inclusive spectrum of visual concepts and linguistic styles. A comprehensive approach should consider all these interconnected aspects to effectively reduce bias.
Data Diversity Wins#
The concept of “Data Diversity Wins” highlights the significant performance improvements achieved by incorporating diverse data sources in training machine learning models. It challenges the conventional approach of relying heavily on English-centric data, which can introduce biases and limit generalizability. The core idea is that multilingual and multicultural data enrich model representations by providing diverse perspectives on common concepts and highlighting culturally salient ones. This diversity isn’t merely beneficial for non-English tasks but, surprisingly, boosts performance even on standard English-centric benchmarks, suggesting a more generalizable and robust model is produced. The findings underscore the importance of moving beyond monolingual biases in data curation, advocating for the deliberate inclusion of diverse datasets to enhance model capabilities. Translation plays a crucial role, allowing for the integration of non-English data while maintaining a common language for analysis. However, it is also noted that the process might introduce artifacts and possibly lose some richness, highlighting the need for more nuanced approaches to multilingual data integration in the future.
Future Directions#
The paper’s “Future Directions” section would ideally delve into several promising avenues. One key area is improving the translation methods used to incorporate non-English data. Exploring more advanced, nuanced translation techniques that better preserve cultural context and meaning is crucial. Addressing the limitations of relying solely on English-centric benchmarks is also vital; proposing the development and adoption of truly multilingual benchmarks would provide more robust evaluations of vision-language models. Investigating the interplay between image and text features within a multilingual context, perhaps identifying unique visual-linguistic patterns across different cultural backgrounds, represents another critical path forward. Finally, the study could explore extending the analysis beyond image classification to other downstream tasks, like visual question answering or image caption generation, to fully grasp the impact of multilingual diversity on model performance across various modalities.
More visual insights#
More on figures
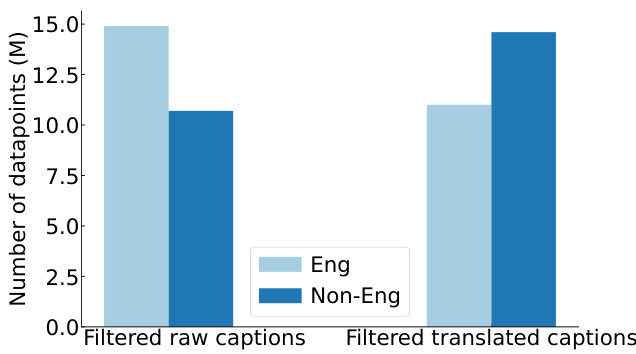
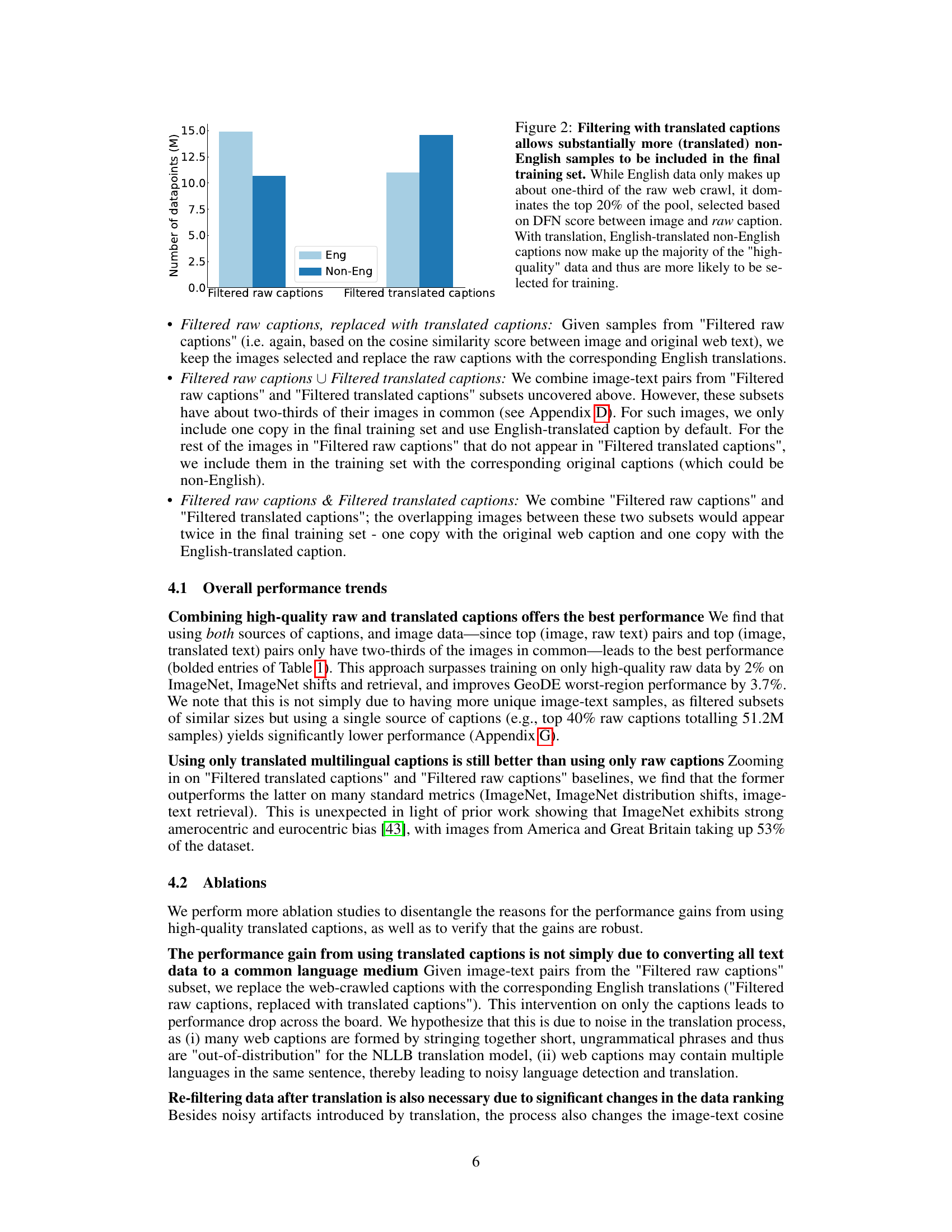
This figure is a bar chart comparing the number of English and non-English data points before and after translation and filtering. Before filtering (using the Data Filtering Network - DFN), English data points constitute only one-third of the data. After filtering with raw captions, English data points make up the majority of the top 20% (highest quality) samples. However, after translating non-English captions to English and then re-filtering, the majority of the top 20% samples are (translated) non-English data points. This shows how the translation process and the filtering algorithm can drastically increase the amount of non-English data selected, which indicates the potential of non-English data to increase dataset diversity and model performance.
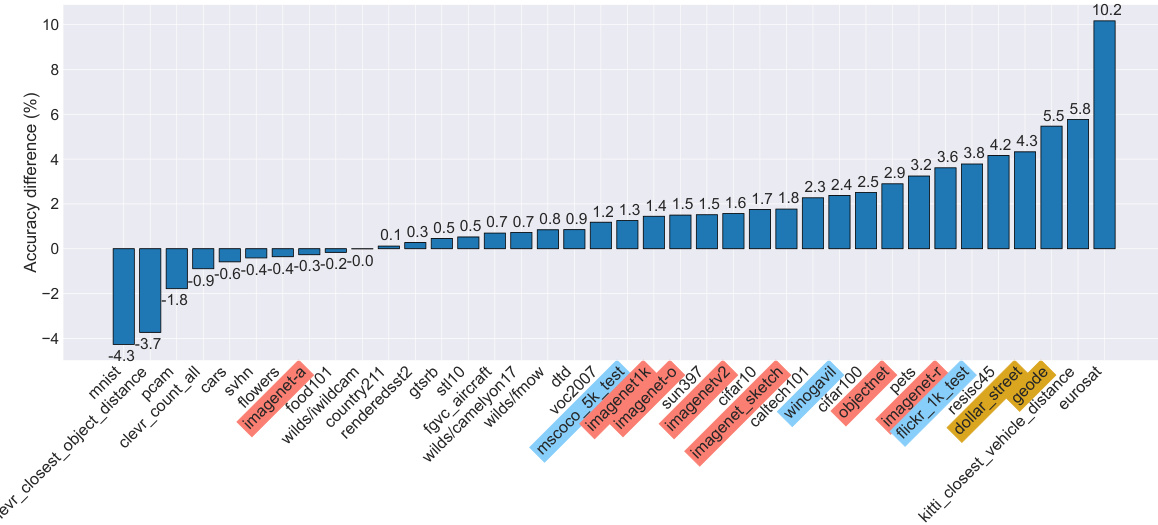
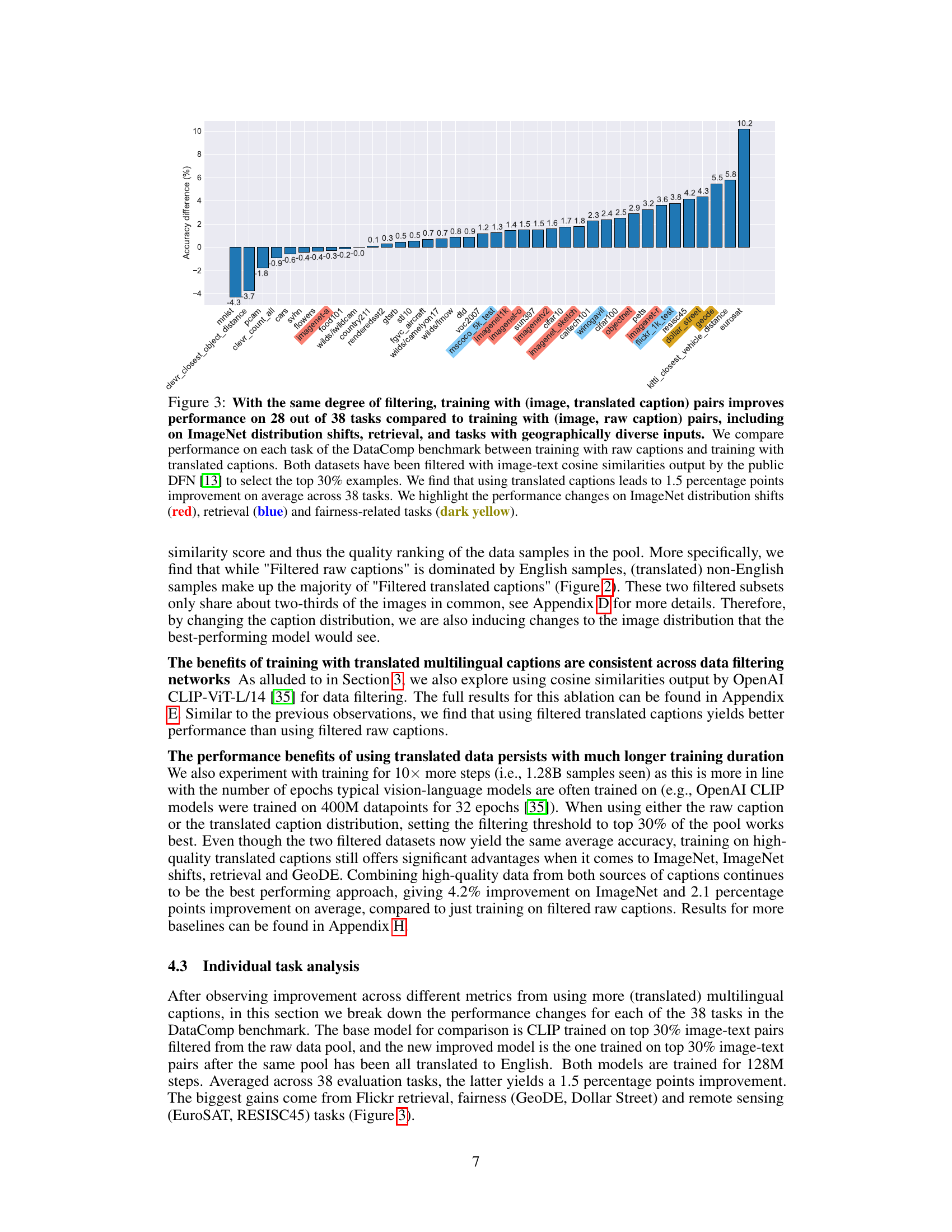
This figure shows the performance difference between using raw captions and translated captions for training on 38 different tasks from the DataComp benchmark. The results indicate that using translated captions leads to improved performance in most of the tasks, especially those involving ImageNet distribution shifts, retrieval, and fairness-related tasks. The improvement is highlighted in different colors for better visualization.

This figure shows the performance improvement on GeoDE (a geographically diverse benchmark) when using translated multilingual captions for training, compared to using only English captions. The bar chart displays a significant increase in accuracy across all geographical regions, most notably in Africa. This visually represents the benefit of incorporating diverse cultural and linguistic data in model training, demonstrating improved performance on tasks beyond those focused on English-speaking regions.
This figure demonstrates how multilingual data enriches vision-language datasets. Panel (a) showcases examples of culturally specific concepts from non-English datasets that are absent in English-centric datasets like those filtered by CLIP. Panel (b) illustrates how even common objects like stoves are visually depicted differently across languages, highlighting the visual diversity introduced by multilingual data. This diversity is not just about word choices but also about the visual representations of the objects.

This figure shows how multilingual data adds diversity to English-centric datasets. Panel (a) illustrates examples of culturally specific concepts (bamboo steamer, kiji bird, yalı house) rarely found in English-only datasets. Panel (b) demonstrates how even common objects (stoves) have different visual representations across different languages, highlighting the richness and variety of multilingual data.

This figure demonstrates how multilingual data enriches datasets by showing examples of culturally specific items and variations in visual representations of common objects. Panel (a) highlights concepts likely absent from English-centric datasets, illustrating the value of including non-English data. Panel (b) shows how even common objects like ‘stoves’ are depicted differently across languages, emphasizing the diversity in visual representation.

This figure demonstrates how multilingual data enriches vision-language datasets by showcasing two key aspects: (a) It illustrates the inclusion of culturally specific concepts not commonly found in English datasets, such as a bamboo steamer, the Japanese national bird (kiji), and a traditional Turkish waterside house (yalı). These examples highlight the limitations of English-centric datasets. (b) It shows how even common objects, like a stove, are visually represented differently across languages and cultures, demonstrating the value of multilingual data for creating more robust and comprehensive visual representations.

This figure demonstrates how multilingual data enriches vision-language datasets. Panel (a) showcases examples of culturally specific objects that are unlikely to appear in English-centric datasets, illustrating the increased conceptual diversity offered by multilingual data. Panel (b) compares the visual representation of a common object (‘stove’) across different languages, highlighting the diverse visual interpretations of the same concept.

This figure shows how multilingual data introduces diversity into vision-language models. Panel (a) demonstrates that multilingual datasets include culturally specific concepts absent in English-centric datasets. Panel (b) illustrates that even for common objects like stoves, the visual representation differs significantly between English and non-English datasets, highlighting the enriching potential of multilingual data.

This figure shows how multilingual data enriches datasets by providing culturally salient concepts and visually diverse representations of common objects. Panel (a) demonstrates this by showing examples of items unlikely to be found in English-centric datasets. Panel (b) illustrates how even common objects like stoves are depicted differently in various languages, highlighting the value of multilingual data in improving multimodal models.

This figure shows how multilingual data adds diversity to English data. Panel (a) gives examples of concepts prevalent in non-English cultures that are absent from English-centric datasets, highlighting the cultural richness multilingual data offers. Panel (b) illustrates that even for common objects like stoves, the visual representation can differ significantly between English and non-English data sources.
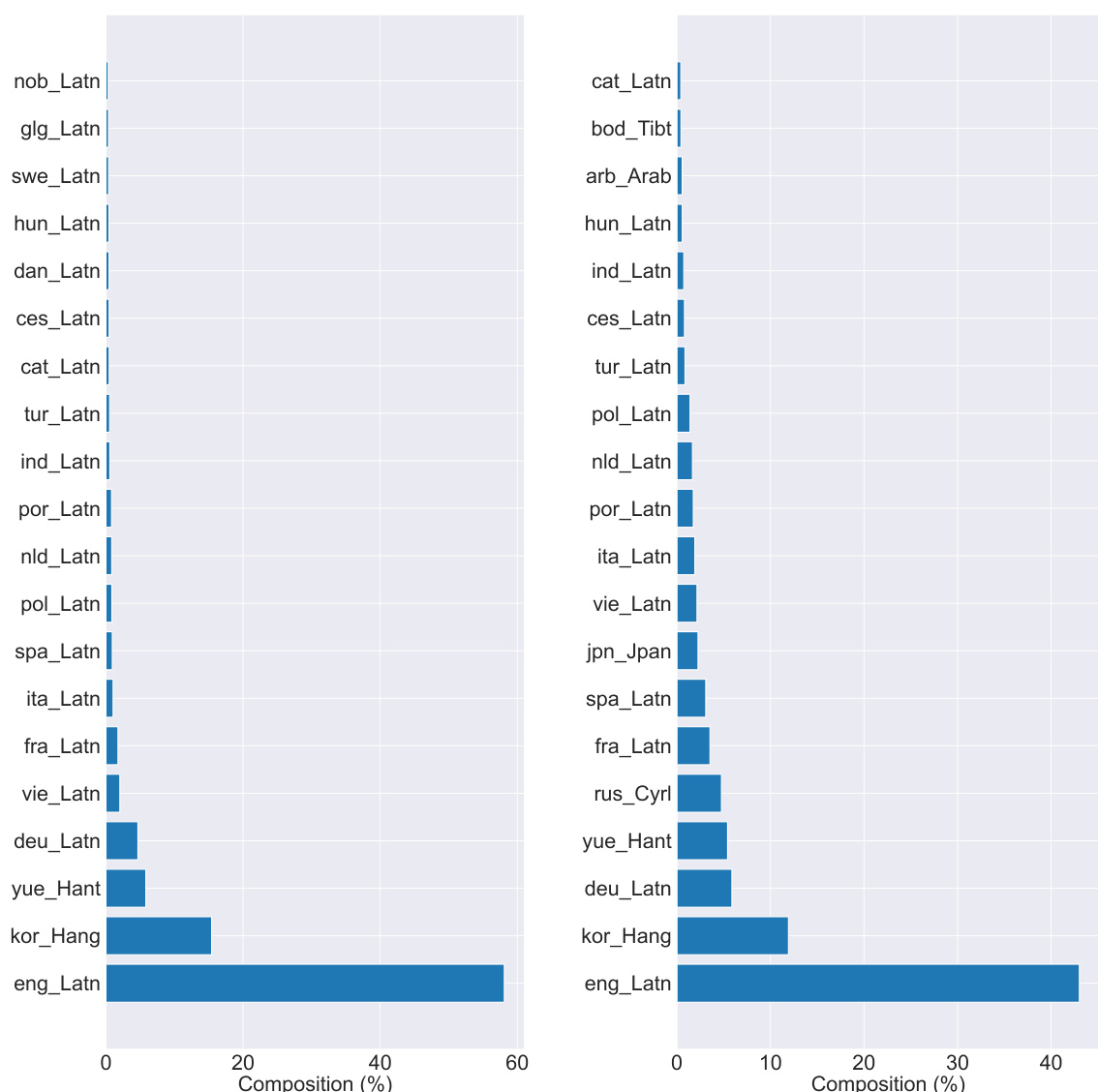
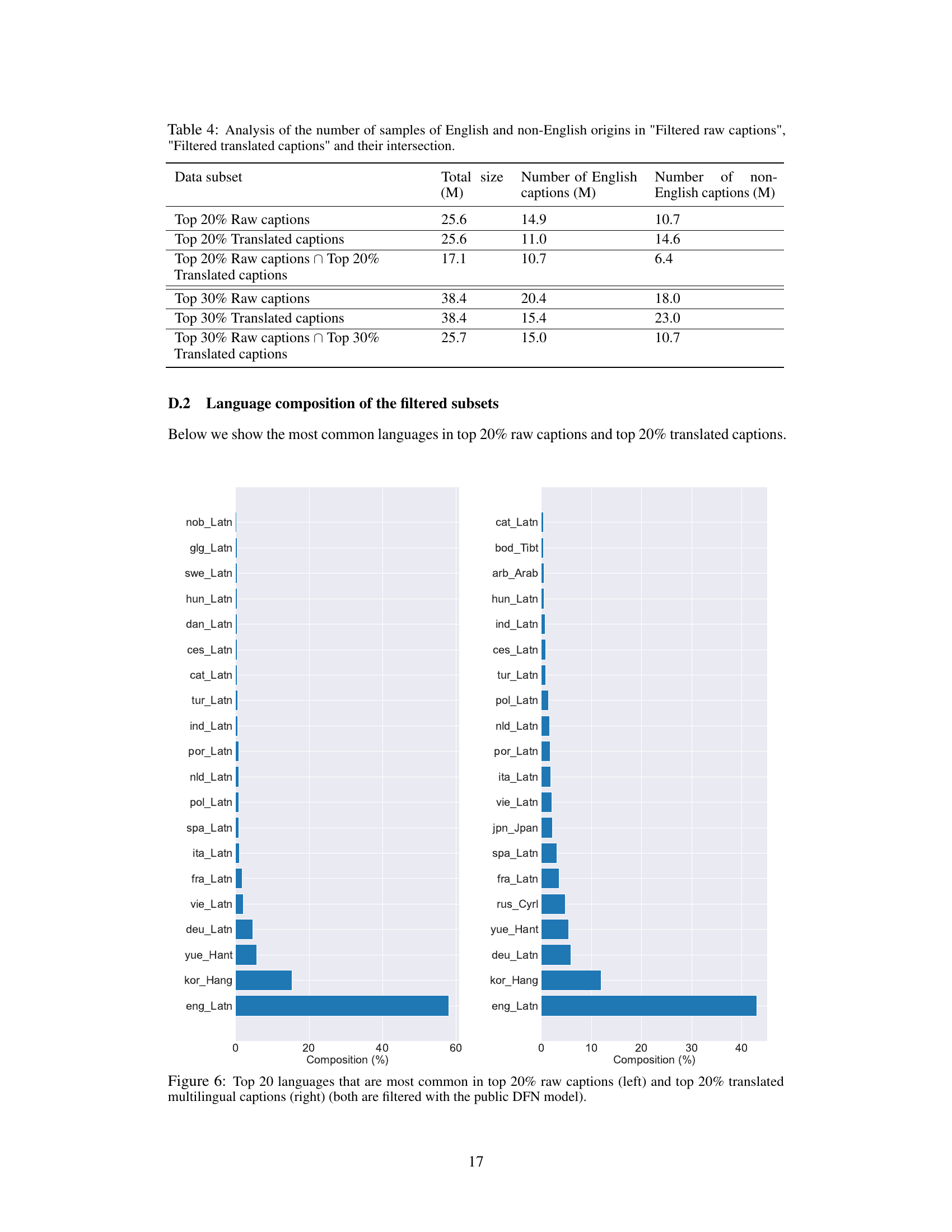
This figure shows the language distribution of the top 20% of image-text pairs selected by the DFN filter from the raw data pool (left) and the translated data pool (right). The left chart represents the original language distribution before translation. The right chart shows the distribution after all captions have been translated to English. The visualization helps demonstrate how the translation process and subsequent filtering change the representation of different languages in the dataset. English dominates the original data, but the translated dataset shows a more diverse distribution, though English remains highly prevalent.
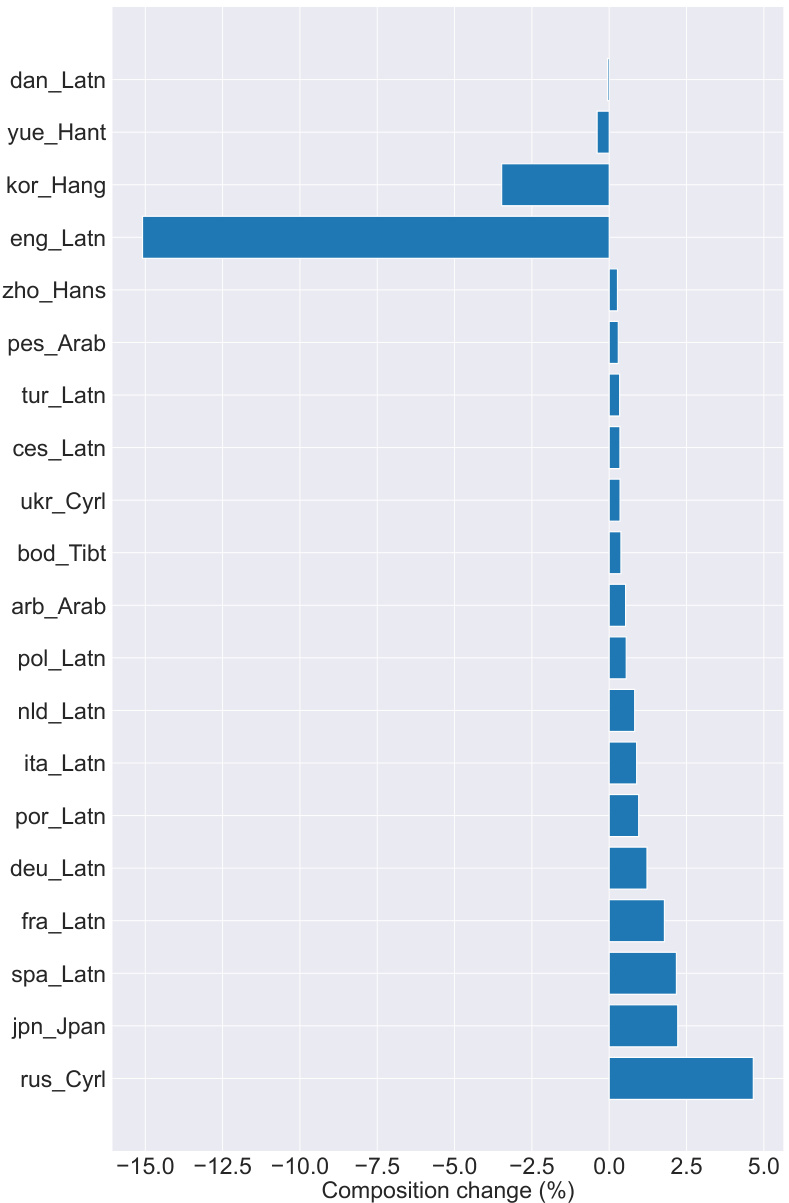
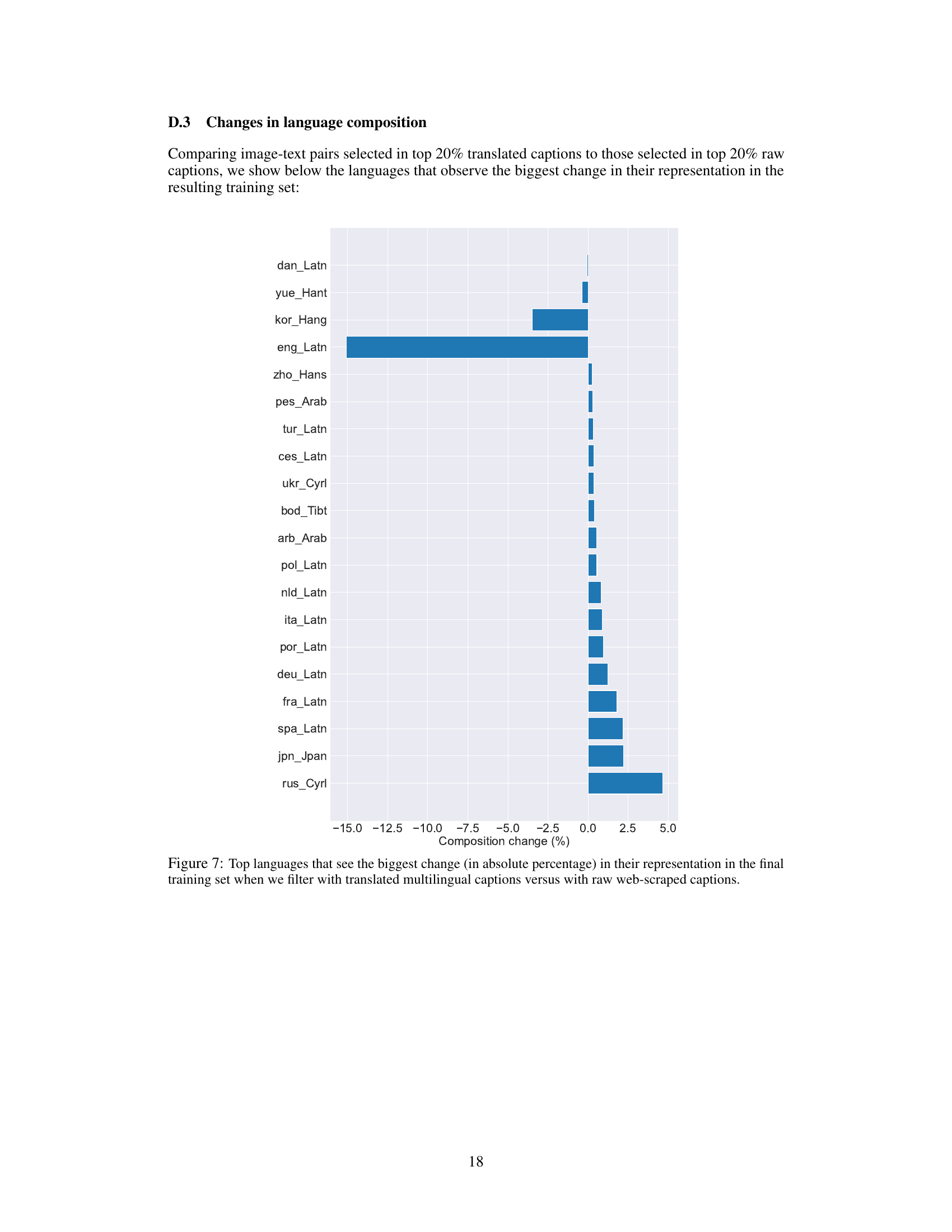
This figure shows the change in the proportion of different languages in the training dataset after applying translation and filtering. The x-axis represents the percentage change in the proportion of each language after translation and re-filtering compared to before translation. Positive values indicate an increase in the language’s proportion, negative values indicate a decrease. The figure highlights which languages saw the most significant shifts in their representation in the final, high-quality training dataset.
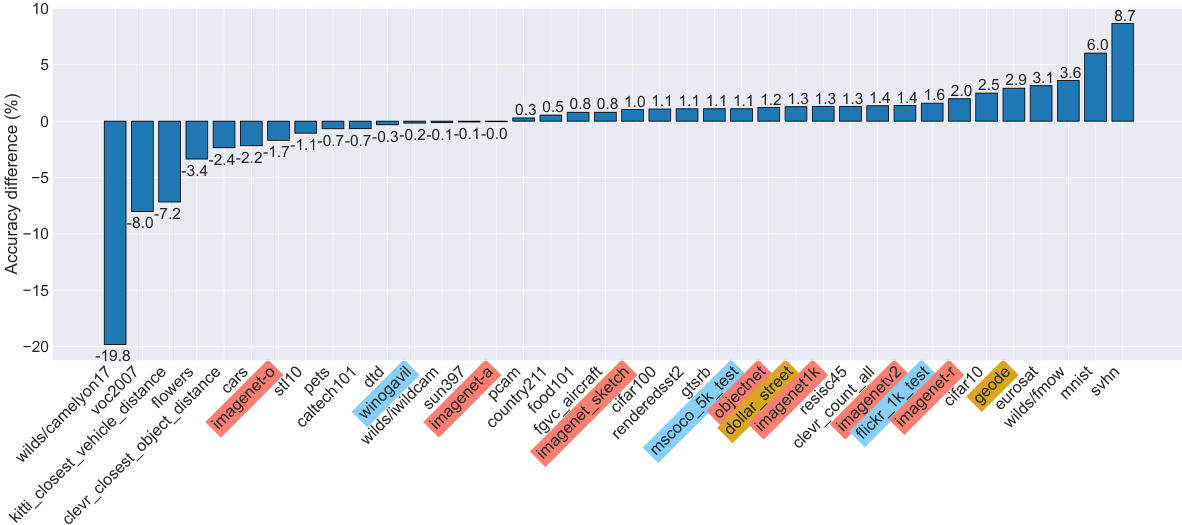
This figure compares the performance of models trained on datasets with raw captions and translated captions across 38 tasks from the DataComp benchmark. The datasets were filtered using cosine similarity scores to select the top 30% of samples. The results show that using translated captions leads to performance improvements on many tasks, especially those related to ImageNet distribution shifts, retrieval, and fairness.

This figure shows the improved performance of using translated multilingual captions on the Dollar Street dataset, which focuses on fairness. The dataset consists of images of common objects collected from households across various income levels globally. The results demonstrate that using the translated captions improves accuracy across all income groups compared to using only raw captions. The improvement underscores the benefit of incorporating multilingual data for enhancing model performance on fairness-related tasks.

This figure demonstrates how multilingual data introduces diversity into vision-language datasets. Panel (a) showcases examples of culturally specific objects, which are unlikely to appear in English-centric datasets. Panel (b) shows how even common objects like stoves are depicted differently across languages, highlighting the visual diversity introduced by non-English data.
More on tables
This table presents the results of experiments conducted on the DataComp benchmark using different training data: filtered raw captions, filtered translated captions, and combinations thereof. The table shows that training with translated captions generally outperforms using only raw captions across various metrics including ImageNet accuracy, ImageNet distribution shift accuracy, retrieval performance, and average performance across 38 tasks. The best performance is achieved by combining both filtered raw and translated captions. The table also includes results when training for a longer duration (10x longer).
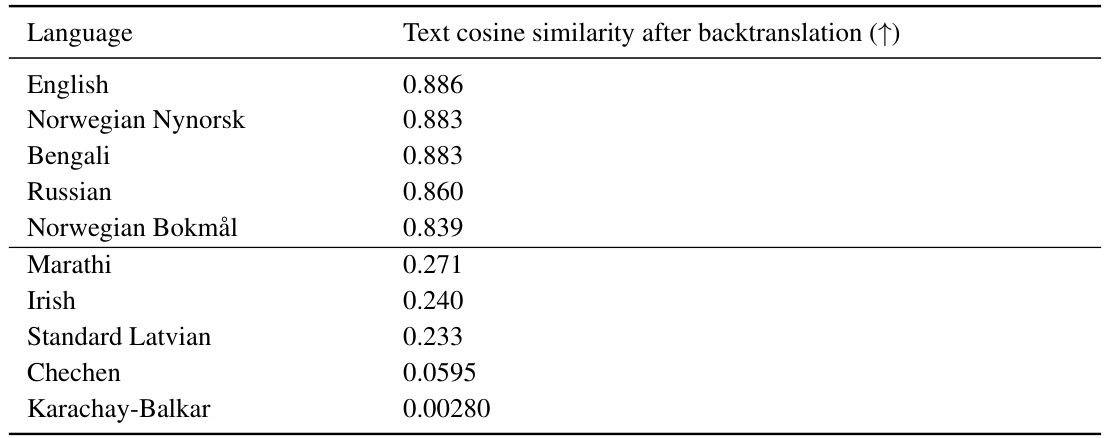
This table compares the performance of different training methods on the DataComp benchmark. The methods vary in how they use raw and translated captions, as well as the size of the filtered training dataset. The table shows improvements when using translated captions, particularly when combined with raw captions, across a range of metrics including ImageNet accuracy, ImageNet distribution shift, retrieval accuracy, and GeoDE (a geographically diverse task). The results suggest that incorporating translated multilingual data improves model performance, especially when combined with English data.
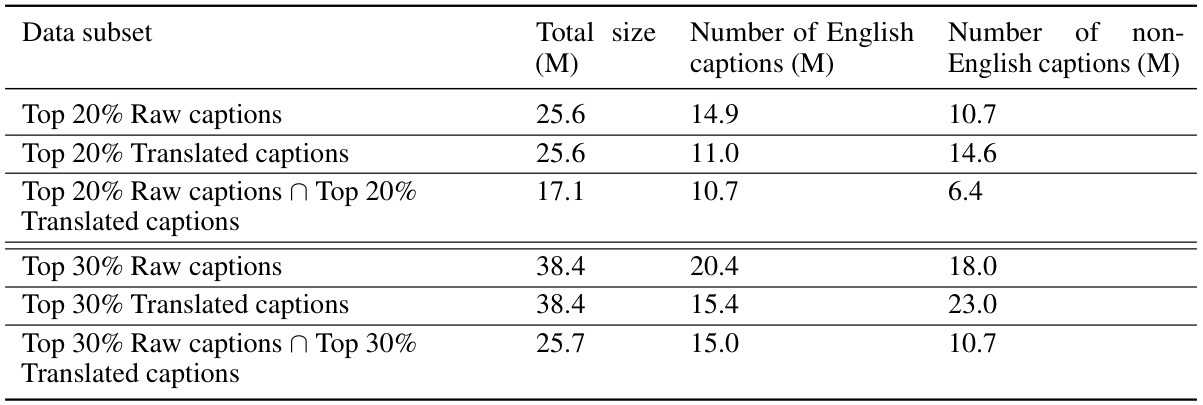
This table presents the results of several experiments on the DataComp benchmark, comparing different approaches to training a CLIP model. The key comparison is between using only English captions, raw multilingual captions, translated multilingual captions, and combinations of these. The table shows the dataset sizes after filtering, and the performance on ImageNet, ImageNet distribution shifts, image retrieval, and a geographically diverse task (GeoDE) and average across 38 tasks from the DataComp benchmark.
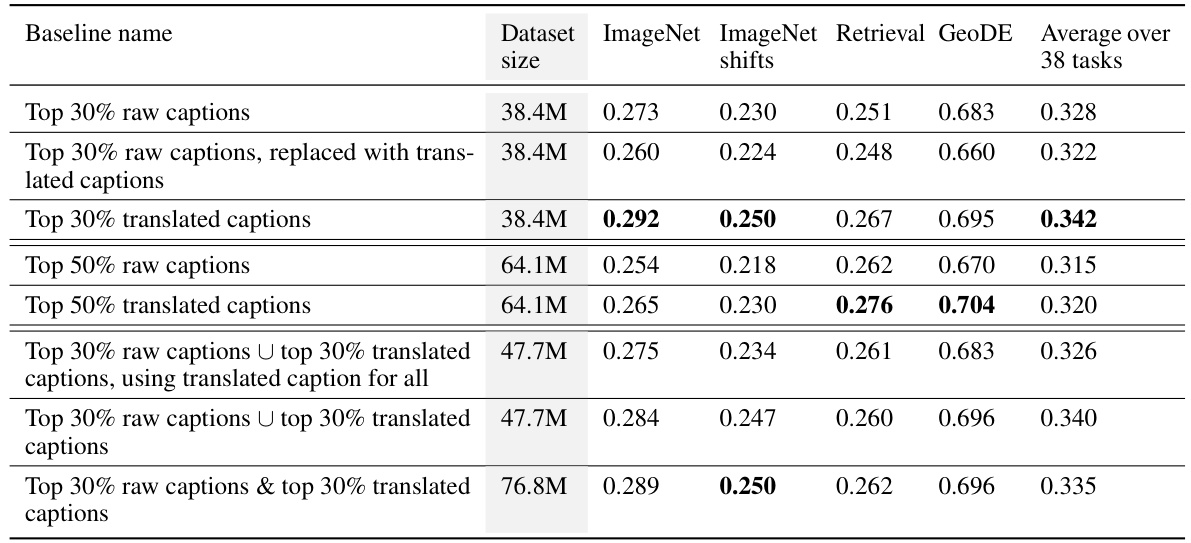
This table presents the results of several experiments on the DataComp benchmark, comparing different methods of training a CLIP model. The key comparison is between using only English captions, only translated non-English captions, and combining both. The table shows that using translated non-English captions, and particularly combining them with English captions, leads to significant improvements in various metrics, such as ImageNet accuracy, ImageNet distribution shift accuracy, retrieval performance, and average performance across 38 DataComp tasks. The results are presented for different dataset sizes achieved through varying filtering thresholds. The experiment uses the same training steps for all baselines, allowing for direct comparison based solely on data composition.
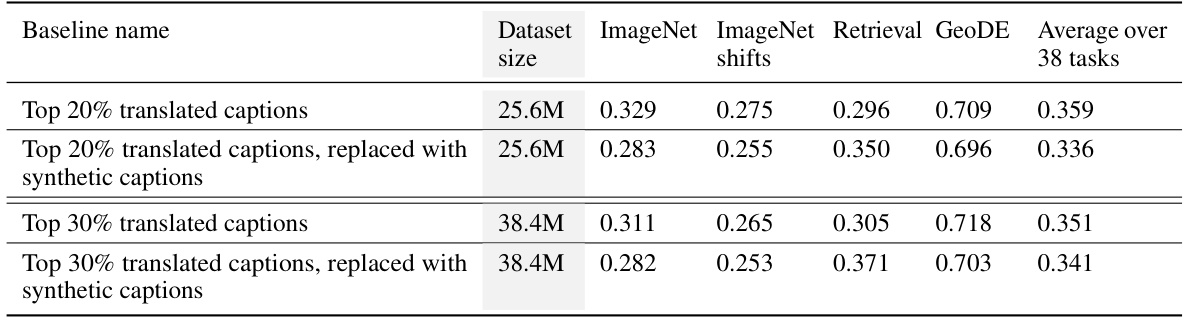
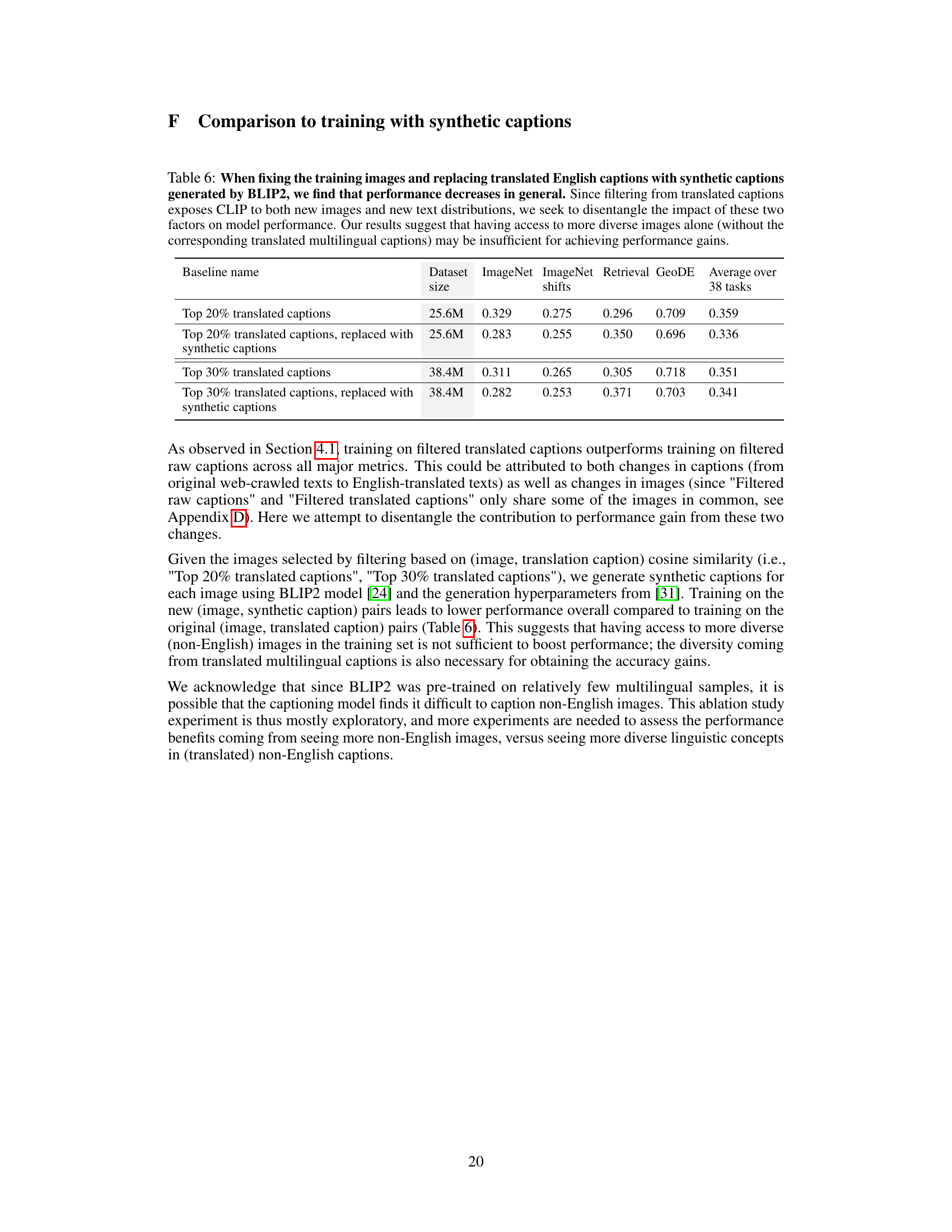
This table presents an ablation study to understand the impact of translated multilingual captions on model performance. It compares performance when using translated captions against performance when replacing the translated captions with synthetic captions generated by BLIP2, while keeping the training images the same. The results show that simply having diverse images is not enough to replicate the performance gains from using translated multilingual captions, highlighting the importance of both diverse images and diverse text for improved model performance.
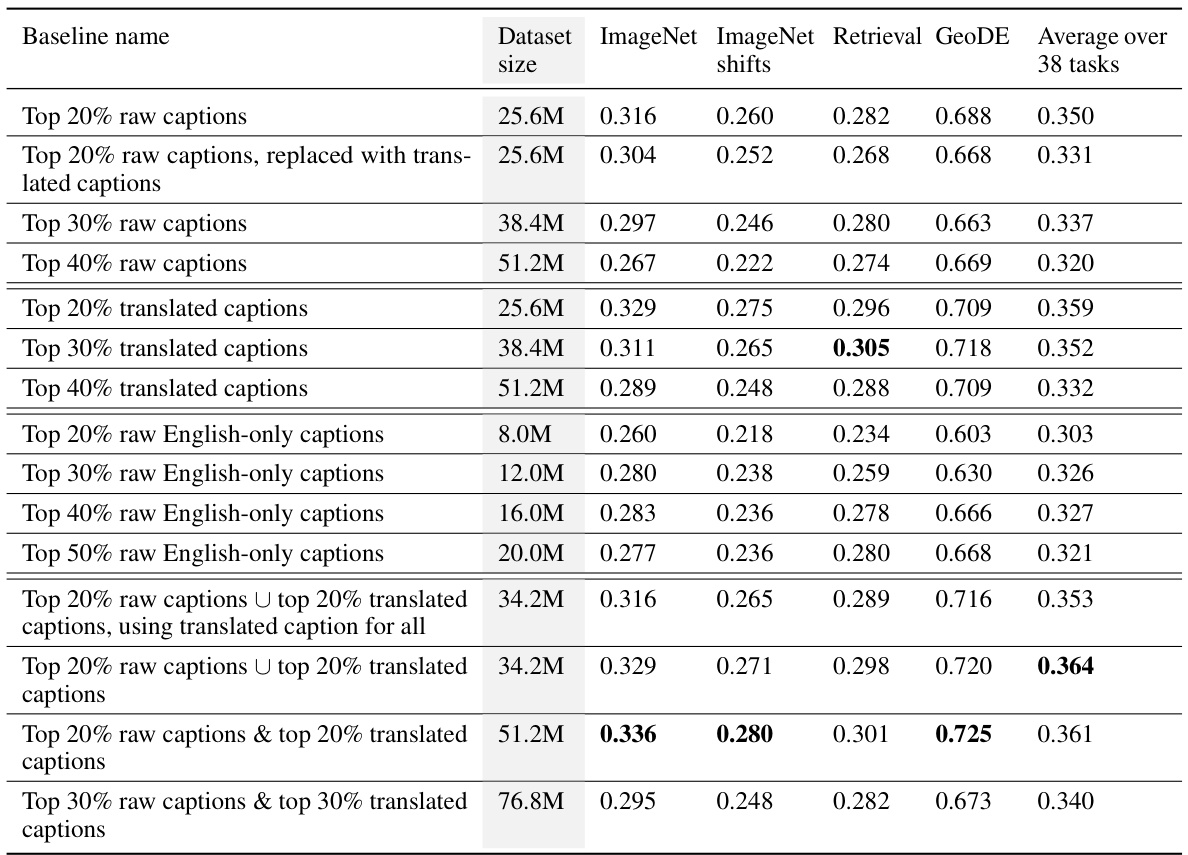
This table presents the results of experiments on the DataComp benchmark, comparing the performance of different training methods on several metrics. The methods involve training on filtered raw captions, filtered translated captions, and combinations of both. The table shows that using translated captions improves performance on ImageNet, ImageNet distribution shifts, retrieval, and an average of 38 tasks in the DataComp benchmark, with the best performance achieved when combining both raw and translated captions.
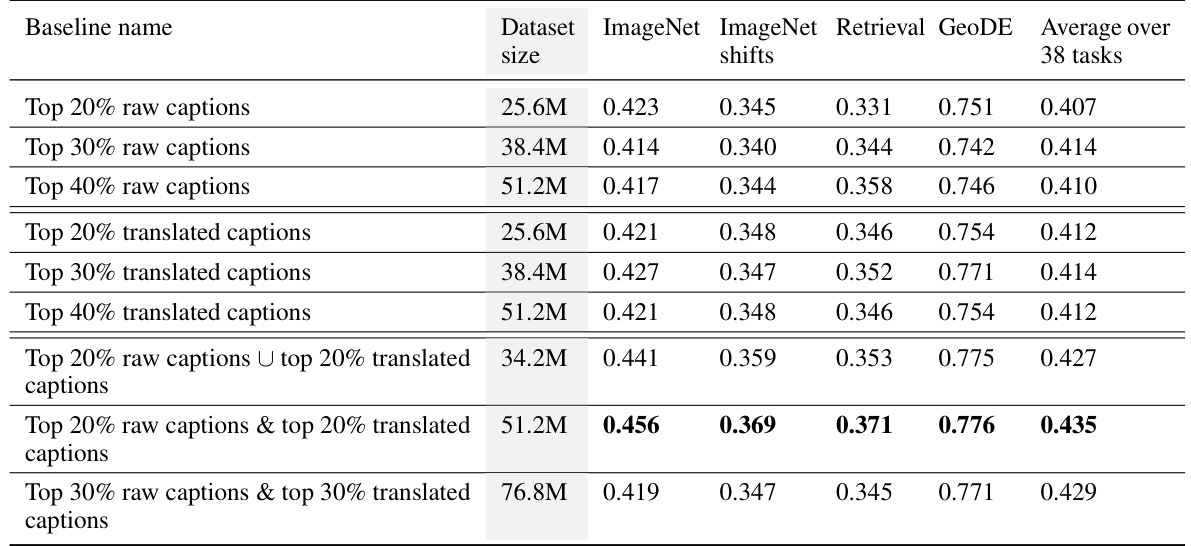
This table presents the results of experiments on the DataComp benchmark, comparing the performance of different training methods on various metrics. The methods involve using only raw captions, only translated captions, and combinations of both. The table demonstrates that using translated captions improves performance across ImageNet, ImageNet distribution shifts, retrieval, and GeoDE, especially when both raw and translated captions are combined. The filtering threshold is tuned for each method to maximize average accuracy across 38 tasks.
Full paper#